目錄
- 一,線性表
- 1.基本概念
- 2.基本操作
- 【小結】
- 二,順序表
- 1.存盤結構
- 2.實作方式
- (1)靜態分配
- (2)動態分配
- (3)順序表的特點
- 3.基本操作
- (1) 初始化一個順序表
- (2)銷毀一個順序表
- (3)插入元素
- (4)洗掉元素
- (5)按位查找
- (6)按值查找
- (7)順序表輸出
- (8)增長順序表長度
- 【小結】
- 三,鏈表
- 1.存盤結構
- 2.實作方式
- (1)不帶頭結點
- (2)帶頭結點
- 3.基本操作
- (1)插入元素
- (2)洗掉元素
- (3)查找元素
- (4)求表長
- (5)列印鏈表
- (6)建立單鏈表
- 【小結】
- 【總結】
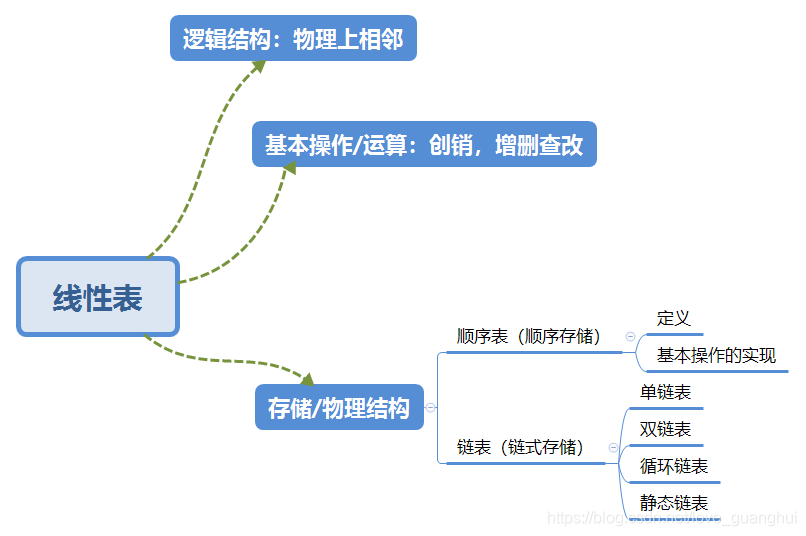
一,線性表
1.基本概念
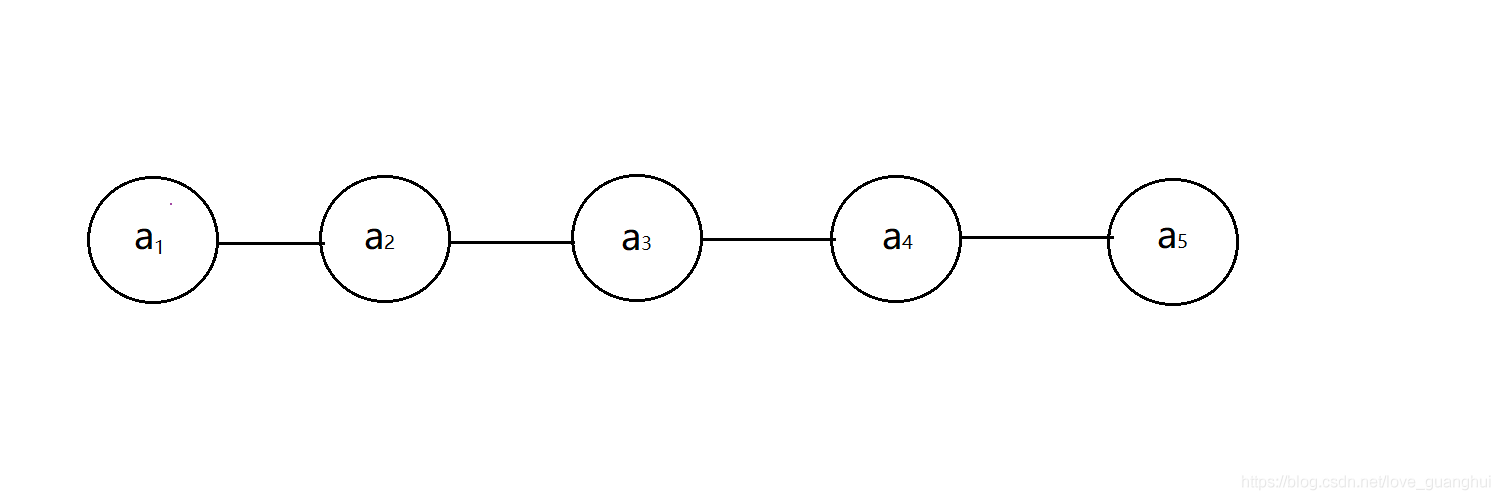
a.定義:線性表是具有相同資料型別的n個資料元素的有限序列 ,其中n位表長,當n=0是線性表是一個空表,
b.幾個概念:
·ai是線性表中的“第i個”元素線性表中的位序(注意:位序從1開始,陣列下標從0開始),
·a1是表頭元素;an是表尾元素,
·除第一個元素外,每個元素有且僅有一個前驅;除最后一個元素外,每個元素有且僅有一個后繼,
2.基本操作
InitList(&L):初始化表,構造一個空的線性表L,分配記憶體空間
DestroyList(&L):銷毀操作,銷毀線性表,并釋放線性表L所占記憶體空間
ListInsert(&L,n,e):插入操作,在第n個位置插入元素e
ListDelete(&L,n,&e):洗掉操作,洗掉表L中第n個位置元素,并用e回傳洗掉元素的值
LocateElem(&L,n):按值查找,在表L中查找指定元素n的位置
GetElem(&L,n):按位查找,獲取表L中第n個位置的元素的值
其他常用操作:
Length(L):求表長,回傳線性表L的長度,即元素個數
PrintList(L):輸出操作,按前后順序輸出線性表L的所有值
Empty(L):判空操作,若L為空表,則回傳true,否則回傳false
(1)以上函式名均可自己定義,但要有可讀性,
(2)有些用到&是需要保留修改的結構,這是傳址運算
【小結】
二,順序表
1.存盤結構
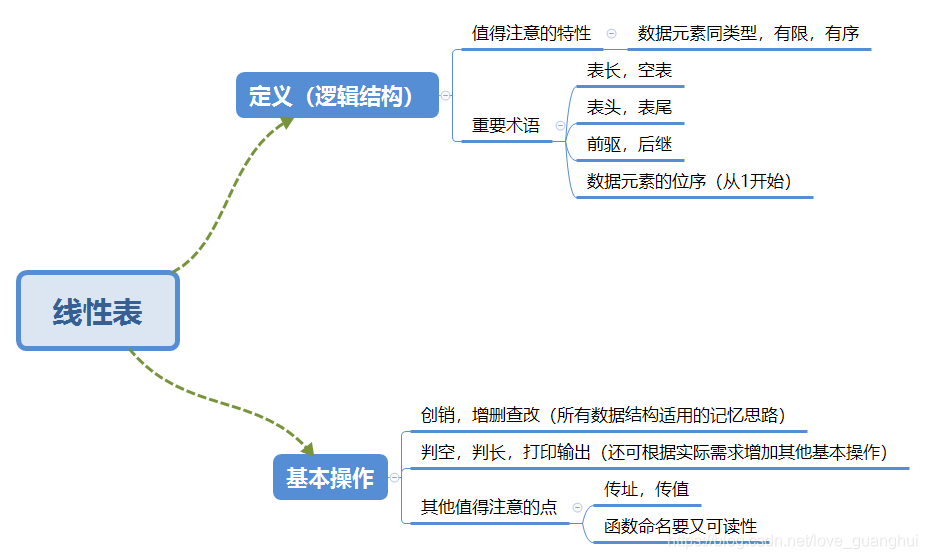
(1)定義:順序表是具有相同型別的n(n>=0)個資料元素的有限序列,
(2)順序存盤:在邏輯上相鄰的元素存盤在物理位置上也相鄰的存盤單元中,元素之間的關系又存盤單元的鄰接關系來體現,
2.實作方式
(1)靜態分配
使用“靜態陣列”實作,在定義時就已經確定了元素的個數,且大小無法被改變,
代碼實作
typedef struct SeqList
{
