文章目錄
- 1.unordered_ map、unordered_set
- 1.1介紹
- 1.2效率對比
- 1.3實戰演練
- 2.哈希
- 2.1哈希的概念
- 2.2哈希函式
- 2.2.1設計原則
- 2.2.2常見哈希函式
- 2.2.2.1常用哈希函式
- 2.2.2.2 不常用哈希函式
- 2.3哈希沖突
- 3.閉散列
- 3.1線性探測
- 3.2閉散列擴容-載荷因子
- 3.3二次探測
- 3.4平均查找長度
- 3.5模擬實作
- 4.開散列
- 4.1開散列概念
- 4.2開散列擴容
- 4.3總結(開散列和閉散列的比較)
- 4.4代碼實作以及效果驗證
1.unordered_ map、unordered_set
1.1介紹
在C++98之中提供了四個關聯式容器,分別是:map、set、multimap、multiset,他們的底層是紅黑樹,查詢時候的效率可以達到longN,但是當資料量非常大的時候,也不是很理想,于是在C++11之中,又增加了四個用法一樣的關聯式容器,只是底層的實作采用的是哈希表,這四個關聯式容器分別是:unordered_map、unordered_set、unordered_multimap、unordered_multiset
它們的底層用的是哈希桶,因此迭代器是單向的
1.2效率對比
#include <iostream>
#include <set>
using namespace std;
#include <time.h>
#include <unordered_set>
int main()
{
srand((unsigned)time(NULL));
set<int> RBset;
unordered_set<int> Hash;
int begin1=clock();
for (int i = 0; i < 500000;i++)
{
RBset.insert(rand() % 1000);
}
int end1 = clock();
int begin2 = clock();
for (int i = 0; i < 500000; i++)
{
Hash.insert(rand() % 1000);
}
int end2 = clock();
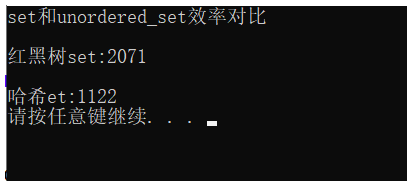
cout << "set和unordered_set效率對比" << endl << endl;
cout << "紅黑樹set:" << end1 - begin1 << endl << endl;
cout << "哈希et:" << end2 - begin2 << endl;
system("pause");
return 0;
}
1.3實戰演練
哈希常見面試題
2.哈希
2.1哈希的概念
map和set底層用的都是紅黑樹,進行元素的查找和插入都需要經過logN的時間復雜度,即需要通過元素之間的多次比較才能夠完成,
理想的搜索方法是,不經過任何比較,一次性直接從表中獲取元素,哈希就是這種設計理念,通過某種函式(hashFunc)使元素的存盤位置與它的關鍵碼之間能夠建立起對應的映射關系,在O(1)的時間內,插入、獲取元素
向結構中插入元素:
根據待插入元素的關鍵碼,用哈希函式計算出對應的存盤位置,并且按照此位置行程存放
搜索結構中的元素:
對元素關鍵碼進行計算,將函式回傳值作為元素的存盤位置進行搜索,如果對應的位置的元素與搜索元素可以匹配,則搜索成功
這種方法即為哈希(散列)方法,哈希方法中使用的函式稱之為哈希函式,構造出來的結構稱為哈希表
2.2哈希函式
2.2.1設計原則
哈希函式設計的不合理,會導致哈希沖突,哈希函式一般按照以下幾點原則進行設計:
1.哈希函式的定義域必須包括需要存盤的全部關鍵碼,而如果散串列允許有m個地址時,其值域必須在0到m-1之間
2.哈希函式計算出來的地址能夠均勻分布在整個空間之中
3.哈希函式應該比較簡單
2.2.2常見哈希函式
2.2.2.1常用哈希函式
1.直接定址法(常用)
取關鍵字的某個線性函式作為散列地址:hash(key)=A*key + B
優點:簡單、均勻
