
-1. C++中通過基類指標分別指向基類物件以及派生類物件時,呼叫虛函式以及同名的普通函式的情況,
只有虛函式(非預設引數)才使用的是動態系結,其他的全部是靜態系結,
eg: BaseClass *p=new DerivedClass();
1. 靜態型別:指編譯時靜態系結的型別,比如上述指標,靜態型別就是左側BaseClass,
2. 動態型別:是運行階段動態系結的,比如上述指標的動態型別就是右側的型別DerivedClass,
在這里,涉及的知識點是系結問題,靜態系結和動態系結,
1)靜態系結:非virtual成員的系結是靜態的,外加預設成員函式的系結(該預設成員函式可以為virtual型別的),此時它呼叫的成員都是跟變數(指標)的靜態型別一致的,即根據物件的靜態型別選擇函式,
2)動態系結:即非預設函式的virtual的成員函式是動態系結的,呼叫它的指變數的動態型別決定了所呼叫的成員函式,
0. 基礎知識點:
C++中整個編譯的程序分為:
1)預處理階段:將頭檔案拷貝過來,將替換所有的宏,
2)編譯階段:詞法分析/語法分析/語意分析/中間代碼的生成/代碼的優化—>匯編程式
3)匯編階段:匯編程式–>機器語言
4)鏈接:目標代碼塊連接成可執行檔案(靜態/動態)
5)執行
@C++中的死回圈:
1)for回圈中判斷陳述句(S2)的缺失或者while回圈中判斷陳述句永遠為true,造成死回圈問題,
2)邏輯錯誤:比如在while回圈體或者for回圈體內部出現回圈變數賦值的問題,
for(int i=0;i<10;i++){
if(i=5){ //邏輯等==寫成了運算賦值符=
cout<<i<<endl;
}
}
3)無窮遞回造成的回圈:遞回一定要有遞回終止條件,如果沒有遞回終止條件只有遞回體,那么就會無窮的遞回,最終甚至會造成堆疊溢位,
4)假死回圈:看著是死回圈,但是由于某些性質,經過長時間之后會結束回圈,
eg:i=65535是最大值,
for(unsigned short int i=1;i!=0;i++){
cout<<i<<<endl;
}

0. 關于運行時錯誤和編譯錯誤的問題:
1)編譯錯誤:一般就是詞法錯誤、語法錯誤、語意錯誤,比如關鍵字錯誤、型別不匹配(int資料賦string型別的值),沒有逗號結尾等等,
2)運行時錯誤:可能是由于不夠仔細代碼撰寫或者輸入資料出問題,比如陣列下標訪問越界,除0錯,堆疊溢位,還有可能是由于程式復雜出現邏輯錯誤,使得程式執行結果出現問題,
1. 關于const和static以及普通的成員變數初始化的問題:
1)static是屬于類級別的,不是物件級別的變數,所以在類內是宣告,初始化只能放到類外進行(并且在類外不能加static關鍵字,類內宣告的時候加即可,)
2)const型別的成員變數只能直接初始化,不可以先宣告之后再賦值!所以可以在類內直接初始化或者通過建構式的初始化串列(加快效率)進行初始化,絕對不可以在類外(它屬于物件級別的變數),或者在建構式體內部進行二次賦值!
3)普通的成員變數可以在類內初始化或者在建構式內部或者初始化串列中進行初始化,但是一般為了效率可以選擇在初始化串列進行,比在建構式內部快,
2. 初始化串列涉及的問題以及多繼承實體化子類時建構式的執行順序問題:
1)對于初始化串列:如其名,初始化成員變數的串列,初始化!!!(就是宣告時立即開辟空間賦予初值),在這里初始化成員變數的順序跟初始化串列中賦值的順序完全無關,只跟類內部變數宣告的順序有關!!!!!!
2)多繼承實體化子類時建構式的執行順序問題:跟上面的問題一模一樣,跟你建構式初始化串列中給初始化父類成員的順序完全無關(父類建構式有參時,必須在子類建構式初始化串列內顯示傳參),跟子類繼承父類時宣告所繼承的父類的順序一樣!!!!!!
一般為了在時間和空間上同時節省資源,我們呼叫函式時使用參考傳遞,為了安全性考慮,還可以使用const型別的參考傳遞,方式參考修改變數值,
3. 會呼叫復制建構式(拷貝建構式)的情況
一定是用該型別的物件去初始化一個本型別的物件的時候(即用一個已存在的物件去初始化一個物件!)
1)A a(b);或者在初始化串列中這樣去初始化其他class型別的成員變數,
2)function test(A b); 作為實參會初始化形參(但是如果形參是參考型別的,就不會呼叫,此時形參只是別名而已!),
3)在函式內return A,此時A作為該函式內的區域變數,會在函式運行結束后自動呼叫解構式,所以在回傳值的時候會呼叫復制建構式用A初始化相同的一個物件回傳,
A Reuse(A a, A b) {
A A1;
A1.b= a.b + b.b;
return A1;
}
int main() {
int a = 10;
int b = 100;
A A1;
A A2;
A A3;
A3=Reuse(A1, A2);
return 0;
}
class A {
public:
int b = 10; //類內可以賦初值的有普通變數和常量!
