YARN 架構設計
提示:文章寫完后,目錄可以自動生成,如何生成可參考右邊的幫助檔案
文章目錄
- 一、Hadoop MRv1 不足
- 二、Hadoop YARN 架構演進
- 三、Hadoop YARN 概述
- 四、Hadoop YARN(MRv2)優勢
- 五、YARN 核心組件功能特性分析
- 1.YARN Client
- 2.ResourceManager
- 2.1、用戶互動模塊
- 2.2、NodeManger 管理
- 2.3、ApplicationMaster 管理
- 2.4、Application 管理
- 3. ApplicationMaster
- 4. MRAppMaster
- 5. Scheduler
- 6. NodeManager
一、Hadoop MRv1 不足
原 MapReuce 框架也稱 MRv1,它是一個主從式的架構,主節點 JobTracker 負責集群的資源管理和處理 Client 請求,從節點 TaskTracker 負責管理資源和執行任務,不僅存在 JobTracker 的 SPOF 問題,而且 JobTracker 的負載非常高,集群的資源管理也非常粗暴不合理,
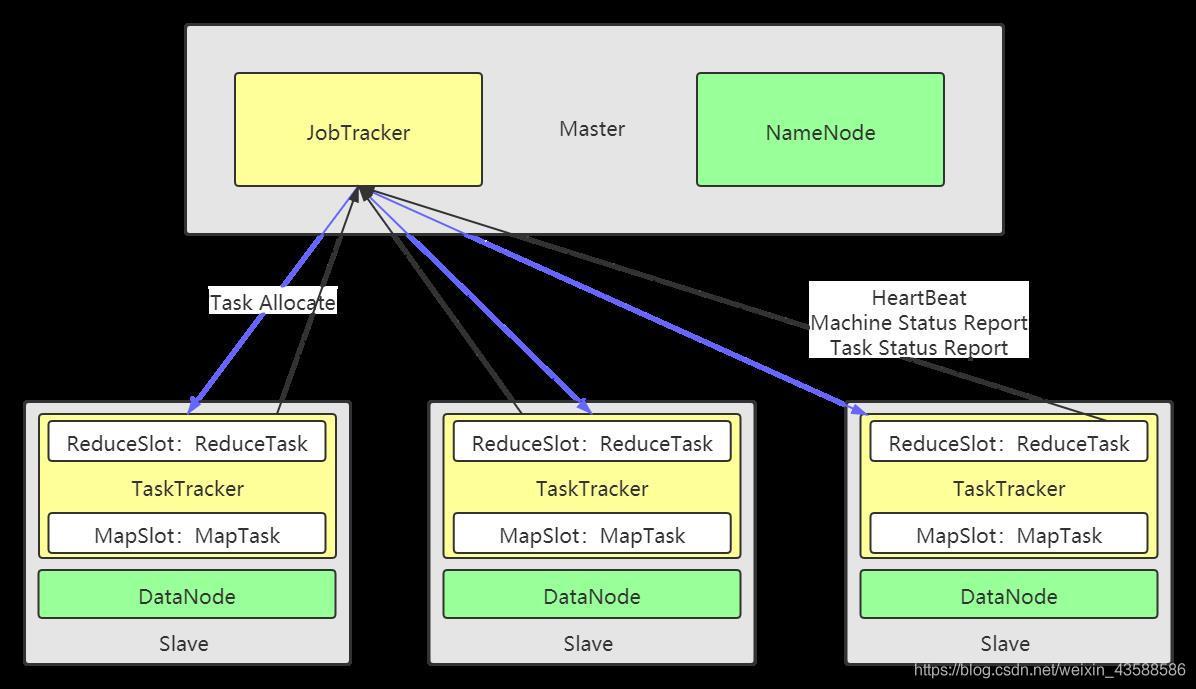
1、單點故障,可靠性低:JobTracker 采用了 master/slave 結構,是集群事務的集中處理點,存在單點故障
2、單點瓶頸,擴展性差:JobTracker 需要完成的任務太多,Jobtracker 兼顧資源管理和作業控制跟蹤功能跟蹤任務,啟動失敗或遲緩的任務,記錄任務的執行狀態,維護計數器),壓力大,成為系統的瓶頸
3、資源管理和任務執行強耦合:在 TaskTracker 端,用 Map/Reduce Task 作為資源的表示過于簡單,沒有考慮到 CPU、記憶體等資源情況,當把兩個需要消耗大記憶體的 Task 調度到一起,很容易出現 OOM
4、資源利用率低:基于槽位的資源分配模型,槽位是一種粗粒度的資源劃分單位,通常一個任務不會用完一個槽位的資源,hadoop1把資源強制劃分為Map/Reduce 兩種Slot,當只有 MapTask 時,Teduce Slot 不能用;當只有 Reduce Task 時,Map Slot 不能用,容易造成資源利用不足,
5、不支持多種分布式計算框架,
二、Hadoop YARN 架構演進
從 Hadoop-2.x 開始,Hadoop 的架構發生了變化:將原來的 MapReduce(資源的管理調度和資料的處理計算) 集群一分為二:MapReduce 和 YARN
