1、 字串陣列列印(指標的步長)
1.1 指標變數+1
char *p = NULL;
printf("%d\n",p); // 0
printf("%d\n",p+1); // 1
int *p2 = NULL;
printf("%d\n",p2); // 0
printf("%d\n",p2+1); // 4
1.2 字串陣列的步長
main()
{
char *str[]={"ab","cd","ef","gh","ij","kl"};
char *t;
t=(str+4)[-1];
printf("%s",t);
}
則顯示"gh"
為什么呢:
首先要知道存放的是char* 型別的陣列,所以str + 4 也就是陣列的第5個元素:“ij”,最后得到的是第5個元素的首地址,我們在去陣列的[-1]索引也就是“gh”的首地址,最終列印的就是gh
1.3 跨行加?????
main()
{
//例子[1]
int a[5]={1,2,3,4,5};
int *ptr=(int *)(&a+1);//&a相當于變成了行指標,加1則變成了下一行首地址
printf("%d,%d,%d",*(a+1),*(ptr-1));
//例子[2]
int * ptr1 = (int *)( (int)a + 1);
int * ptr2 = (int *)( (int)a + 4);
printf("%d,%d\n", ptr[-1],*ptr2);
}
例子[1]
1. *(a+1)就是a[1],執行結果是2
因為a是int*型別,a+1步長為4
2.*(ptr-1)就是a[4],結果為5
首先我們得到的是&a的地址,而&a是一個含有5個int型別的陣列,所以&a+1的步長就是a陣列整個的大小,加到a陣列的末尾后面,
(int *)(&a+1)這一句話,把它轉換成int *型別的指標,步長又為4了,后面給它-1,即*(ptr-1) 相當于減了一個int* 的步長,結果為5
例子[2]
首先看里面的陳述句 (int)a + 1 、(int)a + 4
這個意思是我們把a的地址得到,然后把a的地址+1和+4,
那么ptr1肯定是一個亂的值,因為取的是不對的地址
而ptr2得到的是陣列第二個元素的地址,再轉換成(int *)型別
這樣我們又可以進行后續的+-操作進行指標的參考了,
2、大端小端
小端:低位位元組資料存盤在低地址
大端:高位位元組資料存盤在低地址
例如:int a=0x12345678;(a首地址為0x2000)
0x2000 0x2001 0x2002 0x2003
0x12 0x34 0x56 0x78 大端格式
3、異步IO和同步IO區別
如果是同步IO,當一個IO操作執行時,應用程式必須等待,直到此IO執行完,相反,異步IO操作在后臺運行,
IO操作和應用程式可以同時運行,提高系統性能,提高IO流量; 在同步檔案IO中,執行緒啟動一個IO操作然后就立即進入等待狀態,直到IO操作完成后才醒來繼續執行,而異步檔案IO中,
執行緒發送一個IO請求到內核,然后繼續處理其他事情,內核完成IO請求后,將會通知執行緒IO操作完成了,
4、變數a的不同定義
一個整型數 int a;
一個指向整型數的指標 int *a;
一個指向指標的指標,它指向的指標式指向一個整型數 int **a;
一個有10個整型數的陣列 int a[10];
一個有10指標的陣列,該指標是指向一個整型數 int *a[10];
一個指向有10個整型數陣列的指標 int (*a)[10];
一個指向函式的指標,該函式有一個整型數引數并回傳一個整型數 int ( *a)(int);
一個有10個指標的陣列,該指標指向一個函式,該函式有一個整型數引數并回傳一個整型 int (*a[10])(int);
5、關于char越界的數值
int foo(void)
{
int i;
char c=0x80;
i=c;
if(i>0)
return 1;
return 2;
}
回傳值為2;因為i=c=-128;如果c=0x7f,則i=c=127
6、利用移位、與實作模
a=b*2;a=b/4;a=b%8;a=b/8*8+b%4;a=b*15;實作效率最高的演算法
a=b*2 -> a=b<<1;
a=b/4 -> a=b>>2;
a=b%8 -> a=b&7;
a=b/8*8+b%4 -> a=((b>>3)<<3)+(b&3)
a=b*15 -> a=(b<<4)-b
7、無符號與有符號相加結果為無符號型別
int main(void)
{
unsigned int a = 6;
int b = -20;
char c;
(a+b>6)?(c=1):(c=0);
}
c=1,但a+b=-14;如果a為int型別則c=0,
原來有符號數和無符號數進行比較運算時(==,<,>,<=,>=),有符號數隱式轉換成了無符號數(即底層的補碼不變,但是此數從有符號數變成了無符號數),
比如上面 (a+b)>6這個比較運算,a+b=-14,-14的補碼為1111111111110010,此數進行比較運算時, 被當成了無符號數,它遠遠大于6,所以得到上述結果,
如果a = 1,b = -2 結果為2^32 -1
8、實作某一位置0或置1操作,保持其它位不變
#define BIT3 (0x1<<3)
static int a;
void set_bit3(void)
{
a |= BIT3;
}
void clear_bit3(void)
{
a &= ~BIT3;
}
實作多位置1與置0
a &= ~( 1 << 3 | 1 << 4); //置0
a |= (1<< 3 | 1 << 4); //置1
9、設定一絕對地址為0x67a9的整型變數的值為0xaa66
int *ptr;
ptr = (int *)0x67a9;
*ptr = 0xaa66;(建議用這種)
一個較晦澀的方法是:
*(int * const)(0x67a9) = 0xaa66;
10、中斷函式中的注意問題
__interrupt void compute_area (void)
{
double area = PI * radius * radius;
printf(" Area = %f", area);
return area;
}
1、 ISR不可能有引數和回傳值的!
2、 ISR盡量不要使用浮點數處理程式,浮點數的處理程式一般來說是不可重入的,而且是消耗大量CPU時間的!!
10.1 什么是不可重入函式
-
函式體內使用了靜態(static)的資料結構;
-
函式體內呼叫了 malloc() 或者 free() 函式;
-
函式體內呼叫了標準 I/O 函式;
printf函式一般也是不可重入的,UART屬于低速設備,printf函式同樣面臨大量消耗CPU時間的問題!
