1.研報概述
本文是券商金工研報復現系列的第二篇,文本復現了【光大證券】的【基于阻力支撐相對強度(RSRS)的市場擇時】,
阻力位與支撐位傳統的應用方法一般是選取特定的阻力位、支撐位作為閾值來進行突破、反轉策略的構建,常見的策略如均線策略:【若當日收盤價超過 20 日均線,則建倉買入,一直持倉至收盤價低于 20 日均線,賣出平倉】,
不同于選取阻力位與支撐位閾值區間的傳統應用方法,該篇研報關注阻力位與支撐位的相對強弱程度,
阻力位與支撐位實際上反應了交易者對市場狀態頂部和底部的預期判斷,
從直覺上看,如果這種預期判斷極易改變,則表明支撐位或阻力位的強度小,有效性弱;而如果眾多交易者預期較為一致、變動不大,則表明支撐位或阻力位強度高,有效性強,
如果支撐位的強度小,作用弱于阻力位,則表明市場參與者對于支撐位的分歧大于對于阻力位的分歧,市場接下來更傾向于向熊市轉變,而如果支撐位的強度大,作用強于阻力位,則表示市場參與者對于支撐位的認可度更高于對于阻力位的認可度,市場更傾向于在牛市轉變,
我們按照不同市場狀態分類來說明支撐阻力相對強度的應用邏輯:
1.市場在上漲牛市中:
如果支撐明顯強于阻力,牛市持續,價格加速上漲
如果阻力明顯強于支撐,牛市可能即將結束,價格見頂
2.市場在震蕩中:
如果支撐明顯強于阻力,牛市可能即將啟動
如果阻力明顯強于支撐,熊市可能即將啟動
3.市場在下跌熊市中:
如果支撐明顯強于阻力,熊市可能即將結束,價格見底
如果阻力明顯強于支撐,熊市持續,價格加速下跌
該篇研報構建衡量阻力位與支撐位相對強度的指標RSRS(Resistance Support Relative Strength),當支撐位強度小,阻力位強度大時,RSRS的值較高,相反RSRS的值較低,
2.研究環境
資料源:聚寬JoinQuant,2005.6-2017.5日線資料
import datetime
import math
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import statsmodels.api as sm
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
3.研報復現
3.1量化阻力位支撐位相對強度RSRS
該研報要解決的首要問題是如何定義并量化阻力位與支撐位的相對強度,而解決該問題首先要選取一對合適的阻力位與支撐位指標,
3.1.1如何選取阻力位與支撐位
量化阻力位與支撐位相對強度的第一步,是選取合適的阻力位和支撐位指標,在技術分析學派中,已經有了許多對于支撐位與阻力位的定義,常見的包括通道線(布林帶的上下軌),一段時間內 的前高與前低,區間震蕩線(DPO)等等,
該篇研報選取每日的最高價和最低價作為阻力位和支撐位,因為每日的最高價和最低價可以迅速反應近期市場對于阻力位與支撐位態度的性質,
3.1.2RSRS構建的基本思想
本篇研報提出了多種相對強弱程度的量化方法,并且是逐層優化的關系,
這里對各自方法進行簡單的介紹,后面會給出每種量化方法構建的策略的效果,
基本思想:
這里使用最高價和最低價的相對變化速率,即類似 delta(high)/delta(low)的值來描
述支撐位與阻力位的相對強度,即最低價每變動 1 的時候,最高價變動的幅度,
基于該基本思想,原研報使用
線性回歸線的斜率
斜率標準分
修正標準分
右偏標準分
四種方法量化阻力支撐相對強弱程度,這四種方法是逐層遞進、優化的關系,
最后又結合價量資料優化策略,本文將會對每一種方法給出其計算方法和構建的策略的效果,
3.2 具體計算方法和策略效果
3.2.0 資料格式與策略統計函式
在給出具體的策略代碼之前,我們先介紹策略使用的資料格式,
在策略回測中,我們使用DataFrame格式的資料df,其不僅包含價格和RSRS指標的時間序列,還有flag和position兩列,
flag是開倉平倉標志位,df[‘flag’][i]為1時,表明第i日進行了開倉操作,df[‘flag’][i]為-1時,表明第i日進行了平倉操作,position是賬戶持倉標志位,其值為1表明當前賬戶持有證券,其值為0表明當前賬戶為空倉,
同時,本文構建的策略中,只有當前賬戶空倉時才進行買入操作,
這里,我們先給出統計策略結果的函式,后文會多次用到該函式,
def calculate_statistics(df):
'''
輸入:
DataFrame型別,包含價格資料和倉位、開平倉標志
position列:倉位標志位,0表示空倉,1表示持有標的
flag列:買入賣出標志位,1表示在該時刻買入,-1表示在該時刻賣出
close列:日收盤價
輸出:dict型別,包含夏普比率、最大回撤等策略結果的統計資料
'''
#凈值序列
df['net_asset_pct_chg'] = df.net_asset_value.pct_change(1).fillna(0)
#總收益率與年化收益率
total_return = (df['net_asset_value'][df.shape[0]-1] -1)
