HugeCTR原始碼閱讀
- HugeCTR簡介
- 整體架構
- 代碼閱讀
- 參考文獻
HugeCTR簡介
基于引數服務器架構的大規模稀疏訓練,可以說好幾年沒有新的變化和進步了,直到百度的aibox論文出現,以及后來nvidia開發的hugectr開源出來,總算是看到引數服務器架構又朝前走了一步,可以預見的是,這樣的異構訓練架構,相比之前的純CPU的方式,一定會隨著更多的高性能硬體、新的訓練優化的出現,有更進一步的改進空間,希望大家看到后有什么問題可以留言討論,一起進步,
相關的代碼庫鏈接:https://github.com/NVIDIA/HugeCTR/
hugectr是nvidia開發的GPU分布式訓練框架,它主要針對的是推薦ctr場景,支持大規模稀疏引數的分布式訓練與評估,
hugectr是一個基于引數服務器架構的訓練框架,它的主要亮點在于,它有基于GPU顯存的引數服務器(通俗一點說就是GPU顯存里有個hashmap用來存引數),這樣在做GPU訓練的時候,引數可以直接從GPU拷貝或者利用GPU通信,大大加速了引數通信(pull和push),因為引數通信不再經過CPU了,
當然這也拋出了幾個問題,不妨先思考一下:
(1)我們知道hashmap通常在大小接近一定閾值的時候,會做rehash的操作,而對引數服務器來說,隨著不斷訓練,引數服務器存的引數也可能不斷增多,尤其是訓練剛開始的階段,hashmap大小增長較快,如果頻繁rehash或者創建新的key,那么就會存在頻繁的GPU顯存申請釋放和拷貝,會很影響性能,
(2)GPU多了一步資料從CPU拷貝到GPU的程序,如果不做什么改進,計算的加速是否一定相比額外的資料拷貝要快呢?
(3)大規模稀疏引數,我們key的規模在十億,value(即embedding向量)假如是32維float向量,假如我們使用的是adam優化器,那么算上優化器狀態就是32 * 3 = 96維,總的引數規模大于300G,全放在顯存里放得下嗎?
這些問題在后面看的程序中會逐步解答,接下來讓我們先看一下整體架構,
整體架構
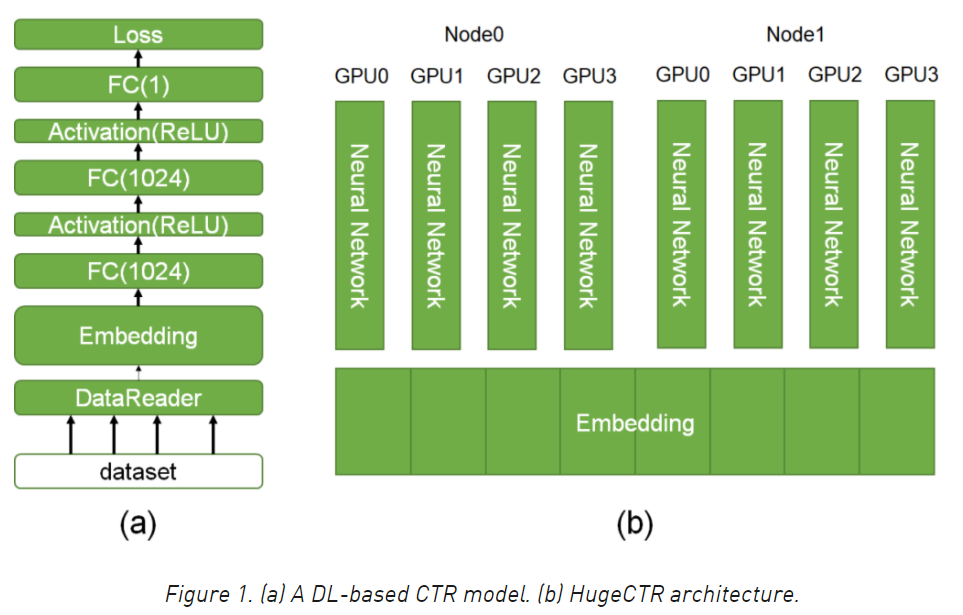
訓練流程:首先reader從dataset中讀取batch_size(比如32)的原始資料,決議原始資料,得到輸入的sparse key,dense向量,label等,并根據sparse key從引數服務器(下文簡稱ps,即parameter server)中拉取(pull)對應的embedding向量,然后輸入到深度學習神經網路中做前向-反向計算,并把反向計算得到的引數梯度推送(push)到ps,由ps根據梯度更新引數,
訓練的程序可以認為是資料并行+模型并行,資料并行主要體現在每個GPU卡的同時讀取不同的資料做訓練,而模型訓練主要體現在sparse引數的存盤是存盤在多個節點(node)上,每個節點分配一部分引數,
我們知道,ctr場景中,sparse引數的規模通常很大,從千萬到萬億級別的大小,dense引數(網路中的權重)通常很小,占用記憶體大小也就幾MB到幾十MB,因此對sparse引數的存取需要好好設計,hugectr中對sparse的存盤方式有兩種:local和distribute,
讓我們先看看local模式:一個slot的引數,只會在一個gpu卡上,這樣查完embedding之后,因為已經拿到了這個slot的所有embedding,可以做完pooling之后再做GPU多卡通信,可以降低通信量,(這里slot的意思是特征種類,也可以稱作field)
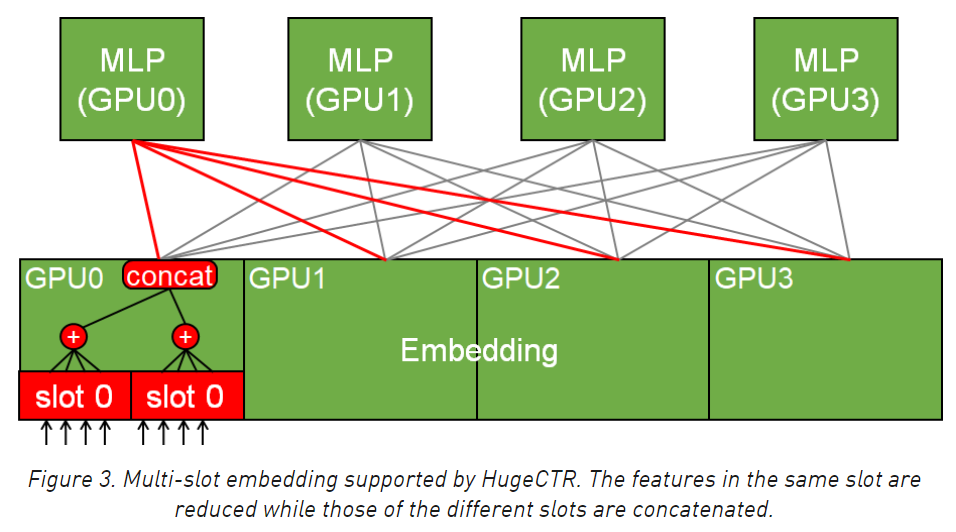
舉個例子,我們是單機訓練有4張GPU卡,有8個slot:slot0到slot7,如果是local模式,那么就是GPU0存slot0和slot1,GPU1存slot2和slot3,GPU2存slot4和slot5,GPU3存slot6和slot7,
對于distribute模式,每個GPU上上都會存所有slot的一部分引數,至于如何將一個引數分配到哪個GPU上,可以通過哈希的方法,
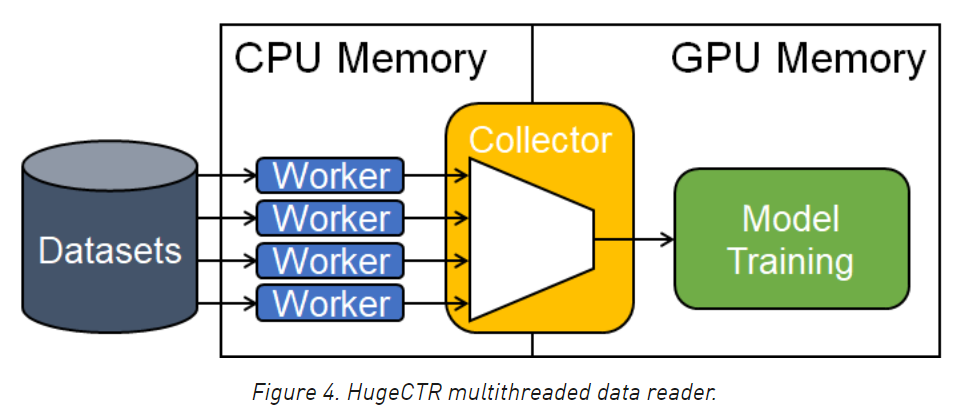
下圖是從多執行緒資料讀取、資料從CPU拷貝到GPU、訓練的程序,圖里的worker,其實指的就是reader,多個reader同時決議dataset的資料,然后由collector模塊將資料拷貝到GPU,圖里的worker、collector、training這三個是通過流水線串起來,各個部分相互獨立,同時在不同的執行緒中運行,