int data[MaxSize];//用靜態的“陣列”存放資料元素,“陣列”的具體型別根據具體需求選擇
int length;//順序表的當前長度
}SL;//順序表的型別定義
(2)動態分配
使用“動態陣列”實作,當順序表存滿時,可再用malloc動態擴展順序表的最大容量,需要將資料元素復制到新的存盤區域,并用free函式釋放原區域,
代碼實作
typedef struct SeqList
{
int* data;//指向動態分配陣列的指標
int MaxSize;//順序表的最大容量
int length;//順序表當前的長度
}SL;
(3)順序表的特點
a.隨機訪問,即可以在O(1)時間內找到第i個元素,
b.存盤密度高,每個節點只存盤資料元素,
c.擴展內容不方便(基本采用動態分配的方式實作,擴展長度的時間復雜度也比較高)
d.插入,洗掉操作不方便,需要移動大量元素,
3.基本操作
研究資料結構的基本操作一般是創建,銷毀,增刪查改,
由于代碼實作都是編者之間以int型別寫的,難免出現一些問題,可能不難保證代碼的健壯性,若讀者發現其中的問題,可以指出
(1) 初始化一個順序表
void InitList(SL* L)
{
L->data = (int*)malloc(InitSize * sizeof(int));//用malloc函式申請一片連續的存盤空間
L->length = 0;//初始化順序表長度為0
L->MaxSize = InitSize;
}
(2)銷毀一個順序表
void DestroyList(SL* L)
{
for (int i = 0; i < L->length; i++)//這一步可以省略
{
L->data[i] = 0;
}
L->length = 0;
}
(3)插入元素
值得注意的是,插入元素需將之后的元素從最后開始往后移,否則會出現資料覆寫的現象,
bool ListInsert(SL* L, int n, int e)//在第n個位置插入e
{
if (n > L->length + 1)//n如果超出順序表當前長度則非法
{
return false;
}
for (int i = L->length; i >= n; i--)//從后往前依次把資料后移
{
L->data[i] = L->data[i - 1];
}
L->data[n - 1] = e;//在第n個位置插入e
L->length++;//L當前長度+1
return true;
}
(4)洗掉元素
而洗掉元素應將之后的元素從前開始前移,
bool ListDelete(SL* L, int n, int* e)//洗掉第n個位置的元素e
{
if (n < 0 || n > L->length + 1)
{
return false;
}
*e = L->data[n - 1];//把第n個位置的元素賦值給e