annual_return = (total_return)**(1/(df.shape[0]/252)) -1
total_return = total_return*100
annual_return = annual_return*100
#夏普比率
df['ex_pct_chg'] = df['net_asset_pct_chg']
sharp_ratio = df['ex_pct_chg'].mean() * math.sqrt(252)/df['ex_pct_chg'].std()
#回撤
df['high_level'] = (
df['net_asset_value'].rolling(
min_periods=1, window=len(df), center=False).max()
)
df['draw_down'] = df['net_asset_value'] - df['high_level']
df['draw_down_percent'] = df["draw_down"] / df["high_level"] * 100
max_draw_down = df["draw_down"].min()
max_draw_percent = df["draw_down_percent"].min()
#持倉總天數
hold_days = df['position'].sum()
#交易次數
trade_count = df[df['flag']!=0].shape[0]/2
#平均持倉天數
avg_hold_days = int(hold_days/trade_count)
#獲利天數
profit_days = df[df['net_asset_pct_chg'] > 0].shape[0]
#虧損天數
loss_days = df[df['net_asset_pct_chg'] < 0].shape[0]
#勝率(按天)
winrate_by_day = profit_days/(profit_days+loss_days)*100
#平均盈利率(按天)
avg_profit_rate_day = df[df['net_asset_pct_chg'] > 0]['net_asset_pct_chg'].mean()*100
#平均虧損率(按天)
avg_loss_rate_day = df[df['net_asset_pct_chg'] < 0]['net_asset_pct_chg'].mean()*100
#平均盈虧比(按天)
avg_profit_loss_ratio_day = avg_profit_rate_day/abs(avg_loss_rate_day)
#每一次交易情況
buy_trades = df[df['flag']==1].reset_index()
sell_trades = df[df['flag']==-1].reset_index()
result_by_trade = {
'buy':buy_trades['close'],
'sell':sell_trades['close'],
'pct_chg':(sell_trades['close']-buy_trades['close'])/buy_trades['close']
}
result_by_trade = pd.DataFrame(result_by_trade)
#盈利次數
profit_trades = result_by_trade[result_by_trade['pct_chg']>0].shape[0]
#虧損次數
loss_trades = result_by_trade[result_by_trade['pct_chg']<0].shape[0]
#單次最大盈利
max_profit_trade = result_by_trade['pct_chg'].max()*100
#單次最大虧損
max_loss_trade = result_by_trade['pct_chg'].min()*100
#勝率(按次)
winrate_by_trade = profit_trades/(profit_trades+loss_trades)*100
#平均盈利率(按次)
avg_profit_rate_trade = result_by_trade[result_by_trade['pct_chg'] > 0]['pct_chg'].mean()*100
#平均虧損率(按次)
avg_loss_rate_trade = result_by_trade[result_by_trade['pct_chg'] < 0]['pct_chg'].mean()*100
#平均盈虧比(按次)
avg_profit_loss_ratio_trade = avg_profit_rate_trade/abs(avg_loss_rate_trade)
statistics_result = {