public:
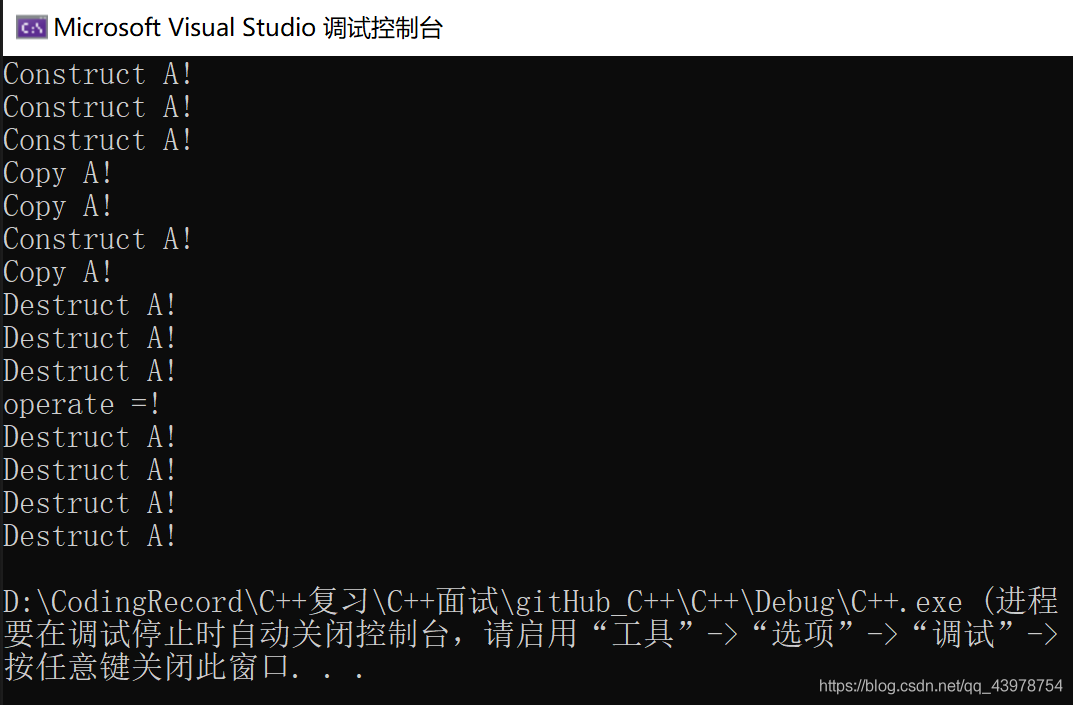
A(){ //注意,這是初始化串列,一個成員初始化只有一次!!!
cout << "Construct A!" << endl;
}
A(A& p){
b = p.b;
cout << "Copy A!" << endl;
}
~A() {
cout << "Destruct A!" << endl;
}
A& operator=(const A& p1) {
cout << "operate =!" << endl;
this->b = p1.b;
return *this;
}
};
3. 關于this指標的問題:
1)每個非靜態的成員函式中都有一個this指標,指向呼叫它們的物件,當一個物件呼叫它的非靜態成員函式時,會自動的將該物件的地址賦值給該成員函式的this指標,之后隱式的通過this指標去操作該物件的成員資料,
2)非靜態非const型別的成員函式:this指標式 ClassName* const this,即this指標是常量型別的,不可以更改this指標的值,
3)非靜態但是為const型別的成員函式:const ClassName* const this,即既是常量型別的指標又是指標型別的常量,既不能修改指標的值,又不能修改指標指向的物件(即const成員函式不可以修改成員函式的值,也不可以訪問非const型別的成員函式,因為非const型別的成員函式是有權限修改成員變數的),
4. 如何定義一個只能在堆上(堆疊上)生成物件的類?:
1)僅在堆上生成,那么就以為著系統不能進行自主的構造和析構在堆疊上實體化的物件,可以將類的解構式private化,每次系統想在堆疊上實體化一個物件前都會檢查該類的解構式是否可訪問,不可訪問就不行,