不可重入函式在實作時候通常使用了全域的資源,在多執行緒的環境下,如果沒有很好的處理資料保護和互斥訪問,就會發生錯誤,常見的不可重入函式有:
-
printf --------參考全域變數stdout
-
malloc --------全域記憶體分配表
-
free --------全域記憶體分配表
-
滿足下列條件的函式多數是不可重入的:
(1)函式體內使用了靜態的資料結構;
(2)函式體內呼叫了malloc()或者free()函式;
(3)函式體內呼叫了標準I/O函式,
10.2 如何寫出可重入的函式??????
- 在函式體內不訪問那些全域變數;
- 如果必須訪問全域變數,記住利用互斥信號量來保護全域變數,或者呼叫該函式前關中斷,呼叫后再開中斷;
- 不使用靜態區域變數;
- 堅持只使用預設態(auto)區域變數;
- 在和硬體發生互動的時候,切記關閉硬體中斷,完成互動記得打開中斷,在有些系列上,這叫做“進入/退出核心”或者用 OS_ENTER_KERNAL/OS_EXIT_KERNAL 來描述;
- 不能呼叫任何不可重入的函式;
- 謹慎使用堆疊,最好先在使用前先 OS_ENTER_KERNAL;
11、關于malloc申請大小問題
#include <stdio.h>
#include <malloc.h>
int main()
{
char *ptr;
if((ptr = (char *)malloc(0)) == NULL)
puts("got a null pointer\n");
else
puts("got a valid pointer\n");
int a = malloc_usable_size(ptr);
printf("size = %d\n", a);
return 0;
}
malloc申請一段長度為0的空間,malloc依然會回傳一段地址,還有一段地址空間,所以ptr不等于NULL,
malloc這個函式,會有一個閾值,申請小于這個閾值的空間,那么會回傳這個閾值大小的空間,
如閾值為24,那么申請小于24的值就會回傳24
結果如下圖所示
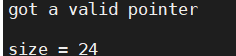
這個閾值會隨著編譯器的不同而不同
如果申請一個負數,那么回傳的是0,如下圖
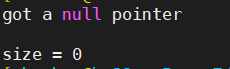
這是因為malloc規定不可以申請一個負數
參考博客
12、變數全置0與全置1
unsigned int zero = 0;
unsigned int compzero = 0xFFFF;
對于一個int型不是16位的處理器為說,上面的代碼是不正確的,應撰寫如下:
unsigned int compzero = ~0; //這樣才是全是置位1
13、實作strcpy
已知strcpy函式的原型是:
char * strcpy(char * strDest,const char * strSrc);
1.不呼叫庫函式,實作strcpy函式,
2.解釋為什么要回傳char *,
13.1 代碼實作
char * strcpy(char * strDest,const char * strSrc)
{
if ((NULL==strDest) || (NULL==strSrc))
//[1]
throw "Invalid argument(s)";
//[2]
char * strDestCopy = strDest;
//[3]
while ((*strDest++=*strSrc++)!='\0');
//[4]
return strDestCopy;
}
錯誤的做法[1]:
(A) 不檢查指標的有效性,說明答題者不注重代碼的健壯性,
(B) 檢查指標的有效性時使用((!strDest)||(! strSrc))或(!(strDest&&strSrc)),說明答題者對C語言中型別的隱式轉換沒有深刻認識,在本例中char *轉換為bool即是型別隱式轉換,這種功能雖然靈活,但更多的是導致出錯概率增大和維護成本升高,所以C++專門增加了bool、true、false三個關鍵字以提供更安全的條件運算式,
? 檢查指標的有效性時使用((strDest0)||(strSrc0)),說明答題者不知道使用常量的好處,直接使用字面常量(如本例中的0)會減少程式的可維護性,0雖然簡單,但程式中可能出現很多處對指標的檢查,萬一出現筆誤,編譯器不能發現,生成的程式內含邏輯錯誤,很難排除,而使用NULL代替0,如果出現拼寫錯誤,編譯器就會檢查出來,
錯誤的做法[3]:
(A)忘記保存原始的strDest值,說明答題者邏輯思維不嚴密,
錯誤的做法[4]:
(A)回圈寫成while ( * strDestCopy++ = * strSrc++);,同[1](B),
(B)回圈寫成while (*strSrc!=’\0’) * strDest++ = * strSrc++;,說明答題者對邊界條件的檢查不力,回圈體結束后,strDest字串的末尾沒有正確地加上’\0’,
13.2 strcpy能把strSrc的內容復制到strDest,為什么還要char *型別的回傳值?
回傳strDest的原始值使函式能夠支持鏈式運算式,增加了函式的“附加值”,同樣功能的函式,如果能合理地提高的可用性,自然就更加理想,
? 鏈式運算式的形式如:
? int iLength=strlen(strcpy(strA,strB));
? 又如:
? char * strA=strcpy(new char[10],strB);
14、寫一個“標準”宏MIN,這個宏輸入兩個引數并回傳較小的一個
#define Min(a,b) (a) <= (b) ? (a) : (b)
15、說明關鍵字volatile有什么含意,并給出例子
volatile表示被修飾的符號是易變的,告訴編譯器不要隨便優化我的代碼!!
15.1 實作硬體暫存器
15.2 中斷中用到的變數
15.3 執行緒之間共享變數
16、位反轉
實作一個8位資料反轉
位 8 7 6 5 4 3 2 1
數 v8 v7 v6 v5 v4 v3 v2 v1
轉換后:
位 8 7 6 5 4 3 2 1
數 v1 v2 v3 v4 v5 v6 v7 v8
unsigned char bit_reverse(unsigned char c)
{
unsigned char buf;
int bit = 8;
while(bit)
{
bit--;//最后需要移動0位,所以要先bit--,最后才能到0,如果在后面最后0的時候就會退出了
buf |= ( (c&1) << bit);
c >>= 1;
}
return buf;
}
17、字串翻轉
18、參考和指標的區別
(1). 指標是一個物體,而參考僅是個別名;
(2). 參考使用時無需解參考(*),指標需要解參考;
(3). 參考只能在定義時被初始化一次,之后不可變;指標可變;
(4). 參考沒有 const,指標有 const,const 的指標不可變;
(5). 參考不能為空,指標可以為空;
(6). “sizeof 參考”得到的是所指向的變數(物件)的大小,
而“sizeof指標”得到的是指標本身(所指向的變數或物件的地址)的大小;
(7). 指標和參考的自增(++)運算意義不一樣;
19、-1,2,7,28,126請問28和126中間那個數是什么?為什么?