'net_asset_value':df['net_asset_value'][df.shape[0]-1],#最終凈值
'total_return':total_return,#收益率
'annual_return':annual_return,#年化收益率
'sharp_ratio':sharp_ratio,#夏普比率
'max_draw_percent':max_draw_percent,#最大回撤
'hold_days':hold_days,#持倉天數
'trade_count':trade_count,#交易次數
'avg_hold_days':avg_hold_days,#平均持倉天數
'profit_days':profit_days,#盈利天數
'loss_days':loss_days,#虧損天數
'winrate_by_day':winrate_by_day,#勝率(按天)
'avg_profit_rate_day':avg_profit_rate_day,#平均盈利率(按天)
'avg_loss_rate_day':avg_loss_rate_day,#平均虧損率(按天)
'avg_profit_loss_ratio_day':avg_profit_loss_ratio_day,#平均盈虧比(按天)
'profit_trades':profit_trades,#盈利次數
'loss_trades':loss_trades,#虧損次數
'max_profit_trade':max_profit_trade,#單次最大盈利
'max_loss_trade':max_loss_trade,#單次最大虧損
'winrate_by_trade':winrate_by_trade,#勝率(按次)
'avg_profit_rate_trade':avg_profit_rate_trade,#平均盈利率(按次)
'avg_loss_rate_trade':avg_loss_rate_trade,#平均虧損率(按次)
'avg_profit_loss_ratio_trade':avg_profit_loss_ratio_trade#平均盈虧比(按次)
}
return statistics_result
3.2.1斜率方法
因為市場上存在噪聲,所以考慮用連續N日的最高價與最低價的線性回歸模型的斜率來量化支撐位與阻力位的相對強度,以求增加信噪比,
即,取連續N日的最高價與最低價的線性回歸模型
high = alpha + beta*low
中的beta,即直線的斜率,作為我們的相對強度RSRS,
斜率指標計算方法:
- 取前 N 日的最高價序列與最低價序列,
- 將兩列資料按式(1)的模型進行 OLS 線性回歸,
- 將擬合后的 beta 值作為當日 RSRS 斜率指標值,
在原研報中,經過對N的不同取值的比較,N取18時,量化出的指標構建的策略更有效,
基于斜率方法,構建策略:
- 計算 RSRS 斜率,
- 如果斜率大于 1,則買入持有,
- 如果斜率小于 0.8,則賣出手中持股平倉,
策略源代碼
#當日斜率指標計算方式,線性回歸
def cal_nbeta(df,n):
nbeta = []
trade_days = len(df.index)
df['position'] = 0
df['flag'] = 0
position = 0
#計算斜率值
for i in range(trade_days):
if i < (n-1):
#n-1為配合接下來用iloc索引
continue
else:
x = df['low'].iloc[i-n+1:i+1]
#iloc左閉右開
x = sm.add_constant(x)
y = df['high'].iloc[i-n+1:i+1]
regr = sm.OLS(y,x)
res = regr.fit()
beta = round(res.params[1],2)#斜率指標
nbeta.append(beta)
df1 = df.iloc[n-1:]
df1['beta'] = nbeta
#執行交易策略
for i in range(len(df1.index)-1):
#此處-1是為了避免最后一行
if df1['beta'].iloc[i] > 1 and position == 0:
df1['flag'].iloc[i] = 1 #開倉標志
df1['position'].iloc[i+1] =1 #倉位不為空
position = 1
elif df1['beta'].iloc[i] < 0.8 and position == 1:
df1['flag'].iloc[i] = -1 #平倉標志
df1['position'].iloc[i+1] = 0 #倉位為空
position = 0
else:
df1['position'].iloc[i+1] = df1['position'].iloc[i]
#計算凈值序列
