🎈 作者:Linux猿
🎈 簡介:CSDN博客專家🏆,C/C++、面試、刷題、演算法盡管咨詢我,關注我,有問題私聊!
🎈 關注專欄:C/C++面試通關集錦 (優質好文持續更新中……)🚀
目錄
一、冒泡排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
二、選擇排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
三、快速排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
四、歸并排序
1. 演算法思想
2. 實體演示
3. 代碼演示
4. 演算法復雜度
五、堆排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
六、直接插入排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
七、希爾排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
八、基數排序
1. 演算法思想
2. 實體演示
3. 代碼實作
4. 演算法復雜度
本文來整理一下八大排序演算法,下面將結合實體演示進行說明!
一、冒泡排序
1. 演算法思想
冒泡排序是一種比較簡單的排序演算法,它是一種基于比較的演算法,是一種穩定的排序演算法,從第一個元素開始,每次比較相鄰元素,如果元素順序不正確,則進行交換,否則,比較下一對相鄰元素,重復上述程序,一直到所有元素都有序,
穩定性:
若經過排序后,各元素的相對位置不變(排序前 r[i] 在 r[j] 前,排序后 r[i] 依然在 r[j] 后,相對位置不變),即排序具有穩定性,
2. 實體演示
下面以陣列 [7, 9, 5 , 3, 1] 為例進行從小到大排序的演示:
第一趟排序:
7 與 9 不交換 =》 9 與 5 交換 =》 9 與 3 交換 =》 9與1交換
第一趟排序結果為:
[7, 5, 3, 1, 9]
經過第一趟排序后,9已經在最終排序位置上,
第二趟排序:
7與5 交換 =》 7 與 3 交換 =》 7與1不交換(9 已經在最終位置上不必進行比較)
第二趟排序結果為:
[5, 3, 1, 7, 9]
經過第二趟排序后,7,9已經在最終排序位置上,
第三趟排序:
5 與 3 交換,5與1交換
第三趟排序結果為:
[3, 1, 5, 7, 9]
經過第三趟排序后,5,7,9 已經在最終位置上,
第四趟排序:
3 與 1 交換
第四趟排序結果為:
[1, 3, 5, 7, 9]
經過第四趟排序后,陣列已經有序,
可以看到每一趟排序后至少有一個元素在最終的排序位置上,最多經過 n-1 趟排序,陣列全部有序,
接下來看一下代碼實作,
3. 代碼實作
void bubbleSort(int g[], int n) {
bool flag = true; //檢查陣列是否有序
for(int i = 0;i < n-1; ++i){
flag = false;
for(int j = 0; j < n-i-1; ++j){//n-i-1 已經有序的元素不再比較
if(g[j] > g[j+1]){
swap(g[j], g[j+1]);
flag = true;
}
}
if(!flag) break; // flag = false 表示沒有交換元素,陣列已經有序
}
}4. 演算法復雜度
空間復雜度:除了本身的陣列不需要額外的存盤空間,故空間復雜度為 O(1),
時間復雜度:有兩層 for 回圈,排序次數的時間復雜度為 O(n),交換次數的時間復雜度為O(n),因為是嵌套的,故總的復雜度為O(n^2),
二、選擇排序
1. 演算法思想
選擇排序是一個比較簡單的排序,是一種基于選擇的排序演算法,但并不是一個穩定的排序演算法,
基本思想(從小到大排序):選擇陣列最小的元素,與陣列第一個元素交換,然后選擇剩余的陣列元素中最小的元素,與陣列第二個元素交換,一直重復上述操作,直到陣列有序,
2. 實體演示
下面以陣列 [7, 9, 5 , 3, 1] 為例進行從小到大排序的演示:
第一趟排序:
遍歷一遍陣列,最小的元素是1,與 第一個元素 7 交換,
第一趟排序的結果為:
[1, 9, 5, 3, 7]
第一趟排序后,元素 1 已經在最終排序位置上,
第二趟排序:
遍歷一遍陣列剩余元素,最小元素是3,3 與 9 交換,
第二趟排序的結果為:
[1, 3, 5, 9, 7]
經過第三趟排序后,將 3 放置到最終排序位置(其實 5 也已經在最終位置了)
第三趟排序:
遍歷一遍陣列剩余元素,最小元素是 5,已經在最終排序位置,不用交換,
第三趟排序的結果為:
[1, 3, 5, 9, 7]
第四趟排序:
遍歷一遍陣列剩余元素,最小元素是 7,將 7 與 9 交換,
第四趟排序結果為:
[1, 3, 5, 7, 9]
第四趟排序后,全部元素已經有序,
3. 代碼實作
void selectSort(int a[], int n){
int Min;
for(int i = 0;i < n-1; ++i){//選擇 n-1 次
Min = i;
for(int j = i+1; j < n; ++j){//從 i-n之間選擇一個最小值放在i處,
if(a[j] < a[Min]){
Min = j;
}
}
if(Min != i){
swap(a[i], a[Min]);
}
}
}4. 演算法復雜度
空間復雜度:除了本身的陣列不需要額外的存盤空間,故空間復雜度為 O(1),
時間復雜度:兩層嵌套的 for 回圈,每個的時間復雜度為O(n),故總的時間復雜度為O(n^2)
三、快速排序
1. 演算法思想
快速排序是一種更優的排序演算法,是一種不穩定的排序演算法,它采用分而治之的思想,每次排序選擇待排序序列的一個值,該值作為樞紐值,以該值為基點,小于該值的交換到左邊,大于該值的交換到右邊,然后,重復上述操作,排序左右兩邊待排序的序列,一直分解到單個元素,每次分解都會確定一個元素的最終位置,
那么,交換的規則是什么呢?
