前言
本文整理C++實戰筆記,是極客時間羅劍鋒老師的C++實戰筆記筆記,希望大家購買原版,本文如有侵權立刪,
- google c++ code style
https://zh-google-styleguide.readthedocs.io/en/latest/google-cpp-styleguide/
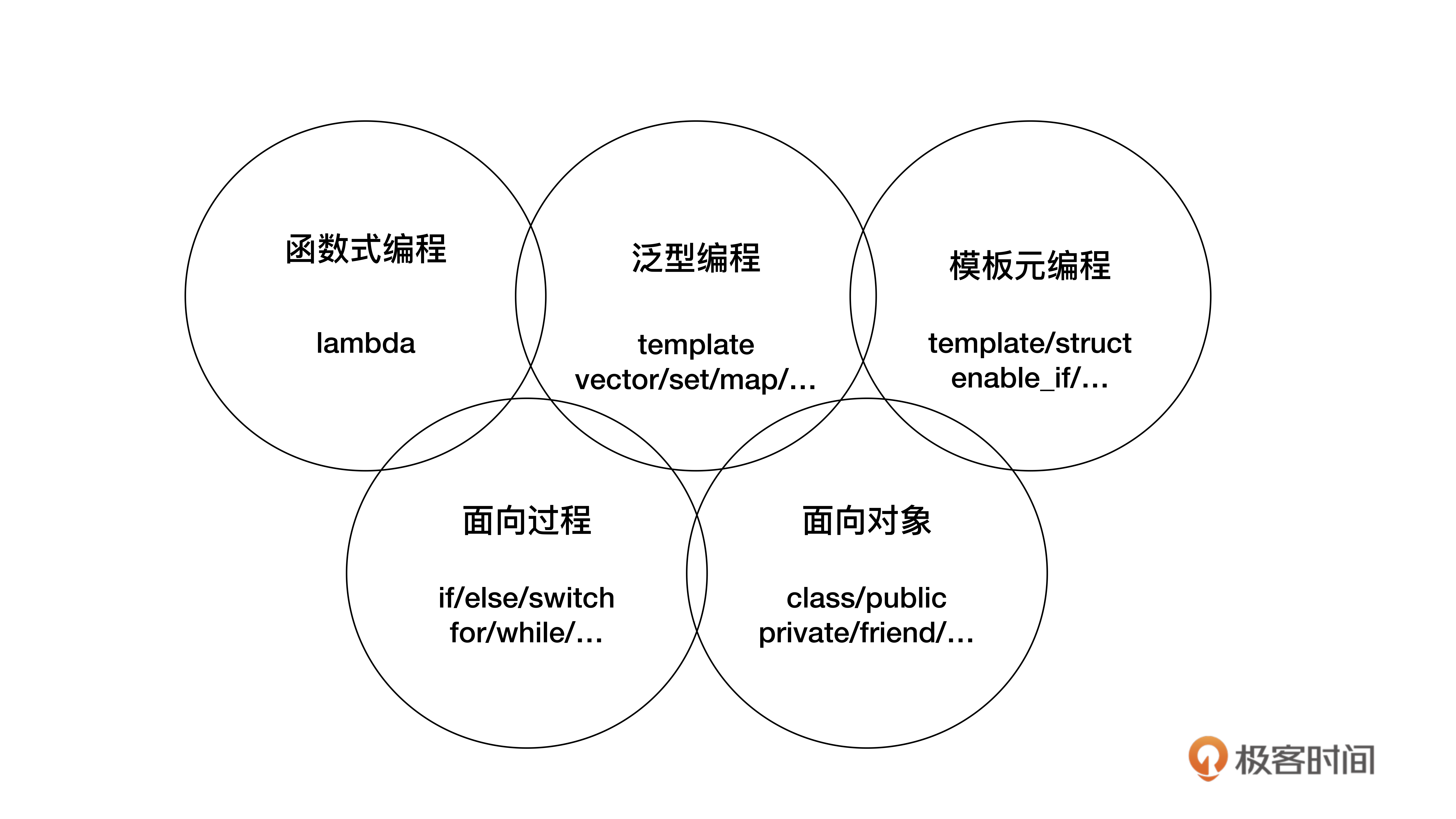
C++語言的編程范式
“編程范式”是一種“方法論”,就是指導你撰寫代碼的一些思路、規則、習慣、定式和常用語,
C++是一種多范式的編程語言,具體來說,現代C++(11/14以后)支持“面向程序”“面向物件”“泛型”“模板元”“函式式”這五種主要的編程范式,
-
面向程序是C++里最基本的一種編程范式,它的核心思想是“命令”,通常就是順序執行的陳述句、子程式(函式),把任務分解成若干個步驟去執行,最終達成目標,
-
面向物件是C++里另一個基本的編程范式,它的核心思想是“抽象”和“封裝”,倡導的是把任務分解成一些高內聚低耦合的物件,這些物件互相通信協作來完成任務,它強調物件之間的關系和介面,而不是完成任務的具體步驟,
在C++里,面向物件范式包括class、public、private、virtual、this等類相關的關鍵字,還有建構式、解構式、友元函式等概念, -
泛型編程是自STL(標準模板庫)納入到C++標準以后才逐漸流行起來的新范式,核心思想是“一切皆為型別”,或者說是“引數化型別”“型別擦除”,使用模板而不是繼承的方式來復用代碼,所以運行效率更高,代碼也更簡潔,
在C++里,泛型的基礎就是template關鍵字,然后是龐大而復雜的標準庫,里面有各種泛型容器和演算法,比如vector、map、sort,等等, -
模板元編程,這個詞聽起來好像很新,其實也有十多年的歷史了,不過相對于前三個范式來說,確實“資歷淺”,它的核心思想是“型別運算”,操作的資料是編譯時可見的“型別”,所以也比較特殊,代碼只能由編譯器執行,而不能被運行時的CPU執行,
模板元編程是一種高級、復雜的技術,C++語言對它的支持也比較少,更多的是以庫的方式來使用,比如type_traits、enable_if等, -
函式式,它幾乎和“面向程序”一樣古老,但卻直到近些年才走入主流編程界的視野,所謂的“函式式”并不是C++里寫成函式的子程式,而是數學意義上、無副作用的函式,核心思想是“一切皆可呼叫”,通過一系列連續或者嵌套的函式呼叫實作對資料的處理,
函式式直到C++11引入了Lambda運算式,它才真正獲得了可與其他范式并駕齊驅的地位,
說得具體一點,就是要認識、理解這些范式的優勢和劣勢,在程式里適當混用,取長補短才是“王道”,
如果是開發直接面對用戶的普通應用(Application),那么你可以再研究一下“泛型”和“函式式”,就基本可以解決90%的開發問題了;如果是開發面向程式員的庫(Library),那么你就有必要深入了解“泛型”和“模板元”,優化庫的介面和運行效率,
如何寫出好的c++代碼
編碼階段的code style
- 混用這幾種中能夠讓名字辨識度最高的那些優點,就是四條規則:
變數、函式名和名字空間用snake_case,全域變數加“g_”前綴;
自定義類名用CamelCase,成員函式用snake_case,成員變數加“m_”前綴;
宏和常量應當全大寫,單詞之間用下劃線連接;
盡量不要用下劃線作為變數的前綴或者后綴(比如_local、name_),很難識別,
#define MAX_PATH_LEN 256 //常量,全大寫
int g_sys_flag; // 全域變數,加g_前綴
namespace linux_sys { // 名字空間,全小寫
void get_rlimit_core(); // 函式,全小寫
}
class FilePath final // 類名,首字母大寫
{
public:
void set_path(const string& str); // 函式,全小寫
private:
string m_path; // 成員變數,m_前綴
int m_level; // 成員變數,m_前綴
};
預處理階段:宏定義和條件編譯
預處理階段編程的操作目標是“原始碼”,用各種指令控制前處理器,把原始碼改造成另一種形式,就像是捏橡皮泥一樣,
首先,預處理指令都以符號“#”開頭,雖然都在一個源檔案里,但它不屬于C++語言,它走的是前處理器,不受C++語法規則的約束,
所以,預處理編程也就不用太遵守C++代碼的風格,一般來說,預處理指令不應該受C++代碼縮進層次的影響,不管是在函式、類里,還是在if、for等陳述句里,永遠是頂格寫,
