一. Hbase 的 region
咱們先簡單介紹下 Hbase 的 架構和 region :web
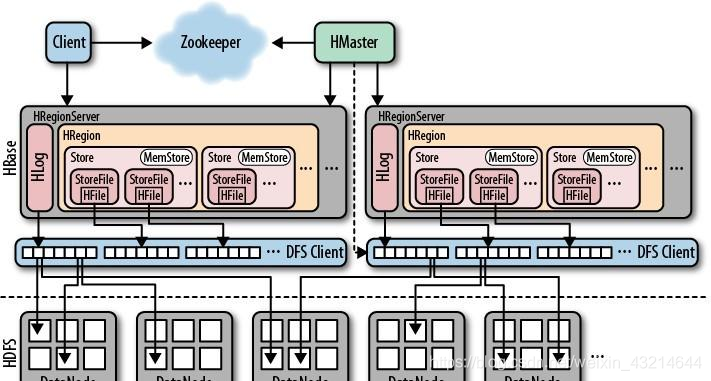
從物理集群的角度看,Hbase 集群中,由一個 Hmaster 管理多個 HRegionServer,其中每一個 HRegionServer 都對應一臺物理機器,一臺 HRegionServer 服務器上又能夠有多個 Hregion(如下簡稱 region),要讀取一個資料的時候,首先要先找到存放這個資料的 region,而 Spark 在讀取 Hbase 的時候,讀取的 Rdd 會根據 Hbase 的 region 數量劃分 stage,因此當 region 存盤設定得比較大致使 region 比較少,而 spark 的 cpu core 又比較多的時候,就會出現沒法充分利用 spark 集群全部 cpu core 的狀況,shell
咱們再從邏輯表結構的角度看看 Hbase 表和 region 的關系,服務器
Hbase是經過把資料分配到必定數量的region來達到負載均衡的,一個table會被分配到一個或多個region中,這些region會被分配到一個或者多個regionServer中,在自動split策略中,當一個region達到必定的大小就會自動split成兩個region,
Region由一個或者多個Store組成,每一個store保存一個columns family,每一個Strore又由一個memStore和0至多個StoreFile 組成,memStore存盤在記憶體中, StoreFile存盤在HDFS上,
region是HBase中分布式存盤和負載均衡的最小單元,不一樣Region分布到不一樣RegionServer上,但并非存盤的最小單元,
二. Spark 讀取 Hbase 優化及 region 手動拆分
在用spark的時候,spark正是根據hbase有多少個region來劃分stage,也就是說region劃分得太少會致使spark讀取時的并發度過低,浪費性能,但若是region數目太多就會形成讀寫性能降低,也會增長ZooKeeper的負擔,因此設定每一個region的大小就很關鍵了,架構
自0.94.0版本以來,split還有三種策略能夠選擇,不過通常使用默認的磁區策略就能夠知足需求,咱們要修改的是會觸發 region 磁區的存盤容量大小,并發
而在0.94.0版本中,默認的 region 大小為10G,就是說當存盤的資料達到 10 G 的時候,就會觸發 region 磁區操做,有時候這個值可能太大,這時候就須要修改配置了,咱們能夠在 HBASE_HOME/conf/hbase-site.xml 檔案中,增長以下配置:負載均衡
hbase.hregion.max.filesize 536870912 其中的 value 值就是你要修改的觸發 region 磁區的大小,要注意這個值是以 bit 為單位的,這里是將region檔案的大小改成512m,分布式修改以后咱們就能夠手動 split region了,手動磁區會自動根據這個新的配置值大小,將 region 已經存盤起來的資料進行再次進行拆分,svg
咱們能夠在 hbase shell 中使用 split 來進行操做,有如下幾種方式能夠進行手動拆分,性能
split ‘tableName’
split ‘namespace:tableName’
split ‘regionName’ # format: ‘tableName,startKey,id’
split ‘tableName’, ‘splitKey’
split ‘regionName’, ‘splitKey’
這里使用的是 split ‘namespace:tableName’ 這種方式,其中 tableName 自沒必要多說,就是要拆分的表名,namespace能夠在hbase的web界面中查看,通常會是default,優化
使用命令以后稍等一會,hbase會根據新的region檔案大小去split,最終結果能夠在web-ui的"table Details"一欄,點擊具體table查看,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287590.html
標籤:其他
上一篇:CI框架實作框架前后端分離的方法詳解:把前端代碼統一管理
下一篇:分布式事務詳解