背景:
在KUDU之前,大資料主要以兩種方式存盤:
-
靜態資料:以HDFS引擎作為存盤引擎,適用于高吞吐量的離線大資料分析場景,這類存盤的局限性是資料無法進行隨機的讀寫,
-
動態資料:以HBase、Cassandra作為存盤引擎,適用于大資料隨機讀寫場景,這類存盤的局限性是批量讀取吞吐量遠不如HDFS,不適用于批量資料分析的場景,
從上面分析可知,這兩種資料再存盤方式上完全不同,進而導致使用場景完全不同,但在真實場景中,邊界可能沒有那么清晰,面對既需要隨機讀寫、又需要批量分析的大資料場景,該如何選擇呢?一個常見的方案是:
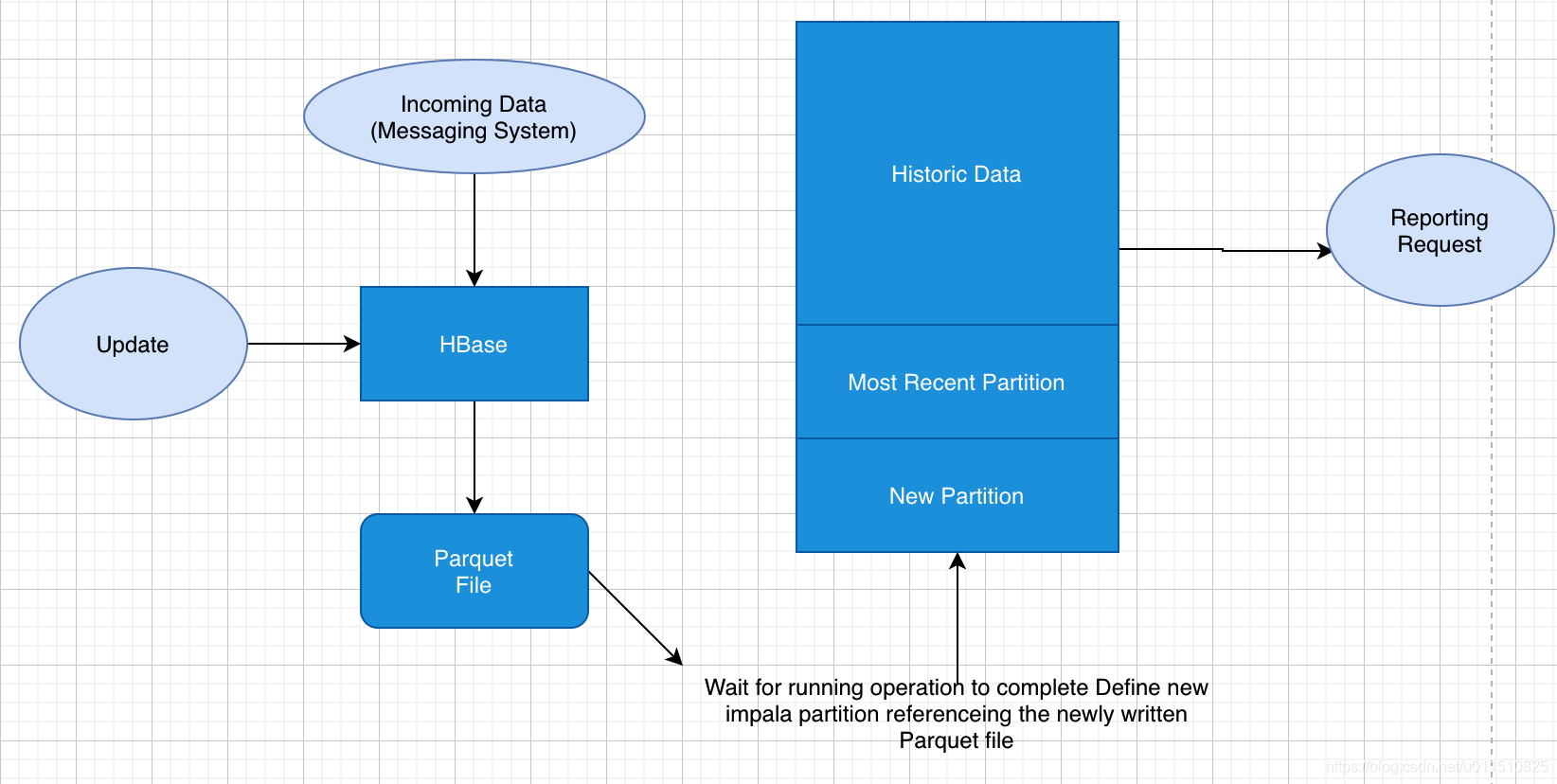
從上圖可以看出,KUDU是一個這種的產品,在HDFS和HBase這兩個偏科生中平衡了隨機讀寫和批量分析的性能,從KUDU的誕生可以說明一個問題:底層的技術發展很多時候都是上層業務推動的,脫離業務的技術很可能是“空中樓閣”
資料模型
KUDU的資料模型與傳統的關系型資料庫類似,一個KUDU集群由多個表組成,每個表由多個欄位組成,一個表必須指定一個由若干個(>=1)欄位組成的主鍵
