基于Spring Cloud的全自動化微信公眾號訊息采集系統
文章目錄
- 基于Spring Cloud的全自動化微信公眾號訊息采集系統
- 前言
- 一、系統簡介
- 二、系統架構
- 技術架構
- 存盤
- 快取
- 代理
- 三、系統優劣性
- 系統優點
- 系統缺點:
- 四、模塊簡介
- common-ws-starter
- redis-ws-starter
- rocketmq-ws-starter
- db-ws-starter
- sql-wx-spider
- pc-wx-spider
- java-wx-spider
- mobile-wx-spider
- 五、大體流程圖
- 六、運行截圖
- PC和移動端
- 控制臺
- 運行結束
- 總結
前言
由于公司業務需求,需要獲取客戶提供的微信公眾號的歷史文章并每天進行更新,三百多個公眾號顯然不能通過人工去每天查看,問題提交到了IT組,對于熱愛爬蟲的我肯定要盤他,之前做過搜狗的微信爬蟲,后來一直致力于java web了,這個專案又重新燃起了我對爬蟲的熱愛,第一次使用spring cloud架構來做爬蟲,歷時二十多天,終于搞定,接下來,我將通過一系列文章來分享此次專案經歷,并奉上原始碼供大家指正!
一、系統簡介
本系統是基于Java開發,可通過簡單配置公眾號名稱或微信號,實作定時或即時抓取微信公眾號的文章(包括閱讀量、點贊、在看),
二、系統架構
技術架構
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
存盤