- MapReduce:僅僅只是一套用來撰寫分布式計算應用程式的 API
- YARN:是一個 master/slave 架構的分布式集群,用來進行集群的資源管理和調度作業,提供了 job 調度規范,除了能運行MapReduce 應用程式
之外,還可以支持 Spark,Flink 等分布式計算應用程式,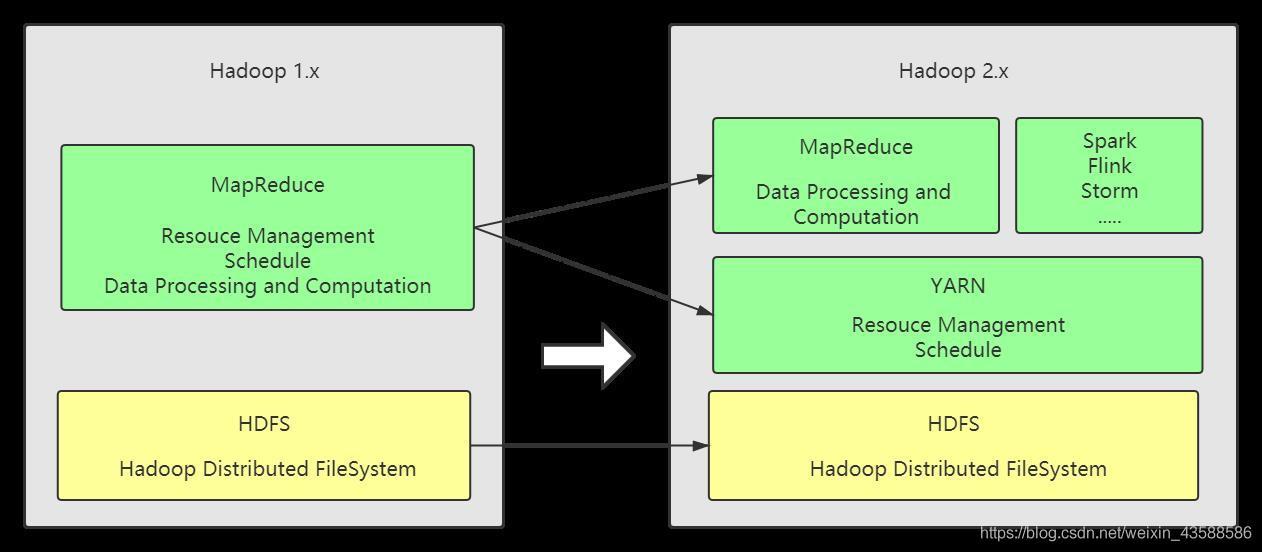
這樣拆分的目的,大大的提高了 Hadoop 平臺的通用性,逐漸演變成一個大資料基礎平臺,甚至可以理解成用來解決大資料問題的分布式作業系統,
Hadoop-2.x 分為四個部分: common, hdfs,mapreduce, yarn
三、Hadoop YARN 概述
YARN,Yet Another Resource Negotiator,是 Hadoop-2.x 版本中的一個新特性,它為上層應用提供統一的資源管理和調度,它的引入為集群在利用率、資源統一管理和資料共享等方面帶來了巨大好處,它的出現其實是為了解決第一代 MapReduce 編程框架的不足,提高集群環境下的資源利用率,這些資源包括記憶體,磁盤,網路,IO等,Hadoop-2.X 版本中重新設計的這個 YARN 集群,具有更好的擴展性,可用性,可靠性,向后兼容性,以及能支持除 MapReduce 以外的更多分布式計算程式,YARN 負責將系統資源分配給在 Hadoop 集群中運行的各種應用程式,并調度要在不同集群節點上執行的任務,它相當于一個分布式的作業系統平臺,而 MapReduce 等運算程式則相當于運行于作業系統之上的應用程式,
YARN 的核心特性:
- YARN 并不清楚用戶提交的程式的運行機制,只是提供了一套資源管理和調度的規范,
- YARN 只提供運算資源的調度(用戶程式向 YARN 申請資源,YARN 就負責分配資源,具體的計算執行邏輯完全由用戶程式決定)
- YARN 是一個 master/slave 的主從機構,依靠 ZooKeeper 實作 HA,主節點叫做ResourceManager,從節點叫做 NodeManager
- YARN 被設計成一個通用的資源管理和作業調度平臺,Spark、Flink 等運算框架都可以整合在 YARN 上運行,只要滿足 YARN 規范的資源請求機制 即可
四、Hadoop YARN(MRv2)優勢