答案應該是4^3-1=63 規律是n3-1(當n為偶數0,2,4)n3+1(當n為奇數1,3,5)
20、一級指標無效傳參
先看這個例子:
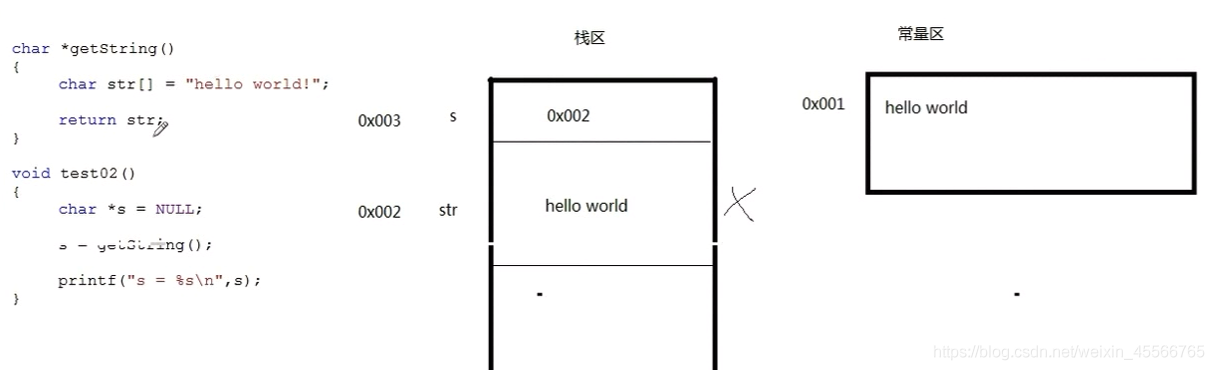
進入test02后堆疊上給s分配了一個空間,然后進入getstring,首先常量區給helloworld開辟了空間,然后str這個區域變數,在堆疊上也存放了helloworld內容,最后回傳str指標的地址0x002,但是堆疊區的空間在執行完getstring后已經被回收了,所以列印的是亂碼的東西,
答:結果可能是亂碼,因為getstring回傳的是指向“堆疊記憶體”的指標,該指標的地址不是 NULL,
但其原現的內容已經被清除,新內容不可知,
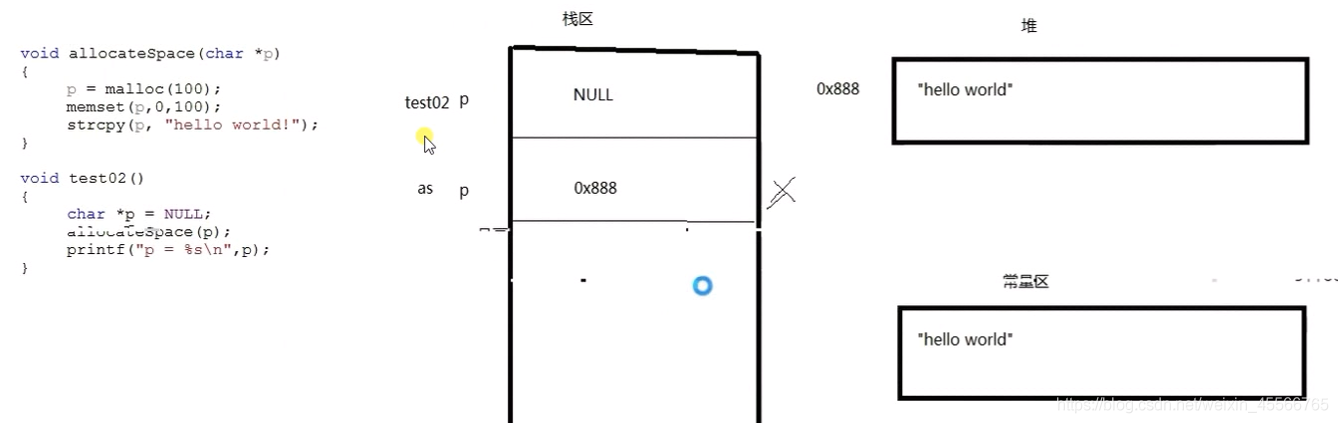
#include<stdio.h>
#include<memory.h>
void allo(char *p)
{
p = malloc(100);
memset(p,0,100);
strcpy(p,"hello word");
}
int main()
{
char *p = NULL;
allo(p);
printf("%d\n",p);
system("pause");
return 0;
}
結果為0;
同理這里進入allo函式后函式為char *p形參在堆疊上分配空間,然后p指向堆中一塊記憶體,再把helloworld內容拷到p指向記憶體的地址,但是這個函式執行完后,p內容處的內容就釋放掉了,并不會列印,
解決方法:改用二級指標或者回傳char*
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-iBEf3cfN-1623580014556)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210607214257340.png)]](https://img.uj5u.com/2021/06/16/244843160811587.png)
21、寫出float x 與“零值”比較的if陳述句
if(x>0.000001&&x<-0.000001)
22、修改野指標
void Test(void)
{
char *str = (char *) malloc(100);
strcpy(str, “hello”);
free(str);
if(str != NULL)
{
strcpy(str, “world”);
printf(str);
}
}
篡改動態記憶體區的內容,后果難以預料,非常危險,因為free(str);之后,str成為野指標, if(str != NULL)陳述句不起作用,
野指標不是NULL指標,是指向被釋放的或者訪問受限記憶體指標,
造成原因:指標變數沒有被初始化,任何剛創建的指標不會自動成為NULL;
指標被free或delete之后,沒有置NULL;
指標操作超越了變數的作用范圍,比如要回傳指向堆疊記憶體的指標或參考,因為堆疊記憶體在函式結束時會被釋放,
23、void* 型別
任何資料都是有型別的,告訴編譯器分配多少記憶體
void val; //錯誤的
但是void* 可以 ,四個位元組
void* 是所有型別指標的祖宗
int * pInt = NULL;
char *PChar = pInt;
從int* 到char* 系統會警告,可以使用型別轉換:
int * pInt = NULL;
char *PChar = (char *)pInt;
或者用void * 接收
void * pVoid = pInt;
任何型別的指標,都可以不經過強制轉換,轉換成void* 型別,所以可以理解為void* 是所有型別指標的祖宗,
void * 主要用于資料結構的封裝
24、sizeof的回傳型別
(0)sizeof是運算子,sizeof測量的物體大小在編譯階段就已經確定
(1)sizeof回傳的是unsigned int 所以
sizeof(int) - 5 其實結果是 > 0的
(2)當陣列作為引數傳入的時候,退化為首元素的指標
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-FXNk6tXP-1623580014560)(H:\software\有道云本地檔案\weixinobU7VjhbDPCdu5duX0DmyyhWb5gE\c901ab43046f498692cfc30ec3c6d5c2\clipboard.png)]](https://img.uj5u.com/2021/06/16/244843160811588.png)
結果為28,4
25、typedef的作用
26、浮點數
首先我們如何表示一個浮點數,例子:
1011.01
8 4 2 1 . 0.5 0.25 按照這個規則,得到上面二進制的結果為11.25
單精度一共32位,我們也可以按照這個規律去定義
其中最高位為1為S符號位,中間8位為指數(E),表示小數點在第幾位上,后面23位小數(M)表示二進制
| S | |-> | 指 | 數 | 8位 | <-| | |-> | 小 | 數 | 23位 | <-| |
|---|
結果為: 
浮點數:0X41360000
0100 0001 0011 0110 000 0 0000 0000 0000
M = 011 0110 0000 0000 0000 0000 ,E = 100 0001 0
- M * 2 ^( E-127) = 1.0110110 * 2^3 相當于小數點往后移動3位 —> 1011.0110 = 11.375
