在一個主備關系中,每個備庫接收主庫的binlog并執行,
正常情況下,只要主庫執行更新生成的所有binlog,都可以傳到備庫并被正確執行,備庫就能達到跟主庫一致的狀態,這就是最終一致性,
但MySQL要提供高可用能力,只有最終一致性還不夠,為什么呢?
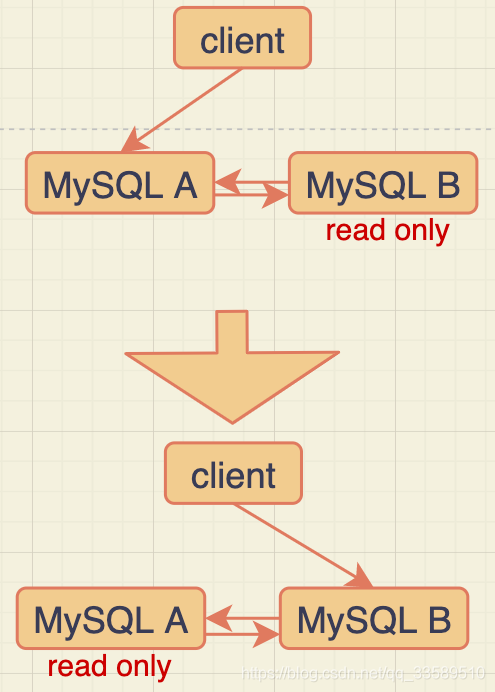
- MySQL主備切換流程–雙M結構
主備延遲
主備切換可能是:
- 主動運維動作
比如軟體升級、主庫所在機器按計劃下線等 - 被動操作
比如主庫所在機器掉電,
同步延遲
與資料同步有關的時間點主要包括以下三個:
- 主庫A執行完成一個事務,寫入binlog,該時刻記為t1
- 之后傳給備庫B,備庫B接收完該binlog的時刻記為t2
- 備庫B執行完成該事務,該時刻記為t3
主備延遲,就是同一事務,在 備庫執行完成的時間 和 主庫執行完成的時間 之間的差值,即t3-t1,
可以在備庫執行show slave status,它的回傳結果會顯示SBM(簡稱 SBM),表示當前備庫延遲了多少s,
SBM 計算方法:
- 每個事務的binlog都有一個時間欄位,以記錄主庫上寫入的時間
- 備庫取出當前正在執行的事務的時間欄位的值,計算它與當前系統時間的差值,得到SBM,
其實SBM就是t3-t1,所以,可以用SBM作為主備延遲的值,這個值的時間精度是s,
- 若主備庫機器的系統時間設定不一致,不會導致主備延遲的值不準嗎?
不會的,因為,備庫連接到主庫時,會通過執行SELECT UNIX_TIMESTAMP()函式獲得當前主庫系統時間,若此時發現主庫系統時間與自己不一致,備庫在執行SBM計算時,會自動扣掉該差值,
在網路正常時,日志從主庫傳給備庫所需時間很短,即t2-t1非常小,即網路正常情況下,主備延遲的主要來源是備庫接收完binlog和執行完該事務之間的時間差,
所以主備延遲最直接的表現是,備庫消費中轉日志(relay log)的速度,比主庫生產binlog的速度要慢,這可能是由哪些原因導致的呢?
主備延遲的來源
備庫所在機器的性能 < 主庫所在的機器性能
部署的人會想,反正備庫沒有請求,所以可以用差點兒的機器,或把20個主庫放在4臺機器,而把備庫集中在一臺機器,
但更新請求對IOPS的壓力,在主庫和備庫上是無差別的,所以,做這種部署時,一般都會將備庫設定為“非雙1”模式,
但實際上,更新程序中也會觸發大量讀操作,所以,當備庫主機上的多個備庫都在爭搶資源時,就可能導致主備延遲,
這種部署現在少了,因為主備可能發生切換,備庫隨時可能變成主庫,所以主備庫必須選用相同規格機器,并且做對稱部署,
我們也做了對稱部署,但還有延遲,為啥?
很可能備庫的壓力大,主庫既然提供了寫能力,那么備庫可以提供一些讀能力,或一些運營后臺需要的分析陳述句,不能影響正常業務,所以只能在備庫上跑,
由于主庫直接影響業務,大家使用起來會比較克制,反而忽視了備庫的壓力控制,結果備庫上的查詢耗費大量CPU,影響同步速度 =》主備延遲,
這時一般可以這么處理:
- 一主多從
除了備庫外,可以多接幾個從庫,讓這些從庫來分擔讀壓力,大多采用該方案,因為資料庫系統必須保證有定期全量備份能力,而從庫,很適合用來做備份, - 通過binlog輸出到外部系統
比如Hadoop,讓外部系統提供統計類查詢的能力,
從庫和備庫在概念上其實差不多,一般把會在HA程序中被選成新主庫的,稱為備庫,其他的稱為從庫,
我們也采用了一主多從,保證備庫壓力不會超過主庫,但還主備延遲,為啥?
可能就是大事務了,因為在主庫,必須等事務執行完成才會寫binlog,再傳給備庫,所以,若一個主庫的陳述句執行10min,則該事務可能就會導致從庫延遲10min,
delete一次性洗掉太多資料
比如,一些歸檔類資料,平時沒有注意洗掉歷史資料,等空間快滿,SE要一次性刪大量歷史資料,又要避免在高峰期,所以會在晚上執行這些大量資料洗掉,
結果,DBA半夜收到延遲報警,然后,DBA要求你后續再刪資料時,要控制每個事務洗掉的資料量,分成多次洗掉,
大表DDL
計劃內的DDL,建議使用gh-ost方案
我們主庫也沒大事務,怎么還主備延遲?