2)僅在堆疊上生成,那么就是不能通過new去產生一個物件,即不能夠直接呼叫該類的建構式,將建構式私有化,然后用單例模式的思想產生物件即可,
1. C++ 的STL中的vector/map/set中增刪元素對迭代器的影響?
(1)對于底層是連續存盤實作的vector來說,洗掉元素和插入元素都會使得當前迭代器以及之后的都失效,可以通過 erase(洗掉位置的指標) 回傳下一個資料的一個新的迭代器來繼續遍歷資料,插入元素失效的原因可以使因為push_back()操作使得vector容量不夠進行擴容,尋找了新的地址,也可能是因為insert操作使得當前以及之后的迭代器均無效,依照C++標準,插入和洗掉位置之后的迭代器是應該失效的,
#include<stdlib.h>
#include<iostream>
#include<vector>
using namespace std;
int main() {
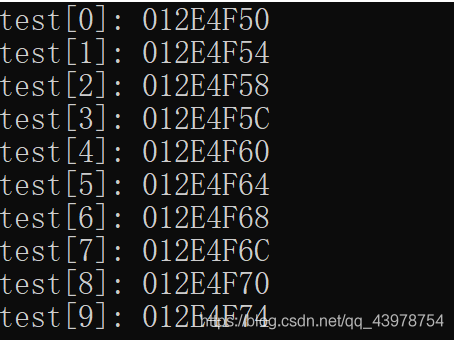
vector<int> test(10, -1);
for (int i = 0; i < test.size(); i++) {
cout << "test[" << i << "]: " << &test[i] << endl;
}
return 0;
}
(2)對于set和map這種底層是非連續的實作的(即非連續存盤結構),洗掉以及插入均只會使得當前迭代器失效,不會影響到后續的迭代器,
#include<stdlib.h>
#include<iostream>
#include<set>
using namespace std;
int main() {
set<int> test;
for (int i = 0; i < 10; i++) {
test.insert(i);
}
set<int>::iterator iter= test.begin();
for (; iter != test.end();) {
cout << *iter << endl;
test.erase(iter++); //再洗掉之前必須使得其自增指向下一個元素的迭代器,
}
cout << "test.length=" << test.size() << endl;
return 0;
}
1)map底層是用紅黑樹或者哈希表實作的,unordered_map是用哈希表實作的,當碰撞不多的時候查詢速度非常的,但是碰撞比較多的時候到O(n)了,將其換成紅黑樹存盤,雖然插入和洗掉的時間比較多,但是相比于沖突很多的HushMap而言,查詢的速度可以優化到O(logn),(頻繁插入和洗掉更適合unorder_map,頻繁檢索更適合map)
2)set的底層實作是紅黑樹(鏈式存盤),
2. New/Delete和malloc/free的區別?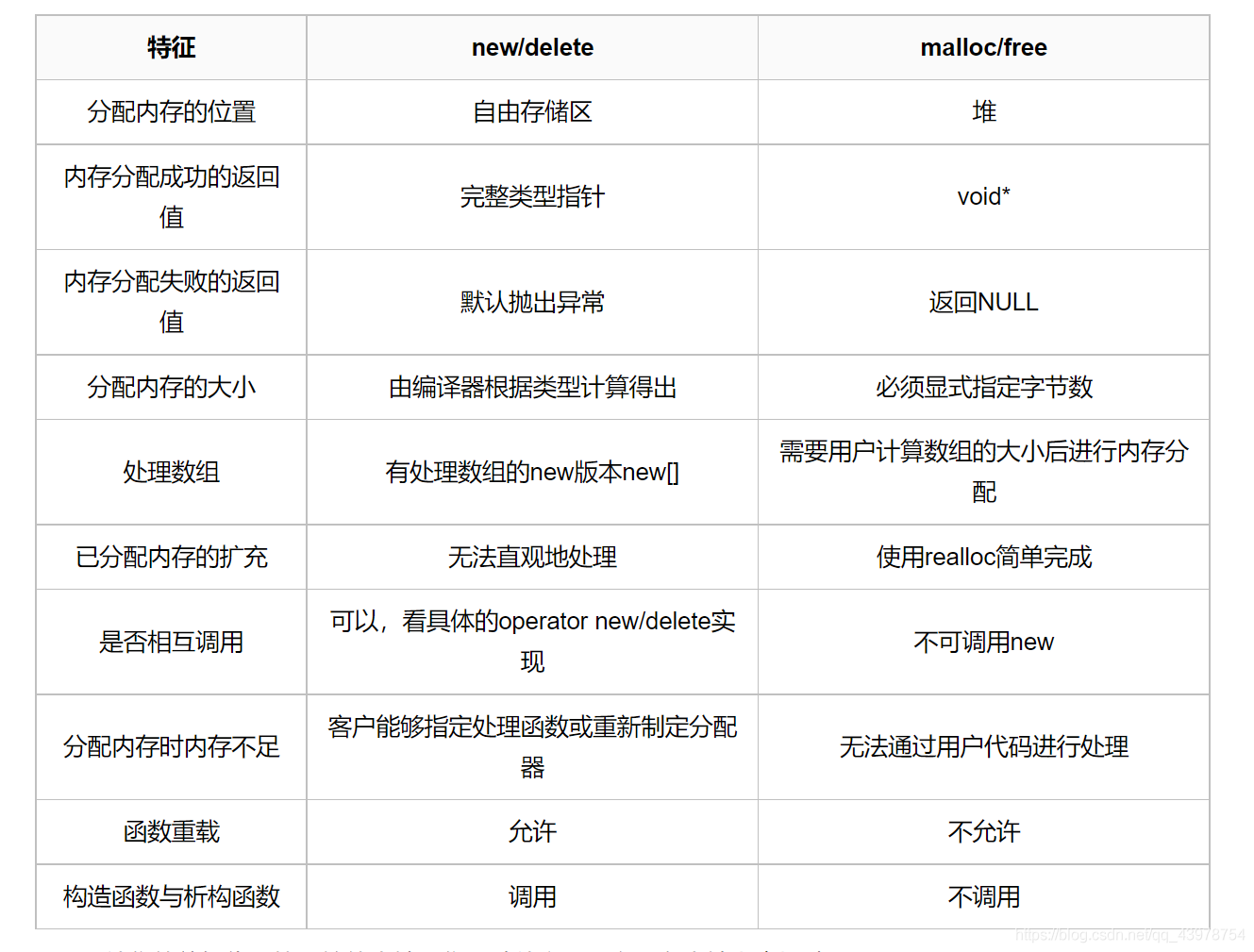
3. const和define的區別
(1)const
1. 編譯器預處理的方式不同:
define是在預處理階段展開的,const常量是在編譯運行的時候使用的,
2. 型別和安全性檢查不同:
define宏沒有型別,直接展開,const常量有具體的型別,在編譯的時期需要進行型別檢查,
3. 存盤的方式不同:
define宏僅僅之展開,有多少地方使用就展開多少次,不分配記憶體,
const常量會在記憶體的常量存盤區中為其分配記憶體,
4. 不能在類宣告中初始化const資料成員,const資料成員的初始化只能在類建構式的初始化表中進行,
5. const 可以節省空間,避免不必要的記憶體分配,const定義的常量在程式運行程序中只有一份拷貝,而#define定義的常量在記憶體中有若干個拷貝,
6. 提高了效率,編譯器通常不為普通const常量分配存盤空間,而是將它們保存在符號表中,這使得它成為一個編譯期間的常量,沒有了存盤與讀記憶體的操作,使得它的效率也很高,
提問:既然C++中有更好的const為什么還要使用宏?