double型別:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-Urc45oOh-1623580014564)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210608200505511.png)]](https://img.uj5u.com/2021/06/16/2448431608115810.png)
27、i++操作
27.1 i++的操作順序
int a = 5, b = 7, c;
c = a+++b;
c = 12;
++優先級比+高,所以先++后+
27.2 可以 &(i++) 嗎?
為什么見:34
28、什么是左值與右值
左值就是出現在運算式左邊的值(等號左邊),可以被改變,他是存盤資料值的那塊記憶體的地址,也稱為變數的地址;
右值是指存盤在某記憶體地址中的資料,也稱為變數的資料,
左值可以作為右值,但右值不可以是左值,
因此也只有左值才能被取地址,
一句話概括就是:左值就是可以被尋址的值
28.1 舉例:
int i = 0;
(i++)+=i; //錯誤
(++i)+=i; //正確
int *ip = &(i++); //錯誤
int *ip = &(++i); //正確
28.2 i++為什么不能作為左值
我們來看i++和i++的實作
// 前綴形式:
int& int::operator++() //這里回傳的是一個參考形式,就是說函式回傳值也可以作為一個左值使用
{//函式本身無參,意味著是在自身空間內增加1的
*this += 1; // 增加
return *this; // 取回值
}
//后綴形式:
const int int::operator++(int) //函式回傳值是一個非左值型的,與前綴形式的差別所在,
{//函式帶參,說明有另外的空間開辟
int oldValue = *this; // 取回值
++(*this); // 增加
return oldValue; // 回傳被取回的值
}
簡單得到理解,就是i++回傳的是一個臨時變數,函式回傳后不能被尋址得到,它只是一個資料值,而非地址,因此不能作為左值,
更簡單的代碼解釋
// i++:
{
int tmp;
tmp=i;
i=i+1;
return tmp;
}
// ++i:
{
i=i+1;
return i;
}
C++部分
1、C++例外
拋出例外throw 和
捕獲例外try catch
try 塊中的代碼有可能拋出例外,它后面通常跟著一個或多個catch 塊在想要處理問題的地方,通過例外處理程式捕獲例外
foo()
{
//[1]
...
...
.A.
.B.
//[2]
throw
//[3]
...
...
...
//[4]
}
如果在throw處發生了例外,會干兩件事:
1、程式首先會回到foo()函式的呼叫處,[3]底下的代碼都不去運行了,
2、上面[1] - [2]之前的代碼都會進行清理,一個回轉的操作,如果呼叫了A或B,則回去呼叫A和B的解構式,避免資源泄露 也可以理解成代碼調轉到[4]上結束運行這個函式,堆疊上的資料都銷毀把A和B進行析構,
代碼示例:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-aAzNIL3I-1623580014566)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210608170158193.png)][外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-At558k52-1623580014569)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210608170218948.png)]](https://img.uj5u.com/2021/06/16/2448431608115811.png)
通過拋出例外回傳一個 字串"my exception" 在catch中捕捉到了這個字串列印輸出,
不可以濫用例外,銷毀資料會造成性能消耗!
只有你實在沒有辦法解決的時候,比如一個除法,分母為0的時候,我不知道該怎么,我不能回傳0和-1,因為結果并不是0和-1,我就可以拋出一個例外 const *str的字串,并且你可以catch這個const *str
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-ImABj2QQ-1623580014571)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210608165759377.png)]](https://img.uj5u.com/2021/06/16/2448431608115812.png)
2、參考
2.1 什么是參考?
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-qcTPzlju-1623580014573)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210608201006077.png)]](https://img.uj5u.com/2021/06/16/2448431608115813.png)
別名:同樣的記憶體地址
2.2 參考 VS 指標
參考的記憶體意義:同樣的記憶體地址!!!
