文章目錄
- 運算子
- 分類
- 算術運算子
- 移位運算子
- 整數存盤規則
- 左右移位規則
- 補充:
- 位運算子
- 運算規則
- 計算方法
- 注意
- 例題
- 用處
- 賦值運算子
- 單目運算子
- 邏輯反操作!
- 取地址運算子& 解參考運算子*
- 型別長度運算子`sizeof`
- 按位取反運算子~
- `++` `--` 運算子
- 強制型別轉換運算子(type)
- 例題
- 關系運算子=
- 邏輯運算子
- 例題
- 條件運算子
- 逗號運算式
- 下標參考、函式呼叫和結構成員
- 下標參考運算子`[]`
- 函式呼叫運算子`()`
- 結構成員運算子`.` `->`
- 運算式求值
- 隱式型別轉換
- 整型提升
- 如何整型提升
- 例題
- 算術轉換
- 運算子的屬性
- 總結
運算子
分類
算術運算子
移位運算子
位運算子
賦值運算子
單目運算子
關系運算子
邏輯運算子
條件運算子
逗號運算式
下標參考、函式呼叫和結構成員
算術運算子
+ - * / %
//1.
int ret = 9 / 2;
printf("%d", ret);//4
//2.
double ret2 = 9 / 2;
printf("%lf", ret2);//4.000000
//3.
double ret3 = 9 / 2.0;
printf("%lf", ret3);//4.500000
從這兩個對比可以看出,不是存盤的問題,而是計算機里9/2就是等于4,怎么存都是4,
要想得到正確結果,則要改成9.0/2或者9/2.0,
/的兩個運算元都為整數時,執行整數除法,只要有浮點數就執行浮點數除法,%的兩個運算元必須為整數,所得結果的范圍在 [ 0 , 除 數 ? 1 ] [0, 除數-1] [0,除數?1] 之間,
接下來的移位運算子和位運算子都是較為復雜的,涉及到二進制位,
移位運算子
<< //左移運算子
>> //右移運算子
整數存盤規則
移位運算子移動的是二進制位,整數在記憶體中存盤的是二進制補碼,移位操作的也是記憶體中的補碼,
整數在記憶體中的存盤:
- 正數:
- 原碼反碼補碼相同
- 負數:
- 原碼:二進制序列
- 反碼:原碼符號位不變,其他位按位取反
- 補碼:反碼 + 1 +1 +1
左右移位規則
知道二進制位如何轉化后,我們再來看移位運算子的移動規則,
- 左移運算子
左邊舍棄,右邊補0

int a = 5;
int b = a << 1;
a<<1的意思就是a的補碼向左移動一位,正數的原反補相同,所以得補碼為00000000 00000000 00000000 00000101 ,向左移動一位得00000000 00000000 00000000 00001010,換算一下就可得到10,
此時a的值還是5,可以類比b=a+1,a并不會發生變化,
int c = -1;
int d = c << 1;
先寫出 -1的原碼,再取反加一得補碼,補碼向左移動一位,然后將得到的補碼按相同規則換算成原碼,就可以得到 -2了,
10000000 00000000 00000000 00000001 - -1的原碼
11111111 11111111 11111111 11111110 - -1的反碼
11111111 11111111 11111111 11111111 - -1的補碼
11111111 11111111 11111111 11111110 - -1<<1的補碼
11111111 11111111 11111111 11111101 - 反碼
10000000 00000000 00000000 00000010 - 原碼 = -2
-
右移運算子
右移規則分兩種,一種是邏輯右移一種是算術右移,但絕大多數編譯器都是采用算術右移,
算術右移:左邊補原符號位,右邊舍棄
邏輯右移:左邊補0,右邊舍棄
int a = -1;
printf("%d\n", a >> 1);
//10000000 00000000 00000000 00000001 - 原碼
//11111111 11111111 11111111 11111110 - 反碼
//11111111 11111111 11111111 11111111 - 補碼
//11111111 11111111 11111111 11111111 - 補碼
