Redis主從復制
- 主從復制簡介
- 主從復制的概念
- 主從復制的作用
- 主從復制作業流程
- 階段一:建立連接階段
- 主從連接(slave連接master)
- 第一種方式
- 第二種方式
- 第三種方式
- 授權訪問
- 階段二:資料同步階段作業流程
- 資料同步階段master說明
- 資料同步階段slave說明
- 階段三:命令傳播階段
- 命令傳播階段的部分復制
- 服務器的運行 id
- 復制緩沖區
- 復制緩沖區內部作業原理
- 復制緩沖區
- 主從服務器復制偏移量(offset)
- 資料同步+命令傳播階段作業流程
- 心跳機制
- 心跳階段注意事項
- 主從復制常見問題
- 引發頻繁的全量復制1
- 引發頻繁的全量復制2
- 頻繁的網路中斷1
- 頻繁的網路中斷2
- 資料不一致
主從復制簡介
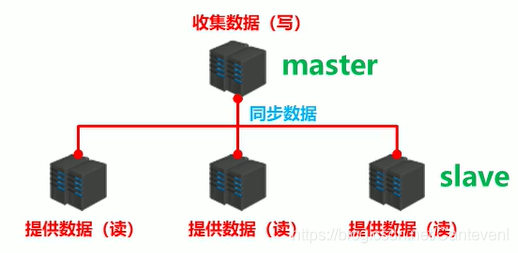
主從復制是為了達成高可用
- 為了避免單點Redis服務器故障,準備多臺服務器,互相連通,將資料復制多個副本保存在不同的服
務器上,連接在一起,并保證資料是同步的, - 即使有其中一臺服務器宕機,其他服務器依然可以繼續提供服務,實作Redis的高可用,同時實作資料冗余備份,
-
提供資料方:master
- 主服務器,主節點,主庫
主客戶端
- 主服務器,主節點,主庫
-
接收資料方:slave
- 從服務器,從節點,從庫
從客戶端
- 從服務器,從節點,從庫
-
需要解決的問題
- 資料同步
-
核心作業
- master的資料復制到slave中
主從復制
-
主從復制即將master中的資料即時、有效的復制到slave中
-
一個master可以擁有多個slave,一個slave只對應一個master
-
職責
-
master:
- 寫資料
- 執行寫操作時,將出現變化的資料自動同步到slave
- 讀資料(可忽略)
-
slave:
- 讀資料
- 寫資料(禁止)
-
主從復制的概念
主從復制,是指將一臺Redis服務器的資料,復制到其他的Redis服務器,前者稱為主節點(master/leader),后者稱為從節點(slave/follower) ; 資料的復制是單向的,只能由主節點到從節點,Master以寫為主,Slave以讀為主,
默認情況下,每臺Redis服務器都是主節點 ;
且一個主節點可以有多個從節點(或沒有從節點),但一個從節點只能有一個主節點,
主從復制的作用
-
讀寫分離:主節點寫,從節點讀,提高服務器的讀寫負載能力
-
資料冗余︰主從復制實作了資料的熱備份,是持久化之外的一種資料冗余方式,
-
故障恢復︰當主節點出現問題時,可以由從節點提供服務,實作快速的故障恢復 ; 實際上是一種服務的冗余,
-
負載均衡︰在主從復制的基礎上,配合讀寫分離,可以由主節點提供寫服務,由從節點提供讀服務(即寫Redis資料時應用連接主節點,讀Redis資料時應用連接從節點),分擔服務器負載 ; 尤其是在寫少讀多的場景下,通過多個從節點分擔讀負載,可以大大提高Redis服務器的并發量,
-
高可用(集群)基石︰除了上述作用以外,主從復制還是哨兵和集群能夠實施的基礎,因此說主從復制是Redis高可用的基礎,
主從復制作業流程
總述
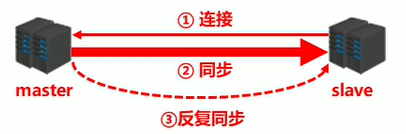
- 主從復制程序大體可以分為3個階段
- 建立連接階段(即準備階段)
- 資料同步階段
- 命令傳播階段
階段一:建立連接階段
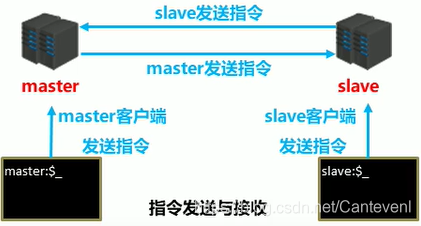
- 建立slave到master的連接,使master能夠識別slave,并保存slave埠號
- 設定master的地址和埠,保存master資訊
- 建立socket連接
- 發送ping命令(定時器任務)
- 身份驗證
- 發送slave埠資訊
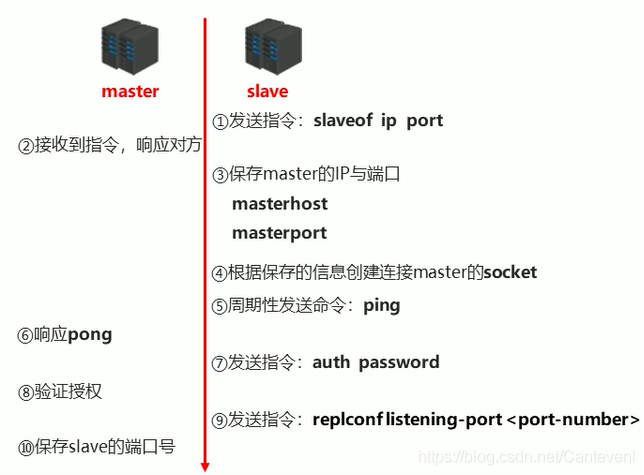
slave:保存master的地址和埠
master:保存slave的埠
總體:之間創建了socket連接
主從連接(slave連接master)
-
方式一:客戶端發送命令
slaveof <masterip> <masterport> -
方式二:啟動服務器引數
