最近面臨面試,抽空了解了下分布式事務,這篇主要介紹一下分布式事務相關的知識點以及現目前最流行的分布式事務解決工具seata,OK,進入正題
目錄
1.本地事務
1.1 什么是本地事務
1.2 本地事務如何保證ACID
1.2.1 undo和redo日志
2. 分布式事務
2.1 跨資料源的分布式鎖事務
2.2 跨服務
2.3 分布式系統帶來的資料一致性問題
3. 解決分布式事務的思路
3.1 CAP定理
3.1.1 consistency
3.1.2 Availability
3.1.3 partition tolerance
3.1.4 Consistency 和 Availability 的矛盾
3.1.5常見問題
3.2 BASE理論
4. 分階段提交
4.1 DTP和XA
4.2 二階段提交
4.3 TCC
4.3.1 基本原理
4.3.2 實體
4.3.3 優勢與缺點
4.3.4 使用場景
4.4 可靠訊息服務
4.4.1 基本原理
4.4.2 本地訊息表
4.5 AT模式
4.5.1 基本原理
4.5.2 詳細架構和流程
4.5.3 優缺點
5. seata
5.1 介紹
5.2 seata產品模塊
5.3 seata支持的事務模型
5.4 AT模式
5.4.1 準備資料
5.4.2 代碼
1.本地事務
在了解分布式事務之前,我們先來了解一下 本地事務,
什么是事務
事務:是資料庫操作的最小作業單元,是作為單個邏輯作業單元執行的一系列操作
1.1 什么是本地事務
本地事務,是指傳統單機模式下資料庫事務,必須滿足ACID原則:
- 原子性:指的是在整個、
- 要么全部執行成功,要么全部回滾不執行,
- 一致性:事務的執行必須保證系統的一致性,比如說:A向B打錢100元,那么A必須-100,B必須+100,
- 隔離性:不同事務之間操作互不影響,資料庫保證隔離性的四個隔離級別:
- 讀未提交:讀取了某個事務修改但為提交的資料,(造成臟讀)
- 讀已提交:解決了讀未提交造成的影響,由于多個事務同時處理某個資料,導致兩次讀到的資料不一致,(造成不可重復讀)
- 可重復讀:mysql的默認隔離級別,解決了不可重復讀的問題,(但是會造成幻讀)
- 可串行化:最高的隔離級別,它會對事務進行強制排序,解決之前所說的一切問題,
- 持久性:事務一旦提交永久保存
因為在傳統專案中,專案部署基本是單點的,即單個服務器和單個資料庫,這種情況下,資料庫本身的事務機制就能保證ACID的原則,這樣的事務就叫本地事務,
簡單來說的話,其實只要是在單個服務和單個資料庫的架構中,產生的事務即都是本地事務,
1.2 本地事務如何保證ACID
隔離性來說,資料庫本身就提供了4個隔離級別供其原則,簡單來說,你選擇不同的隔離級別,它會根據不同型別的鎖來進行執行,比如說排它鎖和共享鎖,
一致性來說,我認為其實它其實有點像“偽命題”,保證強一致性勢必保存同一個時刻只有一個事務在操作某條資料或者使用鎖的形式來操作,
而真正涉及到使用mysql自己的日志來處理的,就只有原子性和持久性,
1.2.1 undo和redo日志
再次回顧一下,
資料庫事務的原子性:在整個事務的所有操作中,要么全部成功,要么失敗回滾,
持久性:事務一旦提交永久保存,
Mysql有六種日志:
MySQL 中有六種日志檔案,分別是:
重做日志(redo log)、回滾日志(undo log)、二進制日志(binlog)、錯誤日志(errorlog)、慢查詢日志(slow query log)、一般查詢日志(general log),中繼日志(relay log),
這里只會講一講undo和redo日志,其余有興趣的同學可以下來自行了解下,比如主從復制用到的bin log 和 relay log,
undo日志
undo日志其實很好理解,你可以把它理解成記錄原始資料(也就是資料改變之前的樣子),
在任何資料操作之前,都會將其資料備份到undo log,如果出現了錯誤或者用戶開啟了rollback陳述句,那么系統將會利用undo log中的備份進行恢復,
下面是undo日志簡化程序:
假設有A、B兩個資料,值分別為1,2,
A. 事務開始.
B. 記錄A=1到undo log.
C. 修改A=3.
D. 記錄B=2到undo log.
E. 修改B=4.
F. 將undo log寫到磁盤,
G. 將資料寫到磁盤,
H. 事務提交
- 如何保證持久性?
事務提交前,會把修改的資料丟到磁盤,也就說只要事務提交了,那么資料肯定持久化了,
- 如何保證原子性呢?
每次對資料庫修改,都會把之前的資料備份到undo日志,那么需要回滾的時候,即可使用,
- 這時候有人會問了,如果系統在G和H之間崩潰了咋辦呢?
此時事務還沒提交,需要回滾,但是undo日志里面已經有東西了,所以可以直接根據undo日志來恢復資料,
- 如果在G之前崩潰了咋辦
此時的資料沒有持久到磁盤,不需要修改,因為它還在之前的狀態,
缺陷:每個事務提交前將資料和undo日志寫入磁盤,這樣會導致大量的磁盤IO,性能會降低,
這時候,我們就想辦法能不能將資料快取一段時間,減少IO呢?但是這樣的話又會喪失事務的持久性,這時候,我們就需要redo日志了,
redo日志
它和undo日志完全不一樣,它記錄的是新資料的備份,它在事務提交前,只需要將redo log持久化,不需要把資料持久化,這樣就減少了磁盤的io的次數,
先看看程序:
假設有A、B兩個資料,值分別為1,2
A. 事務開始.
B. 記錄A=1到undo log buffer.
C. 修改A=3.
D. 記錄A=3到redo log buffer.
E. 記錄B=2到undo log buffer.
F. 修改B=4.
G. 記錄B=4到redo log buffer.
H. 將undo log寫入磁盤
I. 將redo log寫入磁盤
J. 事務提交
-
如何保證原子性?
如果在事務提交前故障,通過undo log日志恢復資料,如果undo log都還沒寫入,那么資料就尚未持久化,無需回滾
-
如何保證持久化?
大家會發現,這里并沒有出現資料的持久化,因為資料已經寫入redo log,而redo log持久化到了硬碟,因此只要到了步驟
I以后,事務是可以提交的, -
記憶體中的資料庫資料何時持久化到磁盤?
因為redo log已經持久化,因此資料庫資料寫入磁盤與否影響不大,不過為了避免出現臟資料(記憶體中與磁盤不一致),事務提交后也會將記憶體資料刷入磁盤(也可以按照固設定的頻率重繪記憶體資料到磁盤中),
- redo log何時寫入磁盤
redo log會在事務提交之前,或者redo log buffer滿了的時候寫入磁盤
這里存在兩個問題:
問題1:之前是寫undo和資料庫資料到硬碟,現在是寫undo和redo到磁盤,似乎沒有減少IO次數
-
資料庫資料寫入是隨機IO,性能很差
-
redo log在初始化時會開辟一段連續的空間,寫入是順序IO,性能很好
-
實際上undo log并不是直接寫入磁盤,而是先寫入到redo log buffer中,當redo log持久化時,undo log就同時持久化到硬碟了,
因此事務提交前,只需要對redo log持久化即可,
另外,redo log并不是寫入一次就持久化一次,redo log在記憶體中也有自己的緩沖池:redo log buffer,每次寫redo log都是寫入到buffer
問題2:redo log 資料是寫入記憶體buffer中,當buffer滿或者事務提交時,將buffer資料寫入磁盤,
redo log中記錄的資料,有可能包含尚未提交事務,如果此時資料庫崩潰,那么如何完成資料恢復?