邏輯右移會把負數搞成整數,所以算術右移顯得更正確一些,
值得一提的是,-1的補碼右移一位后仍是-1,
補充:
- 不難發現左移使資料變大,右移使資料變小,左移就是資料 × 2 ×2 ×2,右移即資料 ÷ 2 ÷2 ÷2 ,
- 左移右移運算元必須為整數,
- 移位運算子不可移動負數位,即
1>>-1,標準未定義行為,
位運算子
& //按位與
| //按位或
^ //按位異或
同樣位運算子也是按二進制位,
運算規則
按位與 &
全1則1,有0則0
按位或 |
有1則1,全0則0
按位異或 ^
相同為0,相異為1
通過運算規則可以看出,按位與和按位或和邏輯與、邏輯或還是有異曲同工之妙的,
int a = 3;
int b = -2;
int c = a & b;
//1.求a的補碼
100000000 000000000 000000000 000000010 - -2的原碼
111111111 111111111 111111111 111111101 - -2的反碼
111111111 111111111 111111111 111111110 - -2的補碼
//2.求b的補碼
000000000 000000000 000000000 000000011 - 3的原反補相同!!
//3.求a & b
111111111 111111111 111111111 111111110 - -2的補碼
000000000 000000000 000000000 000000011 - 3的補碼
000000000 000000000 000000000 000000010 - 所得數的補碼!! (全1為1,有0則0)
//4.轉化為原碼
000000000 000000000 000000000 000000010 - 正數的原反補相同
計算方法
- 求兩運算元的補碼
- 計算按位與、或、異或的結果
- 將所得補碼轉換成原碼
將a和b的補碼求出來,然后再按位與、或,得到所得數的補碼,再轉換成原碼,這幾步很繞人,前往別被帶溝里了,其他兩個除了運算規則不一樣外,其他都一樣,
注意
- 整數的原反補相同,可別照負數的規范求,
- 按位與、按位或的結果同樣是補碼,最后還需轉換成原碼,
例題
不創建臨時變數,實作兩數交換,
int a = 10;
int b = 20;
printf("a=%d,b=%d\n", a, b);
//1.
a = a + b;
b = a - b;//(a+b)-b = a
a = a - b;//(a+b)-a = b
printf("a=%d,b=%d\n", a, b);
//溢位風險
//2.
a = a ^ b;
b = a ^ b;//(a ^ b) ^ b = a
a = a ^ b;//(a ^ b) ^ a = b
//可讀性差,只支持正數
a^b的值再和a異或,則得到b;a^b的值再和b異或,則得到a,a ^ a = 0a ^ 0 = a(a ^ a) ^ b = b(a ^ b) ^ a = b,由此也可以說異或支持交換律
用處
給出一個正整數,想知道其(如果是負數的話,就是補碼)二進制位最低位是0是1,怎么辦?
將這個正整數按位與1,如果所得結果為1則最低位為1,反之則為0,如:
int a = 15;
int b = a & 1;
00000000 00000000 00000000 00001111 - 15原反補相同
00000000 00000000 00000000 00000001 - 1
00000000 00000000 00000000 00000001 - b=1原反補相同
從這個例子可以看出某個正數&1,所得結果為1則最低位為1,反之則為0,如果搭配上>>右移運算子,可以得到每一位的數字, 如:
int num = 15;
int count = 0;
for (int i = 0; i < 32; i++)
{
if (((num >> i) & 1) == 1){
count++;
}
}
printf("%d\n", count);
賦值運算子
=
//復合賦值符
+= -= *= /= %= >>= <<=
賦值運算子沒什么講頭,我們來看看一些奇葩的東西,
int a = 10;
int x = 0;
int y = 20;
a = x = y+1;//連續賦值
如何理解這個連續賦值呢?