redis-server -slaveof <masterip> <masterport> -
方式三:服務器配置
vim redis.conf slaveof <masterip> <masterport>
第一種方式
打開redis服務端
redis-server redis_config/redis-6379.conf # 主機
redis-server redis_config/redis-6380.conf # 從機
進入從機
[root@maomao bin]# redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
查看主機日志資訊
Synchronization with replica 127.0.0.1:6380 succeeded
查看從機日志資訊
MASTER <-> REPLICA sync: receiving 361 bytes from master to disk
2125:S 18 Apr 2021 09:27:01.525 * MASTER <-> REPLICA sync: Flushing old data
2125:S 18 Apr 2021 09:27:01.525 * MASTER <-> REPLICA sync: Loading DB in memory
說明主從已經配置完畢
測驗
在主節點創建一個key
127.0.0.1:6379> set master maomao
OK
在從節點查看
127.0.0.1:6380> get master
"maomao"
還可以通過 info replication 命令查看
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
第二種方式
在命令列直接連接
[root@maomao bin]# redis-server redis_config/redis-6380.conf --slaveof 127.0.0.1 6379
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
第三種方式
[root@maomao redis_config]# vim redis-6380.conf
添加
slaveof 127.0.0.1 6379
啟動redis
[root@maomao bin]# redis-server redis_config/redis-6380.conf
[root@maomao bin]# redis-cli -p 6380
127.0.0.1:6380> get slave
"xiaotian"
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
-
主從斷開連接
客戶端發送命令
slaveof no one -
slave斷開連接后,不會洗掉已有資料,只是不再接受master發送的資料
在從機上
127.0.0.1:6380> slaveof no one
OK
127.0.0.1:6379> set slave maomao
OK
127.0.0.1:6380> get slave
"xiaotian"
授權訪問
-
master客戶端發送命令設定密碼
requirepass <password> -
master組態檔設定密碼
config set requirepass <password> config get requirepass -
slave客戶端發送命令設定密碼
auth <password> -
slave組態檔設定密碼
masterauth <password> -
slave啟動服務器設定密碼
redis-server –a <password>
階段二:資料同步階段作業流程
- 在slave初次連接master后,復制master中的所有資料到slave
- 將slave的資料庫狀態更新成master當前的資料庫狀態
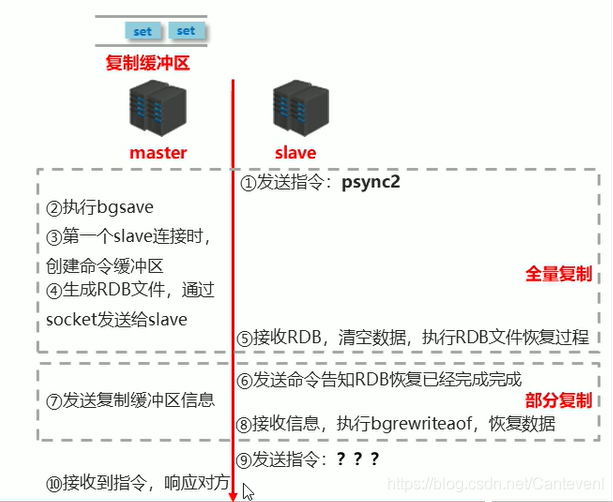
部分復制就是增量復制
增量復制需要在全量復制成功之后才能執行
- 請求同步資料
- 創建RDB同步資料
- 恢復RDB同步資料
- 請求部分同步資料
- 恢復部分同步資料
至此,資料同步作業完成!