單獨的一個“#”也是一個預處理指令,叫“空指令”,可以當作特別的預處理空行,而“#”與后面的指令之間也可以有空格,從而實作縮進,方便排版,
包含檔案#include
在寫頭檔案的時候,為了防止代碼被重復包含,通常要加上“Include Guard”,也就是用“#ifndef/#define/#endif”來保護整個頭檔案,
#ifndef _XXX_H_INCLUDED_
#define _XXX_H_INCLUDED_
... // 頭檔案內容
#endif // _XXX_H_INCLUDED_
宏定義#define/#undef
宏定義是預處理編程里最重要、最核心的指令“#define”,它用來定義一個原始碼級別的“文本替換”,
使用宏的時候一定要謹慎,時刻記著以簡化代碼、清晰易懂為目標,不要“濫用”,避免導致原始碼混亂不堪,降低可讀性,
-
首先,因為宏的展開、替換發生在預處理階段,不涉及函式呼叫、引數傳遞、指標尋址,沒有任何運行期的效率損失,所以對于一些呼叫頻繁的小代碼片段來說,用宏來封裝的效果比inline關鍵字要更好,因為它真的是原始碼級別的無條件行內,
-
其次,你要知道,宏是沒有作用域概念的,永遠是全域生效,所以,對于一些用來簡化代碼、起臨時作用的宏,最好是用完后盡快用“#undef”取消定義,避免沖突的風險,像下面這樣:
-
使用宏時,關鍵是要“適當”,自己把握好分寸,不要把宏弄得“滿天飛”,
用好“文本替換”的功能,
// Nginx中的宏函式
#define ngx_tolower(c) ((c >= 'A' && c <= 'Z') ? (c | 0x20) : c)
#define ngx_toupper(c) ((c >= 'a' && c <= 'z') ? (c & ~0x20) : c)
#define ngx_memzero(buf, n) (void) memset(buf, 0, n)
#define CUBE(a) (a) * (a) * (a) // 定義一個簡單的求立方的宏
cout << CUBE(10) << endl; // 使用宏簡化代碼
cout << CUBE(15) << endl; // 使用宏簡化代碼
#undef CUBE // 使用完畢后立即取消定義
// 另一種做法是宏定義前先檢查,如果之前有定義就先undef,然后再重新定義:
#ifdef AUTH_PWD // 檢查是否已經有宏定義
# undef AUTH_PWD // 取消宏定義
#endif // 宏定義檢查結束
#define AUTH_PWD "xxx" // 重新宏定義
條件編譯 #if/#else/#endif
可以在預處理階段實作分支處理,通過判斷宏的數值來產生不同的原始碼,改變源檔案的形態,這就是“條件編譯”,
編譯階段:屬性和靜態斷言
編譯是預處理之后的階段,它的輸入是(經過預處理的)C++原始碼,輸出是二進制可執行檔案(也可能是匯編檔案、動態庫或者靜態庫),這個處理動作就是由編譯器來執行的,
編譯階段的特殊性在于,它看到的都是C++語法物體,比如typedef、using、template、struct/class這些關鍵字定義的型別,而不是運行階段的變數,
所以,這時的編程思維方式與平常大不相同,
屬性
可以把它理解為給變數、函式、類等“貼”上一個編譯階段的“標簽”,方便編譯器識別處理;
“屬性”相當于編譯階段的“標簽”,用來標記變數、函式或者類,讓編譯器發出或者不發出警告;
“屬性”是用兩對方括號的形式“[[…]]”,方括號的中間就是屬性標簽,
[[noreturn]] // 屬性標簽,表示這個函式沒有回傳值
int func(bool flag) {
throw std::runtime_error("XXX");
}
[[deprecated("deadline:2020-12-31")]] // C++14 or later,表示這個函式已過期
int old_func();
[[gnu::unused]] // 宣告下面的變數暫不使用,不是錯誤
int nouse;
- 好在“屬性”也支持非標準擴展,允許以類似名字空間的方式使用編譯器自己的一些“非官方”屬性,GCC的部分常用屬性如下:
deprecated:與C++14相同,但可以用在C++11里,
unused:用于變數、型別、函式等,表示雖然暫時不用,但最好保留著,因為將來可能會用,
constructor:函式會在main()函式之前執行,效果有點像是全域物件的建構式,
destructor:函式會在main()函式結束之后執行,有點像是全域物件的解構式,
always_inline:要求編譯器強制行內函式,作用比inline關鍵字更強,