資料恢復有兩種策略:
-
恢復時,只重做已經提交了的事務
-
恢復時,重做所有事務包括未提交的事務和回滾了的事務,然后通過Undo Log回滾那些未提交的事務
Inodb引擎采用的是第二種方案,因此undo log要在 redo log前持久化
,在提交時一次性持久化到磁盤,減少IO次數,
最后總結一下:
-
undo log 記錄更新前資料,用于保證事務原子性
-
redo log 記錄更新后資料,用于保證事務的持久性
-
redo log有自己的記憶體buffer,先寫入到buffer,事務提交時寫入磁盤
-
redo log持久化之后,意味著事務是可提交的
2. 分布式事務
分布式事務,就是指不是在單個服務或單個資料庫架構下,產生的事務:
- 跨資料源的分布式事務
- 跨服務的分布式事務
- 綜合情況
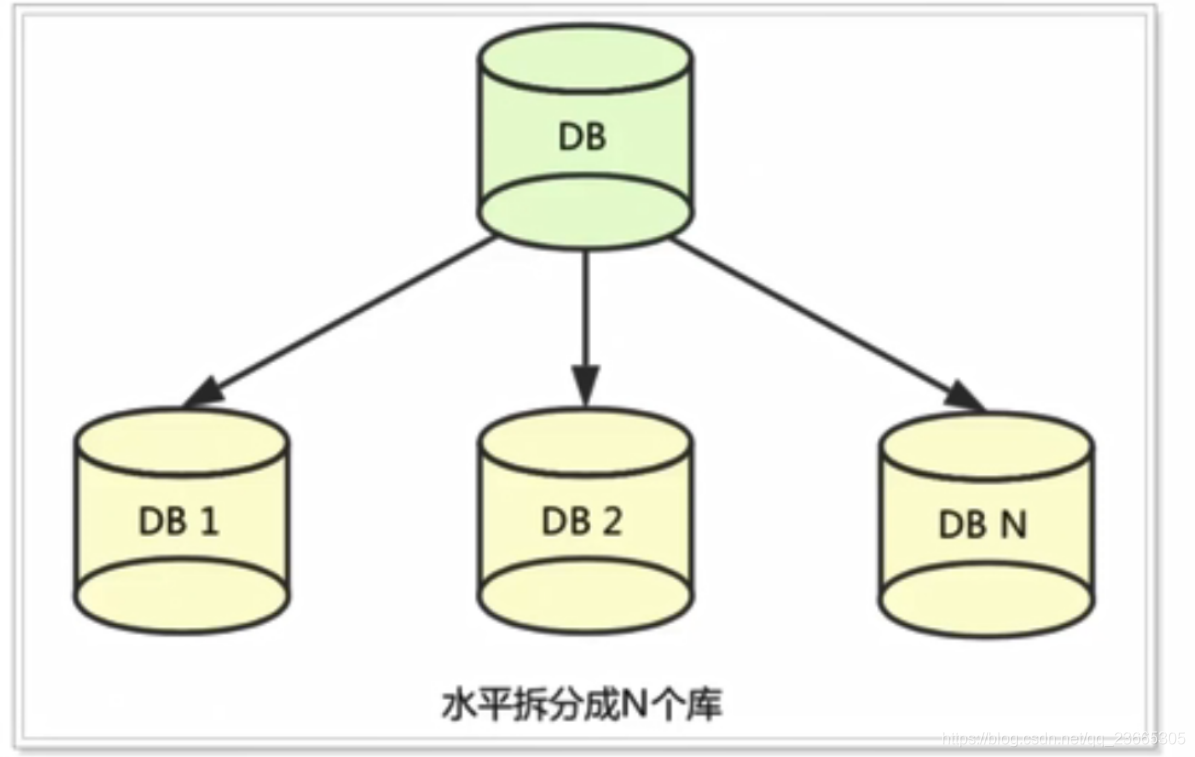
2.1 跨資料源的分布式鎖事務
隨著業務資料規模的快速發展,資料量越來越大,單庫單表逐漸成為瓶頸,所以我們對資料庫進行了水平拆分,將原單表拆分成資料庫分片,于是就產生了跨資料庫事務問題,
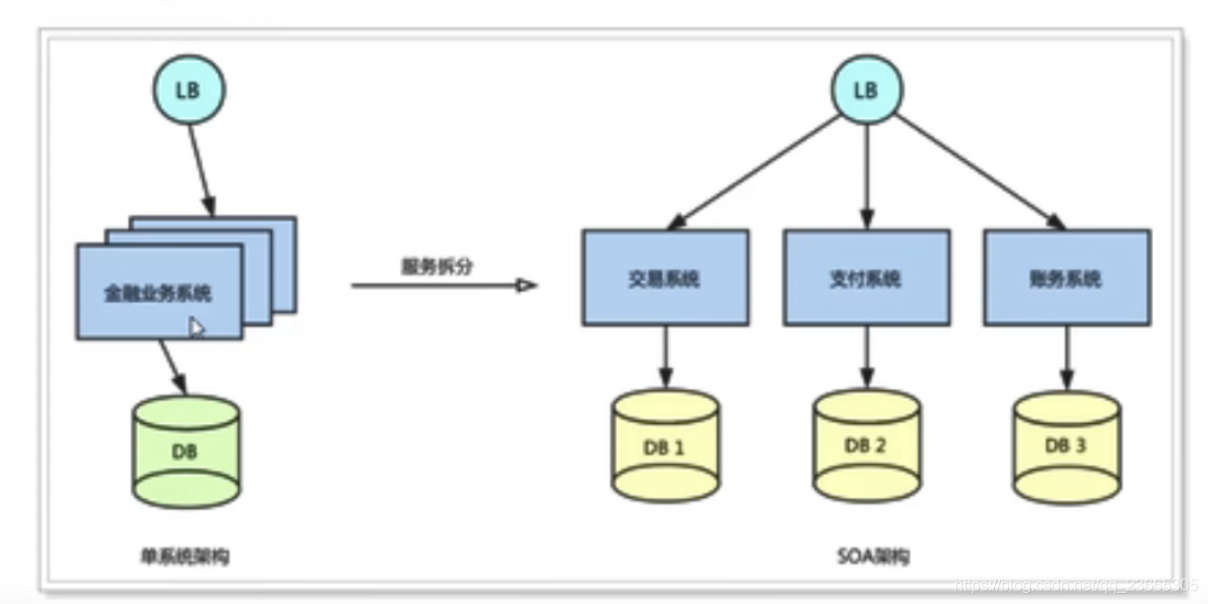
2.2 跨服務
在業務發展初期,單機架構服務就基本能滿足業務需求了,但是隨著業務的快速發展,系統的訪問量和業務的復雜程度都在快速增長,單體架構模式逐漸變成了負擔,所以解決業務系統的高耦合、可伸縮問題的需求越來越強烈,如下圖,按照面向服務(SOA)的架構的設計原則,將單業務系統拆分成多個業務系統,降低系統間的耦合度,使不同的業務系統專注于自身業務,更有利于業務的發展和系統容量的伸縮,
2.3 分布式系統帶來的資料一致性問題
在資料庫水平拆分、服務垂直拆分之后,一個業務操作通常要跨多個資料庫、服務才能完成,在分布式網路環境下,我們無法保障所有的服務、資料庫都百分之百能夠正常使用,一定會出現部分業務,資料庫執行成功,另外一個部分執行失敗的場景,
當出現部分業務操作成功、部分業務失敗時,業務資料就會出現不一致,
舉個簡單地例子,電商行業下單付款:
- 創建訂單
- 扣減商品庫存
- 扣款
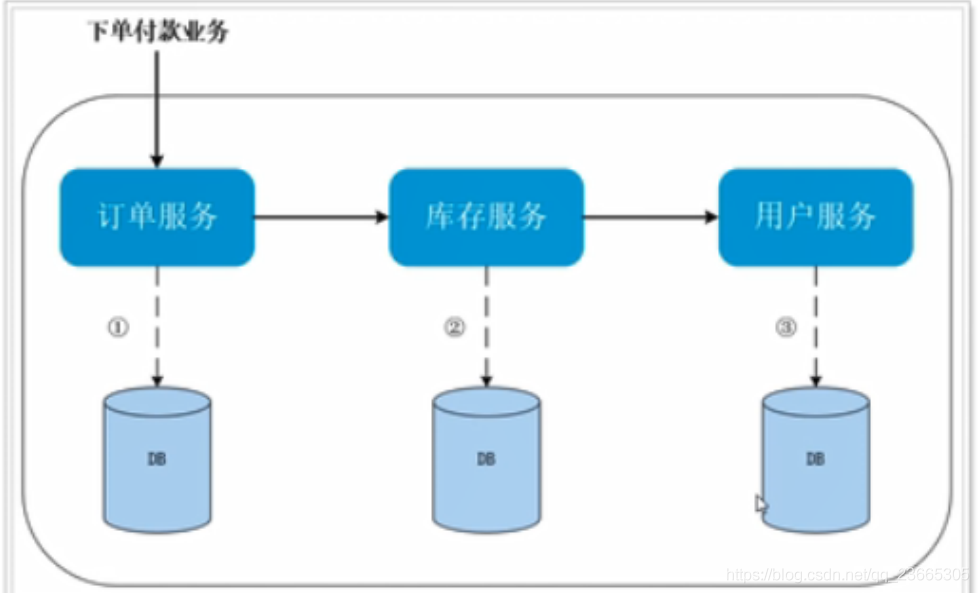
如上圖所示,肯定會出現我剛剛提到的問題,按照我們代碼的邏輯,如果下訂單成功之后,但是扣庫存失敗了,那么此時應該取消訂單的創建/ 或者訂單和庫存都成功了,扣款失敗了,需要回退訂單或者庫存,但是 由于它們不是本地事務,這個完全是相當于“三件事情”,所以沒辦法保證ACID,
3. 解決分布式事務的思路
剛才舉了例子,有的同學可能會問,為啥呢?
為啥分布式系統下,事務的ACID原則難以滿足?