缺點:實作需要知道關鍵字的分布情況,并且只適合查找比較小,且連續分布的情況
場景:
適用場景:查找字串中,第一次出現的單詞:構建一個陣列 hash[ch-‘a’] 即為對應的地址
不適用場景:給一批資料, 1 5 8 100000 像這資料跨度大,資料元素不連續,很容易造成空間浪費
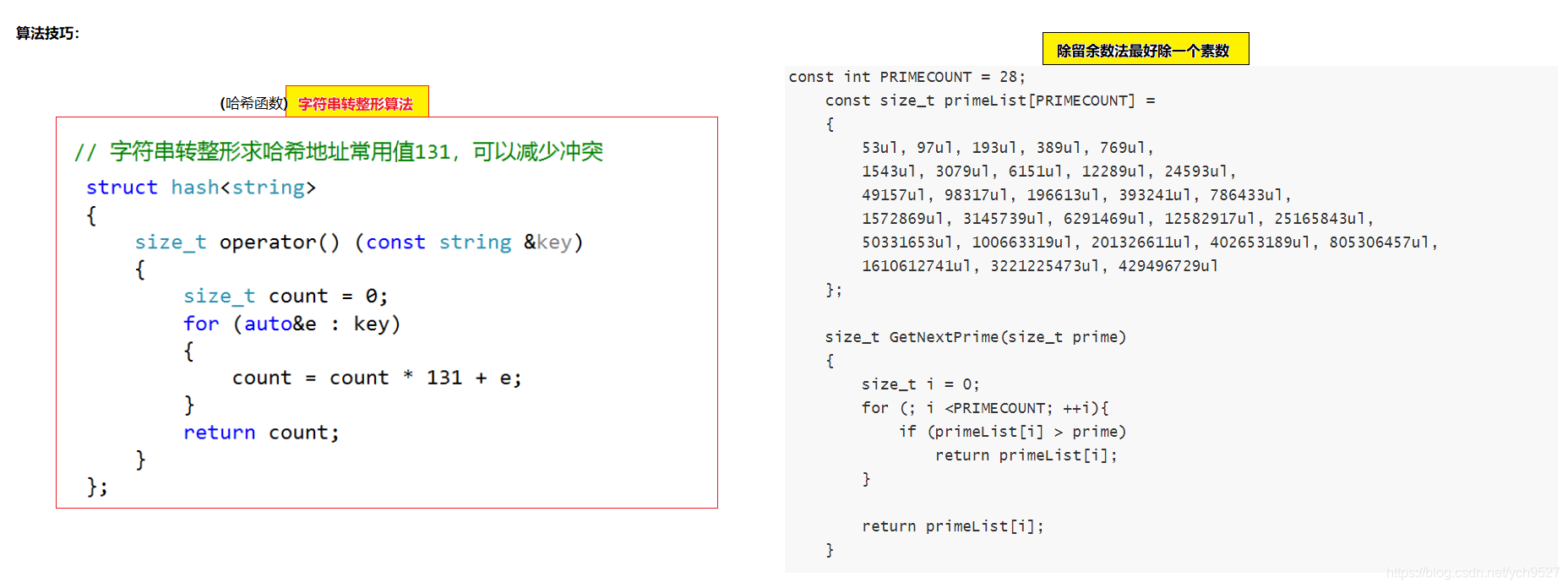
2.除留余數法(常用)
設散串列中允許的地址數為m,通常是取一個不大于m,但是最接近或者等于m的質數num,作為除數,按照哈希函式進行計算hash(key)= key%num, 將關鍵碼轉換成哈希地址
除留余數法,最好模一個素數:
const int PRIMECOUNT = 28;
const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 429496729ul
};
size_t GetNextPrime(size_t prime)
{
size_t i = 0;
for (; i <PRIMECOUNT; ++i){
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
2.2.2.2 不常用哈希函式
1.平方取中法
hash(key)=key*key -> 然后取函式回傳值的中間的幾位,作為哈希地址
比如 25^2 = 625 取中間的一位 2 作為哈希地址
比較適合不知道關鍵字的分布,而位數又不是很大的情況
2.折疊法
將關鍵字從左到右分割成位數相等的幾部分(最后一部分可以短些),然后將這幾部分疊加求和,并且按照散串列長度,取最后幾位作為散列地址
適用于不知道關鍵字分布,關鍵字位數比較多的情況
3.亂數法
選取一個隨機函式,取關鍵字的隨機函式值,作為它的哈希地址,hash(key) = random(key),random為隨機函式
通常用于關鍵字長度不等的情況
4.數學分析法
通過實作分析關鍵字,來獲取哈希地址
比如用每個人的手機號碼充當關鍵字,如果采用前三位作為哈希地址,那么沖突的概率是非常大的,如果采用的是中間3位那么沖突的概率要小很多
常用于處理關鍵字位數比較大的情況,且事前知道關鍵字的分布和關鍵字的若干位的分布情況
2.3哈希沖突

解決哈希沖突常見的兩種方法是閉散列和開散列
3.閉散列
閉散列也叫做開放地址法,當發生哈希沖突的時候,如果哈希表未被填滿,說明在哈希表中必然還有空位置,那么可以把key存放到沖突位置的"下一個"空位置中去,尋找下一個空位置的方法有線性探測法和二次探測法
3.1線性探測
從發生沖突的位置開始,依次向后探測,直到尋找到下一個位置為止
優點:實作非常簡單
缺點:一旦發生哈希沖突,所有的沖突連在一起,容易產生資料"堆積",即不同關鍵碼占據了可利用的空位置,使得尋找某關鍵碼的位置需要進行多次比較,導致搜索效率降低
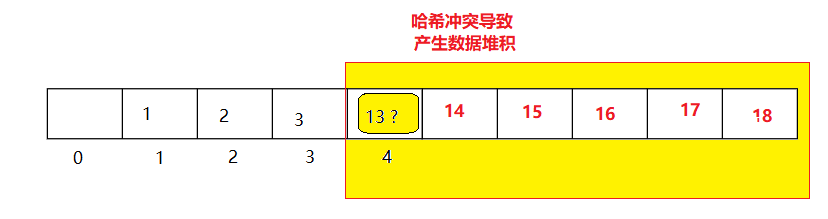
插入:
通過哈希函式插入元素在哈希表中的位置,如果發生了哈希沖突,則使用線性探測尋找下一個空位置插入元素
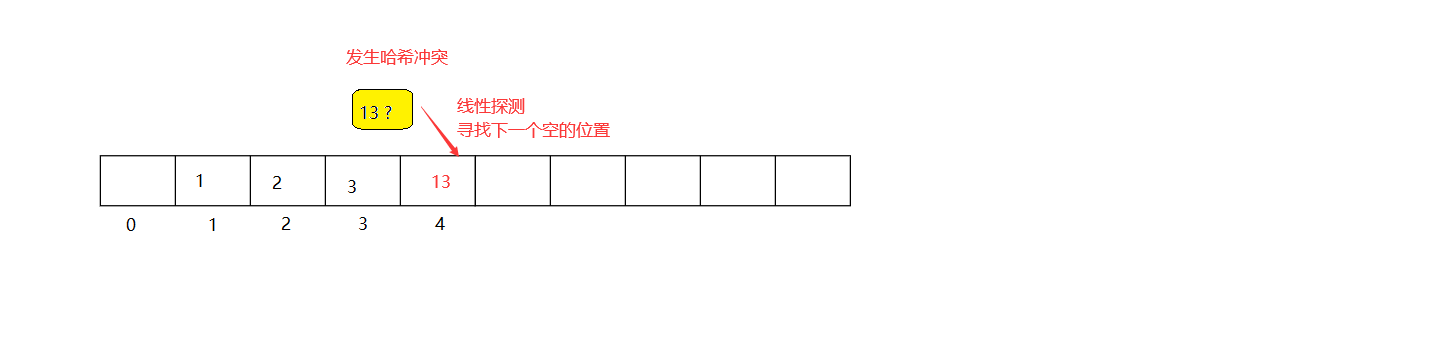
洗掉:
采用閉散列處理哈希沖突時,不能隨便洗掉哈希表中已有的元素,如果直接洗掉元素,會影響其他元素的搜索
因此線性探測采用標記的偽洗掉法來洗掉下一個元素
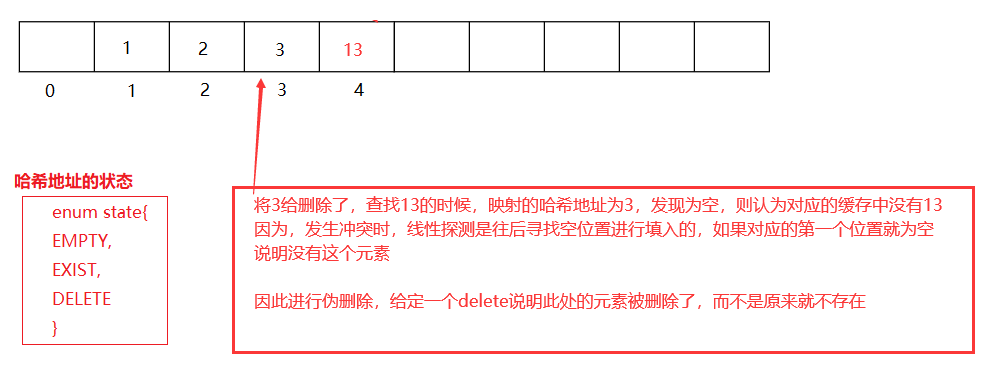
3.2閉散列擴容-載荷因子
散串列的載荷因子定義為 α = 填入表中的元素 / 散串列的長度
α是散串列裝滿程度的標志因子,α越大表明裝入表中的元素越多,產生沖突的可能性也就越大,反之填入表中的元素越少,沖突可能性越低,空間利用率也就越低
閉散列:一般將載荷因子控制在 0.7-0.8以下,超過0.8查表時候的快取不中率會按照指數曲線上升(哈希可能性沖突越大),因此一般hash庫中,都將α設定在0.8以下, 閉散列,千萬不能為滿,否則在插入的時候會陷入死回圈
開散列/哈希桶:一般將載荷因子控制在1,超過1,那么鏈表就掛得越長,效率也就越低