hot:標記“熱點”函式,要求編譯器更積極地優化,
靜態斷言
- 動態斷言:
assert用來斷言一個運算式必定為真,當程式(也就是CPU)運行到assert陳述句時,就會計算運算式的值,如果是false,就會輸出錯誤訊息,然后呼叫abort()終止程式的執行,
assert雖然是一個宏,但在預處理階段不生效,而是在運行階段才起作用,所以又叫“動態斷言”,
assert(i > 0 && "i must be greater than zero");
assert(p != nullptr);
assert(!str.empty());
- 靜態斷言:
叫“static_assert”,不過它是一個專門的關鍵字,而不是宏,因為它只在編譯時生效,運行階段看不見,所以是“靜態”的,
它是在編譯階段計算常數和型別,如果斷言失敗就會導致編譯錯誤;編譯器看到static_assert也會計算運算式的值,如果值是false,就會報錯,導致編譯失敗,
static_assert運行在編譯階段,只能看到編譯時的常數和型別,看不到運行時的變數、指標、記憶體資料等,是“靜態”的,所以不要簡單地把assert的習慣搬過來用,
// 保證程式在64位系統上運行,使用靜態斷言在編譯階段檢查long的大小
static_assert(sizeof(long) >= 8, "must run on x64");
// 下面的代碼想檢查空指標,由于變數只能在運行階段出現,而在編譯階段不存在,所以靜態斷言無法處理,
char* p = nullptr;
static_assert(p == nullptr, "some error."); // 錯誤用法
面向物件編程
C++里類的四大函式:它們是建構式、解構式、拷貝建構式、拷貝賦值函式,
C++11因為引入了右值(Rvalue)和轉移(Move、移動),又多出了兩大函式:轉移建構式和轉移賦值函式,所以,在現代C++里,一個類總是會有六大基本函式:三個構造、兩個賦值、一個析構,
-
= default
對于比較重要的建構式和解構式,應該用“= default”的形式,明確地告訴編譯器(和代碼閱讀者):“應該實作這個函式,但我不想自己寫,”這樣編譯器就得到了明確的指示,可以做更好的優化, -
= delete
這種“= default”是C++11新增的專門用于六大基本函式的用法,相似的,還有一種“= delete”的形式,它表示明確地禁用某個函式形式,而且不限于構造/析構,可以用于任何函式(成員函式、自由函式),讓外界無法呼叫, -
explicit
因為C++有隱式構造和隱式轉型的規則,如果你的類里有單引數的建構式,或者是轉型運算子函式,為了防止意外的型別轉換,保證安全,就要使用“explicit”將這些函式標記為“顯式”, -
成員變數初始化(In-class member initializer)
可以在類里宣告變數的同時給它賦值,實作初始化,這樣不但簡單清晰,也消除了隱患, -
使用using或typedef可以為型別起別名,既能夠簡化代碼,還能夠適應將來的變化,
型別別名不僅能夠讓代碼規范整齊,而且因為引入了這個“語法層面的宏定義”,將來在維護時還可以隨意改換成其他的型別,比如,把字串改成string_view(C++17里的字串只讀視圖),把集合型別改成unordered_set,只要變動別名定義就行了,原代碼不需要做任何改動, -
傳統的撰寫方式是
.h頭檔案加上.cpp,宣告與實作分離,
但是更推薦在一個.hpp里實作類的全部功能,這樣更現代,很多著名的開源現代c++專案全面采用了hpp的方式,
// 使用final避免被繼承
class DemoClass final {
private:
int a = 0; // 整數成員,賦值初始化
string s = "hello"; // 字串成員,賦值初始化
vector v{1,2,3}; // 容器成員,使用{}初始化串列
public:
DemoClass() = default; // 明確告訴編譯器,使用默認實作
~DemoClass() = default; // 明確告訴編譯器,使用默認實作
DemoClass(const DemoClass&) = delete; // 禁止拷貝構造
DemoClass& operator=(const DemoClass&) = delete; // 禁止拷貝賦值
explicit DemoClass(const string_type& str) { // 顯式單參建構式
}
explicit operator bool() { // 顯式轉型為bool