for (int i = n - 1; i < L->length; i++)
{
L->data[i] = L->data[i + 1];
}
L->length--;//順序表當前的長度-1
return true;
}
(5)按位查找
int GetElem(SL* L, int n)//得到第n個位置的元素(按位查找)
{
return L->data[n - 1];
}
(6)按值查找
int LocateElem(SL* L, int n)//得到順序表中值位n的元素的下標
{
for (int i = 0; i < L->length; i++)
{
if (L->data[i] == n)
{
return i;
}
}
return -1;//找不到則回傳-1
}
(7)順序表輸出
void PrintList(SL* L)
{
for (int i = 0; i < L->length; i++)
{
printf("%d ", L->data[i]);
}
}
(8)增長順序表長度
void IncreaseList(SL* L, int len)//增長順序表的長度
{
int* p = L->data;
L->data = (int*)malloc((L->MaxSize + len) * sizeof(int));
for (int i = 0; i < L->length; i++)//將原始資料拷貝到新區域
{
L->data[i] = p[i];
}
free(p);//釋放掉原來的記憶體空間
}
【小結】
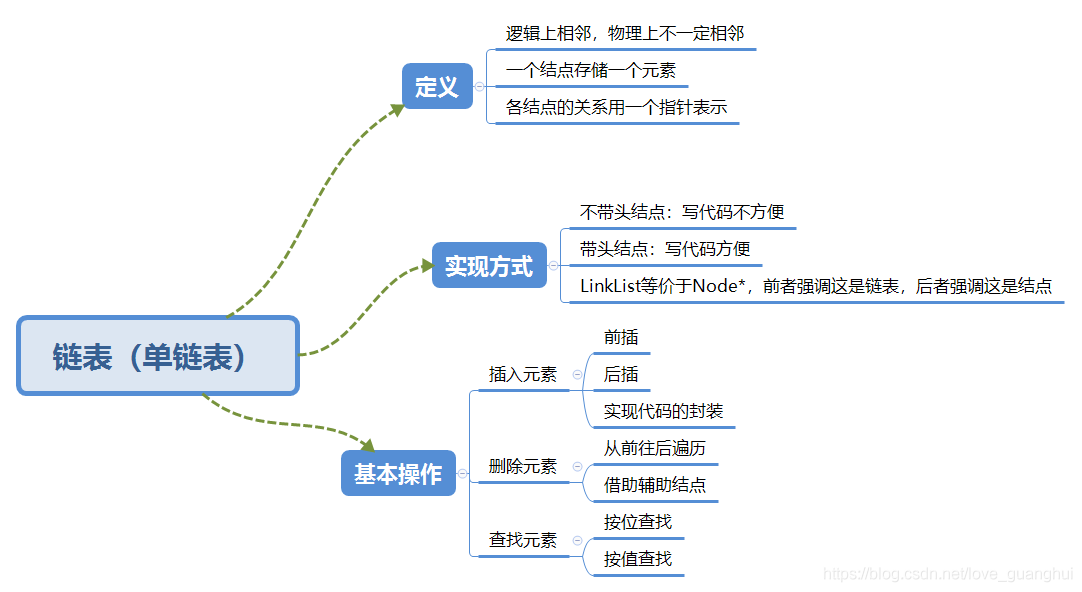
三,鏈表
1.存盤結構
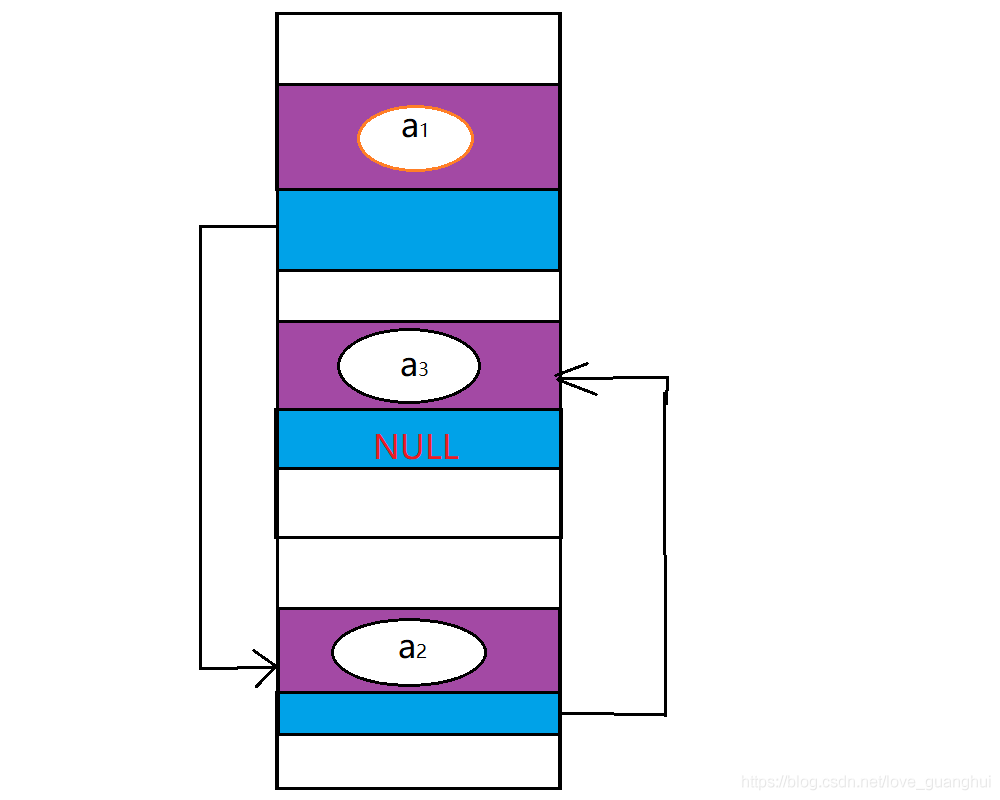
邏輯上相鄰,物理上不一定相鄰,拿單鏈表來說,每個節點除了存放資料元素外,還要存盤指向下一個節點的指標,
2.實作方式
由于作者的精力有限,以下均是單鏈表的實作,雙鏈表讀者可以自己參考撰寫,
鏈表的實作有兩種,一種是帶頭節點,另一種是不帶頭節點,由于不帶頭節點的鏈表在寫代碼時不方便,故不多作分析,
(1)不帶頭結點
typedef struct LNode//定義一個結點
{
int data;//資料域,存放該節點的資料元素
struct LNode* next;//指標域,指向下一個結點
}Node,*LinkList;//Node表示一個結點;LinkList作為指標指向單鏈表
bool InitList(LinkList L)//創建一個單鏈表(不帶頭結點)
{
L = NULL;//空表,暫時還沒有任何結點(防止臟資料)
return true;
}
(2)帶頭結點
typedef struct LNode//定義一個結點
{
int data;//資料域,存放該結點的資料元素