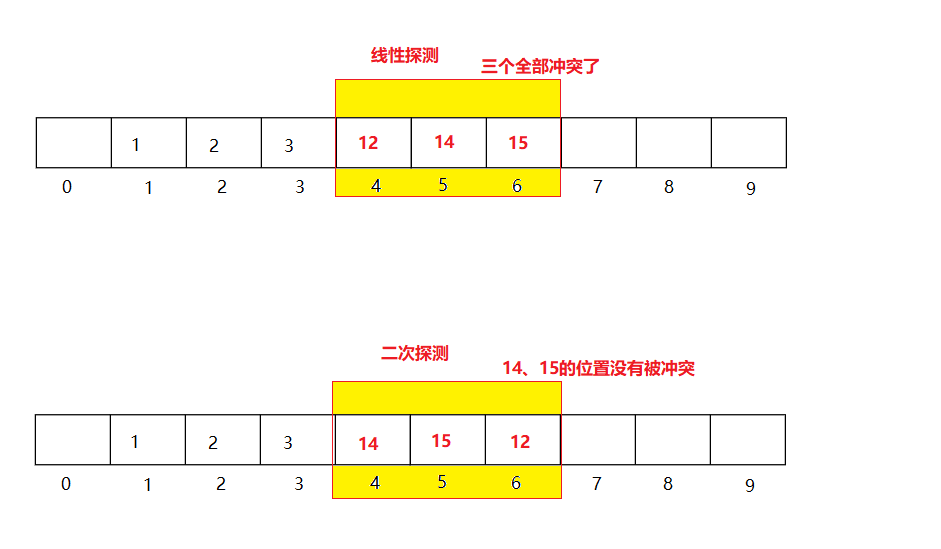
3.3二次探測
線性探測的缺陷是產生哈希沖突,容易導致沖突的資料堆積在一起,這是因為線性探測是逐個的找下一個空位置
二次探測為了緩解這種問題(不是解決),對下一個空位置的查找進行了改進(跳躍式查找):
POS = (H+i^2)%m || POS = (H - i^2)%m
其中:i=1、2、3…
H是發生哈希沖突的位置
m是哈希表的大小
3.4平均查找長度
先將值放入哈希表之中
平均查找次數 = 查找每個值的次數總和/值的個數
3.5模擬實作
設計程序:
1.整體結構:
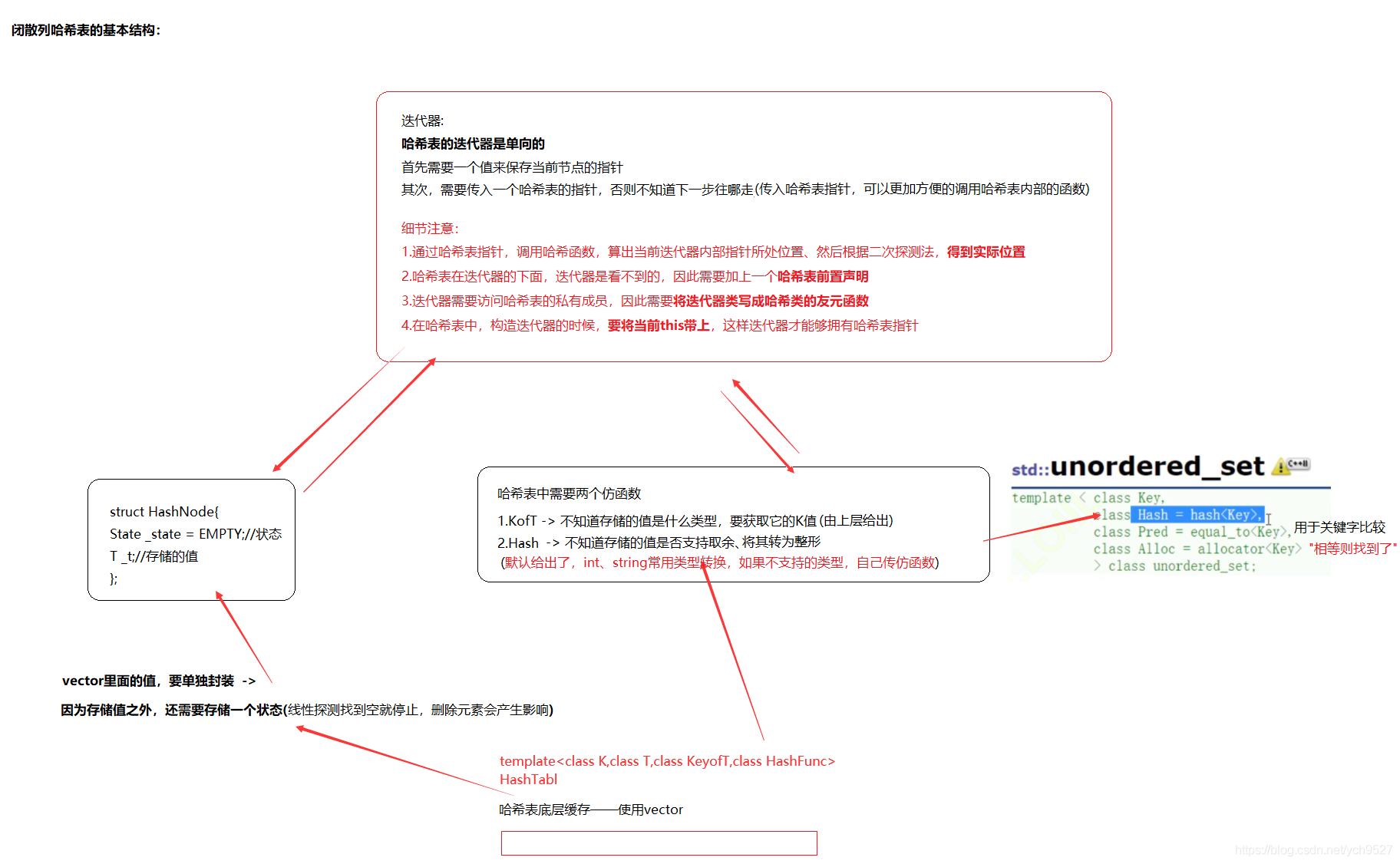
2.擴容實作:

3.演算法技巧
4.封裝成set、map的代碼和驗證

5.代碼和實驗效果
閉散列代碼:
#ifndef _HASH_HPP_
#define _HASH_HPP_
using namespace std;
#include <iostream>
#include <vector>
#include <assert.h>
#include <string>
//閉散列
//set<K> -> HashTable<K,K>
//map<K,V> -> HashTable<K,pair<K,V>>
namespace YCH_CLOSE_HASH
{
enum State
{
EMPTY,//空
DELETE,//存在
EXIST//洗掉
};
template<class T>
struct HashNode//存盤的節點
{
State _state = EMPTY;//節點狀態,默認為空狀態(預設值)
T _t;//節點的值
HashNode(const T&t=T())
:_t(t)
{}
};
//迭代器的構造
//提前宣告哈希表
template <class K, class T, class KeyofT, class Hash>//宣告和定義不能同時候預設引數
class HashTable;
template<class K, class T, class KeyofT, class Hash>
struct HashIterator
{
typedef HashIterator<K, T, KeyofT, Hash> Self;
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyofT, Hash> HashTable;
Node *_node;
HashTable *_pht;//迭代器里面還需要包括哈希表
HashIterator(Node* node, HashTable *pth)
:_node(node)
, _pht(pth)
{}
T& operator*()
{
assert(_node != nullptr);
return _node->_t;
}
T* operator ->()
{
assert(_node != nullptr);
return &(_node->_t);
}
bool operator == (const Self &s)const
{
return _node == s._node;
}
bool operator != (const Self &s)const
{
return _node != s._node;
}
Self& operator++()//尋找當前位置的后面一個有元素的位置
{
//先找到當前節點所在位置,然后往后尋找下一個節點的位置
KeyofT kf;
size_t begin = _pht->HashFunc(kf(_node->_t));//得到映射的哈希位置
//不清楚是否發生沖突因此還要再次尋找
size_t index = begin;
size_t i = 1;
int flag = 1;
while (_pht->_tables[index]._state != EMPTY)//等于空就停止,這也是為什么要用HashNode的原因,直接判斷,如果洗掉了,也會出現空
{