}
DemoClass(int x) : a(x) {} // 可以單獨出似憾訓成員,其它使用默認值
using uint_t = unsigned int; // using別名
typedef unsigned int uint_t; // 等價的typedef
using this_type = DemoClass; // 給自己起個別名
using string_type = std::string; // 字串型別別名
using uint32_type = uint32_t; // 整數型別別名
using set_type = std::set; // 集合型別別名,方便以后替換成unordered_set;
using vector_type = std::vector;// 容器型別別名
};
C++語言特性
自動型別推到auto、decltype
auto
除了簡化代碼,auto還避免了對型別的“硬編碼”,也就是說變數型別不是“寫死”的,而是能夠“自動”適應運算式的型別,比如,你把map改為unordered_map,那么后面的代碼都不用動,這個效果和型別別名有點像,但你不需要寫出typedef或者using,全由auto“代勞”,
“自動型別推導”實際上和“attribute”一樣,是編譯階段的特殊指令,指示編譯器去計算型別,
-
auto的“自動推導”能力只能用在“初始化”的場合,
具體來說,就是賦值初始化或者花括號初始化(初始化串列、Initializer list),變數右邊必須要有一個運算式(簡單、復雜都可以),這樣你才能在左邊放上auto,編譯器才能找到運算式,幫你自動計算型別, -
auto總是推匯出“值型別”,絕不會是“參考”;
-
auto可以附加上const、volatile、*、&這樣的型別修飾符,得到新的型別,
auto str = "hello"; // 自動推導為const char [6]型別,需要手動寫std::string;
std::map m = {{1,"a"}, {2,"b"}}; // 自動推導不出來,需要手動宣告std::map<int,string>
auto iter = m.begin(); // 自動推導為map內部的迭代器型別,代碼簡潔很多
auto x = 10L; // auto推導為long,x是long
auto& x1 = x; // auto推導為long,x1是long&
auto* x2 = &x; // auto推導為long,x2是long*
const auto& x3 = x; // auto推導為long,x3是const long&
auto x4 = &x3; // auto推導為const long*,x4是const long*
vector v = {2,3,5,7,11}; // vector順序容器
for(const auto& i : v) { // 常參考方式訪問元素,避免拷貝代價
cout << i << ","; // 常參考不會改變元素的值
}
for(auto& i : v) { // 參考方式訪問元素
i++; // 可以改變元素的值
cout << i << ",";
}
decltype
decltype的形式很像函式,后面的圓括號里就是可用于計算型別的運算式(和sizeof有點類似),其他方面就和auto一樣了,也能加上const、*、&來修飾,
decltype不僅能夠推匯出值型別,還能夠推匯出參考型別,也就是運算式的“原始型別”,
int x = 0; // 整型變數
decltype(x) x1; // 推導為int,x1是int
decltype(x)& x2 = x; // 推導為int,x2是int&,參考必須賦值
decltype(x)* x3; // 推導為int,x3是int*
decltype(&x) x4; // 推導為int*,x4是int*
decltype(&x)* x5; // 推導為int*,x5是int**
decltype(x2) x6 = x2; // 推導為int&,x6是int&,參考必須賦值
- 實際上,它也有個缺點,就是寫起來略麻煩,特別在用于初始化的時候,運算式要重復兩次(左邊的型別計算,右邊的初始化),把簡化代碼的優勢完全給抵消了,
所以,C++14就又增加了一個“decltype(auto)”的形式,既可以精確推導型別,又能像auto一樣方便使用,
int x = 0; // 整型變數
decltype(auto) x1 = (x); // 推導為int&,因為(expr)是參考型別
decltype(auto) x2 = &x; // 推導為int*