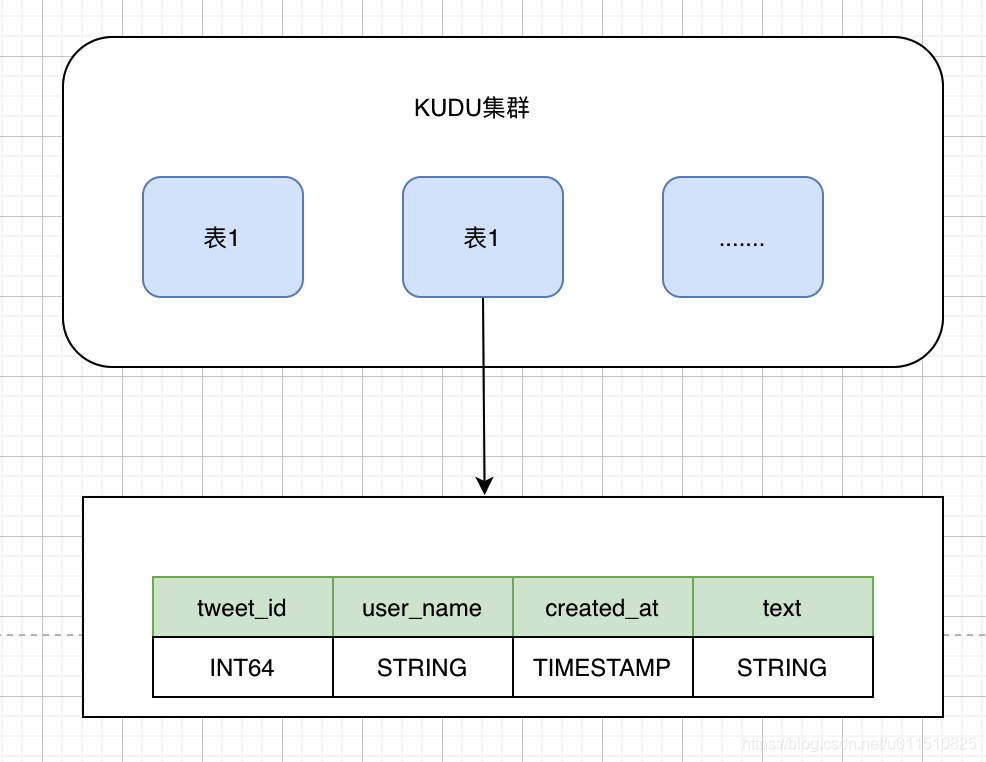
KUDU表中每個欄位是強型別的,而不是HBase那樣所有欄位都認為是bytes,這樣做的好處是可以對不同型別的資料進行不同的編碼,節省空間,同時,因為KUDU的使用場景是OLAP分析,有一個資料型別對下游的分析工具也更加優化,
核心API
KUDU的對外API主要分為寫跟讀兩部分,其中寫包括:Insert、Update、Delete,所有寫操作都必須制定主鍵;讀KUDU對外只體用了Scan操作,Scan時用戶可以指定一個或多個過濾器,用于過濾資料,
(資料庫中有read和scan操作,read:從資料庫中讀一條記錄, scan:在資料庫中執行范圍查詢,結果回傳一個記錄集,)
一致性模型
跟大多數關系型資料庫一樣,KUDU也是通過MVCC(Multi-Version Concurrency Control)來實作內部的事務隔離,
整體架構
KUDU中存在兩個角色
Master Server: 負責集群管理、元資料管理等功能
