閱前說明
C語言學習之路系列博客,是博主自己在學習C語言的程序中所做的筆記,把知識框架整理記錄下來,為了后續回顧與復習,同時也希望該博客可以幫助到一些正在學習C語言的小伙伴,博客內容如有錯誤或疏漏,請大家指出,謝謝啦,博主一定多多學習,及時改正過來,
使用的編譯器:Visual Studio 2019(下載地址)
本篇前言
本篇大致介紹了C語言的基礎知識,希望能讓大家對C語言有一個大概的認識,每個知識點只是簡單介紹,后續篇章都會一一詳細講解,
點擊可直接跳轉
文章目錄
- @[toc]
- (1)什么是C語言?
- 第一個C語言程式
- (2)資料型別
- 每種型別的大小是多少?
- 計算機中的單位
- 計算機中的進制
- (3)變數、常量
- 變數的定義
- 變數的分類
- 變數的作用域和生命周期
- 常量
- (4)字串、轉義字符、注釋
- 字串
- 1、什么是字串:
- 2、字串的存盤:
- 3、字串的結束標志:
- 4、獲取字串的長度:
- 5、計算字符陣列/陣列的長度:
- 6、一定要區分開 '0' 和 '\0' 和 0
- 轉義字符
- 1、什么是轉義字符
- 2、C語言中有哪些轉義字符
- 3、轉義字符的應用
- 4、ASCII編碼
- 5、測驗題:
- 注釋
- (5)運算子
- 算數運算子
- 移位運算子
- 位運算子
- 賦值運算子
- 單目運算子
- 關系運算子
- 邏輯運算子
- 條件運算子
- 逗號運算式
- 下標參考、函式呼叫、結構成員
- (6)常見關鍵字
- 1、關鍵字 `typedef`
- 2、關鍵字 `static`
- `static` 修飾區域變數
- `static` 修飾全域變數
- `static` 修飾函式
- (7)`#define` 定義宏
- (8)選擇陳述句
- (9)回圈陳述句
- (10)函式
- (11)陣列
- (12)指標
- 1、什么是記憶體
- 2、獲取變數的地址
- 3、地址的存盤 - 指標變數
- 4、指標變數的大小
- (13)結構體
文章目錄
- @[toc]
- (1)什么是C語言?
- 第一個C語言程式
- (2)資料型別
- 每種型別的大小是多少?
- 計算機中的單位
- 計算機中的進制
- (3)變數、常量
- 變數的定義
- 變數的分類
- 變數的作用域和生命周期
- 常量
- (4)字串、轉義字符、注釋
- 字串
- 1、什么是字串:
- 2、字串的存盤:
- 3、字串的結束標志:
- 4、獲取字串的長度:
- 5、計算字符陣列/陣列的長度:
- 6、一定要區分開 '0' 和 '\0' 和 0
- 轉義字符
- 1、什么是轉義字符
- 2、C語言中有哪些轉義字符
- 3、轉義字符的應用
- 4、ASCII編碼
- 5、測驗題:
- 注釋
- (5)運算子
- 算數運算子
- 移位運算子
- 位運算子
- 賦值運算子
- 單目運算子
- 關系運算子
- 邏輯運算子
- 條件運算子
- 逗號運算式
- 下標參考、函式呼叫、結構成員
- (6)常見關鍵字
- 1、關鍵字 `typedef`
- 2、關鍵字 `static`
- `static` 修飾區域變數
- `static` 修飾全域變數
- `static` 修飾函式
- (7)`#define` 定義宏
- (8)選擇陳述句
- (9)回圈陳述句
- (10)函式
- (11)陣列
- (12)指標
- 1、什么是記憶體
- 2、獲取變數的地址
- 3、地址的存盤 - 指標變數
- 4、指標變數的大小
- (13)結構體
(1)什么是C語言?
C語言廣泛應用于底層開發(不做詳細介紹,可百度)
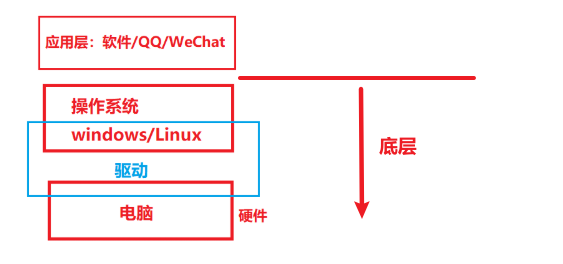
-
計算機語言發展程序
- 二進制語言 0/1
-
匯編語言 - 助記符 ADD/AND
- 高級語言
第一個C語言程式
//test.c(testcode project)
#include <stdio.h>
int main()
{
printf("hello C language\n");
return 0;
}
main函式是程式的入口
一個工程/專案可以有多個.c檔案,但只能有一個main函式
(2)資料型別
char //字符資料型別
short //短整型
int //整型
long //長整型
long long //更長的整型
float //單精度浮點數
double //雙精度浮點數
-
C語言中沒有沒有字串型別?
沒有
-
為什么會出現這么多型別?
更加豐富的表達生活中的各種值,可以提高空間利用率
每種型別的大小是多少?
這里需要用到
sizeof()運算子 - 獲取型別或者變數所占空間大小(以位元組為單位)
#include<stdio.h>
int main()
{
//每種型別的大小是多少?
printf("%d位元組\n", sizeof(int));
printf("%d位元組\n", sizeof(short));
printf("%d位元組\n", sizeof(long));
printf("%d位元組\n", sizeof(long long));
printf("%d位元組\n", sizeof(char));
printf("%d位元組\n", sizeof(float));
printf("%d位元組\n", sizeof(double));
printf("%d位元組\n", sizeof(long double));
return 0;
}
運行結果(x86平臺):

C語言標準:規定只要
sizeof(long)>=sizeof(int)就可以了,不需要一定大于
計算機中的單位
bit - 位元位 - 一個位元位存放一個二進制位 0/1
byte - 位元組 - 一個位元組 = 8bit
kb - 1kb = 1024byte
mb - 1mb = 1024kb
計算機中的進制
二進制:0 1
八進制:0 ~ 7(三位二進制等于一位八進制)
十進制:0 ~ 9
十六進制:0 ~ 9 , A ~ F(四位二進制等于一位十六進制)
(3)變數、常量
變數的定義
注:建議定義變數時給它初始化一個值
#include<stdio.h>
int main()
{
//推薦定義變數時給它初始化一個值,比如:
int age = 0;
double weight = 52.3;
return 0;
}
變數的分類
- 區域變數
- 全域變數(不提倡使用,后續講原因)
#include<stdio.h>
int a = 100; //全域變數 - { }外部定義的
int main()
{
int a = 10; //區域變數 - { }內部定義的
printf("a = %d", a); //輸出a = 10
return 0;
}
思考:為什么會輸出 a = 10 呢?
