目 錄
一 系統性能測驗指標
1.1 回應時間
1.2 并發
1.3 點擊量/點擊率
1.4 吞吐量/吞吐率
1.5 TPS/QPS
1.6 PV/UV
二 Linux服務器性能指標
2.1 CPU使用率
2.2 記憶體占用率
2.3 系統平均負載
2.4 磁盤IO
2.5 linux常用性能命令
2.5.1 CPU
2.5.2 記憶體
2.5.3 負載
2.5.4 磁盤
2.5.5 整體
性能測驗指標是衡量系統性能的評價標準,常用的系統性能測驗指標包括:回應時間、并發用戶/并發、點擊率、吞吐量、TPS/QPS、PV/UV;Linux服務器常用的性能指標包括:CPU使用率、記憶體占用率、磁盤IO、系統平均負載等,
一 系統性能測驗指標
1.1 回應時間
回應時間是指某個請求或操作從發出到接收到反饋所消耗的時間,包括應用服務器(客戶端)處理時間、網路傳輸時間以及資料庫服務器處理時間,比如一個頁面從點擊/輸入到完全加載的時間;完成一次增加、洗掉、修改或者查詢動作的事務回應時間等,
一個請求在網路上的傳輸往往要經歷多個網路節點才能到達目標服務器,我們假設請求經歷了三個網路節點的傳輸時間B1、B2、B3,客戶端的處理時間為A,服務器的回應時間為C,則一次請求的完整路徑可以描述為下圖:
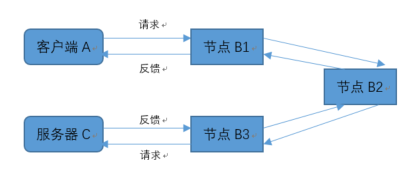
客戶端從發出請求到接收到服務器反饋的完整鏈路時間為A—>B1—>B2—>B3—>C(節點處理時間都包括接收和發送兩個程序),則請求的回應時間為:
回應時間=A+B1+B2+B3+C
1.2 并發
并發是指多個用戶在同一時期內進行相同的事務處理或操作,由于用戶在進行一系列操作流程時有一定的時間間隔(即用戶思考時間)或者服務器處理請求有先后順序,于是,就產生了絕對并發和相對并發概念的區分,
絕對并發是指同一時刻(即同一時間點)并發用戶對服務器同時發送請求,
相對并發是指一段時間內(即同一時間區間)并發用戶對服務器發送請求,
舉個例子,一個并發量為10000人(可同時容納10000人)的動物園,這里的并發量是指絕對并發還是相對并發呢?我們很容易理解,這個并發指的是相對并發,因為整個動物園是一個交織的網狀結構,出入口、老虎、獅子、大象等各個動物站點都有分流的作用,基本不可能出現出入口或者站點能夠同時承載10000人的情況,出入口的并發可能只有200人,因此這個動物園的例子里,并發量10000是指各個節點的總和,參觀者參觀動物園有路徑的先后順序,是相對并發的概念,而出入口的并發量是200人,則是指同一時間在出入口能夠同時容納200人,這就是絕對并發的概念,
一般來說,在系統的性能測驗中,系統或者模塊的并發更多是指相對并發,而介面的并發更傾向于絕對并發,并發性能的概念是指系統、模塊或介面穩定運行,不拋出例外情況下所能夠承載的并發量,