if (_pht->_tables[index]._state == EXIST&&kf(_node->_t) == kf(_pht->_tables[index]._t))//存在且K值對應
{
break;
}
index = (begin + i*i*flag) % _pht->_tables.size();//二次探測
if (flag == -1)
{
i++;//增大值
flag = 1;
}
else
{
flag = -1;//變換方向
}
}
//此時index的位置就是第一個當前位置的資料,然后往后遍歷整張表,輸出元素
for (int i = index+1; i < _pht->_tables.size(); i++)
{
if (_pht->_tables[i]._state == EXIST)
{
/*_node->_t = _pht->_tables[i]._t; //BUG,這是將原來節點里面的值也給更改了
_node->_state = _pht->_tables[i]._state;*/
_node = &(_pht->_tables[i]);
return *this;
}
}
//return _pht->End();這樣不行,沒有接受值,只是回傳了一個下一個位置的迭代器
_node = nullptr;
return *this;
}
Self operator++(int)//后置++
{
//先找到當前節點所在位置,然后往后尋找下一個節點的位置
KeyofT kf;
size_t begin = _pht->HashFunc(kf(_node->_t));//得到映射的哈希位置
//不清楚是否發生沖突因此還要再次尋找
size_t index = begin;
size_t i = 1;
int flag = 1;
while (_pht->_tables[index]._state != EMPTY)//等于空就停止,這也是為什么要用HashNode的原因,直接判斷,如果洗掉了,也會出現空
{
if (_pht->_tables[index]._state == EXIST&&kf(_node->_t) == kf(_pht->_tables[index]._t))//存在且K值對應
{
break;
}
index = (begin + i*i*flag) % _pht->_tables.size();//二次探測
if (flag == -1)
{
i++;//增大值
flag = 1;
}
else
{
flag = -1;//變換方向
}
}
//此時index的位置就是第一個當前位置的資料,然后往后遍歷整張表,輸出元素
Node *copy_node = _node;//保存一份
for (int i = index + 1; i < _pht->_tables.size(); i++)
{
if (_pht->_tables[i]._state == EXIST)
{
/*_node->_t = _pht->_tables[i]._t; //BUG,這是將原來節點里面的值也給更改了
_node->_state = _pht->_tables[i]._state;*/
_node = &(_pht->_tables[i]);
return Self(copy_node, _pht);
}
}
//return _pht->End();這樣不行,迭代器本身沒有改變,只是回傳了一個下一個位置的迭代器
_node = nullptr;
return Self(copy_node, _pht);
}
};
//哈希表的構造
size_t GetNextPrime(size_t prime)
{
static const int PRIMECOUNT = 28;//給成靜態,不用重復生成
static const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 429496729ul
};
size_t i = 0;
for (; i <PRIMECOUNT; ++i){
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