Mysql、MongoDB、Redis、Solr
快取
Redis
代理
Fiddler
三、系統優劣性
系統優點
1、配置完公眾號后可通過Fiddler的JS注入功能和Websocket實作全自動抓取;
2、系統為分布式架構,具有高可用性;
3、RocketMq訊息佇列進行解耦,可解決網路抖動導致采集失敗情況,若消費三次還未成功則將日志記錄到mysql,確保文章的完整性;
4、可加入任意多個微信號提高采集效率和抵抗反爬限制;
5、Redis快取了每個微信號24小時內采集記錄,防止封號;
6、Nacos作為配置中心,可通過熱配置實時調整采集頻率;
7、將采集到的資料存盤到Solr集群,提高檢索速度;
8、將抓包回傳的記錄存盤到MongoDB存檔便于查看錯誤日志,
系統缺點:
1、通過真機真號采集訊息,如果需要采集大量公眾號的話需要有多個微信號作為支撐(若賬號當日到了限制,可通過爬取微信公眾平臺介面獲取訊息);
2、不是公眾號一發文就能馬上抓取到,采集時間是系統設定的,訊息有一定的滯后(如果公眾號不多微信號數量充足可通過提高采集頻率優化),
四、模塊簡介
由于之后要加入管理系統和API呼叫功能,提前對一些功能進行了封裝,
common-ws-starter
公共模塊:存放工具類和物體類等公共訊息,
redis-ws-starter
Redis模塊:對spring-boot-starter-data-redis的二次封裝,對外暴露封裝的Redis工具類和Redisson工具類,
rocketmq-ws-starter