在并發性能測驗中常用到并發用戶數和并發請求數兩個指標,顧名思義,并發用戶數是指同一時間(點或區間),系統、模塊或介面能夠承載的用戶數量;并發請求數是指同一時間(點或區間),系統、模塊或介面能夠承載的請求數量,
1.3 點擊量/點擊率
點擊量是衡量網站流量的一個指標,也就是點擊數clicks,是對網站點擊資料的統計,
點擊率(Clicks Ratio)也可以叫做點進率(“Click-through Rate),它是網站上某一內容被點擊的次數與整個網站內容被顯示次數之比,即clicks/views,反應了網站上某一頁面或內容的受關注程度,經常用來衡量廣告的吸引程度,比如公眾號的一篇文章被瀏覽了10w次,文章中的廣告鏈接被點擊了2000次,那么這條廣告的點擊率是2%(2000/100000*100%),
在性能測驗領域,點擊率(hit rate)常指單位時間內(每秒鐘)頁面的點擊數,即每秒鐘發送的http請求數量,點擊率越大對服務器造成的壓力也越大,對服務器的性能要求也越高,
有些人容易混淆點擊率和點擊量的概念,比如我們經常會聽到有人說某網站的點擊率是多多萬,實際上這里的點擊率指的是點擊量,曝光率或者說頁面瀏覽量,
1.4 吞吐量/吞吐率
吞吐量是指系統處理客戶請求數量的總和,可以指網路上傳輸資料包的總和,也可以指業務中客戶端與服務器互動資料量的總和,
吞吐率是指單位時間內系統處理客戶請求的數量,也就是單位時間內的吞吐量,可以從多個維度衡量吞吐率:①業務角度:單位時間(每秒)的請求數或頁面數,即請求數/秒或頁面數/秒;②網路角度:單位時間(每秒)網路中傳輸的資料包大小,即位元組數/秒等;③系統角度,單位時間內服務器所承受的壓力,即系統的負載能力,
吞吐率(或吞吐量)是一種多維度量的性能指標,它與請求處理所消耗的CPU、記憶體、IO和網路帶寬都強相關,
1.5 TPS/QPS
TPS(Transaction Per Second)是指單位時間(每秒)系統處理的事務量,事務可以是用戶自定義的一系列操作或者動作的集合,比如“用戶注冊“事務是點擊注冊按鈕,填寫用戶注冊資訊,點擊提交按鈕,以及加載注冊成功頁面的動作集合,
QPS(Query Per Second)是指單位時間內查詢或訪問服務器的次數,
TPS和QPS的區別在于一個事務可以包含多次查詢或訪問服務器,也可以只查詢或訪問一次服務器,當多次查詢或訪問時,一個TPS相當于多個QPS;當只查詢或訪問一次時,一個TPS則等價于一個QPS,
1.6 PV/UV
PV和UV是衡量web網站性能容量的兩個重要度量指標,經常用在電子商務網站領域中用來衡量網站的活躍度,
PV(Page View)是頁面的瀏覽量或點擊量,用戶對系統或者網站任何頁面的每一次點擊或者訪問都會被記錄一次瀏覽量或點擊量,對相同頁面進行多次訪問瀏覽量或點擊量也會進行累計,
