攝像頭與電腦的連接
首先,你需要獲得hikvision攝像頭的密碼以及用戶名(不知道的可以去打客服電話進行咨詢),這里不做介紹;
其次,將電腦的ip設定與hikvision同頻段,一般來說,海康威視的ip為192.168.1.64,電腦設定如下:
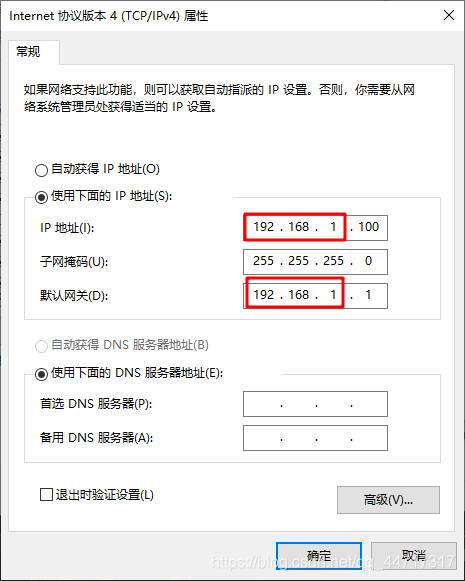
最后,使用IE瀏覽器(其他可能不支持),輸入ip:192.168.1.64并登陸
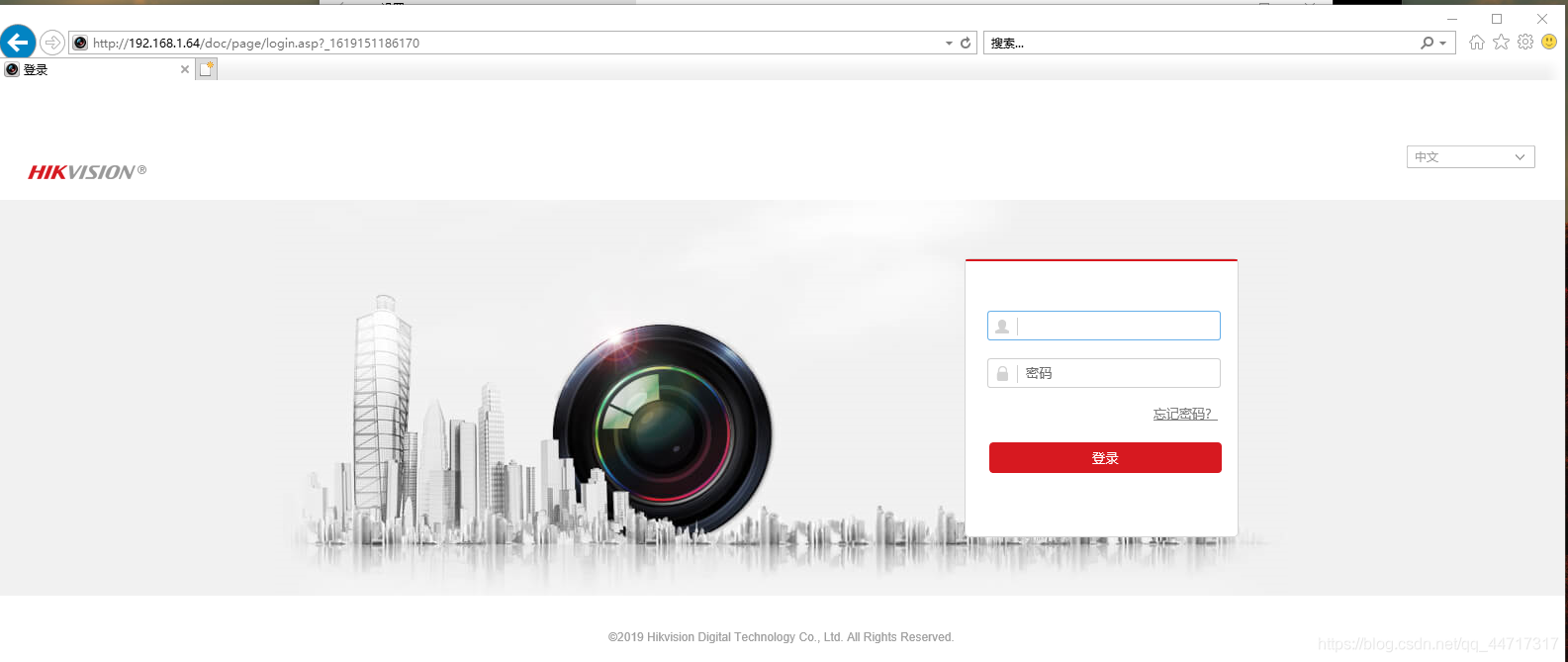
輸入用戶名和密碼即可獲取視頻畫面(可以觀察到,視頻有畸變)

使用python+openCV獲取監控畫面
在使用openCV獲取監控畫面,具體代碼如下
url格式為:“rtsp://用戶名(一般默認admin):密碼@網路IP(海康威視一般為:192.168.1.64)/Streaming/Channels/1”
import cv2
url = "rtsp://admin:*******@192.168.1.64/Streaming/Channels/1"
cap = cv2.VideoCapture(url)
ret, frame = cap.read()
while ret:
# 讀取視頻幀
ret, frame = cap.read()
# 顯示視頻幀
cv2.imshow("frame", frame)
#等候1ms,播放下一幀,或者按q鍵退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
#釋放視頻流
cap.release()
#關閉所有視窗
cv2.destroyAllWindows()
輸出畫面默認是1080P的高清畫面,我們可以寫一個resize方法,等比例縮為720P的畫面,代碼實作如下:
def img_resize(image):
height, width = image.shape[0], image.shape[1]
# 設定新的圖片解析度框架 640x369 1280×720 1920×1080
width_new = 1280
height_new = 720
# 判斷圖片的長寬比率
if width / height >= width_new / height_new:
img_new = cv2.resize(image, (width_new, int(height * width_new / width)))
else:
img_new = cv2.resize(image, (int(width * height_new / height), height_new))
return img_new
然后在顯示之前呼叫該函式進行處理:
# 讀取視頻幀
ret, frame = cap.read()
# 顯示視頻幀
img_new = img_resize(frame)
cv2.imshow("frame", img_new)
#等候1ms,播放下一幀,或者按q鍵退出
實作效果如下:

使用模型處理影像發生記憶體溢位與高延遲問題解決
我的畢業設計主要使用YOLOv3+deep-sort實作目標檢測與實時跟蹤,在這里不做詳細的理論介紹,以及具體代碼的實作,后面會有相關的博客進行專門系統性的講述,這里主要講一種處理記憶體溢位或者高延遲問題的有效解決方案,在使用模型處理影像之后,每次將處理的畫面顯示出來,只有三秒的時間(下面為處理后的畫面)
然后隨后就會發生記憶體溢位的現象,報錯內容如下:

但是,當我使用電腦默認的攝像頭,就發現非常的流暢,沒有記憶體溢位的現象,這就十分的詭異,然后我猜測是不是因呼叫rtsp視頻流或取得沒幀的解析度多大,導致檢測速度過慢,引起傳入幀數與處理幀數不對等引起的記憶體的溢位,但是我嘗試減小了解析度,甚至于獲取的幀影像大小比電腦內置攝像頭還有小,結果沒有任何的改善;
解決這個問題也尋求網上很多解決方案,以下具體結合各位前輩做一下總結:
使用多執行緒解決:
首先,需要思考,為什么會造成這種現象?有大佬給出這樣的解決方案:

FFMPEG Lib對在rtsp協議中的H264 videos不支持?
維基百科:
實時流協議(Real Time Streaming Protocol,RTSP)是一種網路應用協議,專為娛樂和通信系統的使用,以控制流媒體服務器,該協議用于創建和控制終端之間的媒體會話,媒體服務器的客戶端發布VCR命令,例如播放,錄制和暫停,以便于實時控制從服務器到客戶端(視頻點播)或從客戶端到服務器(語音錄音)的媒體流,
FFmpeg 是一個開放源代碼的自由軟體,可以運行音頻和視頻多種格式的錄影、轉換、流功能[1],包含了libavcodec——這是一個用于多個專案中音頻和視頻的解碼器庫,以及libavformat——一個音頻與視頻格式轉換庫,
這個專案最初是由法國程式員法布里斯·貝拉(Fabrice Bellard)發起的,而現在是由邁克爾·尼德梅爾(Michael Niedermayer)在進行維護,許多FFmpeg的開發者同時也是MPlayer專案的成員,FFmpeg在MPlayer專案中是被設計為服務器版本進行開發,
2011年3月13日,FFmpeg部分開發人士決定另組Libav,同時制定了一套關于專案繼續發展和維護的規則
不管怎么說,就是不支持的意思,就是無法實作,我嘗試了這位博主的方法,然而并沒有解決的問題,效果還是原來的效果,還是三秒,真就是三秒啊~
參考博客:解決Python OpenCV 讀取IP攝像頭(RTSP等)出現error while decoding的問題
博主代碼實作如下:
import cv2
import queue
import time
import threading
q=queue.Queue()
def Receive():
print("start Reveive")
cap = cv2.VideoCapture("rtsp://admin:admin_123@172.0.0.0")
ret, frame = cap.read()
q.put(frame)
while ret:
ret, frame = cap.read()
q.put(frame)
def Display():
print("Start Displaying")
while True:
if q.empty() !=True:
frame=q.get()
cv2.imshow("frame1", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if __name__=='__main__':
p1=threading.Thread(target=Receive)
p2 = threading.Thread(target=Display)
p1.start()
p2.start()
使用多行程
其實造成記憶體溢位,主要是由于利用opencv程式調取rtsp視頻流時,處理程式要消耗的CPU時間過于長,VideoCapture的read是按幀讀取所導致的,解決問題點在于把讀取視頻和處理視頻分開,這樣就可以消除因處理圖片所導致的延遲,
其實使用多執行緒當然也可以實作兩個動作分開進行,但是為什么幾乎沒有任何的效果呢?