而指標是int i = 5;
int * p = & i;
明顯需要開辟一個新的地址存放 i 的地址,指向 i
主要有三個不同:
1、不存在空參考!參考必須連接到一塊合法的地址
2、一旦參考被初始化為一個物件,就不能被指向到另一個物件,指標可以在任何時候指向到另一個物件,
3、參考必須在創建時被初始化,指標可以在任何時間被初始化,
2.3 函式傳參用到參考
foo( int a,int *b ,int& c)
{
cout << a << b << c << endl;
}
main()
{
//[1]
int a = 5;
int *b = & a;
int &c = a;
//[2]
foo();
return 0;
}
執行到[1] - [2]之間的時候,堆疊上為 a ,b分配空間,c指向a ,運行到foo()后,堆疊會繼續分配一個a的空間,以及一個b的空間,而c并不占空堆疊空間,直接指向了第一次堆疊上為a分配空間的地址2000上
? 堆疊:
| 2000 | a |
|---|---|
| 1996 | b |
| 1992 | a |
| 1988 | b |
2.4 參考的優點和需要遵守的規則
將“參考”作為函式回傳值型別的格式、好處和需要遵守的規則?
好處:在記憶體中不產生被回傳值的副本
注意:
1.不能回傳區域變數的參考,主要是區域變數會在函式回傳后被銷毀,因此被回傳的參考就成了無所指的參考,程式會進入未知狀態
2.不能回傳函式內部new分配的記憶體的參考(容易造成記憶體泄漏)
string& foo()
{
string* str = new string("abc");
return *str;
}
void main()
{
//[1] 不會記憶體泄漏
string& str1=foo();
delete &str1;
//[2] 記憶體泄漏
string str = foo();
}
? str1是區域變數、出了作用域就沒了,你申請的記憶體還在、但是“載體”沒了,參考是“載體”的參考、 它本身不是“載體”
3.可以回傳類成員的參考,但最好是const
3、 C++函式中的默認值
foo( int a,int *b ,int& c,int d = 200)
{
cout << a << b << c << endl;
}
main()
{
int a = 5;
int *b = & a;
int &c = a;
foo(a,b,c); //正確
foo(100,b, c,200); //錯誤,默認值只能放在最后面,幾個都可以,但是不能放在第一個
}
4、register存盤類
register定義存盤在暫存器中而不是記憶體中的區域變數(只是希望而已)
然而,完全取決于編譯器!
Best Practice:主要為了優化性能,注意,不要過早優化不要因為C++可以做什么就做什么!
優化什么呢:我想頻繁的使用這個變數,從暫存器里面讀肯定會快!
但是也有問題:
register int b;
int * a = & b;
這個時候b肯定不能放在暫存器里面,因為你想取地址b,暫存器哪有地址,編譯器就不會這么做,
5、行內函式inline
如何一個函式比較小巧,經常呼叫,可以減少函式呼叫用到堆疊的開銷
優點:
- 沒有了呼叫的開銷,效率也很高,
- 編譯器在呼叫一個行內函式時,會首先檢查它的引數的型別,保證呼叫正確
- 然后進行一系列的相關檢查,就像對待任何一個真正的函式一樣
- 這樣就消除了它的隱患和局限性,(宏替換不會檢查引數型別,安全隱患較大:對帶參的宏而言,由于是直接替換,并不會檢查引數是否合法,存在安全隱患,)
- 可以作為一個類的成員函式,與類的普通成員函式作用相同
缺點:
- 行內函式的函式體一般來說不能太大,如果行內函式的函式體過大,一般的編譯器會放棄行內方式
- 如果函式體變大的話,會造成很多的cache miss 發生具體原理可以去看一下,
6、const和指標
C++之父推薦的讀法是:從右往左讀
6.1 char * const cp;
//example 1:
char * const cp;
// cp is cosnt pointer to char 說明他是一個cosnt指標,指向的內容為char
// 因此它的指標指向是不可以更改的,如果 cp = &x;
//試圖將 cp的指標指向x地址這是不可以的,因為它不可以修改,
6.2 const char * p;
//example 2:
const char * p
// cp is pointer to cosnt char 說明他是一個指標,指向的內容為 const char
// 因此它的指標指向的內容是不可以更改的,如果 *p = x;
//試圖將 p的指標指向的內容進行修改這是不可以的,因為它不可以修改,
6.3 char const * p;
char const跟 const char是一樣的
//example 3:
const char * p
// cp is a pointer to char that is cosnt 說明他是一個指標,指向的內容為 char const
// 因此它的指標指向的內容是不可以更改的,如果 *p = x;
//試圖將 p的指標指向的內容進行修改這是不可以的,因為它不可以修改,
6.4 char const * const p;
//example 3:
const char * p
// cp is a const pointer to cosnt char
//說明他是一個cosnt指標,指向的內容為 const char
7、建構式
1、一個建構式包含建構式和解構式這是最基本的
2、建構式沒有回傳值,建構式初始化成員在后面用:給成員初始化(使用初始化串列的建構式是顯式的初始化類的成員),而不是{ sz = size};在建構式里面,因為如果這個資料型別比較大的話,開銷就大了,
class Vector{
private:
size_t sz; // size_t = unsigned int
double *elem;
Vector(size_t size)
: sz(size).
elem(new double[sz])
{
}
public:
Vector(initializer_list<double> lst); //類內宣告
double& operator[](int i){
return elem[i];
}
size_t size(){
return sz;
}
~Vector(){};
}
Vector::Vector(initializer_list<double> lst) //可以類內宣告,類外定義函式
:elem(new double[lst.size()])
{
std::copy(lst.begin(),lst.end(),elem);
}
3、建構式可以有很多個,但是會有一個默認的建構式
Vector(){}
explicit建構式
解決隱式型別轉換問題
Vector v1 = 7; // OK ,V1 有7個元素
如果寫成explicit Vector(int s); // no implicit 不可以隱式的
Vector v1(7); // OK ,V1 有7個元素
Vector v1 = 7; // error,不可以隱式轉換
initializer_list的用法
Vector(initializer_list<double> lst)
:elem(new double[lst.size()])
{
std::copy(lst.begin(),lst.end(),elem);
}
Vector v2 {1,2,3,4,5}; //寫一個這樣的建構式就可以實作使用串列初始化
8、拷貝建構式
接著7中的例子:
8.1 淺拷貝
void bad_copy*(Vector v1)
{
Vector v2 = v1;
v1[0] = 2;
v1[1] = 3;
v2[0] = 10;
v2[1] = 20; //此時你以為v1 v2是兩個不同的東西,實際上是兩個相同的東西
}
此時v2 = v1;
在堆疊中v2和v1分別在兩個地方保存, v1中st和v2中的st存在于不同的地址空間,但是指標他們指向的確實同一塊空間,
8.2 實作拷貝建構式
classname (const classname &obj){...}
//在...中實作自己的拷貝建構式
- 通過使用另一個同型別的物件來初始化新創建的物件
- 復制物件把它作為引數傳遞給函式
- 復制物件,并從函式回傳這個物件
- 如果在類中沒有定義拷貝建構式,編譯器會自行定義一個,如果類帶有指標變數,并有動態記憶體分配,則它必須有一個拷貝建構式?????