答: const無法代替宏作為衛哨來防止檔案的重復包含,
4. override重寫和overload多載的區別
(1)override重寫和overload多載
1. override重寫:在虛函式+繼承的基礎上實作的,子類對父類虛函式的重寫(函式名、回傳值型別、引數數目、型別、順序完全一樣,只是對函式體內操作進行修改),實作了多型,基類函式必須是虛函式,具有virtual關鍵字,
2. overload多載:同一個類中的同名但具有不同數目的引數/引數型別不同/引數順序不同的成員函式,或者不是類的成員函式而是普通的具有不同數目引數、不同型別引數、不同順序引數的同名函式,函式多載不靠回傳值區分,C++在編譯階段就可以根據同名函式引數的不同為他們重新分配函式名,
(2)重寫可以改變訪問修飾符
新知識點:重寫可以改變訪問修飾符,也就是說基類虛函式是public型別的,子類重寫他的虛函式可以是private型別的,依舊可以實作多型,基類虛函式private型別,子類是public也行,沒有那么必須從高到低或者從低到高點的限制,但是自己測驗多型性的時候,肯定是 father*p=new son(),所以如果基類的虛函式是private型別的,該指標將無法直接訪問到,但是可以通過基類的其他public的成員函式去呼叫,依舊可以實作多型,
class A {
private:
int x;
virtual void print() {
cout << "Father_print()" << endl;
}
public:
A(int x);
A(A& p);
~A();
int getX();
A operator+(A temp);
void test() {
print();
}
};
class B :public A{
public:
B():A(10){
}
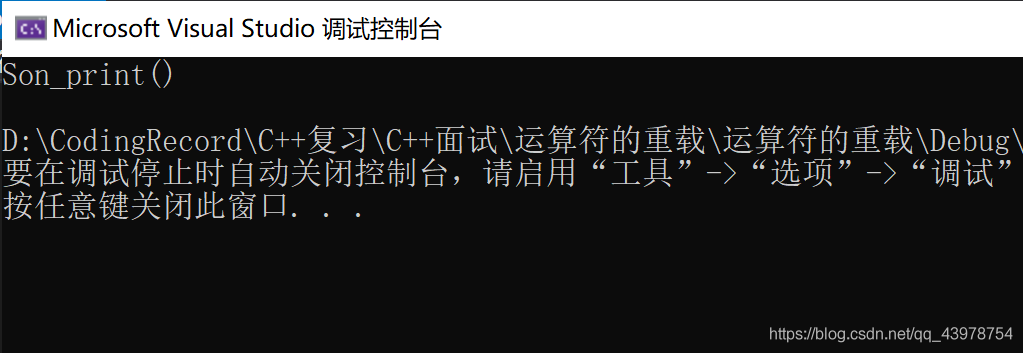
void print() {
cout << "Son_print()" << endl;
}
};
int main() {
A* a = new B();
a->test();
return 0;
}
5. 堆和堆疊的區別?
(1)管理的方式
1. 堆上存放的資料是用戶動態申請的資料,需要用戶手動去釋放空間,否則容易造成內訓泄漏,比如new/malloc.
2. 堆疊上存放的是區域變數以及形參等資料,編譯器自動管理,不需要用戶操作,
(2)空間大小(堆疊要比堆小很多,所以演算法題資料量很大的時候要注意)
1. 堆:對于32位的系統來說,堆存盤空間可以接近4G,從這個角度來看堆記憶體幾乎沒有什么限制,
2. 堆疊:一般都有一定的空間大小,例如在VC6下面,默認的堆疊空間的大小約是1M,
(3)碎片問題
1. 堆由于長期進行new/delete以及malloc/free操作勢必會造成記憶體空間的不連續,會造成大量的碎片,使得程式效率低下,
2. 對于堆疊而言,是編譯器進行空間的管理(分配與回收),而且堆疊是一后進先出的線性表,永遠都不會有一個記憶體塊從中間彈出,所以碎片少,
(4)生長方向
1. 對于堆來講,生長方向是向上的,也就是向著記憶體地址增加的方向,
2. 對于堆疊來講,它的生長方向是向下的,是向著記憶體地址減小的方向增長,
(5)分配方式
1. 堆都是動態分配的,沒有靜態分配的堆,
2. 堆疊有2 種分配方式:靜態分配和動態分配,靜態分配是編譯器完成的,比如區域變數的分配,動態分配由alloca 函式進行分配,但是堆疊的動態分配和堆是不同的,它的動態分配是由編譯器進行釋放,不需要我們手工實作,
(6)分配效率
1. 堆疊是機器系統提供的資料結構,計算機會在底層分配專門的暫存器存放堆疊的地址,壓堆疊出堆疊都有專門的指令執行,這就決定了堆疊的效率比較高,
2. 堆則是C/C++函式庫提供的,它的機制是很復雜的,例如為了分配一塊記憶體,庫函式會按照一定的演算法(具體的演算法可以參考資料結構/作業系統)在堆記憶體中搜索可用的足夠大小的空間,如果沒有足夠大小的空間(可能是由于記憶體碎片太多),就有可能呼叫系統功能去增加程式資料段的記憶體空間,然后進行回傳,顯然,堆的效率比堆疊要低得多,
6. C++中的Static用法
(1)全域的static變數
1. 存盤在全域/靜態資料區,在編譯階段初始化,初始化的時候可以賦初值,如果沒賦初值,系統會自動為它賦予一個初值,比如int型的就是0,
2. 程式運行結束后系統自動進行釋放,
3. 在整個檔案都是可見的,但在檔案之外是不可見的,
(2)區域的static變數(普通函式內部定義的)
1. 存盤在全域/靜態資料區,但是擁有的是區域的作用域,出了函式就不可見了,在程式的運行程序中,它始終存盤在全域/靜態資料區中,直到程式結束,系統進行釋放位置,