當區域變數和全域變數名稱沖突時,區域優先
不建議把全域變數和區域變數的名字寫成一樣(如上面代碼中的 a)
變數的作用域和生命周期
變數的作用域
這個變數可以在哪里使用,哪里就是它的作用域
-
區域變數的作用域
變數所在的區域范圍
#include<stdio.h>
int main()
{
int a = 10;
printf("%d\n", a);
{
int b = 20; //b的作用域為此 {} 內
}
//printf("%d\n", b); //error: "b"是未宣告的識別符號
return 0;
}
-
全域變數的作用域
整個工程(在同一工程的其它檔案下使用需要用 extern 宣告一下變數)
/*源檔案demo2.c(test_4_5 project)*/
int x=5;
/*源檔案demo.c(test_4_5 project)*/
#include<stdio.h>
int main()
{
//宣告 demo2.c 檔案中的全域變數
extern int x;
printf("%d\n", x);
return 0;
}
變數的生命周期
變數的創建到銷毀之間的時間段
//區域變數的生命周期:進入區域范圍生命開始,出區域范圍生命結束
//全域變數的生命周期:就是整個程式的生命周期
#include<stdio.h>
int main() //一個程式的生命周期就是 main 函式的生命周期
{
{ //變數 a 宣告開始
int a = 10;
printf("%d\n", a);
} //變數 a 宣告結束
return 0;
}
常量
C語言中常量分為以下幾種:
- 字面常量
const修飾的常變數#define定義的識別符號常量- 列舉常量
1、字面常量
//字面常量
3.14;
10;
'a'; //字符常量 - 由一對單引號引起來的單個字符
"abcdef"; //字串常量
2、const修飾的常變數
常變數 - 具有常屬性(不能被改變的屬性) - 本質上還是變數,不能當常量使用
這樣是錯誤的(只有在C99語法下才支持變長陣列)
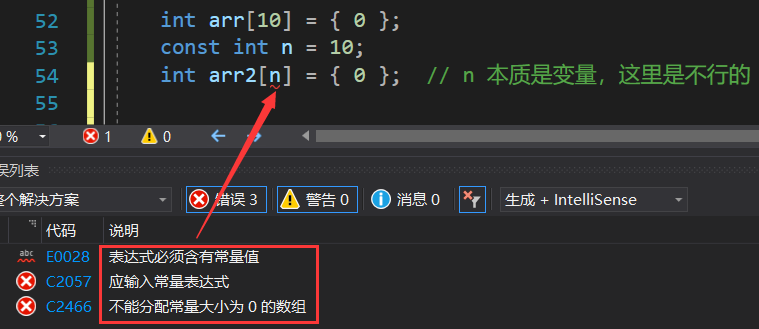
這樣是可以的
int arr[10] = { 0 };
const int N = 9;
//思考:這兩種寫法正確嗎?
arr[N] = 10; //這樣是可以的
N = 20; //error
3、#define 定義的識別符號常量
使用
#define指令為程式中的常量賦予有意義的名稱,它只是一個符號,在預編譯階段進行字符替換
(如下:所有 MAX 符號將被替換成 100)
#include<stdio.h>
#define MAX 100 //#define 定義的識別符號常量
int main()
{
MAX = 200; //error
return 0;
}
4、列舉常量
列舉常量 - 可以一一列舉的常量:比如星期、三原色、性別
//定義列舉常量Sex
enum Sex
{
//列舉常量默認的值: 0 1 2 3 …… 依次遞增 - 其值不可被更改
Male, // 0
Female, // 1
Secret // 2
};
#include<stdio.h>
int main()
{
enum Sex S1 = Male;
printf("%d\n", Male); //輸出:0
printf("%d\n", Female); //輸出:1
printf("%d\n", Secret); //輸出:2
return 0;
}
列舉常量不可以賦值,但可以在定義的時候 指定值,這個可以認為是定義值,而不是賦值,
enum Sex
{
//這個可不是賦值哦
Male = 3,
Female = 100,
Secret
};
printf("%d\n", Male);
printf("%d\n", Female);
printf("%d\n", Secret);
列印其值,運行結果為:
3
100
101
(4)字串、轉義字符、注釋
字串
1、什么是字串:
字串就是由雙引號引起來的一串字符
"hello world"
2、字串的存盤:
因為C語言沒有字串這種資料型別,所以要用到「 字符陣列 」來存盤字串(每個元素都是字符型別的陣列)
#include<stdio.h>
int main()
{
char arr[] = "hello";
//['h']['e']['l']['l']['o']['\0']
return 0;
}
3、字串的結束標志:
C語言規定,在每一個字串常量的結尾,系統都會自動加一個字符 ‘\0’ 作為該字串的“結束標志符”,系統據此判斷字串是否結束,計算字串長度時,’\0’ 不算作字串的內容哦;但是計算陣列長度(或元素個數或所占記憶體空間大小),’\0’ 要算進去,
通過除錯,打開監視視窗可看到字符陣列內部情況
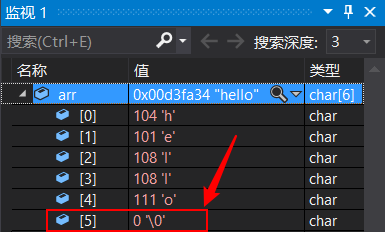
- 接下來我們用代碼來驗證一下:
#include<stdio.h>
int main()
{
char arr1[] = "abc"; //字串
char arr2[] = { 'a','b','c' }; //是字符陣列,但不代表字串,末尾沒有'\0'
printf("%s\n", arr1);
printf("%s\n", arr2);
return 0;
}
除錯這段代碼,我們發現,arr1 陣列尾部有結束標志 ‘\0’ ,而 arr2 陣列后面卻沒有 ‘\0’
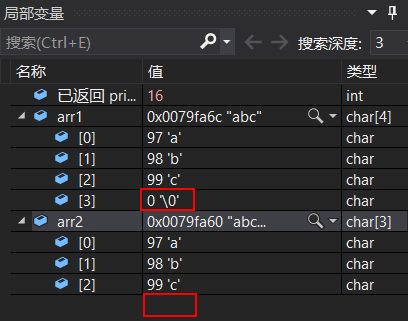
再來看看運行結果,arr1 正常輸出,而 arr2 后面卻亂碼了,輸出了一堆奇怪的符號,這是為什么呢?
