面試官:說說你對vue的理解?
Vue.js(/vju?/,或簡稱為Vue)是一個用于創建用戶界面的開源JavaScript框架,也是一個創建單頁應用的Web應用框架,2016年一項針對JavaScript的調查表明,Vue有著89%的開發者滿意度,在GitHub上,該專案平均每天能識訓95顆星,為Github有史以來星標數第3多的專案同時也是一款流行的JavaScript前端框架,旨在更好地組織與簡化Web開發,Vue所關注的核心是MVC模式中的視圖層,同時,它也能方便地獲取資料更新,并通過組件內部特定的方法實作視圖與模型的互動PS: Vue作者尤雨溪是在為AngularJS作業之后開發出了這一框架,他聲稱自己的思路是提取Angular中為自己所喜歡的部分,構建出一款相當輕量的框架最早發布于2014年2月
ue核心特性
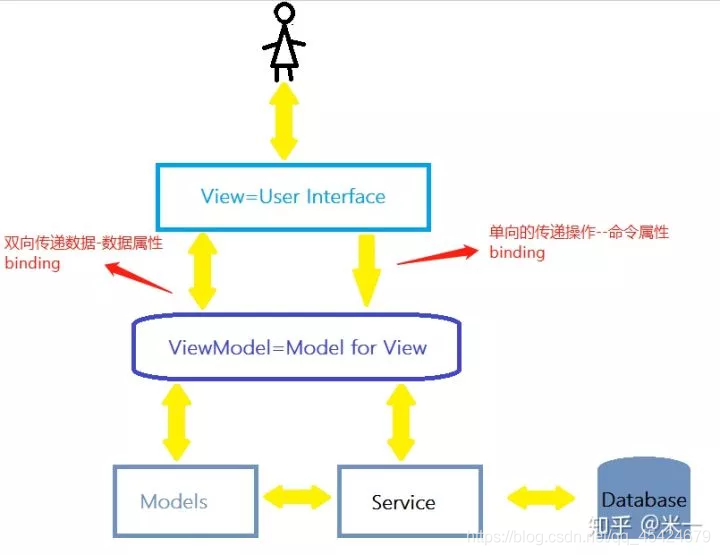
資料驅動(MVVM)
MVVM表示的是 Model-View-ViewModel
Model:模型層,負責處理業務邏輯以及和服務器端進行互動
View:視圖層:負責將資料模型轉化為UI展示出來,可以簡單的理解為HTML頁面
ViewModel:視圖模型層,用來連接Model和View,是Model和View之間的通信橋梁
在這里插入圖片描述
組件化
1.什么是組件化一句話來說就是把圖形、非圖形的各種邏輯均抽象為一個統一的概念(組件)來實作開發的模式,在Vue中每一個.vue檔案都可以視為一個組件2.組件化的優勢
降低整個系統的耦合度,在保持介面不變的情況下,我們可以替換不同的組件快速完成需求,例如輸入框,可以替換為日歷、時間、范圍等組件作具體的實作
除錯方便,由于整個系統是通過組件組合起來的,在出現問題的時候,可以用排除法直接移除組件,或者根據報錯的組件快速定位問題,之所以能夠快速定位,是因為每個組件之間低耦合,職責單一,所以邏輯會比分析整個系統要簡單
提高可維護性,由于每個組件的職責單一,并且組件在系統中是被復用的,所以對代碼進行優化可獲得系統的整體升級
面試官:說說你對雙向系結的理解?
