瘋狂創客圈為小伙伴奉上以下珍貴的學習資源:
-
瘋狂創客圈 經典圖書 : 極致經典 《 Java 高并發 三部曲 》 面試必備 + 大廠必備 + 漲薪必備
-
瘋狂創客圈 經典圖書 : 《Netty Zookeeper Redis 高并發實戰》 面試必備 + 大廠必備 +漲薪必備 免費領
-
瘋狂創客圈 經典圖書 : 《SpringCloud、Nginx高并發核心編程》 面試必備 + 大廠必備 + 漲薪必備 免費領
-
瘋狂創客圈 資源寶庫: Java 必備 百度網盤資源大合集 價值>1000元 【免費取 】
瘋狂創客圈 高質量 博文 推薦
| 高并發 必讀 的精彩博文 | |
|---|---|
| nacos 實戰(史上最全) | sentinel (史上最全+入門教程) |
| Zookeeper 分布式鎖 (圖解+秒懂+史上最全) | Webflux(史上最全) |
| SpringCloud gateway (史上最全) | TCP/IP(圖解+秒懂+史上最全) |
| 10分鐘看懂, Java NIO 底層原理 | Feign原理 (圖解) |
| 大廠必備之:Reactor模式 | 更多精彩博文 … 請參見【 瘋狂創客圈 高并發 總目錄 】 |
1 概述
數年來,Netflix 一直是全球體驗最好的在線訂閱制視頻流媒體服務,其流量占全球互聯網帶寬容量的 15%以上, 在2019 年,Netflix 已經有 1.67 億名訂閱用戶,平均每個季度新增 500 萬訂戶,服務覆寫全球 200 多個國家 / 地區,
Netflix 用戶每天在 4000 多部電影和 47000 集電視劇上花費超過 1.65 億小時的時間,從工程角度看,這些統計資料向我們展示了 Netflix 的技術團隊設計出了多么優秀的視頻流系統,而這套系統具有很高的可用性和可擴展性,能為全球用戶提供服務,
實際上,Netflix的技術團隊是花了超過 8 年時間方打造出今天這樣強大的 IT 系統,
以上內容來源:
medium的博文
Netflix 的基礎架構轉型始于 2008 年 8 月,那時這家公司的資料中心遇到了Web服務中斷的故障,導致整個 DVD 租賃服務關閉3天,損失較大,Netflix 的技術團隊如夢方醒,它需要一個沒有單點故障的更可靠的基礎架構,因此技術團隊管理層做出兩個重要決定,將 IT 基礎架構從自己的IDC遷移到公共云上,通過改造成微服務架構,用較小的易管理軟體組件替換單體程式,
以上這兩個決定為今天 Netflix 的成功打下了堅實基礎,
任何一個普通的服務,放到 Netflix 的大規模集群(上萬臺機器)里運行,如果不做特別處理,會發生各種各樣的問題,以實作一個電影推薦的服務為例,傳統方案:
在傳統的方案里,你會使用固定 DNS 域名決議服務,將一組固定的 IP 放在負載均衡的串列里,服務注冊和發現都是寫在組態檔里,一旦服務掛掉了,依賴于這個服務的其他服務都會受到影響,傳統的辦法只能新起一臺服務器,然后去改變其他機器的組態檔,并重啟關聯的服務,
在小的集群里這種方式或許可以忍受,但在上萬臺服務器的集群里,管理500多種服務的時候,情況將變得非常復雜,Netflix 通過多年的實踐,貢獻出了很多開源專案,例如:Eureka, Hystrix, Feign,Ribbon 等等, 來解決大規模集群里服務管理的問題,
說明:Netflix 的微服務有500多種,這些微服務的實體運行在上萬臺的機器上,有上萬個實體,
Netflix 之所以選擇 AWS 云來遷移其 IT 基礎架構,是由于 AWS 可以在全球范圍內提供高度可靠的資料庫、大規模云存盤和眾多資料中心,Netflix 利用了由 AWS 構建和維護的云基礎架構,從而免去自建資料中心的繁重重復勞動,并將更多精力放在提供高質量視頻流體驗的核心業務上,盡管 Netflix 需要重構整個技術體系,以使其能在 AWS 云上平穩運行,但作為回報,系統的可擴展性和服務可用性得到明顯地提高,
Netflix 還是微服務架構背后的首批主要推動者之一,微服務鼓勵關注點分離來解決單體軟體設計存在的問題,在這種架構中,大型程式通過模塊化和獨立的資料封裝被分解為許多較小的軟體組件,微服務還通過水平擴展和作業負載磁區來提升可擴展性,采用微服務后,Netflix 工程師可以輕松更改任何服務,從而加快部署速度,更重要的是,他們能跟蹤每個服務的性能水平,并在其出現問題時與其他正在運行的服務快速隔離開來,
2 架構