decltype(auto) x3 = x1; // 推導為int&
- 在定義類的時候,因為auto被禁用了,所以這也是decltype可以“顯身手”的地方,它可以搭配別名任意定義型別,再應用到成員變數、成員函式上,變通地實作auto的功能,
class DemoClass final
{
public:
using set_type = std::set; // 集合型別別名
private:
set_type m_set; // 使用別名定義成員變數
// 使用decltype計算運算式的型別,定義別名
using iter_type = decltype(m_set.begin());
iter_type m_pos; // 型別別名定義成員變數
};
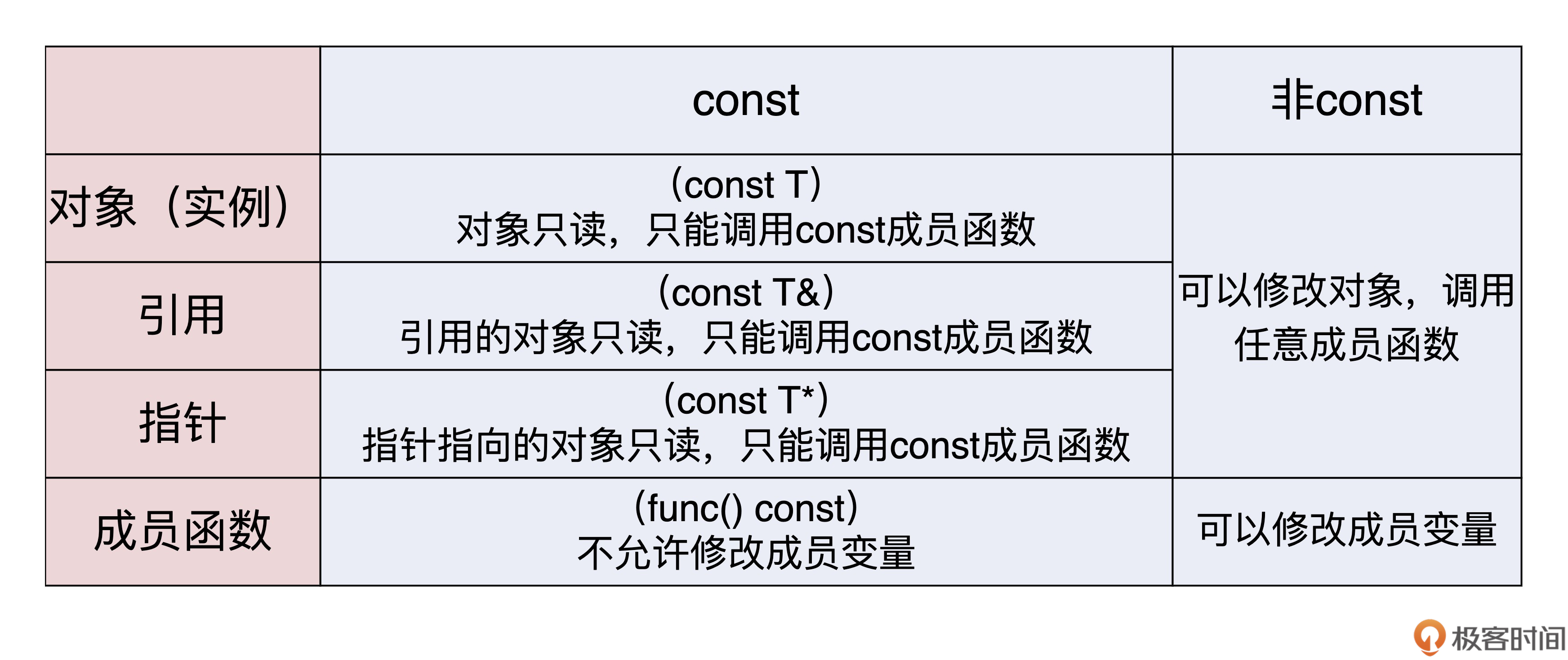
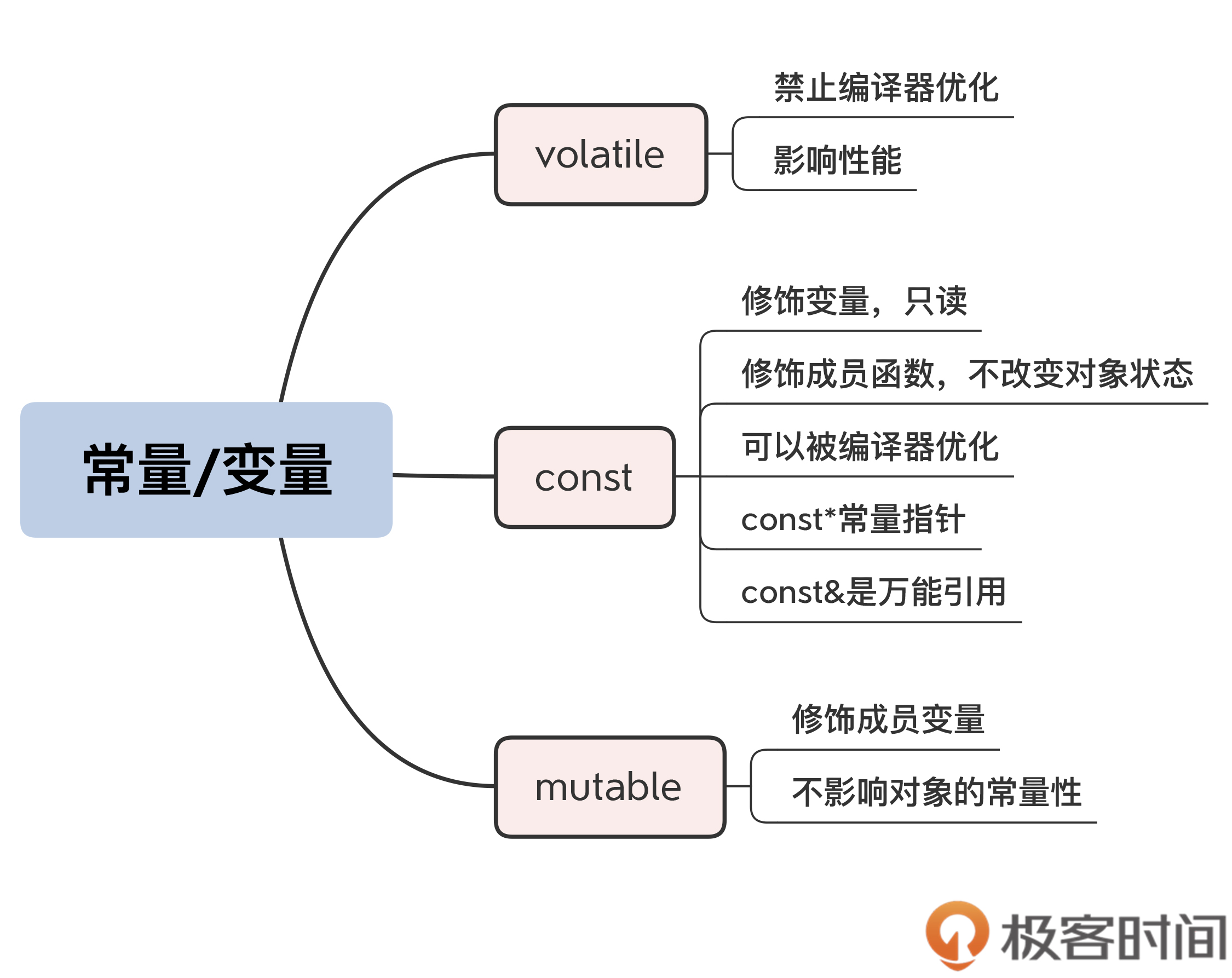
const、volatile、mutable
-
const和宏定義的區別:
const定義的常量在預處理階段并不存在,而是直到運行階段才會出現,
即const修飾的實際上是運行時的“變數”,只不過不允許修改,是“只讀”的(read only),叫“只讀變數”更合適, -
const修飾指標,
const int *p,即常量指標,指標的指向不可改,即指向一個只讀變數;
const也可以修飾參考,const int& rx = x;即常量參考;const &可以參考任何型別,被稱為萬能參考; -
在設計函式的時候,建議盡可能地使用它作為入口引數,一來保證效率,二來保證安全,
-
const成員函式
表示該函式的執行程序中不會修改類中的成員變數, -
可以使用指標強制修改const值,但需要加上volatile,避免編譯器優化
不添加volatile的話,編譯期會將參考該常量的值直接替換成原始值;添加volatile后,禁止編譯器對該值進行優化,必須在運行時去讀取該值,
// 需要加上volatile修飾,運行時才能看到效果
const volatile int MAX_LEN = 1024;
auto ptr = (int*)(&MAX_LEN);
*ptr = 2048;
cout << MAX_LEN << endl; // 輸出2048
int x = 100;
const int& rx = x; // const修飾參考
const int* px = &x; // const修飾指標
class DemoClass final
{
private:
const long MAX_SIZE = 256; // const成員變數
int m_value; // 成員變數
mutable mutex_type m_mutex;
public:
int get_value() const // const成員函式,不能修改非mutable成員變數
{
// m_mutex,可以操作mutable修飾的成員變數
return m_value;
}
};
智能指標
-
學會使用智能指標,避免再使用裸指標、new和delete來操作記憶體了,
-
如果指標是“獨占”使用,就應該選擇unique_ptr,它為裸指標添加了很多限制,更加安全,
如果指標是“共享”使用,就應該選擇shared_ptr,它的功能非常完善,用法幾乎與原始指標一樣,
應當使用工廠函式make_unique()、make_shared()來創建智能指標,強制初始化,而且還能使用auto來簡化宣告,
shared_ptr有少量的管理成本,也會引發一些難以排查的錯誤,所以不要過度使用, -
智能指標是代理模式的具體應用,它完全實踐了RAII慣用法,把裸指標包裝起來,在建構式里初始化,在解構式里釋放,這樣當物件失效銷毀時,C++就會自動呼叫解構式,完成記憶體釋放、資源回收等清理作業,而且它還多載了*和->運算子,用起來和原始指標一模一樣,
-
智能指標實際上并不是指標,而是一個物件,
所以,不要企圖對它呼叫delete,它會自動管理初始化時的指標,在離開作用域時析構釋放記憶體, -
智能指標也沒有定義加減運算,不能隨意移動指標地址,這就完全避免了指標越界等危險操作,可以讓代碼更安全
unique_ptr
- unique_ptr表示指標的所有權是“唯一”的,不允許共享,任何時候只能有一個“人”持有它,
unique_ptr禁止了拷貝賦值,所以在向另一個unique_ptr賦值的時候,必須用std::move()函式顯式地宣告所有權轉移,
unique_ptr ptr1(new int(10)); // int智能指標