struct LNode* next;//指標域,指向下一個結點
}Node,*LinkList;//Node表示一個結點;LinkList作為指標指向單鏈表
bool InitList(LinkList L)//初始化一個單鏈表(帶頭結點)
{
//L = (Node*)malloc(sizeof(Node));//分配一個頭結點,頭結點不存盤資料
if (L == NULL)
{
return false;//記憶體不足,分配失敗
}
L->data = 0;
L->next = NULL;//頭節點之后還沒有結點
return true;
}
注意這里Node和LinkList的表達,Node(結構體型別)強調一個節點,LinkList(結構體指標型別)則強調單鏈表,這對于看代碼,理解代碼來說很重要,
3.基本操作
(1)插入元素
bool ListInsert(LinkList L, int i, int e)
{
if (i < 1)
{
return false;
}
/*if (i == 1)//對于不帶頭結點的單鏈表,插入第一個結點需要額外的操作處理
{
Node* s = (Node*)malloc(sizeof(Node));
s->data = e;
s->next = L;
L = s;//修改頭指標指向新的結點,同時后續的j=1,表示當前節點是第一個結點
return true;
}*/
Node* p = L;//指標p指向當前掃描到的結點
int j = 0;//記錄p當前掃描到第j個結點,虛構L頭結點為第0個結點
while (p != NULL && j < i - 1)//回圈找到第i-1個結點
{
p = p->next;
j++;
}
if (p == NULL)//i值不合法
{
return false;
}
//Node* s = (Node*)malloc(sizeof(Node));
//s->data = e;
//s->next = p->next;
//p->next = s;//將節點s連到p之后
//return true;//插入成功
InsertNextNode(p, e);//函式嵌套使用
}
bool InsertNextNode(Node* p, int e)//后插操作:在指定結點后插入元素e
{
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL)//記憶體已滿,分配失敗
{
return false;
}
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
bool InsertPriorNode(Node* p, int e)//前插操作:在指定結點前插入元素e
{
Node* s = (Node*)malloc(sizeof(Node));
if (s == NULL)