Netflix 基于亞馬遜云計算服務(AWS云),及公司內部的內容交付網路:Open Connect 運營,兩套系統必須無縫協作才能在全球范圍內提供高質量的視頻流服務,
從軟體架構的角度來看,Netflix 包括三大部分:客戶端、后端和內容交付網路(CDN),
客戶端是用戶筆記本電腦或臺式機上所有受支持的瀏覽器,或者智能手機 / 智能電視上的 Netflix 應用,Netflix 開發了自己的 iOS 和 Android 應用,試圖為每個客戶端和每臺設備都能提供最佳的觀看體驗,Netflix 可以通過其 SDK 控制自己的應用和其他設備,從而在某些場景下(例如網路速度緩慢或服務器超載)透明地調整流服務,
后端包括完全在 AWS 云上運行的服務、資料庫和存盤,后端基本上可以處理不涉及流視頻的所有內容,后端的某些組件及其對應的 AWS 服務列舉如下:
- 可擴展計算實體(AWS EC2)
- 可擴展存盤(AWS S3)
- 業務邏輯微服務(Netflix 專用框架)
- 可擴展的分布式資料庫(AWS DynamoDB、Cassandra)
- 大資料處理和分析作業(AWS EMR、Hadoop、Spark、Flink、Kafka 和一些 Netflix 專用工具)
- 視頻處理和轉碼(Netflix 專用工具)
Open Connect CDN 是稱為 Open Connect Appliances(OCAs)的服務器網路,已針對存盤和流傳輸大尺寸視頻進行了優化,這些 OCA 服務器放置在世界各地的互聯網服務提供商(ISP)和互聯網交換位置(IXP)網路內,OCA 負責將視頻直接流傳輸到客戶端,
2.1 Playback 架構
當訂閱者單擊應用或設備上的播放按鈕時,客戶端將與 AWS 上的后端和 Netflix CDN 上的 OCA 對話以流傳輸視頻,下圖說明了 playback 流程的作業機制:
用于流視頻的 playback 架構:
- OCA 不斷將關于其負載狀態、可路由性和可用視頻的運行狀況報告發送到在 AWS EC2 中運行的快取控制(Cache Control)服務上,以便 Playback 應用向客戶端更新最新的健康 OCA,
- 播放(Play)請求從客戶端設備發送到在 AWS EC2 上運行的 Netflix 播放應用服務,以獲取流視頻的 URL,
- Playback 應用服務必須確定播放請求是有效的,才能觀看特定視頻,這里的驗證流程將檢查用戶的訂閱計劃,以及在不同國家 / 地區的視頻許可等,
- Playback 應用服務會與同在 AWS EC2 中運行的引導(Steering) 服務對話,以獲取所請求視頻的合適的 OCA 服務器串列,引導服務使用客戶端的 IP 地址和 ISP 資訊來確定一組最適合該客戶端的 OCA,
- 客戶端從 Playback 應用服務回傳的 10 個 OCA 服務器的串列中測驗這些 OCA 的網路連接質量,并選擇最快、最可靠的 OCA 來請求視頻檔案,進行流傳輸,
- 選定的 OCA 服務器接受來自客戶端的請求并開始流傳輸視頻,
在上圖中,Playback 應用服務、引導服務和快取控制服務完全在基于微服務架構的 AWS 云中運行,在下一節中我將介紹 Netflix 后端微服務架構,該架構可提高當前服務的可用性和可擴展性,
2.2 后端架構
如前所述,后端要處理幾乎所有內容,從注冊、登錄、計費到更復雜的處理任務,如視頻轉碼和個性化推薦等無所不包,為同時支持在同一底層基礎架構上運行的輕量與重量級負載,Netflix 為其基于云的系統選擇了微服務架構,圖 2 展示了 Netflix 可能使用的微服務架構,我從一些在線資源中總結出了這些架構形態:
基于多種后端架構參考:
- 客戶端向在 AWS 上運行的后端發送一個播放請求,該請求由 AWS 負載均衡器(ELB)處理,
- AWS ELB 會將請求轉發到在 AWS EC2 實體上運行的 API 網關服務上,名為 Zuul 的組件是由 Netflix 團隊構建的,提供動態路由、流量監控和安全性,以及對云部署邊緣故障的恢復能力,該請求將應用在與業務邏輯對應的一些預定義過濾器上,然后轉發到應用程式(Application)API 做進一步處理,
- 應用程式 API 組件是 Netflix 運營背后的核心業務邏輯,有幾種型別的 API 對應不同的用戶活動,如注冊 API 和用于檢索視頻推薦的推薦 API 等,在這里,來自 API 網關服務的轉發請求由播放 API 處理,
