CV_01 SSD演算法的簡單理解(入門級別)
一. 寫這篇博文的初衷
其實在很多論壇也好,貼吧也罷已經有了很多關于SSD演算法的剖析與理解,但大部分都比較學術和深奧,博主在初學的時候也是遇到了不少難以理解的問題,在反復地學習之后,有了一些比較淺顯的理解與感悟,因此在這里與大家分享一下,當然不免會出現比較低級的錯誤,如果有錯誤的地方還請讀者大大們踴躍地提出來,我們一起進步,
二. 什么叫SSD?
SSD演算法,其英文全名是Single Shot MultiBox Detector,翻譯成中文就是:“單激發多框探測器”,Single shot就指明了SSD演算法屬于one-stage方法,MultiBox指明了SSD是由多個bounding box來完成預測的,那么問題來了什么叫one-stage,什么又叫做bounding box呢?
1. one-stage VS two-stage
簡單地來說,計算機在做目標檢測的時候,通常需要做兩件事,第一件事是【目標在哪(定位)】,第二件事是【目標是啥(分類)】,因此人們就根據這兩件事,把目標檢測分為了兩大類,一類叫做two-stage,另一類就叫做one-stage,對于two-stage來說,它會先生成一些候選區域,這些區域有可能會包含一個待檢測目標(定位),緊接著再采取一些后續操作來區分每個候選區域里具體包含了哪些目標(分類),對于one-stage來說,它則是通過一次網路就同時得到了被檢測物體的位置資訊和分類資訊,因此可以看出來:two-stage的精確度更高,而one-stage的速度更快,
2. bounding box
bounding box翻譯成中文來說就是“邊界框”,從字面上不難理解,它是用來區分框內物體與框外背景的一個工具,也就是說當一張圖片中出現了bounding box的時候,其實就明確地告訴了你圖片中所存在的被檢測物體的位置,有了這個“邊界框”之后,就可以針對邊界框內被檢測物體的特征來完成對它的分類操作,
三. SSD演算法的網路架構及實作流程

大家對這張圖肯定不陌生(我把小汽車換成了小貓咪),
- 在特征提取環節我加入三個不同顏色的框框把SSD目標檢測網路切分成了三個部分,第一個部分(黃色)做的事情就是為了防止影像失真從而將待傳入網路的圖片進行 300x300x3 的resize處理,第二個部分(藍色)就是SSD網路對VGG16深度卷積神經網路的“呼叫”,也就是先讓傳入網路中的影像先過一遍VGG16深度卷積神經網路提取出一大堆特征,第三個部分(紅色)就是SSD演算法新穎的地方,就是它在VGG16的基礎上又新增了四個卷積層,從而進行了更多次的特征提取,來獲得更多數量的特征層,在每一個特征層的上邊都有一組 “數字x數字x數字” 的標注,對于這個標注的理解其實可以簡單地把它想做把影像分割成了多少個網格,比如 38x38x512 就可以理解為將一張圖片分割成了 38x38 個小網格并進行了512次的特征提取,
- 在獲取完這些特征層并對影像添加了網格之后,就需要來添加先驗框了!這里以SSD作者的解釋為例(如下圖):可見右邊這兩個feature map中的虛線部分,就是我們提前根據每個網格的中心而添加的先驗框(def box),這也就是我們為什么要在特征提取環節要對影像繪制網格的原因了,
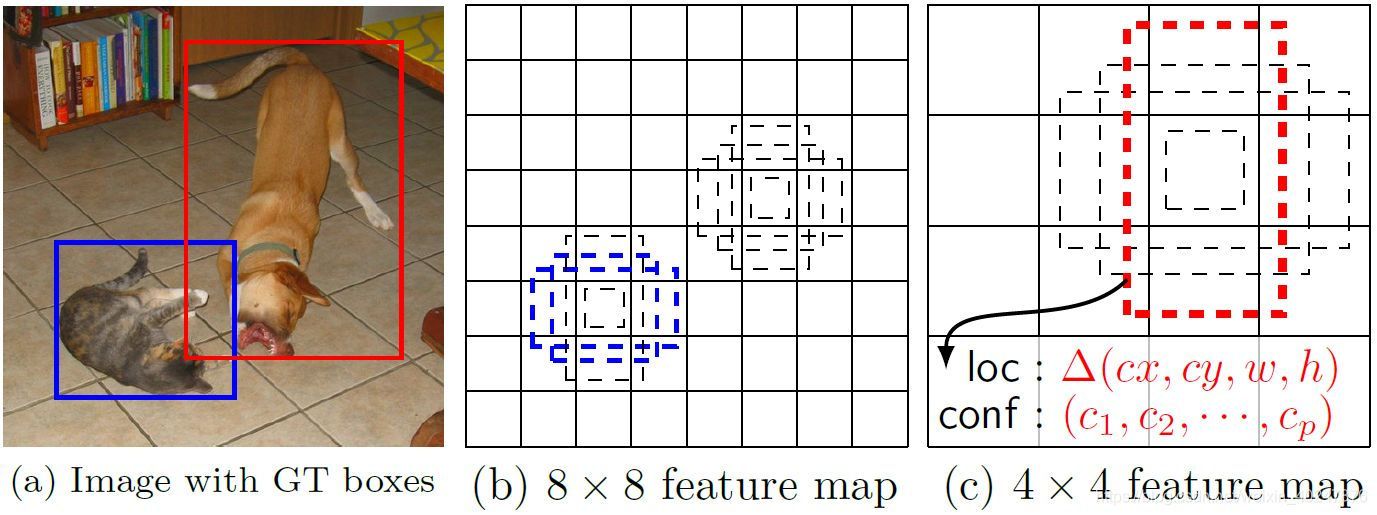
對應SSD網路架構圖中標識,可以看出來我們一共添加了:38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732個先驗框,也就得到了類似于以下的結果,

- 在獲得了這么多的先驗框(def box)之后,分別判斷這8732個先驗框中有沒有我們需要的物體,如果有的話就把它標記出來,當然在利用這些先驗框所得到的框中肯定會有一些比如發生了與被檢測物體重合的情況,之后就需要我們對這些框的得分和重合情況進行判斷,利用非極大抑制的方法找到我們需要的框并且標記出它所屬于的種類,這樣就算完成了SSD檢測演算法的檢測程序了,
四. 博文推薦
由于博主這篇博文是為了讓新手更加輕松地去理解SSD演算法,實際上SSD演算法的巧妙之處并不止這些,如果您想要進一步深入地去了解SSD演算法,請移步以下大佬的博文,
- 目標檢測演算法——SSD詳解
- 目標檢測SSD演算法(新手入門)
- 睿智的目標檢測23——Pytorch搭建SSD目標檢測平臺
- SSD演算法詳解
如有問題,敬請指正,歡迎轉載,但請注明出處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287360.html
標籤:其他
上一篇:Java模擬面試總結