df1['net_asset_value'] = (1+df1.close.pct_change(1).fillna(0)*df1.position).cumprod()
return df1
策略凈值曲線
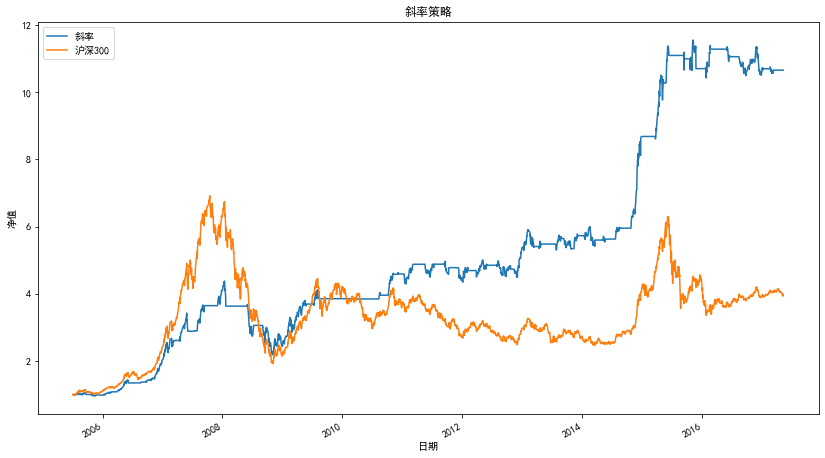
策略的統計指標
| 統計量 | 斜率策略 |
|---|---|
| 凈值 | 10.66 |
| 收益率 | 965.73% |
| 年化收益率 | 21.92% |
| 夏普比率 | 1.16 |
| 最大回撤 | -50.26% |
| 持倉天數 | 1184 |
| 交易次數 | 21 |
| 平均持倉天數 | 56 |
| 盈利天數 | 747 |
| 虧損天數 | 575 |
| 勝率(按天) | 56.51% |
| 平均盈利率(按天) | 1.31% |
| 平均虧損率(按天) | -1.25% |
| 平均盈虧比(按天) | 1.05 |
| 盈利次數 | 16 |
| 虧損次數 | 5 |
| 單次最大盈利 | 170% |
| 單次最大虧損 | -12% |
| 勝率(按次) | 76.19% |
| 平均盈利率(按次) | 25% |
| 平均虧損率(按次) | -3% |
| 平均盈虧比(按次) | 7.86 |
3.2.2斜率方法的優化——斜率標準分
使用斜率指標構建策略時,需要參考斜率指標在歷史上的均值和標準差以選擇合適的開倉、平倉閾值,
但隨時市場的變化,不同時期資料的均值與標準差可能會發生變化,同時交易者也可能更關心在當前市場在近期的環境中處在什么樣的位置,或者接下來一段時間市場相比于目前將會有怎么的發展,所以相較于直接使用斜率在整個歷史上的均值和標準差來幫助選擇閾值,根據斜率在最近一定周期內(600個交易日)的標準分確定閾值可以更加靈活地適應近期的整體市場基本狀態,
斜率標準分計算方法:
- 取前 M 日的斜率時間序列,
- 以此樣本計算當日斜率的標準分,
- 將計算得到的標準分 z 作為當日 RSRS 標準分指標值,
構建標準分策略:
1.根據斜率計算標準分(引數 N=18,M=600),
2.如果標準分大于 S(引數 S=0.7),則買入持有,
3.如果標準分小于-S,則賣出平倉,
策略源代碼
#標準分策略
def cal_stdbeta(df,n):
df['position'] = 0
df['flag'] = 0
position = 0
df1 = cal_nbeta(df,n)
pre_stdbeta = df1['beta']
pre_stdbeta = np.array(pre_stdbeta)
#轉化為陣列,可以對整個陣列進行操作
sigma = np.std(pre_stdbeta)
mu = np.mean(pre_stdbeta)
#標準化
stdbeta = (pre_stdbeta-mu)/sigma
df1['stdbeta'] = stdbeta
for i in range(len(df1.index)-1):
#此處-1是為了避免最后一行
if df1['stdbeta'].iloc[i] > 0.7 and position == 0:
df1['flag'].iloc[i] = 1
df1['position'].iloc[i+1] =1
position = 1
elif df1['stdbeta'].iloc[i] < -0.7 and position == 1:
df1['flag'].iloc[i] = -1
df1['position'].iloc[i+1] = 0
position = 0
else:
df1['position'].iloc[i+1] = df1['position'].iloc[i]
df1['net_asset_value'] = (1+df1.close.pct_change(1).fillna(0)*df1.position).cumprod()
return df1
#stdbeta是陣列 beta是串列
凈值曲線圖
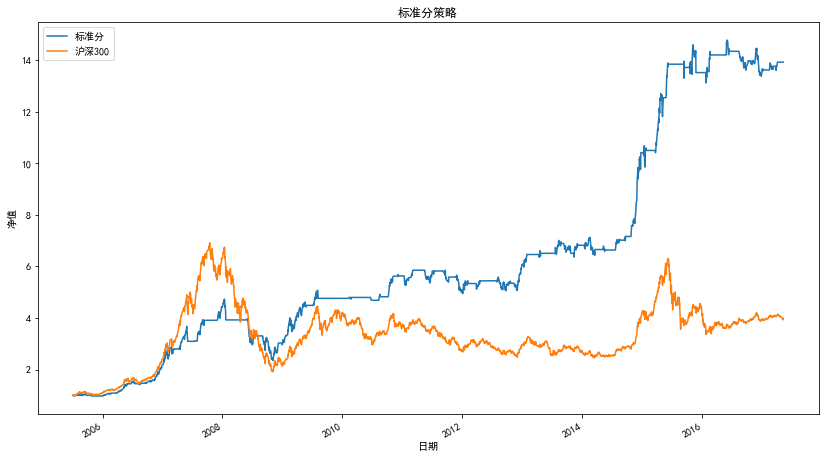
策略的統計指標
| 統計量 | 標準分策略 |
|---|---|
| 凈值 | 13.93 |
| 收益率 | 1292.70% |
| 年化收益率 | 25.07% |
| 夏普比率 | 1.28 |
| 最大回撤 | -50.26% |
| 持倉天數 | 1298 |
| 交易次數 | 67 |
| 平均持倉天數 | 19 |
| 盈利天數 | 741 |
| 虧損天數 | 557 |
| 勝率(按天) | 57.09% |
| 平均盈利率(按天) | 1.32% |
| 平均虧損率(按天) | -1.25% |
| 平均盈虧比(按天) | 1.06 |
| 盈利次數 | 40 |
| 虧損次數 | 26 |
| 單次最大盈利 | 91% |
| 單次最大虧損 | -41% |
| 勝率(按次) | 60.61% |
| 平均盈利率(按次) | 18% |
