1.概述
flume是高可用,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,
2.flume的作用
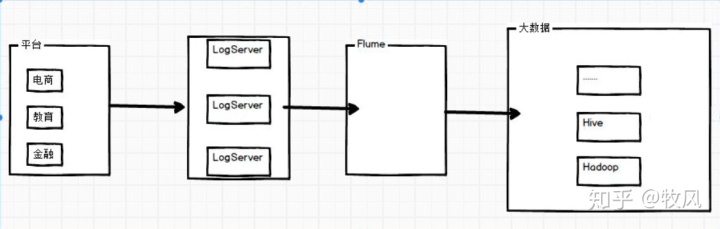
用戶行為日志通過前端平臺存盤到logservice中,通過flume的實時采集發過來的資訊,然后發送到大資料平臺上
3.flume架構
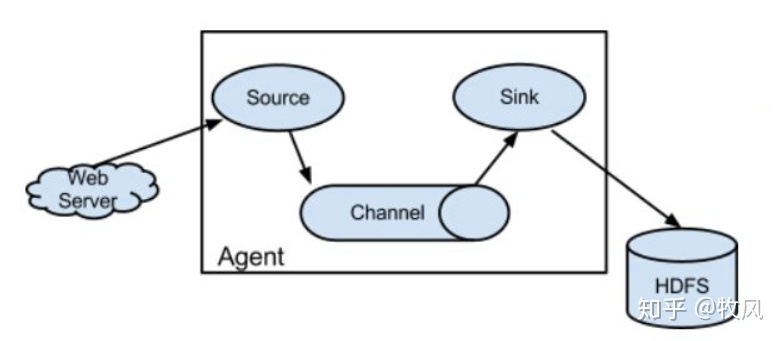
日志源-->source-->channel-->sink-->HDFS
agent:就是一個JVM的行程,里面包含source,channel,sink
source:采集或讀取日志的組件,不同的資料源使用不同的source
channel:緩沖區,讓source和sink可以在不同速率上運行
sink:負責日志的寫出的組件
event:在flume里面傳輸的是event傳輸單元,header和body組成,body 里面存放資料的位元組陣列,header里面默認空,需要手動添加
二、配置和使用
1.配置環境變數的作用
- 方便使用命令
- 方便別的框架使用
2.flume運行agent的命令
兩種寫法
- flume-ng agent --name agent 的名字 --conf 組態檔的目錄 --conf-file 組態檔(自己手動寫)
- flume-ng agent -c conf -f 組態檔 -n agent名字
flume-ng agent: 表示啟動agent--conf | -c : 表示指定flume的conf目錄
--conf-file | -f : 表示指定我們自己撰寫的flume的組態檔
--name | -n : 表示指定agent的名字
-Dflume.root.logger=INFO,console : 傳入引數列印到控制臺
3.通用寫法:
flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/datas/netcat-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console
4.agent 的組態檔
1.需要定義agent的名字,還需要定義source,channel,sink(名字,有幾個)
2.需要對source,channel,sink指明具體的型別和配置
3.需要指明source,channel,sink三者之間的一個關系
注意:一個sink只能對應一個channel,一個channel可以對應多個sink
#1. 監控埠資料:netcat-flume-logger
#source組件:netcat tcp source
#channel組件:memory channel
#sink組件: logger sink
?
# Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1
?
#Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = loacathost
a1.sources.r1.port = 6666
?
#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity=100
?
#Sink
a1.sinks.k1.type = logger
?
#Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
5.各種組件的介紹
source:
- netcat:監聽本機埠
- exec:監控一條linux的命令,監聽一個檔案的目錄,如果掛掉,重新從頭開始讀
- spooldir:監控目錄是否新增檔案,監控不到檔案的內容
- talldir 監聽一個目錄的檔案,記錄好位置,重新讀取的話從上次讀的地方開始續讀
- avro: 監聽埠,接收avrosink發送到的資料
- kafka:作為消費者消費kafka中的資料
sink :
- avro 把內容寫到哪個機器上面
- logger:把資料寫到logger上
- HDFSsink:寫到HDFS上
- Ffile_roll : 寫到本地目錄里面
- kafka:作為生產者向kafka發送資料
channel:
- Memory Channel:以記憶體作為緩沖區
- File Channel:以磁盤作為緩沖區
- Kafka channel :以kafka作為緩沖區
三、flume進階
1.flume事務
退避的概念:當服務器斷開后,以指數的時間間隔進行嘗試連接,到達一定時間間隔后則以此時間間隔來嘗試連接
保證了資料不丟失的關鍵
- put 事務流程:首先source先安照batch大小,將資料寫入導putlist中,當putlist放滿時則開啟一個put事物,將putlist中的資料放入channel,如果放入失敗,則清空putlist,同時告知source,這時source則會把指標重寫指向這個put前的資料開始重新讀取,這樣就保證的資料不丟失
- doput: 將批量資料先寫入臨時緩沖區putlist
- docommit:檢查channel記憶體佇列是否足夠合并
- dorollback:channel記憶體不足,滾回資料
- take事務:
- dotake:將資料取到臨時緩沖區takelist,并將資料發送到HDFS
- docommit:如果資料發送成功,則清空臨時緩沖區takelist
- dorolback:如果資料發送出現例外,則rollback將臨時緩沖區takelist中的資料歸還給channel記憶體佇列
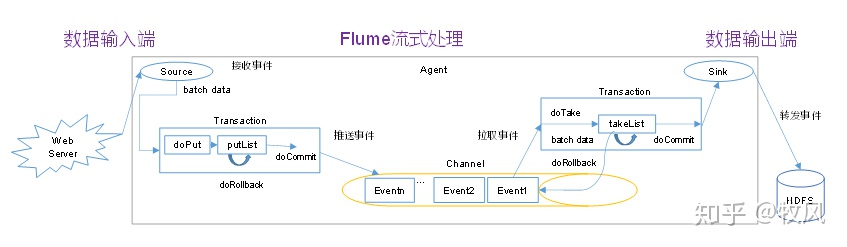
2.flume agent內部原理
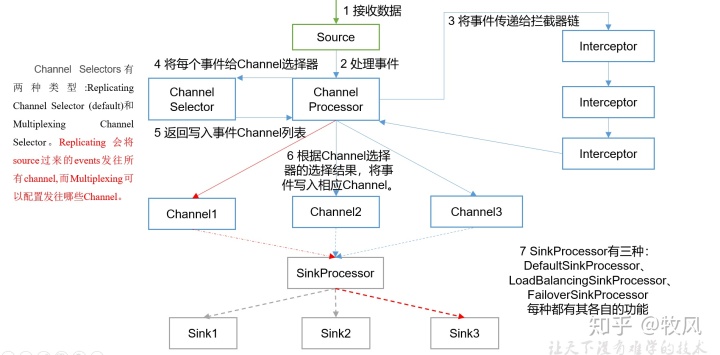
重要組件:
1)ChannelSelector
ChannelSelector的作用就是選出Event將要被發往哪個Channel,其共有兩種型別,分別是Replicating(復制)和Multiplexing(多路復用),