記住,ACID只適用于單機模式下的事務控制,
為了解決分布式事務的處理問題,下面就介紹一下CAP定理和BASE理論
3.1 CAP定理
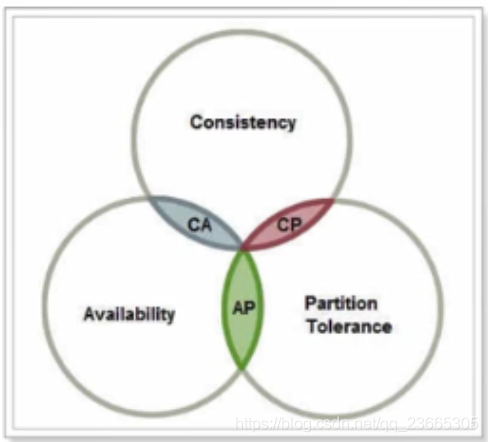
1998年,加州大學的計算機科學家 Eric Brewer 提出,分布式系統有三個指標,
- consistency(一致性)
- availability(可用性)
- partition tolerance(磁區容錯性)
他們的第一個字母分別是 C、A、P,
Eric Brewer 說,這三個指標不可能同時做到,這個結論就叫做 CAP 定理,
3.1.1 consistency
Consistency 中文叫做"一致性",
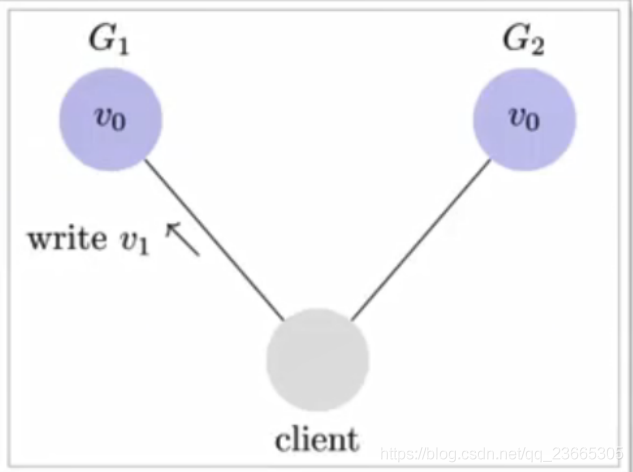
寫操作之后的讀操作,必須回傳該值,舉個例子:某條記錄是V0,用戶G1發起了一個寫操作,改成了V1
接下來,用戶的讀操作就會得到V1,這就叫一致性,
但是,問題來了,用戶可能向G2發起讀操作,由于G2的值沒有發生變化,因此回傳的是V0,G1和G2讀操作的結果不一致了,這就不滿足一致性了,
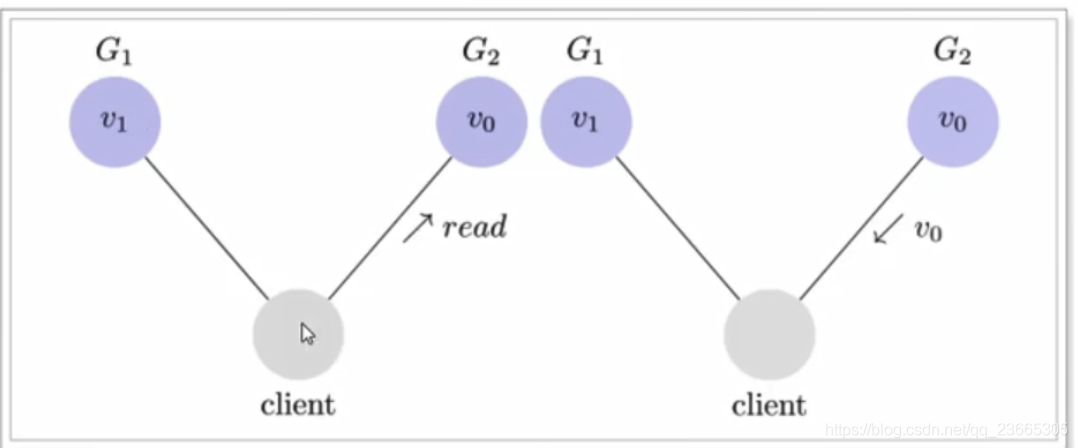
為了讓G2也能變成V1,就要在G1寫操作的時候,讓G1向G2發送一條訊息,告訴G2也要改成V1,(這有點像JMM的可見性),
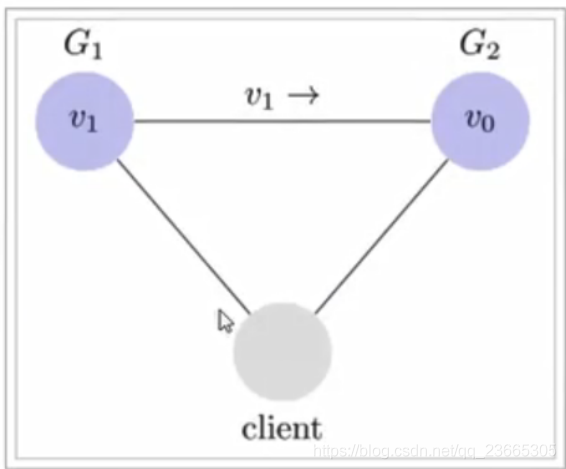
這樣的話,用戶向G2發送讀請求,才能也讀到V1,
3.1.2 Availability
Availability 中文叫做"可用性",意思是只要收到用戶的請求,服務器就必須給出回應(對和錯不論),
用戶可以選擇向G1或者G2發起讀操作,不管是哪臺服務器,只要收到請求,就必須告訴用戶,到底是V0還是V1,否則就不滿足可用性,
3.1.3 partition tolerance
磁區容錯性
一個分布式系統里面,節點組成的網路本來應該是連通的,然而可能因為一些故障,使得有些節點之間不連通了,整個網路就分成了幾塊區域,資料就散布在了這些不連通的區域中,這就叫磁區,
當你一個資料項只在一個節點中保存,那么磁區出現后,和這個節點不連通的部分就訪問不到這個資料了,這時磁區就是無法容忍的,
提高磁區容忍性的辦法就是一個資料項復制到多個節點上,那么出現磁區之后,這一資料項就可能分布到各個區里,容忍性就提高了,
3.1.4 Consistency 和 Availability 的矛盾
一致性和可用性為什么不能同時成立呢?
其實就是可能會通信失敗,
如果保證G2的一致性,那么G1必須在寫操作時,鎖定G2的讀操作和寫操作,只有資料同步后,才能重新放開鎖, 鎖定期間,G2不能讀,沒有可用性,
如果要保證G2的可用性,那么勢必不能對它進行鎖操作,所以一致性不成立,
so,綜上所述,G2無法同時滿足一致性和可用性,系統設計時只能選擇一個目標,如果追求一致性,那么無法保證所有節點的可用性;如果追求所有節點的可用性,那就沒法做到一致性,
3.1.5常見問題
- 怎么才能同時滿足CA?
除非是單機機構
- 何時要滿足CP?
對一致性要求高的場景,例zk,資料同步時,服務對外不可用
- 何時滿足AP
對可用性要求高的場景,比如說eureka,必須保證注冊中心隨時可用,
3.2 BASE理論
BASE是三個單詞的縮寫:
-
Basically Available(基本可用)
-
Soft state(軟狀態)
-
Eventually consistent(最終一致性)
而我們解決分布式事務,就是依據上述理論來實作的,
- BA:假設系統,出現了不可預知的故障,但還是能用
- S:什么是軟狀態呢?相對于原子性而言,要求多個節點的資料副本都是一致的,這是一種“硬狀態”,
- 軟狀態指的是:允許系統中的資料存在中間狀態,并認為該狀態不影響系統的整體可用性,即允許系統在多個不同節點的資料副本存在資料延時,
- E:在一定時間內允許資料不一致
還是以下訂單操作為例子:
訂單服務、庫存服務、用戶服務及他們對應的資料庫就是分布式應用中的三個部分,
- CP方式:現在如果要對事物要求強一致性,就必須在訂單服務資料庫鎖定的時候,對庫存服務,用戶服務同時鎖定,等待三個服務業務全部處理完成,才可以釋放資源,此時如果有其他請求想要操作被鎖定的資源就會被阻塞,此滿足CP,
- AP方式:三個服務對應資料庫各自執行,執行本地事務不會相互鎖定資源,但是中間狀態下,我們去訪問資料庫,可能會遇到不一致性的情況,不過我們需要做一些后補措施,保證在經過一段時間后,資料最終滿足一致性,
由上面的兩種思想,延伸出了很多分布式解決方案:
- XA
- TCC
- 可靠訊息最終一致性
- AT
4. 分階段提交
4.1 DTP和XA
分布式事務的解決手段之一,就是兩階段提交協議(2PC:Two-Phase Commit)
那么到底是兩階段提交呢?
1994年,X/Open組織(即現在的Open Group)定義了分布式事務處理的DTP模型,該模型包括這樣幾個角色:
- 應用程式(AP):我們的微服務
- 事務管理器(TM):全域事務管理者
- 資源管理區(RM):一般都是資料庫
- 通信資源管理器(CRM):是TM和RM間的通信中間件
在該模型中,一個分布式事務(全域事務)可以被拆分成許多個本地事務,運行在不同的AP和RM上,每個本地事務的ACID很好實作,但是全域事務必須保證其中包含的每一個本地事務都能同時成功,若有一個本地事務失敗,則所有其它事務都必須回滾,但問題是,本地事務處理程序中,并不知道其它事務的運行狀態,因此,就需要通過CRM來通知各個本地事務,同步事務執行的狀態,