| 平均虧損率(按次) | -9% |
| 平均盈虧比(按次) | 2.05 |
3.2.3再優化——修正標準分:考慮到線性擬合的程度
使用線性回歸擬合直線的斜率或其標準分作為相對強弱程度時,可能出現斜率或標準分的絕對值很大,但直線本身的擬合效果并不好,使得斜率或斜率的標準分本身不能很好的體現出相對強弱程度的問題,需要構建相對強弱程度指標時可以考慮到線性模型擬合結果的好壞,
在線性回歸中,R 平方值(決定系數)可以理解成線性擬合效果的程度,
因此,使用
修正標準分=標準分*R 平方值(決定系數)
來量化相對強弱程度,可以削弱直線擬合效果對指標效果的影響,
構建修正標準分策略
- 計算修正標準分(N=16,M=300),
- 如果修正標準分大于 S(S=0.7),則買入持有,
- 如果修正標準分小于-S,則賣出平倉,
策略源代碼
#RSRS 標準分指標優化,修正標準分
def cal_better_stdbeta(df,n):
nbeta = []
R2 = []
trade_days = len(df.index)
for i in range(trade_days):
if i < (n-1):
#n-1為配合接下來用iloc索引
continue
else:
x = df['low'].iloc[i-n+1:i+1]
#iloc左閉右開
x = sm.add_constant(x)
y = df['high'].iloc[i-n+1:i+1]
regr = sm.OLS(y,x)
res = regr.fit()
beta = round(res.params[1],2)
R2.append(res.rsquared)
nbeta.append(beta)
prebeta = np.array(nbeta)
sigma = np.std(prebeta)
mu = np.mean(prebeta)
stdbeta = (prebeta-mu)/sigma
r2 = np.array(R2)
better_stdbeta = r2*stdbeta#修正標準分
df1 = df.iloc[n-1:]
df1['beta'] = nbeta
df1['flag'] = 0
df1['position'] = 0
position = 0
df1['better_stdbeta'] = better_stdbeta
for i in range(len(df1.index)-1):
#此處-1是為了避免最后一行
if df1['better_stdbeta'].iloc[i] > 0.7 and position == 0:
df1['flag'].iloc[i] = 1
df1['position'].iloc[i+1] =1
position = 1
elif df1['better_stdbeta'].iloc[i] < -0.7 and position == 1:
df1['flag'].iloc[i] = -1
df1['position'].iloc[i+1] = 0
position = 0
else:
df1['position'].iloc[i+1] = df1['position'].iloc[i]
df1['net_asset_value'] = (1+df1.close.pct_change(1).fillna(0)*df1.position).cumprod()
return df1
策略凈值曲線
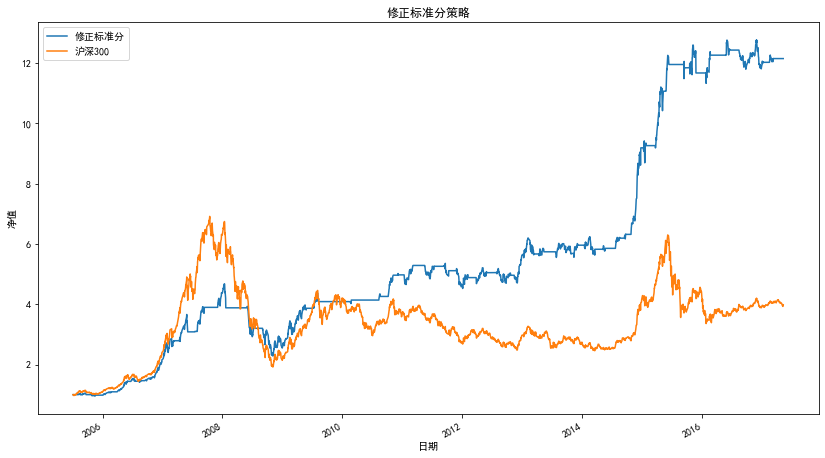
策略指標
| 量 | 修正標準分策略 |
|---|---|
| 凈值 | 12.15 |
| 收益率 | 1115.40% |
| 年化收益率 | 23.47% |
| 夏普比率 | 1.19 |
| 最大回撤 | -51.28% |
| 持倉天數 | 1397 |
| 交易次數 | 46 |
| 平均持倉天數 | 30 |
| 盈利天數 | 790 |
| 虧損天數 | 607 |
| 勝率(按天) | 56.55% |
| 平均盈利率(按天) | 1.30% |
| 平均虧損率(按天) | -1.25% |
| 平均盈虧比(按天) | 1.05 |
| 盈利次數 | 32 |
| 虧損次數 | 14 |
| 單次最大盈利 | 76% |
| 單次最大虧損 | -18% |
| 勝率(按次) | 69.57% |
| 平均盈利率(按次) | 11% |
| 平均虧損率(按次) | -3% |
| 平均盈虧比(按次) | 3.3 |
3.2.4再再優化——右偏標準分:在實踐程序中的猜想
原研報在分析比較標準分和修正標準分對后市的相關性時,發現右側(即z>0)的標準分對后市收益有較好的預測性,而左側的標準分則失去了預測性,因為左側的標準分占了整體的大部分,所以整體標準分與后市收益相關性較低,而修正標準分右側的取值范圍擴大了(相對于左側而言,并非絕對的值域),修正標準分整體上呈現了更好的預測性,