UV(Unique Vistor)是系統或者網站的獨立訪客,一段時間內相同客戶端(或PC)訪問系統或者網站只會被記錄一次,連續重復訪問或者瀏覽多個系統頁面次數不會進行累計,
PV和UV按照統計周期劃分,可以劃分為全天PV、每小時PV、全天UV和每小時UV等,在一些資料或交易量非常龐大的場景中,比如雙11或618等全民購物活動時,常常還會統計峰值PV和峰值UV,
二 Linux服務器性能指標
2.1 CPU使用率
CPU使用率是單位時間內服務器CPU的使用統計,可以用除CPU空閑時間外其他時間占總CPU時間的百分比來表示,即:CPU使用率=1-CPU空閑時間/總CPU時間
命令:#top //top工具間隔3s會動態滾動更新一次資料
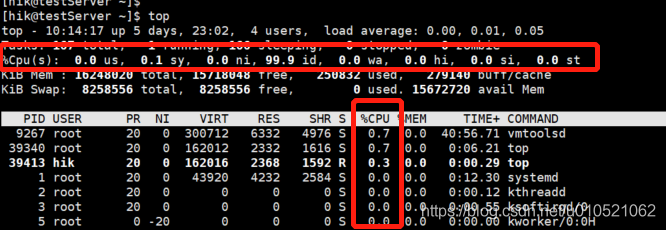
欄位說明:
us (user):用戶態的CPU使用時間比例,是用戶運行程式的真正時間,它不包括后面的ni時間;
sy (system): 內核態的CPU使用時間比例,是作業系統的運行時間,作業系統運行時,用戶運行程式往往處于等待狀態;
ni (nice): 表示低優先級用戶態的CPU時間比例,取值范圍為[-20,19],數值越大,則優先級越低;
id (idle): 表示空閑的CPU時間比例,值越大,CPU空閑時間比例越高,利用率越低;
wa (iowait): 表示處于IO等待狀態的CPU時間比例;
hi (hard interrupt): 表示處理硬中斷的CPU時間比例;
si (soft interrupt): 與hi相反,表示處理軟中斷的CPU時間比例;
st (steal): 表示當前系統運行在虛擬機中被其他虛擬機占用的CPU時間比例,
在性能測驗中,系統整體的CPU使用率可以用(1-id)來計算,當us很高時,說明CPU時間主要消耗在用戶代碼上,可以從用戶代碼角度考慮優化性能;當sy很高時,說明CPU時間主要消耗在內核上,可以從是否系統呼叫頻繁、CPU行程或執行緒切換頻繁角度考慮性能的優化;當wa很高時,說明有行程在進行頻繁的IO操作,可能是磁盤IO或者網路IO,
一般情況下,如果%us+%sy<=70%,我們可以認為系統的運行狀態良好,
2.2 記憶體占用率
Linux的系統記憶體管理機制遵循記憶體利用率最大化的原則,內核會將空余的記憶體劃分為cached(不屬于free),對于有頻繁讀取操作的檔案或資料會被保存在cached中,因此,對于linux系統來說,可用于分配的記憶體不止free的記憶體,同時還包括cached的記憶體(其實還包括buffers的記憶體),
cached和buffers都屬于快取,它們的區別主要在于cached主要用來緩沖頻繁讀取的檔案,它可以直接記憶我們打開的檔案內容;而buffers主要用來給塊設備做的緩沖大小,只記錄檔案系統的metadata以及tracking in-flight pages資訊,比如存盤目錄里面的內容,權限等,