Tablet Server: 負責資料存盤,并提供資料讀寫服務,
為了實作磁區容錯性,跟其他大資料產品一樣,對于每個角色,在KUDU中都可以設定特定資料(3-5)的副本,各副本間通過Raft協議保證資料一致性,
KUDU Client與服務端互動時,先從Master Server獲取元資料資訊,然后去Tablet Server讀寫資料:
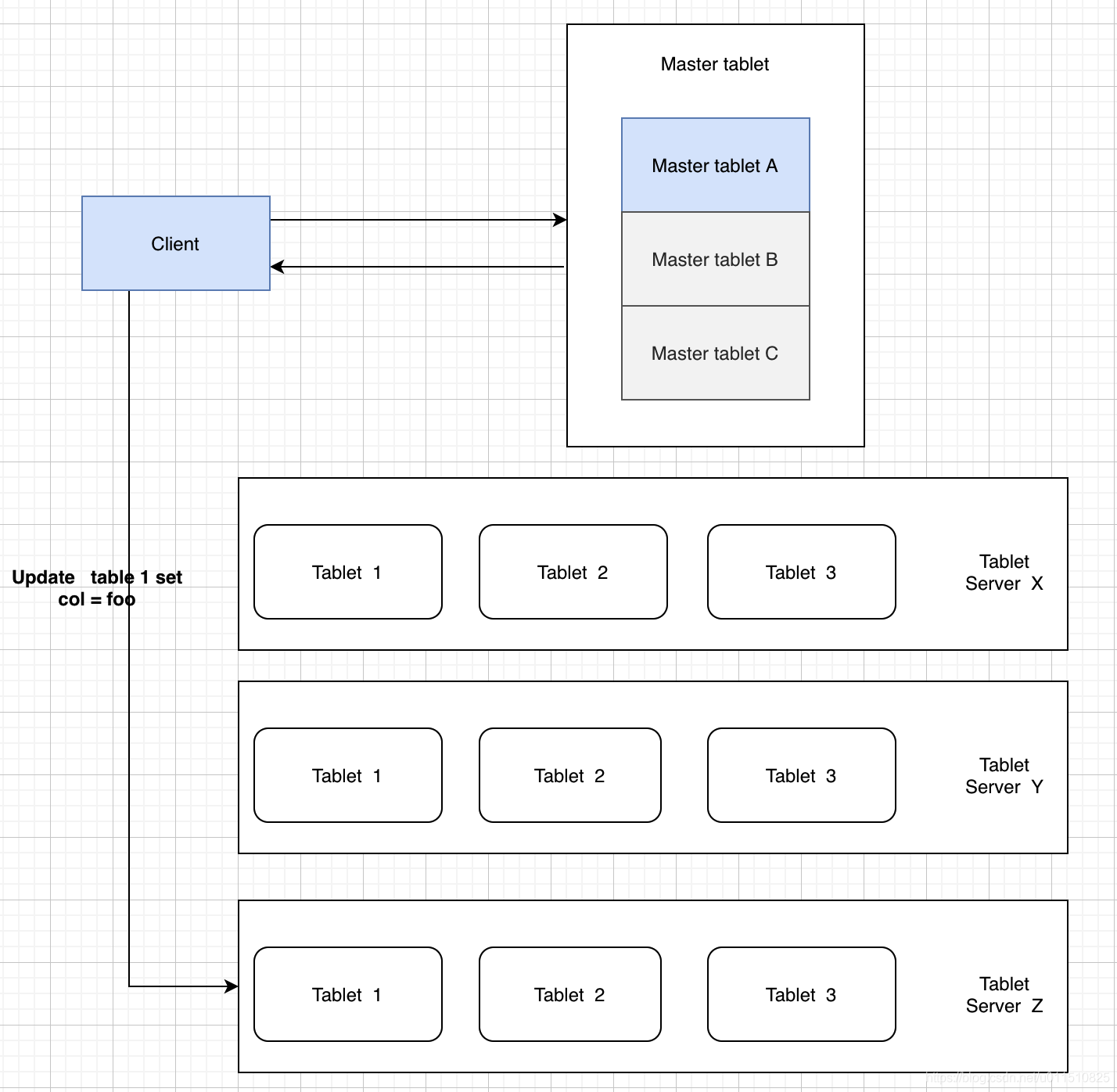
存盤實作:
與其他大資料存盤引擎類似,KUDU 的存盤也是通過 LSM 樹(Log-Structured Merge Tree)來實作的,KUDU 的最小存盤單元是 RowSets,KUDU 中存在兩種 RowSets:MemRowSets、DiskRowSets,資料先寫記憶體中的 MemRowSet,MemRowSet 滿了后刷到磁盤成為一個 DiskRowSet,DiskRowSet 一經寫入,就無法修改了,見下圖:
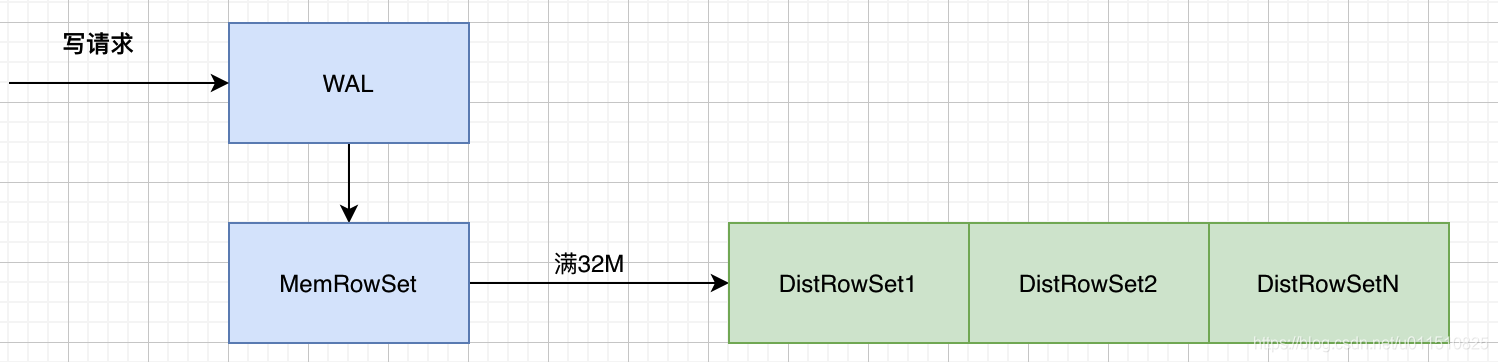
-
如何應對資料變更?
-
如何優化讀寫性能以滿足 OLAP 場景?