2. 在第一次運行擁有它的函式時進行初始化,此時如果沒有賦予初值,系統會自動賦予其一個初值,在之后再次呼叫該程式將不會再次初始化,直接操作的是全域/靜態存盤區中該值,
(3)static函式
定義靜態函式的好處:
? 靜態函式不能被其它檔案所用;,
? 其它檔案中可以定義相同名字的函式,不會發生沖突,
(4)static成員變數
1. 存盤在全域的資料區,類中每個實體化的物件都共享這一個資料,即它只分配一次記憶體供該類所有物件使用,
2. 可以通過 類名::靜態資料成員 或者 通過 實體化的物件名.靜態資料成員 訪問,
3. 在定義的時候分配記憶體空間,所以不能再類宣告中定義,
4. 在沒有產生類實體化物件的時候就可以通過類名進行訪問,
5. ? 同全域變數相比,使用靜態資料成員有兩個優勢:
1) 靜態資料成員沒有進入程式的全域名字空間,因此不存在與程式中其它全域名字沖突的可能性;
2) 可以實作資訊隱藏,靜態資料成員可以是private成員,而全域變數不能;
(5)static成員函式
1. 在類外定義時,不能夠使用static關鍵字,
2. 可以訪問靜態成員(變數、函式),但是不能訪問其他的成員變數和成員函式,
3. 由于沒有this指標的額外開銷,因此靜態成員函式與類的全域函式相比速度上會有少許的增長,
4. 呼叫靜態成員函式可以通過 類名::靜態成員函式 或者 通過 實體化的物件名.靜態成員函式 ,
7. 子類、父類中的名稱遮掩,如何避免?
1. 子類可以呼叫父類的同名函式,通過 父類名::父類成員函式(前提是可以訪問到),
2. 通過子類的實體化物件也可以呼叫,子類實體化物件.父類名::父類成員函式
8. 深拷貝,淺拷貝?
涉及到指標的時候,淺拷貝就是直接指標賦值,兩個指標會指向同一個地址,那么一旦一個物件對指標指向的地址進行更改,對另一個物件而言,也會產生變動,深拷貝就是新生成一個指標,將copy物件指標指向的位置內的資料賦值給新生成的指標指向的物件,
淺拷貝和深拷貝主要區別就是復制指標時是否重新創建記憶體空間,
1)如果沒有沒有創建記憶體只賦值地址為淺拷貝,創建新記憶體把值全部拷貝一份就是深拷貝,
2)淺拷貝在類里面有指標成員的情況下只會復制指標的地址,會導致兩個成員指標指向同一塊記憶體,這樣在要是分別delete釋放時就會出現問題,因此需要用深拷貝,
9.新知識點:C++中的struct和class
C++中的struct和class最大的區別就是默認的訪問訪問權限不同,class默認private,但是struct默認public,
1. 他們兩個都支持繼承、多型、都能包含資料和方法,
2. 但是 “class”這個關鍵字還用于定義模板參 數,就像“typename”,但關鍵字“struct”不用于定義模板引數,
3. C++中的struct和class最大的區別就是默認的訪問訪問權限不同,class默認private,但是struct默認public,
4. 說實話,除了上述兩個不同之外,其他的幾乎一模一樣,但是還是想說,struct中的資料還是不會稱之為成員,他本質還是一個復雜的資料結構,而我們的類就是一個封裝的思想,
5. 甚至class可以繼承struct,struct也可以繼承class,默認繼承的權限取決于子類,子類是class,那么就是private默認繼承,子類是struct,那么就是public默認繼承,
class test {
public:
int m, n;
public:
test(int m,int n) {
this->m = m;
this->n = n;
}
test(test& p) {
m = p.m;
n = p.n;
}
~test() {
}
virtual void print() {
cout << "class_test" << endl;
}
};
struct student: test {
int x;
int y;
public:
student(int x, int y):test(x,y) {
this->x = x;
this->y = y;
}
student(student& p):test(p.m,p.n) {
x = p.x;
y = p.y;
}
~student() {
}
private:
int max();
void print() {
cout << "struct_student" << endl;
}
};
int student::max() {
return x > y ? x : y;
}
int main() {
test* a = new struct student(10, 20);
a->print();
return 0;
}

10.指標和參考的區別?