可能因為備庫的并行復制能力,
其他情況
TODO,
由于主備延遲的存在,所以在主備切換時,就有不同
策略
可靠性優先策略
比如一開始的雙M架構,切換程序如下:
- 判斷備庫B現在的SBM,若小于某值(比如5s)繼續下一步,否則持續重試該步
- 把主庫A改成只讀狀態,即把readonly設定為true
- 判斷備庫B的SBM值,直到該值=0
- 把備庫B改成可讀寫狀態:把readonly 設定為false
- 把業務請求切到備庫B
切換一般由HA系統完成,
MySQL可靠性優先主備切換流程
該切換流程中有不可用時間,因為在step2后,A、B都readonly,此時系統不可寫,直到step5完成后才恢復,
在這個不可用程序,較耗時的是step3,可能耗費幾s,這也是為什么要在step1先做判斷,確保SBM足夠小,
倘若一開始主備延遲就長如30min,而不先做判斷直接切換,系統的不可用時間就會長達30min,一般業務都是不能接受的,
系統的不可用時間,是由該資料可靠性優先的策略決定的,也可選擇可用性優先的策略,來把這個不可用時間幾乎降為0,
可用性優先策略
如果我強行把步驟4、5調整到最開始執行,也就是說不等主備資料同步,直接把連接切到備庫B,并且讓備庫B可以讀寫,那么系統幾乎就沒有不可用時間了,
我們把這個切換流程,暫時稱作可用性優先流程,這個切換流程的代價,就是可能出現資料不一致的情況,
接下來,我就和你分享一個可用性優先流程產生資料不一致的例子,假設有一個表 t:
CREATE TABLE `t` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`c` int(11) unsigned DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(c) values(1),(2),(3);
初始化資料后,主庫和備庫上都是3行資料,接下來,業務人員要繼續在表t上執行兩條插入陳述句的命令,依次是:
insert into t(c) values(4);
insert into t(c) values(5);
假設,現在主庫上其他的資料表有大量更新,導致主備延遲達到5s,在插入一條c=4的陳述句后,發起了主備切換,
-
可用性優先策略,且binlog_format=mixed時的切換流程和資料結果,
-
step2:主庫A執行完insert,插入了一行資料(4,4),之后開始進行主備切換
-
step3:由于主備之間5s延遲,所以備庫B還沒來得及應用“插入c=4”這個中轉日志,就開始接收客戶端“插入 c=5”的命令
-
step4:備庫B插入資料(4,5),并把該binlog發給主庫A
-
step5:備庫B執行“插入c=4”這個中轉日志,插入一行資料(5,4),而直接在備庫B執行的“插入c=5”這個陳述句,傳到主庫A,就插入一行新資料(5,5),
最終,A、B上出現兩行不一致資料,是由可用性優先流程導致,
若我還是想用可用性優先策略,但設定binlog_format=row,會咋樣?
row格式在記錄binlog時,會記錄新插入的行的所有欄位值,所以最后只會有一行不一致,而且兩邊主備同步的應用執行緒會報錯duplicate key error并停止,即這種情況,B的(5,4)和A的(5,5)這兩行資料,都不會被對方執行:
- 可用性優先策略,且binlog_format=row
所以使用row格式,資料不一致更容易被發現,而使用mixed、statement,資料很可能悄悄地就不一致,若你過很久才發現資料不一致,那可能只能刪庫跑路了,
主備切換的可用性優先策略會導致資料不一致,所以更推薦使用可靠性優先策略,畢竟對資料服務,資料的可靠性 > 可用性,
有沒有哪種情況資料的可用性優先級就是更高呢?
有個庫的作用是記錄操作日志,這時,若資料不一致,可通過binlog修復,而這短暫不一致也不會引發業務問題,
同時,業務系統依賴于這個日志的寫入邏輯,若該庫不可寫,會導致線上業務操作無法執行,
這時候,你可能需要先強行切換,事后再補資料,
事后復盤,想到個改進措施:讓業務邏輯不要依賴于這類日志的寫入,即日志寫入這個邏輯模塊應該可降級,比如寫到本地檔案或另外一個臨時庫,
這種場景就可以使用可靠性優先策略了,
按可靠性優先,例外切換會是什么效果?
假設,主庫A和備庫B間的主備延遲是30min,這時主庫A掉電,HA系統要切換B作為主庫,在主動切換時,可以等到主備延遲小于5s時,再啟動切換,但這時已經別無選擇了,
- 可靠性優先策略,主庫不可用
采用可靠性優先策略,必須得等到備庫B的SBM=0后,才能切換,但現在比剛剛更嚴重,并不是系統只讀、不可寫,而是系統處于完全不可用,因為,主庫A掉電后,我們的連接還沒有切到備庫B,
- 能否直接切換到備庫B,但保持B只讀?
不行,因為,這段時間內,中轉日志還沒有應用完成,若直接發起主備切換,客戶端查詢看不到之前執行完成的事務,會認為有“資料丟失”,
雖然隨著中轉日志的繼續應用,這些資料會恢復回來,但對于一些業務,查詢到“暫時丟失資料的狀態”不能被接受,
在滿足資料可靠性的前提下,MySQL高可用系統的可用性,依賴于主備延遲,延遲越小,在主庫故障時,服務恢復需要時間越短,可用性越高,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/286260.html
標籤:其他
上一篇:YARN 架構設計