- 播放 API 將呼叫一個或一系列微服務來滿足請求,圖 1 中的播放應用服務、引導服務和快取控制服務可以視為微服務,
- 微服務主要是無狀態的小型程式,并且也可以相互呼叫,為了控制其級聯故障并獲得彈性, Hystrix 將每個微服務與呼叫者行程隔離開來,其運行結果可以快取在基于記憶體的快取中,以更快地訪問那些關鍵的低延遲請求,
- 微服務能在流程中保存到資料存盤或從資料存盤中獲取資料,
- 微服務可以將用于跟蹤用戶活動或其他資料的事件發送到流處理管道(Stream Processing Pipeline),以實時處理個性化推薦任務,或批處理業務智能任務,
- 來自流處理管道的資料能持久存盤到其他資料存盤中,如 AWS S3、Hadoop HDFS 和 Cassandra 等,
上述架構可以幫助我們概括了解系統的各個部分如何組織和協同作業以流傳輸視頻,但要分析這一架構的可用性和可擴展性,我們需要深入研究每個重要組件,以了解其在不同負載下的性能表現,下一節將具體介紹這部分內容,
3 組件
本節會深入研究第 2 節中定義的組件,以分析其可用性和可擴展性,在介紹每個組件時,我還將說明它們是如何滿足這些設計目標的,在后面的章節中將對整個系統進行更深入的設計分析,
3.1 客戶端
Netflix 技術團隊投入了大量精力來開發能在筆記本、臺式機或移動設備上運行得更快、更智能的客戶端應用,即使在某些沒有專用 Netflix 客戶端的智能電視上,Netflix 仍然可以通過自己提供的 SDK 來控制設備的性能表現,實際上,任何設備環境都需要安裝 Netflix Ready Device Platform(NRDP),以實作最佳的觀看體驗,圖 3 展示了一個典型的客戶端結構組件,
客戶端應用組件
- 客戶端應用(Client App)會將自己與后端的連接分為 2 種型別,分別用于內容發現(Content discovery)和內容播放,客戶端對播放請求使用 NTBA 協議,以確保其 OCA 服務器位置具有更高的安全性,并消除了新連接的 SSL/TLS 握手引起的延遲,
- 在流傳輸視頻時,如果網路連接過載或出現錯誤,客戶端應用會智能地降低視頻質量或切換到其他 OCA 服務器上,即使連接的 OCA 過載或出現故障,客戶端應用也可以輕松切換為其他 OCA 服務器,以獲得更好的觀看體驗,之所以客戶端能實作所有這些目標,是因為其上的 Netflix Platform SDK 一直在跟蹤從播放應用服務中檢索到的最新健康 OCA 串列,
3.2 后端
API 網關服務
API 網關服務(API Gateway Service)組件與 AWS 負載均衡器(Load Balancer)通信以決議來自客戶端的所有請求,該組件可以部署到位于不同區域的多個 AWS EC2 實體上,以提高 Netflix 服務的可用性,圖 4 展示了開源的 Zuul,這是 Netflix 團隊創建的 API 網關的實作,
Zuul 網關服務組件
- 入站過濾器(Inbound Filter)可用于身份驗證、路由和裝飾請求,
- 端點過濾器(Endpoint Filter)可用于回傳靜態資源或將請求路由到適當的 Origin 或應用程式 API 做進一步處理,
- 出站過濾器(Outbound Filter)可用于跟蹤指標、裝飾對用戶的回應或添加自定義標頭,
- Zuul 集成了服務發現組件 Eureka ,從而能夠發現新的應用程式 API,
- Zuul 被廣泛用于各種用途的流量路由任務上,例如啟用新的應用程式 API、負載測驗、在負載很大的情況下路由到不同的服務端點上,等等,
應用程式 API
應用程式 API 充當 Netflix 微服務的業務流程層(也稱編排層),這種 API 提供了一種邏輯,按所需順序組裝對底層微服務的呼叫,并帶有來自其他資料存盤的額外資料以構造適當的回應,Netflix 團隊花了很多時間設計應用程式 API 組件,因為它對應 Netflix 的核心業務功能,它還需要在高請求量下具有可擴展和高可用性,當前,應用程式 API 分為三類:用于非會員請求(例如注冊、下單和免費試用等)的注冊(Signup)API,用于搜索和發現請求的發現(Discovery)API,以及用于流視頻和查看許可請求的播放 API,圖 5 提供了應用程式 API 的詳細結構組件圖,
播放和發現應用程式 API 的分離