因為在輸出 arr1 中的內容程序中,遇到了 ‘\0’ 是字串的結束標志,所以停止輸出;
而輸出 arr2 中的內容時,輸出完 abc 沒有遇到字串結束標志 ‘\0’ ,不知道什么時候停下來,而后面的記憶體空間的內容是未知的,放的是啥我們不知道,所以輸出亂碼,

現在我們修改代碼,主動在 arr2 后面放上 ‘\0’ ,輸出看看效果
#include<stdio.h>
int main()
{
//定義并初始化字串的兩種方式
//一定不要忘記結束標志 '\0' 了哦
char arr1[] = "abc";
char arr2[] = { 'a','b','c','\0' };
printf("%s\n", arr1);
printf("%s\n", arr2);
return 0;
}
運行結果:都能列印出 abc 由此可見,字串的結束標志是至關重要的

4、獲取字串的長度:
這里要使用到一個函式
strlen()- string length - 呼叫該函式需要參考頭檔案<string.h>
#include<stdio.h>
#include<string.h> //呼叫strlen()函式
int main()
{
char arr1[] = "abc";
char arr2[] = { 'a','b','c' };
char arr3[] = { 'a','b','c','\0' };
//列印字串的長度
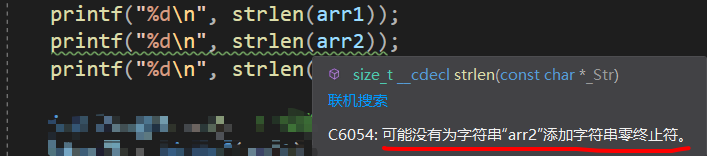
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
printf("%d\n", strlen(arr3));
return 0;
}
運行結果:獲取字串的長度并輸出時,字符陣列 arr2 因為末尾沒有字串結束標志 ‘\0’ ,不知道長度到底是多少,所以輸出隨機值,獲取不了字串的長度,
注:在計算字串長度的時候 ‘\0’ 是結束標志,不算作字串的內容,
5、計算字符陣列/陣列的長度:
計算陣列長度(或元素個數或所占記憶體空間大小), ‘\0’ 要算進去
#include<stdio.h>
int main()
{
char arr[] = "abc";
int len = 0;
//計算陣列 arr 的長度:陣列記憶體總大小(位元組)/單個陣列元素記憶體大小(位元組)
len = sizeof(arr) / sizeof(arr[0]);
printf("len = %d\n", len);
return 0;
}
運行結果:4(因為字符陣列 arr 后面還有一個系統自動添加的結束符 ‘\0’ )
6、一定要區分開 ‘0’ 和 ‘\0’ 和 0
字符 ‘0’ —— ASCII碼值為 48
轉義字符 ‘\0’ —— 字串的結束標志(不算作字串的內容) - ASCII碼值為 0
數字 0
轉義字符
1、什么是轉義字符
轉義字符顧名思義就是轉變了字符原來的意思
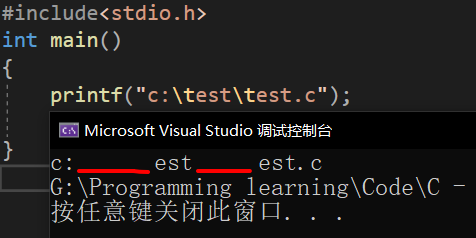
來段代碼感受一下,如果我們想要在螢屏上列印一個目錄:c:\test\test.c
#include<stdio.h>
int main()
{
printf("c:\test\test.c");
return 0;
}
運行結果:很奇怪,和我們想象的不一樣唉,沒有列印出目錄,卻出現了兩段空白,這個字符\和字符t不再是普通的字符的意思了,轉變了原來的意思,變成了轉義字符\t(水平制表符)
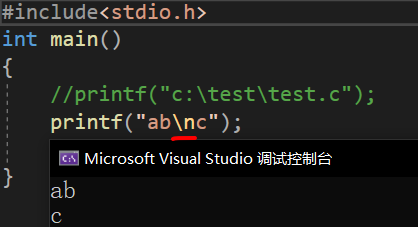
同理,字符\和字符n也不再是兩個普通的字符了,而是轉義字符\n(換行符)
2、C語言中有哪些轉義字符
| 轉義字符 | 釋義 |
|---|---|
| \’ | 用于表示字符常量' |
| \" | 用于表示一個字串內部的雙引號" |
| \\ | 用于表示一個反斜杠,防止它被解釋為一個轉義序列符 |
| \a | 警告字符,蜂鳴 |
| \n | 換行 |
| \r | 回車 |
| \t | 水平制表符(鍵盤上的 Tab 鍵) |
| \v | 垂直制表符 |
| \ddd | ddd表示 1-3 個八進制的數字,如:\130(從 \000 到 \377) |
| \xdd | dd表示 2 個十六進制的數字,如:\x30 |
| \b | 退格符 |
| \f | 進制符 |
| ? | 在書寫連續多個問號時使用,防止他們被決議成三字母詞 |
3、轉義字符的應用
- 思考問題:在螢屏上列印一個單引號
'怎么做?
大家再沒有學習轉義字符之前可能會想直接輸出列印就好啦,而寫成下面這個錯誤示范了哦
錯誤示范:中間的你想要輸出的那個單引號 ’ 和左邊的單引號組成一對了,編譯會 error
printf("%c\n", ''');
修改正確:為了防止其與左邊的單引號組成一對,需要在單引號前加一個轉義符
printf("%c\n", '\''); //這里 \'被決議成一個轉義字符
同理:在螢屏上列印一個雙引號"就可以這樣寫啦
printf("%s\n", "\"");
- 回到最初的問題:在螢屏上列印一個
c:\test\test.c怎么做?
printf("c:\\test\\test.c");
- \ddd 與 \xdd :使用編碼值來間接的表示字符
//輸出字符 A - 對應的ASCII碼的8進制形式是101 - 8進制的130是十進制的65
printf("%c\n", '\101');
//輸出字符 a - 對應的ASCII碼的8進制形式是141 - 8進制的141是十進制的97
printf("%c\n", '\141');
//輸出字符 B - 對應的ASCII碼的16進制形式是42
printf("%c\n", '\x42');
//輸出字符 b - 對應的ASCII碼的16進制形式是62
printf("%c\n", '\x62');
對于轉義字符來說,只能使用八進制或者十六進制,
轉義字符的初衷是用于 ASCII 編碼,所以它的取值范圍有限:
- 八進制形式的轉義字符最多后跟三個數字,也即
\ddd,最大取值是\177, - 十六進制形式的轉義字符最多后跟兩個數字,也即
\xdd,最大取值是\x7F,
@參考文章:C語言轉義字符
4、ASCII編碼
補充知識:
計算機只認識 0 和 1 兩個數字,資料在記憶體中以二進制形式存盤,我們在螢屏上看到的文字,在存盤之前都被轉換成了二進制(0和1序列),在顯示時也要根據二進制找到對應的字符,
那么,怎么將英文字母和二進制對應起來呢?這就需要有一套規范,一種專門針對英文的字符集 - ASCII編碼就被設計出來了,為每個字符分配了唯一的編碼值,在C語言中,一個字符除了可以用它的物體表示,還可以用編碼值表示,使用編碼值來間接地表示字符的方式稱為轉義字符,
在 ASCII 編碼中,大寫字母、小寫字母和阿拉伯數字都是連續分布的(見下表),這給程式設計帶來了很大的方便,例如要判斷一個字符是否是大寫字母,就可以判斷該字符的 ASCII 編碼值是否在 65~90 的范圍內,