assert(*ptr1 == 10); // 可以使用*取內容
assert(ptr1 != nullptr); // 可以判斷是否為空指標
unique_ptr ptr2(new string("hello")); // string智能指標
assert(*ptr2 == "hello"); // 可以使用*取內容
assert(ptr2->size() == 5); // 可以使用->呼叫成員函式
auto ptr3 = make_unique(42); // 工廠函式創建智能指標
assert(ptr3 && *ptr3 == 42);
auto ptr4 = make_unique("god of war"); // 工廠函式創建智能指標
assert(!ptr4->empty());
template // 可變引數模板
std::unique_ptr // 回傳智能指標
my_make_unique(Args&&... args) // 可變引數模板的入口引數
{
return std::unique_ptr( // 構造智能指標
new T(std::forward(args)...)); // 完美轉發
}
auto ptr1 = make_unique(42); // 工廠函式創建智能指標
assert(ptr1 && *ptr1 == 42); // 此時智能指標有效
auto ptr2 = std::move(ptr1); // 使用move()轉移所有權
assert(!ptr1 && ptr2); // ptr1變成了空指標
share_ptr
-
shared_ptr所有權是可以被安全共享的,支持拷貝賦值,允許被多個“人”同時持有,就像原始指標一樣,
-
shared_ptr支持安全共享的秘密在于內部使用了“參考計數”,
參考計數最開始的時候是1,表示只有一個持有者,如果發生拷貝賦值——也就是共享的時候,參考計數就增加,而發生析構銷毀的時候,參考計數就減少,
只有當參考計數減少到0,也就是說,沒有任何人使用這個指標的時候,它才會真正呼叫delete釋放記憶體, -
使用shared_ptr也是有代價的,參考計數的存盤和管理都是成本,這方面是shared_ptr不如unique_ptr的地方,
如果不考慮應用場合,過度使用shared_ptr就會降低運行效率,不過,你也不需要太擔心,shared_ptr內部有很好的優化,在非極端情況下,它的開銷都很小, -
解構式里不要有非常復雜、嚴重阻塞的操作,
因為在運行階段,參考計數的變動是很復雜的,很難知道它真正釋放資源的時機,無法像Java、Go那樣明確掌控、調整垃圾回識訓制,一旦shared_ptr在某個不確定時間點析構釋放資源,就會阻塞整個行程或者執行緒,stop the world,
shared_ptr ptr1(new int(10)); // int智能指標
assert(*ptr1 = 10); // 可以使用*取內容
shared_ptr ptr2(new string("hello")); // string智能指標
assert(*ptr2 == "hello"); // 可以使用*取內容
auto ptr3 = make_shared(42); // 工廠函式創建智能指標
assert(ptr3 && *ptr3 == 42); // 可以判斷是否為空指標
auto ptr4 = make_shared("zelda"); // 工廠函式創建智能指標
assert(!ptr4->empty()); // 可以使用->呼叫成員函式
auto ptr1 = make_shared(42); // 工廠函式創建智能指標
assert(ptr1 && ptr1.unique() ); // 此時智能指標有效且唯一
auto ptr2 = ptr1; // 直接拷貝賦值,不需要使用move()
assert(ptr1 && ptr2); // 此時兩個智能指標均有效
assert(ptr1 == ptr2); // shared_ptr可以直接比較
// 兩個智能指標均不唯一,且參考計數為2
assert(!ptr1.unique() && ptr1.use_count() == 2);
assert(!ptr2.unique() && ptr2.use_count() == 2);
auto ptr_demo = make_shared(new DemoShared());
class DemoShared final // 危險的類,不定時的地雷
{
public:
DemoShared() = default;