先是把y+1賦值給了x,再把運算式x=y+1的值賦值給了a ,
單目運算子
! //邏輯反操作
- //取負
+ //取正
& //取地址
sizeof //運算元的型別長度
~ //按位取反
-- //前后置——
++ //前后置++
* //解參考運算子
(type) //強制型別轉換
邏輯反操作!
非零即為真,零為假,默認規定 !0=1
取地址運算子& 解參考運算子*
int a = 10;
int* p = &a;//* - 說明p為指標變數 ,& - 說明p中存盤的是a的地址
*p = 20;//解參考訪問其存盤的地址中的內容
printf("%d\n", *p);
陣列名作首元素地址問題
int arr[10] = { 0 };
//1.
printf("%p\n", arr + 1);
//2.
printf("%p\n", &arr[0] + 1);
//3.
printf("%p\n", &arr + 1);
arr和arr[0]都是首元素的地址,&arr是整個陣列的地址,列印出來都是一樣的,但是當他們都+1區別就出現了,前兩個加1都是第二個元素的地址,而&arr加1就跳過了整個陣列的地址,
拓寬一點,*p放在=左邊就是一塊空間,而放在=右邊就是一個值,
//1.
int b = *p;//這里*p代表值
//2.
*p = b;//這里*p就代表一塊空間用以存放值
任何一個變數都可以這樣理解,放在=的左邊代表一塊空間
a = 10;,就是左值,放在=右邊就是代表值p = a;,即右值,
型別長度運算子sizeof
sizeof計算變數或型別所占記憶體空間的大小,與其記憶體中存放的資料是什么無關,
//1.
printf("%d\n", sizeof arr);
//2.
printf("%d\n", strlen(arr));
sizeof strlen() 二者的區別
sizeof是計算所占空間的運算子,不關心存放的資料strlen()是計算字串長度的函式,關注存放的資料中的\0前的字符個數
sizeof后面的()是運算式的括號,而不是函式呼叫運算子,正因sizeof是運算子,所以可以省略,
例題:
int a = 5;
short s = 10;
printf("%d\n", sizeof(s = a + 2));//?
printf("%d\n", s);//?
把
int型資料a+2賦值給short型資料s,會發生整型截斷,還是short型的資料,
sizeof內部的運算式是不參與運算的,所以s原來是多少現在還是多少,原因:sizeof內部的運算時再預編譯時期處理的,在程式執行期間早已將內部的運算式替換成了數字,
按位取反運算子~
將其二進制位所有位統統取反,
例題
如何將二進制位指定一位1修改為0,0修改為1?
int a = 13;
//00000000 00000000 00000000 00001101 - 13
//00000000 00000000 00000000 00000010 - 1<<1
//00000000 00000000 00000000 00001111 - 15
int b = a | (1<<1);
printf("%d\n", b);
//00000000 00000000 00000000 00001111 - 15
//11111111 11111111 11111111 11111101 - ~(1<<1)
//00000000 00000000 00000000 00001101 - 13
int c = b & (~(1 << 1));
printf("%d\n", c);
該二進制位為0想改為1,則按位或上這么一個數字
..00100..,該二進制位為1想改為0,則按位與上這么一個數字..11011..