{
return false;
}
s->data = p->data;
s->next = p->next;
p->data = e;
p->next = s;
return true;
}
這里強調一下前插操作,由于是單鏈表,不能訪問特定結點之前的結點,故需要創建一個指標s作為結點p的復制品,而將要插入的元素賦值給p的資料域,用一張圖來理解一下
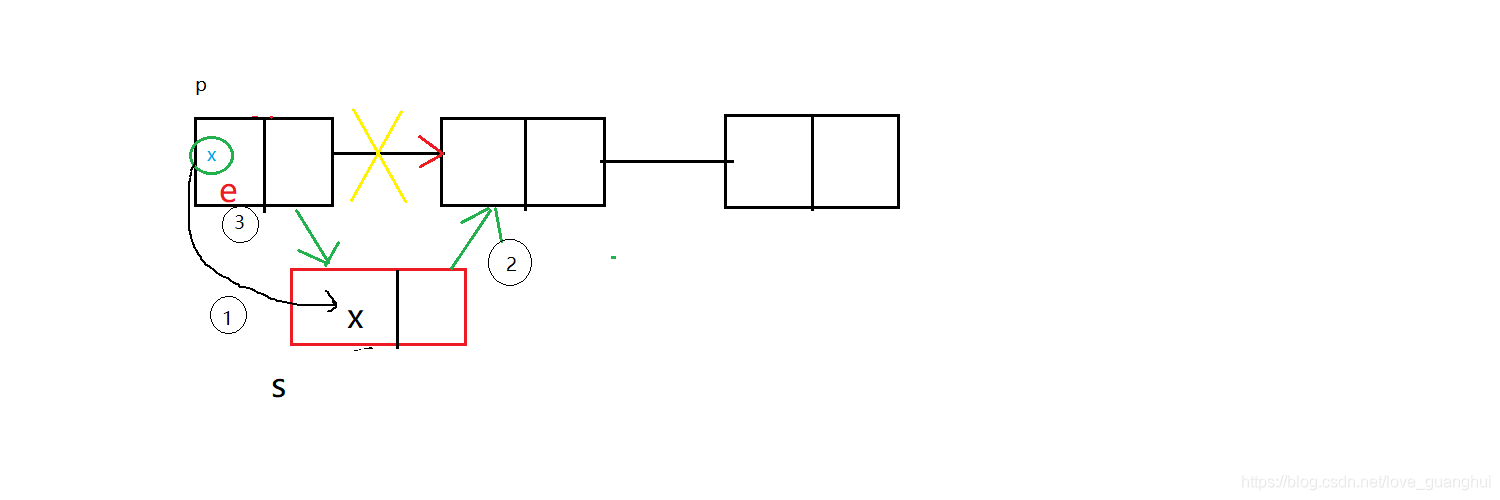
(2)洗掉元素
鏈表的洗掉操作相對比較容易,只需找到要洗掉的結點,讓它前一個結點的next指標指向它后一個結點,再將這個結點的記憶體釋放即可,
bool ListDelete(LinkList L, int i, int* e)
{
if (i < 1)
{
return false;
}
Node* p =L;
int j = 0;
while (p != NULL && j < i - 1)
{
p = p->next;
j++;
}
if (p == NULL)
{
return false;
}
//Node* q = (Node*)malloc(sizeof(Node));
//q = p->next;//q指向要洗掉的結點
//*e = q->data;
//p->next = q->next;
//free(q);
//return true;
DeleteNode(p);
}
bool DeleteNode(Node* p)//洗掉指定結點p
{
if (p == NULL)
{
return false;
}
Node* q = p->next;
p->data = q->data;//局限性:不能洗掉尾結點,p為最后一個結點時,q為NULL
p->next = q->next;
free(q);
return true;
}
同樣對于洗掉特定結點p時,需要將p后的結點拷貝到p上,再釋放p后一個結點,這是單鏈表的局限性,且無法對鏈表最后一個元素進行操作,
(3)查找元素
回傳所找到的第一個結點
a.按位查找
Node* GetElem(LinkList L, int i)//按位查找
{
if (i < 0)
{
return NULL;
}
Node* p = L;
int j = 0;
while (L != NULL && j < i)//回圈找到第i個結點
{
p = p->next;
j++;
}
return p;
}
b.按值查找
Node* LocateNode(LinkList L, int e)//按值查找
{
Node* p = L->next;
while (p->data != e && p != NULL)
{
p = p->next;
}
return p;
}
(4)求表長
int Length(LinkList L)
{
Node* p = L->next;