@參考文章:ASCII編碼,將英文存盤到計算機
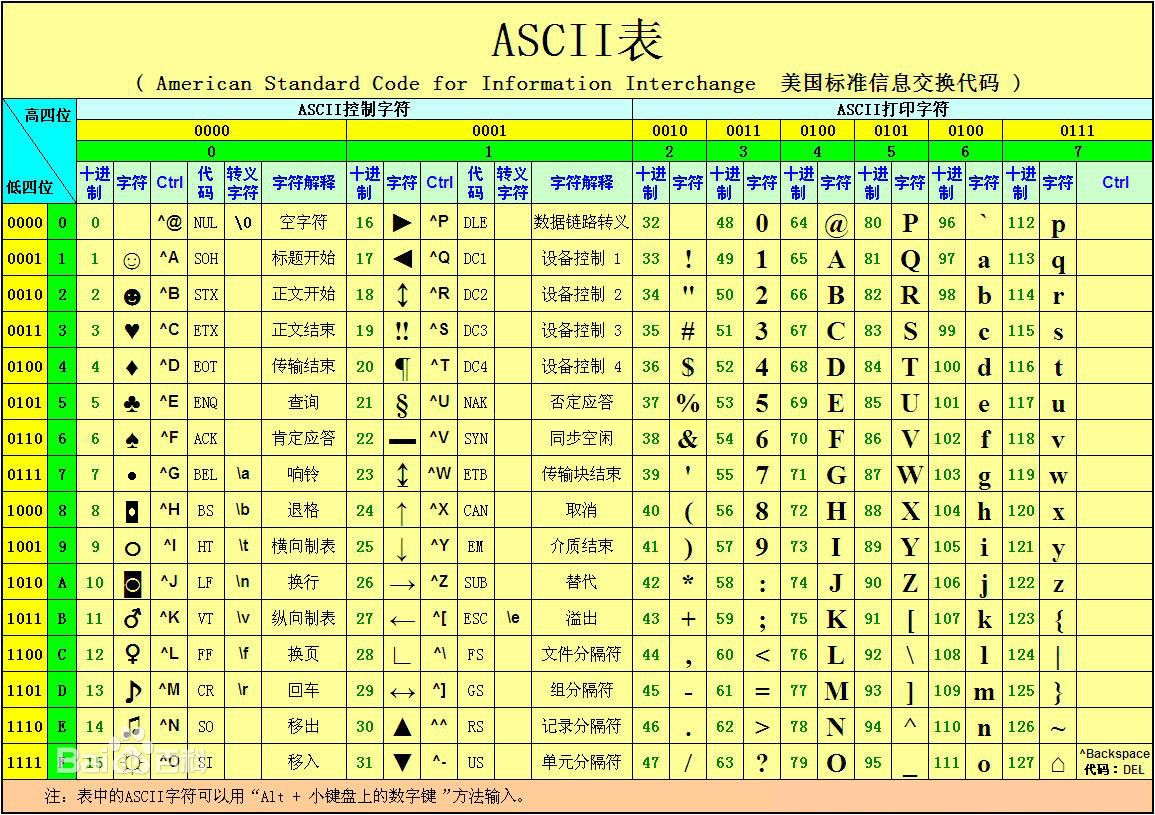
此圖轉載自百度
5、測驗題:
#include<stdio.h>
#include<string.h>
int main()
{
//程式輸出什么呢?
printf("%d\n", strlen("c:\test\328\test.c"));
return 0;
}
運行結果:14(\t和\32分別是一個轉義字符)
注釋
注釋有兩種風格:
在撰寫C語言源代碼時,應該多使用注釋,這樣有助于對代碼的理解,
- C語言風格的注釋(缺陷:不能嵌套注釋)
/*xxxxxxxxxxxx*/
- C++風格的注釋(可以注釋一行也可以注釋多行)
//xxxxxxxxxxxx
(5)運算子
這里只是簡單介紹一下各種運算子,目的是能夠讓大家在代碼中識別出這些,后面我們會詳細講解和學習
算數運算子
+ - * / %
移位運算子
| 移位運算子 | 含義 |
|---|---|
| >> | 右移運算子 - 把二進制位向右移動 - 缺位補 0 |
| << | 左移運算子 - 把二進制位向左移動 - 缺位補 0 |
舉例說明:
int a = 1;
int b = a << 1;
//a - 00000000000000000000000000000001 --> a = 1
//b - 00000000000000000000000000000010 --> b = 2
位運算子
| 位運算子 | 含義 |
|---|---|
| & | 按位與 |
| | | 按位或 |
| ^ | 按位異或 |
賦值運算子
= //賦值符
+= -= *= /= &= ^= |= >>= <<= //復合賦值符
舉例說明:
int a = 0;
a = a + 1;
//等效于:
a += 1;
單目運算子
| 單目運算子 | 含義 |
|---|---|
| ! | 邏輯反操作 |
| - | 負值 |
| + | 正值 |
| & | 取地址 |
| sizeof | 運算元的型別長度(以位元組為單位) |
| ~ | 對一個數的二進制序列按位取反 |
| – | 前置、后置– |
| ++ | 前置、后置++ |
| * | 間接訪問運算子(解參考運算子) |
| (型別) | 強制型別轉換 |
注:
雙目運算子:有兩個運算元(比如:a + b)
單目運算子:只有一個運算元
補充知識:C語言中如何表示真和假?
0 表示假,非 0 表示真
下面來展開講解幾個運算子
- 按(二進制)位取反運算子:~
對一個數的所有二進制位取反,0 變成 1,1 變成 0
#include<stdio.h>
int main()
{
int a = 0;
int b = ~a; //按位取反
printf("%d\n", b); //輸出的是 b 的原碼
return 0;
}
運行結果:-1
這個時候大家可能會有疑問了,為啥會是 -1 呀,別著急,仔細聽我道來
這里需要引入原碼 反碼 補碼的概念
整數在記憶體中存盤的都是二進制形式的「 補碼 」,輸出列印時 要將其轉換成「 原碼 」
「 原碼 」第一位是「 符號位 」表示 「 正負 」(1為負,0為正)
所以:
a - 00000000000000000000000000000000(補碼)
對 a 的二進制位( ~ 按位取反)得到 b 的二進制形式的「 補碼 」,因為輸出的是「 原碼 」所以我們進一步轉換:
b - 11111111111111111111111111111111(補碼)
b - 11111111111111111111111111111110(補碼 -1得到反碼)
b - 10000000000000000000000000000001(符號位不變,其它位按位取反得到原碼)
而二進制序列 10000000000000000000000000000001 就是 -1
知識點:
整數(正數、負數)的原碼反碼補碼:
- 正數:原碼 = 反碼 = 補碼 相同
int i = 2;
00000000000000000000000000000010 - 原碼
00000000000000000000000000000010 - 反碼
00000000000000000000000000000010 - 補碼
- 負數
| 二進制形式 | 轉換規則 |
|---|---|
| 原碼 | 按照整數正負 寫出二進制序列 |
| 反碼 | 「 原碼 」符號位不變 其它位按位取反 |
| 補碼 | 反碼 + 1 |
int i = -2;
10000000000000000000000000000010 - 原碼
11111111111111111111111111111101 - 反碼
11111111111111111111111111111110 - 補碼
- **自增自減運算子:++ – **
#include<stdio.h>
int main()
{
int a = 10;
int b = ++a; //前置++:先++ 后使用
int c = a++; //后置++:先使用 后++
printf("%d\n", a);
printf("%d\n", b);
return 0;
}
前置后置-- 同理
同時建議大家不要去研究這樣的代碼,浪費時間,在不同的編譯器得到的結果都不一樣,平時開發也幾乎不會這樣去寫,可讀性太差
int a = 1;
int b = (++a) + (++a) + (a++);
- 強制型別轉換:(型別)
一般在型別不匹配的時候使用,不推薦,既然你會使用強制型別轉換,說明一開始在撰寫程式的時候就沒有設計好各變數的資料型別,導致程式有缺陷
int a = (int)3.14;
關系運算子
>
>=
<
<=
!= 用于測驗“不相等”
== 用于測驗“相等”
邏輯運算子
描述并且、或者的關系
邏輯 與 / 或 的結果為:真 / 假
&& 邏輯與
|| 邏輯或
條件運算子
運算式 exp1 成立,整個運算式的結果是 exp2 的結果
運算式 exp1 不成立,整個運算式的結果是 exp3 的結果
exp1 ? exp2 : exp3 //也是三目運算子,有三個運算元
舉例說明:
#include<stdio.h>
int main()
{
int a = 10;
int b = 20;
int max = a > b ? a : b;
printf("max = %d\n", max);
return 0;
}
運行結果:max = 20
逗號運算式
逗號隔開的一串運算式,從左向右依次計算的,整個運算式的結果是最后一個運算式的結果
exp1, exp2, exp3, …expN
舉例說明:
#include<stdio.h>
int main()
{
int a = 1;
int b = 2;
int c = 5;
//思考 d 的值是多少?
