架構設計的目的之一是為了解決專案的復雜度,復雜度的來源,追求高性能,高可用,并且拓展,先從高性能來看,
1. 高性能
1.什么是高性能?
- 我們平時開發的時候曾經無數次有提到過追求高性能,那么到底什么是高性能,能抗很高的QPS和TPS,能有很快的回應時間等等,
- 而我們所做的架構,是基于原始計算機的硬體設施達到最大的支撐能力,通俗的講,就是將計算機充分利用,如CPU,記憶體等,別人設計的架構一臺計算幾能抗1WQPS,而我們設計的架構的軟體再計算機上跑能抗2W QPS (相同的業務需求,相同的計算機)這就是牛逼,
2. 為什么高性能會給我們的架構帶來復雜度呢?
- 舉個簡單的列子,為了高性能 我們從無力架構設計的層面看,我們是不是就得引入快取,非關系資料庫,流量有高發期我們是不是就得削峰填谷,那就得引入佇列的中間件,為了高性能單臺不能達到我們的需求,那我們就得搞集群,搞集群就得負載均衡,搞了集群,那么資料庫也得集群,資料庫得主從分離/分庫分表,redis也得集群,,,,,就這么一步一步的復雜下去,
3. 那我們本著什么原則才能解決隨著復雜度的上升不會使我們的架構設計成指數上升呢? 來看看大姥怎么說的,
- 簡單的系統更加容易做到高性能
- 系統的功能越簡單,影響性能的點就越少,就更加容易進行有針對性的優化,而系統很復雜的情況下,首先是比較難以找到關鍵性能點,因為需要考慮和驗證的點太多;其次是即使花費很大力氣找到了,修改起來也不容易,因為可能將 A 關鍵性能點提升了,但卻無意中將 B 點的性能降低了,整個系統的性能不但沒有提升,還有可能會下降,
- 有沒有get到,是不是想到微服務了,把服務拆開,那當單個系統是不是就變得簡單了(其他方面變復雜我們另說)
- 可以針對單個任務進行擴展
- 當各個邏輯任務分解到獨立的子系統后,整個系統的性能瓶頸更加容易發現,而且發現后只需要針對有瓶頸的子系統進行性能優化或者提升,不需要改動整個系統,風隙訓小很多,以微信的后臺架構為例,如果用戶數增長太快,注冊登錄子系統性能出現瓶頸的時候,只需要優化登錄注冊子系統的性能(可以是代碼優化,也可以簡單粗暴地加機器),訊息邏輯、LBS 邏輯等其他子系統完全不需要改動,但是不能劃分的太細,適可而止,
- 這直接就悟了,拆解單個系統,對單個系統進行優化
2. 高可用
2.1 什么是高可用
- 系統無中斷地執行其功能的能力,代表系統的可用性程度,是進行系統設計時的準則之一,
- 單臺機子可以做到無中斷執行嗎?貌似有點難,因為無論是單個硬體還是單個軟體,都不可能做到無中斷,硬體會出故障,軟體會有 bug;硬體會逐漸老化,軟體會越來越復雜和龐大……
- 再說了還有自然災害,地震給你把機房干踏了,那個想不通的同事刪庫跑路了等等,保證100%很難,或者說5個9等,這都還有可能
2.2 如何達到高可用?
-
我們可以先想一想,我們使用的服務器都是在哪部署的?是不是全世界各地等等,達到高可用的根本手段是什么?那就是“冗余”
-
詳細看看大佬的總結:
-
計算高可用
- 無論在哪臺機器上進行計算,同樣的演算法和輸入資料,產出的結果都是一樣的(這不是函式的特性嗎?)