++ -- 運算子
前置++ --是先使用在修改,后置++ --先修改再使用,
int a = 0;
printf("%d\n", a);
int b = a++;
printf("%d\n", b);
int c = --a;
printf("%d\n", c);
++ --這樣使用就可以了,不要去追求一些沒用的復雜使用,沒人會去那么用的,寫代碼的目的并不是不讓人看懂,如:
int a = 0;
int b=(++a)+(a++)+(a++);
這樣的代碼再不同的編譯器上會跑出不同的結果,沒必要在這個上浪費時間,
強制型別轉換運算子(type)
int a = (int)3.14;
例題
void test1(int arr[]){
printf("%d\n", sizeof(arr));//(2)
}
void test2(char ch[]){
printf("%d\n", sizeof(ch));//(4)
}
int main(){
int arr[10] = { 0 };
char ch[10] = { 0 };
printf("%d\n", sizeof(arr));//(1)
printf("%d\n", sizeof(ch));//(3)
test1(arr);
test2(ch);
return 0;
}
- (1) 和 (3) 沒問題,陣列名單獨放在
sizeof內,計算的是整個陣列的大小,分別是40和10,- (2) 和 (4) 是陣列名作函式引數,別看表面上是用陣列接收,其實是用指標接收的,計算的都是指標的大小,陣列名作函式引數,沒有可能將陣列整個傳參過去,編譯器自動將其降級優化為指向元素首地址的指標,
關系運算子=
> >= < <= != ==
==和=不一樣,如果寫錯就成賦值了,
邏輯運算子
&& //邏輯與
|| //邏輯或
邏輯運算子只關注真偽,邏輯與 && 就是并且,邏輯或 || 就是或者,
邏輯與 && 兩邊運算元都為真,整個條件才為真,邏輯或 ||兩邊運算元有一個是真,則整個條件就為真,
例題
int main()
{
int i = 0,a=0,b=2,c =3,d=4;
i = a++ && ++b && d++;
i = a++||++b||d++;
printf("a = %d\n b = %d\n c = %d\nd = %d\n", a, b, c, d);
return 0;
}
短路運算
- 邏輯與
&&,當左邊的運算式為假時,整個條件為假,不再進行運算, - 邏輯或
||,當左邊的運算式為真時,整個條件為真,不再進行運算,
i = a++ && ++b && d++,第一步a++=0為假,則整個運算式為假,i=0;i = a++||++b||d++,第二步a++為真,整個運算式為真,后面的運算式也不進行運算了,
條件運算子
exp1 ? exp2 : exp3
運算式exp1的結果為真,執行exp2并將exp2的結果作為整個運算式的結果,反之,則執行exp3并將其賦值給整個運算式,
逗號運算式
exp1, exp2, exp3,...,expN
從左向右依次計算,整個運算式的結果為最后一個運算式的結果,
那既然這樣,為什么我們還要計算前面的運算式呢,直接算最后一個不就好了嗎?
前面的運算式可能會影響到最后一個運算式的值,如:
int a = 1,b = 2;
int c = (a>b, a=b+10, a, b=a+1);
下標參考、函式呼叫和結構成員
[] () . ->
下標參考運算子[]

arr+i即為陣列中下標為i的元素的地址,
[]是一個運算子,它的兩個運算元分別為陣列名和下標,缺一不可,對于arr[i]可理解為*(arr+i),既然如此我們就可寫出:
arr[i] <=> *(arr+i) <=> *(i+arr) <=> i[arr]
int arr[10] = { 0 };
for (int i = 0; i < 10; i++){
printf("%p --- %p\n", &i[arr], i+arr);
}
這就體現出了
[]是個運算子,這樣的寫法語法是支持的,
函式呼叫運算子()
printf("%u\n", strlen("abc"));
這里printf和strlen函式都必須帶上(),不傳參也要帶上,不然就錯,
對于函式呼叫運算子(),可以有一個或者兩個運算元都可以,
結構成員運算子. ->
.結構體.成員名
->結構體指標->成員名
結構體用于描述一個復雜的物件,
結構體定義
struct Book{
char name[50];
char id[15];
float price;
};
結構體使用
Print(struct Book b1){
printf("書名為:%s\n", b1.name);
printf("價格為:%f\n", b1.price);
printf("書號為:%s\n", b1.id);
}
int main(){
struct Book b1 = { "譚浩強C語言程式設計",55.5f,"2020322222" };
Print(b1);
return 0;
}
使用結構體型別struct Book創建了一個結構體型別的變數b,b中成員有三個name、id和price,
我們還可以后續去修改價格,如:
b1.price = 100.0f;
那我們能不能把書名或者書號都給改了呢?
b1.name = "資料結構";
當然是不行的,我們可以看得出,書名
name和書號id都是通過陣列創建的,對于他們來說b1.name是陣列的首地址,怎么能對地址賦值呢,
那既然是地址的話,我們對地址進行解參考,不就可以訪問陣列元素了嘛~,我們再試一下,
*(b1.name) = "資料結構";
當然,仍然是不對的,會顯示亂碼,
那如何結構體變數的陣列成員呢,答案是使用庫函式strcpy對字串賦值
strcpy(b1.name, "資料結構");
結構體地址
將變數地址傳過去,如何使用呢?