狀態:
- slave:
具有master端全部資料,包含RDB程序接收的資料 - master:
保存slave當前資料同步的位置 - 總體:
之間完成了資料克隆
資料同步階段master說明
- 如果master資料量巨大,資料同步階段應避開流量高峰期,避免造成master阻塞,影響業務正常執行
- 復制緩沖區大小設定不合理,會導致資料溢位,如進行全量復制周期太長,進行部分復制時發現資料已
經存在丟失的情況,必須進行第二次全量復制,致使slave陷入死回圈狀態,
修改復制緩沖區大小
repl-backlog-size 1mb # 默認1mb
- master單機記憶體占用主機記憶體的比例不應過大,建議使用50%-70%的記憶體,留下30%-50%的記憶體用于執行bgsave命令和創建復制緩沖區
資料同步階段slave說明
-
為避免slave進行全量復制、部分復制時服務器回應阻塞或資料不同步,建議關閉此期間的對外服務
slave-serve-stale-data yes|no -
資料同步階段,master發送給slave資訊可以理解master是slave的一個客戶端,主動向slave發送命令
-
多個slave同時對master請求資料同步,master發送的RDB檔案增多,會對帶寬造成巨大沖擊,如果master帶寬不足,因此資料同步需要根據業務需求,適量錯峰
-
slave過多時,建議調整拓撲結構,由一主多從結構變為樹狀結構,中間的節點既是master,也是slave,注意使用樹狀結構時,由于層級深度,導致深度越高的slave與最頂層master間資料同步延遲較大,資料一致性變差,應謹慎選擇
階段三:命令傳播階段
-
當master資料庫狀態被修改后,導致主從服務器資料庫狀態不一致,此時需要讓主從資料同步到一致的狀態,同步的動作稱為命令傳播
-
master將接收到的資料變更命令發送給slave,slave接收命令后執行命令
-
主從復制程序大體可以分為3個階段
- 建立連接階段(即準備階段)
- 資料同步階段
- 命令傳播階段
命令傳播階段的部分復制
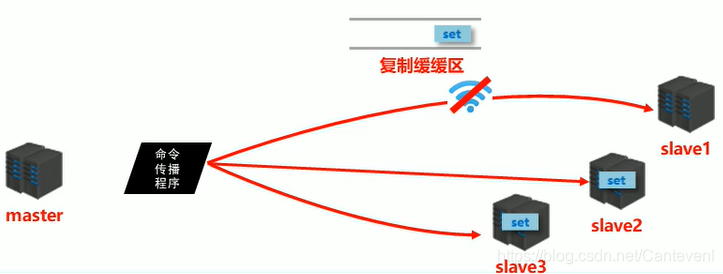
- 命令傳播階段出現了斷網現象
- 網路閃斷閃連 …忽略
- 短時間網路中斷 …部分復制
- 長時間網路中斷 …全量復制
- 部分復制的三個核心要素
- 服務器的運行 id(run id)
- 主服務器的復制積壓緩沖區
- 主從服務器的復制偏移量
服務器的運行 id
- 概念:服務器運行ID是每一臺服務器每次運行的身份識別碼,一臺服務器多次運行可以生成多個運行id
- 組成:運行id由40位字符組成,是一個隨機的十六進制字符
- 例如:0eab876073ab904a4b357000dc8f231f553c20a7
- 作用:運行id被用于在服務器間進行傳輸,識別身份
- 如果想兩次操作均對同一臺服務器進行,必須每次操作攜帶對應的運行id,用于對方識別
- 實作方式:運行id在每臺服務器啟動時自動生成的,master在首次連接slave時,會將自己的運行ID發送給slave,slave保存此ID,通過
info Server命令,可以查看節點的runid
復制緩沖區
- 概念:復制緩沖區,又名復制積壓緩沖區,是一個==先進先出(FIFO)==的佇列,用于存盤服務器執行過的命令,每次傳播命令,master都會將傳播的命令記錄下來,并存盤在復制緩沖區
復制緩沖區內部作業原理
-
組成
- 偏移量
- 位元組值
-
作業原理
- 通過offset區分不同的slave當前資料傳播的差異
- master記錄已發送的資訊對應的offset
- slave記錄已接收的資訊對應的offset
set name maomao
以這種格式
$3 \r\n
set \r\n
$4 \r\n
name \r\n
$6 \r\n
maomao \r\n
到復制緩沖區

復制緩沖區
- 概念:復制緩沖區,又名復制積壓緩沖區,是一個==先進先出(FIFO)==的佇列,用于存盤服務器執行過的命令,每次傳播命令,master都會將傳播的命令記錄下來,并存盤在復制緩沖區
- 復制緩沖區默認資料存盤空間大小是1M,由于存盤空間大小是固定的,當入隊元素的數量大于佇列長度時,最先入隊的元素會被彈出,而新元素會被放入佇列
- 由來:每臺服務器啟動時,如果開啟有AOF或被連接成為master節點,即創建復制緩沖區
- 作用:用于保存master收到的所有指令(僅影響資料變更的指令,例如set,select)
- 資料來源:當master接收到主客戶端的指令時,除了將指令執行,會將該指令存盤到緩沖區中