原因主要是GIL的存在:
維基百科:
全域解釋器鎖(英語:Global Interpreter Lock,縮寫GIL),是計算機程式設計語言解釋器用于同步執行緒的一種機制,它使得任何時刻僅有一個執行緒在執行,[1]即便在多核心處理器上,使用 GIL 的解釋器也只允許同一時間執行一個執行緒,常見的使用 GIL 的解釋器有CPython與Ruby MRI,
在Windows上為Win thread,完全由作業系統調度執行緒的執行,一個Python解釋器行程內有一個主執行緒,以及多個用戶程式的執行執行緒,即便使用多核心CPU平臺,由于GIL的存在,也將禁止多執行緒的并行執行,
Python解釋器行程內的多執行緒是以協作多任務方式執行,當一個執行緒遇到I/O任務時,將釋放GIL,計算密集型(CPU-bound)的執行緒在執行大約100次解釋器的計步(ticks)時,將釋放GIL,計步(ticks)可粗略看作Python虛擬機的指令,計步實際上與時間片長度無關,可以通過sys.setcheckinterval()設定計步長度,
因此,選擇使用多行程
- 然后要考慮怎樣在兩個行程中傳參的問題:
- multiprocessing中有Quaue、SimpleQuaue等行程間傳參類,還有Manager這個大管家,
- Quaue這一類都是嚴格的資料結構佇列型別
- Manager比較特殊,它提供了可以在行程間傳遞的串列、字典等python原生型別
- 還要考慮怎樣才能達到處理行程可以在讀取行程中得到最新的一幀:
- 其實VideoCapture是一個天生的佇列,先進先出,如果要達到實時獲得最新幀的目的,就需要堆疊來存盤視頻幀,而不是佇列,
- 這樣的話,Quaue這一大類就都沒有可能了,肯定不能用它來傳參,
- 提到堆疊突然想到了python的串列,它的append和pop操作完全可以當”不嚴格“的堆疊來用,所以順理成章地multiprocessing.Manager.list就是最好的行程間傳參型別,
- 再就是傳參堆疊自動清理的問題,壓堆疊頻率肯定是要比出堆疊頻率高的,時間一長就會在堆疊中積累大量無法出堆疊的視頻幀,會導致程式崩潰,這就需要有一個自動清理機制:
- 設定一個傳參堆疊容量,每當達到這個容量就直接把堆疊清空,再利用gc庫手動發起一次python垃圾回收,這樣就不會導致嚴重的記憶體溢位和程式崩潰,
代碼:
import os
import cv2
import gc
from multiprocessing import Process, Manager