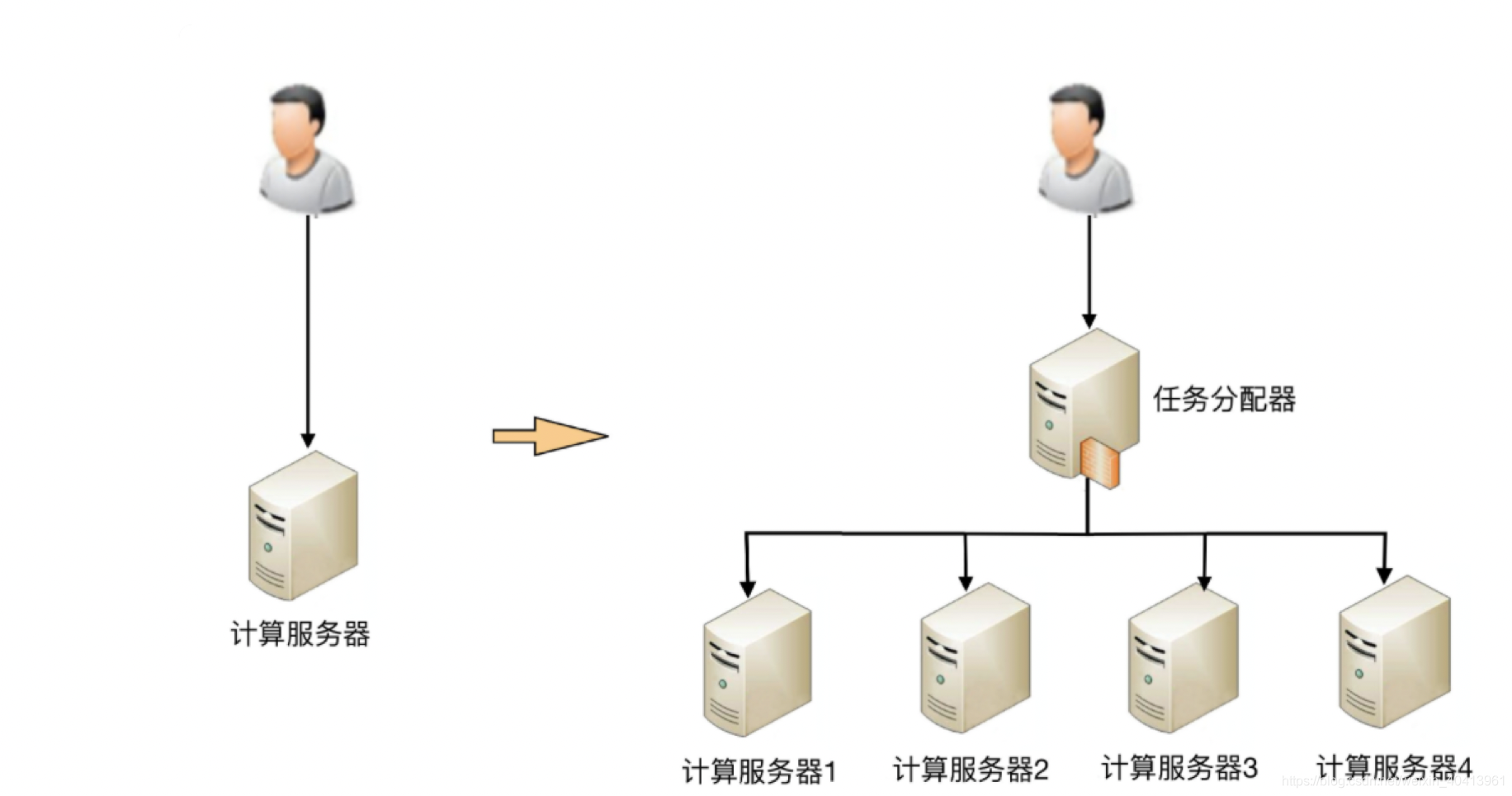
2.高可用是沒什么問題,但是我們怎么能知道那個可用那個不可用等等,這些也就用到了我們分布式中間件,如zookpeer,springCloud等會有一些心跳檢測機制,得知那臺機器可用不可用
- 無論在哪臺機器上進行計算,同樣的演算法和輸入資料,產出的結果都是一樣的(這不是函式的特性嗎?)