int d = (a = b + 2, c = a - 4, b = c + 2);
printf("d = %d\n", d);
return 0;
}
運行結果:d = 2
思考題:
函式呼叫 exec( ( vl, v2 ), ( v3, v4 ), v5, v6 ); 中,實參的個數是:( 4 ) - 分別是v2 v4 v5 v6
下標參考、函式呼叫、結構成員
[] 下標參考運算子
() 函式呼叫運算子
. 結構體成員訪問運算子
->
舉例說明

(6)常見關鍵字
1.關鍵字是C語言提供的,不能自己創建關鍵字
2.關鍵字不能做變數名
auto(修飾區域變數,一般是省略的) break case char const continue default
do double else enum(列舉) extern(宣告外部符號) float for goto if int
long register(暫存器) return short signed(有符號數) unsigned(無符號數)
sizeof(計算機型別/變數所占記憶體空間大小) static(靜態) struct(結構體) switch
typedef(型別定義) union(聯合體/共用體) void volatile(C語言中暫時不講) while
- 補充知識:
計算機中,資料可以存放到哪里呢?
暫存器(會被頻繁呼叫的資料,放在暫存器中,可以提高效率,現在編譯器已經能夠自動識別這種資料并放在其中,register實用意義不大)
高速快取
記憶體
硬碟
- 思考:
#define是不是關鍵字?include是不是關鍵字?
都不是,它們是預處理指令(預編譯期間處理的指令)
關鍵字這次先簡單介紹幾個,后續遇到了再講解
1、關鍵字 typedef
型別重定義,型別重命名,相當于取了一個別名
舉例說明:
#include<stdio.h>
//把 unsigned int 重命名為 u_int,現在 u_int 也是一個型別名了
typedef unsigned int u_int;
int main()
{
//a 和 b 的型別相同
unsigned int a = 10;
u_int b = 20;
return 0;
}
2、關鍵字 static
static 用來修飾變數和函式
1)修飾區域變數 - 靜態區域變數
2)修飾全域變數 - 靜態全域變數
3)修飾函式 - 靜態函式
static 修飾區域變數
改變了區域變數的生命周期(本質上是變數的存盤型別),讓靜態區域變數出了作用域依然存在,直到程式結束生命周期才結束
代碼1:
#include<stdio.h>
void test()
{
int a = 1; //區域變數 a
a++;
printf("%d ", a);
}
int main()
{
int i = 0;
for (i = 0; i < 10; i++)
{
test();
}
return 0;
}
運行結果:2 2 2 2 2 2 2 2 2 2(10個2)
代碼2:
#include<stdio.h>
void test()
{
static int a = 1; //靜態區域變數a
a++;
printf("%d ", a);
}
int main()
{
int i = 0;
for (i = 0; i < 10; i++)
{
test();
}
return 0;
}
運行結果:2 3 4 5 6 7 8 9 10 11
為啥會出現這樣的結果呢?
這里補充一點小知識,記憶體會被分為幾個區域,今天在這里我們只討論和這次C語言有關的幾個區域,區域變數 a 開始放在堆疊區的,被 static 修飾后就被放到靜態區去了,改變了它的存盤型別,存在不同的區域,就有不同的特點了,靜態變數 a 的生命周期和全域變數一樣,為整個程式
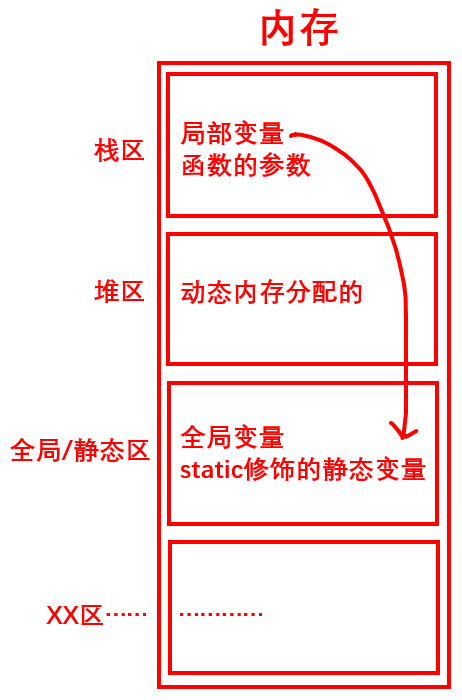
static 修飾全域變數
static修飾全域變數,使得這個全域變數只能在自己所在的源檔案(.c)內使用不能在同一工程的其他源檔案內使用
代碼實體:
/*源檔案demo2.c(test project)*/
//靜態全域變數g_val
static int g_val = 2021;
/*源檔案demo.c(test project)*/
#include<stdio.h>
//宣告靜態全域變數 g_val
extern int g_val;
int main()
{
printf("%d\n", g_val);
return 0;
}
運行結果:error
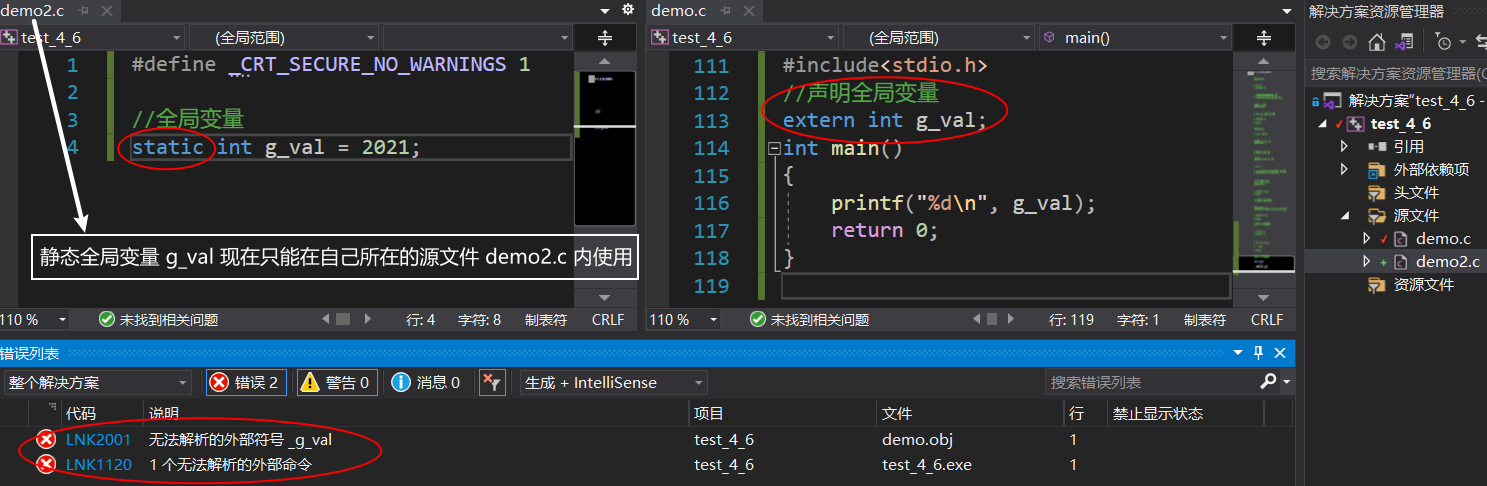
運行程式,結果error了,那么 static 修飾全域變數的本質是什么呢?