因此,各個本地事務的通信必須有統一的標準,否則不同資料庫間就無法通信,XA就是 X/Open DTP中通信中間件與TM間聯系的介面規范,定義了用于通知事務開始、提交、終止、回滾等介面,各個資料庫廠商都必須實作這些介面,
4.2 二階段提交
二階段提交協議就是依據這一思想衍生出來的,將全域事務拆分成兩個階段來執行:
- 階段一:準備階段,各個本地事務完成本地事務的準備作業
- 階段二:執行階段,各個本地事務根據上一階段執行結果,進行提交或者回滾
這個程序中需要一個協調者(coordinator),還有事務的參與者(voter)
情況1:正常執行
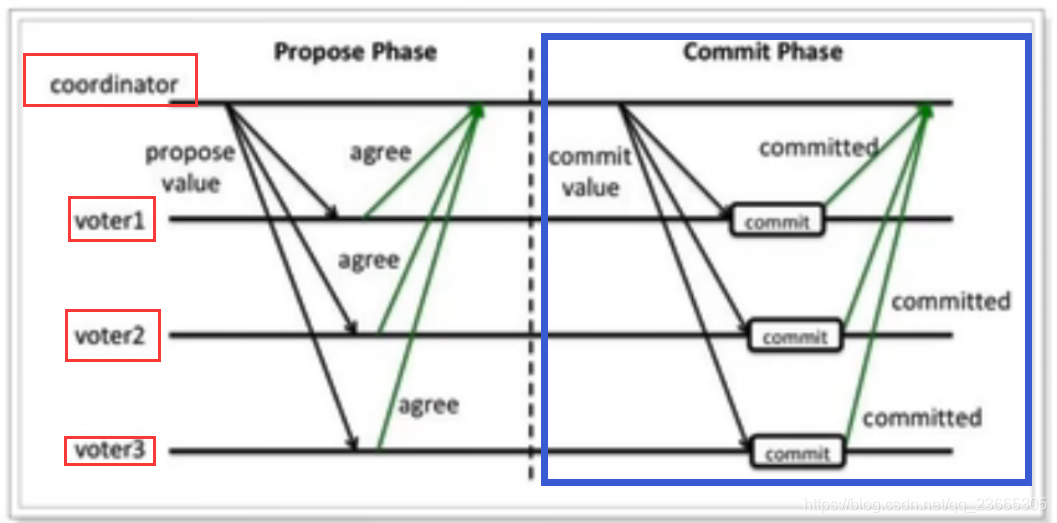
如上圖所示,
準備階段:協調者詢問每個事務參與者,是否可以執行事務,每個事務參與者執行事務,寫入redo和undo日志,然后進行反饋,
提交階段:協調者收到反饋如果發現每個參與者都可以正常執行事務,然后發出指令讓他們進行commit操作,
情況2:例外情況
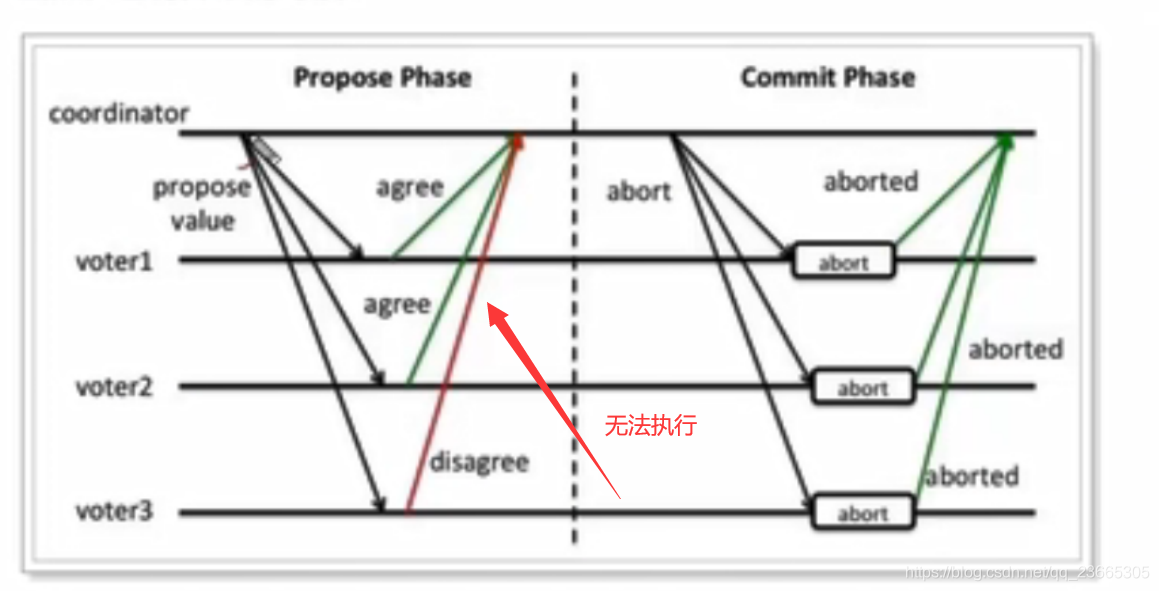
準備階段:協調者詢問每個事務參與者,是否可以執行事務,每個事務參與者執行事務,寫入redo和undo日志,然后進行反饋,but,只要有一個參與者回傳disagree,則說明執行失敗,
提交階段:協調者收到反饋如果發現每個參與者都可以正常執行事務,然后發出指令讓他們進行commit操作,如果有disagree,認為執行失敗,于是發出abort指令,各個事務回滾事務,
缺點
- 單點故障:如果協調者掛了,那么根本無法執行了,
- 阻塞問題:在準備階段,提交階段,每個事務參與者都會鎖定本地資源,并等待其他事務的執行結果,阻塞時間較長、資源鎖定時間太久,因此執行的效率比較低,
由于2PC的缺點,后來有提出了3PC,但是只是解決了阻塞問題,因此使用場景很少,
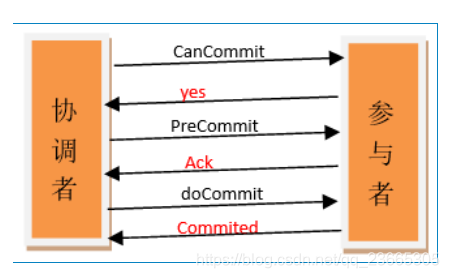
- 引入超時機制,同時在協調者和參與者中都引入超時機制,
- 在第一階段和第二階段中插入一個準備階段,保證了在最后提交階段之前各參與節點的狀態是一致的,
使用場景
對事務有強一致性要求(鎖資源),對事務執行效率不敏感,并且不希望有太多代碼侵入,
4.3 TCC
TCC模式可以解決2PC中的資源鎖定和阻塞問題,減少資源鎖定時間,
4.3.1 基本原理
它本質是一種補償機制的思路,事務運行包括是三個方法,
Try:資源的檢測和預留;
Confirm:執行的業務操作提交;要求Try成功Confirm一定要能成功;
Cancel:預留資源釋放,
執行分為兩個階段:
準備階段(try):資源的檢測和預留;
執行階段(confirm/cancel ):根據上一步結果,判斷下面的執行方法,如果上一步所有事務參與者都成功,那么confirm,否則執行cancel,
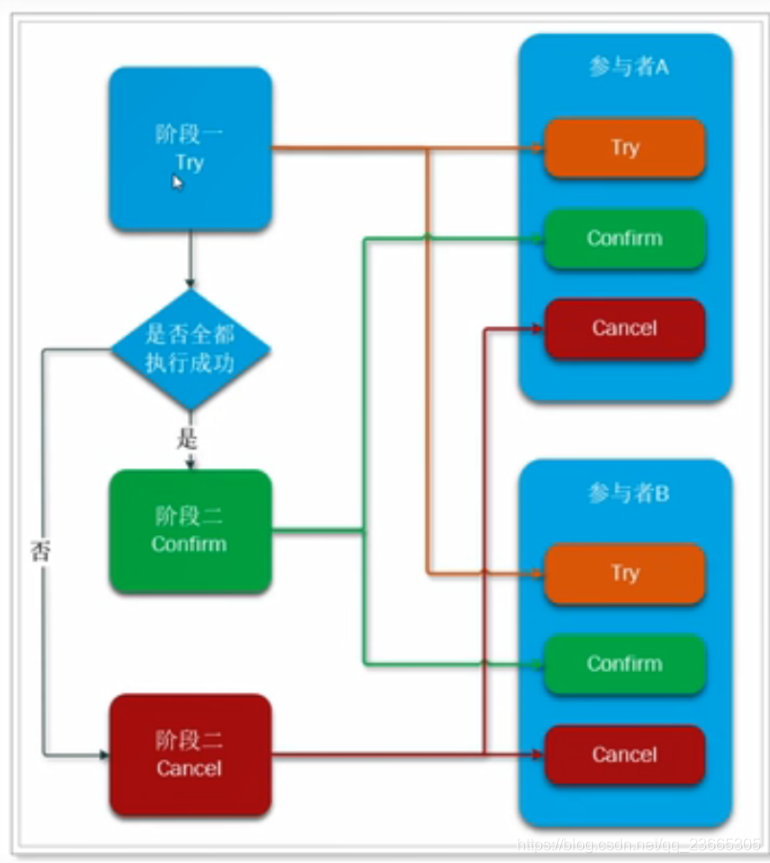
粗看似乎與兩階段提交沒什么區別,其實差別很大:
- try、confirm、cancel都是獨立的事務,不受其他參與者的影響,不會阻塞等待它人,
- try、confirm、cancel由程式猿在業務層撰寫,鎖粒度由代碼控制,
4.3.2 實體
我們之前的下單業務中的扣減余額為例,假設賬戶A的余額原來是100,需要余額扣減30元,如圖:

-
一階段(Try):余額檢查,并凍結用戶部分金額,此階段執行完畢,事務已經提交
-
檢查用戶余額是否充足,如果充足,凍結部分余額
-
在賬戶表中添加凍結金額欄位,值為30,余額不變
-
-
二階段
-
提交(Confirm):真正的扣款,把凍結金額從余額中扣除,凍結金額清空
-
修改凍結金額為0,修改余額為100-30 = 70元
-
-
補償(Cancel):釋放之前凍結的金額,并非回滾
-
余額不變,修改賬戶凍結金額為0
-
-
4.3.3 優勢與缺點
-
優勢
TCC執行的每一個階段都會提交本地事務并釋放鎖,并不需要等待其它事務的執行結果,而如果其它事務執行失敗,最后不是回滾,而是執行補償操作,這樣就避免了資源的長期鎖定和阻塞等待,執行效率比較高,屬于性能比較好的分布式事務方式,
-
缺點
-
代碼侵入:需要人為撰寫代碼實作try、confirm、cancel,代碼侵入較多
-
開發成本高:一個業務需要拆分成3個步驟,分別撰寫業務實作,業務撰寫比較復雜
-
安全性考慮:cancel動作如果執行失敗,資源就無法釋放,需要引入重試機制,而重試可能導致重復執行,還要考慮重試時的冪等問題
-
4.3.4 使用場景
-
對事務有一定的一致性要求(最終一致)
-
對性能要求較高
-
開發人員具備較高的編碼能力和冪等處理經驗
4.4 可靠訊息服務
這種實作方式的思路,其實是源于ebay,其基本的設計思想是將遠程分布式事務拆分成一系列的本地事務,
4.4.1 基本原理
一般分為事務的發起者A和事務的其它參與者B:
-
事務發起者A執行本地事務
-
事務發起者A通過MQ將需要執行的事務資訊發送給事務參與者B
-
事務參與者B接收到訊息后執行本地事務
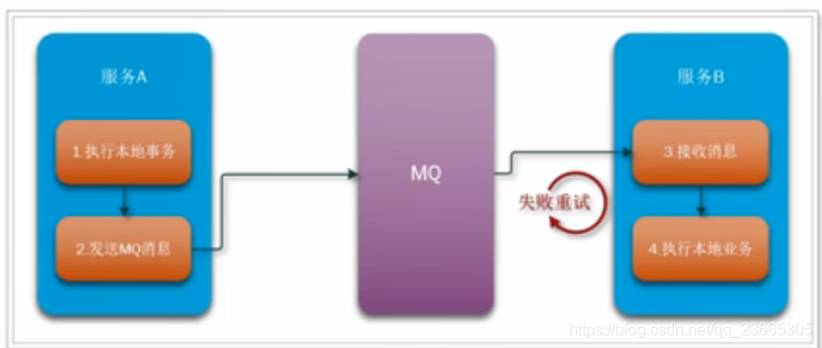
這個程序有點像你去學校食堂吃飯:
-
拿著錢去收銀處,點一份紅燒牛肉面,付錢
-
收銀處給你發一個小票,還有一個號牌,你別把票弄丟!
-
你憑小票和號牌一定能領到一份紅燒牛肉面,不管需要多久
幾個注意事項:
-
事務發起者A必須確保本地事務成功后,訊息一定發送成功
-
MQ必須保證訊息正確投遞和持久化保存
-
事務參與者B必須確保訊息最終一定能消費,如果失敗需要多次重試
-
事務B執行失敗,會重試,但不會導致事務A回滾
那么問題來了,我們如何保證訊息發送一定成功?如何保證消費者一定能收到訊息?