什么是雙向系結
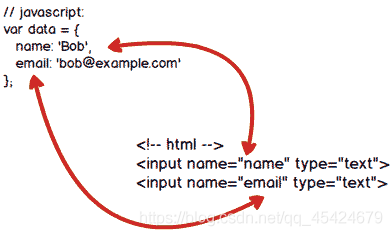
我們先從單向系結切入單向系結非常簡單,就是把Model系結到View,當我們用JavaScript代碼更新Model時,View就會自動更新雙向系結就很容易聯想到了,在單向系結的基礎上,用戶更新了View,Model的資料也自動被更新了,這種情況就是雙向系結舉個栗子
雙向系結的原理是什么
我們都知道 Vue 是資料雙向系結的框架,雙向系結由三個重要部分構成
資料層(Model):應用的資料及業務邏輯
視圖層(View):應用的展示效果,各類UI組件
業務邏輯層(ViewModel):框架封裝的核心,它負責將資料與視圖關聯起來
而上面的這個分層的架構方案,可以用一個專業術語進行稱呼:MVVM這里的控制層的核心功能便是 “資料雙向系結” ,自然,我們只需弄懂它是什么,便可以進一步了解資料系結的原理
理解ViewModel
它的主要職責就是:
資料變化后更新視圖
視圖變化后更新資料
當然,它還有兩個主要部分組成
監聽器(Observer):對所有資料的屬性進行監聽
決議器(Compiler):對每個元素節點的指令進行掃描跟決議,根據指令模板替換資料,以及系結相應的更新函式
實作雙向系結
我們還是以Vue為例,先來看看Vue中的雙向系結流程是什么的
new Vue()首先執行初始化,對data執行回應化處理,這個程序發生Observe中
同時對模板執行編譯,找到其中動態系結的資料,從data中獲取并初始化視圖,這個程序發生在Compile中
同時定義?個更新函式和Watcher,將來對應資料變化時Watcher會呼叫更新函式
由于data的某個key在?個視圖中可能出現多次,所以每個key都需要?個管家Dep來管理多個Watcher
將來data中資料?旦發生變化,會首先找到對應的Dep,通知所有Watcher執行更新函式
說說你對SPA(單頁應用)的理解?
什么是SPA
SPA(single-page application),翻譯過來就是單頁應用SPA是一種網路應用程式或網站的模型,它通過動態重寫當前頁面來與用戶互動,這種方法避免了頁面之間切換打斷用戶體驗在單頁應用中,所有必要的代碼(HTML、JavaScript和CSS)都通過單個頁面的加載而檢索,或者根據需要(通常是為回應用戶操作)動態裝載適當的資源并添加到頁面頁面在任何時間點都不會重新加載,也不會將控制轉移到其他頁面舉個例子來講就是一個杯子,早上裝的牛奶,中午裝的是開水,晚上裝的是茶,我們發現,變的始終是杯子里的內容,而杯子始終是那個杯子結構如下圖
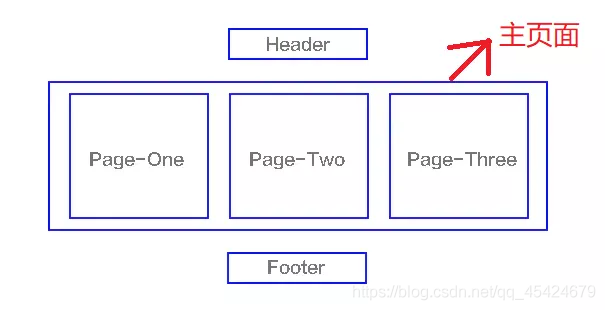
SPA和MPA的區別
單頁應用與多頁應用的區別
|
| 單頁面應用(SPA) | 多頁面應用(MPA) |
|---|---|
| 組成 | 一個主頁面和多個頁面片段 |
| 重繪方式 | 區域重繪 |
| url模式 | 哈希模式 |
| SEO搜索引擎優化 | 難實作,可使用SSR方式改善 |
| 資料傳遞 | 容易 |
| 頁面切換 | 速度快,用戶體驗良好 |
| 維護成本 | 相對容易 |
單頁應用優缺點
優點:
具有桌面應用的即時性、網站的可移植性和可訪問性
用戶體驗好、快,內容的改變不需要重新加載整個頁面
良好的前后端分離,分工更明確
缺點:
不利于搜索引擎的抓取
首次渲染速度相對較慢
實作一個SPA
原理
監聽地址欄中hash變化驅動界面變化
用pushsate記錄瀏覽器的歷史,驅動界面發送變化
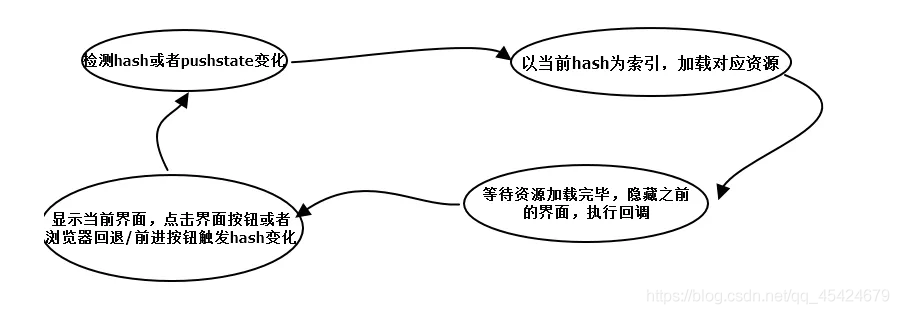
實作
hash 模式
核心通過監聽url中的hash來進行路由跳轉
// 定義 Router
class Router {
constructor () {
this.routes = {}; // 存放路由path及callback
this.currentUrl = ‘’;
