文章目錄
- 一.常用排序演算法的種類及其時間復雜度和穩定性
- 二.對部分排序演算法的決議以及代碼實作
- 1.選擇排序法
- 2.冒泡排序法
- 3.插入排序法
- 4.希爾排序法
相信很多同學對排序演算法都有了不同程度的理解,這篇文章僅僅是為了總結一些常用的排序演算法的原理,追求更加深入的理解這些排序演算法的實作原理,更加細致地去理解代碼為什么要這么個寫法,雖然真正需要對資料排序的時候沒有必要自己再寫一個排序演算法,直接呼叫內置函式即可,但是深入地去理解這些演算法的實作方式,其實會發現這其中有許多的樂趣,哎!就是玩兒~,
第一次寫,歡迎指正~~
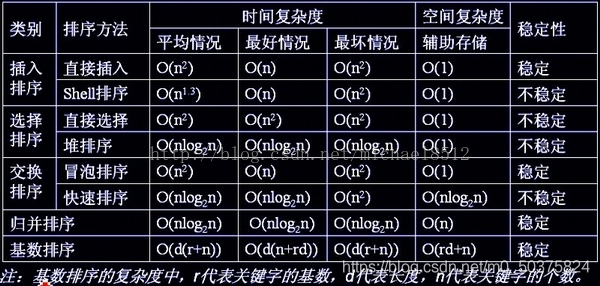
一.常用排序演算法的種類及其時間復雜度和穩定性
| 種類 | 時間復雜度 |
|---|---|
| 選擇排序法 | O(n^2) |
| 冒泡排序法 | O(n^2) |
| 插入排序法 | O(n^2) |
| 希爾排序法 | O(nlog2n) |
| 歸并排序法 | O(nlog2n) |
| 快速排序法 | O(nlog2n) |
| 堆排序法 | O(nlog2n) |
| 計數排序 | O(n+k) |
| 桶排序 | O(n+k) |
| 基數排序 | O(n*k) |
二.對部分排序演算法的決議以及代碼實作
1.選擇排序法
1.1 作業原理:
對未排序的序列進行遍歷,找到最大(小)的元素,將其放在該序列的起始位置,然后再從對未進行排序的序列進行遍歷,繼續尋找最大(小)的元素,放到該未排序序列的起始位置,以此類推,直到所有元素都排序完畢,
1.2 具體代碼實作:
int Selection_Sort(int array[],int size)
{
int temp;
for (int i=0; i < size-1; i++) //外層回圈
{
for (int j = i + 1; j < n; j++) //內層回圈
{
if (array[j] < array[i]) //這個if就是實作比對的程序
{
temp = array[j]; //交換元素的程序
array[j] = array[i];
array[i] = temp;
}
}
}
return 0;
}
當然此處函式的傳入引數也可以不是陣列名而是一個指向陣列的指標變數,如*array也是可行的,
1.3 程序分析:
利用兩層回圈,外層回圈遍歷序列中的前n-1個元素,因此外層回圈的次數應為n-1,內層回圈則從當前外層回圈遍歷到的數的后一個元素開始遍歷,直到序列的最后一個元素,這樣做的目的是:每次首先假設未排序序列的首元素為最大(小)的元素,通過與后面元素的比對,在一次外層回圈結束后得到該未排序序列中的最大(小)值,
實際例子示例:
待排序列:11 37 20 18 8
第一次:8 37 20 18 11
第二次:8 11 20 18 37
第三次:8 11 18 20 37 排序結束
1.4 時間復雜度分析:
首先外層回圈要遍歷整個序列的n-1個元素,一次外層回圈分別對應了n-1,n-2,…,1次的內層回圈,因此,總共回圈的次數就是(n-1)+(n-2)+…+1=n*(n-1)/2次,n的次數為2,所以時間復雜度為O(n^2),
2.冒泡排序法
冒泡排序演算法跟選擇排序演算法的不同之處在于選擇排序演算法是在整個序列中找出最大(小)的元素,而冒泡排序演算法是比較相鄰的元素,把較大(小)的元素放在前面,該程序就好像氣泡冒出水面一樣,因此稱之為冒泡排序演算法,
2.1 作業原理:
對一個序列重復遍歷,每次比較兩個元素,如果他們的順序錯誤,則將他們的順序進行調換,那么在這樣的一次遍歷交換的程序之后,這個序列的最后一個元素就是該序列中最大的元素了(看不懂沒關系,后面會有實數栗子),當整個序列的元素沒有必要再進行順序調換時,則遍歷結束,
2.2 具體代碼實作:
int Bubble_Sort(int array[], int size)
{
int temp;
for (int i = 0; i < size - 1; i++)
{
for (int j = 0; j < size - 1; j++)
{
if (array[j] > array[j + 1])
{
temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
return 0;
}
2.3 程序分析:
對于一個包含n個元素的序列,假設要實作從小到大的排序,外層回圈的回圈次數是考慮該序列排序的最壞情況,也就是該序列從大到小的情況,那么序列起始位置的元素到達末尾需要經歷n-1次的交換,因此為了滿足該情況,外層回圈的次數應該達到n-1次,那么內層回圈又在搞什么名堂呢?內層回圈其實是在進行比對與交換的作業,那在一次外層回圈中到底要進行多少次的內層回圈呢?因為前面已經提到了,在一次外層回圈結束后,序列的最后一個元素就已經是最大的了,因此倒數第二位的元素沒有必要再和最后一位元素進行比對,這就是限制內層回圈次數的一個重要條件,
實際例子示例:
待排序列:11 37 20 8 18
i=0:
11 20 8 18 37
i=1:
11 8 18 20 37
i =2:
8 11 18 20 37
再來看一個最壞的情況:
待排序列:5 4 3 2 1
i=0:
4 3 2 1 5
i=1:
3 2 1 4 5
i=2:
2 1 3 4 5
i=3:
1 2 3 4 5
2.4時間復雜度分析:
對于包含n個元素的序列,外層回圈執行n-1次,每次外層回圈對應的內層回圈次數分別為:n-1,n-2,n-3…1次,因此一共需要回圈的次數為:(n-1)+(n-2)+…+1=n(n-1)/2,因此時間復雜度為O(n^2),
3.插入排序法
3.1作業原理:
構建了一個有序的序列,從未排序的序列中抽取元素向有序序列中插入,
3.2具體代碼實作:
int Insertion_Sort(int array[], int size)
{
int i, j, temp;
for (i = 1; i < size; i++)
{
for (j = i; j > 0; j--)
{
if (array[j] < array[j - 1])
{
temp = array[j];
array[j] = array[j - 1];
array[j - 1] = temp;
}
}
}
return 0;
}
3.3程序分析:
對于一個包含n個元素的序列,可以看作將這n個元素依次插入到一個已經排好序的序列中,每次插入元素時,對已經排好序的序列從后向前進行掃描,掃描到的每一個數都與要插入的數進行比對,最終將這個數插入到已經排序好的序列中,并不會影響該序列的有序性,其實這種排序方法和冒泡排序如出一轍,都是分別對比兩個相鄰數的大小,這個插入的程序,其實就是這個數在已經排序好的數列中向自己應該所處的位置“冒”,
這里再細致地分析一下內層回圈的執行機制,令j=i,讓a[j]與a[j-1]進行比對,如果沒有滿足后一個數大于前一個數的條件,那么內層回圈將不會執行if的陳述句,也就是說后續j會自減至j=0從而結束外層回圈,
實際例子演示:
待排序列:11 37 20 8 18
【11】37 20 8 18
【11 37】20 8 18
【11 20 37】8 18
【8 11 20 37】18
【8 11 18 20 37】
對于我們人類而言,我們在運用這個插入排序的時候,就是一個簡簡單單的插入的動作,因為我們可以直接 判斷出這個待插入的數應該處于哪個位置,但是機器他笨吶(小丑是我自己)~,他就需要一個一個數去比對,這個插入的程序對于機器來說其實還是一個數值位置轉換的程序,只不過最后呈現出來的效果是這個數插進去了,
3.4 時間復雜度分析:
外層回圈回圈了n-1次,內層回圈分別執行1,2,3…n-1次,所以一共執行了1+2+3+…+(n-1)=n*(n-1)/2次的回圈,因此時間復雜度為O(n^2),
可以發現選擇排序法,冒泡排序法以及插入排序法,雖然實作演算法的方式和原理不一樣,但是他們的時間復雜度是相同的,
4.希爾排序法
這個演算法他🐂🍺啊(雖然不是最🐂的一個)!但是他首次突破了O(n^2)的時間復雜度,讓排序變得更快咯,就像那句話說的“向前一小步…”,啊~ 不是,應該是“我的一小步,人類的一大步”,就是內味,其實了解了希爾排序演算法后,就相當于了解了冒泡和插入排序法了,因為插入排序包含了冒泡排序,而希爾排序又是插入排序的改進版,他們就是一環套一環的關系~
4.1 作業原理:
將整個待排序列進行分組,分組的方式是設定一個間隔,每經過一個間隔就取出對應的數放入組中,然后再對不同組的元素進行插入排序,在經過一次分組插入排序后,將間隔減半,再次分組,再次進行分組插入排序,以此類推,一直到最終分組時只分得一個組也就是間隔為1的情況,最后進行一次插入排序,最終排序結束,
4.2具體代碼實作:
int Shell_Sort(int array[], int size)
{
int i, j, gap, temp;
for (gap = size / 2; gap > 0; gap /= 2) //第一層回圈:確定分組間隔,并且縮減間隔
{
for (i = gap; i < size; i++) //第二層回圈
{
for (j = i - gap; j -gap>=0 && array[j-gap]>array[j]; j -= gap)
{
temp = array[j];
array[j] = array[j-gap];
array[j - gap] = temp;
}
}
}
return 0;
}
4.3 程序分析:
首先來看一下第一層回圈在搞什么東東,可以看到定義了gap(分組間隔)為待排序列長度的1/2,并且當gap>0時,每次第一層回圈都會讓gap變為原本的1/2,從而達到縮減間隔的目的,可以得知最終gap將會變為1,也就是把整個序列作為了一組,
再來看看第二層回圈:他的語法到底在表達什么意思呢?對于這段陳述句,個人認為應當結合上第三層回圈共同理解,實際上第二與第三層回圈進行的作業是,對分隔后的小組進行直接插入排序(第三種介紹的排序演算法),那么如何在一個整體序列中對分組序列進行插入排序呢?如果我用python的話,我一定會把這些分好組的元素抽出來放進不同的陣列里面,這樣整個程序中運用的邏輯思維難度就降低了不少,然而…但是…可是,現在我們在利用C語言來解決這個問題,所以就需要一定的思維邏輯來進行實作,邏輯如下(可能是我比較愚笨所以覺得很巧妙):
利用實體進行講解:
待排序列:
55 2 6 4 32 12 9 73 (共8個元素)
gap=8/2=4
第一次分組情況為:
一. 55 9 >>>> 9 55
二. 2 73 >>>> 2 73
三. 6 26 >>>> 6 26
四. 4 37 >>>> 4 37
排序后: 9 2 6 4 55 73 26 37
gap=4/2=2
第二次分組情況為:
一. 9 6 55 26 >>>> 6 9 26 55
二. 2 4 73 37 >>>> 2 4 37 73
排序后:6 2 9 4 32 12 55 73
gap=2/2=1
第三次分組情況為:
一.6 2 9 4 32 12 55 73 >>>> 2 4 6 9 12 32 55 73
那么以上分組插入排序的程序是如何通過代碼實作的呢?
我們再次回到第二與第三次回圈中來,并通過第二次分組來演示代碼執行程序,第二次排序前的序列為: 6 2 9 4 32 12 55 73,令i=gap=2,就是讓i指向第三個數9,此后第二次回圈將遍歷9(包括9)以后的所有元素,而第三層回圈做的作業就是讓i指向的數插入到前面的已經排序好的序列中去,j = i-gap;j-gap>=0;j-=gap表達的意思就是讓j去掃描排好序的序列中的各個元素,以確定i指向的元素應當插入到哪個位置(其實就是插入排序的程序),
實際上,這個分組插入的程序是交替性進行的,也就是說不是第一組排序完畢后,再進行第二,三…n組的排序,而是第一組排序>第二組排序>…>第n組排序,然后再重復進行第一組排序>第二組排序>…>第n組排序,這個邏輯就是理解第二三層回圈的關鍵,
4.4 時間復雜度分析:
實際上希爾排序演算法的時間復雜度與增量序列的定義有關系,當增量序列為{1,2,4,8…}(也是該程式的增量序列)時,最壞情況的時間復雜度可以達到O(n^ 2), Hibbard提出的增量序列{1,3,7…,2^ k-1}(質數增量),最壞情況下的時間復雜度為O(n^ 2/3),Sedge提出的幾種增量序列最好的一個{1,5,19,41,109…}在最壞情況下的時間復雜度為O(n^1.3),
好了,這篇先寫這么多,下一篇再介紹快速排序,歸并排序,堆排序等等的排序演算法,然后再補充一下時間復雜度的數學分析,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/277086.html
標籤:其他