4.4.2 本地訊息表
我了避免訊息發送失敗或者丟失,我們可以把訊息持久化到資料庫中,實作時有簡化版本和解耦合版本兩種方式,
1.簡化版本
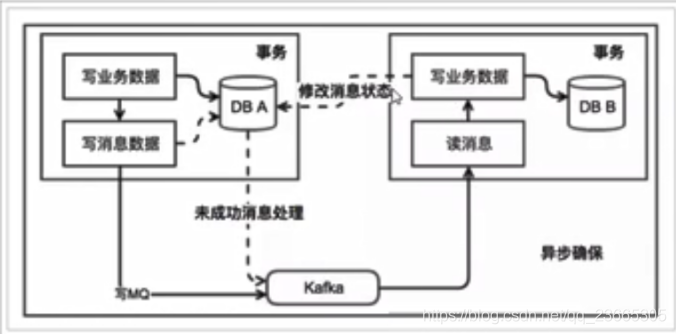
事務發起者:
-
開啟本地事務
-
執行事務相關業務
-
發送訊息到MQ
-
把訊息持久化到資料庫,標記為已發送
-
提交本地事務
事務接收者:
-
接收訊息
-
開啟本地事務
-
處理事務相關業務
-
修改資料庫訊息狀態為已消費
-
提交本地事務
額外的定時任務
-
定時掃描表中超時未消費訊息,重新發送
優點:
- 與tcc相比,實作方式較為簡單,開發成本低,
缺點:
-
資料一致性完全依賴于訊息服務,因此訊息服務必須是可靠的,
-
需要處理被動業務方的冪等問題
-
被動業務失敗不會導致主動業務的回滾,而是重試被動的業務
-
事務業務與訊息發送業務耦合、業務資料與訊息表要在一起
2.獨立訊息服務
為了解決上述問題,我們會引入一個獨立的訊息服務,來完成對訊息的持久化、發送、確認、失敗重試等一系列行為,大概的模型如下
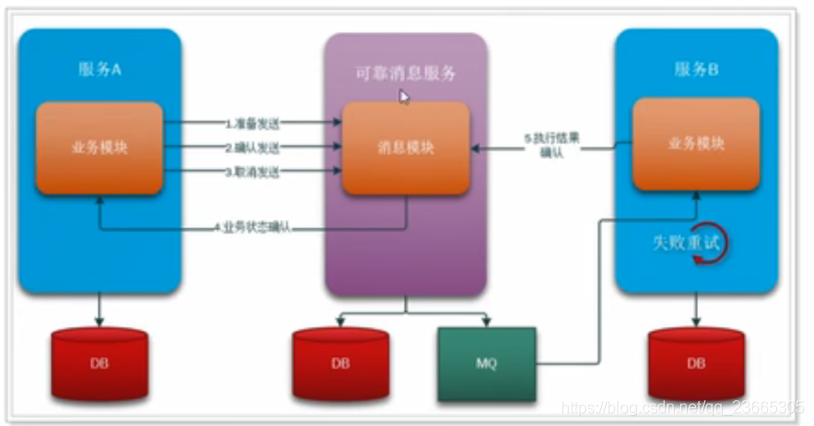
事務發起者A的基本執行步驟:
-
開啟本地事務
-
通知訊息服務,準備發送訊息(訊息服務將訊息持久化,標記為準備發送)
-
執行本地業務,
-
執行失敗則終止,通知訊息服務,取消發送(訊息服務修改訂單狀態)
-
執行成功則繼續,通知訊息服務,確認發送(訊息服務發送訊息、修改訂單狀態)
-
-
提交本地事務
訊息服務本身提供下面的介面:
-
準備發送:把訊息持久化到資料庫,并標記狀態為準備發送
-
取消發送:把資料庫訊息狀態修改為取消
-
確認發送:把資料庫訊息狀態修改為確認發送,嘗試發送訊息,成功后修改狀態為已發送
-
確認消費:消費者已經接收并處理訊息,把資料庫訊息狀態修改為已消費
-
定時任務:定時掃描資料庫中狀態為確認發送的訊息,然后詢問對應的事務發起者,事務業務執行是否成功,結果:
-
業務執行成功:嘗試發送訊息,成功后修改狀態為已發送
-
業務執行失敗:把資料庫訊息狀態修改為取消
-
事務參與者B的基本步驟:
-
接收訊息
-
開啟本地事務
-
執行業務
-
通知訊息服務,訊息已經接收和處理
-
提交事務
優點:
-
解除了事務業務與訊息相關業務的耦合
缺點:
-
實作起來比較復雜
4.5 AT模式
2019年 1 月份,Seata 開源了 AT 模式,AT 模式是一種無侵入的分布式事務解決方案,可以看做是對TCC或者二階段提交模型的一種優化,解決了TCC模式中的代碼侵入、編碼復雜等問題,
在 AT 模式下,用戶只需關注自己的“業務 SQL”,用戶的 “業務 SQL” 作為一階段,Seata 框架會自動生成事務的二階段提交和回滾操作,
4.5.1 基本原理
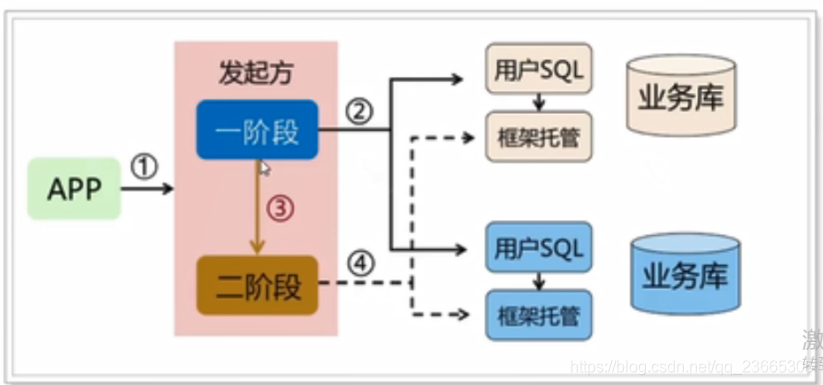
感覺和TCC的執行很像,都是分兩個階段:
- 一階段:執行本地事務,并回傳執行結果
- 二階段:根據一階段的結果,判斷二階段的做法:提交或者回滾
但是AT模式不一樣之處在于,第二階段不需要我們撰寫,全部由seata自己實作了,也就是說:我們寫的代碼與本地事務代碼一樣,無需手動處理分布式鎖事務了,
so,AT模式是如何實作無代碼入侵呢?
一階段
在一階段,Seata會攔截“業務sql”,首先決議SQL語意,找到“業務SQL要更新的業務資料”,在業務資料被更新前,將其保存成“before images”(這里面就是需要修改的值修改之前的值),然后執行SQL,更新資料,在業務資料更新之后,再將其保存成“after image”,最后獲取全域行鎖,提交事務,以上操作全部在一個資料事務內完成,這樣保證了原子性,
其實這里的“before image”和“after image”類似于資料庫的undo和redo日志,但其實是用資料庫模擬的,
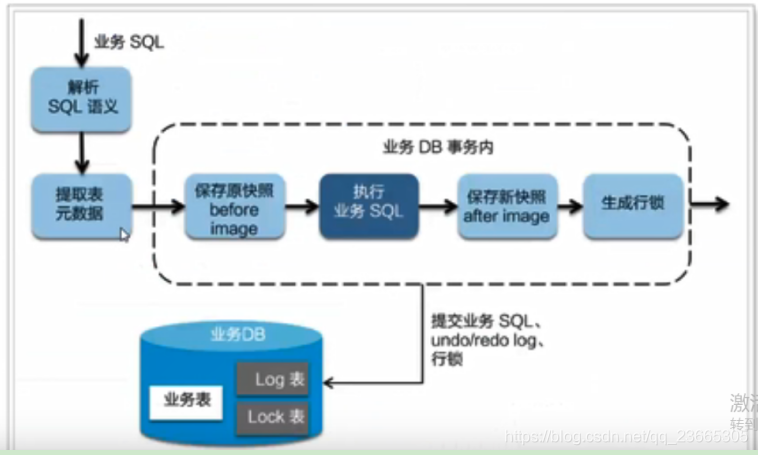
二階段提交
二階段如果只是提交,因為“業務SQL”在一階段已經提交至資料庫,所以seata框架只需要將一階段保存的快照資料和行鎖刪掉,完成資料清理即可,
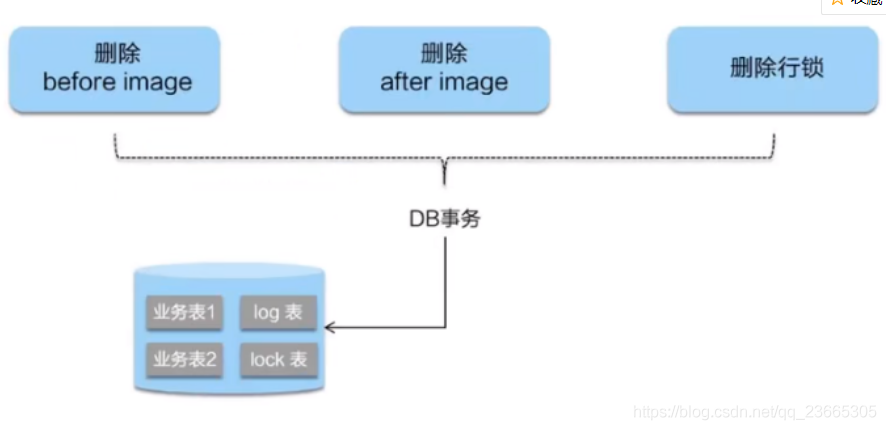
二階段回滾
二階段如果是回滾的話,Seata 就需要回滾一階段已經執行的“業務 SQL”,還原業務資料,回滾方式便是用“before image”還原業務資料;但在還原前要首先要校驗臟寫,對比“資料庫當前業務資料”和 “after image”,如果兩份資料完全一致就說明沒有臟寫,可以還原業務資料,如果不一致就說明有臟寫,出現臟寫就需要轉人工處理,