應對資料變更
首先上面我們講了,DiskRowSet 是不可修改了,那么 KUDU 要如何應對資料的更新呢?在 KUDU 中,把 DiskRowSet 分為了兩部分:*base data*、*delta stores*,base data 負責存盤基礎資料,delta stores負責存盤 base data 中的變更資料,整個資料更新方案如下:
-
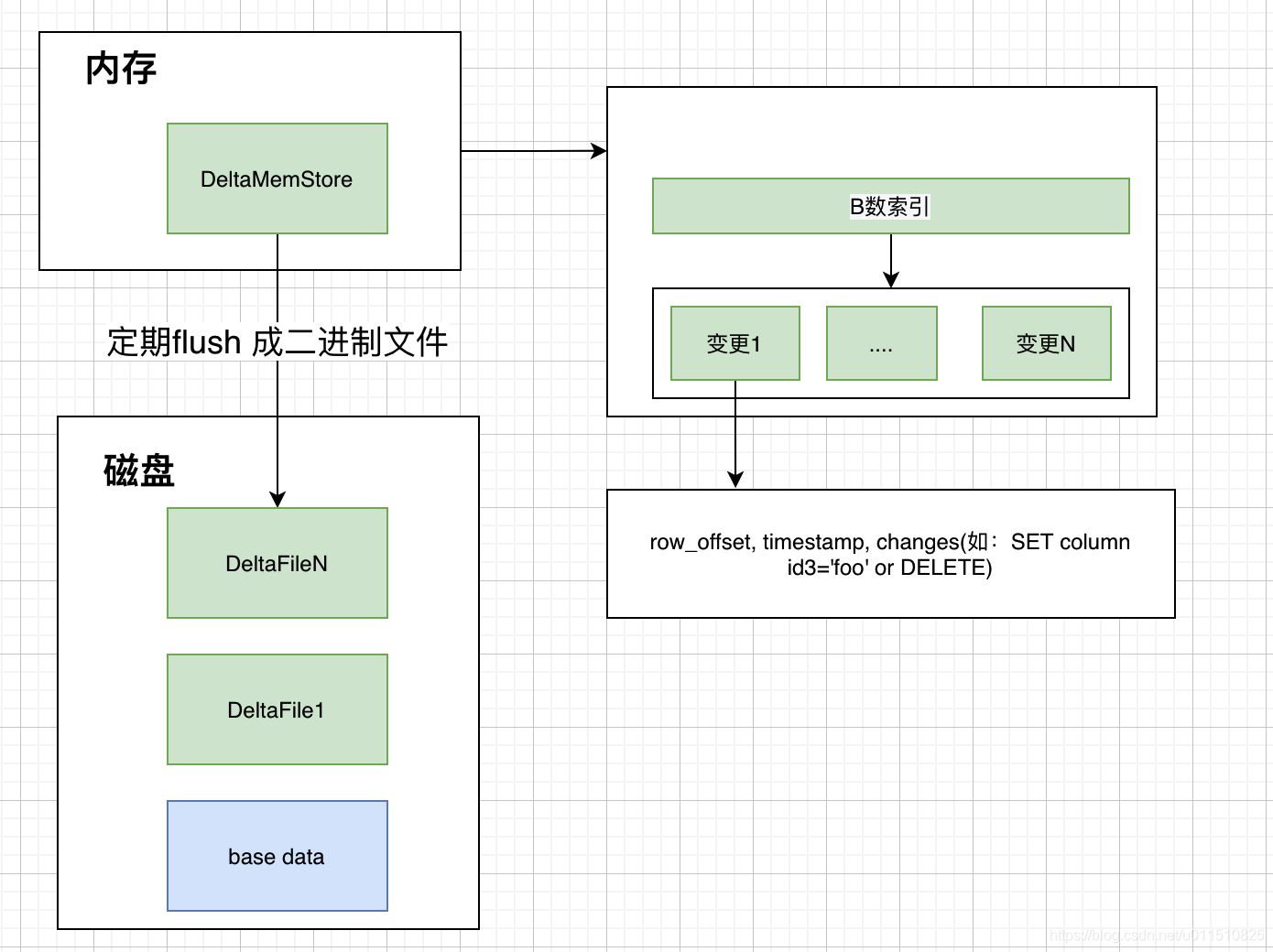
如上圖所示,資料從MeMRowSet刷到磁盤后就形成了一份DiskRowSet(只包含base data),每份DiskRowSet在記憶體中都會有一個對應的DeltaMemStore,負責記錄此DiskRowSet后續的資料變更(更新、洗掉),DeltaMemStore資料增長到一定程度后轉化成為二進制檔案存盤到磁盤中,形成一個DeltaFile,隨著base data對應資料的不斷變更,DeltaFile逐漸增長,
優化讀寫性能
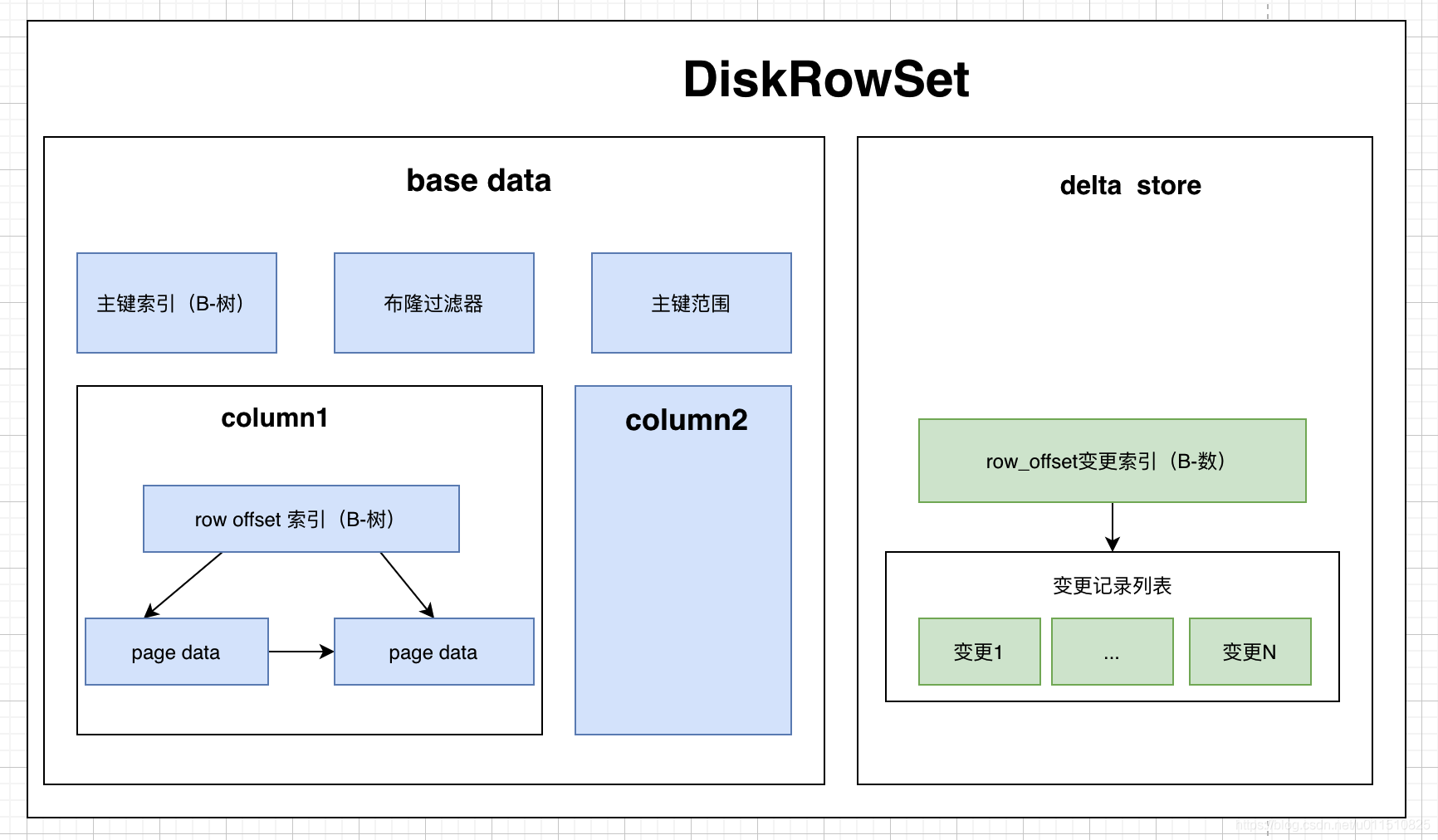
首先我們從KUDU的DiskRowSet資料結構上分析:
-
-
從上圖可知,在具體的資料(列資料、變更記錄)上,KUDU都做了B-樹索引,以提高隨機讀寫的性能,
-
主鍵范圍索引:記錄本DiskRowSet中主鍵的范圍,用于粗粒度過濾一些主鍵范圍,
-
布隆過濾器:通過主鍵的布隆過濾器來實作不存在資料的過濾
-
主鍵索引:要精確定位一個主鍵是否存在,以及具體在DiskRowSet中的位置(即:row_offset),通過以B-樹為資料結構的主鍵索引來快速查找,
隨著時間的推移,KUDU中的小檔案會越來越多,主要包括各個DiskRowSet中的base data, 還有每個base data對應的若干份DeltaFile,小檔案的增多會影響KUDU的性能,特別是DeltaFile中還有很多重復的資料,為了提高性能,KUDU會進行定期Compaction,compaction主要包括兩部分:
-
DeltaFile compaction: 過多的DeltaFile影響讀性能,定期將DeltaFile合并回base data可以提升性能,
-
DiskRowSet compaction: 除了DeltaFile,定期將DiskRowSet合并也能提升性能,一個原因是合并時我們可以將被洗掉的資料徹底的洗掉,而且可以減少同樣key范圍內資料的檔案數,提升索引的效率,
當用戶的查詢存在列的過濾條件時,KUDU還可以在查詢時進行 延遲物化來提升性能,舉例說明:
-
-
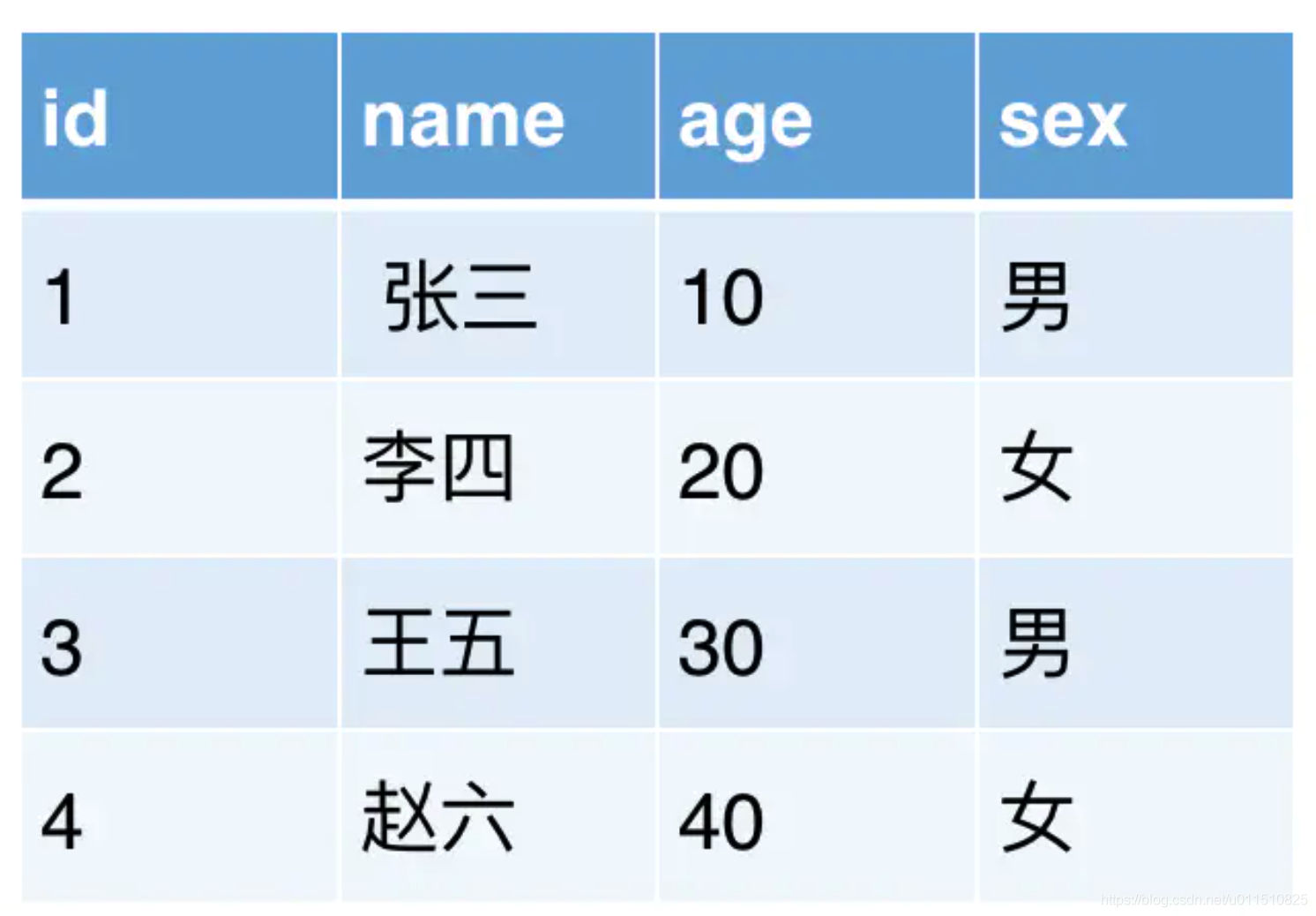
用戶的SQL是這樣的:
select * from tb where sex=‘男’ and age >20KUDU中資料查詢程序是這樣的:
1、掃描sex列,過濾出要查詢的行[1,3]
2、掃碼age列,過濾出要查詢的行[3,4]
3、過濾條件相交,得到3
4、真正讀取id=3行所對應的列資訊,組裝
資料寫程序
-
-
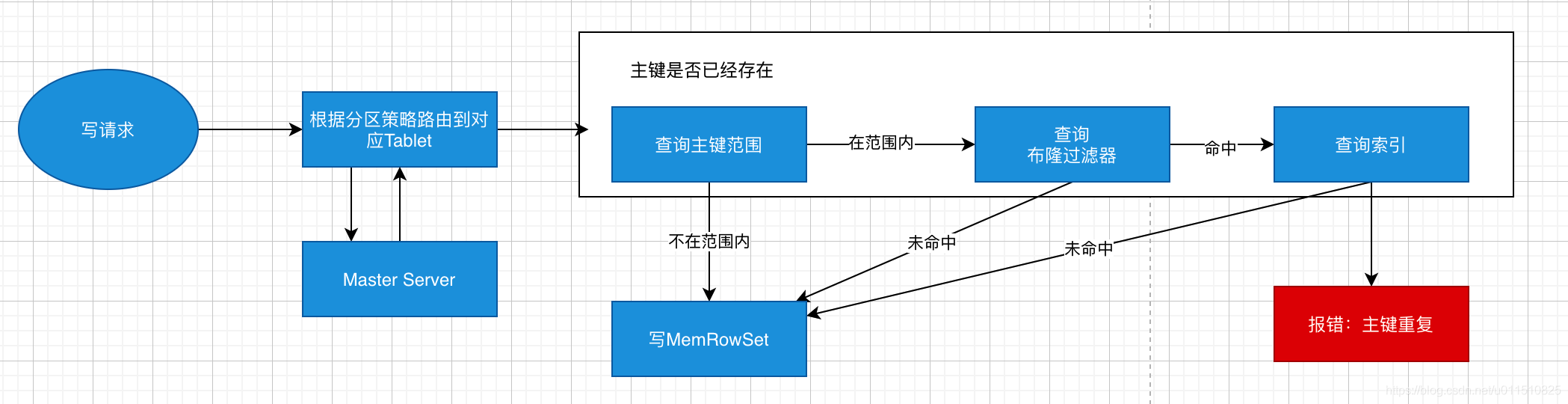
如上圖,當 Client 請求寫資料時,先根據主鍵從 Mater Server 中獲取要訪問的目標 Tablets,然后到依次對應的 Tablet 獲取資料,因為 KUDU 表存在主鍵約束,所以需要進行主鍵是否已經存在的判斷,這里就涉及到之前說的索引結構對讀寫的優化了,一個 