- 案例背景
- 案例分析
- MySQL 主從結構
- 案例解答
- 總結
案例背景
假設你公司面臨雙 11 大促,投入了大量營銷費用用于平臺推廣,這帶來了巨大的流量,如果你是訂單系統的技術負責人,要怎么應對突如其來的讀寫流量呢?
這是一個很典型的應用場景,我想很多研發工程師會回答:通過 Redis 作為 MySQL 的快取,然后當用戶查看“訂單中心”時,通過查詢訂單快取,幫助 MySQL 抗住大部分的查詢請求,
應用快取的原則之一是保證快取命中率足夠高,不然很多請求會穿透快取,最終打到資料庫上,然而在“訂單中心”這樣的場景中,每個用戶的訂單都不同,除非全量快取資料庫訂單資訊(又會帶來架構的復雜度),不然快取的命中率依舊很低,
所以在這種場景下,快取只能作為資料庫的前置保護機制,但是還會有很多流量打到資料庫上,并且隨著用戶訂單不斷增多,請求到 MySQL 上的讀寫流量會越來越多,當單臺 MySQL 支撐不了大量的并發請求時,該怎么辦?
案例分析
互聯網大部分系統的訪問流量是讀多寫少,讀寫請求量的差距可能達到幾個數量級,就好比你在京東上的商品的瀏覽量肯定遠大于你的下單量,
所以你要考慮優化資料庫來抗住高查詢請求,首先要做的就是區分讀寫流量區,這樣才方便針對讀流量做單獨擴展,這個程序就是流量的“讀寫分離”,
讀寫分離是提升 MySQL 并發的首選方案,因為當單臺 MySQL 無法滿足要求時,就只能用多個具有相同資料的 MySQL 實體組成的集群來承擔大量的讀寫請求,
MySQL 主從結構
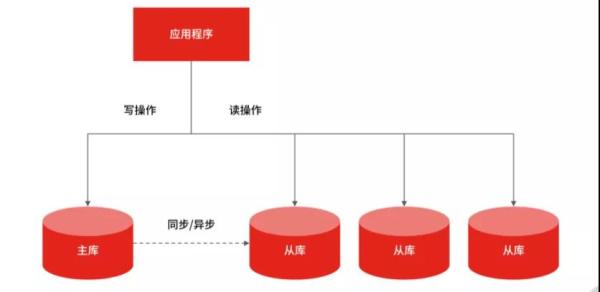
MySQL 做讀寫分離的前提,是把 MySQL 集群拆分成“主 + 從”結構的資料集群,這樣才能實作程式上的讀寫分離,并且 MySQL 集群的主庫、從庫的資料是通過主從復制實作同步的,
那么面試官會問你“MySQL 集群如何實作主從復制?” 換一種問法就是“當你提交一個事務到 MySQL 集群后,MySQL 都執行了哪些操作?”面試官往往會以該問題為切入點,挖掘你對 MySQL 集群主從復制原理的理解,然后再模擬一個業務場景,讓你給出解決主從復制問題的架構設計方案,
所以,針對面試官的套路,你要做好以下的準備:
- 掌握讀多寫少場景下的架構設計思路,知道快取不能解決所有問題,“讀寫分離”是提升系統并發能力的重要手段,
- 深入了解資料庫的主從復制,掌握它的原理、問題,以及解決方案,
- 從實踐出發,做到技術的認知抽象,從方法論層面來看設計,
案例解答
MySQL 主從復制的原理無論是“MySQL 集群如何實作主從復制”還是“當你提交一個事務到 MySQL 集群后,MySQL 集群都執行了哪些操作?”面試官主要是問你:MySQL 的主從復制的程序是怎樣的?