// 監聽路由change呼叫相對應的路由回呼
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback){
this.routes[path] = callback;
}
push(path) {
this.routes[path] && this.routes[path]()
}
}
// 使用 router
window.miniRouter = new Router();
miniRouter.route(’/’, () => console.log(‘page1’))
miniRouter.route(’/page2’, () => console.log(‘page2’))
miniRouter.push(’/’) // page1
miniRouter.push(’/page2’) // page2
history模式
history 模式核心借用 HTML5 history api,api 提供了豐富的 router 相關屬性先了解一個幾個相關的api
history.pushState 瀏覽器歷史紀錄添加記錄
history.replaceState修改瀏覽器歷史紀錄中當前紀錄
history.popState 當 history 發生變化時觸發
// 定義 Router
class Router {
constructor () {
this.routes = {};
this.listerPopState()
}
init(path) {
history.replaceState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
route(path, callback){
this.routes[path] = callback;
}
push(path) {
history.pushState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
listerPopState () {
window.addEventListener('popstate' , e => {
const path = e.state && e.state.path;
this.routers[path] && this.routers[path]()
})
}
}
// 使用 Router
window.miniRouter = new Router();
miniRouter.route(’/’, ()=> console.log(‘page1’))
miniRouter.route(’/page2’, ()=> console.log(‘page2’))
// 跳轉
miniRouter.push(’/page2’) // page2
題外話:如何給SPA做SEO
下面給出基于Vue的SPA如何實作SEO的三種方式
SSR服務端渲染
將組件或頁面通過服務器生成html,再回傳給瀏覽器,如nuxt.js
靜態化
目前主流的靜態化主要有兩種:(1)一種是通程序式將動態頁面抓取并保存為靜態頁面,這樣的頁面的實際存在于服務器的硬碟中(2)另外一種是通過WEB服務器的 URL Rewrite的方式,它的原理是通過web服務器內部模塊按一定規則將外部的URL請求轉化為內部的檔案地址,一句話來說就是把外部請求的靜態地址轉化為實際的動態頁面地址,而靜態頁面實際是不存在的,這兩種方法都達到了實作URL靜態化的效果
使用Phantomjs針對爬蟲處理
原理是通過Nginx配置,判斷訪問來源是否為爬蟲,如果是則搜索引擎的爬蟲請求會轉發到一個node server,再通過PhantomJS來決議完整的HTML,回傳給爬蟲,下面是大致流程圖
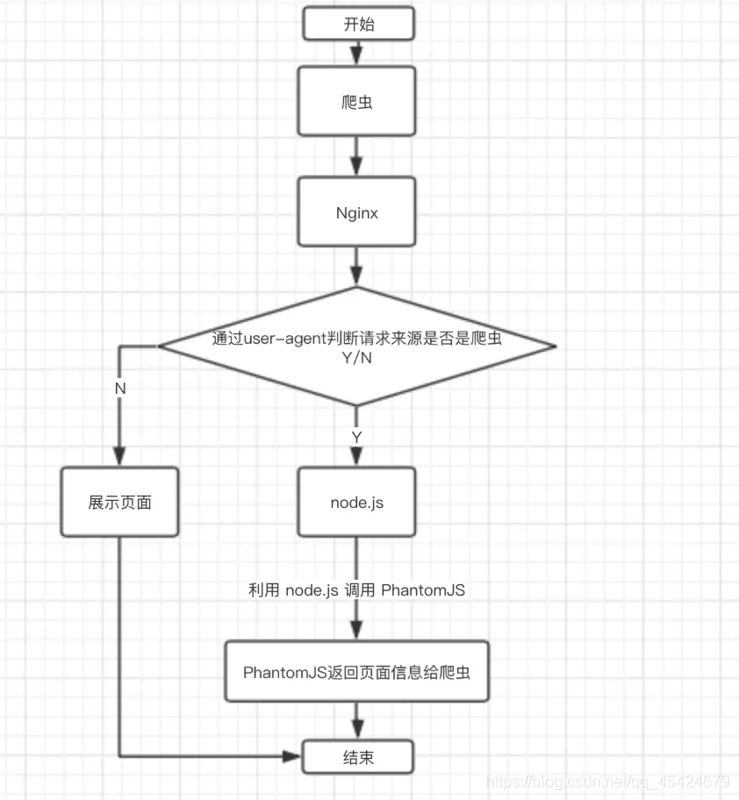
Vue實體掛載的程序中發生了什么?