YARN/MRv2 最基本的想法是將原 JobTracker 主要的資源管理和 Job 調度/監視功能分開作為兩個單獨的守護行程,有一個全域的ResourceManager(RM) 和每個Application 有一個 ApplicationMaster(AM),Application 相當于 MapReduce Job 或者 DAG jobs,ResourceManager和 NodeManager(NM) 組成了基本的資料計算框架,ResourceManager 協調集群的資源利用,任何 Client 或者運行著的 ApplicatitonMaster 想要運行Job 或者 Task 都得向 RM 申請一定的資源,ApplicatonMaster 是一個框架特殊的庫,對于 MapReduce 框架而言有它自己的 AM 實作,用戶也可以實作自己的 AM,在運行的時候,AM 會與 NM 一起來啟動和監視 Tasks,
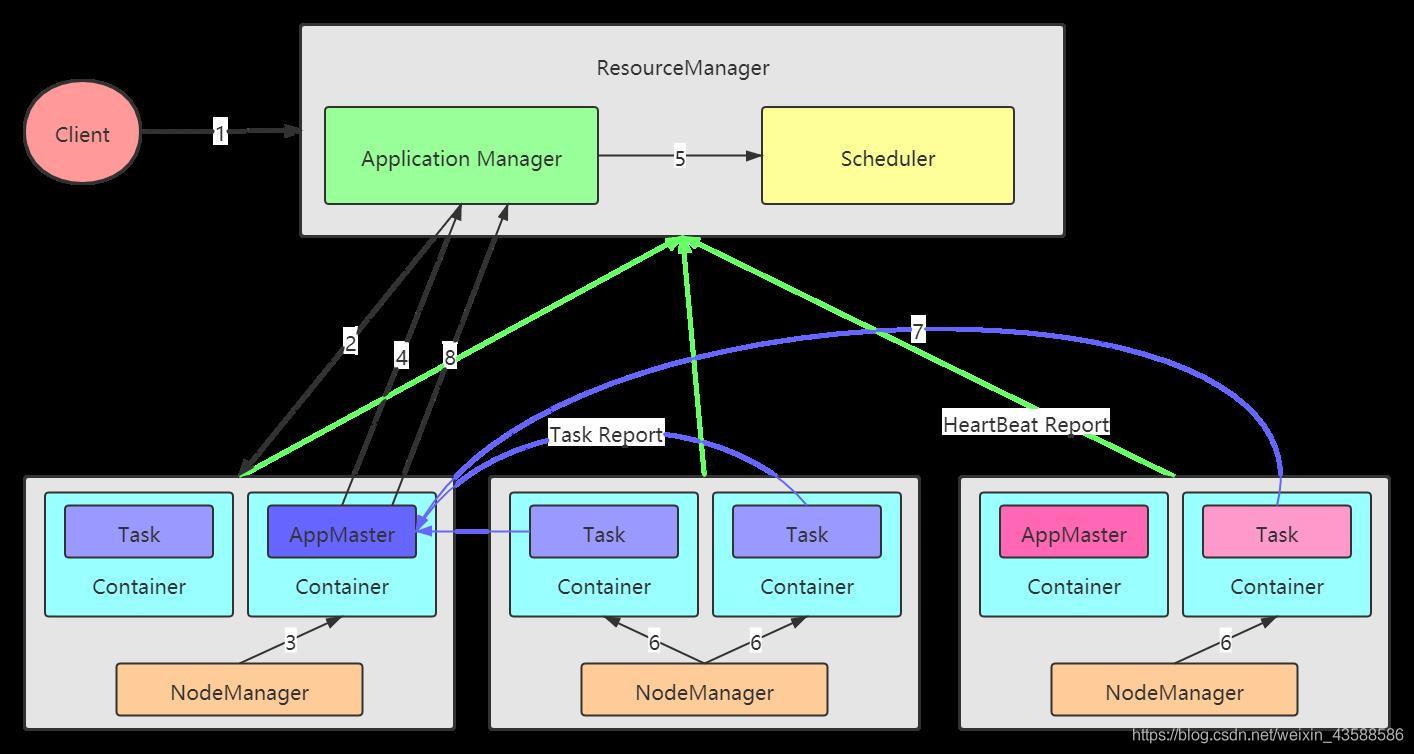
1、極大減小了 JobTracker 的資源消耗,每個應用程式的 ApplicationMaster 都分布式在分布式在整個集群的所有 NodeManager 中了,
2、YARN 中的 ApplicationMaster 只是一個規范,用戶可以把自己的分布式計算應用程式部署到 YARN 上運行,只要滿足 ApplicationMaster 的規范
3、YARN 中的 Container 的資源抽象比 Slot 更合理,老版本的 Slot 分為 mapslot 和 reduceslot,不能混合使用,資源利用率低,
4、借用 ZooKeeper 解決 RM 的 SPOF 問題,老版本的 JobTracker 是存在 SPOF 的問題的,
五、YARN 核心組件功能特性分析
YARN 采用 C/S 架構,主要有一下幾大組件,
1.YARN Client
YARN Client 提交 Application 到 ResourceManager,它會首先創建一個 Application 背景關系件物件,并設定 ApplicationMaster 必需的資源請求資訊,
然后提交到 ResourceManager,YARN Client 也可以與 ResourceManager 通信,獲取到一個已經提交并運行的 Application 的狀態資訊等,
2.ResourceManager
管理者(主節點: 做管理作業) + 作業者(提供計算或者存盤資源的,用來解決實際問題的)
ResourceManager 是一個全域的資源管理器,集群只有一個,有 SPOF 問題,可以通過 ZooKeeper 實作 HA 機制,它主要負責整個系統的資源管理和分配,回應用戶提交的不同型別應用程式的決議,調度,監控等作業,啟動和監控 ApplicationMaster,監控 NodeManager 等,
整體職責決議:
- 處理客戶端請求
- 啟動和監控 ApplicationMaster
- 監控 NodeManager
- 負責資源的分配與調度
內部組成結構如下:
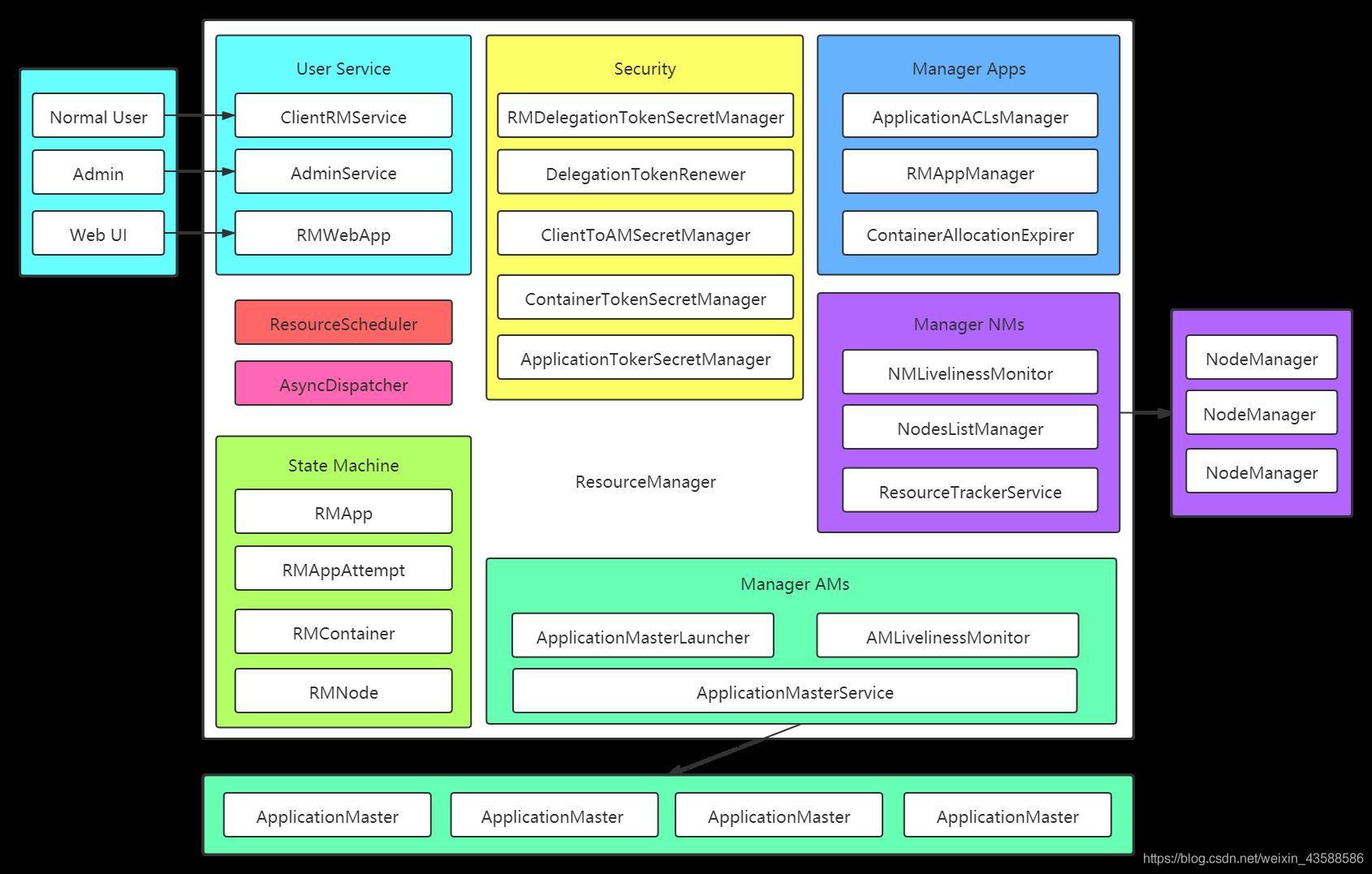
所有的這些 Service 都會經歷三個步驟:
- Service 實體的創建,創建好了之后,放在 CompositeService 的 serviceList 這個成員變數集合中
- 然后遍歷這個 serviceList 集合,取出每個 service 呼叫 serviceInit() 方法
- 然后遍歷這個 serviceList 集合,取出每個 service 呼叫 serviceStart() 方法
關于上述圖中的 ResourceManager 的主要成員的作業職責決議:
2.1、用戶互動模塊
ClientService:是為普通用戶提供的服務,它會處理來自客戶端各種 RPC 請求,比如提交應用程式、終止應用程式,獲取應用程式運行狀態等,
AdminService:YARN 為管理員提供了一套獨立的服務介面,以防止大量的普通用戶請求使管理員發送的管理命令餓死,管理員可通過這些介面管理集群,比如動 態更新節點串列,更新 ACL 串列,更新佇列資訊等,
2.2、NodeManger 管理
NMLivelinessMonitor:監控 NM 是否活著,如果一個 NodeManager 在一定時間(默認10min)內未匯報心跳資訊,則認為它死掉了,會將其從集群中移除,
NodesListManager:維護正常節點和例外節點串列,管理 exlude(類似于黑名單)和 inlude(類似于白名單)節點串列,這兩個串列均是在組態檔中設定 的,可以動態加載,
ResourceTrackerService:處理來自 NodeManager 的請求,主要包括兩種請求:注冊和心跳,其中,注冊是 NodeManager 啟動時發生的行為,請求包中 包含節點ID,可用的資源上限等資訊,而心跳是周期性行為,包含各個 Container 運行狀態,運行的 Application 串列、節點健康狀況(可通過一個腳本設 置),而ResourceTrackerService 則為 NM 回傳待釋放的 Container 串列、Application 串列等,
2.3、ApplicationMaster 管理
AMLivelinessMonitor:監控 AM 是否活著,如果一個 ApplicationMaster 在一定時間(默認為10min)內未匯報心跳資訊,則認為它死掉了,它上面所有 正在運行的Container 將被認為死亡,AM本身會被重新分配到另外一個節點上(用戶可指定每個 ApplicationMaster 的嘗試次數,默認是1次)執行,
