高性能快取架構
當服務使用關系型資料庫已經達到性能瓶頸的時候我們應該怎么辦,資料庫已經分片了,也分庫分表了,索引什么也都極致了(一般不可能)但是還是扛不住高流量,有點經驗的同學都會說:“加快取,上redis or 直接應用記憶體(快取)“,
什么時候用高性能快取架構?
-
需要經過復雜運算后得出的資料,存盤系統無能為力
- 當我們是一個用戶中心的系統,需求是提供在線用戶的人數,那我們肯定不能去select count(*) 資料庫去統計吧,一般
-
讀多寫少的資料,存盤系統有心無力
-
微信,我們每天發不了幾個朋友圈,甚至不怎發的,然而我們每天都在看朋友圈(讀多寫少)
-
據個人經歷,一般C端的系統大多是讀多寫少的,然而B端一般都是寫多讀少(但是B端一般流量都不會太大)
-
-
極端的熱點資料查詢
- 什么是極端 熱點資料? 微博上的熱搜,”爆“ ,一時間大家都去看這個點下的資料,微博如果不用快取的結果是什么,下一個熱搜又出來的 ”微博掛掉了“ (開個玩笑),
什么是高性能快取架構
- 先認識一下什么是快取
- 快取,是一種存盤資料的組件,它的作用是讓對資料的請求更快地回傳,(上面的例子充分體現)
- 快取一般都是放在記憶體中來做的,還有人認為快取就是記憶體,這個世界上就沒有什么絕對的事情, 見識不夠,千萬不要妄下定論,(360 開源的 Pika 就是使用 SSD 存盤資料解決 Redis 的容量瓶頸的,)一般我們使用記憶體,因為我們常用的redis就是純記憶體來進行存盤的.
- 快取常見的幾種型別:
a. 靜態快取:靜態快取在 Web 1.0 時期是非常著名的,它一般通過生成 Velocity 模板或者靜態 HTML 檔案來實作靜態快取,在 Nginx 上部署靜態快取可以減少對于后臺應用服務器的壓力
b. 分布式快取:Memcached、Redis
c. 熱點本地快取: 熱點本地快取主要部署在應用服務器的代碼中,用于阻擋熱點查詢對于分布式快取節點或者資料庫的壓力,通過應用服務內部的容器進行存盤:HashMap(currentHashMap,TreeMap等),Caffeine Cache,Guava Cache等
- 使用快取帶來的問題
不得不說,這都快被面試官問爛了,玩歸玩,鬧歸鬧,別拿快取開玩笑(無里頭),來認真看下:
- 快取穿透
- 快取穿透是指快取沒有發揮作用,業務系統雖然去快取查詢資料,但快取中沒有資料,業務系統需要再次去存盤系統查詢資料,
- 通常情況下有兩種情況:
- 存盤資料不存在,有惡意請求,也有正常請求,請求本來就沒有的用戶
- 快取資料生成耗費大量時間或者資源 ,我們都知道,記憶體是相對比較貴的資源,我們還是比較 省著點用的,熱點快取,然后到時見失效,(這里的失效只是一部分,也需有同學就會說:這不就是快取雪崩嗎?)