全域變數,可以在同一工程的其他源檔案內被使用,是因為全域變數具有外部鏈接屬性
但是當被 static 修飾成靜態全域變數,就變成了內部鏈接屬性,其他源檔案就不能鏈接到這個靜態全域變數了
所以無法被其他源檔案所使用,只能在自己所在的源檔案內使用
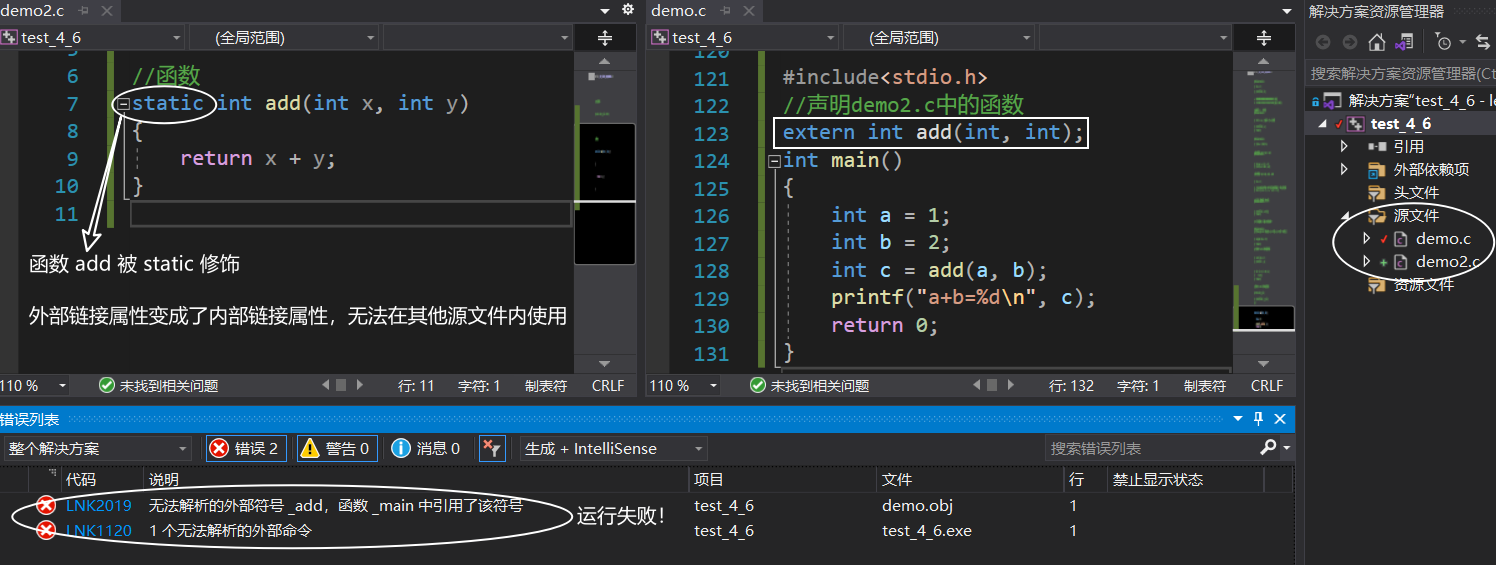
static 修飾函式
static修飾函式,使得這個函式只能在自己所在的源檔案(.c)內使用不能在同一工程的其他源檔案內使用
本質上是:
static將函式的外部鏈接屬性變成了內部鏈接屬性(和static修飾全域變數一樣)
仔細對比代碼1和代碼2,理解 static 在修飾函式前后的意義
代碼1:
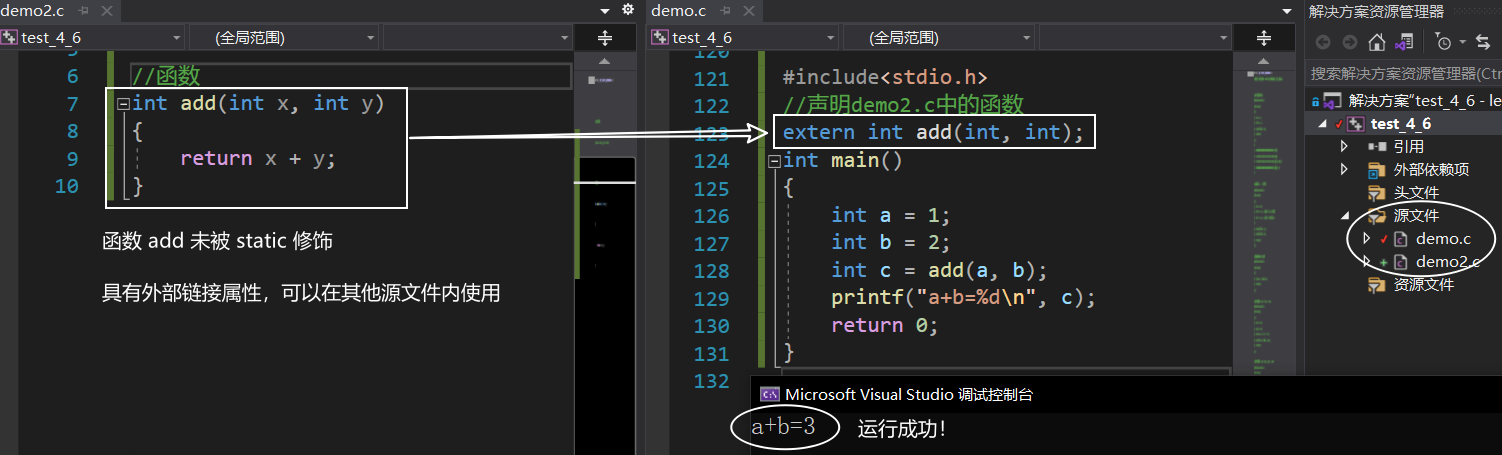
代碼2:
(7)#define 定義宏
#define是C語言提供的宏定義命令,它用來將一個識別符號定義為一個字串,該識別符號被稱為宏名,被定義的字串稱為替換文本,該命令有兩種格式:一種是簡單的宏定義,另一種是帶引數的宏定義,在該程式被編譯前,先將宏名用被定義的字串替換,這稱為宏替換,替換后才進行編譯,宏替換是簡單的替換,
還有就是要記住這是簡單的替換而已,不要在中間計算結果,一定要替換出運算式之后再算,
//普通宏
#define PI (3.1415926)
//帶引數的宏
#define ADD(a,b) ( (a) + (b) )
//關鍵是十分容易產生錯誤,包括機器和人理解上的差異等等
來看一個例子:
int a = 2 * ADD(2, 3);
預處理階段之后,ADD(2, 3) 則會被替換成 ( (2) + (3) )
int a = 2 * ( (2) + (3) ); //結果為 10
如果沒有括號
#define ADD(a,b) a + b
替換之后的結果是:
int a = 2 * 2 + 3; //結果為 7
(8)選擇陳述句
為了先將C語言拉通介紹一遍,能夠對其有一個整體的認識,這里的內容只進行一個簡單的介紹,后續會詳細講解
生活中的選擇無處不在,那么在計算機中,怎么用C程式設計語言表示呢?