- 在播放 API 實作的最新更新中,播放 API 和微服務之間的網路協議是 gRPC/HTTP2,它“允許通過協議緩沖區定義 RPC 方法和物體,并自動以多種語言生成客戶端庫 /SDK”,此項更改使應用程式 API 可以通過雙向通信與自動生成的客戶端進行適當集成,并“盡可能減少跨服務邊界的代碼重用”,
- 應用程式 API 還提供了一種基于 Hystrix 命令的通用彈性機制,以保護其底層微服務,
由于應用程式 API 必須處理大量請求并構造適當的回應,因此其內部處理作業需要高度并行運行,Netflix 團隊發現正確的方法是同步執行和異步 I/O 相結合應用,
應用程式 API 的同步執行和異步 I/O
- 來自 API 網關服務的每個請求都將放入應用程式 API 的網路事件回圈(Network Event Loop)中處理;
- 每個請求將被一個專用的執行緒處理程式阻止,該處理程式將 Hystrix 命令(如 getCustomerInfo 和 getDeviceInfo 等)放入傳出事件回圈(Outgoing Event Loop)中,傳出事件回圈是針對每個客戶端設定的,并以非阻塞 I/O 運行,一旦呼叫的微服務完成或超時,上述專用執行緒將構造對應的回應,
微服務
按照 Martin Fowler 的定義,“微服務是一組小型服務,每個小服務都在自己的行程中運行,并使用輕量機制通信……”,這些小型程式可以獨立部署或升級,并具有自己的封裝資料,
Netflix 上的微服務組件實作如圖 7 所示,
微服務的結構微服務化組件
- 微服務可以獨立作業,也能通過 REST 或 gRPC 呼叫其他微服務,
- 微服務的實作可以類似于圖 6 中描述的應用程式 API 的實作:請求將被放入網路事件回圈中,而來自其他被呼叫的微服務的結果將放入異步非阻塞 I/O 中的結果佇列,
- 每個微服務能擁有自己的資料存盤和一些存放近期結果的記憶體快取存盤,EVCache 是Netflix 微服務快取的主要選擇,
資料存盤
Netflix 將其基礎架構遷移到 AWS 云時,針對不同的用途使用了不同的資料存盤(圖 8),包括 SQL 和 NoSQL,
部署在 AWS 上的 Netflix 資料存盤
- MySQL 資料庫用于電影標題管理和交易 / 下單目的,
- Hadoop 用于基于用戶日志的大資料處理,
- ElasticSearch 為 Netflix 應用提供了標題搜索能力,
- Cassandra 是基于列的分布式 NoSQL 資料存盤,可處理大量讀取請求,而沒有單點故障,為了優化大規模寫請求的延遲,Netflix 使用了 Cassandra,因為它具有最終的一致性能力,
流處理管道
流處理資料管道(Stream Processing Data Pipeline)已成為 Netflix 業務分析和個性化推薦任務的資料骨干,它負責實時生成、收集、處理和匯總所有微服務事件,并將其移動到其他資料處理器上,圖 9 展示了該平臺的各個部分,
Netflix 的 Keystone 流處理平臺
- 這一流處理平臺每天處理數以萬億計的事件和 PB 級的資料,隨著訂戶數量的增加,它也會自動擴展,
- 路由(Router)模塊支持路由到不同的資料 sink 或應用程式上,而 Kafka 負責路由訊息,并為下游系統提供緩沖,
- 流處理即服務(SPaaS)使資料工程師可以構建和監視他們自定義的可管理流處理應用程式,而平臺將負責可擴展性和運維,
3.3 Open Connect
Open Connect 是一個全球內容交付網路(CDN),負責存盤 Netflix 電視節目和電影并將其交付給全世界的訂戶,Netflix 為了讓人們想要觀看的內容盡可能靠近他們想要觀看的位置,而構建和運營了 Open Connect 這一高效率的網路,為了將觀看 Netflix 視頻的流量導向到客戶的當地網路中,Netflix 已與世界各地的互聯網服務提供商(ISP)和互聯網交換點(IX 或 IXP)合作,以在這些合作伙伴的網路內部部署稱為 Open Connect Appliances(OCA)的專用設備,
將 OCA 部署到 IX 或 ISP 站點
OCA 是經過優化的服務器,用于存盤來自 IX 或 ISP 站點的大型視頻檔案,并直接流式傳輸到訂戶的家中,這些服務器會定期向 AWS 上的 Open Connect 控制平面(Control Plane)服務報告自己的運行狀況指標,包括它們從 IXP/ISP 網路學到的最佳路徑,以及自己的 SSD 上都存盤了哪些視頻等資訊,反過來,控制平面服務將根據這些資料中反映的檔案可用性、服務器健康狀況以及與客戶端的網路距離等指標,自動引導客戶端設備到最佳的 OCA 上,