- 快取雪崩
- 快取雪崩是指當快取失效(過期)后引起系統性能急劇下降的情況,其實很好理解也就是超熱點的資料,然后key失效,導致查不到這個資料,直接擊穿到資料庫,
- 解決快取問題的集中策略
大佬們的經驗和總結,總結出來集中快取的策略來解決我們遇到的問題,和快取設計
-
Cache Aside(旁路快取)策略
Cache Aside 策略(也叫旁路快取策略),這個策略資料以資料庫中的資料為準,快取中的資料是按需加載的,它可以分為讀策略和寫策略,
其中讀策略的步驟是:從快取中讀取資料;如果快取命中,則直接回傳資料;如果快取不命中,則從資料庫中查詢資料;查詢到資料后,將資料寫入到快取中,并且回傳給用戶,
寫策略的步驟是:更新資料庫中的記錄;洗掉快取記錄, -
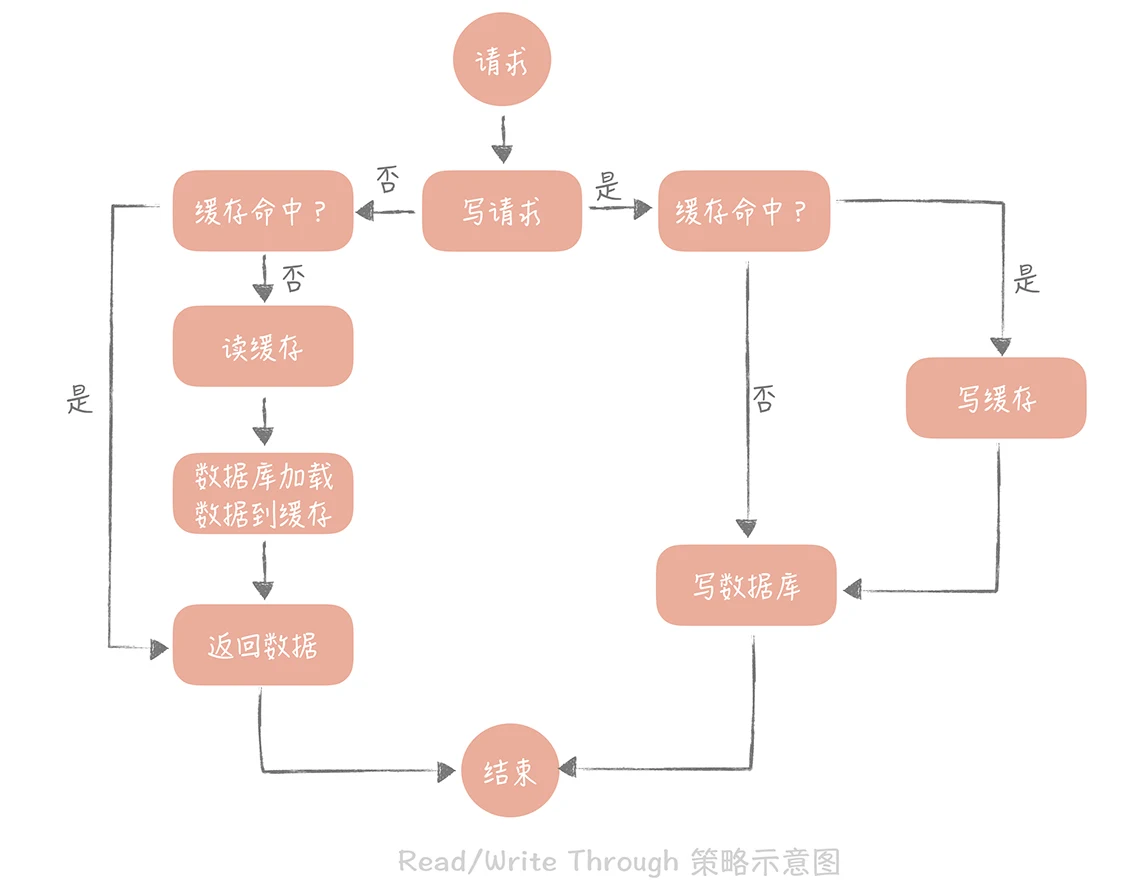
Read/Write Through(讀穿 / 寫穿)策略
- 這個策略的核心原則是用戶只與快取打交道,由快取和資料庫通信,寫入或者讀取資料,這就好比你在匯報作業的時候只對你的直接上級匯報,再由你的直接上級匯報給他的上級,你是不能越級匯報的,
- Write Through 的策略是這樣的:先查詢要寫入的資料在快取中是否已經存在,如果已經存在,則更新快取中的資料,并且由快取組件同步更新到資料庫中,如果快取中資料不存在,我們把這種情況叫做“Write Miss(寫失效)”,