下圖就是流水線的具體示例,每種顏色代表一級流水線,共三級流水線,當第一級決議完batch0后,扔給第二級用來拷貝給GPU,這時候第一級繼續決議batch1,當batch0在訓練的時候,同時在做的是batch1拷貝到GPU,
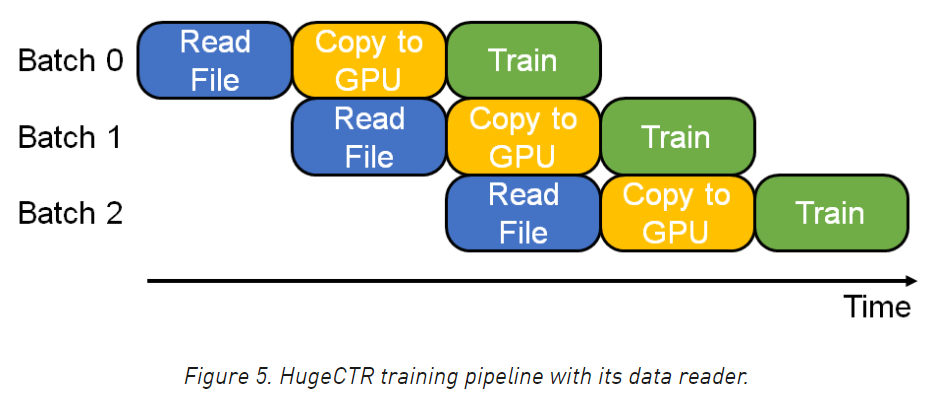
需要注意的是,上圖各級流水線的時間默認是相等的,但是實際情況一般不會這么巧,那么一般是需要靈活調整各級流水線的執行緒數的,讓各級流水線的速度匹配起來,舉個例子比如,readfile開10個執行緒,copy開5個執行緒,訓練開8個執行緒,另外,上面實際是縱向在看流水線,如果橫向來看,是各個batch互相獨立的在做readfile-copy-train,
有沒有發現,這里的流水線解答了開頭的第2個問題,
代碼閱讀
我看代碼喜歡自頂向下的看,這樣不僅能開始就能掌握運行的整個流程,后面看細節的時候也可以有針對性得看,另外,我沒有弄太多子標題,順序往下看就好,
我們首先看readme中的例子,這是一個呼叫了python api的例子,hugectr與常見的深度學習框架一樣,分為python端和c++端,python封裝user api,c++實作底層訓練邏輯,
# train.py
import sys
import hugectr
from mpi4py import MPI
def train(json_config_file):
solver_config = hugectr.solver_parser_helper(batchsize = 16384,
batchsize_eval = 16384,
vvgpu = [[0,1,2,3,4,5,6,7]],
repeat_dataset = True)
sess = hugectr.Session(solver_config, json_config_file)
sess.start_data_reading()
for i in range(10000):
sess.train()
if (i % 100 == 0):
loss = sess.get_current_loss()
print("[HUGECTR][INFO] iter: {}; loss: {}".format(i, loss))
if __name__ == "__main__":
json_config_file = sys.argv[1]
train(json_config_file)
另外,觀察這里的api會發現,長得跟tensorflow單機的api是不是很像,確實分布式框架的一個目標就是用起來像寫單機程式一樣順手,也就是所謂的“易用性”,
這里的solver_config就是把各種訓練配置傳入hugectr,session就是封裝了分布式訓練邏輯,start_data_reading就是字面意思,啟動上文的readfile的異步執行緒,也就是第一級流水線,接著就是train,然后列印oss,
前面說過,自頂向下看代碼的好處是可以對細節有針對性,那咱們先看重點,也就是sess.train,
python端與c++端的連接,可以使用pybind庫,連接的“橋梁”定義在pybind/session_wrapper.hpp這個檔案里:
void SessionPybind(pybind11::module &m) {
pybind11::class_<HugeCTR::Session, std::shared_ptr<HugeCTR::Session>>(m, "Session")
.def(pybind11::init<const SolverParser &, const std::string &, bool, const std::string>(),
pybind11::arg("solver_config"), pybind11::arg("config_file"),
pybind11::arg("use_model_oversubscriber") = false,
pybind11::arg("temp_embedding_dir") = std::string())
.def("train", &HugeCTR::Session::train)
.def("eval", &HugeCTR::Session::eval)
.def("start_data_reading", &HugeCTR::Session::start_data_reading)
....