如何去做:
? 首先建立物件,并呼叫其建構式,然后成員被拷貝,
? 用A初始化B的完成方式是記憶體拷貝,復制所有成員的值
? 指標雖然復制了,但所指向的空間并沒有復制,而是由兩個物件共用了
Vector::Vector(const Vector& other)
:sz(other.size()),
:elem(new double[other.size()])
{
for(int i = 0; i!=sz; i++)
elem[i] = other.elem[i];
}
8.3 拷貝建構式被呼叫的情況
-
物件初始化拷貝賦值 Mytype B = A
-
定義新物件,并用已有物件初始化新物件時,即執行陳述句“MyType B=A;”時(定義物件時使用賦值初始化)
-
當物件直接作為引數傳給函式時,函式將建立物件的臨時拷貝,這個拷貝程序也將調同拷貝建構式
-
函式回傳時,函式堆疊區的物件會復制一份到函式的回傳去
Mytype foo() { return A; //堆疊上開辟臨時變數,復制給B } Mytype B = foo();
8.4 深拷貝與淺拷貝?????
淺拷貝是增加了一個指標,指向原來已經存在的記憶體,而深拷貝是增加了一個指標,并新開辟了一塊空間讓指標指向這塊新開辟的空間,淺拷貝在多個物件指向一塊空間的時候,釋放一個空間會導致其他物件所使用的空間也被釋放了,再次釋放便會出現錯誤,
8.5 不會進入到拷貝建構式,而是進入賦值建構式的情況????
Mytype B;
B = A;
此時就不會進入拷貝建構式!!!
9、賦值建構式
如何進入賦值建構式,見8.4
Vector& Vector::operator=(const Vector& a)
{
if( &a == this )
return *this;
double *p = new double[a.size()];
for(int i = 0; i!=sz;++i)
p[i] = a.elem[i]; //記住C++中分配空間和初始化寫在一起,
delete[] elem;
elem = p;
sz = a.sz;
return *this;
}
10、左值、右值參考是什么?
左值指的是既能夠出現在等號左邊也能出現在等號右邊的變數(或運算式)
int a;
int b;
a = 3;
b = 4;
a = b;
b = a;
// 以下寫法不合法,
3 = a;
a+b = 4;
右值指的則是只能出現在等號右邊的變數(或運算式),如運算操作(加減乘除,函式呼叫回傳值等)所產生的中間結果,
10.1 左值參考
MyType &參考名 = 左值運算式;
int main(){
int a = 0;
int &b = a;
b = 11;
return 0;
}
10.2 右值參考
右值的參考,就是給右值取別名
Type &&參考名 = 右值運算式;
10.3 為什么要有右值參考呢?
左值參考我們知道可以用于函式傳參,減少不必要的物件拷貝,提升效率;或者用于替代指標的使用,
C++11引入右值參考主要是為了實作移動語意和完美轉發,
10.3.4 移動語意
首先實作string類?????
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
class MyString{
public:
static size_t Ctor; //統計呼叫建構式的次數
static size_t CCtor; //統計呼叫拷貝建構式的次數
public:
//建構式
MyString(const char* str = nullptr) {
++Ctor;
if (str != nullptr) {
m_data = new char[strlen(str) + 1];
strcpy(m_data, str);
}
else {
m_data = new char[1];
*m_data = '\0';
}
}
// 拷貝建構式
MyString(const MyString& other) {
++CCtor;
m_data = new char[strlen(other.m_data) + 1];
strcpy(m_data, other.m_data);
}
// 拷貝賦值函式 =號多載
MyString& operator=(const MyString& other) {
if (this == &other) // 避免自我賦值!!
return *this;
delete[] m_data; // 先釋放原來的空間
m_data = new char[strlen(other.m_data) + 1];
strcpy(m_data, other.m_data);
return *this;
}
~MyString() {
delete[] m_data;
m_data = NULL;
}
private:
char* m_data;
};
測驗一下代碼:
size_t MyString::Ctor = 0;
size_t MyString::CCtor = 0;
int main(){
vector<MyString> vecStr;
vecStr.reserve(1000); //先分配好1000個空間
for (int i = 0; i < 1000; i++) {
vecStr.push_back(MyString("hello"));
}
cout << "構造次數:" << MyString::Ctor << endl;
cout << "拷貝構造次數:" << MyString::CCtor << endl;
}
結果:
構造次數:1000
拷貝構造次數:1000
我們每次拷貝一個臨時變數都需要深拷貝即進入拷貝建構式中,這樣會降低效率,因此拷貝建構式每次都是重新分配一塊新的空間,同時將要拷貝的物件復制過來,
要是我們能夠減少這個拷貝的次數,效率就提升了,所以這個時候右值參考就派上用場了
右值參考可以參考并修改右值,但是通常情況下,修改一個臨時值是沒有意義的,然而在對臨時值進行拷貝時,我們可以通過右值參考來將臨時值內部的資源移為己用,從而避免了資源的拷貝
增加移動建構式:
size_t MyString::MCtor = 0; //統計呼叫移動建構式的次數
// 移動建構式
MyString(MyString&& str)
:m_data(str.m_data) {
++MCtor;
str.m_data = nullptr; //不再指向之前的資源了
}
測驗結果:
構造次數:1000
拷貝構造次數:0
移動構造次數:1000
成功減少了臨時物件拷貝的次數,
11、移動建構式
移動建構式與拷貝建構式的區別是,拷貝構造的引數是const Mytype& str,是常量左值參考,而移動構造的引數是Mytype&& str,是右值參考
移動建構式與拷貝構造不同,它并不是重新分配一塊新的空間同時將要拷貝的物件復制過來,而是"拿"了過來,將自己的指標指向別人的資源,然后將別人的指標修改為nullptr,這一步很重要,如果不將別人的指標修改為空,那么臨時物件析構的時候就會釋放掉這個資源,那么就沒有“拿”過來,
拷貝建構式中,對于指標,我們一定要采用深層復制
而移動建構式中,對于指標,我們采用淺層復制
注意:指標的淺層復制危害性極大!