1. 本質:
?指標:它是一個變數,保存地址,可以為NULL,非const型別的指標的值可以進行改變,
?參考:是一個變數的別名,必須在宣告的時候初始化,系結物件,且后續不能改變這個系結,
2. sizeof()值的區別:
?sizeof(指標)是這個指標本身的大小,32位機就是4,64位機就是8,
?sizeof(參考)是系結的原來的資料型別的大小,
3. const常指標和常參考
指標有指標常量和常量指標:const int* p為 常量指標,指向常量的指標,指標的指向可以變化,但是不可以通過指標更改所指向的資料的值,
4. 作為函式引數進行傳遞時的區別:
?指標作為函式引數傳遞時,函式內部的指標形參是指標實參的一個副本,改變指標形參并不能改變指標實參的值,通過解參考*運算子來更改指標所指向的記憶體單元里的資料,
?參考在作為函式引數進行傳遞時,實質上傳遞的是實參本身,即傳遞進來的不是實參的一個拷貝,因此對形參的修改其實是對實參的修改,所以在用參考進行引數傳遞時,不僅節約時間,而且可以節約空間,
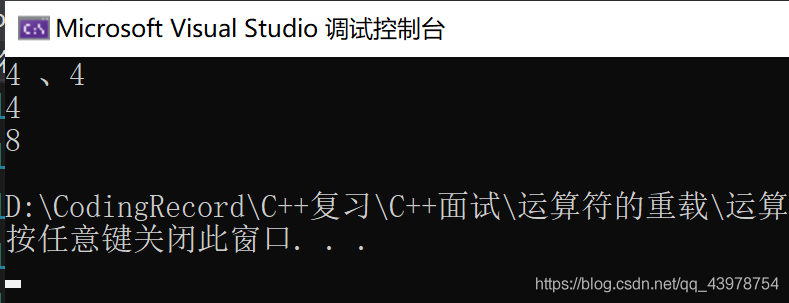
int main() {
int b = 10;
int* a =& b;
int& c = b;
cout << sizeof(a) << " 、" << sizeof(c) << endl;
double m = 10;
double* n = &m;
cout << sizeof(n) << endl;
cout << sizeof(m) << endl;
return 0;
}
11. C++中的強制型別轉換
C++不是型別安全型的,兩個不同型別的指標之間可以進行強制型別轉換(reinterfret_cast)
(1)static_cast:可以在不同的基本型別之間、具有繼承關系的兩個類之間、不同型別的類指標之間進行轉化,(但是基本型別的指標之間不可以!!!)
1)進行上行轉換(把子類的指標或參考轉換成基類表示)是安全的;
進行下行轉換(把基類指標或參考轉換成子類表示)時,由于沒有動態型別檢查,所以是不安全的,
2)在編譯期強制轉換,
#include<stdlib.h>
#include<iostream>
#include<string>
using namespace std;
class A {
private:
int a;
public:
A(int a) {
this->a = a;
}
virtual void print() {
cout << "father_A_print()" << endl;
}
void test() {
cout << "father_A: a= " << a << endl;
}
};
class B:public A {
private:
int b;
public:
B(int a,int b):A(a) {
this->b = b;
}
void print() {
cout << "son_B_print()" << endl;
}
void test() {
cout << "son_B: b= " << b << endl;
}
};
int main(){
//static_cast:用于基本型別之間、有繼承關系的類之間、類指標之間的轉換,
//不能用于基本型別指標之間的轉換,
int a = 10;
int* pa = &a;
double b = 100.98;
double* pb = &b;
//pa = static_cast<int*>(pb); error
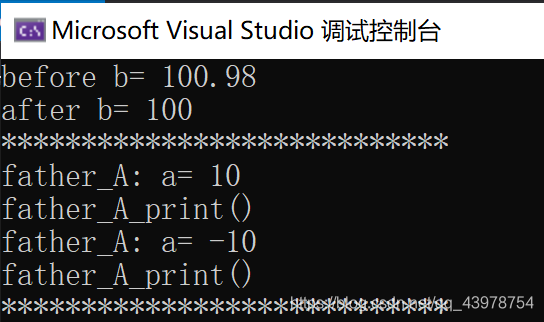
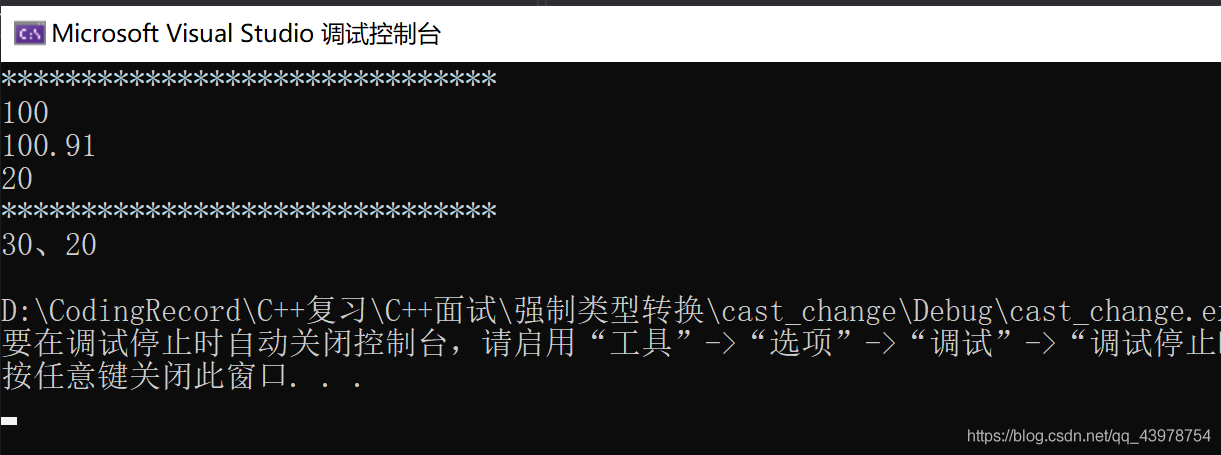
cout << "before b= " << b << endl;
a = static_cast<int> (b);
cout << "after b= " << a << endl;
A a1(10);
B b1(-10, 20);
A* pa1 = new A(1);
B* pb1 = new B(-1,-2);
cout << "****************************" << endl;
a1.test();
a1.print(); //輸出的a的值是10.