在python呼叫sess.train,對應了c++的HugeCTR::Session::train,讓我們來看一下這個函式,我加了一些注釋:
bool Session::train() {
// 判斷reader是否啟動,未啟動就開始訓練則報錯
if (train_data_reader_->is_started() == false) {
CK_THROW_(xxxx);
}
// 等待reader讀取至少一個batchsize的資料
long long current_batchsize = 0;
while ((current_batchsize = train_data_reader_->read_a_batch_to_device_delay_release()) &&
(current_batchsize < train_data_reader_->get_full_batchsize())) {
// 告訴reader可以開始決議資料了,通過設定flag:READY_TO_WRITE
train_data_reader_->ready_to_collect();
}
// 讀不到資料了,即沒有資料可以訓練了,直接回傳
if (!current_batchsize) {
return false;
}
// reader決議完一個batch的資料后,flag會被設定為READY_TO_READ
// 上面通過read_a_batch_to_device_delay_release把資料已經從reader中取出來,
// 并且正在異步的拷貝到GPU,
// 呼叫ready_to_collect,首先sync上面的異步拷貝,然后讓reader繼續決議下一個batch
train_data_reader_->ready_to_collect();
// 從ps查embedding,做sum或者avg
for (auto& one_embedding : embeddings_) {
one_embedding->forward(true);
}
// 這里的邏輯看著有點亂,也就是多卡資料并行訓練,
// 一個網路有gpu卡數個副本,也就是networks大小大于1的原因,
if (networks_.size() > 1) {
// 單機多卡或多機多卡
// execute dense forward and backward with multi-cpu threads
#pragma omp parallel num_threads(networks_.size())
{
// dense網路的前向反向
size_t id = omp_get_thread_num();
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(id);
networks_[id]->train(current_batchsize_per_device);
// 多卡之間交換dense引數的梯度
networks_[id]->exchange_wgrad();
// 更新dense引數
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
// 多機單卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device);
networks_[0]->exchange_wgrad();
networks_[0]->update_params();
} else {
// 單機單卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device);
networks_[0]->update_params();
}
// embedding的反向
for (auto& one_embedding : embeddings_) {
one_embedding->backward();
// 更新sparse引數
one_embedding->update_params();
}
return true;
}
看到這里,基本上訓練中的大體流程是清楚了,接下來,我們繼續深入往下看reader、embedding、引數存盤和通信等部分,首先有必要看一下初始化,
HugeCTR::Session的初始化代碼如下:
parser.create_pipeline(
train_data_reader_, evaluate_data_reader_,
embeddings_, networks_, resource_manager_);
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
networks_[id]->initialize();
if (solver_config.use_algorithm_search) {
networks_[id]->search_algorithm();
}
CK_CUDA_THROW_(cudaStreamSynchronize(
resource_manager_->get_local_gpu(id)->get_stream()));
}
init_or_load_params_for_dense_(solver_config.model_file);
init_or_load_params_for_sparse_(solver_config.embedding_files);
load_opt_states_for_sparse_(solver_config.sparse_opt_states_files);
load_opt_states_for_dense_(solver_config.dense_opt_states_file);
也就是分為以下步驟:
(1)創建三級流水線,即create_pipeline
(2)初始化network
(3)初始化引數,以及對應的優化器狀態
這里面比較重要的部分是創建三級流水線,我們看一下create_pipeline的實作(函式傳參先忽略掉):
// create reader
create_datareader<TypeKey>()(...);
// create embedding
for (unsigned int i = 1; i < j_layers_array.size(); i++) {
// 網路配置的每層是從bottom到top的,因此只要遇到非embedding的layer,
// 后面的layer就不用檢查了
const nlohmann::json& j = j_layers_array[i];
auto embedding_name = get_value_from_json<std::string>(j, "type");
Embedding_t embedding_type;
if (!find_item_in_map(embedding_type, embedding_name, EMBEDDING_TYPE_MAP)) {
break;
}
create_embedding<TypeKey, float>()(...);
}
// create network,每張GPU卡創建一個network副本
for (size_t i = 0; i < resource_manager->get_local_gpu_count(); i++) {
network.emplace_back(Network::create_network(...));
}
可以看到create_pipeline主要包含了三步:create_datareader、create_embedding、create_network
我們接下來先看create_datareader里面做了什么:創建了一個train_data_reader和一個evaluate_data_reader,也就是一個用于訓練,一個用于評估,然后還各自創建了WorkerGroup,
DataReader<TypeKey>* data_reader_tk = new DataReader<TypeKey>(...);
train_data_reader.reset(data_reader_tk);
DataReader<TypeKey>* data_reader_eval_tk = new DataReader<TypeKey>(...);
evaluate_data_reader.reset(data_reader_eval_tk);
train_data_reader->create_drwg_norm(source_data, check_type, repeat_dataset_);
evaluate_data_reader->create_drwg_norm(eval_source, check_type, repeat_dataset_);
void create_drwg_norm(std::string file_name, Check_t check_type,
bool start_reading_from_beginning = true) override {
source_type_ = SourceType_t::FileList;
worker_group_.reset(new DataReaderWorkerGroupNorm<TypeKey>(
csr_heap_, file_name, repeat_, check_type, params_, start_reading_from_beginning));
file_name_ = file_name;
}
// DataReaderWorkerGroupNorm的建構式主要是如下功能,創建DataReaderWorker
for (int i = 0; i < NumThreads; i++) {
std::shared_ptr<IDataReaderWorker> data_reader(new DataReaderWorker<TypeKey>(
i, NumThreads, csr_heap, file_list, max_feature_num_per_sample, repeat, check_type, params));
data_readers_.push_back(data_reader);
}
// 然后創建了多個執行緒,每個執行緒對應一個reader,執行如下邏輯
while (*p_loop_flag) {
data_reader->read_a_batch();
}
好了,看到這里,出現了兩個類DataReader和DataReaderWorkerGroupNorm,這兩個類有必要看一下細節,從而弄清楚資料讀取,
先看DataReader里的重要的函式和變數:
template <typename TypeKey>
class DataReader : public IDataReader {
std::shared_ptr<HeapEx<CSRChunk<TypeKey>>> csr_heap_;
std::shared_ptr<DataCollector<TypeKey>> data_collector_;
std::shared_ptr<DataReaderWorkerGroup> worker_group_;
//還有各種tensor:label_tensors_、dense_tensors_、row_offsets_tensors_、value_tensors_等
DataReader(...) {
// 初始化heap,這個類后面介紹
csr_heap_.reset(new HeapEx<CSRChunk<TypeKey>>(...));
// 為每個GPU初始化一個buffer
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> buffs;
for (size_t i = 0; i < local_gpu_count; i++) {
buffs.push_back(GeneralBuffer2<CudaAllocator>::create());
}
// create label and dense tensor
size_t batch_size_per_device = batchsize_ / total_gpu_count;
for (size_t i = 0; i < local_gpu_count; i++) {
// Tensor2并不持有記憶體或者顯存,是在buffs里
{
Tensor2<float> tensor;
buffs[i]->reserve({batch_size_per_device, label_dim_}, &tensor);
label_tensors_.push_back(tensor);
}
{
Tensor2<float> tensor;
buffs[i]->reserve({batch_size_per_device, dense_dim_}, &tensor);
dense_tensors_.push_back(tensor.shrink());
}
}
...