ApplicationMasterLauncher:與 NodeManager 通信,要求它為某個應用程式啟動 ApplicationMaster,
ApplicationMasterService:處理來自 ApplicationMaster 的請求,主要包括兩種請求:注冊和心跳,其中,注冊是 ApplicationMaster 啟動時發生 的行為,包括請求包中包含的所在節點,RPC 埠號和 tracking URL 等資訊;而心跳是周期性行為,包含請求資源的型別描述、待釋放的 Container 串列 等,而 AMS 則為之回傳新分配的 Container、失敗的 Container 等資訊,
2.4、Application 管理
ApplicationACLsManager:管理應用程式訪問權限,包含兩部分權限:查看和修改,查看主要指查看應用程式荃本資訊,而修改則主要是修改應用程式優先級、 殺死應用程式等,
RMAppManager:管理應用程式的啟動和關閉,
ContainerAllocationExpirer:YARN 不允許 AM 獲得 Container 后長時間不對其使用,因為這會降低整個集群的利用率,當 AM 收到 RM 新分配的一個 Container 后,必須在一定的時間(默認為10min)內在對應的 NM 上啟動該 Container,否則RM 會回收該Container,
3. ApplicationMaster
一個 Application 運行在 YARN 之上: 主控程式(AM = TL) + 任務程式(Task = TM)
應用程式管理器 ApplicationMaster 負責管理整個系統中所有應用程式,包括應用程式提交、與調度器協商資源以啟動 MRAppMaster、監控MRAppMaster 運行狀態并在失敗時重新啟動它等,
整體職責決議:
- 每個運行在 YARN 內部的 Application 都會啟動一個 ApplicationMaster,負責向
ResourceManger 注冊 Application 和申請 Container - ApplicationMaster 就是運行在 YARN 集群中的 NodeManager 中,相較于 MRv1,不會對
ResourceManager 造成較大的負擔 - 負責整個應用程式的管理,跟 NodeManager 通信啟動或者停止 Task,監控/收集task執行進度結果,或者進行 Task 的容錯