# 向共享緩沖堆疊中寫入資料:
def write(stack, cam, top: int) -> None:
"""
:param cam: 攝像頭引數
:param stack: Manager.list物件
:param top: 緩沖堆疊容量
:return: None
"""
print('Process to write: %s' % os.getpid())
cap = cv2.VideoCapture(cam)
while True:
_, img = cap.read()
if _:
stack.append(img)
# 每到一定容量清空一次緩沖堆疊
# 利用gc庫,手動清理記憶體垃圾,防止記憶體溢位
if len(stack) >= top:
del stack[:]
gc.collect()
# 在緩沖堆疊中讀取資料:
def read(stack) -> None:
print('Process to read: %s' % os.getpid())
while True:
if len(stack) != 0:
value = stack.pop()
# 對獲取的視頻幀解析度重處理
img_new = img_resize(value)
# 使用yolo模型處理視頻幀
yolo_img = yolo_deal(img_new)
# 顯示處理后的視頻幀
cv2.imshow("img", yolo_img)
# 將處理的視頻幀存放在檔案夾里
save_img(yolo_img)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
if __name__ == '__main__':
# 父行程創建緩沖堆疊,并傳給各個子行程:
q = Manager().list()
pw = Process(target=write, args=(q, url, 100))
pr = Process(target=read, args=(q,))
# 啟動子行程pw,寫入:
pw.start()
# 啟動子行程pr,讀取:
pr.start()
# 等待pr結束:
pr.join()
# pw行程里是死回圈,無法等待其結束,只能強行終止:
pw.terminate()
實時畫面如下:
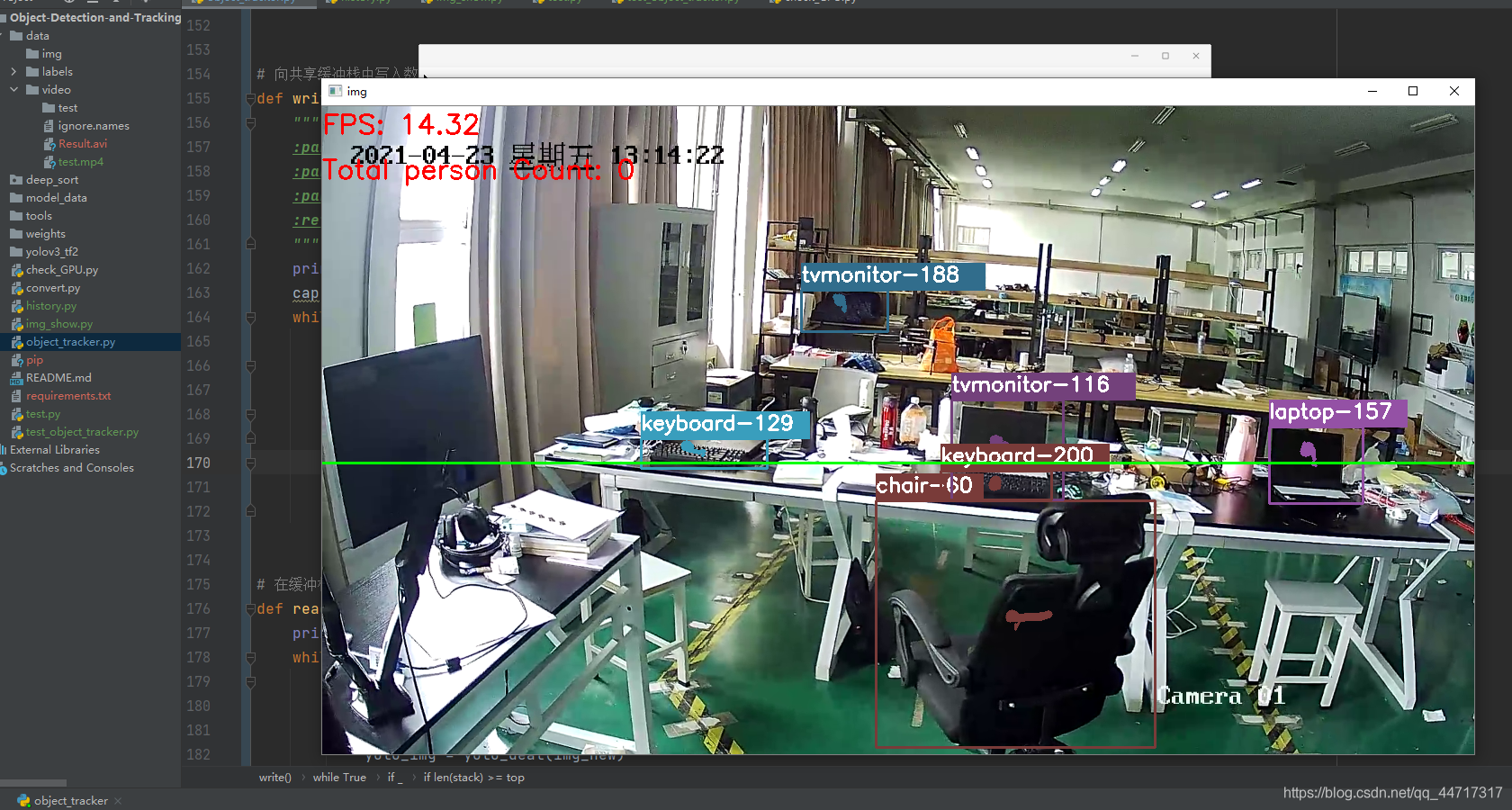
存入視頻幀:

nice!
專案實作后續系統講述…
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279844.html
標籤:其他