總的來講,MySQL 的主從復制依賴于 binlog ,也就是記錄 MySQL 上的所有變化并以二進制形式保存在磁盤上,復制的程序就是將 binlog 中的資料從主庫傳輸到從庫上,這個程序一般是異步的,也就是主庫上執行事務操作的執行緒不會等待復制 binlog 的執行緒同步完成,
為了方便你記憶,我把 MySQL 集群的主從復制程序梳理成 3 個階段,
- 寫入 Binlog:主庫寫 binlog 日志,提交事務,并更新本地存盤資料,
- 同步 Binlog:把 binlog 復制到所有從庫上,每個從庫把 binlog 寫到暫存日志中,
- 回放 Binlog:回放 binlog,并更新存盤資料,
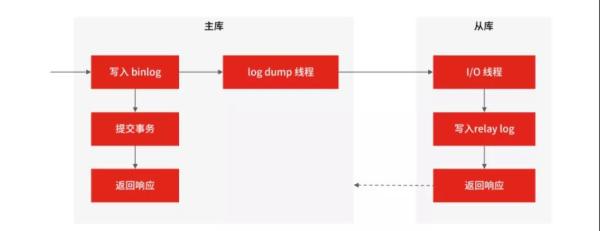
但在面試中你不能簡單地只講這幾個階段,要盡可能詳細地說明主庫和從庫的資料同步程序,為的是讓面試官感受到你技術的扎實程度(詳細程序如下),
MySQL 主庫在收到客戶端提交事務的請求之后,會先寫入 binlog,再提交事務,更新存盤引擎中的資料,事務提交完成后,回傳給客戶端“操作成功”的回應,
從庫會創建一個專門的 I/O 執行緒,連接主庫的 log dump 執行緒,來接收主庫的 binlog 日志,再把 binlog 資訊寫入 relay log 的中繼日志里,再回傳給主庫“復制成功”的回應,
從庫會創建一個用于回放 binlog 的執行緒,去讀 relay log 中繼日志,然后回放 binlog 更新存盤引擎中的資料,最終實作主從的資料一致性,
在完成主從復制之后,你就可以在寫資料時只寫主庫,在讀資料時只讀從庫,這樣即使寫請求會鎖表或者鎖記錄,也不會影響讀請求的執行,
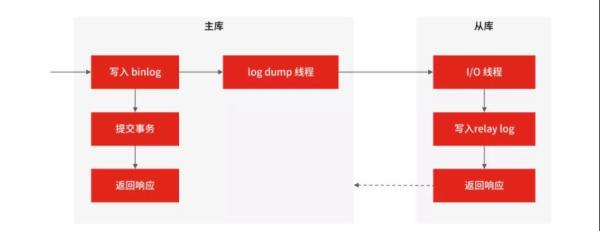
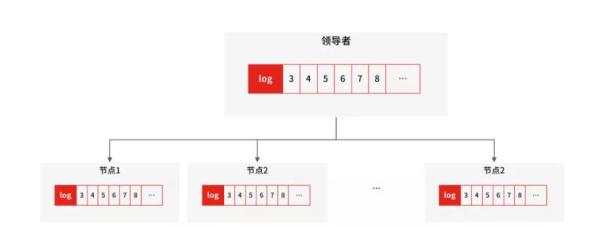
同時,在讀流量比較大時,你可以部署多個從庫共同承擔讀流量,這就是“一主多從”的部署方式,你在垂直電商專案中可以用該方式抵御較高的并發讀流量,另外,從庫也可以作為一個備庫,以避免主庫故障導致的資料丟失,
MySQL 一主多從
當然,一旦你提及“一主多從”,面試官很容易設陷阱問你:那大促流量大時,是不是只要多增加幾臺從庫,就可以抗住大促的并發讀請求了?
當然不是,
因為從庫數量增加,從庫連接上來的 I/O 執行緒也比較多,主庫也要創建同樣多的 log dump 執行緒來處理復制的請求,對主庫資源消耗比較高,同時還受限于主庫的網路帶寬,所以在實際使用中,一個主庫一般跟 2~3 個從庫(1 套資料庫,1 主 2 從 1 備主),這就是一主多從的 MySQL 集群結構,
其實,你從 MySQL 主從復制程序也能發現,MySQL 默認是異步模式:MySQL 主庫提交事務的執行緒并不會等待 binlog 同步到各從庫,就回傳客戶端結果,這種模式一旦主庫宕機,資料就會發生丟失,
而這時,面試官一般會追問你“MySQL 主從復制還有哪些模型?”主要有三種,
- 同步復制:事務執行緒要等待所有從庫的復制成功回應,
- 異步復制:事務執行緒完全不等待從庫的復制成功回應,
- 半同步復制:MySQL 5.7 版本之后增加的一種復制方式,介于兩者之間,事務執行緒不用等待所有的從庫復制成功回應,只要一部分復制成功回應回來就行,比如一主二從的集群,只要資料成功復制到任意一個從庫上,主庫的事務執行緒就可以回傳給客戶端,
這種半同步復制的方式,兼顧了異步復制和同步復制的優點,即使出現主庫宕機,至少還有一個從庫有最新的資料,不存在資料丟失的風險,
講到這兒,你基本掌握了 MySQL 主從復制的原理,但如果面試官想挖掘你的架構設計能力,還會從架構設計上考察你怎么解決 MySQL 主從復制延遲的問題,比如問你“在系統設計上有哪些方案可以解決主從復制的延遲問題?”