ReplicatingSelector會將同一個Event發往所有的Channel,Multiplexing會根據相應的原則,將不同的Event發往不同的Channel,
2)SinkProcessor
SinkProcessor共有三種型別,分別是DefaultSinkProcessor、LoadBalancingSinkProcessor和FailoverSinkProcessor
DefaultSinkProcessor對應的是單個的Sink,LoadBalancingSinkProcessor和FailoverSinkProcessor對應的是Sink Group,LoadBalancingSinkProcessor可以實作負載均衡的功能,FailoverSinkProcessor可以錯誤恢復的功能,
3 Flume拓撲結構
3.1 簡單串聯
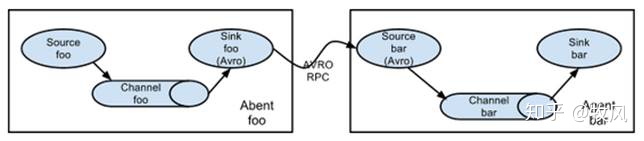
這種模式是將多個flume順序連接起來了,從最初的source開始到最終sink傳送的目的存盤系統,此模式不建議橋接過多的flume數量, flume數量過多不僅會影響傳輸速率,而且一旦傳輸程序中某個節點flume宕機,會影響整個傳輸系統,
3.2 復制和多路復用
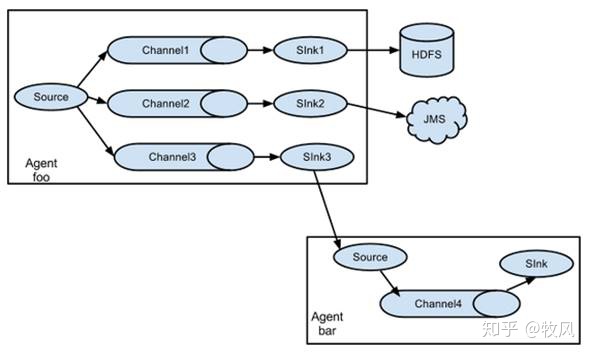
Flume支持將事件流向一個或者多個目的地,這種模式可以將相同資料復制到多個channel中,或者將不同資料分發到不同的channel中,sink可以選擇傳送到不同的目的地,
3.3 負載均衡和故障轉移
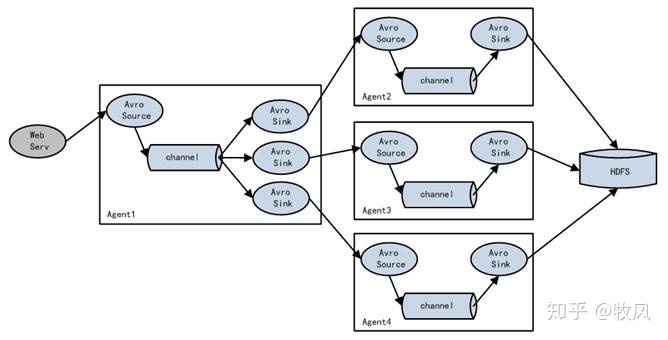
Flume支持使用將多個sink邏輯上分到一個sink組,sink組配合不同的SinkProcessor可以實作負載均衡和錯誤恢復的功能,
3.4 聚合
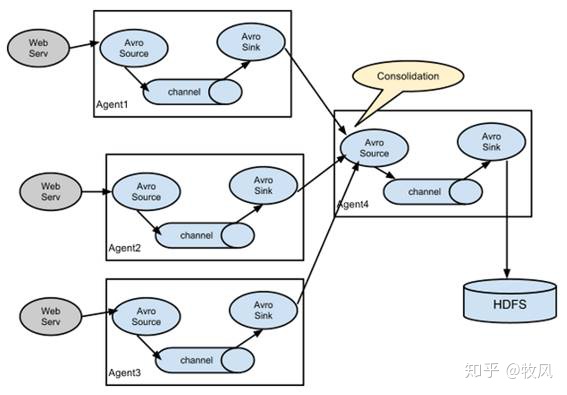
這種模式是我們最常見的,也非常實用,日常web應用通常分布在上百個服務器,大者甚至上千個、上萬個服務器,產生的日志,處理起來也非常麻煩,用flume的這種組合方式能很好的解決這一問題,每臺服務器部署一個flume采集日志,傳送到一個集中收集日志的flume,再由此flume上傳到hdfs、hive、hbase等,進行日志分析,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/277831.html
標籤:其他
上一篇:20面試官21-04-17
下一篇:React框架發展史