template<class K, class T, class KeyofT, class Hash>//默認給int進行比較
class HashTable
{
public:
//構造迭代器
typedef HashIterator<K, T, KeyofT, Hash> Iterator;
friend Iterator; //<=>HashIterator<K, T, KeyofT, Hash>;//將迭代器宣告為,哈希表的友元類,即可以訪問哈希表的私有成員
Iterator Begin()
{
for (int i = 0; i < _tables.size(); i++)//找到第一個不為空的值
{
if (_tables[i]._state == EXIST)
return Iterator(&_tables[i], this);
}
return End();
}
Iterator End()
{
return Iterator(nullptr, this);
}
//構造插入函式
size_t HashFunc(const K& key)//哈希函式
{
Hash hf;
return hf(key) % _tables.size();
}
pair<Iterator,bool> Insert(const T & t)
{
//判斷要插入的元素是否已經存在
KeyofT kf;
Iterator ret = Find(kf(t));
if (ret!=End())//已經存在了,multiset/multimap則不需要
return make_pair(ret,false);
//進行擴容檢測
if (_size == 0 || (_size / _tables.size() * 10 > 7))//當前個數為0或者載荷因子超過了,則進行擴容
{
//size_t newsize = _size == 0 ? 10 : 2 * _tables.size();//初始化給10,后續擴容兩倍
//選取素數
size_t newsize = GetNextPrime(_tables.size());
//擴容之后,需要重新計算元素的位置
HashTable<K, T, KeyofT, Hash> newtable;
newtable._tables.resize(newsize);
for (auto&e : _tables)
{
if (e._state == EXIST)
newtable.Insert(e._t);
}
_tables.swap(newtable._tables);//進行交換
}
//查找插入的位置
//KeyofT kf;//獲取元素型別
//Hash hf;//將元素轉為整形
size_t begin = HashFunc(kf(t));//獲取映射位置
size_t index = begin;
size_t i = 1;
int flag = 1;
while (_tables[index]._state == EXIST)//發生沖突,則繼續尋找
{
index = (begin + i*i*flag) % _tables.size();//二次探測
if (flag == -1)
{
i++;//增大值
flag = 1;
}
else
{
flag = -1;//變換方向
}
}
//此時已經找到位置了,進行元素的添加
_tables[index]._t = t;
_tables[index]._state = EXIST;
_size++;
return make_pair(Iterator(&_tables[index],this),true);
}
Iterator Find(const K& key)//查找的時候需要注意,查找的值不一定存在
{
if (_size == 0)//為空
return Iterator(nullptr,this);
//Hash hf;//轉整形
KeyofT kf;//拿K值
size_t begin = HashFunc(key);//轉為整形,獲取映射位置.