(*結構體指標).成員名
Print2(struct Book* pb){
printf("書名為:%s\n", (*pb).name);
printf("價格為:%f\n", (*pb).price);
printf("書號為:%s\n", (*pb).id);
}
結構體指標->成員名
Print3(struct Book* pb){
printf("書名為:%s\n", pb->name);
printf("價格為:%f\n", pb->price);
printf("書號為:%s\n", pb->id);
}
運算式求值
一個運算式在求值時,一部分取決于它的運算子的優先級和結合性,一部分取決于編譯器自己的規則,我們寫出的運算式一定要讓編譯器的邏輯與自己的代碼邏輯相一致,否則就是沒用的代碼,與此同時,有一些運算式中的運算元可能需要型別提升,
隱式型別轉換
在運算的程序中,一些小位元組的型別會向大位元組的型別轉換后再加以運算,整個程序是編譯器自動一次完成的,
整型提升
如,short和char會轉化為int,再進行運算,不是說只有不同型別資料運算時才會發生型別轉換,而是為適應CPU4個位元組的運算器,都會轉化為普通整型,這個程序被稱為整型提升,只要有運算就會有整型提升,如:
char a=1,b=2,c=3;
...
char d=a+b+c;
如這樣的一個例子,先將字符型的
a,b,c整型提升為普通整型,然后進行運算,再放到d中,最后再發生截斷,只取最后一個位元組,轉化回為字符型,
如何整型提升
按型別的符號位進行整型提升,如:
char c = -1;
//11111111 11111111 11111111 11111111
//11111111
printf("%d\n",c);
//11111111 11111111 11111111 11111111
有符號數
- 寫出變數的二進制補碼
- 按最高位符號位進行填充
- 得到的補碼再轉換成原碼
無符號數
最高位填充0
如何得到c的補碼?(1)先把c當成int型別然后,寫出32位補碼,(2)然后進行截斷,只得最后8位,(3)最后再按此時的最高位填充,是0就填充0,反之則1,
例題
Example 1
char a = 3;
//00000000 00000000 00000000 00000011 - int a
//00000011 - char a
char b = 127;
//00000000 00000000 00000000 01111111 - int b
//01111111 - char b
char c = a + b;
//00000000 00000000 00000000 00000011 - int a 發生整型提升
//00000000 00000000 00000000 01111111 - int b
//00000000 00000000 00000000 10000010 - int c
//10000010 - char c 發生截斷
printf("%d\n", c);
//11111111 11111111 11111111 10000010 - int c - 補碼 發生整型提升
//10000000 00000000 00000000 01111110 - int c - 原碼
- 寫出
a和b的32位補碼- 進行截斷,存入記憶體
- 整型提升,按最高位進行填充
- 進行運算
- 進行截斷,再整型提升
- 將所得補碼轉換回原碼
如:

我們在得到兩個變數的二進制碼后,對其進行整型提升,再對所得結果進行截斷,因為要存入字符型變數c中,又因為要以
%d的形式列印變數c,再次對已經截斷過的補碼(存入記憶體中的都是補碼),進行整型提升,轉換成原碼,
Example 2
char a = 0xb6;
//10110110
short b = 0xb600;