a1 = static_cast<A>(b1); //可以從子類到父類,但是不可以從父類到子類!
a1.test();
a1.print(); //輸出的a的值是-10.
cout << "****************************" << endl;
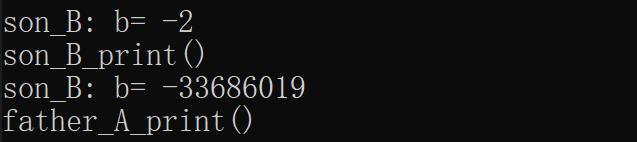
pb1->test();
pb1->print();
pb1 = static_cast<B*>(pa1); //指標的話父到子類、子類到父類都可以!
pb1->test();
pb1->print();
cout << "****************************" << endl;
pa1->test(); //是滿足多型性的
pa1->print();
pa1 = static_cast<A*>(pb1);
pa1->test();
pa1->print(); //是滿足多型性的!
return 0;
}

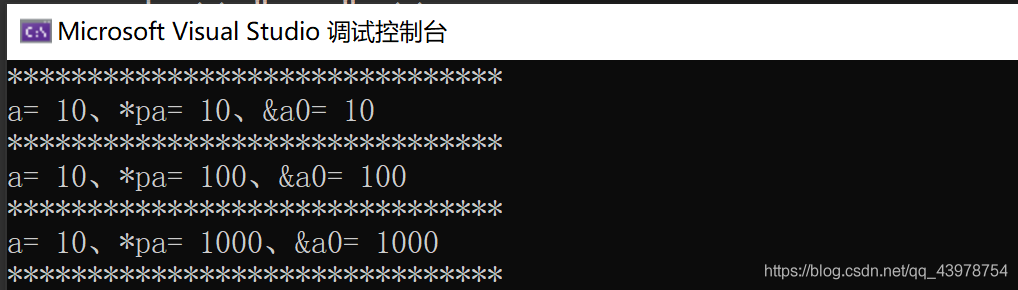
(2)const_cast:用于去除變數的只讀特性,用于指標之間以及參考之間型別的轉換,但是注意,不能更改基礎型別,只能調節型別限定符,
不能更改基礎型別,只能調節型別限定符,
cout <<"before: b0=" << b0 << endl;
//a0 = const_cast<int&>(b0); error,不能更改基礎型別,只能調節型別限定符,
b0 = const_cast<int&>(a0);
cout << "after: b0=" << b0 << endl;
//const_cast: 用于去除變數的只讀特性,用于指標之間以及參考之間型別的轉換,
const int a = 10;
int* pa = const_cast<int*>(&a);
int& a0 = const_cast<int&>(a);
cout << "*******************************" << endl;
cout << "a= " << a ;
cout<<"、*pa= " << *pa;
cout << "、&a0= " << a0 << endl;
cout << "*******************************" << endl;
*pa = 100;
cout << "a= " << a;
cout << "、*pa= " << *pa;
cout << "、&a0= " << a0 << endl;
cout << "*******************************" << endl;
a0 = 1000;
cout << "a= " << a;
cout << "、*pa= " << *pa;
cout << "、&a0= " << a0 << endl;
cout << "*******************************" << endl;
(3)reinterpret_cast:用于指標型別之間,整數和指標型別之間的轉換,(基本型別之間不可以!)
(4)dynamic_cast:用于有繼承關系的類指標之間、有交叉關系的類指標之間的轉換、具有型別檢查的功能、需要虛函式的支持
作用:用于將一個父類的指標或參考轉化為子類的指標或參考(安全的向下轉型)
1. 基類指標所指物件是派生類物件,這種轉換是安全的;
2. 基類指標所指物件為基類物件,轉換失敗,回傳結果為0,
class Base
{
public:
Base() {};
virtual void show() { cout << "Base\n"; }
};
class Derive :public Base
{
public:
Derive() {};
virtual void show() { cout << "Derive\n"; }
};
int main()
{
Base* base = new Derive;
if (Derive * ptr1 = dynamic_cast<Derive*>(base))
{
cout << "轉換成功" << endl; //執行
ptr1->show();
cout << endl;
}
base = new Base;
if (Derive * ptr2 = dynamic_cast<Derive*>(base))
{
cout << "轉換成功" << endl;
ptr2->show();
cout << endl;
}
else
{
cout << "轉換失敗" << endl; //執行
}
delete(base);
return 0;
}
12. 當一個類A 中沒有聲命任何成員變數與成員函式這時sizeof(A)的值是多少,如果不是零,請解釋一下編譯器為什么沒有讓它為零,
肯定不是零,舉個反例,如果是零的話,宣告一個class A[10]物件陣列,而每一個物件占用的空間是零,這時就沒辦法區分A[0],A[1]…了,所以,通常是1,用作占位的,為了確保不同物件有不同的地址,
class test {
};
int main(){
cout << sizeof(test) << endl;
return 0;
}

13. 為什么行內函式,建構式,靜態成員函式不能為virtual函式?