注意 ResourceManager,ApplicationMaster,Task 之間的關系
-
客戶端提交 Job 到 ResourceManager,ResourceManager 會為該 Job 啟動一個ApplicationMaster 來負責這個 Job 中的所有的 Task 的執行,所以 ResourceManager 負責管理 ApplicationMaster
-
啟動的 ApplicationMaster 專門負責一個 Job 的所有的 Task 的啟動,執行,生命周期管理,狀態跟蹤,容錯等等,
4. MRAppMaster
MRAppMaster 就是 MapReduce 的一個 Application 應用程式運行在 YARN 之上的 ApplicationMaster
MRAppMaster 負責管理 MapReduce 作業的生命周期,當客戶端提交一個 MapReduce job 到 YARN 的時候,ResourceManager 會指派一個NodeManager 來啟動一個 MRAppMaster 主控程式,來主持這個 MapReduce Job 的所有 Task 的執行,
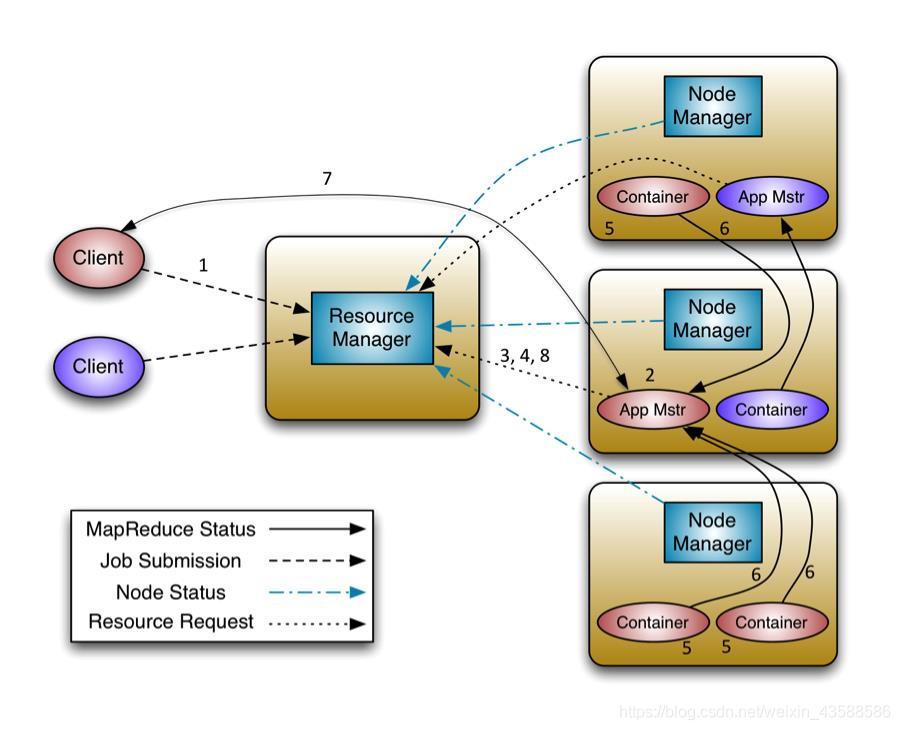
流程決議:
- 步驟1:用戶向 YARN 中提交應用程式,其中包括 ApplicationMaster 程式、啟動 ApplicationMaster 的命令、用戶程式等,
- 步驟2:ResourceManager 為該應用程式分配第一個 Container,并與對應的 NodeManager 通信,要求它在這個Container 中啟動應用程式的ApplicationMaster,
- 步驟3:ApplicationMaster 首先向 ResourceManager 注冊,這樣用戶可以直接通過
ResourceManager 查看應用程式的運行狀態,然后它將為各個任務 申請資源,并監控它的運行狀態,直到運行結束,即重復步驟4~7, - 步驟4:ApplicationMaster 采用輪詢的方式通過 RPC 協議向 ResourceManager 申請和領取資源,
- 步驟5:一旦 ApplicationMaster 申請到資源后,便與對應的 NodeManager 通信,要求它啟動任務,
- 步驟6:NodeManager 為任務設定好運行環境(包括環境變數、JAR包、二進制程式等)后,將任務啟動命令寫到一個腳本中,并通過運行該腳本啟動任務,