以左邊第一個是樞紐值為例,樞紐值首先從右向左找到一個小于樞紐值的元素,將這個元素與樞紐值交換位置,交換后再從左到右與樞紐值進行比較,找到一個比樞紐值大的元素,與樞紐值交換,然后重復上述程序,直到樞紐值左邊元素不大于樞紐值,樞紐值右邊不小于樞紐值為止,
2. 實體演示
下面以陣列 [5, 7, 9 , 3, 1] 為例進行從小到大排序的演示:
樞紐值的選擇以待排序序列的第一個為例,
首先,選取 5 為樞紐值,先從右向左找到一個小于樞紐值 5 的值,并與之交換位置,很明顯,
5 與 1 交換,交換后陣列變為:
[1, 7, 9, 3, 5]
然后,從左向右找到一個比樞紐值大的元素,并與之交換位置,這個元素是7,與5交換位置后,陣列變為:
[1, 5, 9, 3, 7]
然后,從右向左找到一個比樞紐值小的元素,并與之交換位置,這個元素是3,與5交換位置后,陣列變為:
[1, 3, 9, 5, 7]
然后,從左向右找到一個比樞紐值大的元素,并與之交換位置,這個元素是 9,與5交換位置后,陣列變為:
[1, 3, 5, 9, 7]
然后重復上述操作,排序[1, 3] 和 [9, 7]兩個序列,
序列[1, 3], 1為樞紐值,從右向左找到一個比樞紐值1 小的元素,序列已經有序了,1 的右邊值比1大,左邊沒有值,因為1右邊序列[3] 只有一個元素,故不用排序,
序列[9, 7],9 為樞紐值,從右向左找到一個比樞紐值9小的元素,這個元素是 7,7與9交換位置,交換后為:
[7, 9],序列已經有序,樞紐值左邊序列[7] 只有一個元素,故不用排序,
最后,得到有序序列 [1, 3, 5, 7, 9],
3. 代碼實作
遞回版本:
/*快速排序演算法
* l ----- 序列左邊下標
* t ----- 序列右邊下標
* a[] --- 排序陣列
*/
int Partition(int a[], int l, int t){//使用樞紐值劃分待排序序列
int idx = l + rand()%(t - l + 1);//樞紐值是隨機選取的
swap(a[l], a[idx]);
int i = l;
int j = t;
int x = a[i];
while(i < j){
while(i < j && a[j] > x)
j--;
if(i < j)
a[i++] = a[j];
while(i < j && a[i] < x)
i++;
if(i < j)
a[j--] = a[i];
}
a[i] = x;
return i;
}
//遞回進行劃分
void Quick_Sort(int a[], int l, int t){