Tablet 中存在很多個 RowSets,為了提升性能,我們要盡可能地減少要掃描的 RowSets 數量,首先,我們先通過每個 RowSet 中記錄的主鍵的(最大最小)范圍,過濾掉一批不存在目標主鍵的 RowSets,然后在根據 RowSet 中的布隆過濾器,過濾掉確定不存在目標主鍵的 RowSets,最后再通過 RowSets 中的 B-樹索引,精確定位目標主鍵是否存在,如果主鍵已經存在,則報錯(主鍵重復),否則就進行寫資料(寫 MemRowSet),
資料更新程序
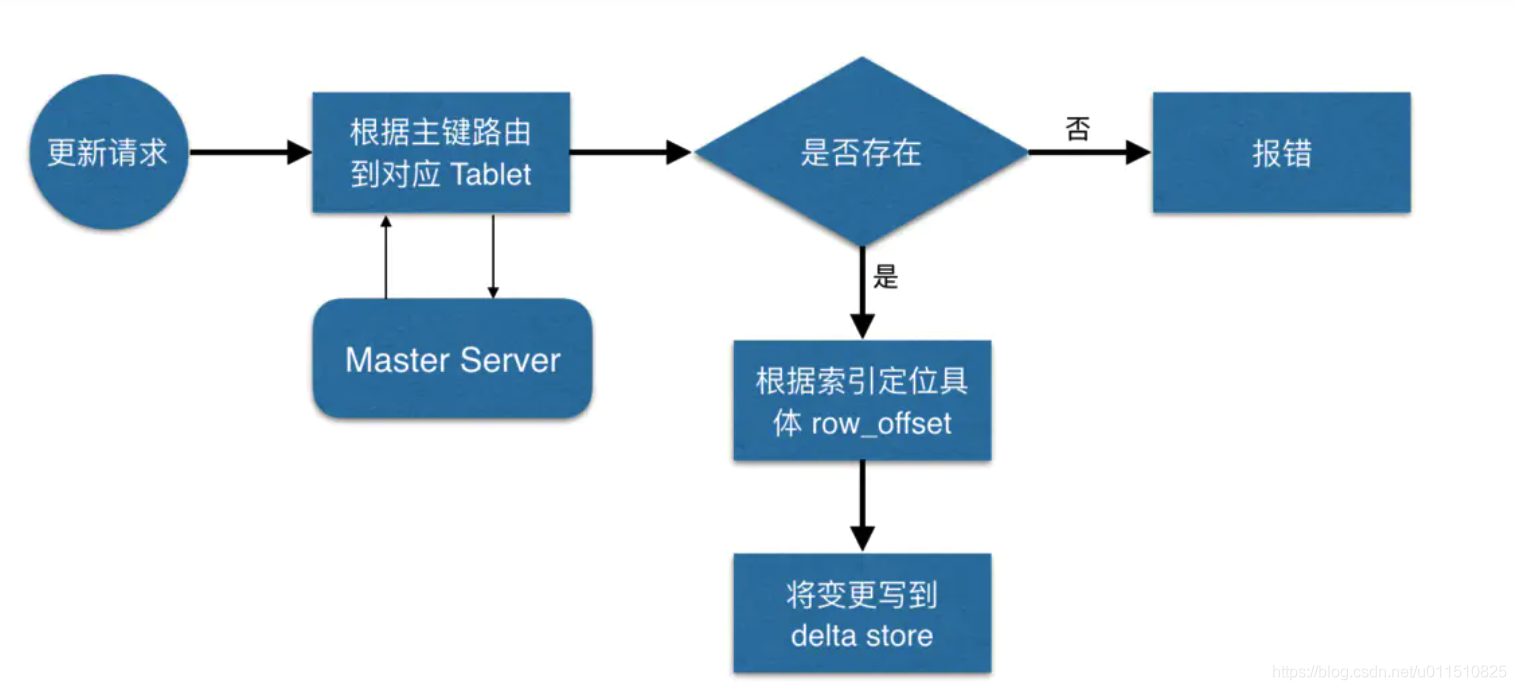
-
-
資料更新的核心是定位到待更新資料的位置,這塊與寫入的時候類似,就不展開了,等定位到具體位置后,然后將變更寫到對應的 delta store 中,
資料讀程序
-
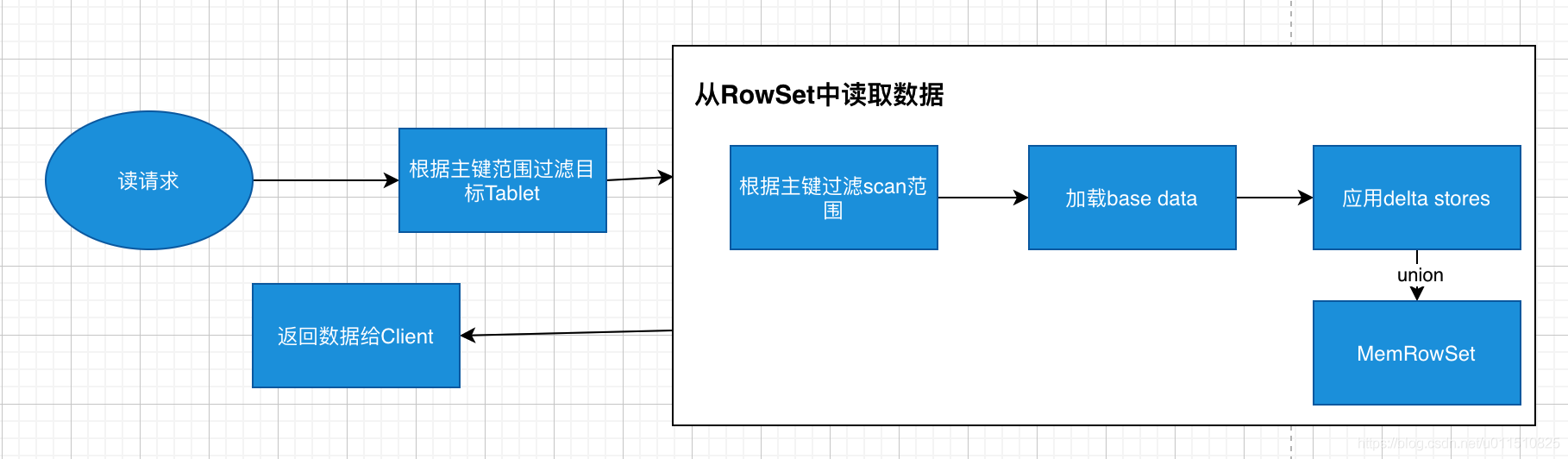
如上圖, 資料讀取程序大致如下:先根據要掃描資料的主鍵范圍,定位到目標的Tablets,然后讀取Tablets中的RowSets,在讀取每個RowSet時,先根據主鍵過濾要scan范圍,然后加載范圍內的base