在呼叫beforeCreate之前,資料初始化并未完成,像data、props這些屬性無法訪問到
到了created的時候,資料已經初始化完成,能夠訪問data、props這些屬性,但這時候并未完成dom的掛載,因此無法訪問到dom元素
掛載方法是呼叫vm.$mount方法
說說你對Vue生命周期的理解
生命周期 描述
beforeCreate 組件實體被創建之初
created 組件實體已經完全創建
beforeMount 組件掛載之前
mounted 組件掛載到實體上去之后
beforeUpdate 組件資料發生變化,更新之前
updated 資料資料更新之后
beforeDestroy 組件實體銷毀之前
destroyed 組件實體銷毀之后
activated keep-alive 快取的組件激活時
deactivated keep-alive 快取的組件停用時呼叫
errorCaptured 捕獲一個來自子孫組件的錯誤時被呼叫
具體分析
beforeCreate -> created
初始化vue實體,進行資料觀測
created
完成資料觀測,屬性與方法的運算,watch、event事件回呼的配置
可呼叫methods中的方法,訪問和修改data資料觸發回應式渲染dom,可通過computed和watch完成資料計算
此時vm.$el 并沒有被創建
created -> beforeMount
判斷是否存在el選項,若不存在則停止編譯,直到呼叫vm.$mount(el)才會繼續編譯
優先級:render > template > outerHTML
vm.el獲取到的是掛載DOM的
beforeMount
在此階段可獲取到vm.el
此階段vm.el雖已完成DOM初始化,但并未掛載在el選項上
beforeMount -> mounted
此階段vm.el完成掛載,vm.$el生成的DOM替換了el選項所對應的DOM
mounted
vm.el已完成DOM的掛載與渲染,此刻列印vm.$el,發現之前的掛載點及內容已被替換成新的DOM
beforeUpdate
更新的資料必須是被渲染在模板上的(el、template、render之一)
此時view層還未更新
若在beforeUpdate中再次修改資料,不會再次觸發更新方法
updated
完成view層的更新
若在updated中再次修改資料,會再次觸發更新方法(beforeUpdate、updated)
beforeDestroy
實體被銷毀前呼叫,此時實體屬性與方法仍可訪問
destroyed
完全銷毀一個實體,可清理它與其它實體的連接,解綁它的全部指令及事件監聽器
并不能清除DOM,僅僅銷毀實體
題外話:資料請求在created和mouted的區別
created是在組件實體一旦創建完成的時候立刻呼叫,這時候頁面dom節點并未生成mounted是在頁面dom節點渲染完畢之后就立刻執行的觸發時機上created是比mounted要更早的兩者相同點:都能拿到實體物件的屬性和方法討論這個問題本質就是觸發的時機,放在mounted請求有可能導致頁面閃動(頁面dom結構已經生成),但如果在頁面加載前完成則不會出現此情況建議:放在create生命周期當中
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/277830.html
標籤:其他
上一篇:精通Mybatis之快取體系
下一篇:flume事務和進階