分布式系統的一致性原理
對于分布式系統,我們必須要深刻理解和牢記一點:分布式系統的不可靠性,
可靠性指系統可以無故障地持續運行,如果一個系統在運行中意外宕機或者無法正常使用,它就是一個不可靠的系統,即使宕機和無法使用的時間很短,我們知道,分布式系統通常是由獨立的服務器通過網路松散耦合組成的,網路在本質上是一個復雜的IO系統,在通常情況下,I/O發生故障的概率和不可靠性要遠遠高于主機的CPU和記憶體,加之網路設備的引入,也增加了系統發生大面積“癱瘓”的可能性,總之,分布式系統中重要的理論和設計都是建立在分布式系統不可靠這一基礎上的,因為系統不可靠,所以我們需要增加一些額外的復雜設計和功能,來確保由于分布式系統的不可靠導致系統不可用性的概率降到最低,可用性是一個計算指標,如果系統在每小時崩潰lms,它的可用性就超過99.999 9%;如果一個系統從來不崩潰,但是每年要停機兩周,那么它是高度可靠的,但是可用性只有96%,
在理解了分布式系統的可靠性原理后,接下來我們開始接觸分布式系統中影響深遠的一個重要原理——一致性原理,分布式集群的一致性是在分布式系統里“無法繞開的一塊巨石”,很多重要的分布式系統都涉及一致性問題,而目前解決此問題的幾個一致性演算法都非常復雜,
分布式集群中一致性問題的場景描述如下:
N個節點組成一個分布式集群,要保證所有節點都可以執行相同的命令序列,并達到一致的狀態,即在所有節點都執行了相同的命令序列后,每個節點上的結果都完全相同,實際上,由于分布式系統的不可靠性,通常只要保證集群中超過半數的節點(N/2+1)正常并達到一致性即可,
前面說過,絕大多數分布式集群都采用了中心化的設計思想,上述最終一致性問題場景里的集群也遵循了這種設計,即存在一個Leader,但比較特別的是在這個場景里,集群中的其他節點都是Leader 的追隨者——Follower,客戶端發送給Leader的所有指令,Follower都復制一遍,這聽起來很簡單,但在一個分布式環境下實際上很難實作,
如下圖所示是分布式集群“一致性”演算法的一個典型案例,來自Kafka,
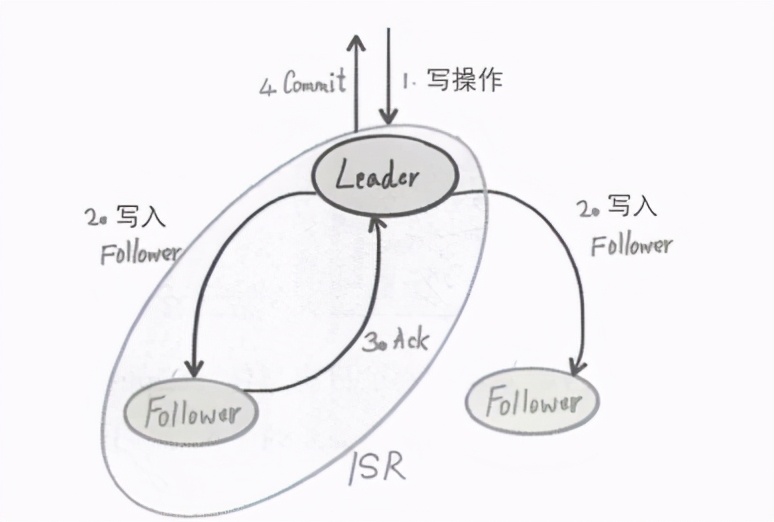
當客戶端向Kafka集群發起寫Message請求時,集群的Leader就會先寫一份資料到本地,同時向多個Follower 發起遠程寫入請求,在這個程序中,可能會有意外情況導致某些Follower節點發生故障而無法應答(Ack),此時,按照一致性演算法,如果在集群中有超過一半以上的節點正常應答,則表明此次操作執行成功,在上圖中包括Leader在內的兩個節點成功,所以Leader會提交(Commit)Message資料并且回傳成功應答給客戶端,否則不會提交資料,此次寫入請求失敗,