因此猜測:是否右側的取值范圍越廣(相對于左側而言,并非絕對的值域范圍),指標的預測性更好?
為了驗證該猜想,構建右偏標準分
右偏標準分=修正標準分*斜率
構建右偏標準分策略
- 計算右偏標準分(N=16,M=300),
- 如果右偏標準分大于 S(S=0.7),則買入持有,
- 如果右偏標準分小于-S,則賣出平倉,
策略源代碼
#右偏標準分 此時N取16
def cal_right_stdbeta(df,n):
df1 = cal_better_stdbeta(df,n)
df1['position'] = 0
df1['flag'] = 0
df1['net_value'] = 0
position = 0
df1['right_stdbeta'] = df1['better_stdbeta']*df1['beta']
#修正標準分與斜率值相乘能夠達到使原有分布右偏的效果
for i in range(len(df1.index)-1):
#此處-1是為了避免最后一行
if df1['right_stdbeta'].iloc[i] > 0.7 and position == 0:
df1['flag'].iloc[i] = 1
df1['position'].iloc[i+1] =1
position = 1
elif df1['right_stdbeta'].iloc[i] < -0.7 and position == 1:
df1['flag'].iloc[i] = -1
df1['position'].iloc[i+1] = 0
position = 0
else:
df1['position'].iloc[i+1] = df1['position'].iloc[i]
df1['net_asset_value'] = (1+df1.close.pct_change(1).fillna(0)*df1.position).cumprod()
return df1
凈值曲線圖
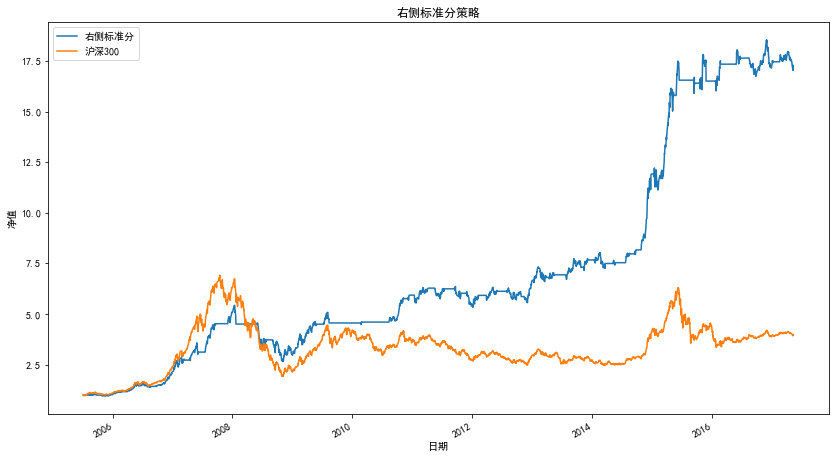
策略指標
| 統計量 | 右偏標準分 |
|---|---|
| 凈值 | 17.67 |
| 收益率 | 1667.22% |
| 年化收益率 | 27.88% |
| 夏普比率 | 1.29 |
| 最大回撤 | -51.16% |
| 持倉天數 | 1638 |
| 交易次數 | 37.5 |
| 平均持倉天數 | 43 |
| 盈利天數 | 928 |
| 虧損天數 | 710 |
| 勝率(按天) | 56.65% |
| 平均盈利率(按天) | 1.27% |
| 平均虧損率(按天) | -1.22% |
| 平均盈虧比(按天) | 1.04 |
| 盈利次數 | 26 |
| 虧損次數 | 11 |
| 單次最大盈利 | 91% |
| 單次最大虧損 | -17% |
| 勝率(按次) | 70.27% |
| 平均盈利率(按次) | 15% |
| 平均虧損率(按次) | -3% |
| 平均盈虧比(按次) | 4.6 |
3.3 結合市場狀態的優化
基于上文介紹的四種阻力支撐相對強弱程度指標RSRS構建出的交易策略都大幅度地跑贏了基準收益,但也都有一個共同的缺陷:凈值在08年股災期間都出現了大幅的回撤,
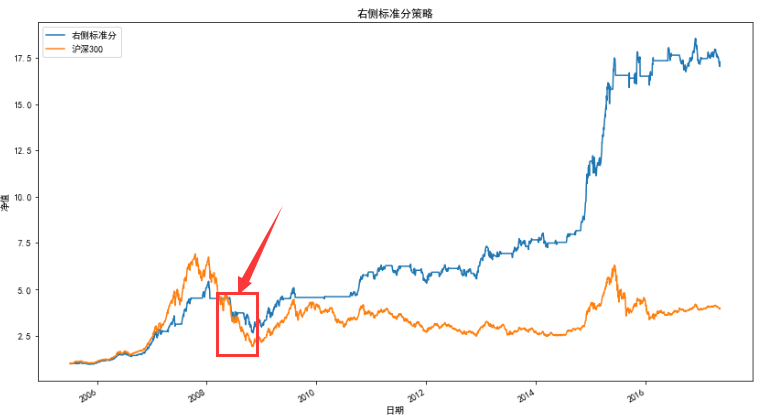
這是因為按照阻力支撐相對強弱指標的邏輯,策略大概率是在左側開倉、左側平倉,(這里的左側是指股價呈現“V”字型時的下跌階段,并不是上文討論右偏標準分時提到的左側),但當市場處在大熊市狀態時,如果開倉預測失誤,就會造成嚴重的虧損,
因此,我們期望在保證收益的同時,盡可能降低熊市錯誤開倉的幾率,
簡單的想法是:先判斷市場狀態是處在上升還是下跌趨勢,再結合RSRS構建買入、賣出策略,
3.3.1 結合均線指標的優化
有很多指標幫助我們判斷近期市場狀態,如MA,MACD等,在這里我們使用當日 20 日均線值與 3 日前 20 日均線值的相對大小來判斷近期市場狀態,
優化后的交易策略為:
1.計算 RSRS 標準分指標買賣信號,
- 如果指標發出買入信號,同時滿足前一日 MA(20)的值大于前三日MA(20)的值,則買入,
- 如果指標發出賣出信號,則賣出手中持股,
策略代碼
RSRS 指標配合價格資料優化策略
def cal_ma_beta(df,n):
df1 = cal_stdbeta(df,n)
df1['position'] = 0
df1['flag'] = 0
df1['net_asset_value'] = 0
position = 0
#beta是前17天沒有資料(n=18) ma20是前20天沒有資料
for i in range(5,len(df1.index)-1):
if df1['stdbeta'].iloc[i] > 0.7 and df1['ma20'].iloc[i-1]>df1['ma20'].iloc[i-3] and position == 0:
df1['flag'].iloc[i] = 1