控制平面服務還控制每晚在 OCA 上添加新檔案或更新檔案的填充(filling)行為,填充行為如圖 11 所示,
-
當新的視頻檔案已成功轉碼并存盤在 AWS S3 上時,AWS 上的控制平面服務會將這些檔案傳輸到 IXP 站點上的 OCA 服務器上,這些 OCA 服務器將應用快取填充(cache fill),將這些檔案傳輸到其子網下 ISP 站點上的 OCA 服務器上,
-
當 OCA 服務器成功存盤視頻檔案后,它將能夠啟用對等填充(peer fill),以根據需要將這些檔案復制到同一站點內的其他 OCA 服務器上,
-
在可以看到彼此 IP 地址的 2 個不同站點之間,OCA 可以應用層填充(tier fill)流程,而不是常規的快取填充,
OCA 之間的填充模式
4 設計目標
在前面的章節中,我詳細介紹了為 Netflix 視頻流業務提供支持的云架構及其組件,在本節和后續章節中,我想更深入地分析這種設計架構,我會從最重要的設計目標串列開始,如下所示:
- 確保全球范圍內流服務的高可用性,
- 彈性處理網路故障和系統中斷,
- 在各種網路條件下,將每臺受支持設備的流傳輸延遲降至最低,
- 支持高請求量的可擴展性,
在下面的小節中,我將分析流服務的可用性及其對應的最佳延遲,第 6 節是關于彈性機制(例如混沌工程)的更深入分析,而第 7 節介紹了流服務的可擴展性,
4.1 高可用性
根據定義,系統的可用性是用一段時間內對請求的回應有多少次來衡量的,但不能保證回應包含了資訊的最新版本,在我們的系統設計中,流服務的可用性是由后端服務和保存流視頻檔案的 OCA 服務器的可用性共同決定的,
后端服務的目標是通過快取或某些微服務的執行來獲取最接近特定客戶端的健康 OCA 串列,因此,其可用性取決于涉及播放請求的眾多組件:負載均衡器(AWS ELB)_ 代理服務器(API 網關服務)、播放 API、微服務的執行、快取存盤(EVCache)和資料存盤(Cassandra):
- 負載均衡器可以將流量路由到不同的代理服務器上以幫助防止負載超載,從而提高可用性,
- 播放 API 通過 Hystrix 命令控制超時微服務的執行,從而防止級聯故障影響其他服務,
- 如果微服務對外部服務或資料存盤的呼叫所花費的時間超出預期,則它可以使用快取中的資料回應播放 AI,
- 快取會被復制以加快訪問速度,
當客戶端從后端接收到 OCA 服務器串列時會在網路上探測這些 OCA,并選擇最佳的 OCA 進行連接,如果該 OCA 在流處理程序中超載或失敗,則客戶端將切換到另一個狀態良好的 OCA 上,否則 Platform SDK 將請求其他 OCA,因此,其可用性與 ISP 或 IXP 中所有可用 OCA 的可用性高度相關,
Netflix 流服務的高可用性是以復雜的多區域 AWS 運維和服務,以及 OCA 服務器的冗余為代價的,
4.2 低延遲
流服務的等待時間主要取決于播放 API 能多快地決議健康的 OCA 串列,以及客戶端與所選 OCA 服務器的連接健康水平,
正如我在應用程式 API 組件部分中所述,播放 API 不會永遠等待微服務的執行,因為它使用 Hystrix 命令來控制獲取到結果之前要等待的時間,一旦超時就會從快取獲取非最新資料,這樣做可以將延遲控制在可接受的水平上,還能避免級聯故障影響更多服務,
如果當前選定的 OCA 服務器出現網路故障或超載,則客戶端將立即切換到其他具有最可靠網路連接的 OCA 服務器上,如果發現網路連接質量下降,它也可以降低視頻質量以使其與網路質量相匹配,
5 權衡
經過認真考慮,在上述系統設計中已經做出了兩個重要的權衡:
- 用一致性換取低延遲
- 用一致性換取高可用性
該系統后端服務的架構設計選擇了用一致性來換取低延遲,播放 API 可以從 EVCache 存盤或最終一致的資料存盤(如 Cassandra)中獲取過時的資料,
類似地,所謂用一致性換取高可用性的權衡是說,系統希望以可接受的延遲發起回應,而不會對像 Cassandra 這樣的資料存盤中的最新資料執行微服務,
在可擴展性和性能之間還存在不完全相關的權衡,在這種權衡下,通過增加實體數量來處理更多負載來提高可擴展性,可能會導致系統達不到預期的性能提升水平,對于那些無法在可用 worker 之間很好地平衡負載的設計架構來說,這可能是個問題,但是,Netflix 通過 AWS 自動擴展解決了這一矛盾,我們將在第 7 節中具體討論這個解決方案,