// 這里又出現一個DataCollector類
data_collector_.reset(new DataCollector<TypeKey>(...);
data_collector_->start();
// buffs在每個GPU上分配顯存
for (size_t i = 0; i < local_gpu_count; i++) {
CudaDeviceContext context(resource_manager_->get_local_gpu(i)->get_device_id());
buffs[i]->allocate();
}
}
詳細介紹一下上面出現的類:
(1)CSR:一種用來壓縮稀疏矩陣的存盤格式,例子如下
假如有這樣一組資料
* 4,5,1,2
* 3,5,1
* 3,2
用CSR可以表示為
row offset: 0,4,7,9
value: 4,5,1,2,3,5,1,3,2
這里的CSR由于是用來存盤slot里的sparse key,其實少了column index,因為一個slot里的sparse key直接順序存就好了,CSR可以參考這篇文章,總是令人想起百度paddle的lodtensor,
(2)HeapEx:為每個資料決議的執行緒維護了三個佇列,ready queue 、 wait queue 和 credit queue,佇列中的元素就是CSR存盤,當credit queue非空,意味著有空閑的CSR可以用來存盤決議好的資料,
- 決議資料(多執行緒):當前執行緒只會操作自己的queue,從credit queue取出一個空閑的CSR后,會同時把它塞到wait queue里,資料決議完存到該CSR后,會把它從wait queue移除,塞到ready queue里(之所以多了一步放在wait queue里的步驟,主要是為了記錄該CSR,從而塞到ready queue里),
- 讀資料(單執行緒):從上述多個佇列里取資料,HeapEx里有一個變數count,記錄了上次是從哪個index的資料決議執行緒的ready queue中取得的資料,下次取資料還是從這個index的ready queue開始遍歷,也就是“”輪詢”,歸還資料還給這個index,歸還是歸還到credit queue里,并將其從ready queue移除,當歸還成功后count++,(為啥不是取資料的時候,就把資料從ready queue移除呢?因為取資料是單執行緒的,所以這樣做是可以的)
(3)DataReaderWorker:就是上面的決議資料執行緒,
(4)DataCollector:就是上面的讀資料執行緒,把資料從CSR拷貝到GPU,它會啟動一個執行緒不斷的執行如下函式:
template <typename TypeKey>
void DataCollector<TypeKey>::collect_() {
std::unique_lock<std::mutex> lock(stat_mtx_);
CSRChunk<TypeKey>* chunk_tmp = csr_heap_->checkout_data_chunk();
while (stat_ != READY_TO_WRITE && stat_ != STOP) {
usleep(2);
}
...
cudaMemcpyAsync 做拷貝
...
cudaStreamSynchronize
...
csr_heap_->return_free_chunk();
stat_ = READY_TO_READ;
這里checkout_data_chunk從一個佇列里取出一個CSR,拷貝完成后再呼叫return_free_chunk歸還,
為了清晰一點表示流程,我畫了個簡易的圖,綠色的線是資料生產消費,紅色是資料歸還,data reader worker獲取到空閑的CSR就決議資料填進去,并放到ready queue中,而data collector發現有可用的CSR,就拷貝到GPU中,然后歸還CSR,可以說,data reader worker和data collector是相互獨立的,兩者通過存放資料的佇列聯系起來,
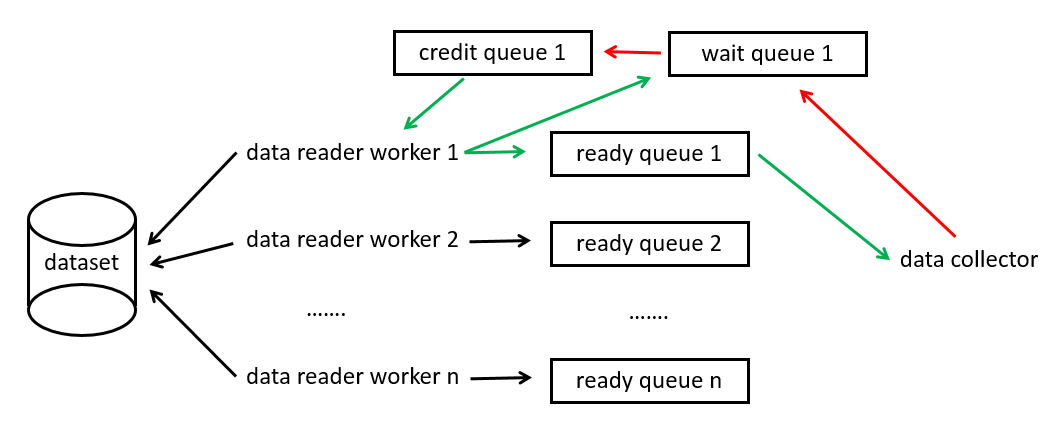
還有一些細節值得注意:
(1)hugectr還實作了兩外兩種data reader worker,一種是DataReaderWorkerRaw,它讀取的資料是通過mmap直接映射到記憶體,還有一種是DataReaderWorkerGroup,讀取parquet格式的檔案,
(2)data reader worker決議資料放到CSR的細節:
// 回傳的是get_batchsize訓練配置的batch size
for (i = 0; i < csr_chunk->get_batchsize(); i++) {
// dense輸入
{
// label_dense_buffers的大小是當前節點的gpu卡數
// buffer_id就是這條樣本落在哪張卡上
int buffer_id = i / (csr_chunk->get_batchsize() / label_dense_buffers.size());
// local_id是這條樣本在當前卡上的偏移
int local_id = i % (csr_chunk->get_batchsize() / label_dense_buffers.size());
// 拷貝,從決議資料的buffer拷貝到CSR里
float* ptr = label_dense_buffers[buffer_id].get_ptr();
for (int j = 0; j < label_dense_dim; j++) {
ptr[local_id * label_dense_dim + j] = label_dense[j]; // row major for label buffer
}
}
// sparse輸入
for (auto& param : params_) {
for (int k = 0; k < param.slot_num; k++) {
// 省略了讀取資料
...