之所以危險,是因為兩個指標共同指向一片記憶體空間,若第一個指標將其釋放,另一個指標的指向就不合法了,所以我們要重設指標為nullptr(因為a我們不再使用了,如果不設為nullptr那么指標還指向新創建的空間,一旦出現記憶體被釋放了以后,指標卻還指向該記憶體,就會出現“野指標”的問題,容易出現記憶體非法訪問錯誤,)
用a初始化b后,a我們就不需要了,最好是初始化完成后就將a析構(不能用了)所以移動建構式,專門處理這種,用a初始化b后,就將a析構的情況
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-JrjC2o6x-1623580014577)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210610212324324.png)]](https://img.uj5u.com/2021/06/16/2448431608115814.png)
移動建構式 在初始化的時候就是作了一個淺拷貝
然后把指標指向了空,
關于move的使用呼叫移動建構式?????
move方法來將左值轉換為右值,從而呼叫移動建構式而不是拷貝建構式,
使用移動建構式會提升函式的效率,見下面代碼中return z;
Vector foo()
{
Vector x(2000);
Vector y(2000);
Vector z(2000);
z = x; // 執行賦值建構式
y = std::move(x); //執行移動建構式
return z; // 我們回傳z,再想一個問題之前提到8.3的第四條中,在堆疊中回傳,它是一個將亡之人,如果我們呼叫拷貝建構式的話會效率很低,因為這個z我后面并不需要它了,因此我們用淺拷貝(移動建構式)就可以了,
}
12、拷貝建構式的引數為什么必須是參考?
拷貝建構式的引數為什么必須是參考?_nwd0729的專欄-CSDN博客
13、 靜態成員與靜態成員函式
-
靜態成員函式可以把函式與類的任何特定物件獨立開來
-
靜態成員函式即使在類物件不存在的情況下也能被呼叫,只要使用類名加范圍決議運算子::就可以訪問
class A{
int sz;
static void foo()
{
}
};
A a;
A::foo();
創建了一個物件a,但是foo并不屬于a
-
靜態成員函式只能訪問靜態成員資料、其他靜態成員函式和類外部函式靜態成員函式不能訪問類的 this 指標,都需要物件所以就沒有this指標
static int foo() { return 2 * sz; }這就是錯誤的了,不能訪問某個物件的成員,
作業系統部分
0、什么是內核?
0.1 Linux內核系統體系結構
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-Fu6GIWBJ-1623580014579)(D:\desktop\33題.png)]](https://img.uj5u.com/2021/06/16/2448431608115815.png)
5大模塊:行程調度模塊、記憶體管理模塊、檔案系統模塊、行程間通信模塊和網路介面模塊,
**行程調度模塊:**控制行程被CPU資源的使用,采取的策略是不同行程能夠公平合理的訪問CPU,同時保證記憶體能夠及時的執行硬體操作
**記憶體管理模塊:**保證所有的行程能夠安全的來共享機器上的記憶體區,同時這個記憶體管理的模塊還支持虛擬記憶體的管理方式,能夠使得支持行程使用比實際使用記憶體的空間更大,并且可以利用檔案系統把這些暫時不用的記憶體資料塊交換到外部的存盤設備上,
**檔案系統模塊:**支持對外部設備的驅動和一些存盤,虛擬檔案系統VFS(這里面的回答很重要?????)這個模塊通過所有的外部設備提供一個通用的檔案介面,他隱藏了各種各樣硬體設備以及實作細節
0.1.1虛擬檔案系統:
? 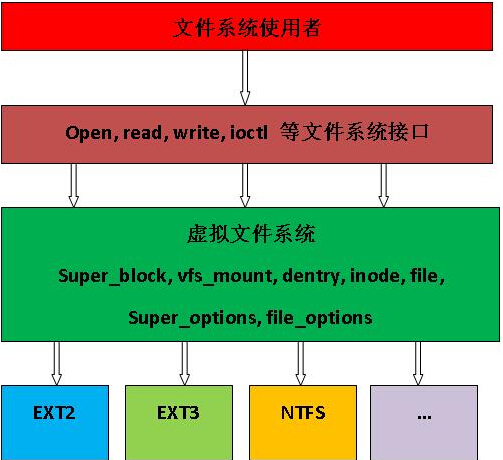
? 虛擬檔案系統是一套代碼框架(framework),它處于檔案系統的使用者與具體的檔案系統之間,將兩者隔離開來,這種引入 一個抽象層次的設計思想,即“上層不依賴于具體實作,而依賴于介面;下層不依賴于具體實作,而依賴于介面”,就是著名的“依賴反 轉”,它在 Linux內核中隨處可見,
? VFS框架的設計,需要滿足如下需求:
? 1、 為上層的用戶提供統一的檔案和目錄的操作介面,如 open, read, write
? 2、 為下層的具體的檔案系統,定義一系列統一的操作“介面”, 如 file_operations, inode_operations, dentry_operation,而 具體的 檔案系統必須實作這些介面,才能融入VFS框架中,
**行程間通信模塊:**用于多種行程間通信
**網路介面模塊:**支持各種網路通信的標準
0.2 Linux內核結構體
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-OHxdS25r-1623580014585)(C:\Users\Jocelin\AppData\Roaming\Typora\typora-user-images\image-20210612190659502.png)]](https://img.uj5u.com/2021/06/16/2448431608115816.png)
0.3