df1['position'].iloc[i+1] = 1
position = 1
elif df1['stdbeta'].iloc[i] < -0.7 and df1['ma20'].iloc[i-1]<df1['ma20'].iloc[i-3] and position == 1:
df1['flag'].iloc[i] = -1
df1['position'].iloc[i+1] = 0
position = 0
else:
df1['position'].iloc[i+1] = df1['position'].iloc[i]
df1['net_asset_value'] = (1+df1.close.pct_change(1).fillna(0)*df1.position).cumprod()
return df1
凈值曲線
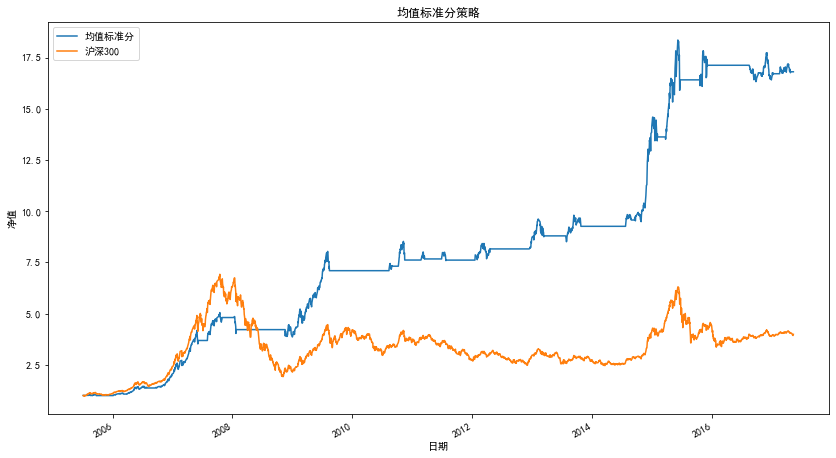
策略指標
| 統計量 | 均值優化標準分策略 |
|---|---|
| 凈值 | 16.91 |
| 收益率 | 1591.22% |
| 年化收益率 | 27.36% |
| 夏普比率 | 1.48 |
| 最大回撤 | -23.61% |
| 持倉天數 | 1638 |
| 交易次數 | 37.5 |
| 平均持倉天數 | 43 |
| 盈利天數 | 714 |
| 虧損天數 | 470 |
| 勝率(按天) | 60.30% |
| 平均盈利率(按天) | 1.24% |
| 平均虧損率(按天) | -1.24% |
| 平均盈虧比(按天) | 1 |
| 盈利次數 | 26 |
| 虧損次數 | 11 |
| 單次最大盈利 | 91% |
| 單次最大虧損 | -17% |
| 勝率(按次) | 70.27% |
| 平均盈利率(按次) | 15% |
| 平均虧損率(按次) | -3% |
| 平均盈虧比(按次) | 4.6 |
3.3.2 結合交易量相關性的優化
除卻直接從近期歷史價格來確認當下市場趨勢狀態,很多發表的研究表明市場漲跌與交易量有明顯的正相關性,借鑒類似的想法,我們嘗試用交易量與修正標準分之間的相關性來過濾誤判信號,只有在相關性為正的時刻給出的交易信號,我們才認為是合理的信號,
優化后的策略為
- 計算 RSRS 標準分指標買賣信號,
- 如果指標發出買入信號,同時滿足前 10 日交易量與修正標準分之間的相關性為正,則買入,
- 如果指標發出賣出信號,則賣出手中持股,
策略代碼
#基于 RSRS 指標與交易量相關性的優化
def cal_vol_beta(df,n):
df1 = cal_stdbeta(df,n)
df1['position'] = 0
df1['flag'] = 0
df1['net_asset_value'] = 0
position = 0
for i in range(10,len(df1.index)-1):
pre_volume = df1['volume'].iloc[i-10:i]
series_beta = df1['stdbeta'].iloc[i-10:i]
#計算相關系數需要資料為series格式
corr = series_beta.corr(pre_volume,method = 'pearson')
if df1['stdbeta'].iloc[i] > 0.7 and corr > 0 and position == 0:
df1['flag'].iloc[i] = 1
df1['position'].iloc[i+1] = 1
position = 1
elif df1['stdbeta'].iloc[i] < -0.7 and position == 1:
df1['flag'].iloc[i] = -1
df1['position'].iloc[i+1] = 0
position = 0
else:
df1['position'].iloc[i+1] = df1['position'].iloc[i]
df1['net_asset_value'] = (1+df1.close.pct_change(1).fillna(0)*df1.position).cumprod()
return df1
凈值曲線
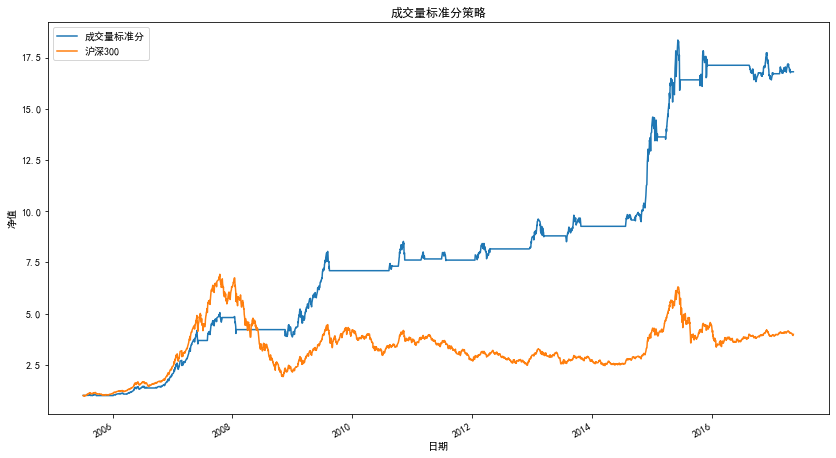
策略指標
| 統計量 | 成交量優化標準分策略 |
|---|---|
| 凈值 | 13.97 |
| 收益率 | 1296.64% |
| 年化收益率 | 25.10% |
| 夏普比率 | 1.57 |
| 最大回撤 | -22.29% |
| 持倉天數 | 916 |
| 交易次數 | 40 |
| 平均持倉天數 | 22 |
| 盈利天數 | 548 |
| 虧損天數 | 368 |
| 勝率(按天) | 59.83% |
| 平均盈利率(按天) | 1.29 |
| 平均虧損率(按天) | -1.16 |
| 平均盈虧比(按天) | 1.11 |