~DemoShared() // 復雜的操作會導致shared_ptr析構時世界靜止
{
// Stop The World ...
}
};
- shared_ptr依靠參考計數,可能會發生互相參考,導致記憶體泄露,
這時候就要使用weak_ptr,它專門為打破回圈參考而設計,只觀察指標,不會增加參考計數(弱參考),但在需要的時候,可以呼叫成員函式lock(),獲取shared_ptr(強參考),
class Node final
{
public:
using this_type = Node;
// using shared_type = std::shared_ptr; // 當使用shared_ptr時,就會回圈參考,造成記憶體泄露
// 注意這里,別名改用weak_ptr
using shared_type = std::weak_ptr;
public:
shared_type next; // 因為用了別名,所以代碼不需要改動
};
auto n1 = make_shared(); // 工廠函式創建智能指標
auto n2 = make_shared(); // 工廠函式創建智能指標
n1->next = n2; // 兩個節點互指,形成了回圈參考
n2->next = n1;
assert(n1.use_count() == 1); // 因為使用了weak_ptr,參考計數為1,否則是2
assert(n2.use_count() == 1); // 打破回圈參考,不會導致記憶體泄漏
if (!n1->next.expired()) { // 檢查指標是否有效
auto ptr = n1->next.lock(); // lock()獲取shared_ptr
assert(ptr == n2);
}
例外
-
建議最好不要直接用throw關鍵字,而是要封裝成一個函式,這和不要直接用new、delete關鍵字是類似的道理——通過引入一個“中間層”來獲得更多的可讀性、安全性和靈活性,
-
關鍵字noexcept標記函式不拋出例外,可以讓編譯器做更好的優化,
但是,也不要一股腦地給所有函式都加上noexcept修飾;因為noexcept只是做出了一個“不可靠的承諾”,不是“強保證”,編譯器無法徹底檢查它的行為,標記為noexcept的函式也有可能拋出例外:
noexcept的真正意思是:“我對外承諾不拋出例外,我也不想處理例外,如果真的有例外發生,請讓我死得干脆點,直接崩潰(crash、core dump),” -
一般認為,重要的建構式(普通建構式、拷貝構造、轉移構造)、解構式應當進來宣告為noexcept,以優化性能,而析構桉樹則必須保證絕對不會拋例外,
-
寫catch塊就像是寫一個標準函式,所以入口引數也應當使用“const &”的形式,避免物件拷貝的代價:
[[noreturn]] // 屬性標簽
void raise(const char* msg) // 函式封裝throw,沒有回傳值
{
throw my_exception(msg); // 拋出例外,也可以有更多的邏輯
}
try
{
raise("error occured"); // 函式封裝throw,拋出例外
}
catch(const exception& e) // const &捕獲例外,可以用基類
{
cout << e.what() << endl; // what()是exception的虛函式
}
void func_noexcept() noexcept // 宣告絕不會拋出例外
{
cout << "noexcept" << endl;
}
字串string
-
string是一個typedef
string其實并不是一個“真正的型別”,而是模板類basic_string的特化形式,是一個typedef:
using string = std::basic_string;// string其實是一個型別別名 -
目前C++對Unicode的支持還不太完善,建議盡量避開國際化和編碼轉化,不要“自討苦吃”;
建議你只用string,而且在涉及Unicode、編碼轉換的時候,盡量不要用C++,目前它還不太擅長做這種作業; -
應當把string視為一個完整的字串來操作,不要把它當成容器來使用;
string的成本問題,它確實有點“重”,大字串的拷貝、修改代價很高,所以我們通常都盡量用const string&,
容器
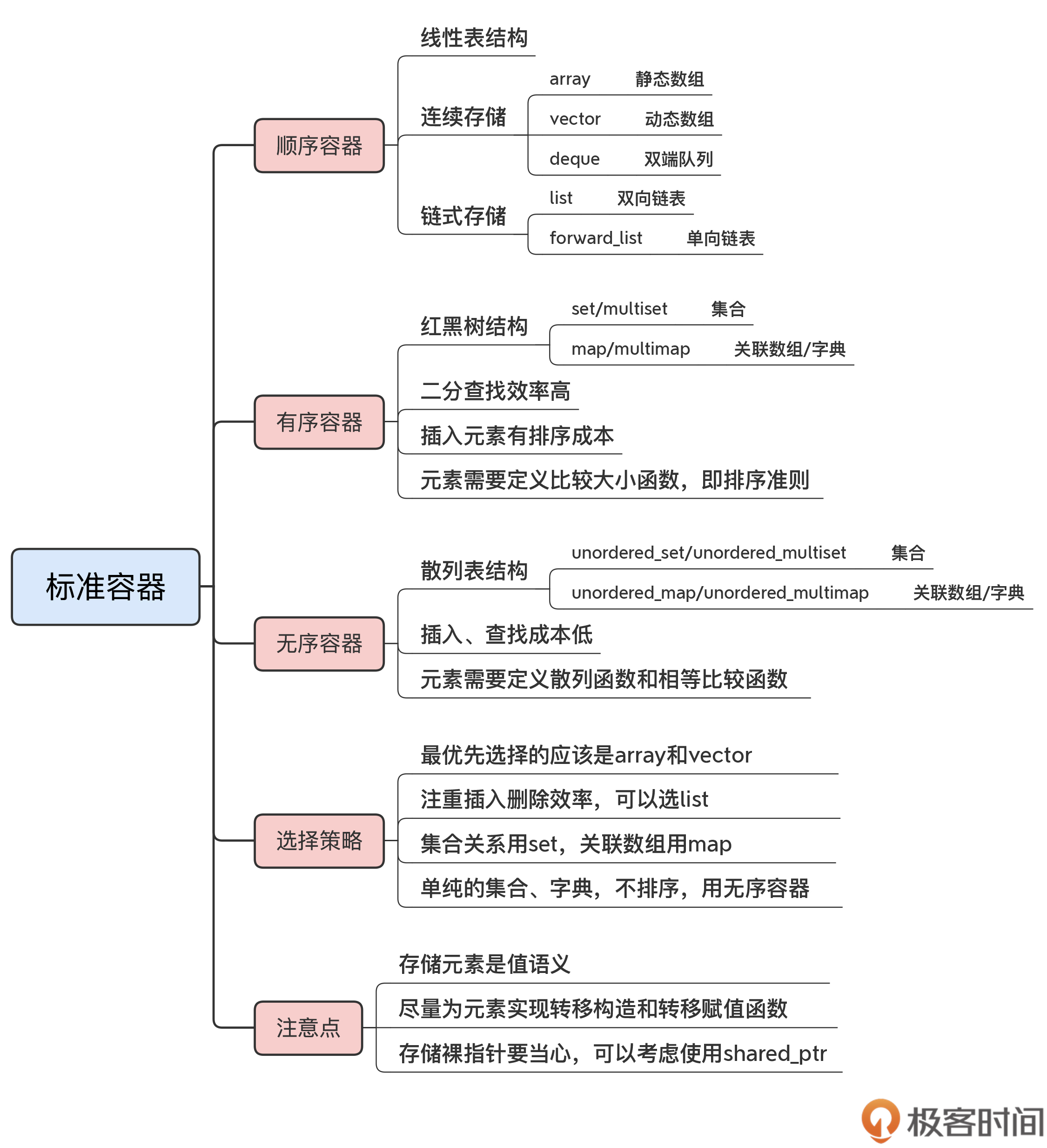
你必須要知道所有容器都具有的一個基本特性:它保存元素采用的是“值”(value)語意,也就是說,容器里存盤的是元素的拷貝、副本,而不是參考,