6 彈性
從遷移到 AWS 云的那一天起,設計一套能夠從故障或停機中自我恢復的云系統就一直是 Netflix 的長期目標,該系統已解決的一些常見故障如下:
決議服務依賴項時失敗,
執行微服務時的失敗,導致級聯失敗影響其他服務,
由于過載導致無法連接到某個 API 上,
連接到實體或服務器(如 OCA)時失敗,
為了檢測并解決這些故障,API 網關服務 Zuul 提供了一些內置功能,如自適應重試和限制對應用程式 API 的并發呼叫等,反過來說,應用程式 API 使用 Hystrix 命令來使對微服務的呼叫超時,以停止級聯故障并將故障點與其他服務隔離開來,
Netflix 技術團隊也以其在混沌工程上的實踐而聞名,這個想法是將偽隨機錯誤注入生產環境,并構建解決方案以自動檢測、隔離這類故障,并從中恢復,這些錯誤可能會增加執行微服務的回應的延遲、殺死服務、停止服務器或實體,甚至可能導致整個區域的基礎架構癱瘓,通過有目的地使用檢測和解決此類故障的工具,將現實的生產故障引入受監控的環境,Netflix 可以在這類缺陷造成較大問題之前提早發現它們,
7 可擴展性
在本節中,我將介紹水平擴展、并行執行和資料庫磁區這些 Netflix 的流服務可擴展性要素,快取和負載均衡等要素也有助于提高可擴展性,它們已在第 4 節中提到了,
首先,AWS 自動擴展(Auto Scaling)服務提供了 Netflix 上 EC2 實體的水平擴展能力,當請求量增加時,這個 AWS 服務將自動啟動更多彈性實體,并關閉未使用的實體,更具體地說,在成千上萬個此類實體的基礎上,Netflix 構建了一個開源容器管理平臺 Titus,其每周可運行約 300 萬個容器,同樣,圖 2 架構中的任何組件都可以部署在容器內,此外,Titus 允許容器運行在全球各大洲的多個區域內,
其次,第 3.2.2 節中應用程式 API 或微服務的實作還允許在網路事件回圈和異步傳出事件回圈上并行執行任務,從而提高了可擴展性,
最后,寬列存盤(如 Cassandra)和鍵值物件存盤(如 ElasticSearch)還提供了高可用性和高可擴展性,同時沒有單點故障,
8 線上發布的方式:
金絲雀、藍綠、紅黑灰發布
8.1發布之痛
相信每個程式員都曾經經歷過,或正在經歷過發布的痛苦,每個發布日的夜晚通常是燈火通明,在現在互聯網公司較高的發布頻率之下更是放大了這種痛苦,多少正值青春年華的程式員為此白了發、禿了頭!讓程式員經歷發布痛苦的原因有很多,其中之一就是發布方式,
發布造成系統故障影響系統可用性的最大原因之一,因此大多數的公司會選擇在用戶量最小的深夜進行發布,這就造成了每到發布日就有一大堆黑眼圈的程式員熬夜坐等發布,但其實有了一些好的發布方式也許就不必如此,
我曾經帶過兩家公司,這兩家公司團隊的對于發布時間的看法則孑然不同,第一家公司的總是擔心發布會對用用戶造成影響,因此每次發布都會選擇深夜進行發布,而另一家公司則認為應該在用戶流量最大的時候進行發布,這樣系統問題則可以盡早的暴露出來,造成這兩種的結果我分析有很多原因,開發人員信心、交付質量、資源工具、發布方式…我們今天就來看看一些常用的發布方式,
8.2 常用的發布方式
蠻力發布
顧名思義,這種方式簡單而粗暴!直接將新的版本覆寫掉老的版本,其優點就是簡單而且成本較低,但缺點同樣很明顯,就是發布程序中通常會導致服務中斷進而導致用戶受到影響,這種方式比較適應于開發環境或者測驗環境或者是公司內部系統這種對可用性要求不高的場景,有些小的公司資源稀缺(服務器資源,基礎設施等)的時候也會采用這種方式,比如小公司開始的規模較小的時候,通常會選擇一個夜深人靜、訪問量小的時候,悄悄地發布,
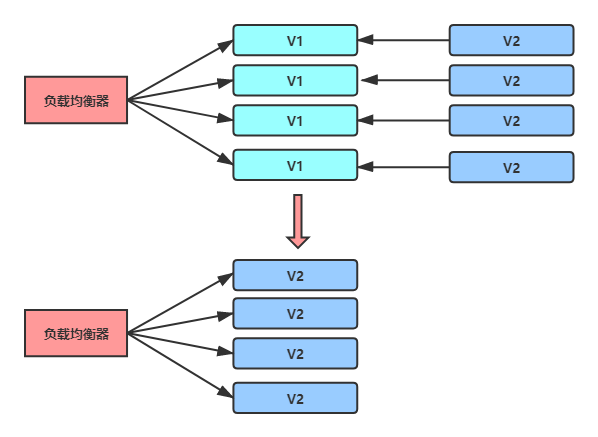
金絲雀發布
金絲雀發布是灰度發布的一種,灰度發布是指在黑與白之間,能夠平滑過渡的一種發布方式,即在發布程序中一部分用戶繼續使用老版本,一部分用戶使用新版本,不斷地擴大新版本的訪問流量,最終實作老版本到新版本的過度,由于金絲雀對瓦斯極其敏感,因此以前曠工開礦下礦洞前,先會放一只金絲雀進去探是否有有毒氣體,看金絲雀能否活下來,金絲雀發布由此得名,