| 盈利次數 | 27 |
| 虧損次數 | 13 |
| 單次最大盈利 | 79% |
| 單次最大虧損 | -16% |
| 勝率(按次) | 67.50% |
| 平均盈利率(按次) | 13% |
| 平均虧損率(按次) | -4% |
| 平均盈虧比(按次) | 3.71 |
3.4 策略結果匯總
現在給出所有RSRS策略的凈值曲線和統計資料

| 統計量 | 斜率 | 標準分 | 修正標準分 | 右偏標準分 | 均值優化標準分 | 成交量優化標準分 |
|---|---|---|---|---|---|---|
| 凈值 | 10.66 | 13.93 | 12.15 | 17.67 | 16.91 | 13.97 |
| 收益率 | 965.73% | 1292.70% | 1115.40% | 1667.22% | 1591.22% | 1296.64% |
| 年化收益率 | 21.92% | 25.07% | 23.47% | 27.88% | 27.36% | 25.10% |
| 夏普比率 | 1.16 | 1.28 | 1.19 | 1.29 | 1.48 | 1.57 |
| 最大回撤 | -50.26% | -50.26% | -51.28% | -51.16% | -23.61% | -22.29% |
| 持倉天數 | 1184 | 1298 | 1397 | 1638 | 1638 | 916 |
| 交易次數 | 21 | 67 | 46 | 37.5 | 37.5 | 40 |
| 平均持倉天數 | 56 | 19 | 30 | 43 | 43 | 22 |
| 盈利天數 | 747 | 741 | 790 | 928 | 714 | 548 |
| 虧損天數 | 575 | 557 | 607 | 710 | 470 | 368 |
| 勝率(按天) | 56.51% | 57.09% | 56.55% | 56.65% | 60.30% | 59.83% |
| 平均盈利率(按天) | 1.31% | 1.32% | 1.30% | 1.27% | 1.24% | 1.29 |
| 平均虧損率(按天) | -1.25% | -1.25% | -1.25% | -1.22% | -1.24% | -1.16 |
| 平均盈虧比(按天) | 1.05 | 1.06 | 1.05 | 1.04 | 1 | 1.11 |
| 盈利次數 | 16 | 40 | 32 | 26 | 26 | 27 |
| 虧損次數 | 5 | 26 | 14 | 11 | 11 | 13 |
| 單次最大盈利 | 170% | 91% | 76% | 91% | 91% | 79% |
| 單次最大虧損 | -12% | -41% | -18% | -17% | -17% | -16% |
| 勝率(按次) | 76.19% | 60.61% | 69.57% | 70.27% | 70.27% | 67.50% |
| 平均盈利率(按次) | 25% | 18% | 11% | 15% | 15% | 13% |
| 平均虧損率(按次) | -3% | -9% | -3% | -3% | -3% | -4% |
| 平均盈虧比(按次) | 7.86 | 2.05 | 3.3 | 4.6 | 4.6 | 3.71 |
4.總結
本文基本復現了【光大證券-基于阻力支撐相對強度(RSRS)的市場擇時】的研究內容,同時得到了與原研報相近的結果,
本文的不足:
1.沒有考慮交易成本,原研報同時給出了在不同交易成本下各策略的結果,凈值有略微的下降,
2.沒有給出選取不同N、M時策略的表現情況,
5.本文作者
何百圣 哈爾濱工業大學威海校區 經濟管理學院
蔡金航 哈爾濱工業大學威海校區 計算機科學與技術學院
寫在最后
我們是國內普通高校的在校學生,同時也是量化投資的初學者,我們的學校不是清北復交,也沒有金融工程實驗室,同時地處三線小城,因此我們在校期間較難獲得量化實習機會,但我們期待與業界進行溝通、交流,
蔡金航同學是我們其中的一員,其在尋找暑期量化實習時,收到了幾家私募和券商金工組的筆試邀請,筆試內容皆為在給定時間內復現出一篇金工研報,蔡同學受到啟發,發覺復現金工研報是我們學習量化策略、鍛煉程式設計能力同時也是與業界交流的很好的途徑,
在蔡同學的建議下,我們開啟研報復現系列的創作,記錄我們的學習程序,并將我們的創作內容分享出來,與讀者們一起交流、學習、進步,
我們的水平有限,創作的內容難免會有錯誤或不嚴謹的內容,我們歡迎讀者的批評指正,
如果您對我們的內容感興趣,請聯系我們:cai_jinhang@foxmail.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279845.html
標籤:其他
上一篇:OpenCV呼叫海康威視等攝像頭(處理rtsp視頻流)方法以及,出現記憶體溢位(error while decoding)或者高延遲問題解決