if(l < t){
int mid = Partition(a, l, t);//劃分,回傳基準值下標
Quick_Sort(a, l, mid-1);//樞紐值左邊待排序序列
Quick_Sort(a, mid+1, t);//樞紐值右邊待排序序列
}
}非遞回版本:
//Pair存盤待排序序列的第一個和最后一個坐標,
//這樣就可以確定一個序列,
typedef pair<int, int> Pair;
int Partition(int a[], int lt, int rt){//以樞紐值劃分待排序序列
int i = lt;
int j = rt;
int rm = i + rand()%(j - i + 1);//樞紐值隨機選取
swap(a[i], a[rm]);
int x = a[i];
while(i < j){
while(i < j && a[j] > x)
j--;
if(i < j)
a[i++] = a[j];
while(i < j && a[i] < x)
i++;
if(i < j)
a[j--] = a[i];
}
a[i] = x;
return i;
}
//以堆疊的形式模擬遞回
void Quick_Sort(int a[], int l, int t){
stack<Pair>S;
S.push(Pair(l, t));
while(!S.empty()){//使用堆疊模擬
int lt = S.top().first;
int rt = S.top().second;
S.pop();
int mid = Partition(a, lt, rt);
if(mid+1 < rt)
S.push(Pair(mid+1, rt));
if(lt < mid-1)
S.push(Pair(lt, mid-1));
}
}
4. 演算法復雜度
空間復雜度:不管是遞回版本,還是非遞回版本,都會占用空間,復雜度為O(log2n) ~ O(n),最好的情況是每次都是2分序列,復雜度為 O(log2n),最差的情況是每次的樞紐值是最大值或最小值,復雜度為O(n),
時間復雜度:平均情況下,有n個元素,堆疊的深度為 log2n,故總的時間復雜度為O(nlog2n),
四、歸并排序
1. 演算法思想
歸并排序是一種比較快的排序演算法,是一種穩定排序演算法,它也是采用分而治之的思想,歸并排序是先劃分排序元素,每次都是二分,先不進行比較,直到劃分為單個元素后,回溯的時候進行比較,作歸并,
如果還不懂,沒關系!接下來看一下實體演示就懂了,
2. 實體演示
下面以陣列 [5, 7, 9 , 3, 1, 8,6,2] 為例進行從小到大排序的演示:
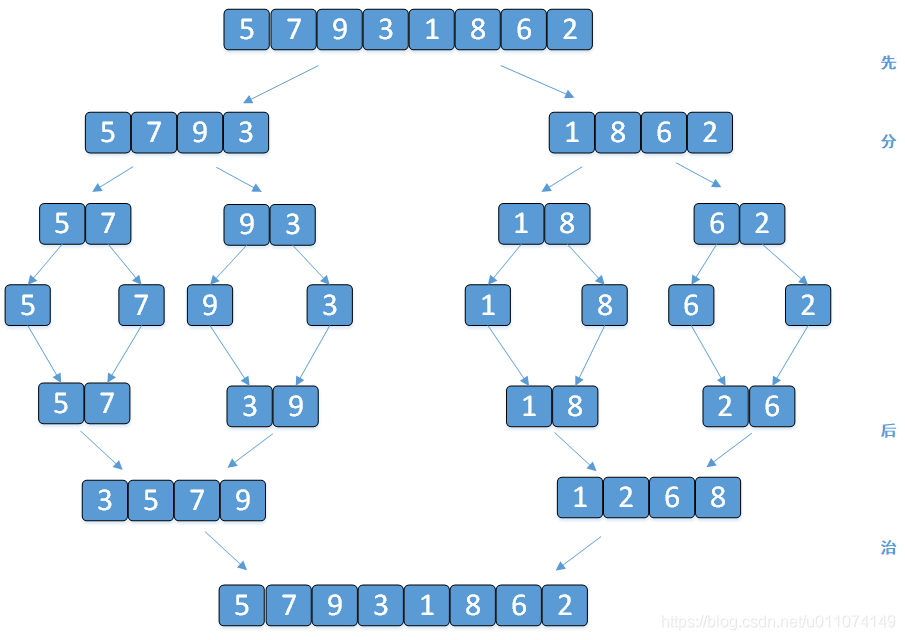
3. 代碼演示
//歸并排序的合并操作
void Merge(int a[], int lt, int rt, int p[]){//p是合并用的臨時陣列
int mid = (rt - lt)/2 + lt;
int i = lt, j = mid + 1;
int k = 0;
while(i <= mid && j <= rt){
if(a[i] <= a[j]){
p[k++] = a[i++];
}else {
p[k++] = a[j++];
}
}
while(i <= mid){
p[k++] = a[i++];
}
while(j <= rt){
p[k++] = a[j++];
}
for(i = 0; i < k; ++i){
a[lt+i] = p[i];
}
}
//劃分函式,遞回劃分
void MergeSort(int a[], int lt, int rt, int p[]){
if(lt < rt){
int mid = (rt - lt)/2 + lt;
MergeSort(a, lt, mid, p);
MergeSort(a, mid+1, rt, p);
Merge(a, lt, rt, p);
}
}4. 演算法復雜度
空間復雜度:在作合并的時候,需要一個輔助陣列,故空間復雜度為O(n);
時間復雜度:劃分時,堆疊的深度為 log2n,時間復雜度為 O(log2n),合并時,每次合并的時間復雜度為 O(n),故總的時間復雜度為 O(nlog2n),
五、堆排序
1. 演算法思想
堆排序是一種不穩定的排序演算法,適合于求第k大的數,
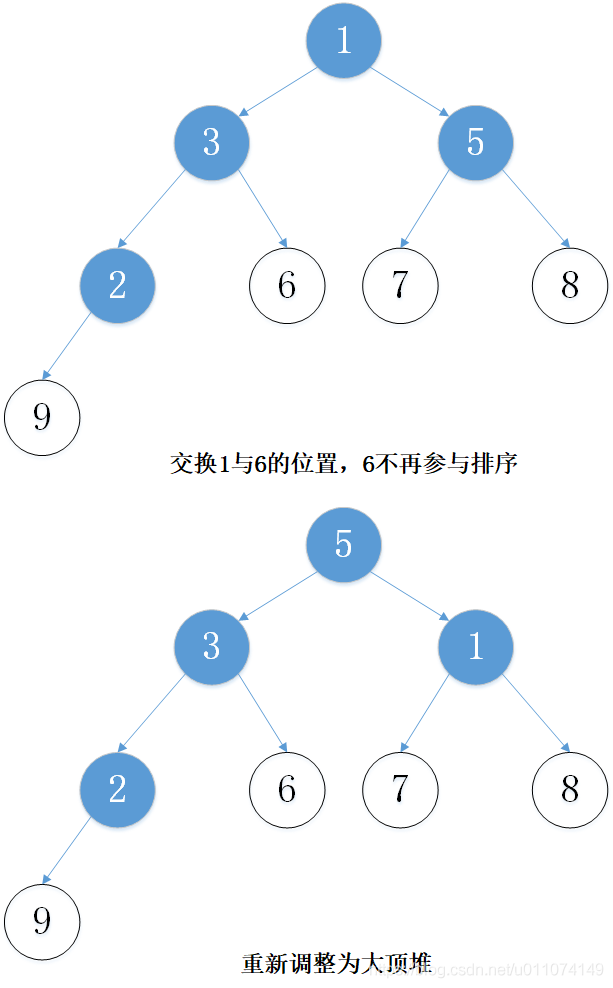
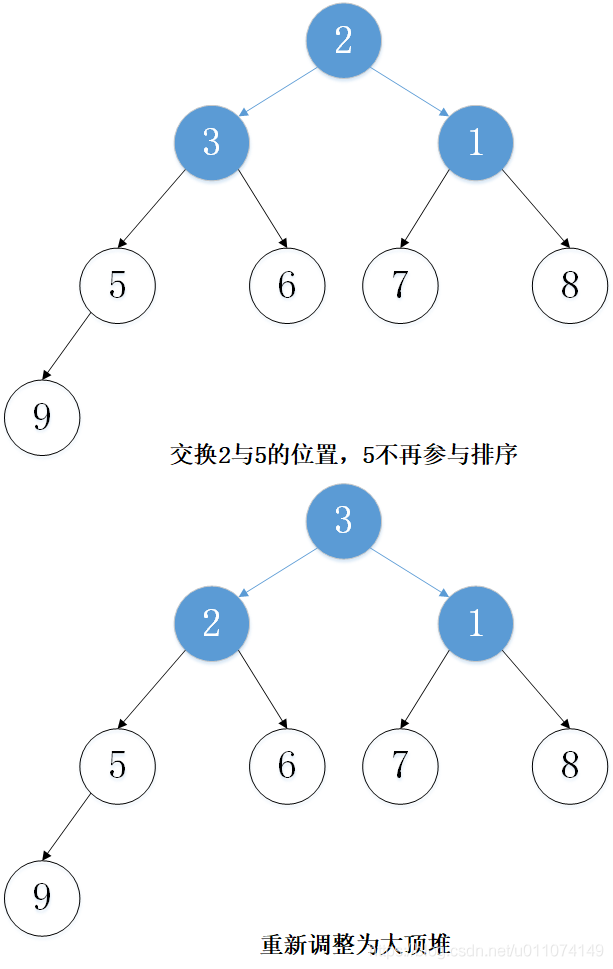
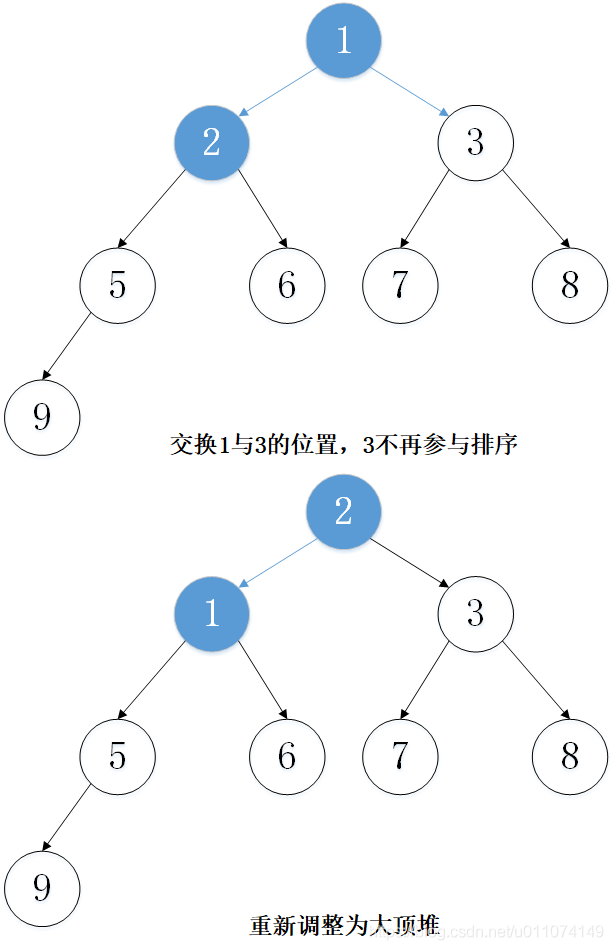
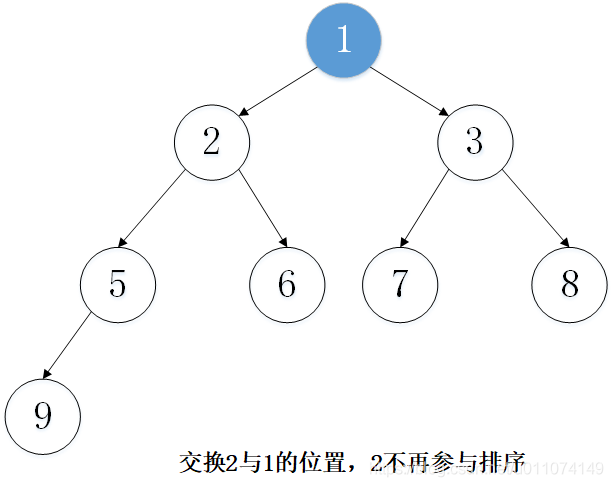
主要思想:以從小到大排序為例,先建立大頂堆,然后取出堆頂元素(堆頂元素一定是當前堆中的最大值),將堆的最后一個元素放置到堆頂,這時,并不是一個大頂堆,然后調整堆使其成為大頂堆,然后將堆頂元素取出,重復上述程序,一直到最后一個元素,
2. 實體演示
下面以陣列 [5, 7, 9 , 3, 1, 8,6,2] 為例進行從小到大排序的演示:
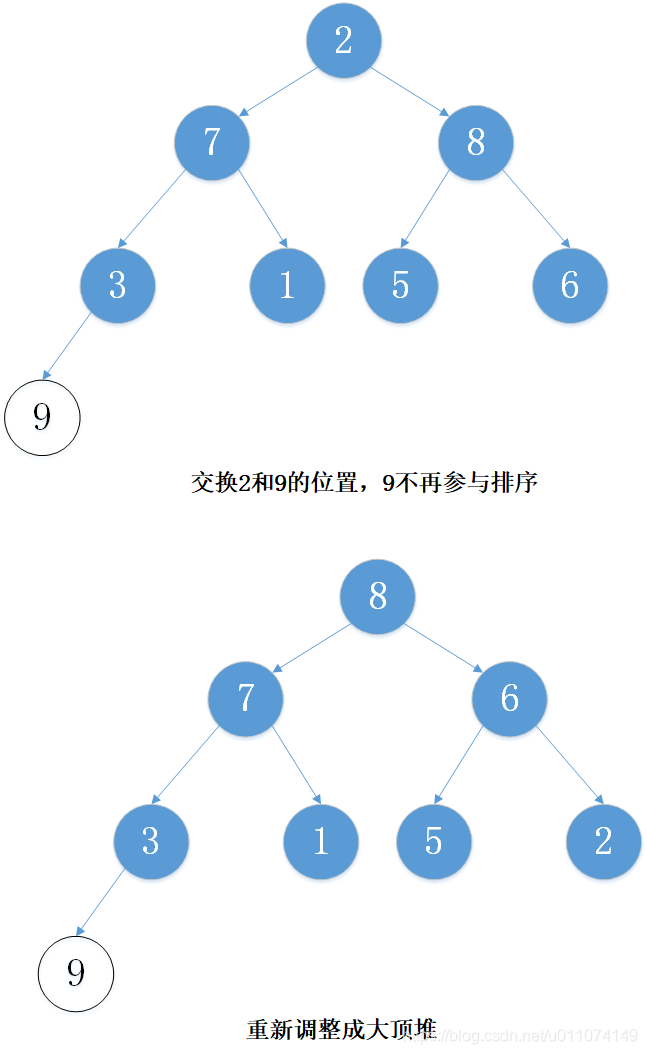