data,再找到對應的delta stores, 應用所有變更,最后union上MemRowSet中的內容,回傳資料給Client,
-
應用案例
在使用KUDU前,小米的架構是這樣的:
-
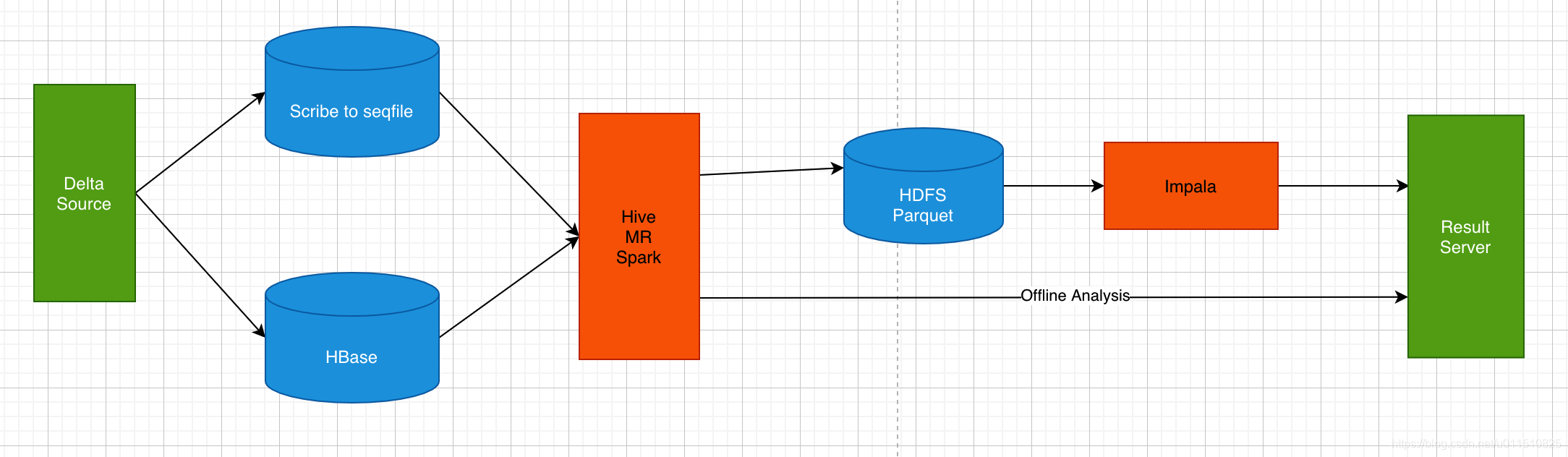
-
一部分源系統資料是通過Scribe(日志聚合系統)吧資料寫到HDFS,另一部分源系統資料直接寫入HBase,然后通過Hive/MR/Spark作業把兩部分資料合并,給離線數倉和OLAP分析,
在使用KUDU后,架構簡化成了:
-
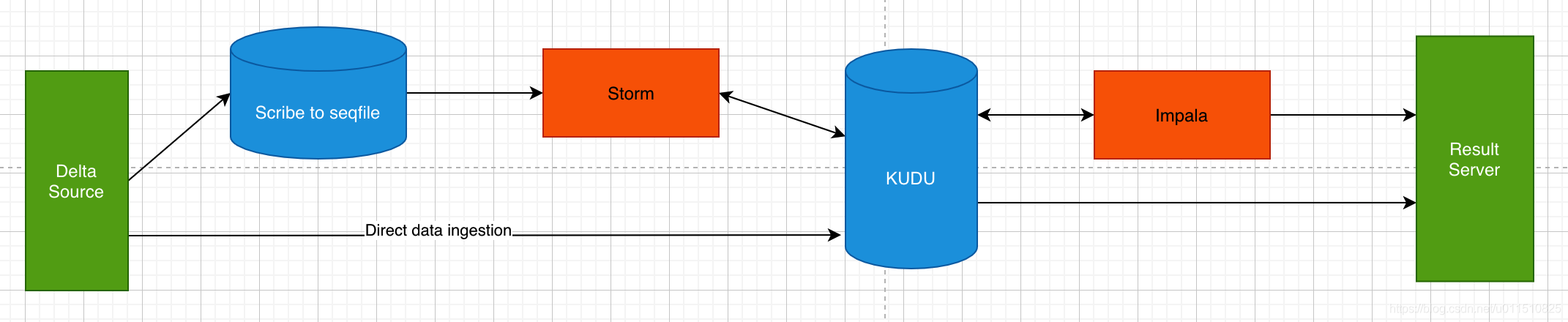
從上圖我們可以看到,所有的資料存盤都集中到KUDU一個上,減少了整體的架構復雜度,同時,也大大提升了實時性,
參考:
https://kudu.apache.org/
https://www.jianshu.com/p/93c602b637a4
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287584.html
標籤:其他