RocketMq模塊:對rocketmq-spring-boot-starter的二次封裝,提供消費重試和記錄失敗日志功能,
db-ws-starter
mysql資料源模塊:對mysql資料源進行封裝,支持多資料源,自定義注解實作資料源動態切換,
sql-wx-spider
mysql資料庫模塊:提供了所有對mysql資料庫操作的功能,
pc-wx-spider
PC端采集模塊:包含PC端采集公眾號歷史訊息相關功能,
java-wx-spider
Java提取模塊:包含java程式提取文章內容相關功能,
mobile-wx-spider
模擬器采集模塊:包含通過模擬器或手機端采集訊息的互動量相關功能,
五、大體流程圖
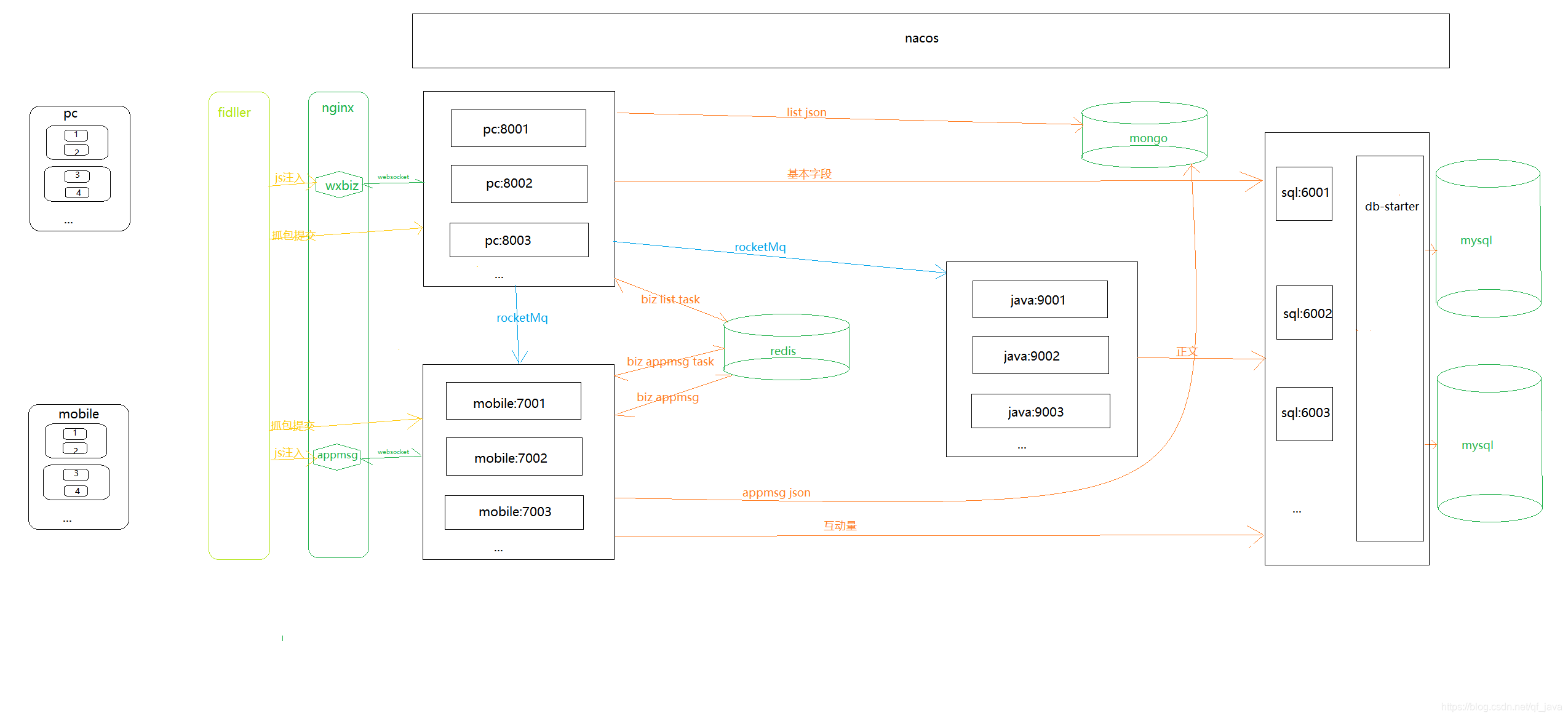
六、運行截圖
PC和移動端

控制臺
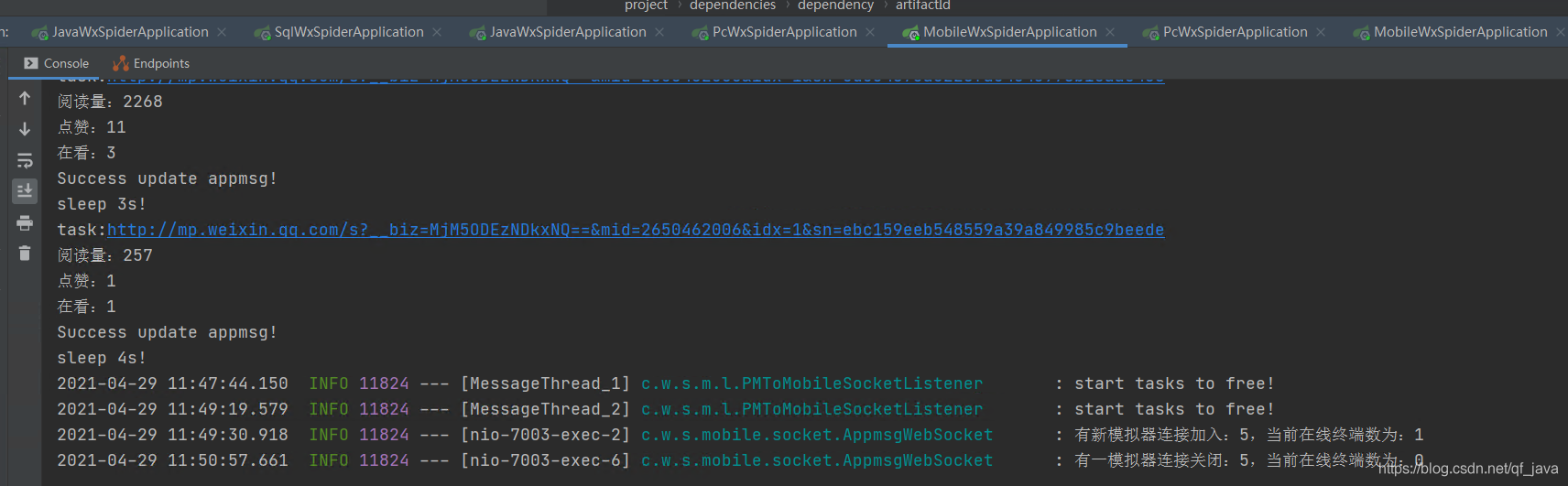
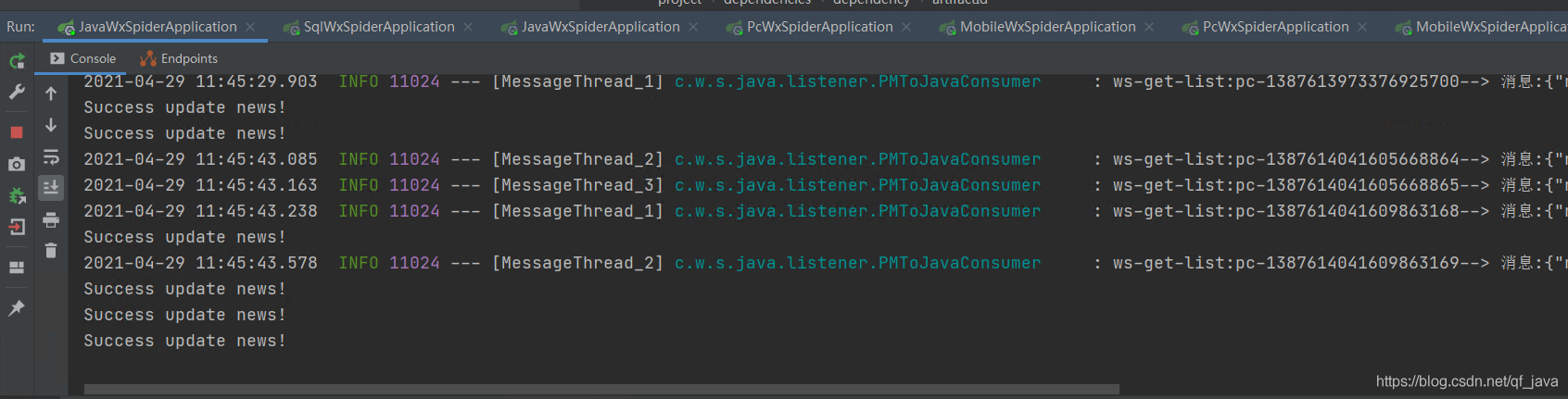
運行結束

總結
專案親測可用現在已經在運行中,并且在專案開發中解決了微信的搜狗臨時鏈接轉永久鏈接問題,希望能對被相似業務困擾的老鐵有所幫助,如今做java如逆水行舟,不進則退,不知什么時候就被卷了進去,祝愿每個人都有一本自己的葵花寶典,看到這還不給個收藏嗎,
直接附上java后端原始碼:ws-spider
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281761.html
標籤:其他
上一篇:Spring學習(一):框架概述
下一篇:ARM匯編指令集