主從服務器復制偏移量(offset)
- 概念:一個數字,描述復制緩沖區中的指令位元組位置
- 分類:
- master復制偏移量:記錄發送給所有slave的指令位元組對應的位置(多個)
- slave復制偏移量:記錄slave接收master發送過來的指令位元組對應的位置(一個)
- 資料來源:
- master端:發送一次記錄一次
slave端:接收一次記錄一次
- master端:發送一次記錄一次
- 作用:同步資訊,比對master與slave的差異,當slave斷線后,恢復資料使用
資料同步+命令傳播階段作業流程
主從連接之后
- master生成復制緩沖區
- slave發送指令:psync2 ? -1 (意思需要全部資訊)
- master接收到指令,執行bgsave生成RDB檔案,記錄當前的復制偏移量
offset但是因為第一次slave發送的是空白, - 于是master將runid 和offset發給slave,發送 +FULLRESYNC
runidoffset,(全量復制),通過socket發送RDB檔案給slave - slave收到 +FULLRESYNC(全量復制),保存master的
runid和offset,清空當前全部資料,通過socket接收RDB檔案,恢復RDB資料 - 在整個程序中有一些指令要進入復制緩沖區,master接收這些客戶端指令,offset發生了變化
- slave 發送命令:psync2 runid offset
- master 接收命令,判斷runid是否匹配,判定offset是否在復制緩沖區中
- 如果runid或offset有一個不滿足,執行全量復制(回圈之前的全量復制)
- 如果runid或offset校驗通過,offset與
offset相同,則忽略 - 如果如果runid或offset校驗通過,offset與
offset不相同,
就發送 +CONTINUEoffset,
通過socket發送復制緩沖區中offset到offset的資料 - slave 收到 +CONTINE
保存master的offset
接收到資訊后,執行bgrewriteaof,恢復資料

心跳機制
-
進入命令傳播階段候,master與slave間需要進行資訊交換,使用心跳機制進行維護,實作雙方連接保持在線
-
master心跳:
- 指令:PING
- 周期:由repl-ping-slave-period決定,默認10秒
- 作用:判斷slave是否在線
- 查詢:INFO replication 獲取slave最后一次連接時間間隔,lag項維持在0或1視為正常
-
slave心跳任務
- 指令:REPLCONF ACK {offset}
- 周期:1秒
- 作用1:匯報slave自己的復制偏移量,獲取最新的資料變更指令
- 作用2:判斷master是否在線
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=927,lag=1
心跳階段注意事項
-
當slave多數掉線,或延遲過高時,master為保障資料穩定性,將拒絕所有資訊同步操作
min-slaves-to-write 2 min-slaves-max-lag 8- slave數量少于2個,或者所有slave的延遲都大于等于10秒時,強制關閉master寫功能,停止資料同步
-
slave數量由slave發送REPLCONF ACK命令做確認
-
slave延遲由slave發送REPLCONF ACK命令做確認
主從復制常見問題
引發頻繁的全量復制1
伴隨著系統的運行,master的資料量會越來越大,一旦master重啟,runid將發生變化,會導致全部slave的全量復制操作
- 內部優化調整方案:
- master內部創建master_replid變數,使用runid相同的策略生成,長度41位,并發送給所有slave
- 在master關閉時執行命令 shutdown save,進行RDB持久化,將runid與offset保存到RDB檔案中
- repl-id repl-offset
- 通過redis-check-rdb命令可以查看該資訊
- master重啟后加載RDB檔案,恢復資料
重啟后,將RDB檔案中保存的repl-id與repl-offset加載到記憶體中- master_repl_id = repl master_repl_offset = repl-offset
- 通過info命令可以查看該資訊
- 作用:
本機保存上次runid,重啟后恢復該值,使所有slave認為還是之前的master
[root@maomao redis_config]# cd /usr/local/redis/data/
[root@maomao data]# ls
6379.log 6380.log appendonly-6379.aof dump-6379.rdb dump.rdb
[root@maomao data]# redis-check-rdb dump-6379.rdb
[offset 0] Checking RDB file dump-6379.rdb
[offset 26] AUX FIELD redis-ver = '6.2.1'
[offset 40] AUX FIELD redis-bits = '64'
[offset 52] AUX FIELD ctime = '1618763025'
[offset 67] AUX FIELD used-mem = '1942304'
[offset 85] AUX FIELD repl-stream-db = '0'
[offset 135] AUX FIELD repl-id = '2d82ff022e405afb883753f4d0c52f8ceb36d740' # runid
[offset 151] AUX FIELD repl-offset = '885' #offset
[offset 167] AUX FIELD aof-preamble = '0'
[offset 169] Selecting DB ID 0
[offset 391] Checksum OK
[offset 391] \o/ RDB looks OK! \o/
[info] 5 keys read
[info] 0 expires
[info] 0 already expired
引發頻繁的全量復制2
-
問題現象
- 網路環境不佳,出現網路中斷,slave不提供服務
-
問題原因
- 復制緩沖區過小,斷網后slave的offset越界,觸發全量復制
-
最終結果
- slave反復進行全量復制
-
解決方案
- 修改復制緩沖區大小
repl-backlog-size
- 修改復制緩沖區大小
-
建議設定如下:
- 測算從master到slave的重連平均時長second
- 獲取master平均每秒產生寫命令資料總量write_size_per_second
- 最優復制緩沖區空間 = 2 * second * write_size_per_second
頻繁的網路中斷1
- 問題現象
- master的CPU占用過高 或 slave頻繁斷開連接
- 問題原因
- slave每1秒發送REPLCONF ACK命令到master
- 當slave接到了慢查詢時(keys * ,hgetall等),會大量占用CPU性能
- master每1秒呼叫復制定時函式replicationCron(),比對slave發現長時間沒有進行回應
- 最終結果
- master各種資源(輸出緩沖區、帶寬、連接等)被嚴重占用
- 解決方案
- 通過設定合理的超時時間,確認是否釋放slave
repl-timeout
該引數定義了超時時間的閾值(默認60秒),超過該值,釋放slave
- 通過設定合理的超時時間,確認是否釋放slave
頻繁的網路中斷2
- 問題現象
- slave與master連接斷開
- 問題原因
- master發送ping指令頻度較低
- master設定超時時間較短
- ping指令在網路中存在丟包
- 解決方案
- 提高ping指令發送的頻度
repl-ping-slave-period
超時時間repl-time的時間至少是ping指令頻度的5到10倍,否則slave很容易判定超時
- 提高ping指令發送的頻度
資料不一致
- 問題現象
- 多個slave獲取相同資料不同步
- 問題原因
- 網路資訊不同步,資料發送有延遲
- 解決方案
- 優化主從間的網路環境,通常放置在同一個機房部署,如使用阿里云等云服務器時要注意此現象
- 監控主從節點延遲(通過offset)判斷,如果slave延遲過大,暫時屏蔽程式對該slave的資料訪問
slave-serve-stale-data yes|no
開啟后僅回應info、slaveof等少數命令(慎用,除非對資料一致性要求很高)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278064.html
標籤:其他
上一篇:從零開始學架構-day03
下一篇:HugeCTR原始碼閱讀