從架構上解決主從復制延遲
我們來結合實際案例設計一個主從復制延遲的解決方案,
在電商平臺,每次用戶發布商品評論時,都會先呼叫評論審核,目的是對用戶發布的商品評論進行如言論監控、圖片鑒黃等操作,
評論在更新完主庫后,商品發布模塊會異步呼叫審核模塊,并把評論 ID 傳遞給審核模塊,然后再由評論審核模塊用評論 ID 查詢從庫中獲取到完整的評論資訊,此時如果主從資料庫存在延遲,在從庫中就會獲取不到評論資訊,整個流程就會出現例外,

主從延遲影響評論讀取的實時性
這是主從復制延遲導致的查詢例外,解決思路有很多,我提供給你幾個方案,
使用資料冗余
可以在異步呼叫審核模塊時,不僅僅發送商品 ID,而是發送審核模塊需要的所有評論資訊,借此避免在從庫中重新查詢資料(這個方案簡單易實作,推薦你選擇),但你要注意每次呼叫的引數大小,過大的訊息會占用網路帶寬和通信時間,
使用快取解決
可以在寫入資料主庫的同時,把評論資料寫到 Redis 快取里,這樣其他執行緒再獲取評論資訊時會優先查詢快取,也可以保證資料的一致性,
不過這種方式會帶來快取和資料庫的一致性問題,比如兩個執行緒同時更新資料,操作步驟如下:
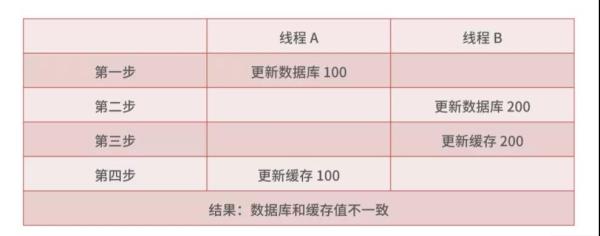
執行緒 A 先更新資料庫為 100,此時執行緒 B 把資料庫和快取中的資料都更新成了 200,然后執行緒 A 又把快取更新為 100,這樣資料庫中的值 200 和快取中的值 100 就不一致了,
總的來說,通過快取解決 MySQL 主從復制延遲時,會出現資料庫與快取資料不一致的情況,
直接查詢主庫
該方案在使用時一定要謹慎,你要提前明確查詢的資料量不大,不然會出現主庫寫請求鎖行,影響讀請求的執行,最終對主庫造成比較大的壓力,
當然了,面試官除了從架構上考察你對 MySQL主從復制延遲的理解,還會問你一些擴展問題,比如:當 MySQL 做了主從分離后,對于資料庫的使用方式就發生了變化,以前只需要使用一個資料庫地址操作資料庫,現在卻要使用一個主庫地址和多個從庫地址,并且還要區分寫入操作和查詢操作,那從工程代碼上設計,怎么實作主庫和從庫的資料訪問呢?
實作主庫和從庫的資料庫訪問
一種簡單的做法是:提前把所有資料源配置在工程中,每個資料源對應一個主庫或者從庫,然后改造代碼,在代碼邏輯中進行判斷,將 SQL 陳述句發送給某一個指定的資料源來處理,
這個方案簡單易實作,但 SQL 路由規則侵入代碼邏輯,在復雜的工程中不利于代碼的維護,
另一個做法是:獨立部署的代理中間件,如 MyCat,這一類中間件部署在獨立的服務器上,一般使用標準的 MySQL 通信協議,可以代理多個資料庫,
該方案的優點是隔離底層資料庫與上層應用的訪問復雜度,比較適合有獨立運維團隊的公司選型;缺陷是所有的 SQL 陳述句都要跨兩次網路傳輸,有一定的性能損耗,再就是運維中間件是一個專業且復雜的作業,需要一定的技術沉淀,
總結
我們先從一個案例出發,了解了在互聯網流量讀多寫少的情況下,需要通過“讀寫分離”提升系統的并發能力,又因為“讀寫分離”的前提是做 “主+從”的資料集群架構,所以我們又講了主從復制的原理,以及怎么解決主從復制帶來的延遲,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279227.html
標籤:其他
上一篇:基于RV1126平臺imx291分析 --- 運行設備(VIDIOC_STREAMON)
下一篇:谷粒商城專案簡介