- 一般來說,我們可以選擇兩種“Write Miss”方式:一個是“Write Allocate(按寫分配)”,做法是寫入快取相應位置,再由快取組件同步更新到資料庫中;另一個是“No-write allocate(不按寫分配)”,做法是不寫入快取中,而是直接更新到資料庫中,
- 在 Write Through 策略中,我們一般選擇“No-write allocate”方式,原因是無論采用哪種“Write Miss”方式,我們都需要同步將資料更新到資料庫中,而“No-write allocate”方式相比“Write Allocate”還減少了一次快取的寫入,能夠提升寫入的性能,
-
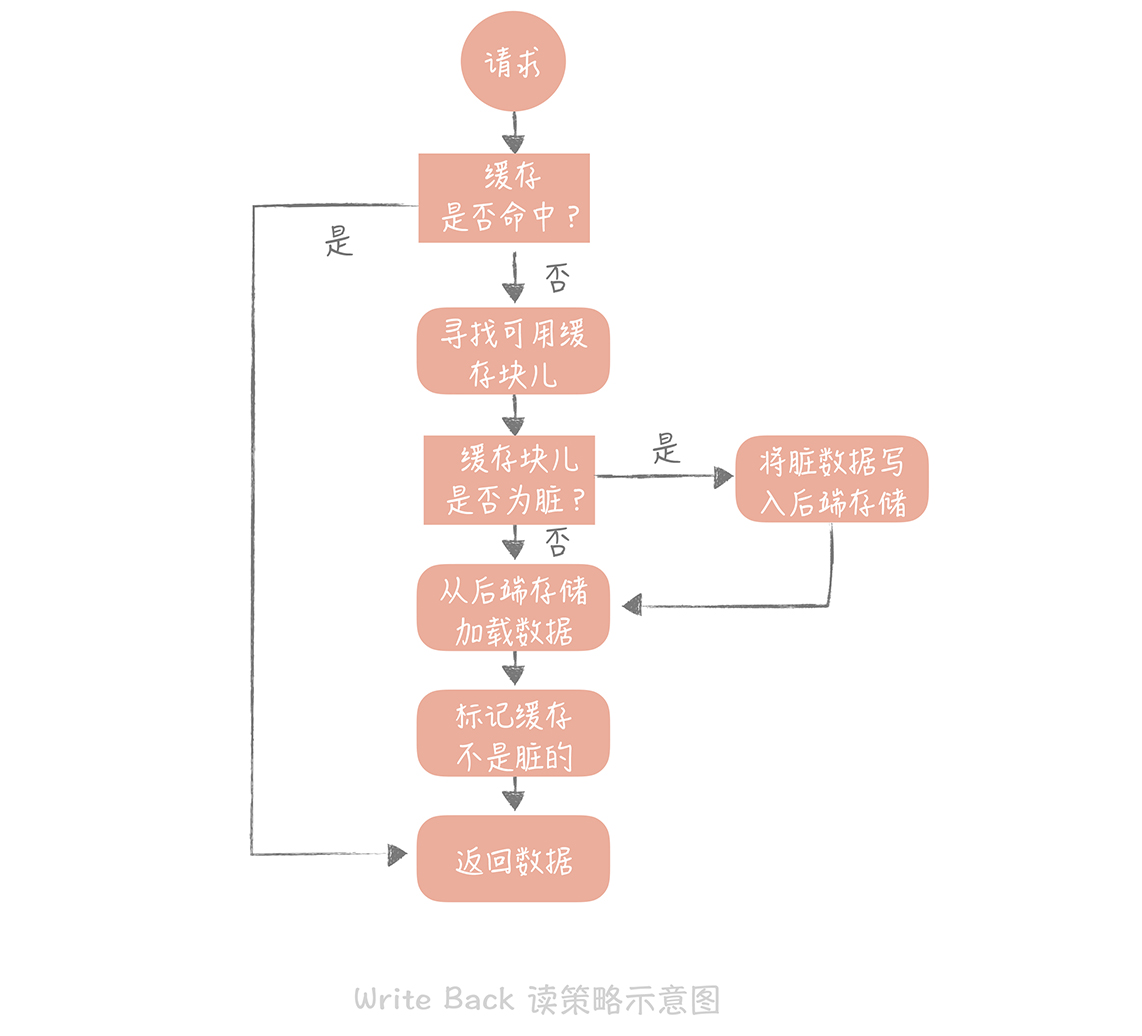
Write Back(寫回)策略
-
這個策略的核心思想是在寫入資料時只寫入快取,并且把快取塊兒標記為“臟”的,而臟塊兒只有被再次使用時才會將其中的資料寫入到后端存盤中,不描述那么多了,有興趣的可以拜讀這篇文章:https://time.geekbang.org/column/article/150881
-
- 說了這么多那到底什么快取是高性能快取架構?