-
存盤高可用
- 對于需要存盤資料的系統來說,整個系統的高可用設計關鍵點和難點就在于“存盤高可用”,存盤與計算相比,有一個本質上的區別:將資料從一臺機器搬到到另一臺機器,需要經過線路進行傳輸,線路傳輸的速度是毫秒級別,同一機房內部能夠做到幾毫秒;分布在不同地方的機房,傳輸耗時需要幾十甚至上百毫秒,例如,從廣州機房到北京機房,穩定情況下 ping 延時大約是 50ms,不穩定情況下可能達到 1s 甚至更多,
- 存盤高可用的難點不在于如何備份資料,而在于如何減少或者規避資料不一致對業務造成的影響,
- 綜合分析,無論是正常情況下的傳輸延遲,還是例外情況下的傳輸中斷,都會導致系統的資料在某個時間點或者時間段是不一致的,而資料的不一致又會導致業務問題;但如果完全不做冗余,系統的整體高可用又無法保證,所以存盤高可用的難點不在于如何備份資料,而在于如何減少或者規避資料不一致對業務造成的影響,
- 分布式領域里面有一個著名的 CAP 定理,從理論上論證了存盤高可用的復雜度,也就是說,存盤高可用不可能同時滿足“一致性、可用性、磁區容錯性”,最多滿足其中兩個,這就要求我們在做架構設計時結合業務進行取舍,
2.3 高可用狀態決策
無論是計算高可用還是存盤高可用,其基礎都是“狀態決策”,即系統需要能夠判斷當前的狀態是正常還是例外,如果出現了例外就要采取行動來保證高可用,如果狀態決策本身都是有錯誤或者有偏差的,那么后續的任何行動和處理無論多么完美也都沒有意義和價值,但在具體實踐的程序中,恰好存在一個本質的矛盾:通過冗余來實作的高可用系統,狀態決策本質上就不可能做到完全正確,下面我基于幾種常見的決策方式進行詳細分析,
- 獨裁式
- 獨裁式決策指的是存在一個獨立的決策主體,我們姑且稱它為“決策者”,負責收集資訊然后進行決策;所有冗余的個體,我們姑且稱它為“上報者”,都將狀態資訊發送給決策者,
- 獨裁式的決策方式不會出現決策混亂的問題,因為只有一個決策者,但問題也正是在于只有一個決策者,當決策者本身故障時,整個系統就無法實作準確的狀態決策,如果決策者本身又做一套狀態決策,那就陷入一個遞回的死回圈了,
- 協商式
- 協商式決策指的是兩個獨立的個體通過交流資訊,然后根據規則進行決策,最常用的協商式決策就是主備決策,
- 這個架構的基本協商規則可以設計成:
- 2 臺服務器啟動時都是備機,
- 2 臺服務器建立連接,
- 2 臺服務器交換狀態資訊,
- 某 1 臺服務器做出決策,成為主機;另一臺服務器繼續保持備機身份,協商式決策的架構不復雜,規則也不復雜,其難點在于,如果兩者的資訊交換出現問題(比如主備連接中斷),此時狀態決策應該怎么做,
- 如果備機在連接中斷的情況下認為主機故障,那么備機需要升級為主機,但實際上此時主機并沒有故障,那么系統就出現了兩個主機,這與設計初衷(1 主 1 備)是不符合的,就說這么多吧,不再狀態都懶得復制了眼睛疼
- 民主式
- 民主式決策指的是多個獨立的個體通過投票的方式來進行狀態決策,例如,ZooKeeper 集群在選舉 leader 時就是采用這種方式,
- 民主式決策和協商式決策比較類似,其基礎都是獨立的個體之間交換資訊,每個個體做出自己的決策,然后按照“多數取勝”的規則來確定最終的狀態,不同點在于民主式決策比協商式決策要復雜得多,ZooKeeper 的選舉演算法 ZAB,絕大部分人都看得云里霧里,更不用說用代碼來實作這套演算法了,
- 除了演算法復雜,民主式決策還有一個固有的缺陷:腦裂,這個詞來源于醫學,指人體左右大腦半球的連接被切斷后,左右腦因為無法交換資訊,導致各自做出決策,然后身體受到兩個大腦分別控制,會做出各種奇怪的動作,例如:當一個腦裂患者更衣時,他有時會一只手將褲子拉起,另一只手卻將褲子往下脫,腦裂的根本原因是,原來統一的集群因為連接中斷,造成了兩個獨立分隔的子集群,每個子集群單獨進行選舉,于是選出了 2 個主機,相當于人體有兩個大腦了,
- 為了解決腦裂問題,民主式決策的系統一般都采用“投票節點數必須超過系統總節點數一半”規則來處理,
就搞到這,眼睛疼,大家加油,
對我寫的這篇文章感興趣的可以看:https://time.geekbang.org/column/article/6895(阿里技術專家寫的專欄)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278063.html
標籤:其他