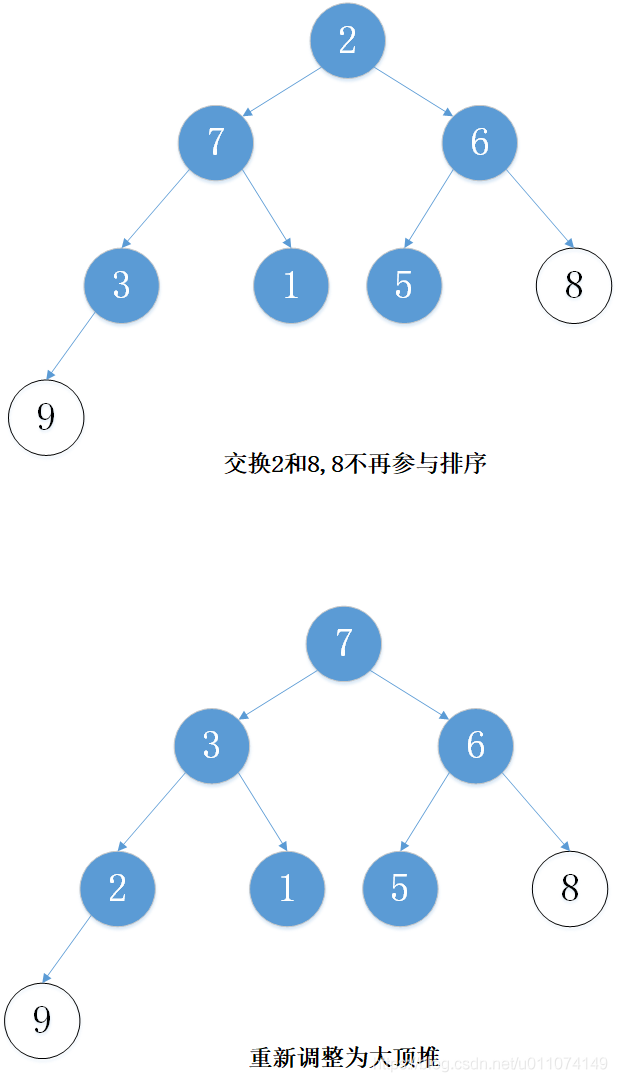
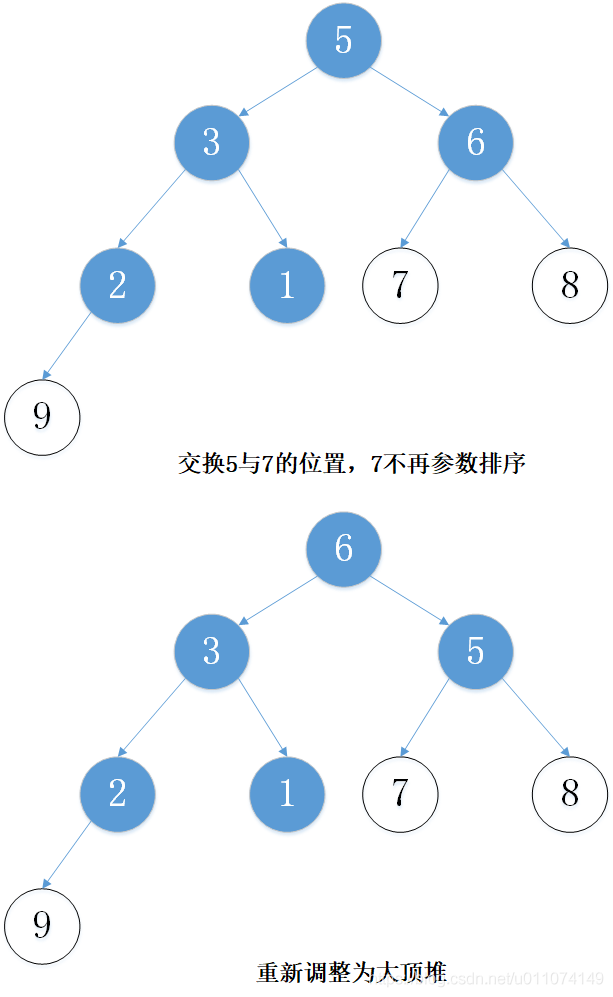
3. 代碼實作
#include <iostream>
using namespace std;
//向下調整堆
void adjustHeap(int a[], int idx, int Len){
while(idx*2+1 < Len){
int temp = idx*2+1;
if(temp+1 < Len && a[temp+1] > a[temp]){
temp++;
}
if(a[idx] < a[temp]){
swap(a[idx], a[temp]);
idx = temp;
}else break;
}
}
/*
* 堆排序
* g[] : 待排序陣列
* n : 元素個數
*/
void heapSort(int g[], int n){
//先建立大頂堆
for(int i = (n-1)/2; i >= 0; --i){
adjustHeap(g, i, n);
}
//排序
for(int i = 0;i < n; ++i){
swap(g[0], g[n-i-1]);
adjustHeap(g, 0, n-i-1);
}
}
int main()
{
int n = 8;
int g[] = {5, 7, 9, 3, 1, 8, 6, 2};
heapSort(g, n);
for(int i = 0; i < n; ++i) {
cout<<g[i]<<" ";
}
cout<<endl;
return 0;
}4. 演算法復雜度
空間復雜度:在上述代碼中,沒有使用到額外的輔助空間,故空間復雜度為O(1),
時間復雜度:在上述代碼中,建立大頂堆的時間復雜度為O(n),進行排序的時間復雜度為O(nlog2n),故總的時間復雜度為O(nlog2n),
六、直接插入排序
1. 演算法思想
直接插入排序是一種很好理解的排序演算法,是一種穩定的排序演算法,
假設元素存盤在陣列 g 中,共有 n 個元素,依次遍歷每一個元素,將元素 g[i] 按大小順序插入到 0 ~ i 的位置,一直重復插入,直到第n個元素,
2. 實體演示
下面以陣列 [7, 9, 5 , 3, 1] 為例進行從小到大排序的演示:
從第2個元素開始插入,
第2個元素插入:
9 比 7 大,所以 9 不需要移動位置,陣列元素位置沒有變化,
第3個元素插入:
經過比較,5 需要插入到 7 的前面,插入后的陣列為:
[5, 7, 9, 3, 1]
第4個元素插入:
經過比較,3 需要插入到 5 的前面,插入后的陣列為:
[3, 5, 7, 9, 1]
第5個元素插入:
經過比較,1 需要插入到 3 的前面,插入后的陣列為:
[1, 3, 5, 7, 9]
陣列已經有序了,
3. 代碼實作
/*
* 直接插入排序演算法:
* g :待排序的陣列
* n :陣列的長度
*/
void directInsertSort(int g[], int n)
{
for(int i = 1; i < n; ++i) { //依次遍歷所有元素
int j = i-1;
int tmp = g[i];
while(j >= 0 && g[j] > tmp) {
g[j+1] = g[j];
j--;
}
g[j+1] = tmp;
}
}4. 演算法復雜度
空間復雜度:除了本身的陣列不需要額外的存盤空間,故空間復雜度為 O(1),
時間復雜度:需要排序的元素的時間復雜度為 O(n),對應第一層 for 回圈,每插入一個元素的時間復雜度為O(n),對應while回圈,故總的時間復雜度為 O(n^2),
七、希爾排序
1. 演算法思想
希爾排序是將元素進行分組插入排序的演算法,是一種不穩定的排序演算法,
主要思想:間隔以陣列長度每次除以2為例,陣列中的元素先以n/2為間隔分組,每個分組使用插入排序演算法的思想進行排序,排序后每個分組中的元素是有序的,然后,將間隔設為 n/2/2 進行分組,每個分組使用插入排序演算法思想進行排序,后面重復上述程序,直到間隔為1,間隔為1時和插入排序演算法一樣了,
2. 實體演示
下面以陣列 [35, 51, 20, 0, 231, 100, 92, 27, 789, 9] 為例進行從小到大排序的演示:
我們以陣列長度每次除2為間隔(step),上述陣列 n = 10,
第一次,step = 10/2 = 5
那么,會分成如下幾組:
(35, 100), (51, 92), (20, 27), (0, 789), (231, 9)
每組經過插入排序后,結果為:
(35, 100), (51, 92), (20, 27), (0, 789), (9, 231)
排序后的陣列為:
[35, 51, 20, 0, 9, 100, 92, 27, 789, 231]
第二次,step = 5/2 = 2
那么,會分成如下幾組:
(35, 20, 9, 92, 789), (51, 0, 100, 27, 231)
每組經過插入排序后,結果為:
(9, 20, 35, 92, 789), (0, 27, 51, 100, 231)
排序后的陣列為:
[9, 0, 20, 27, 35, 51, 92, 100, 789, 231]
第三次,step = 2/2 = 1
那么,整個陣列就是一個分組,直接進行插入排序了,排序后的結果為:
[0, 9, 20, 27, 35, 51, 92, 100, 231, 789]
3. 代碼實作
#include <iostream>
using namespace std;
void shellSort(int g[], int n) {
//每次排序間隔的步數
for(int step = n >> 1; step > 0; step = step >> 1) {
for(int i = step; i < n; ++i) {//對間隔為 step 的各個分組進行插入排序
if(g[i] < g[i-step]) {//小于分組中前一個元素的情況下才排序,否則已有序
int j = i;
int tmp = g[j];
while(j-step >= 0 && g[j] < g[j-step]) {
g[j] = g[j-step];
j -= step;
}
g[j] = tmp;
}
}
}
}
int main()
{
int n = 10;
int g[] = {35, 51, 20, 0, 231, 100, 92, 27, 789, 9};
shellSort(g, n);
for(int i = 0; i < n; ++i) {
cout<<g[i]<<" ";
}
cout<<endl;
return 0;
}4. 演算法復雜度
空間復雜度:在上述代碼中,沒有使用到額外的空間,空間復雜度為O(1),
時間復雜度:希爾排序的時間復雜度為O(n^(1.3 - 2)),
八、基數排序
1. 演算法思想
基數排序是一種比較容易理解的排序,是一種穩定的排序演算法,
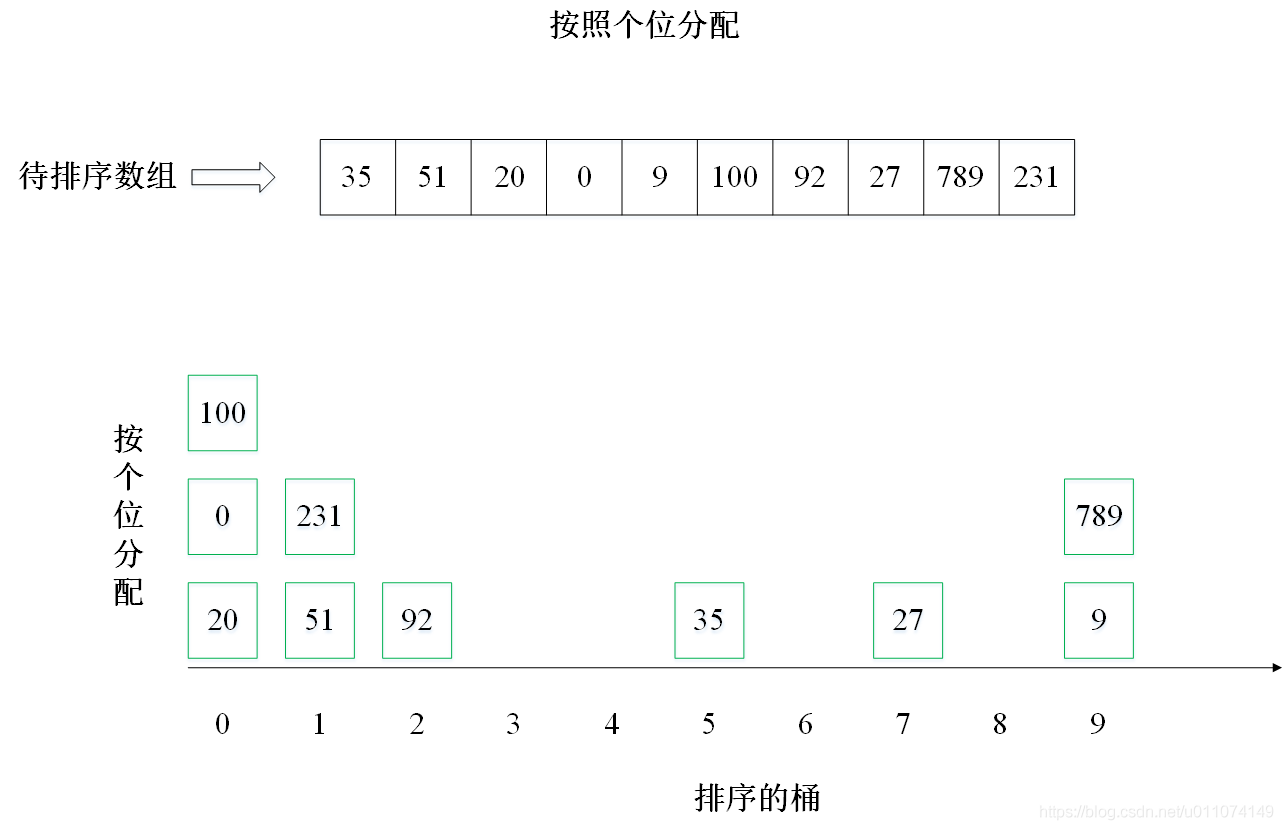
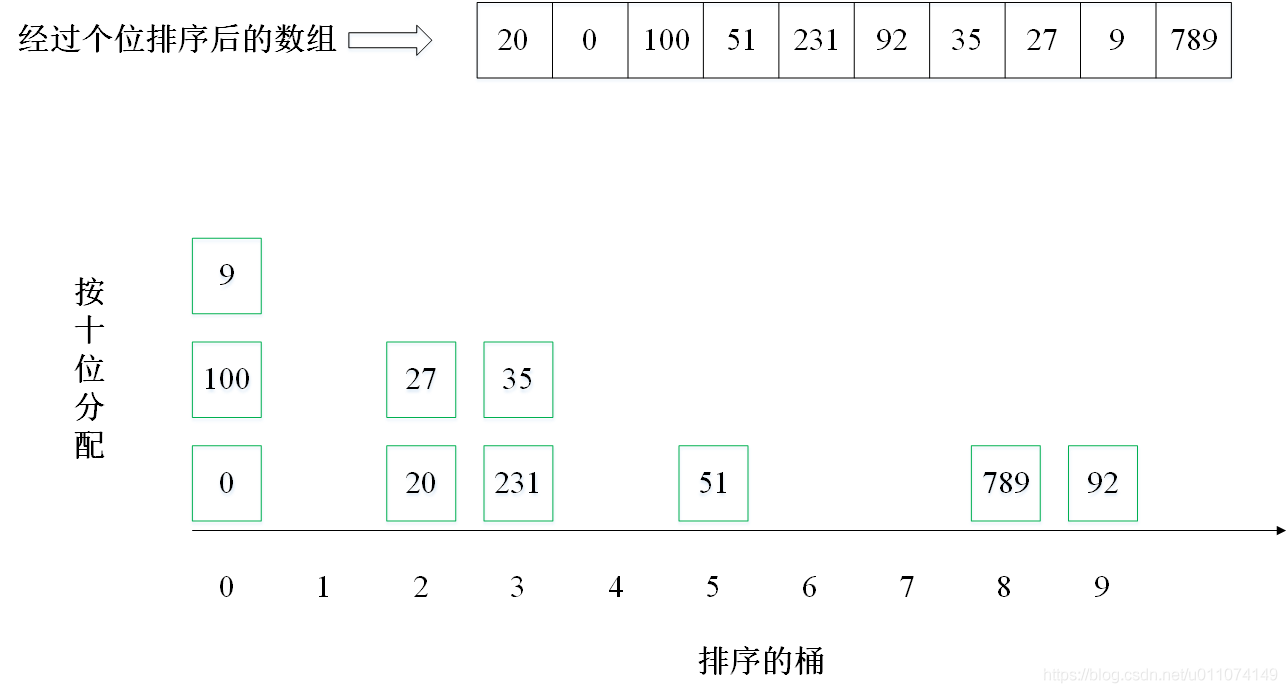
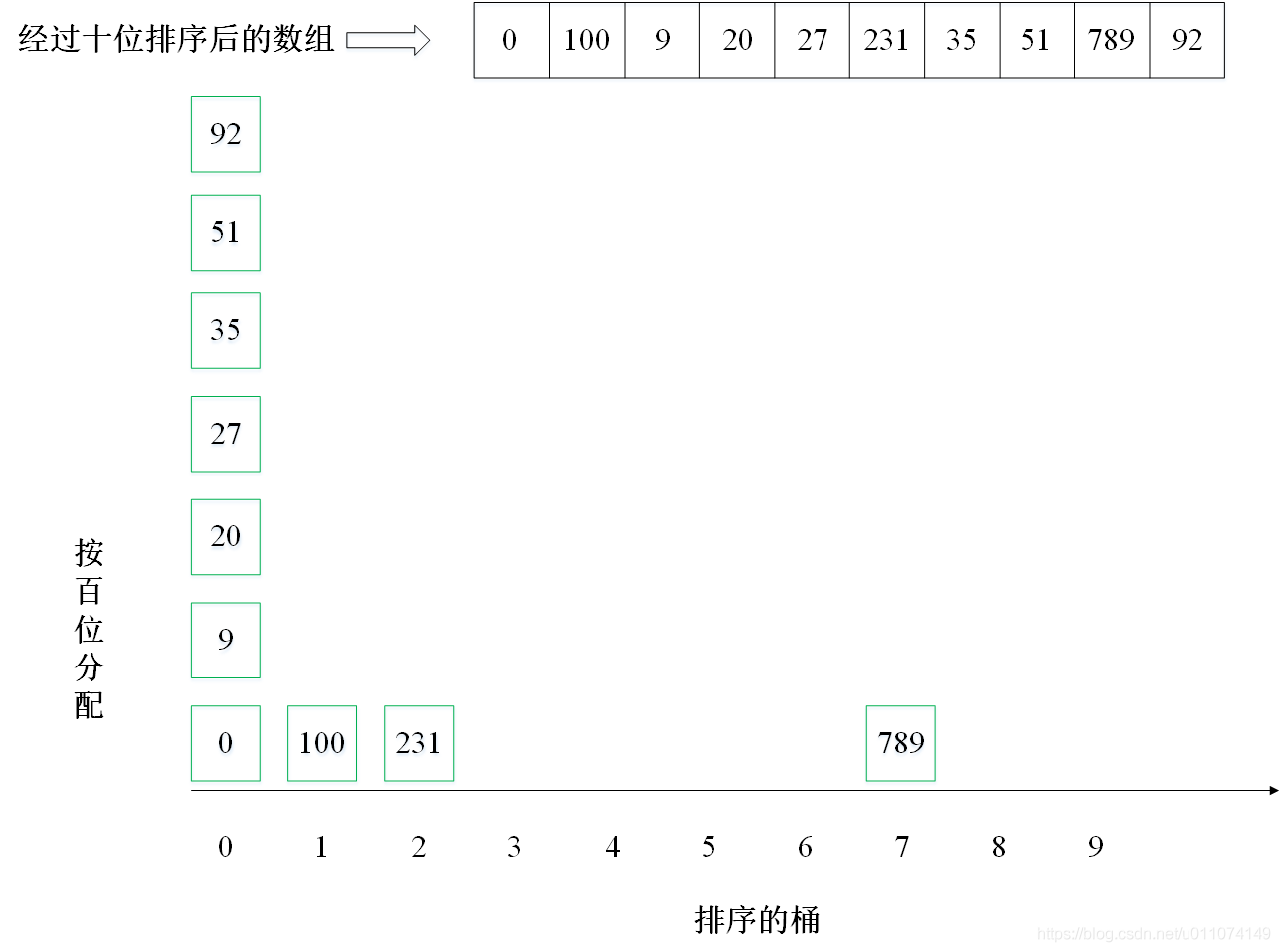
主要思想:按照數字的位數進行排序,即:先排個位,再排十位,再排百位……,有10個桶,標號為0~9,排序個位時,按照個位值的不同,分配到10個桶中(0分配到0號桶,1分配到1號桶,以此類推),然后將分配后的結果收集,這時候陣列是按照個位排序的,繼續按照十位重復上述排序程序,一直排序完所有的位數(取決于陣列中最大數的位數),
2. 實體演示
下面以陣列 [35, 51, 20, 0, 9, 100, 92, 27, 789, 231] 為例進行從小到大排序的演示:

3. 代碼實作
#include <iostream>
#include <vector>
using namespace std;
//求陣列中值的最大位數
int maxBit(int g[], int n)
{
//找出最大數
int maxVal = g[0];
for (int i = 1; i < n; ++i){
maxVal = max(maxVal, g[i]);
}
//計算最大數的位數
int num = 0;
while(maxVal) {
++num;
maxVal /= 10;
}
return num ? num : 1;
}
void radixSort(int g[], int n) //基數排序
{
int p = 1;
int d = maxBit(g, n);
vector<int>bucket[10];
for(int i = 0; i < d; ++i) {
//清空存盤值的桶
for(int j = 0; j < 10; j++) {
bucket[j].clear();
}
//將每個元素分到對應桶里
for(int j = 0; j < n; ++j) {
int k = (g[j]/p)%10;
bucket[k].push_back(g[j]);
}
//將桶里的數依次取出
int idx = 0;
for(int j = 0; j < 10; ++j) {
for(int k = 0; k < (int)bucket[j].size(); ++k) {
g[idx++] = bucket[j][k];
}
}
p *= 10;
}
}
int main()
{
int n = 10;
int g[] = {35, 51, 20, 0, 9, 100, 92, 27, 789, 231};
radixSort(g, n);
for(int i = 0; i < n; ++i) {
cout<<g[i]<<" ";
}
cout<<endl;
return 0;
}4. 演算法復雜度
空間復雜度:在上述代碼中,使用到了一個vector陣列來輔助排序,故空間復雜度為O(d+n);
時間復雜度:在上述代碼中,要遍歷最大位數 d(第一層 for 回圈),每次遍歷次數需要遍歷整個排序陣列,因為兩者是嵌套的關系,故總的時間復雜度為O(dn),
🎈 歡迎小伙伴們點贊👍、收藏?、留言💬
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/290922.html
標籤:其他
上一篇:C語言實作掃雷簡易版
下一篇:CSS加載影片效果