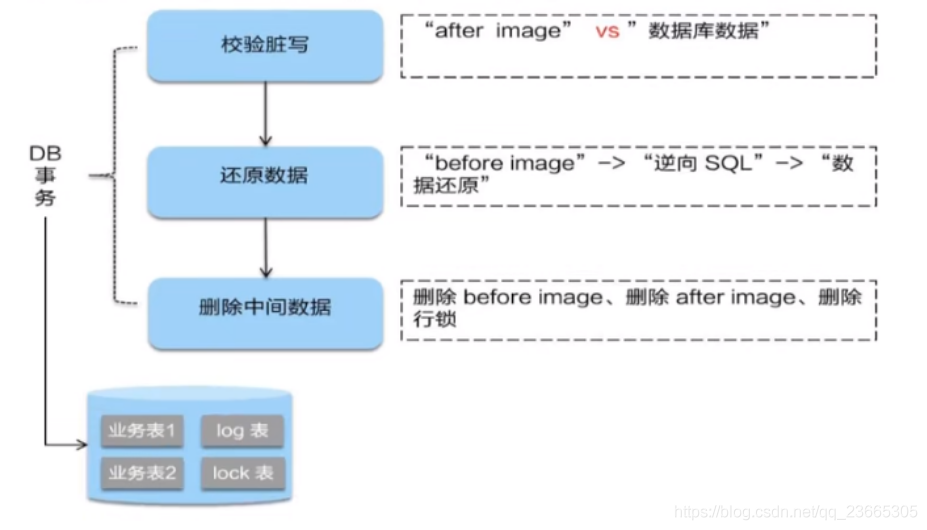
不過因為有全域鎖機制,所以可以降低出現臟寫的概率,
AT 模式的一階段、二階段提交和回滾均由 Seata 框架自動生成,用戶只需撰寫“業務 SQL”,便能輕松接入分布式事務,AT 模式是一種對業務無任何侵入的分布式事務解決方案,
4.5.2 詳細架構和流程
Seata中的幾個基本概念:
-
TC(Transaction Coordinator) - 事務協調者
維護全域和分支事務的狀態,驅動全域事務提交或回滾(TM之間的協調者),
-
TM(Transaction Manager) - 事務管理器
定義全域事務的范圍:開始全域事務、提交或回滾全域事務,
-
RM(Resource Manager) - 資源管理器
管理分支事務處理的資源,與TC交談以注冊分支事務和報告分支事務的狀態,并驅動分支事務提交或回滾,可以理解為資料庫
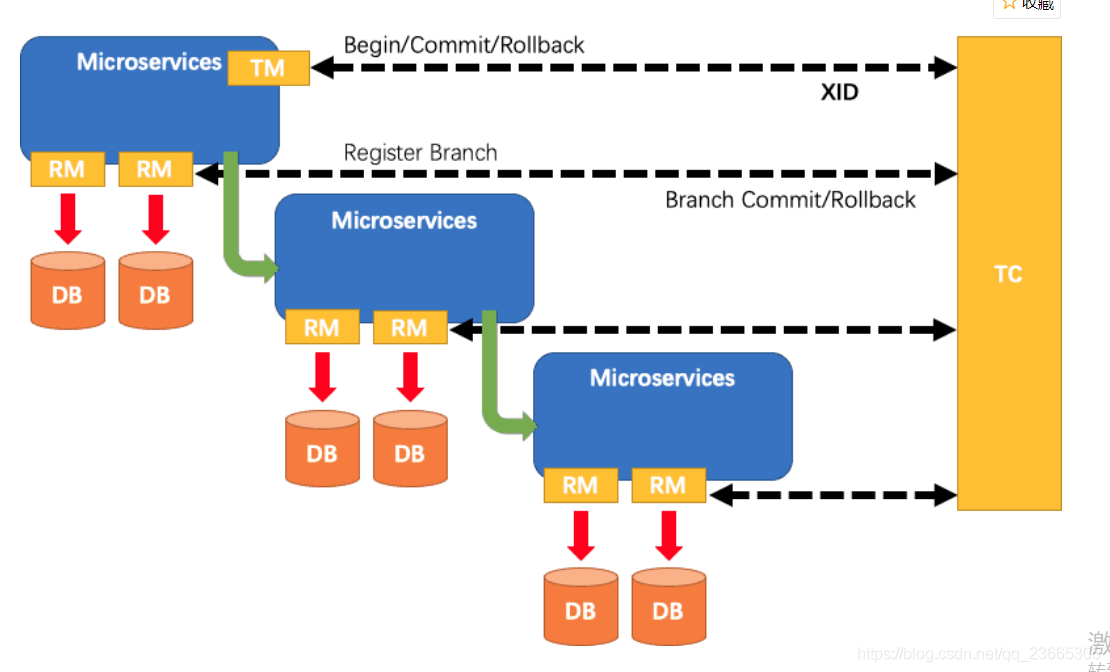
分布式事務的執行流程
- TM開啟分布式事務(TM向TC注冊全域事務記錄) ;
- 按業務場景,編排資料庫、服務等事務內資源(RM向TC匯報資源準備狀態) ;
- TM結束分布式事務,事務一階段結束(TM通知TC提交/回滾分布式事務) ;
- TC匯總事務資訊,決定分布式事務是提交還是回滾;
- TC通知所有RM提交/回滾資源,事務二階段結束,
一階段:
-
TM開啟全域事務,并向TC宣告全域事務,包括全域事務XID資訊
-
TM所在服務呼叫其它微服務
-
微服務,主要有RM來執行
-
查詢
before_image -
執行本地事務
-
查詢
after_image -
生成
undo_log并寫入資料庫 -
向TC注冊分支事務,告知事務執行結果
-
獲取全域鎖(阻止其它全域事務并發修改當前資料)
-
釋放本地鎖(不影響其它業務對資料的操作)
-
-
待所有業務執行完畢,事務發起者(TM)會嘗試向TC提交全域事務
二階段:
-
TC統計分支事務執行情況,根據結果判斷下一步行為
-
分支都成功:通知分支事務,提交事務
-
有分支執行失敗:通知執行成功的分支事務,回滾資料
-
-
分支事務的RM
-
提交事務:直接清空
before_image和after_image資訊,釋放全域鎖 -
回滾事務:
-
校驗after_image,判斷是否有臟寫
-
如果沒有臟寫,回滾資料到
before_image,清除before_image和after_image -
如果有臟寫,請求人工介入
-
-
4.5.3 優缺點
優點:
-
與2PC相比:每個分支事務都是獨立提交,不互相等待,減少了資源鎖定和阻塞時間
-
與TCC相比:二階段的執行操作全部自動化生成,無代碼侵入,開發成本低
缺點:
-
與TCC相比,需要動態生成二階段的反向補償操作,執行性能略低于TCC
5. seata
5.1 介紹
Seata(Simple Extensible Autonomous Transaction Architecture,簡單可擴展自治事務框架)是 2019 年 1 月份螞蟻金服和阿里巴巴共同開源的分布式事務解決方案,Seata 開源半年左右,目前已經有接近一萬 star,社區非常活躍,我們熱忱歡迎大家參與到 Seata 社區建設中,一同將 Seata 打造成開源分布式事務標桿產品,
Seata:https://github.com/seata/seata
5.2 seata產品模塊
如下圖,seata中有三大模塊,分別是TM,RM和TC,其中TM和RM是作為seata的客戶端與業務端系統集成在一起的,TC作為seata的服務端獨立部署,
5.3 seata支持的事務模型
seata會有4種分布式解決方案,分別是AT,TCC,Saga,和XA模式,

5.4 AT模式
seata中比較常見的是AT模式,在本篇文章中我們以AT模式作為講解,想要了解其他模式的可以通過seata官網的檔案去了解,
我們設定一個場景,一個用戶購買商品的業務邏輯,整個業務邏輯由3個微服務提供支持:
-
倉儲服務:對給定的商品扣除倉儲數量,
-
訂單服務:根據采購需求創建訂單,
-
帳戶服務:從用戶帳戶中扣除余額,
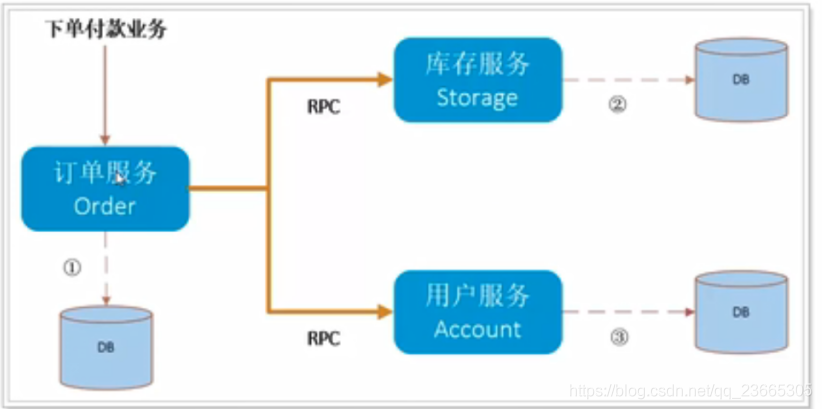
訂單服務在下單時,同時呼叫庫存服務和用戶服務,此時就會發生跨服務和跨資料源的分布式事務問題,
5.4.1 準備資料
執行資料中提供的seata_demo.sql檔案,匯入資料,
其中包含4張表,
Order表:
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(11) NULL DEFAULT NULL COMMENT '用戶id',