size_t index = begin;
size_t i = 1;
int flag = 1;
while (_tables[index]._state != EMPTY)//等于空就停止,這也是為什么要用HashNode的原因,直接判斷,如果洗掉了,也會出現空
{
if (_tables[index]._state == EXIST&&key == kf(_tables[index]._t))//存在且K值對應
{
return Iterator(&_tables[index],this);
}
index = (begin + i*i*flag) % _tables.size();//二次探測
if (flag == -1)
{
i++;//增大值
flag = 1;
}
else
{
flag = -1;//變換方向
}
}
//當前值不存在
return End();
}
bool Erase(const K& key)//先找到再洗掉
{
HashNode<T>* node = Find(key);
if (node)
{
node->_state = DELETE;//偽洗掉
_size--;
return true;
}
return false;
}
private:
vector<HashNode<T>> _tables;//底層結構
size_t _size = 0;//存盤的資料的個數
};
};
#endif
封裝:
map封裝:
#pragma once
#include "hash.hpp"
namespace YCH_MAP
{
//內置哈希轉換函式 <-> 常用int 和 string
//如果K型別不支持取模,就需要配上一個仿函式來進行使用
template<class K>
struct Hash
{
size_t operator() (const K&key)
{
return key;
}
};
//string型別常用,進行特化
template<>
struct Hash<string>
{
size_t operator() (const string &key)
{
size_t count = 0;
for (auto&e : key)
{
count = count * 131 + e;// 字串轉整形求哈希地址常用值131,可以減少沖突
}
return count;
}
};
template<class K, class V, class hash = Hash<K>>
class ych_unordered_map
{
private:
struct map_KeyofT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename YCH_CLOSE_HASH::HashTable<K, pair<K, V>, map_KeyofT, hash>::Iterator iterator;
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
private:
YCH_CLOSE_HASH::HashTable<K, pair<K, V>, map_KeyofT, hash> _ht;
};
};
set封裝:
#pragma once
#include "hash.hpp"
namespace YCH_MAP
{
template<class K, class hash = Hash<K>>
class ych_unordered_set
{
private:
struct set_KeyofT
{
const K& operator()(const K& k)
{
return k;
}
};
public:
typedef typename YCH_CLOSE_HASH::HashTable<K, K, set_KeyofT, hash>::Iterator iterator;
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
pair<iterator, bool> insert(const K& k)
{
return _ht.Insert(k);
}
iterator find(const K &k)
{
return _ht.Find(k);
}
private:
YCH_CLOSE_HASH::HashTable<K, K, set_KeyofT, hash> _ht;
};
};
實驗檢測:
#include "hash.hpp"
#include "hashmap.hpp"
#include "hashset.hpp"
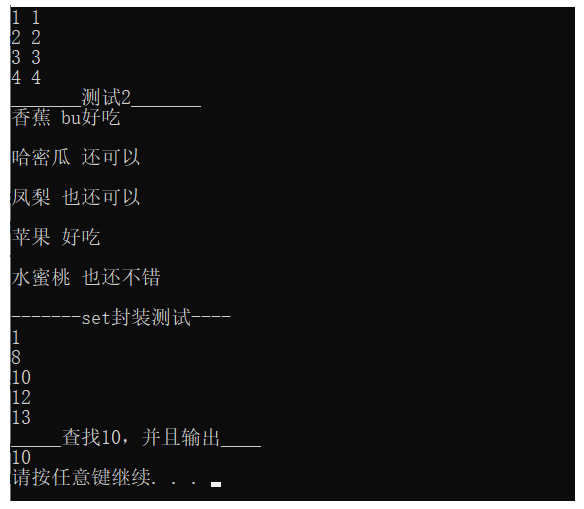
void test_map()
{
YCH_MAP::ych_unordered_map<int, int> map;
map.insert(make_pair(1, 1));
map.insert(make_pair(2, 2));
map.insert(make_pair(3, 3));
map.insert(make_pair(4, 4));
for (auto&e : map)
{
cout << e.first << " " << e.second << endl;
}
cout << "_______測驗2_______" << endl;
YCH_MAP::ych_unordered_map<string, string> map2;
map2.insert(make_pair("蘋果", "好吃"));
map2.insert(make_pair("香蕉", "bu好吃"));
map2.insert(make_pair("哈密瓜", "還可以"));
map2.insert(make_pair("鳳梨", "也還可以"));
map2.insert(make_pair("水蜜桃", "也還不錯"));
for (auto&e : map2)
{
cout << e.first << " " << e.second << endl << endl;
}
}
void test_set()
{
cout << "-------set封裝測驗----" << endl;
YCH_MAP::ych_unordered_set<int> set;
set.insert(1);
set.insert(12);
set.insert(13);
set.insert(10);
set.insert(8);
for (auto &e : set)
{
cout << e << endl;
}
cout << "_____查找10,并且輸出____" << endl;
YCH_MAP::ych_unordered_set<int>::iterator it = set.find(10);
if (it != set.end())
cout << *it << endl;
}
int main()
{
test_map();
test_set();
system("pause");
return 0;
}
實驗效果:
4.開散列
4.1開散列概念
開散列又名哈希桶/開鏈法,首先對關鍵碼集合采用散列函式計算散列地址,具有相同地址的關鍵碼歸于同一子集合,每一個子集合稱為一個桶,各個桶中的元素通過一個單鏈表串聯起來,各個鏈表的頭節點存盤在哈希表中
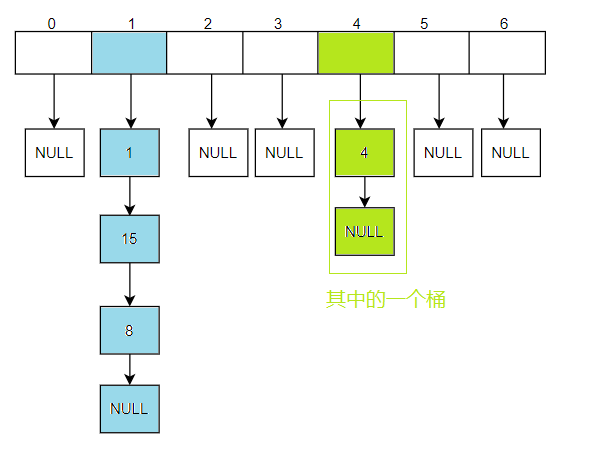
4.2開散列擴容
桶的個數是一定的,不斷的插入元素,會導致單個的桶的長度很長,影響哈希表的性能,理想的情況下是每個桶下面只有一個節點,哈希桶的載荷因子控制在1,當大于1的時候就進行擴容,這樣平均下來,每個桶下面只有一個節點;
**與開散列進行比較:**看起來哈希桶之中存盤節點的指標開銷比較大,其實不然,開散列的載荷因子保證小于0.7,來確保有足夠的空間降低哈希沖突的概率,而表項的空間消耗遠遠高于指標所占的空間效率,因此哈希桶更能節省空間

4.3總結(開散列和閉散列的比較)
**1.開散列的載荷因子:**α<=1,即平均每個桶下面掛一個節點,平均時間復雜度為1
2.開散列產生哈希沖突時:直接頭插至鏈表之中,而閉散列就會出現哈希沖突,容易出現踩踏效應(二次探測也只是緩解這種情況)
3.開散列的優缺點:
優點:
不同位置沖突時,不再互相干擾,載荷因子一般控制在1
缺點:
迭代器遍歷輸出的時候,不是有序輸出的,
**延伸:**要想做到有序輸出,那么必須再用個list保存一份,哈希表里面存個地址指向對應的list,輸出的時候就輸出list里面的內容,但是這樣的空間和時間消耗的代價就更大了
**4.開散列的優化:**如果所有的資料都沖突到一個桶下面了,怎么辦?
1.在桶下面掛紅黑樹:極限也是lgN的時間復雜度,但是也只是這一會而已,當增容的時候,這種現象就會緩解
2.多階哈希:多個哈希表,沖突的時候,掛到另外一個哈希表上,長度不一樣,對應的位置就不一樣

5.開散列增容那一下的性能
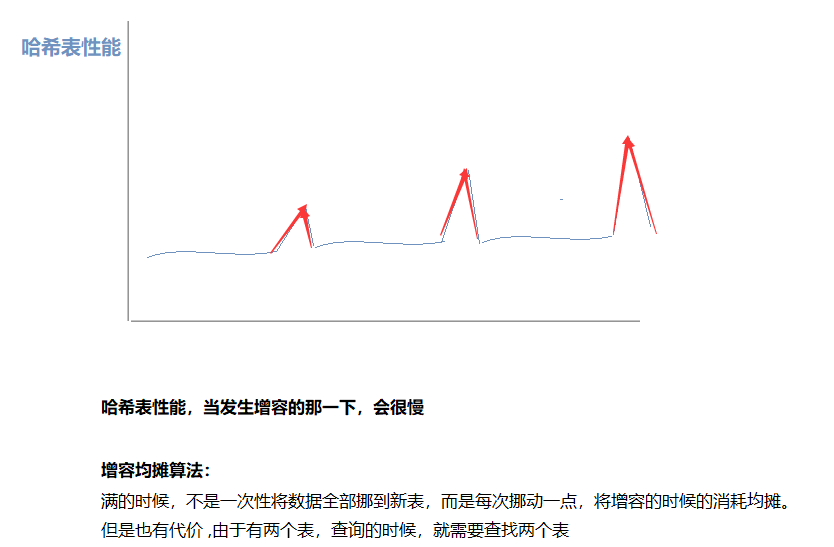
4.4代碼實作以及效果驗證
#ifndef _HASH_HPP_
#define _HASH_HPP_
using namespace std;
#include <iostream>
#include <vector>
#include <assert.h>
#include <string>
static size_t GetNextPrime(size_t prime)
{
static const int PRIMECOUNT = 28;//給成靜態,不用重復生成
static const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 429496729ul
};
size_t i = 0;
for (; i <PRIMECOUNT; ++i){
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
namespace YCH_OPEN_HASH
{
//節點
template<class T>
struct HashLink
{
HashLink<T> *_next;
T _t;
HashLink(const T& t)
:_t(t)
,_next(nullptr)
{}
};
//前置宣告
template<class K, class T, class KeyofT, class Hash>
class HashTable;
//迭代器
template<class K, class T,class Ref,class Ptr ,class KeyofT, class Hash>
struct HashIterator
{
typedef HashLink<T> Node;
typedef HashTable<K, T, KeyofT, Hash> HashTable;
typedef HashIterator<K, T, Ref, Ptr, KeyofT,Hash> Self;
Node *_node;//節點
HashTable *_pht;//哈希表指標,++的時候需要計算位置
HashIterator(Node *node,HashTable* tables)//建構式需要傳入節點指標,和哈希表指標
:_node(node)
, _pht(tables)
{}
Ref operator*()
{
assert(_node);
return _node->_t;
}
Ptr operator->()
{
assert(_node);
return &(_node->_t);//回傳去的是一個地址,使用的時候編譯器優化,減少了一個箭頭
}
KeyofT kf;
Self &operator++()//前置
{
size_t pos = _pht->HashFunc(kf(_node->_t),_pht->_tables);//獲取當前位置
pos++;
_node = _node->_next;
if (_node == nullptr)//當前鏈表走完了,尋找下一個節點
{
for (int i = pos; i < _pht->_tables.size(); i++)
{
if (_pht->_tables[i] != nullptr)
{
_node = _pht->_tables[i];
break;
}
}
}
return *this;
}
bool operator!=(Self &s)
{
return _node != s._node;
}
};
template<class K, class T, class KeyofT,class Hash>
class HashTable
{
public:
typedef HashLink<T> Node;
typedef HashIterator<K, T, T&, T*, KeyofT, Hash> Iterator;
typedef HashIterator<K, T, const T&, const T*, KeyofT, Hash> Const_Iterator;
//迭代器友元
friend HashIterator<K, T, T&, T*, KeyofT, Hash>;
friend Const_Iterator;
Iterator Begin()
{
for (int i = 0; i < _tables.size(); i++)
{
if (_tables[i] != nullptr)
return Iterator(_tables[i], this);
}
return Iterator(nullptr, this);
}
Iterator End()
{
return Iterator(nullptr, this);
}
KeyofT kf;//提取key值
//哈希函式
size_t HashFunc(const K& key,const vector<HashLink<T>*> tables)
{
Hash hf;
return hf(key) % tables.size();
}
pair<Iterator,bool> Insert(const T& t)
{
//判斷是否存在
if (_tables.size())//防止%0
{
Iterator fi = Find(kf(t));
if (fi != End())//存在
return make_pair(fi, false);
}
//判斷是否需要擴容
if (_size == _tables.size())//α<=1
{
size_t newsize = GetNextPrime(_tables.size());
vector<Node*> newtables(newsize, nullptr);//構造一個新表出來
for (int i = 0; i < _tables.size(); i++)
{
Node* node = _tables[i];
while (node)//當前位置有節點
{
Node *next = node->_next;//保存當前鏈表的下一個位置
size_t index = HashFunc(kf(node->_t),newtables);//得到位置
node->_next = newtables[index];
newtables[index] = node;
node = next;
}
_tables[i] = nullptr;//原表置空
}
//兩表交換
newtables.swap(_tables);
}
//插入節點
size_t index = HashFunc(kf(t),_tables);//尋找插入位置
Node *newnode = new Node(t);//構造一個節點
newnode->_next = _tables[index];//頭插
_tables[index] = newnode;
_size++;