如果(if)就……
否則(else)就……
這就是選擇!
#include<stdio.h>
int main()
{
int a = 10;
int b = 20;
if (a > b)
{
printf("較大值:a\n");
}
else
{
printf("較小值:b\n");
}
return 0;
}
如果 a 比 b 大,輸出 a,否則就輸出 b
(9)回圈陳述句
生活中有些事,要一直做,重復做,比如學習、吃飯、睡覺等等,如何用C語言實作回圈呢?
- while 陳述句
- for 陳述句
- do…while 陳述句
后面會詳細講解
(10)函式
假設(我是 main函式)(張三是 add 函式),有一天,我想讓張三給我帶飯,所以得告訴他我想帶什么飯,并給他帶飯的錢,(蛋炒飯,10元),張三接收到資訊和拿到錢,最后回傳(return)給我一份蛋炒飯
實體:用函式實作求兩數的和
#include<stdio.h>
int add(int x, int y) //求兩數的和
{
return x + y;
}
int main()
{
int a = 10;
int b = 20;
int sum = add(a, b);
printf("sum = %d\n", sum);
return 0;
}
函式的特點就是簡化代碼,代碼復用
(11)陣列
我們需要存盤 10 個數字,怎么辦呢?如果去定義 10 個變數來存盤,那也太麻煩了,這時我們可以用陣列
C語言中陣列的定義:一組相同資料型別的元素的集合
- 陣列的定義與初始化
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 }; //完全初始化
int arr2[5] = { 1,2,3 }; //不完全初始化,剩余的默認為 '\0'
- 陣列元素的訪問(通過陣列下標訪問,陣列的下標是從 0 開始的)
arr1[0] = 1;
arr1[1] = 2;
……
arr1[9] = 10;
(12)指標
指標是C語言中非常非常重要的內容,我們要談指標,必須先要搞明白記憶體
1、什么是記憶體
記憶體是電腦上特別重要的存盤器,計算機中所有程式的運行都是在記憶體中進行的,
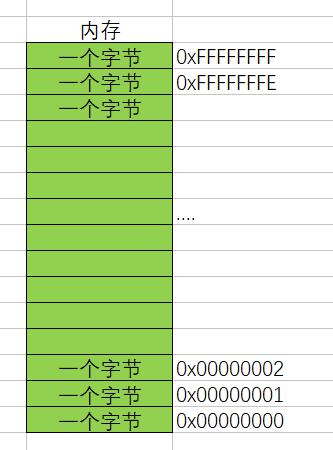
為了有效的使用記憶體,就把記憶體劃分成一個個小的記憶體單元,「 每個記憶體單元的大小是1個位元組 」,
為了能夠有效的訪問到記憶體的每個單元,就給記憶體單元進行了編號,這些編號被稱為該「 記憶體單元的地址 」,
- 記憶體單元是如何編號的?
電腦分為 32位 和 64位 的,以 32位 舉例
32位 - 有32根地址線 - 通電會產生 1/0 電信號 - 電信號轉換成數字信號 - 變成32個 1/0 組成的二進制序列
共有 2 (32) = 4,294,967,296 種不同的序列
00000000000000000000000000000000
00000000000000000000000000000001
…………
01111111111111111111111111111111
11111111111111111111111111111111
我們就可以用這些二進制序列來給記憶體單元編號,一個位元組的編號就會由32個0/1組成,這就是它們的地址,
記憶體地址只是一個編號,代表一個記憶體空間,在計算機中存盤器的容量是以位元組為基本單位的,也就是說一個記憶體地址代表一個位元組(8bit)的存盤空間,例如經常說 32位 的作業系統最多支持4GB的記憶體空間,也就是說CPU只能尋址2的32次方(4GB)空間,
類比到生活中,一棟宿舍樓相當于一塊記憶體區域,被劃分成了一個個宿舍,為了方便管理和找到某一個宿舍,我們給每一間宿舍都編了門牌號,比如307,表示3樓7號,這樣很容易就找到它們的位置在哪里了,
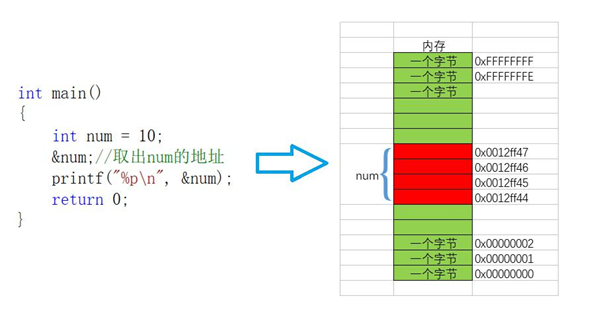
2、獲取變數的地址
#include<stdio.h>
int main()
{
//num在記憶體要被分配 4位元組 的記憶體空間
int num = 10;
//%p - 以地址的形式列印
printf("%p\n", &num);
return 0;
}
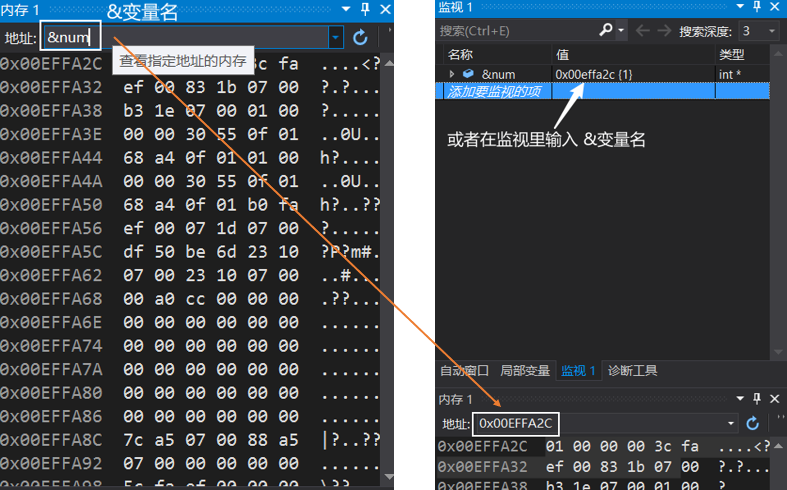
運行結果:004FFD64(這個地址是變數num所在記憶體空間的第一個位元組的地址)