(1)行內函式inline
因為inline函式是在編譯時期展開的,但是虛函式是在運行時期動態編譯系結的,所以兩者定義矛盾,不能將inline行內函式定義為虛函式,
(2)建構式
1. 建構式是用來創建一個物件,而虛函式的運行是在一個物件之上,當物件還不存在的時候是沒法運行虛函式的,所以如果建構式是虛函式的話,那么建構式將無法運行,
2. 當實體化一個物件執行建構式時,會為該物件初始化一個指向虛函式表的虛表指標vptr,當建構式未執行時,虛表指標尚未初始化,那么是無法執行建構式的,
(3)靜態成員函式
1. 靜態成員函式是在編譯時期就系結的,屬于這個類,可以直接通過類去呼叫靜態成員函式而不必實體化物件去呼叫,但是虛函式是運行時期動態編譯的,是通過實體化物件中生成的vptr指標指向的虛函式表呼叫的,但是靜態成員函式中是沒有this指標的,所以沒法呼叫,
2. 對于靜態成員函式,它沒有this指標,所以無法訪問vptr. 這就是為何static函式不能為virtual,
14. 建構式和解構式為什么沒有回傳值?
1. 安全性方面:如果建構式和解構式帶有回傳值的話,那么編譯器必須制定如何處理回傳值,或者由程式員去顯示的呼叫建構式和解構式,這樣一來,安全性就被人破壞了,
2. 在程式中創建和消除一個物件的行為非常特殊,就像出生和死亡,而且總是由編譯器來呼叫這些函式以確保它們被執行,
15. 函式模板與類模板的區別?
函式模板的實體化可以由編譯階段自處理函式時自動完成,
但是類模板必須由程式員在程式中顯示的指示,
template<class T>
T Max(T a, T b) {
return a > b ? a : b;
}
//可以隱式呼叫,編譯程式在處理函式呼叫時自動完成的,
cout << Max(a1, b1) << endl;
//也可以顯示的呼叫,自己在程式中指出型別,
cout << Max<double>(10.0,20.0) << endl;
template<class T>
class test_template {
private:
T a;
T b;
public:
test_template(T a,T b) {
this->a = a;
this->b = b;
}
T add() {
return a + b;
}
T max() {
return a > b ? a : b;
}
};
int main(){
test_template<int> p(10, 20);
}
16. 基類的解構式不是虛函式,會帶來什么問題?
如果存在基類的指標指向new出來的子類的物件,那么會使得后期呼叫delete去析構該指標所指向的空間時,只會呼叫基類的解構式,而不會呼叫子類的虛構函式(因為基類的解構式不是virtual型別的,所以不會有多型性),使得子類開辟的空間不會被回收,可能產生記憶體泄露問題,
17. 建構式可以呼叫虛函式嗎?語法上通過嗎?語意上可以通過嗎?
建構式可以呼叫虛函式,語法上通過,語意上也通過,但是該虛函式不會具有多型性,而是會被當成一個普通成員函式呼叫,所以呼叫的只能是基類的,
呼叫當然是沒有問題的但多型這個功能被屏蔽了,
首先,建構式的執行是通過實體化物件中的虛表指標vptr執行的,當我們宣告一個基類的指標指向new出的父類的物件時:
father *p=new son(); 首先會呼叫父類的建構式,此時該物件的vptr指向的是父類的虛函式表,并且此時并未呼叫子類的建構式,C++為了防止vptr訪問未初始化的資料,所以限定在建構式中呼叫的虛函式不具備多型性,此時呼叫的就是父類的虛函式,
18. 解構式可以拋出例外嗎?為什么不能拋出例外?會造成什么問題?
解構式不可以拋出例外,如果解構式執行程序中在某點拋出例外沒那么在該點之后如果存在資源的釋放將不會執行,會造成資源的泄漏問你,
通常例外發生時,c++的機制會呼叫已經構造物件的解構式來釋放資源,此時若解構式本身也拋出例外,則前一個例外尚未處理,又有新的例外,會造成程式崩潰的問題,
解構式中拋出例外導致程式不明原因的崩潰是許多系統的致命內傷,
解決辦法:那就是把例外完全封裝在解構式內部,決不讓例外拋出函式之外,如使用Try{ }Catch{這里可以什么都不做,只是保證catch塊的程式拋出的例外不會被扔出解構式之外,}
19. 虛函式與純虛函式區別?
1. 含有純虛函式的類是抽象類,不可以實體化物件,
2. 虛函式必須給出實作,但是純虛函式沒有實作體,宣告之后就是=0,
3. 定義純虛函式沒有實作,表示的是一個規范的介面,繼承抽象類的子類中必須實作抽象類中的所有純虛函式,
4. 虛函式和純虛函式都可以在子類(sub class)中被多載,以多型的形式被呼叫
20. 如何減少頻繁分配記憶體(malloc或者new)造成的記憶體碎片?
記憶體池(Memory Pool)是一種記憶體分配方式, 通常我們習慣直接使用new、malloc等API申請分配記憶體,這樣做的缺點在于:由于所申請記憶體塊的大小不定,當頻繁使用時會造成大量的記憶體碎片并進而降低性能,記憶體池則是在真正使用記憶體之前,先申請分配一定數量的、大小相等(一般情況下)的記憶體塊留作備用,
當有新的記憶體需求時,就從記憶體池中分出一部分記憶體塊,若記憶體塊不夠再繼續申請新的記憶體,這樣做的一個顯著優點是盡量避免了記憶體碎片,使得記憶體分配效率得到提升,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/291528.html
標籤:其他
下一篇:關于git簡單的使用(碼云篇)