top工具既可以查看系統CPU使用情況,也可以查看系統記憶體使用資訊,
命令:#top
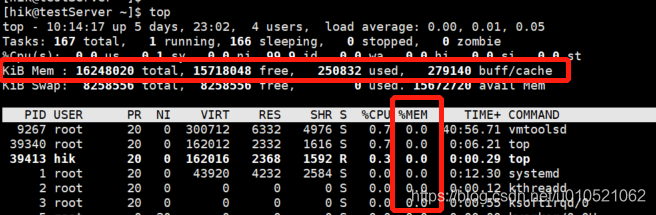
在性能測驗中,經常會用到系統已用記憶體、物理已用記憶體、系統記憶體占用率以及物理記憶體占用率這幾個指標,它們的計算公式如下:
系統已用記憶體MemUsed=MemTotal-MemFree //包含buffers和cached
物理已用記憶體-/+Used= MemTotal-MemFree-MemBuffers-MemCached
系統記憶體占用率MemUsed%=(MemUsed/ MemTotal)*100%
物理記憶體占用率-/+Used%=(-/+Used/ MemTotal)*100%
一般情況下,系統記憶體占用率<=70%,我們可以認為系統的記憶體使用情況良好,如果超出則說明系統記憶體資源緊張,
2.3 系統平均負載
當發現系統出現卡斷或者運行不順暢時,我們可以通過uptime,top或者w命令來查看系統的負載情況,
命令1:#uptime

命令2:#top
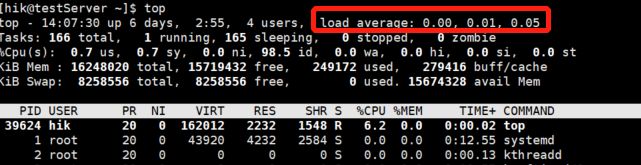
命令3:#w
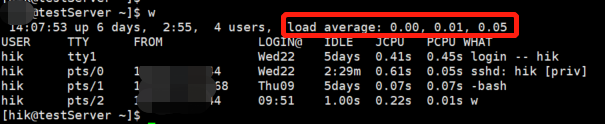
Linux的load average表示系統負載的平均值,顯示的三個數值分別表示1分鐘、5分鐘和15分鐘內的平均負載情況,這里的平均負載是指單位時間內,系統處于可運行狀態和不可中斷狀態的平均行程數,可以簡單的理解為平均負載就是系統平均活躍行程數,其中可運行狀態是指正在使用CPU或者正在等待CPU的行程(處于R狀態:Running或者Runnable的行程);不可中斷狀態的行程指的是正處于內核態關鍵流程中的行程,處于這個流程的行程是不可打斷的,比如等待硬體設備的I/O回應,
舉個例子,當平均負載的值為4:
對于只有1個CPU的系統,意味著平均有3個行程競爭不到CPU;
對于擁有4個CPU的系統,意味著CPU利用率為100%;
對于擁有8個CPU的系統,意味著CPU利用率為50%,有一半空閑,
可以看出,當系統平均負載的值如果超過系統CPU的數量時,那么系統有可能會遇到性能瓶頸,要視具體情況而定,
在性能測驗中,我們也經常會通過比較1min、5min或者15min的值,來判斷系統平均負載的變化情況:
如果1min的值大于5min或者15min的值,說明負載在增加;
如果1min的值小于5min或者15min的值,說明負載在減小;
2.4 磁盤IO
Linux服務器性能除了CPU和記憶體外,還有磁盤IO也是一種常用的性能指標,
命令:#iostat –x –k 2 3 //每隔2S輸出磁盤IO的使用情況,共采樣3次