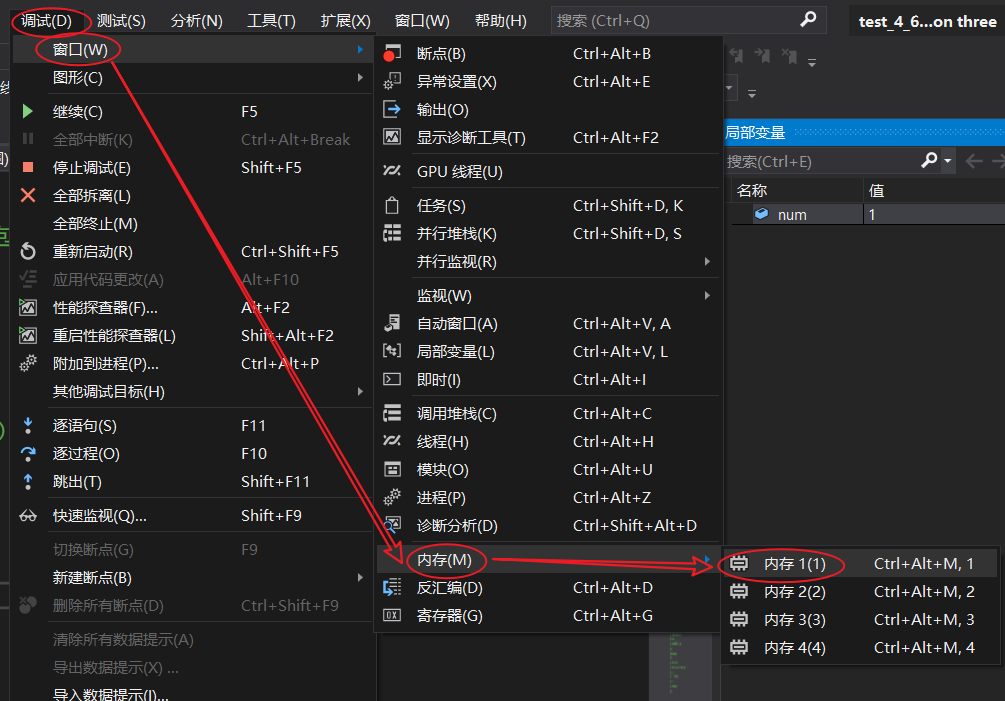
在VS2019中,F10進入除錯模式,選擇除錯選單 - 視窗 - 記憶體,就可以找到記憶體視窗
輸入 &變數名,取出變數的地址,這個地址是變數所在記憶體空間的第一個位元組的地址
3、地址的存盤 - 指標變數
指標變數存放相同資料型別的變數的首地址
//定義一個整型指標變數,存盤整型變數num的地址
int num = 10;
int* p = #
//字符型指標變數指向字符型變數
char ch = 'b';
char* str = &ch;
指標變數的使用舉例:通過指標變數存放的變數的地址,找到所指向的變數
#include<stdio.h>
int main()
{
int num = 10;
//指標變數 p
int* p = #
//* 是 解參考運算子 / 間接訪問運算子,訪問指標 p 指向的記憶體空間
*p = 20;
printf("num = %d\n", num);
return 0;
}
運行結果:num = 20
4、指標變數的大小
任何型別的指標變數在 32位平臺 是4個位元組大小,64位平臺 是8個位元組大小
指標變數占幾個位元組跟語言無關,取決于變數的地址的存盤需要多大的空間,進一步講,是與系統的尋址能力有關*(提示:結合上面內容 - 1、什么是記憶體 - 記憶體是如何編號的? - 進行理解)*
32位系統 - 32根地址總線 - 一個地址是 32 個位元位 - 4位元組
64位系統 - 64根地址總線 - 一個地址是 64 個位元位 - 8位元組
所以,不管你是整型變數還是字符型變數還是浮點型變數,在 32/64 位平臺中,你的第一個位元組(首地址)的編址是由 32/64 個位元位組成的二進制序列,占 4/8 個位元組

#include<stdio.h>
int main()
{
printf("%d位元組\n", sizeof(char *));
printf("%d位元組\n", sizeof(int *));
printf("%d位元組\n", sizeof(double *));
return 0;
}
運行結果:在(32位平臺)均輸出 4位元組、在(64位平臺)均輸出 8位元組
- VS2019中,這里可以切換程式運行的平臺 x86(32位) / x64(64位)
(13)結構體
結構體是C語言中特別重要的內容,結構體使得C語言可以描述復雜型別
比如描述一個人,用之前學過的任何一種型別變數都不足以描述清楚,int? float? char?,似乎都沒內味,人是一個復雜物件,有姓名,年齡,性別等等;描述一本書,有作者,定價,書類等等
而我們用結構體,就可以創造一些型別,來描述這些復雜型別了
接下來,我們來創建一個學生的結構體
struct Student
{
char name[20]; //姓名
int age; //年齡
double grade; //成績
};
結構體變數的定義與初始化
- 定義時初始化
- 定義之后初始化
一般在定義時初始化,比較方便;定義之后初始化,就只能對每一個成員一一賦值初始化了
//定義一個結構體變數并初始化
struct Student s1 = { "瑪卡巴卡",20,85 };
//定義之后初始化
strcpy(s1.name, "李四"); //因為name是陣列名,它是一個地址,不能用 s1.name = "李四";
//strcpy - 字串拷貝函式 - 庫函式 - 參考頭檔案string.h
s1.age = 25;
s1.grade = 90;
訪問結構體變數中的成員
//方法(1):結構體變數.結構體成員
printf("name: %s age: %d grade: %lf\n", s1.name, s1.age, s1.grade);
//方法(2):結構體指標->結構體成員
struct Student* ps = &s1;
printf("name: %s age: %d grade: %lf\n", ps->name, ps->age, ps->grade);
//方法(3):太麻煩,建議用 ->運算子 訪問更直觀
printf("name: %s age: %d grade: %lf\n", (*ps).name, (*ps).age, (*ps).grade);
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279856.html
標籤:其他