// 下面這段代碼,對理解embedding的兩種存盤方式很有幫助
if (param.type == DataReaderSparse_t::Distributed) {
// 所有節點的每張卡上都會存所有slot
for (int dev_id = 0; dev_id < csr_chunk->get_num_devices(); dev_id++) {
csr_chunk->get_csr_buffer(param_id, dev_id).new_row();
}
// 這里就是判斷slot的key應該存在哪張卡上
for (int j = 0; j < nnz; j++) {
int dev_id = feature_ids_[j] % csr_chunk->get_num_devices();
dev_id = std::abs(dev_id);
T local_id = feature_ids_[j];
csr_chunk->get_csr_buffer(param_id, dev_id).push_back(local_id);
}
} else if (param.type == DataReaderSparse_t::Localized) {
// 一個slot只會存在一張卡上
int dev_id = k % csr_chunk->get_num_devices();
csr_chunk->get_csr_buffer(param_id, dev_id).new_row();
for (int j = 0; j < nnz; j++) {
T local_id = feature_ids_[j];
csr_chunk->get_csr_buffer(param_id, dev_id).push_back(local_id);
}
}
}
}
}
(3)data collector拷貝資料的細節:
// total_device_count 所有節點的gpu之和
for (int ix = 0; ix < total_device_count; ix++) {
int i =
((id_ == 0 && !reverse_) || (id_ == 1 && reverse_)) ? ix : (total_device_count - 1 - ix);
int pid = resource_manager_->get_process_id_from_gpu_global_id(i);
int label_copy_num = (label_dense_buffers[0]).get_num_elements();
if (pid == resource_manager_->get_process_id()) {
...
for (int j = 0; j < num_params; j++) {
// 這里的i * num_params + j取的就是全域的偏移
unsigned int nnz = csr_cpu_buffers[i * num_params + j]
.get_row_offset_tensor()
.get_ptr()[csr_cpu_buffers[i * num_params + j].get_num_rows()];
// cudaMemcpyAsync 異步拷貝
}
我們發現:所有的節點都會決議所有的資料!在拷貝的時候,才會只拷貝出屬于本節點的資料,這種實作,對于大資料量來說,性能是很值得懷疑的,帶寬可能不夠,并且會決議大量無用的資料,
一方面資料拷貝的時候會只保留屬于本gpu的sparse key,另一方面本gpu中也只會存盤屬于本節點的sparse key,那么也就是說sparse pull和push的時候就不需要位元組點間的通信了,當然后續還是需要位元組點間通信,把資料拼成完整的batch做前向反向計算,得到梯度后位元組點間的梯度平均,這塊會在create embedding處詳細展開,
實際上面的data reader worker 與 data collector就是本文開頭的圖里的第一、二級流水線了,接下來我們再看一下創建第三級流水線中的create_embedding部分,
創建embedding初始化,我們應該最關注的是如何存引數,在此之前,我們看看網路配置,看看是咋組織embedding的, 這里就以deepfm為例,首先看一下輸入層
"dense": {
"top": "dense",
"dense_dim": 13
},
"sparse": [
{
"top": "data1",
"type": "DistributedSlot",
"max_feature_num_per_sample": 30,
"slot_num": 26
}
]
dense輸入是deepfm的fm輸入,sparse是deepfm的deep輸入,包含了26個slot,再看embedding層的定義,max_vocabulary_size_per_gpu是一個gpu卡上的最大sparse key的個數,embedding_vec_size就是embedding向量維度,combiner表示查完embedding做pooling是sum還是avg,
{
"name": "sparse_embedding1",
"type": "DistributedSlotSparseEmbeddingHash",
"bottom": "data1",
"top": "sparse_embedding1",
"sparse_embedding_hparam": {
"max_vocabulary_size_per_gpu": 1447751,
"embedding_vec_size": 11,
"combiner": 0
}
}
hugectr有兩種embedding:DistributedSlotSparseEmbeddingHash和 LocalizedSlotSparseEmbeddingHash,我們一個一個看,
大致掃一眼hashmap創建的代碼,兩者是一樣的:
// 注意到hash table的value type是個size_t,這個是記錄了embedding在存盤中的偏移量
using NvHashTable = HashTable<TypeHashKey, size_t>;
// 這個是hashmap的定義,發現外面套了個vector,需要弄清楚vector每個元素是啥
std::vector<std::shared_ptr<NvHashTable>> hash_tables_;
// 原來vector大小是本地gpu數,也就是說每個gpu卡對應一個hash table
hash_tables_.resize(Base::get_resource_manager().get_local_gpu_count());
// 事先就固定了hash table容納元素的最大數量為max_vocabulary_size_per_gpu_
#pragma omp parallel num_threads(Base::get_resource_manager().get_local_gpu_count())
{
size_t id = omp_get_thread_num();
CudaDeviceContext context(Base::get_local_gpu(id).get_device_id());
// construct HashTable object: used to store hash table <key, value_index>
hash_tables_[id].reset(new NvHashTable(max_vocabulary_size_per_gpu_));
Base::get_buffer(id)->allocate();
}
這里可以解答開頭的第一個問題了,答案很簡單粗暴,就是事先固定了哈希表的大小,
這樣其實對于大規模稀疏來說,支持的引數規模不會很大,就像開頭第三個問題算過的億級別就得300G,因此hugectr支持的引數規模會因為這樣的設計,而受到比較大的限制,