- 那就是我么通過自己的經驗和具體的業務邏輯,通過某些快取中間件設計一個可以達到高性能的高流量的服務架構,(怎么感覺我放了個屁),
具體實作的一個高性能架構
使用到的中間件
redis ,guava cache , canal mysql kafka ,
業務場景
- 后臺配置config ,應用需要讀取config 進行使用,讀取的量很大,有上萬級別的QPS,再次更改的時候可以達到實時且安全的更新,
方案
-
資料的持久化,mysql
-
流量太高,mysql 甚至redis也有點危險,所以兩級快取,redis + guava cache (記憶體)
-
需要實時更新,監聽mysql的binlog 發送訊息給應用更新記憶體 canal + kafka (其他的訊息佇列也沒什么問題)
-
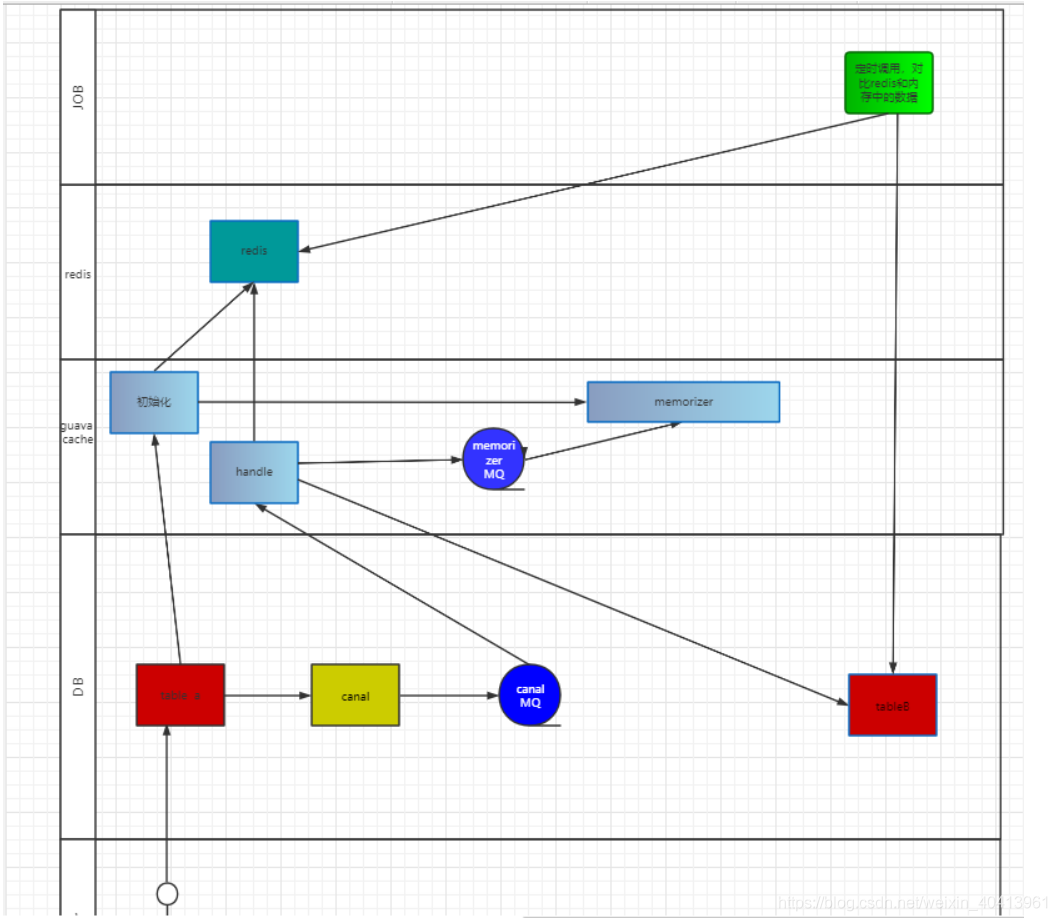
具體的業務架構圖:
-
看完圖,你也許心中會飄過:“畫的這是個吊玩意!!!!“ 我接受批評,確實不好看,也不清晰
-
我大概描述一下程序:
- 更新表的程序:
后臺更新table a 表,更新后canal監聽binlog 通過佇列訊息推送給應用端,應用端拿到訊息后 重繪redis ,
且同時再發送訊息給一個記憶體佇列(異步防止這個流程太長),且同時存盤記憶體的時候,將key 存入tableB 中(后續進行對數,防止資料不一致的問題)
- 重新啟動服務的程序:
分頁拉去資料庫資料,更新進記憶體和快取中去,
-
job的作用是每周進行對數: 將記憶體和資料庫,還有guava 中的進行對數更新,
-
我這只是畫了存盤的,讀取的沒有畫,大家想想怎么讀取資料呢?? (其實是我不想寫了)
-
還有就是這種架構結合上面的集中策略,會有什么問題呢?(我們一塊思考一下)
參考
https://time.geekbang.org/column/article/150881
https://time.geekbang.org/column/article/8640
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287596.html
標籤:其他
上一篇:Java實作多執行緒局域網聊天室
下一篇:關于MVVM和MVC的一些總結