由于一致性演算法所描述的場景很有代表性,而且分布式系統中幾乎每個涉及資料持久化的系統都會面臨這一復雜問題,加上該演算法本身的復雜性與挑戰性,所以它一直是分布式領域的熱點研究課題之一,早在1989年就誕生了著名的 Paxos經典演算法(ZooKeeper就采用了Paxos演算法的“近親兄弟”Zab演算法),但由于Paxos演算法非常難以理解、實作和排錯,所以不斷有人嘗試簡化這一演算法,直到2013年才有了重大突破:斯坦福的 Diego Ongaro、John Ousterhout 以易懂性(Understandability)為目標設計了新的一致性演算法——Raft,并發布了對應的論文InSearch of an Understandable Consensus Algorithm,到現在已經有以十多種語言實作的Raft演算法實作框架,較為出名的有以Go實作的Etcd,它的功能類似于ZooKeeper,但采用了更為主流的REST 介面,
Raft演算法把分布式集群的一致性問題抽象成一個特殊的狀態機模型——Replicated StateMachine,如下圖所示,
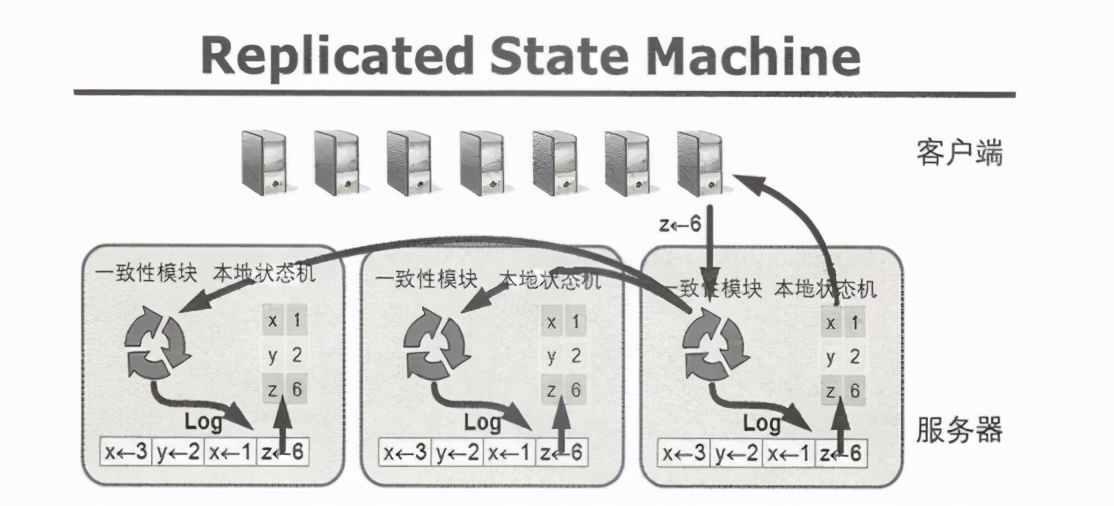
在上述模型里,集群中的每臺服務器都通過日志檔案(ReplicatedLog)來持久化保存客戶端發出的指令序列,供本地狀態機(State Machine)順序執行,只需保證每臺服務器上日志檔案的一致性,就能保證整個集群里狀態機的一致性,
接下來談談分布式集群的最終一致性問題,其實最終一致性是降低了標準的一致性,即以資料一致性存在延時來換取資料讀寫的高性能,目前最終一致性基本成為越來越多的分布式系統所遵循的一個設計目標,對其場景的完整描述如下,
假設資料B被更新,則后續對資料B的讀取操作得到的不一定是更新后的值,從資料B被更新到后續讀取到資料B的最新值會有一段延時,這段延時又叫作不一致視窗(InconsistencyWindow),不一致視窗的最大值可以根據以下因素確定:通信延時、系統負載、復制方案涉及的副本數量等,最終一致性則保證了不一致視窗的時間是有限的,最終所有的讀取操作都會回傳資料B的最新值,DNS 就是使用最終一致性的成功例子,
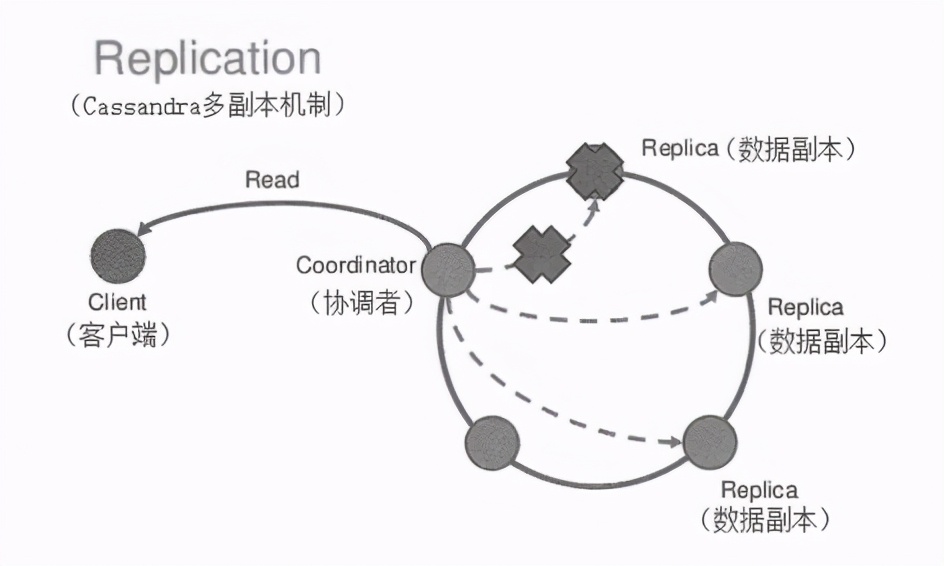
Facebook 開源的分布式資料庫 Cassandra 就是采用了最終一致性設計目標的一個知名NoSQL系統,如下所示是Cassandra 的資料復制架構示意圖,可以看到其與Kafka集群的資料復制流程類似,Cassandra被Digg、Twitter、360等公司大規模使用,其先進的架構和特性被眾多技術精英所看好,2015年,KVM之父AviKivity用C++重新開發了一款兼容Cassandra的全新開源資料庫——ScyllaDB,其聲稱每個節點每秒可處理100萬TPS,擁有超過Cassandra 10多倍的吞吐量并減少了延時,一時引發轟動,
本文給大家講解的內容是架構解密從分布式到微服務:分布式系統的一致性原理
- 下篇文章給大家講解的是架構解密從分布式到微服務:分布式系統的基石之 ZooKeeper;
- 覺得文章不錯的朋友可以轉發此文關注小編;
- 感謝大家的支持!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287361.html
標籤:其他
下一篇:物聯網平臺:一份全面前端知識總結