容器操作元素的很大一塊成本就是值的拷貝,所以,如果元素比較大,或者非常多,那么操作時的拷貝開銷就會很高,性能也就不會太好,
- 盡量為元素實作轉移構造和轉移賦值函式,在加入容器的時候使用std::move()來“轉移”,減少元素復制的成本:
Point p; // 一個拷貝成本很高的物件
v.push_back(p); // 存盤物件,拷貝構造,成本很高
v.push_back(std::move(p)); // 定義轉移構造后就可以轉移存盤,降低成本
// 直接使用C++11為容器新增加的emplace操作函式,它可以“就地”構造元素,免去了構造后再拷貝、轉移的成本
v.emplace_back(...); // 直接在容器里構造元素,不需要拷貝或者轉移
- 容器中存放指標,則必須要自己手動管理元素的生命周期
如果真的有這種需求,可以考慮使用智能指標unique_ptr/shared_ptr,讓它們幫你自動管理元素,
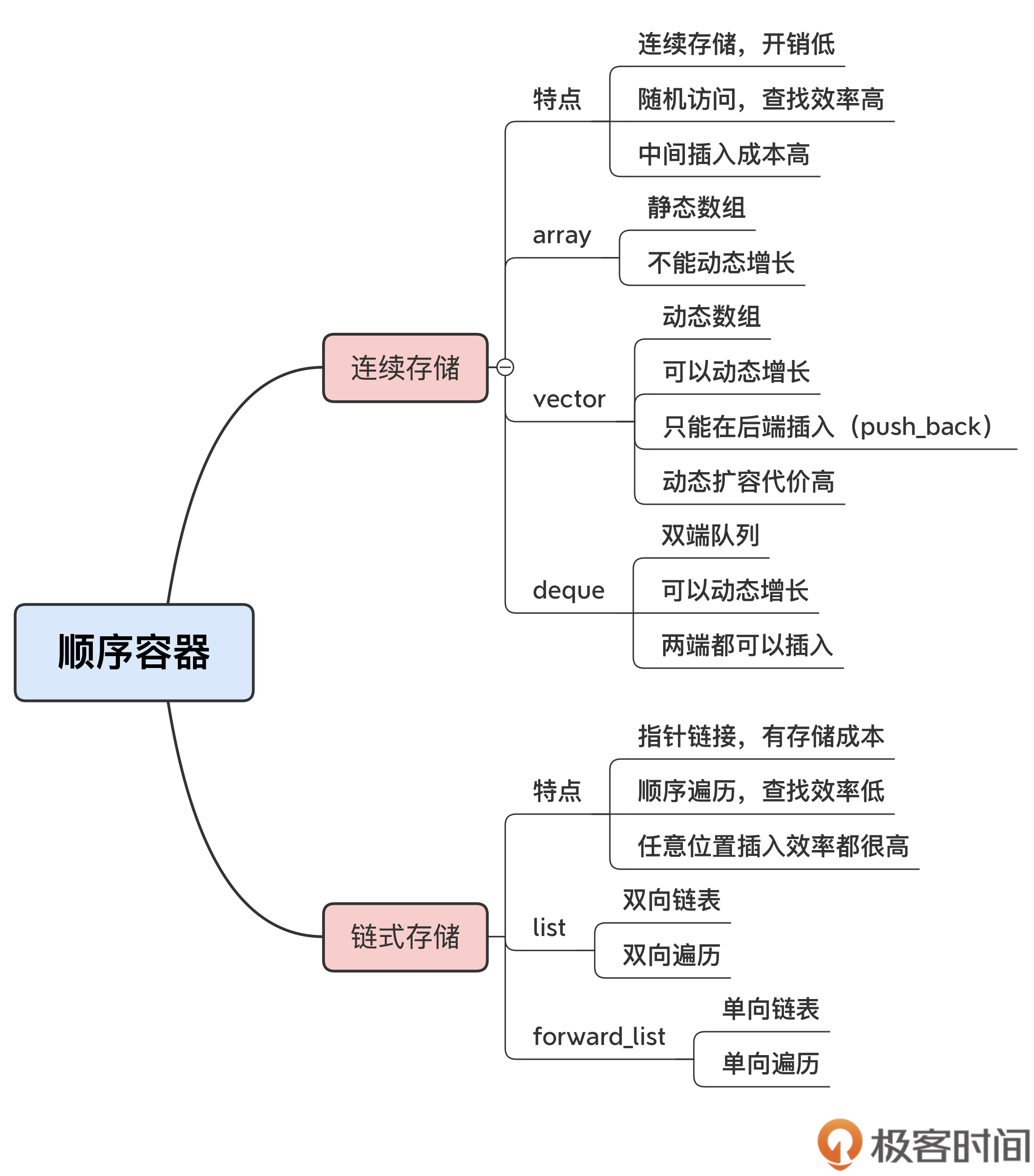
順序容器
連續存盤的陣列:array、vector和deque,
指標結構的鏈表:list和forward_list,
array和vector直接對應C的內置陣列,記憶體布局與C完全兼容,所以是開銷最低、速度最快的容器,
它們兩個的區別在于容量能否動態增長,array是靜態陣列,大小在初始化的時候就固定了,不能再容納更多的元素,
而vector是動態陣列,雖然初始化的時候設定了大小,但可以在后面隨需增長,容納任意數量的元素,
deque也是一種可以動態增長的陣列,它和vector的區別是,它可以在兩端高效地插入洗掉元素,這也是它的名字double-end queue的來歷,而vector則只能用push_back在末端追加元素,
有序容器
C++的有序容器使用的是樹結構,通常是紅黑樹——有著最好查找性能的二叉樹,
標準庫里一共有四種有序容器:set/multiset和map/multimap,set是集合,map是關聯陣列(在其他語言里也叫“字典”),
這就導致了有序容器與順序容器的另一個根本區別,在定義容器的時候必須要指定key的比較函式,
解決這個問題有兩種辦法:一個是多載“<”,另一個是自定義模板引數,
無序容器
無序容器也有四種,名字里也有set和map,只是加上了unordered(無序)前綴,分別是unordered_set/unordered_multiset、unordered_map/unordered_multimap,
無序容器同樣也是集合和關聯陣列,用法上與有序容器幾乎是一樣的,區別在于內部資料結構:它不是紅黑樹,而是散串列(也叫哈希表,hash table),
并發
在C++多執行緒編程里讀取const變數總是安全的,對類呼叫const成員函式、對容器呼叫只讀演算法也總是執行緒安全的,
使用std::call_once、thread_local和atomic這三個C++里的工具,它們都不與執行緒直接相關,但卻能夠用于多執行緒編程,盡量消除顯式地使用執行緒,
C++標準庫里有專門的執行緒類thread,使用它就可以簡單地創建執行緒,在名字空間std::this_thread里,還有yield()、get_id()、sleep_for()、sleep_until()等幾個方便的管理函式,
標準庫里還有mutex、lock_guard、condition_variable、promise等很多工具,
C++里的幾個好用的網路通信庫
-
libcurl:高可移植、功能豐富的通信庫
libcurl的介面可以粗略地分成兩大類:easy系列和multi系列,其中,easy系列是同步呼叫,比較簡單;multi系列是異步的多執行緒呼叫,比較復雜,通常情況下,我們用easy系列就足夠了, -
cpr是對libcurl的一個C++11封裝,使用了很多現代C++的高級特性,對外的介面模仿了Python的requests庫,非常簡單易用,
-
ZMQ不僅是一個單純的網路通信庫,更像是一個高級的異步并發框架,
Zero Message Queue——零延遲的訊息佇列,意味著它除了可以收發資料外,還可以用作訊息中間件,解耦多個應用服務之間的強依賴關系,搭建高效、有彈性的分布式系統,從而超越原生的Socket,
作為訊息佇列,ZMQ的另一大特點是零配置零維護零成本,不需要搭建額外的代理服務器,只要安裝了開發庫就能夠直接使用,相當于把訊息佇列功能直接嵌入到你的應用程式里:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/287649.html
標籤:其他
上一篇:嵌入式面試總結