`product_id` bigint(11) NULL DEFAULT NULL COMMENT '產品id',
`count` int(11) NULL DEFAULT NULL COMMENT '數量',
`money` decimal(11, 0) NULL DEFAULT NULL COMMENT '金額',
`status` int(1) NULL DEFAULT NULL COMMENT '訂單狀態:0:創建中;1:已完結',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4;商品庫存表:
DROP TABLE IF EXISTS `seata_storage`;
CREATE TABLE `t_storage` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`product_id` bigint(11) NULL DEFAULT NULL COMMENT '產品id',
`total` int(11) NULL DEFAULT NULL COMMENT '庫存',
`used` int(11) NULL DEFAULT NULL COMMENT '已用庫存',
`residue` int(11) NULL DEFAULT NULL COMMENT '剩余庫存',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8mb4;用戶賬戶表:
DROP TABLE IF EXISTS `t_account`;
CREATE TABLE `t_account` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(11) NULL DEFAULT NULL COMMENT '用戶id',
`total` decimal(10, 0) NULL DEFAULT NULL COMMENT '總額度',
`used` decimal(10, 0) NULL DEFAULT NULL COMMENT '已用額度',
`residue` decimal(10, 0) NULL DEFAULT NULL COMMENT '剩余可用額度',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8mb4;還有用來記錄Seata中的事務日志表undo_log,其中會包含after_image和before_image資料,用于資料回滾:
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;三個庫
create database seata_order;
create database seata_storage;
create database seata_account;依次在對應的庫中創建表
5.4.2 代碼
seata-order-service
在order服務中,我們主要需要做三個操作,創建訂單,扣減庫存,扣款,修改訂單狀態
@Service
@Slf4j
public class OrderServiceImpl implements OrderService {
@Resource
private OrderDao orderDao;
@Resource
private AccountService accountService;
@Resource
private StorageService storageService;
/**
* name隨意取,只要全域唯一
* @param order
*/
@Override
@GlobalTransactional(name = "fsp-create-order",rollbackFor = Exception.class)
public void create(Order order) {
log.info("--------->開始新建訂單");
//1 新建訂單
orderDao.create(order);
//2 扣減庫存
log.info("------------->訂單微服務開始呼叫庫存,做扣減Count");
storageService.decrease(order.getProductId(), order.getCount());
log.info("------------->訂單微服務開始呼叫庫存,做扣減end");
//3 扣減賬戶
log.info("------------->訂單微服務開始呼叫賬戶,做扣減Money");