- 步驟7:各個任務通過某個 RPC 協議向 ApplicationMaster 匯報自己的狀態和進度,以讓 ApplicationMaster 隨時掌握各個任務的運行狀態,從而可以在 任務失敗時重新啟動任務,在應用程式運行程序中,用戶可隨時通過 RPC 向 ApplicationMaster 查詢應用程式的當前運行狀態,
- 步驟8:應用程式運行完成后,ApplicationMaster 向 ResourceManager 注銷并關閉自己,
5. Scheduler
YARN 的資源調度服務:根據應用程式需要的資源請求以及集群的資源情況,為應用程式分配對應的資源,他不會關心你拿申請到的 Container 資源去做什么,
調度器就是根據容量 、佇列一些限制條件,將系統中的資源分配給各個正在運行的應用程式,這里有一句話想說,調度器是一個純調度器,就是它只管資源分配,不參與具體應用程式相關的作業,
YARN 內部有 3 種資源調度策略的實作:FifoScheduler、FairScheduler、CapacityScheduler,其中默認實作為 CapacityScheduler,
- FIFO Scheduler:先進先出,不考慮應用程式本身的優先級和資源使用情況
- Capacity Scheduler:將資源分成佇列,共享集群資源但需要保證佇列的最小資源使用需求,(容量調度中也可以設定佇列之間的搶占配置)
- Fair Scheduler:公平的將資源分給應用,保證應用使用的資源是均衡的,
CapacityScheduler 實作了資源更加細粒度的分配,可以設定多級佇列,每個佇列都有一定的容量,即對佇列設定資源上限和下限,然后對每一級別佇列分別再采用合適的調度策略(如 FIFO)進行調度,
6. NodeManager
NodeManager 是 YARN 集群當中真正資源的提供者,是真正執行應用程式的容器的提供者,監控應用程式的資源使用情況(CPU,記憶體,硬碟,網路),并通過心跳向集群資源調度器 ResourceManager 進行匯報以更新自己的健康狀態,同時其也會監督 Container 的生命周期管理,監控每個Container 的資源使用(記憶體、CPU 等)情況,追蹤節點健康狀況,管理日志和不同應用程式用到的附屬服(auxiliary service),
整體職責決議:
- 管理自身的資源
- 處理來自 ResourceManager 的命令
- 處理來自 ApplicationMaster 的命令
NM的內部也是很多Service組成,這里不詳細羅列了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286259.html
標籤:其他
上一篇:kafka的配置說明