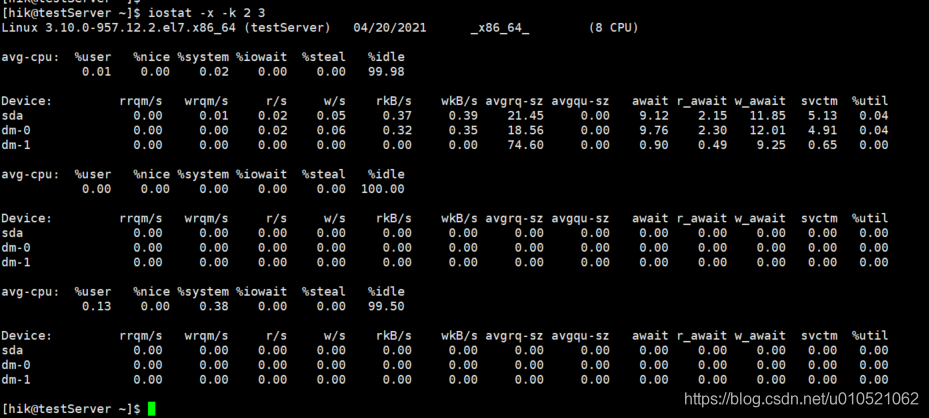
通過ll /dev/mapper命令可以查看dm-x與磁盤邏輯卷的映射關系;

欄位說明:
rrqm/s: 每秒對該設備的讀請求被合并次數,檔案系統會對讀取同塊(block)的請求進行合并;
wrqm/s: 每秒對該設備的寫請求被合并次數;
r/s: 每秒完成的讀次數;
w/s: 每秒完成的寫次數;
rkB/s: 每秒讀資料量(kB為單位);
wkB/s: 每秒寫資料量(kB為單位);
avgrq-sz:平均每次IO操作的資料量(扇區數為單位);
avgqu-sz: 平均等待處理的IO請求佇列長度;
await: 平均每次IO請求等待時間(包括等待時間和處理時間,毫秒為單位);
svctm: 平均每次IO請求的處理時間(毫秒為單位);
%util: 采用周期內用于IO操作的時間比率,即IO佇列非空的時間比率;
在性能測驗中,我們可以重點關注iowait%和%util引數,其中iowait% 表示CPU等待IO時間占整個CPU周期的百分比,如果iowait值超過50%,或者明顯大于%system、%user以及%idle,表示IO可能存在問題了;%util表示磁盤忙碌的情況,一般%util<=70%表示該磁盤IO使用狀態良好,
2.5 linux常用性能命令
2.5.1 CPU
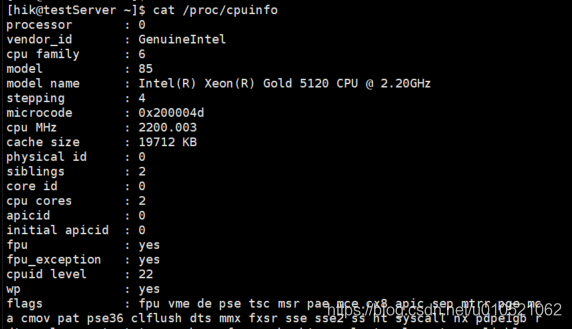
命令1: # cat /proc/cpuinfo //獲取CPU詳情
命令2: # top //包含CPU、記憶體使用等情況,常用命令
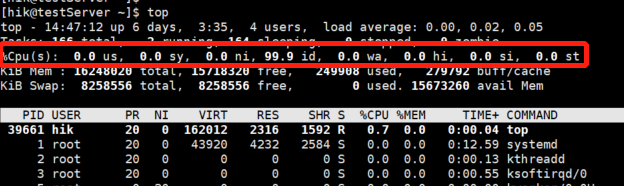
2.5.2 記憶體
命令1: # free –h

命令2:# top
2.5.3 負載
命令1:#uptime
命令2:#top
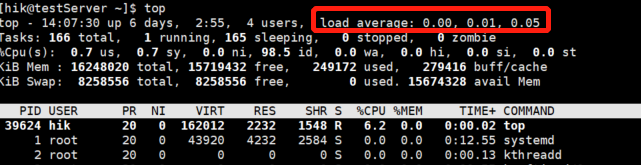
命令3:#w
2.5.4 磁盤
命令1: #fdisk –l //查看硬碟及磁區情況
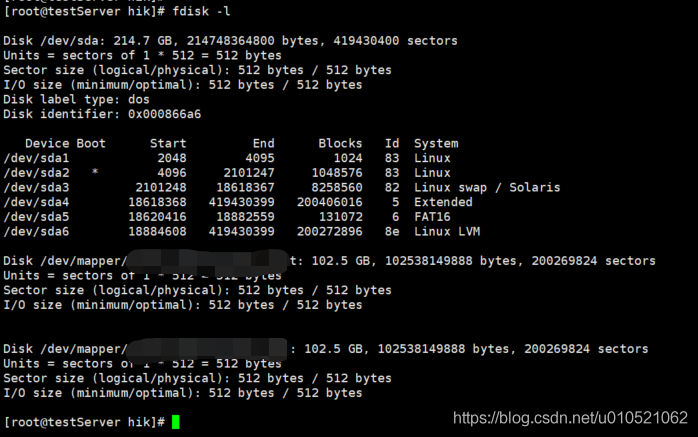
命令2:# df –h //查看檔案系統的磁盤空間使用情況
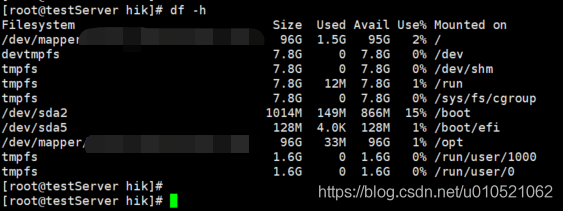
2.5.5 整體
命令:# vmstat 3 2 //每3秒一次,共2次

如果文章對你有幫助,記得點贊,收藏,加關注,會不定期分享一些干貨哦......~~~///(^v^)\\\~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278899.html
標籤:其他
上一篇:計算機網路學習:網路層IP資料報、ICMP協議 看一篇就夠了!(含具體實驗演示)
下一篇:【資料結構】線性表