發布程序中,先發一臺或者一小部分比例的機器作為金絲雀,用于流量驗證,如果金絲雀驗證通過則把剩余機器全部發掉,如果金絲雀驗證失敗,則直接回退金絲雀,金絲雀發布的優勢在于可以用少量用戶來驗證新版本功能,這樣即使有問題所影響的也是很小的一部分客戶,如果對新版本功能或性能缺乏足夠信心那么就可以采用這種方式,這種方式也有其缺點,金絲雀發布本質上仍然是一次性的全量發布,發布程序中用戶體驗并不平滑,有些隱藏深處的bug少量用戶可能并不能驗證出來問題,需要逐步擴大流量才可以,
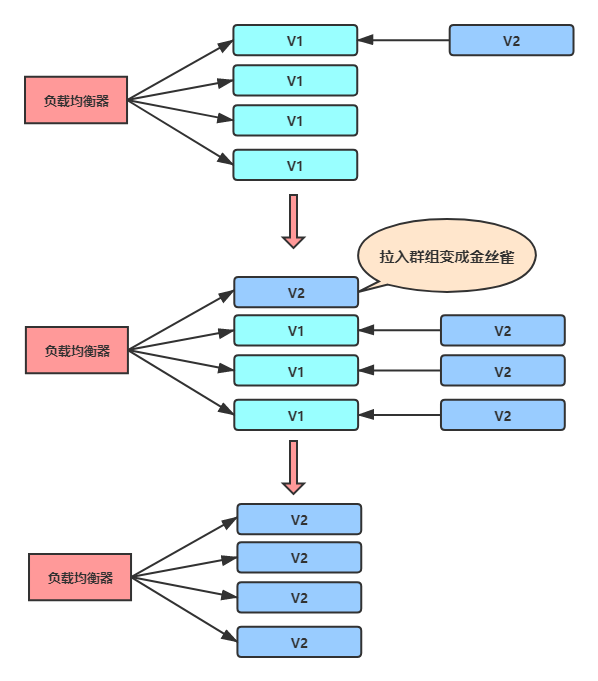
滾動發布
滾動發布是在金絲雀發布基礎上進行改進的一種發布方式,相比于金絲雀發布,先發金絲雀,然后全發的方式,滾動發布則是整個發布程序中按批次進行發布,每個批次拉入后都可作為金絲雀進行驗證,這樣流量逐步放大直至結束,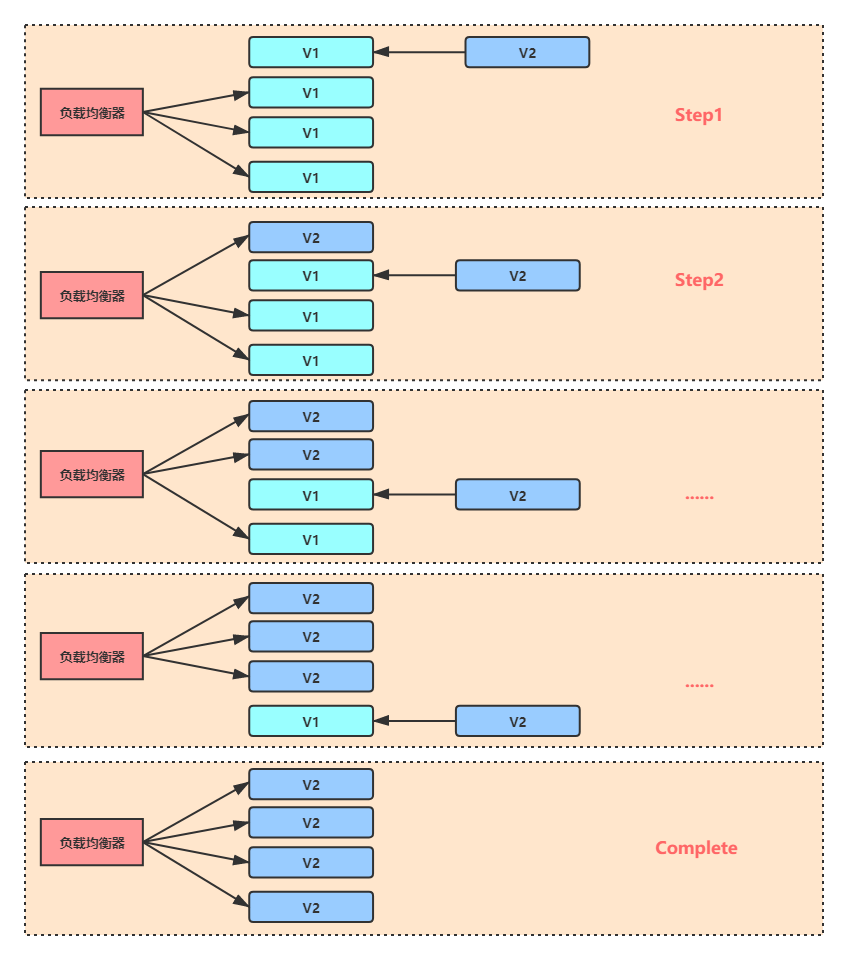
這種方式的優點就是對用戶的影響小,體驗平滑,但同樣也有很多缺點,首先就是發布和回退時間慢,其次發布工具復雜,負載均衡設備需要具有平滑的拉入拉出能力,一般公司并沒有資源投入研發這種復雜的發布工具,再者
發布程序中新老版本同時運行,需要注意兼容性問題,
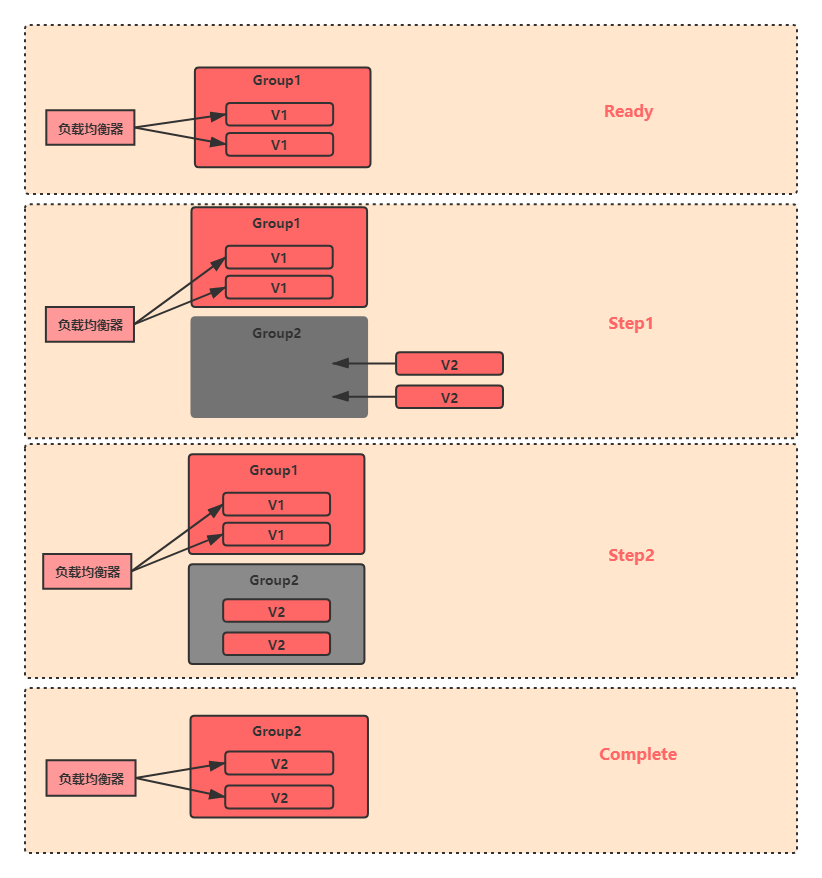
藍綠部署
藍綠部署,是采用兩個分開的集群對軟體版本進行升級的一種方式,它的部署模型中包括一個藍色集群 Group1 和一個綠色集群 Group2,在沒有新版本上線的情況下,兩個集群上運行的版本是一致的,同時對外提供服務,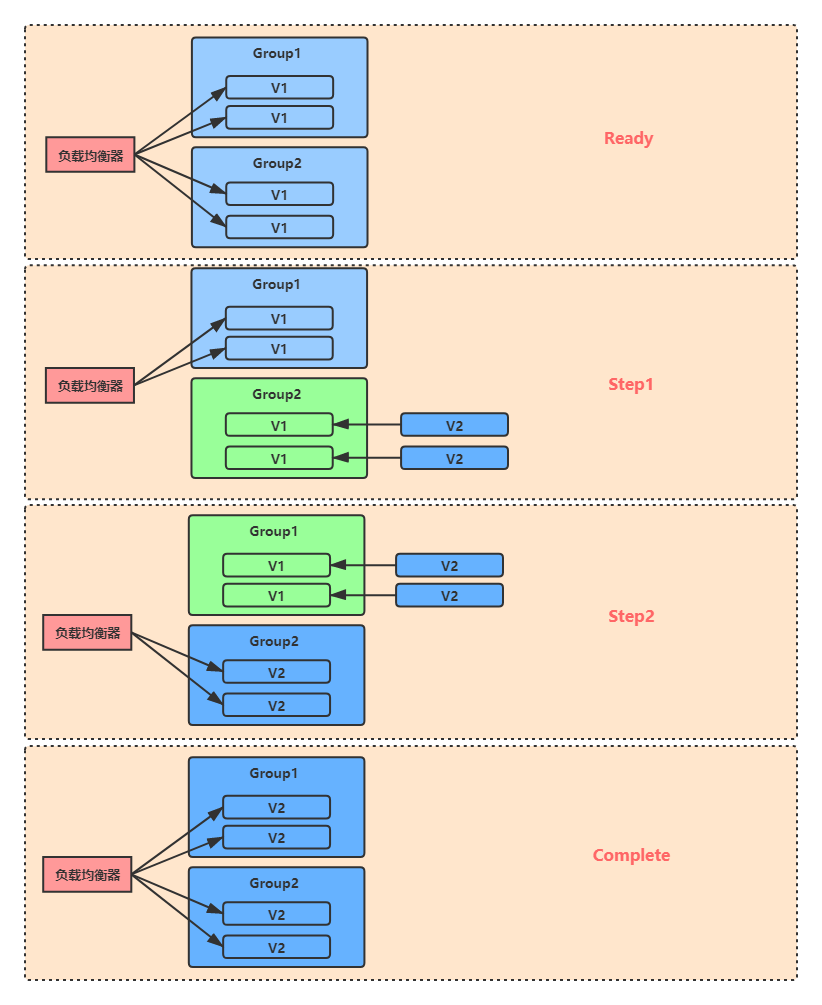
系統升級時,藍綠部署的流程是:
- 從負載均衡器串列中洗掉集群Group1,讓集群 Group2 單獨提供服務,
- 在集群 Group1 上部署新版本,
- 集群 Group1 升級完畢后,把負載均衡串列全部指向 Group1,并洗掉集群 Group2 ,由 Group1 單獨提供服務,
- 在集群 Group2 上部署完新版本后,再把它添加回負載均衡串列中,
這樣,就完成了兩個集群上所有機器的版本升級,
藍綠部署的優點是升級和回退速度非常快,缺點是全量升級,如果V2版本有問題,對用戶影響大再者由于升級程序中會服務器資源會減少一半,有可能產生服務器過載問題,因此這種發布方式也不適用于在業務高峰期使用,
紅黑發布
與藍綠部署類似,紅黑部署也是通過兩個集群完成軟體版本的升級,當前提供服務的所有機器都運行在紅色集群 Group1 中,當需要發布新版本的時候,具體流程是這樣的:
-
先申請一個黑色集群 Group2 ,在 Group2 上部署新版本的服務;
-
等到 Group2 升級完成后,我們一次性地把負載均衡全部指向 Group2 ;
-
把 Group1 集群從負載均衡串列中洗掉,并釋放集群 Group1 中所有機器,這這樣就完成了一個版本的升級,
可以看到,與藍綠部署相比,紅黑部署獲得了兩個收益:一是,簡化了流程;二是,避免了在升級的程序中,由于只有一半的服務器提供服務,而可能導致的系統過載問題,但同樣也存在全量升級對用戶的影響問題,也帶來了一個新的問題,就是發布程序中需要兩倍的服務器資源,
功能開關
這種發布方式是利用代碼中的功能開關來控制發布邏輯,是一種相對比較低成本和簡單的發布方式,研發人員可以靈活定制和自助完成的發布方式,這種方式通常依賴于一個配置中心系統,當然如果沒有,可以使用簡單的組態檔,
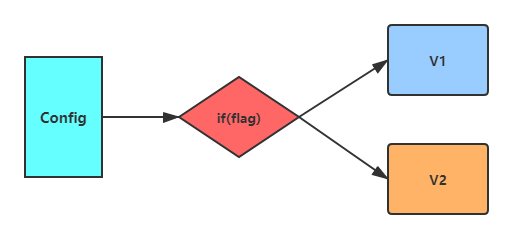
應用上線后,開關先不打開,只待一聲令下,可以全量打開開關,也可以按照某種維度(公司ID,用戶ID等)分批打開開關進行流量驗證,如果有問題,則隨時關閉開關,
這種方式的優勢在于升級切換和回退速度非常快,而且相對于復雜的發布工具,成本較為低廉,但是也有很大的不足之處,就是開關本身也是代碼,而且是與業務無關的代碼,對代碼的侵入性較高,也必須定期清理老版本的邏輯,使得維護成本增加,
發布方式小結
每種發布方式各有其優缺點,但其實在真正實踐程序中這些發布方式往往是根據具體的情況來結合使用的,主要可以通過升級回退速度、成本、對用戶影響三個方面來考慮,
8.3 Eureka 紅黑發布
Eureka 解決的問題
Eureka 服務器是服務的注冊中心,它能提高大規模集群環境里服務發現的容錯性和可用性,并且可以解決跨資料中心之間的服務注冊和發現的問題,
Netflix 推薦在每個 Region 搭建一個 Eureka 集群,每個 Region 里的可用區至少有一個 Eureka Server,這樣可以保證任意一個可用區的服務注冊資訊都會被復制到各個可用區,實作服務資訊的高可用,在任意可用區的客戶端都可以訪問到服務的注冊資訊,客戶端在訪問服務器之后會在本地快取服務的資訊,并且定期(30秒)重繪服務的狀態,