那是不是第三個問題無解了呢,其實不然,百度的aibox不存在的這樣的限制,因為它采用了多級ps(ssd+mem+gpu),并且gpu ps的大小會隨著當前訓練的增量資料的key的多少而動態創建不同大小的hashmap,這里aibox暫時先不展開了,我后面會寫一篇文章專門介紹它的論文,:)
繼續看一下HashTable這個類
template <typename KeyType, typename ValType>
class HashTable {
// 查找key,如果key不在table里就insert
void get_insert(const KeyType* d_keys, ValType* d_vals, size_t len, cudaStream_t stream);
// 查找key
void get(const KeyType* d_keys, ValType* d_vals, size_t len, cudaStream_t stream) const;
// 把table里的kv都dump出來
void dump(KeyType* d_key, ValType* d_val, size_t* d_dump_counter, cudaStream_t stream) const;
HashTableContainer<KeyType, ValType>* container_
我們再看一下HashTableContainer,它是繼承了concurrent_unordered_map這個類
template <typename KeyType, typename ValType>
class HashTableContainer
: public concurrent_unordered_map<KeyType, ValType, std::numeric_limits<KeyType>::max()> {
public:
HashTableContainer(size_t capacity)
: concurrent_unordered_map<KeyType, ValType, std::numeric_limits<KeyType>::max()>(
capacity, std::numeric_limits<ValType>::max()) {}
};
concurrent_unordered_map是固定大小的、在顯存中的map,它支持并發insert,但是不支持并發insert和get,因為hugectr訓練是同步的訓練,pull的時候只會有get,push的時候只會有insert,并且不會同時做pull和push,因此這樣的concurrent_unordered_map滿足要求,
首先看一下它的get函式:
// __forceinline__ 強制指定為行內函式
// __host__ __device__ 這個函式會同時為主機端和設備端編譯
__forceinline__ __host__ __device__ const_iterator find(const key_type& k) const {
// 對key做哈希
size_type key_hash = m_hf(k);
// 映射到table的一個index
size_type hash_tbl_idx = key_hash % m_hashtbl_size;
value_type* begin_ptr = 0;
size_type counter = 0;
while (0 == begin_ptr) {
value_type* tmp_ptr = m_hashtbl_values + hash_tbl_idx;
const key_type tmp_val = tmp_ptr->first;
// 找到了這個key
if (m_equal(k, tmp_val)) {
begin_ptr = tmp_ptr;
break;
}
// 這個位置是空的,或者找完了這個table也沒找到
if (m_equal(unused_key, tmp_val) || counter > m_hashtbl_size) {
begin_ptr = m_hashtbl_values + m_hashtbl_size;
break;
}
hash_tbl_idx = (hash_tbl_idx + 1) % m_hashtbl_size;
++counter;
}
return const_iterator(m_hashtbl_values, m_hashtbl_values + m_hashtbl_size, begin_ptr);
}
可以看出,get一個key的時候,如果insert了這個key,可能還是get不到,或者get到的是錯誤的值(insert正在修改這個值的時候,get了這個值),或者舊的值,
再看一下insert,它的主要程序如下
const key_type insert_key = k;
bool insert_success = false;
size_type counter = 0;
while (false == insert_success) {
// 哈希表滿了
if (counter++ >= hashtbl_size) {
return end();
}
key_type& existing_key = current_hash_bucket->first;
volatile mapped_type& existing_value = current_hash_bucket->second;
// existing_key == unused_key時,insert_key會被賦值給existing_key,因為這個位置是空的,
// existing_key == insert_key時,這個位置已經有這個key了,
// 如果這時候existing_value == m_unused_element,就說明其他執行緒正在insert且還沒來得及修改existing_value
const key_type old_key = atomicCAS(&existing_key, unused_key, insert_key);
if (keys_equal(unused_key, old_key)) {
existing_value = (mapped_type)(atomicAdd(value_counter, 1));
break;
} else if (keys_equal(insert_key, old_key)) {
while (existing_value == m_unused_element) { }
break;
}
// 這個位置被其他key占了,繼續往后遍歷
current_index = (current_index + 1) % hashtbl_size;
current_hash_bucket = &(hashtbl_values[current_index]);
}
return iterator(m_hashtbl_values, m_hashtbl_values + hashtbl_size, current
atomicCAS函式參考這篇文章,
兩種embedding:
(1)DistributedSlotSparseEmbeddingHash
void forward(bool is_train) override {
// Read data from input_buffers_ -> look up -> write to output_tensors
CudaDeviceContext context;
for (size_t i = 0; i < Base::get_resource_manager().get_local_gpu_count(); i++) {
context.set_device(Base::get_local_gpu(i).get_device_id());