return make_pair(Iterator(_tables[index], this), true);
}
//查找
Iterator Find(const K& k)
{
size_t index=HashFunc(k, _tables);
Node *cur = _tables[index];
while (cur&&(kf(cur->_t) !=k))
{
cur = cur->_next;
}
return Iterator(cur, this);
}
洗掉
bool Erase(const K& k)
{
size_t intdex = HashFunc(k, _tables);
Node* cur = _tables[index];
Node *prev = nullptr;
while (cur&&kf(cur->_t) != k)
{
prev = cur;
cur = cur->_next;
}
if (cur == nullptr)//沒找到
return false;
prev->_next = cur->_next;
delete cur;
_size--;
return true;
}
private:
vector<Node*> _tables;
size_t _size;
};
};
#endif
#pragma once
#include "hash.hpp"
namespace YCH_MAP
{
//內置哈希轉換函式 <-> 常用int 和 string
//如果K型別不支持取模,就需要配上一個仿函式來進行使用
template<class K>
struct Hash
{
size_t operator() (const K&key)
{
return key;
}
};
//string型別常用,進行特化
template<>
struct Hash<string>
{
size_t operator() (const string &key)
{
size_t count = 0;
for (auto&e : key)
{
count = count * 131 + e;// 字串轉整形求哈希地址常用值131,可以減少沖突
}
return count;
}
};
template<class K, class V, class hash = Hash<K>>
class ych_unordered_map
{
private:
struct map_KeyofT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename YCH_OPEN_HASH::HashTable<K, pair<const K, V>, map_KeyofT, hash>::Iterator iterator;
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
pair<iterator, bool> insert(const pair<const K, V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& k)
{
return ((insert(make_pair(k, V()))).first)->second;
}
private:
YCH_OPEN_HASH::HashTable<K, pair<const K, V>, map_KeyofT, hash> _ht;
};
};
#pragma once
#include "hash.hpp"
namespace YCH_MAP
{
template<class K, class hash = Hash<K>>
class ych_unordered_set
{
private:
struct set_KeyofT
{
const K& operator()(const K& k)
{
return k;
}
};
public:
//typedef typename YCH_CLOSE_HASH::HashTable<K, K, set_KeyofT, hash>::Iterator iterator;閉散列
typedef typename YCH_OPEN_HASH::HashTable<K, K, set_KeyofT, hash>::Iterator iterator;//開散列
iterator begin()
{
return _ht.Begin();
}
iterator end()
{
return _ht.End();
}
pair<iterator, bool> insert(const K& k)
{
return _ht.Insert(k);
}
iterator find(const K &k)
{
return _ht.Find(k);
}
private:
//YCH_CLOSE_HASH::HashTable<K, K, set_KeyofT, hash> _ht;
YCH_OPEN_HASH::HashTable<K, K, set_KeyofT, hash> _ht;
};
};
#include "hash.hpp"
#include "hashmap.hpp"
#include "hashset.hpp"
void test_open_map()
{
cout << "____YCH_MAP::ych_unordered_map<int, int> map___" << endl ;
YCH_MAP::ych_unordered_map<int, int> map;
map.insert(make_pair(1, 1));
map.insert(make_pair(54, 54));
map.insert(make_pair(55, 55));
map.insert(make_pair(56, 56));
map.insert(make_pair(54, 54));
map.insert(make_pair(108, 108));
auto it = map.begin();
while (it != map.end())
{
cout << it->first << " " << it->second << endl;
++it;
}
cout << endl;
cout << "____[]測驗____<<endl";
map[500]++;
map[200]=100;
map[111] = 153;
for (auto&e : map)
{
cout << e.first<<" "<<e.second<< endl;
}
}
void test_open_set()
{
cout << "_____YCH_MAP::ych_unordered_set<string> set______ " << endl;
YCH_MAP::ych_unordered_set<string> set;
set.insert("排序");
set.insert("字串");
set.insert("演算法");
set.insert("演算法");
set.insert("字串");
set.insert("哈希表");
for (auto&e : set)
{
cout << e << endl;
}
}
int main()
{
test_open_map();
test_open_set();
system("pause");
return 0;
}

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287187.html
標籤:其他