如果在集群內有大面積的網路故障時(例如由于交換機故障導致子網之間無法通信),Eureka 會進入自我保護模式,每個Eureka節點會持續的對外提供服務(注:ZooKeeper不會):接收新的服務注冊同時將它們提供給下游的服務發現請求,這樣就可以實作在同一個子網中(Same side of partition),新發布的服務仍然可以被發現與訪問,
在 Eureka V1.0的版本里,Eureka 之間的資料同步是全量同步,每個客戶端都有 Eureka 集群里所有服務的資訊,在 V2.0的版本里,將支持客戶端偏好的服務資訊同步,同時也會增強 Eureka 的讀寫分離和高可用性,
有了 Eureka,Netflix 如何做紅黑發布?
Netflix 發布的方式是紅黑發布,如果監控到線上部署的服務有問題,按傳統方式回滾一個服務需要5-15分鐘,而 Netflix 使用 Eureka 能夠動態的下線/上線一個服務,
服務分兩種:REST 服務和非 REST 服務,如果下線的服務是 REST 服務,那么情況比較簡單,通過 Eureka 可以實時的實作服務的下線和上線,
eureka下線和上線操作(可以通過postman和soapui或者其他http工具來發送命令):
微服務實體下線呼叫方式:PUT
http://ip:8810/eureka/apps/USER-SERVICE/192.168.1.9:user-service:8086/status?value=OUT_OF_SERVICE微服務實體上線呼叫方式:PUT
http://ip:8810/eureka/apps/USER-SERVICE/192.168.1.9:user-service:8086/status?value=UP
Eureka會與Asgard互動 ,完成紅黑發布:
作為與Netflix Asgard一起的紅黑部署 - Asgard一個讓云部署更方便的開源服務,Eureka會與Asgard互動,讓應用在新/老版本部署切換,讓故障處理更快速和無縫 - 尤其是當啟動100個實體部署時要花費很長時間的時候,
來源:https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance
如果服務是非 REST 服務,例如執行 Batching 任務或者快服務的 Transaction 等等,就不能簡單的標記服務下線,借助于 Spring 提供的 EventListener (事件監聽器),Eureka 可以傳遞
EurekaStatusChangeEvent 事件,幫助開發者在這個事件監聽器里去做對應的服務下線處理,
Netflix 在實作紅黑發布的時候,會先將一部分的服務動態下線,如果這些服務有一些 Batching 任務,則通過事件監聽器停掉這些任務,
Netfix在每個區域(region)都會有一個eureka集群,它只知道關于這個區域內的實體資訊,每個zone都至少也有一個eureka服務器來處理zone級別容災,
服務注冊在Eureka上并且每30秒發送心跳來續命,如果一個客戶端在幾次內沒有重繪心跳,它會在90秒后被移出服務器注冊資訊,注冊資訊和重繪資訊會在整個eureka集群的節點進行復制,任何zone的客戶端都可看到注冊資訊(每30秒發生)去定位他們的服務(可能會在任何zone)并做遠程呼叫,
9 總結
本文研究描繪了 Netflix 流服務的整體云架構圖景,另外還從可用性、延遲、可擴展性和對網路故障或系統中斷的適應性方面分析了相應的設計目標,
總體來說,Netflix 的云架構已經過了其生產系統的驗證,可以為在數千個虛擬服務器上運行的數百萬個訂戶提供服務;該架構還通過與 AWS 云服務的集成在全球范圍內提供了高可用性、最佳延遲、強大的可擴展性以及對網路故障和系統故障的恢復能力,
本文提到的大多數架構和組件都是通過互聯網上的可信在線資源學習總結出來的,盡管網上沒有太多資源能直接介紹這些微服務的內部實作,以及監視其性能表現的工具和系統,但本文的研究成果可以作為構建典型生產系統的參考實作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/282905.html
標籤:其他
下一篇:微信小程式自定義組件開發圖文詳解