//10110110 00000000
int c = 0xb6000000;
//10110110 00000000 00000000 00000000
if (a == 0xb6)
//11111111 11111111 11111111 10110110
//10000000 00000000 00000000 01001001
//10000000 00000000 00000000 01001010 - int a
//00000000 00000000 00000000 10110110 - 0xb6
printf("a");
if (b == 0xb600)
//11111111 11111111 10110110 00000000
//10000000 00000000 01001001 11111111
//10000000 00000000 01001010 00000000 - int b
//00000000 00000000 10110110 00000000 - 0xb600
printf("b");
if (c == 0xb60000)
//10110110 00000000 00000000 00000000 - int c
//10110110 00000000 00000000 00000000 - 0xb6000000
printf("c");
- 首先我們寫出
a,b,c的二進制補碼(都是正數),- 然后發現有運算(
==也是運算),只要有運算就要整型提升,整型提升后好巧不巧最高位都是1,默認為負數了,- 這樣經過原反補轉化后無論怎樣都是負數,不會和
0xb6和0xb600相等的,只有c本身就是默認整型,不用提升,
Example 3
char c = 1;
printf("%u\n", sizeof(c));//1
printf("%u\n", sizeof(+c));//4
printf("%u\n", sizeof(-c));//4
計算
sizeof(c)時,沒有運算所以沒有發生整型提升,取正取負也是運算子,sizeof(±c)時(+c)和(-c)兩個運算式發生了整型提升,故變成了四個位元組,
算術轉換
對于short和char需要整型提升為int,那浮點型,長整型呢?對于這些型別,就不叫整型提升了,叫算術轉換,

順序由高到低,當精度低的型別與精度高的型別相運算時,會將低精度轉換為高精度,然后在和高精度資料進行運算,例:
int a = 4;
float f = 4.5f;
f = a + f;
printf("%f\n", f);//8.500000
計算
f時需要先把a轉化為單精度浮點型,
運算子的屬性
運算式的求值有三個影響因素:
- 運算子的優先級
- 運算子的結合性
- 是否控制求值順序
兩個相鄰的運算子先執行那個?
先看優先級,優先級相同看結合性,
//運算式1.
a*b+c*d+e*f;
//運算式2
c + --c;
//運算式3
int a = 1;
a=(++i)+(++i)+(++i);
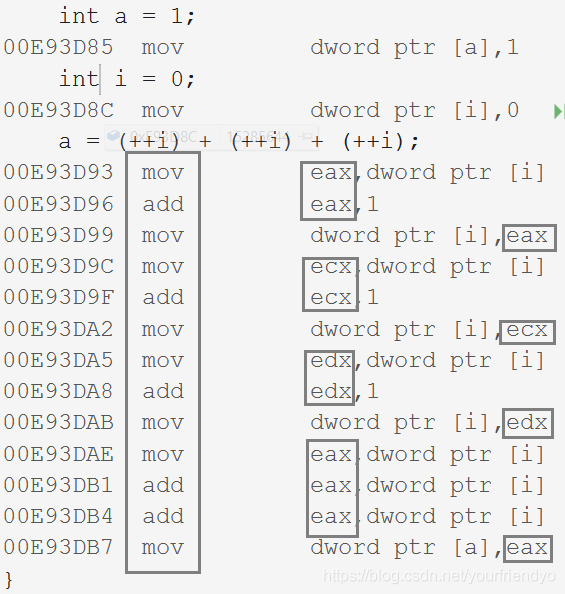
這樣的運算式在不同的編譯器下,會跑出不同的結果,因為各個編譯器的標準不一樣,
對于這樣的運算式,我們知道運算子的優先級和結合性,但我們依然無法確定運算式計算的唯一路徑,所以這樣的代碼是不好的,寧愿多寫幾步,規范確定出運算式的唯一執行路徑,也不要追求過分的簡潔,這不是代碼的目的,
總結
我們寫出的運算式如果不能通過運算子的屬性確定唯一的計算路徑,那這個運算式就是存在問題的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/291538.html
標籤:其他
上一篇:C語言處理批量資料的好伙伴!陣列!C語言陣列的介紹與應用
下一篇:掃雷優化版