functors_.forward_per_gpu(..., Base::get_local_gpu(i).get_stream());
}
// do reduce scatter
size_t recv_count = Base::get_batch_size_per_gpu(is_train) *
Base::get_slot_num() *
Base::get_embedding_vec_size();
functors_.reduce_scatter(recv_count, embedding_feature_tensors_,
Base::get_output_tensors(is_train), Base::get_resource_manager());
// scale for combiner=mean after reduction
if (Base::get_combiner() == 1) {
size_t send_count = Base::get_batch_size(is_train) * Base::get_slot_num() + 1;
functors_.all_reduce(send_count, Base::get_row_offsets_tensors(is_train),
row_offset_allreduce_tensors_, Base::get_resource_manager());
// do average
functors_.forward_scale(Base::get_batch_size(is_train), Base::get_slot_num(),
Base::get_embedding_vec_size(), row_offset_allreduce_tensors_,
Base::get_output_tensors(is_train), Base::get_resource_manager());
}
return;
}
我們先看forward,首先從當前gpu的hashmap做lookup,也就是functors_.forward_per_gpu,此時不需要位元組點間通信,因為當前gpu對應的資料的key都在當前gpu,
接著做了reduce scatter,這個通信可以參考這篇官方檔案
做完forward的時候,每個gpu的資料是batch size條,但是每條資料里的每個slot是一部分key,做完reduce scatter后,資料是完整的了,并且每個gpu上分到一部分完整的資料,
我們假設一共有2個gpu,batch size為2,一共3個slot,那么上面的程序如下:
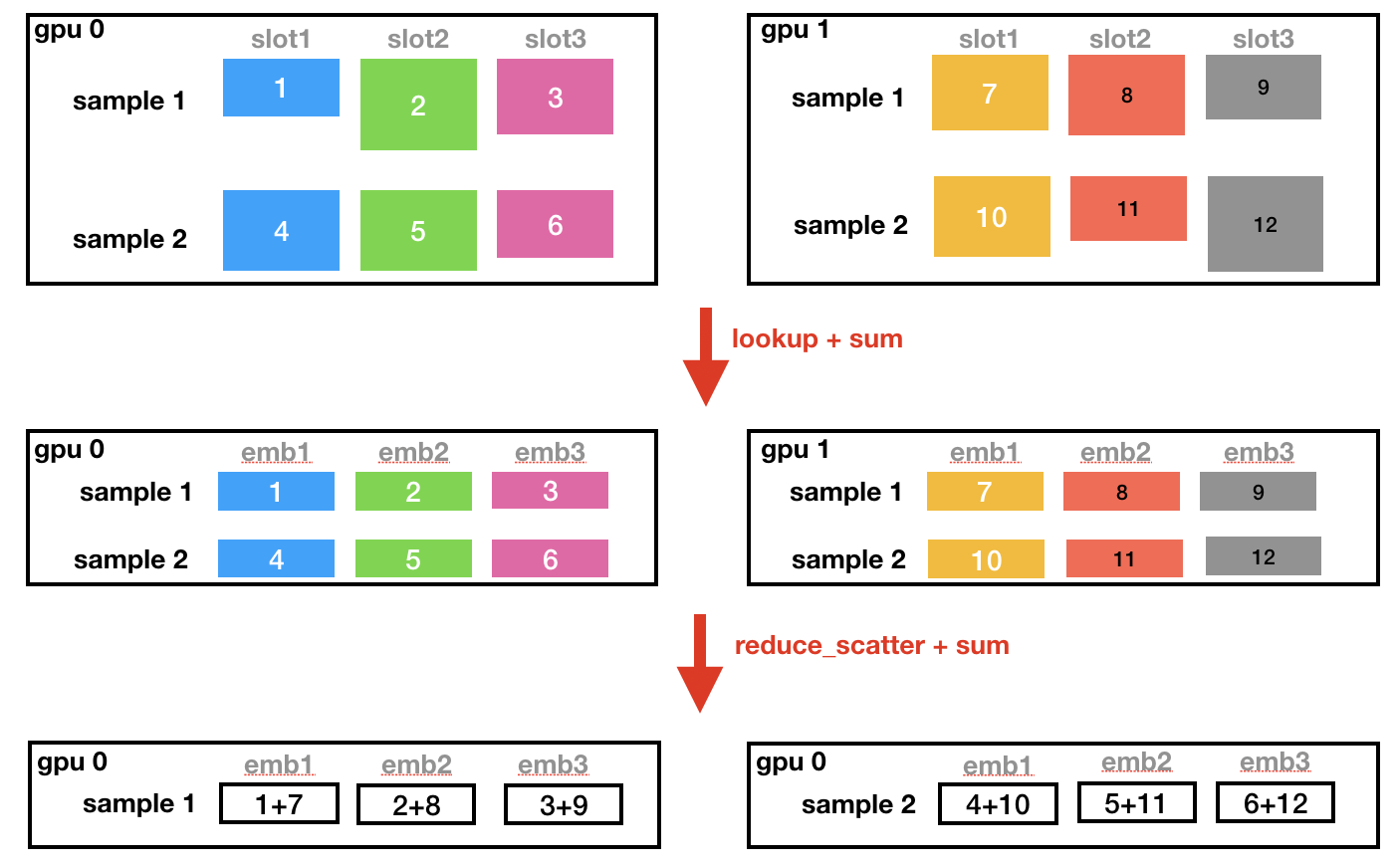
如果是要做mean pooling,還需要做再做一次all reduce,拿到每個sample每個slot里的key的總個數(把csr里的offset求個allreduce,就可以得到全域offset了),然后把embedding的值除以這個個數,也就是求了平均,
再看一看backward
void backward() override {
// Read dgrad from output_tensors -> compute wgrad
// do all-gather to collect the top_grad
size_t send_count =
Base::get_batch_size_per_gpu(true) * Base::get_slot_num() * Base::get_embedding_vec_size();
functors_.all_gather(send_count, Base::get_output_tensors(true), embedding_feature_tensors_,
Base::get_resource_manager());
// do backward
functors_.backward(...);
return;
}
首先做all gather,每個gpu拿到當前batch所有樣本的梯度,然后更新本地每個gpu上的引數,
void update_params() override {
#pragma omp parallel num_threads(Base::get_resource_manager().get_local_gpu_count())
{
size_t id = omp_get_thread_num();
CudaDeviceContext context(Base::get_local_gpu(id).get_device_id());
// accumulate times for adam optimizer
Base::get_opt_params(id).hyperparams.adam.times++;
// do update params operation
functors_.update_params(...);
}
return;
}
dump分為dump引數與dump優化器狀態,兩者代碼比較類似,如下是dump引數:
// dump hash table from GPUs
for (size_t id = 0; id < local_gpu_count; id++) {
// dump key
hash_tables[id]->dump
// 拷貝到記憶體
cudaMemcpyAsync(...,cudaMemcpyDeviceToHost,...)
// dump value
functors_.get_hash_value
// 拷貝到記憶體
cudaMemcpyAsync(...,cudaMemcpyDeviceToHost,...)
}
functors_.sync_all_gpus(...)
for (size_t id = 0; id < local_gpu_count; id++) {
// 每個gpu上引數總大小
size_t size_in_B = count[id] * (sizeof(TypeHashKey) + sizeof(float) * embedding_vec_size);
// memcpy到file_buf
...
// rank0節點負責寫檔案
if (Base::get_resource_manager().is_master_process()) {
weight_stream.write(file_buf.get(), size_in_B);
} else {
// 其他節點把資料發給rank0節點
MPI_Send(file_buf.get(), size_in_B, ...);
}
}
// rank0節點收到資料
if (Base::get_resource_manager().is_master_process()) {
for (int r = 1; r < Base::get_resource_manager().get_num_process(); r++) {
for (size_t id = 0; id < local_gpu_count; id++) {
...
MPI_Recv(...);
weight_stream.write(file_buf.get(), size_in_B);
}
}
}
// 釋放gpu顯存
cudaFree
注意到dump的時候需要把引數和優化器狀態都通過MPI_SEND發給一個節點,引數規模比較大時,0號節點就會成為瓶頸,不如每個節點dump自己的引數,還可以按分片組織引數,
load時候,每個節點都會加載所有模型檔案,然后判斷每個key是否屬于自己:
TypeHashKey key = key_ptr[...];
size_t gid = key % global_gpu_count; // global GPU ID
int dst_rank = get_process_id_from_gpu_global_id(gid); // node id
if (my_rank == dst_rank) {
memcpy(...)