內核的記憶體管理的基本單位是頁(page),原始碼下面 /include/linux/mm_types
1、cache
1.1 cache是什么
Cache存盤器:電腦中為高速緩沖存盤器,是位于CPU和主存盤器DRAM之間,規模較小,但速度很高的存盤器,通常由SRAM靜態存盤器組成,
高速緩沖存盤器最重要的技術指標是它的命中率,CPU要訪問的資料在Cache中有快取,稱為“命中” (Hit),反之則稱為“缺失” (Miss),
現在 CPU 的 Cache 又被細分了幾層,常見的有 L1 Cache, L2 Cache, L3 Cache,其讀寫延遲依次增加,實作的成本依次降低,
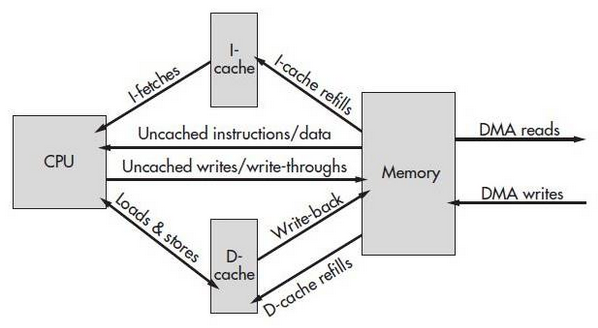
現代系統采用從 Register ―> L1 Cache ―> L2 Cache ―> L3 Cache ―> Memory ―> Mass storage的層次結構,是為解決性能與價格矛盾所采用的折中設計,
下圖描述的就是CPU、Cache、記憶體、以及DMA之間的關系,程式的指令部分和資料部分一般分別存放在兩片不同的cache中,對應指令快取(I-Cache)和資料快取(D-Cache),
1.2 為什么需要cache
CPU快取(Cache Memory)位于CPU與記憶體之間的臨時存盤器,它的容量比記憶體小但交換速度快,在快取中的資料是記憶體中的一小部分,但這一小部分是短時間內CPU即將訪問的,當CPU呼叫大量資料時,就可避開記憶體直接從快取中呼叫,從而加快讀取速度,
使用Cache改善系統性能的依據是程式的區域性原理,包括時間區域性和空間區域性,即最近被CPU訪問的資料,短期內CPU 還要訪問(時間);被 CPU 訪問的資料附近的資料,CPU 短期內還要訪問(空間),因此如果將剛剛訪問過的資料快取在Cache中,那下次訪問時,可以直接從Cache中取,其速度可以得到數量級的提高,
1.3 cpu與cache 記憶體互動的程序
CPU接收到指令后,它會最先向CPU中的一級快取(L1 Cache)去尋找相關的資料,然一級快取是與CPU同頻運行的,但是由于容量較小,所以不可能每次都命中,這時CPU會繼續向下一級的二級快取(L2 Cache)尋找,同樣的道理,當所需要的資料在二級快取中也沒有的話,會繼續轉向L3 Cache、記憶體(主存)和硬碟.
1.4 cache寫機制
Cache寫機制分為write through和write back兩種,
Write-through(直寫模式)在資料更新時,同時寫入快取Cache和后端存盤,此模式的優點是操作簡單;缺點是因為資料修改需要同時寫入存盤,資料寫入速度較慢,
Write-back(回寫模式)在資料更新時只寫入快取Cache,只在資料被替換出快取時,被修改的快取資料才會被寫到后端存盤,此模式的優點是資料寫入速度快,因為不需要寫存盤;缺點是一旦更新后的資料未被寫入存盤時出現系統掉電的情況,資料將無法找回,
讀機制
貫穿讀出式(Look Through)
該方式將Cache隔在CPU與主存之間,CPU對主存的所有資料請求都首先送到Cache,由Cache自行在自身查找,如果命中, 則切斷CPU對主存的請求,并將資料送出;不命中,則將資料請求傳給主存,
該方法的優點是降低了CPU對主存的請求次數,缺點是延遲了CPU對主存的訪問時間,
旁路讀出式(Look Aside)
在這種方式中,CPU發出資料請求時,并不是單通道地穿過Cache,而是向Cache和主存同時發出請求,由于Cache速度更快,如果命中,則Cache在將資料回送給CPU的同時,還來得及中斷CPU對主存的請求;不命中,則Cache不做任何動作,由CPU直接訪問主存,它的優點是沒有時間延遲,缺點是每次CPU對主存的訪問都存在,這樣,就占用了一部分總線時間,
1.5 cache 一致性?????
DMA和cache一致性問題
2、Norflash與Nandflash的區別
(1)、NAND閃存的容量比較大
(2)、由于NandFlash沒有掛接在地址總線上,所以如果想用NandFlash作為系統的啟動盤,就需要CPU具備特殊的功能,
如s3c2410在被選擇為NandFlash啟動方式時會在上電時自動讀取NandFlash的4k資料到地址0的SRAM中,
(3)、NAND Flash一般地址線和資料線共用,對讀寫速度有一定影響,NOR Flash閃存資料線和地址線分開,
所以相對而言讀寫速度快一些,
3、反碼、補碼
反碼:對原碼除符號位外的其余各位逐位取反就是反碼
補碼:負數的補碼就是對反碼加1
正數的原碼、反碼、補碼都一樣
4、記憶體管理MMU的作用
- 記憶體分配和回收
- 記憶體保護
- 記憶體擴充
- 地址映射
5、SRAM、DRAM、SDRAM
SRAM:CPU的快取就是SRAM,靜態的隨機存取存盤器,加電情況下,不需要重繪,資料不會丟失
DRAM,動態隨機存取存盤器最為常見的系統記憶體,需要不斷重繪,才能保存資料
SDRAM:同步動態隨機存盤器,即資料的讀取需要時鐘來同步,
6、主宰作業系統的經典演算法
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287648.html
標籤:其他
上一篇:MySQL記錄洗掉后竟能按中間被洗掉的主鍵加回去,磁盤空間被重用!——底層揭秘MySQL行格式記錄頭資訊
下一篇:C++ C++實戰筆記