accountService.decrease(order.getUserId(), order.getMoney());
log.info("------------->訂單微服務開始呼叫賬戶,做扣減end");
//4 修改訂單狀態
log.info("------------->修改訂單狀態開始");
orderDao.update(order.getUserId(),0);
log.info("------------->修改訂單狀態結束");
log.info("------------->下訂單結束了");
}
}剛剛我們提到了,由于是分布式專案,我們模擬了不同的資料源,所以我們需要去控制對應的資料源操作,提交/回滾,
原始碼地址:
通常來說,我們不做任務處理,如果某一環出了問題,
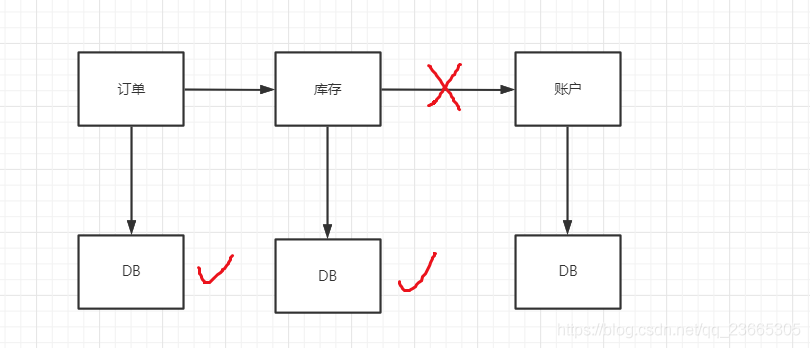
如上圖,如果在訂單下單和庫存扣減都成功的情況下,但是賬戶扣件失敗了,但是由于不是單體架構模式,所以各個服務之間無法感知到失敗與否,如果非要通知,那么其實時很麻煩的事情,比如:使用訊息佇列發送訊息,然后手動開啟/關閉事務,,等等這一系類的操作
此時讓我們進入今天的重頭戲,引入seata的AT.
環境
這里我們使用nacos作為注冊中心,
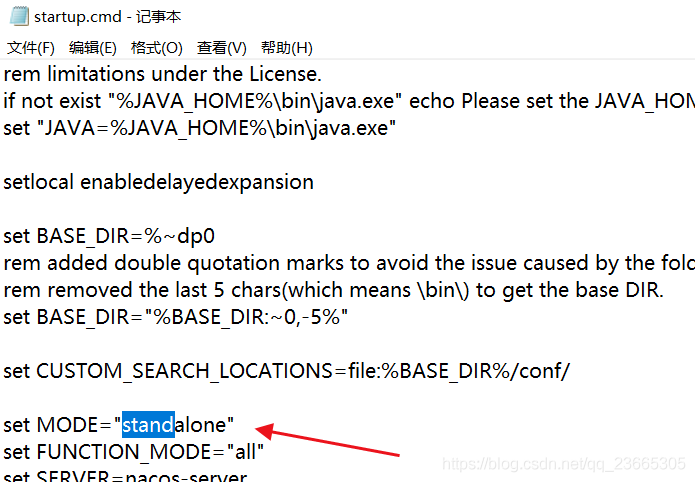
下載nacos,解壓縮,然后進入bin目錄下,由于用的windows環境,我們直接啟動startup.cmd即可,在此之前我們將其修改成非集群模式的
啟動成功之后,我們可以看到
接著下載seata,這里我們使用的是seata1.1.0.
注意了,我們在開發的時候盡量去使用1.0版本以上
下載成功之后,我們進入conf目錄
首先我們先修改file.conf檔案
由于我們使用的資料庫來管理修改mode為“db”
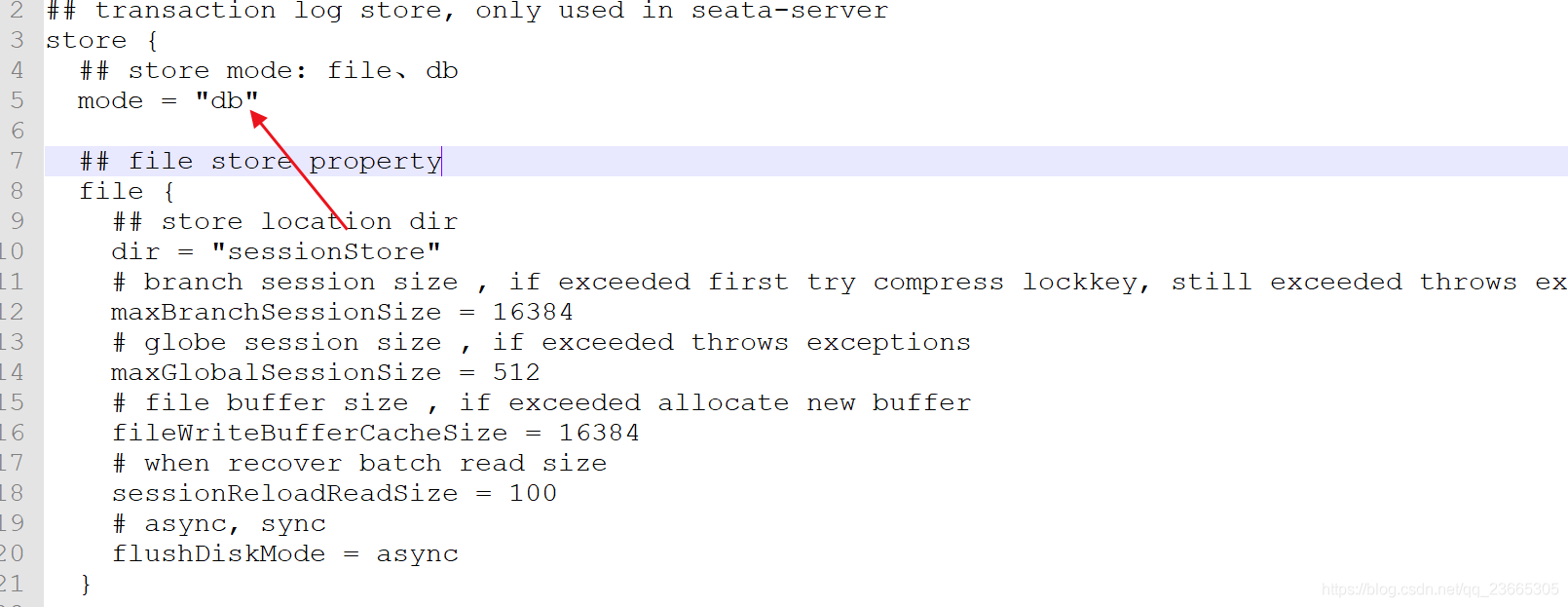
之后修改我們的資料庫配置
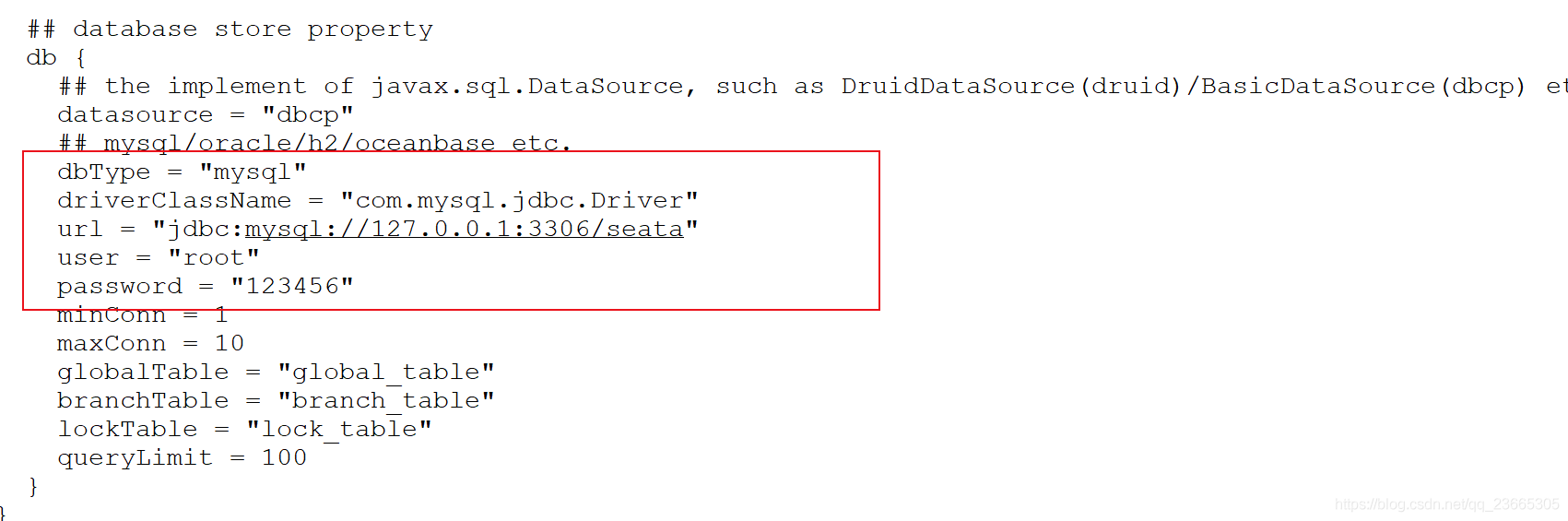
注意:這里我們給出1.1的sql
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(0) NULL DEFAULT NULL,
`gmt_modified` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for global_table
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(0) NULL DEFAULT NULL,
`gmt_modified` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for lock_table
-- ----------------------------
DROP TABLE IF EXISTS `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(0) NULL DEFAULT NULL,
`gmt_modified` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
INDEX `idx_branch_id`(`branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
接著我們來修改register.conf
注冊中心修改為nacos
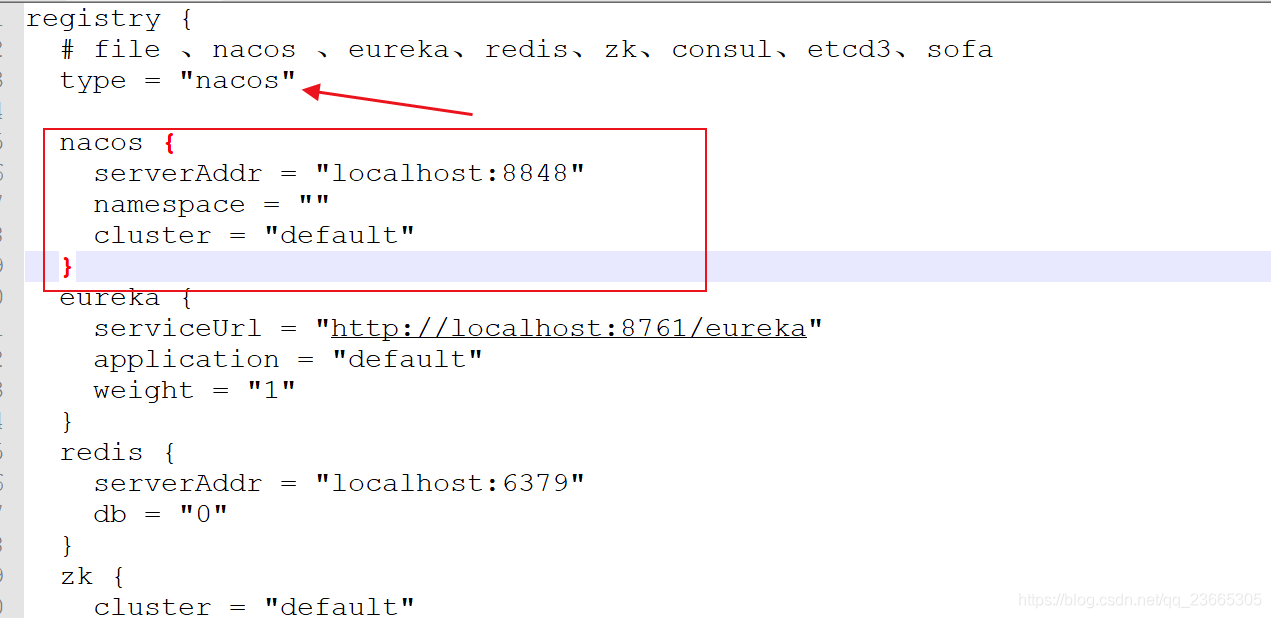
使用檔案file來管理
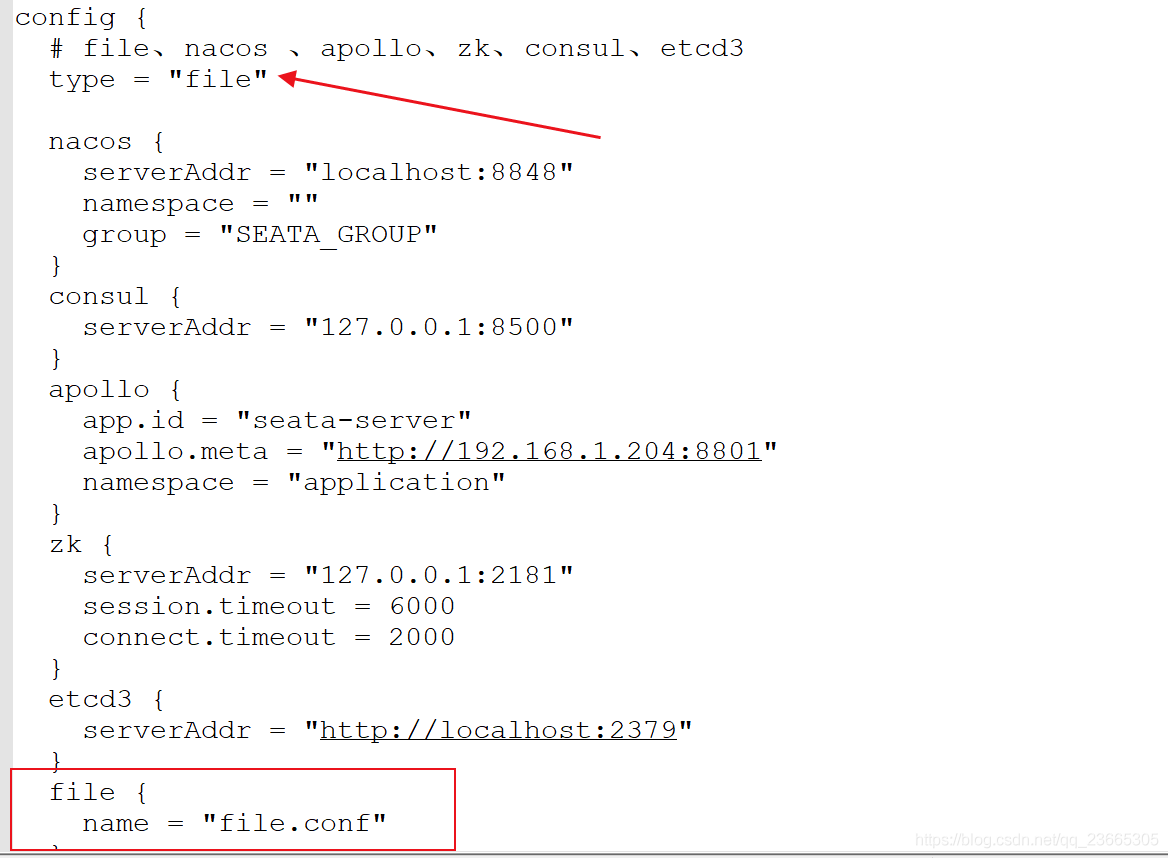
然后再我們的三個服務中添加對應的組態檔
自定義group的名稱:kcp_tx_group
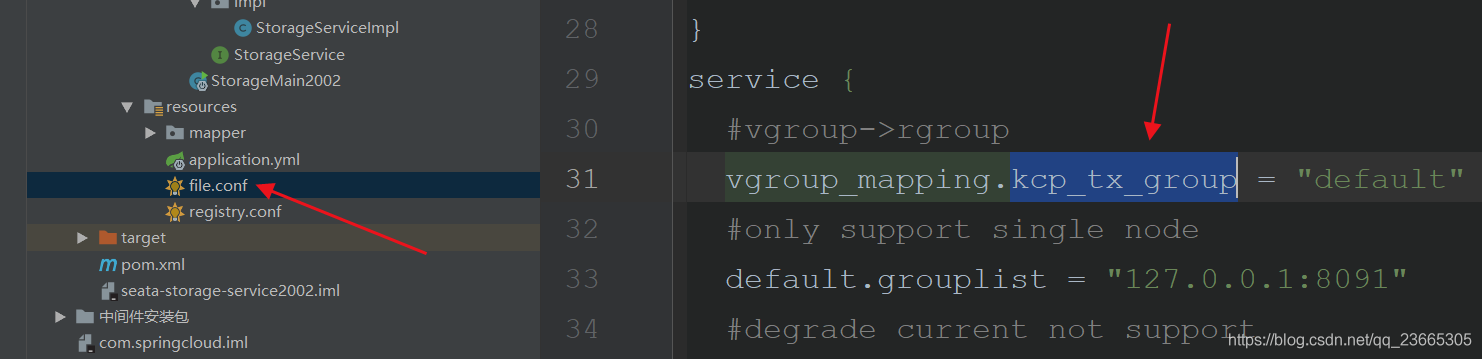
之后再組態檔中配置
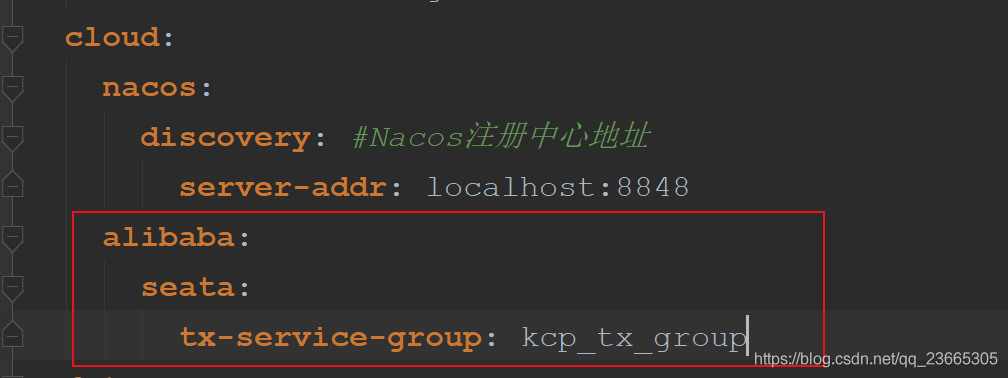
ok,完成,接著我們操作
http://localhost:2001/order/create?userId=1&productId=1&count=10&money=100
即可看到效果!發現三張表都沒有創建/修改成功!
之后會把demo傳上去
https://github.com/hanhan167/springcloud-seata/tree/master
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287591.html
標籤:其他