} else {
continue;
}
(2)LocalizedSlotSparseEmbeddingHash
void forward(bool is_train) override {
CudaDeviceContext context;
for (size_t i = 0; i < Base::get_resource_manager().get_local_gpu_count(); i++) {
context.set_device(Base::get_local_gpu(i).get_device_id()); // set device
functors_.forward_per_gpu(...);
}
functors_.all2all_forward(...);
// reorder:重新組織收到的資料buffer
functors_.forward_reorder(...);
// 保存每個sparse引數對應對的slot id
functors_.store_slot_id(...);
return;
}
all2all_forward的程序如下:
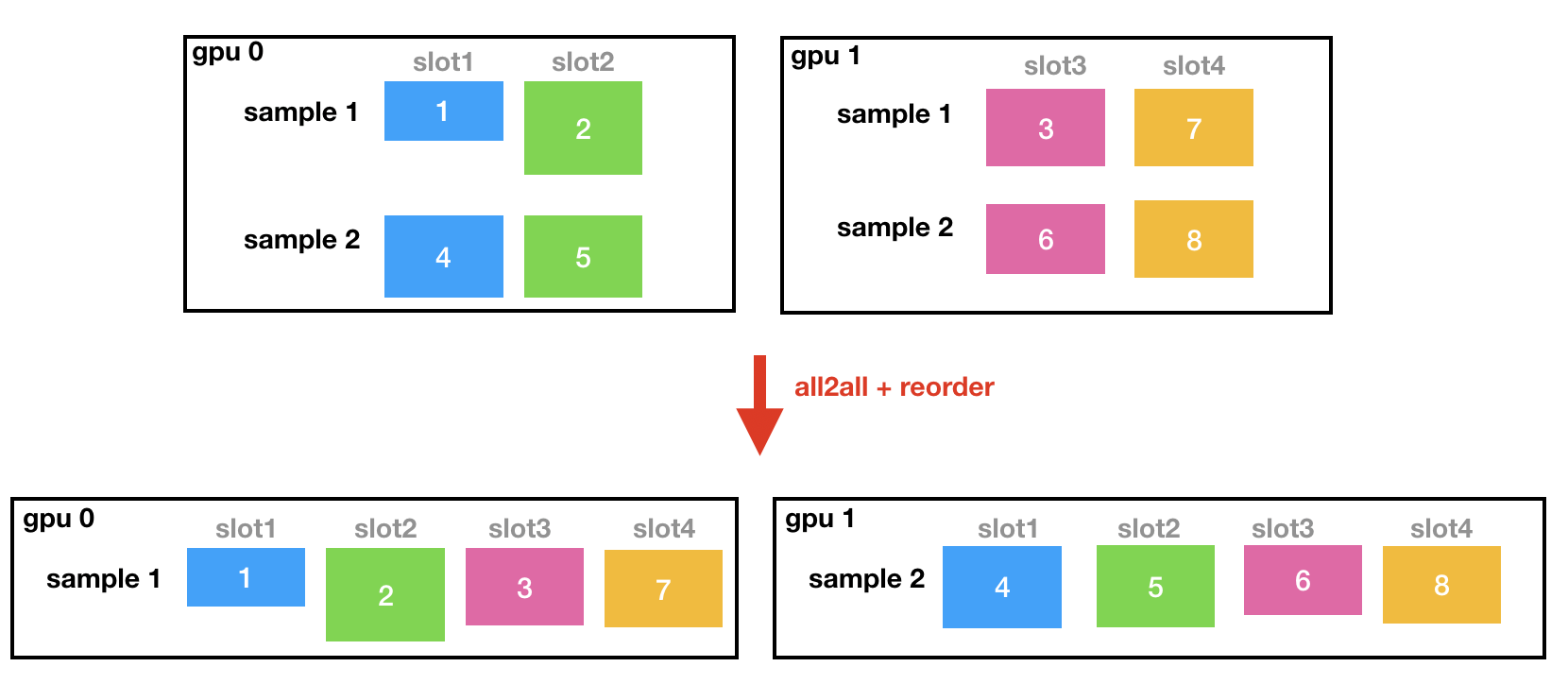
reorder的程序可以這樣理解:
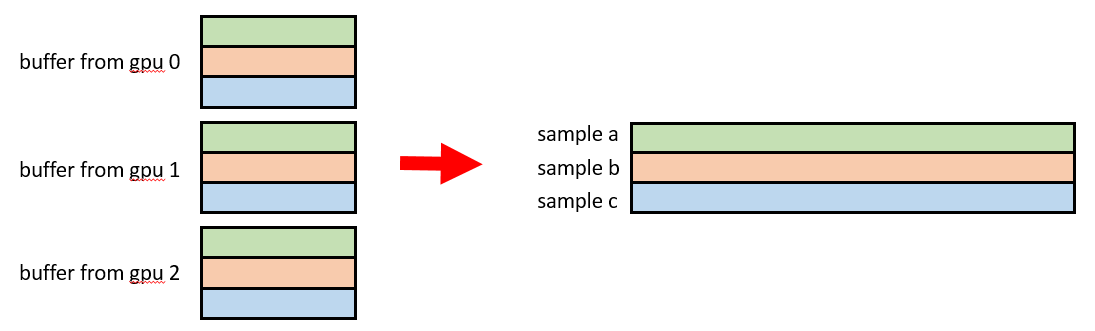
之所以要保存引數對應的slot id,是因為每個gpu上存不同的slot,加載的時候需要知道加載哪個slot的引數,
create_network主要是創建神經網路的各個層,
執行完前向反向后,首先多卡之間會平均梯度,然后再更新dense引數,
void Network::exchange_wgrad() {
CudaDeviceContext context(get_device_id());
ncclAllReduce((const void*)wgrad_tensor_.get_ptr(),
(void*)wgrad_tensor_.get_ptr(), wgrad_tensor_.get_num_elements(),
ncclFloat, ncclSum, gpu_resource_->get_nccl(),
pu_resource_->get_stream()));
}
說到這里,基本上整個訓練流程應該是清楚了,這里再說一下混合精度訓練,hugectr在官方介紹中的Highlighted features提到了混合精度訓練,在hugectr中,embedding層的引數存盤還是用的全精度float32,如果配置了使用mixed_precision,那么embedding層優化器狀態用的是半精度fp16,其輸出也為半精度fp16,并且其他dense支持fp16計算的層也會使用fp16計算,可以看這篇文章,
上面大致了解了hugectr之后,可以再運行一下hugectr官方代碼庫的例子,
看完代碼后,這里小小的總結一下hugectr的優缺點:
優點:
- 大batch訓練 / 復雜模型訓練,sparse引數分布在多個gpu上,worker與ps在同一個行程,支持混合精度訓練,
- embedding表存在gpu中,sparse引數通信比cpu的方式更快,embedding在本節點lookup后,先做sum/embedding,減少通信量,dense引數通信也是通過gpu,
- 三級流水線,隱藏資料時間:決議資料(data reader worker)、拷貝資料到gpu(collector)、訓練(前向反向+更新引數),
缺點:
- 每個節點下載決議全量資料,資料量大時候帶寬會成為瓶頸,
- dump模型的時候只有0號節點節點執行,引數量大的時候0號節點會成為瓶頸,
- lookup之后需要節點間交換樣本:DistributedSlotSparseEmbeddingHash與LocalizedSlotSparseEmbeddingHash都需要通信交換樣本,兩種模式相比之間沒有明顯區別優勢,
- 事先需要分配好引數服務器的顯存,并且大小固定,不適合引數量大的場景,
參考文獻
【1】https://developer.nvidia.com/blog/introducing-merlin-hugectr-training-framework-dedicated-to-recommender-systems/
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278065.html
標籤:其他