int len = 0;
while (p != NULL)
{
p = p->next;
len++;
}
return len;
}
(5)列印鏈表
void PrintList(LinkList L)
{
Node* p = L->next;
while (p != NULL)
{
printf("%d ", p->data);
p = p->next;
}
}
(6)建立單鏈表
a.尾插法建立單鏈表
LinkList List_TailInsert(LinkList L)//每次在表尾插入一個元素
{
L->next = NULL;
int x = 0;//要插入的元素
Node* s, * r = L;
scanf("%d", &x);
while (x != -1)//這里的-1時隨便取的,你可以按自己喜好取
{ //設定一個指標始終指向表尾,這樣尾插時不需要遍歷整個鏈表
s = (Node*)malloc(sizeof(Node));//這樣可以減少時間復雜度
s->data = x;
r->next = s;
r = s;
scanf("%d", &x);
}
r->next = NULL;
return L;
}
b.頭插法建立單鏈表
LinkList List_HeadInsert(LinkList L)//每次在表頭插入一個元素
{
int x = 0;
L->next = NULL;
Node* s;
scanf("%d", &x);
while (x != -1)
{
s = (Node*)malloc(sizeof(Node));
s->data = x;
s->next = L->next;
L->next = s;
scanf("%d", &x);
}
return L;
}
注意到頭插法建立的單鏈表的元素與輸入的元素順序相反,這點可以用于鏈表逆置,下面給出代碼:
LinkList List_Reverse(LinkList L)
{
Node* p = (Node*)malloc(sizeof(Node));//將p指標所指結點頭插方式插入表頭
Node* q = (Node*)malloc(sizeof(Node));//q指標始終指向p所指結點的下一個結點
p = L->next;
L->next = NULL;
while (p)//根據頭插法思想,不斷將鏈表逆置
{
q = p->next;
p->next = L->next;
L->next = p;
p = q;
}
return L;
}
【小結】
【總結】
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278900.html
標籤:其他
上一篇:【性能測驗】性能測驗之性能測驗指標詳解(系統指標、CPU、記憶體、負載、磁盤------全網最詳細,值得收藏!)