
目錄
- 前言
- 指標是什么
- 總結:指標就是變數,用來存放地址的變數,(存放在指標中的值都被當成地址處理)
- 指標和指標型別
- 指標的關系比較
- 指標-指標
- 指標和陣列的關系
- 二級指標
- 指標陣列
- 野指標
- 野指標的原因
- 避免野指標的方法
- 結構體
- 結構的基礎知識
- 結構體的宣告和定義
- 創建結構體的偷懶式寫法(簡潔版)
- 結構體變數定義初始化
- 結構體嵌套
- 結構體變數傳參
- 1、值傳遞
- 2、地址傳遞
- 總結:地址傳遞效率更高
前言
作為一名C程式員,學會指標是我們的首要關鍵,靈活運用指標又是對個人能力的體現,想從此刻學好指標請跟著博主來
指標是什么
在計算機科學中,指標(Pointer)是編程語言中的一個物件,利用地址,它的值直接指向
(points to)存在電腦存盤器中另一個地方的值,由于通過地址能找到所需的變數單元,可以
說,地址指向該變數單元,因此,將地址形象化的稱為“指標”,意思是通過它能找到以它為地址的記憶體單元

總結:指標就是變數,用來存放地址的變數,(存放在指標中的值都被當成地址處理)
每個地址標識一個位元組,那我們就可以給 (2^32Byte == 2^32/1024KB ==
232/1024/1024MB==232/1024/1024/1024GB == 4GB) 4G的空閑進行編址,
同樣的方法,那64位機器,如果給64根地址線,那能編址多大空間,自己計算,
這里我們就明白:
在32位的機器上,地址是32個0或者1組成二進制序列,那地址就得用4個位元組的空間來存盤,所
以一個指標變數的大小就應該是4個位元組,
那如果在64位機器上,如果有64個地址線,那一個指標變數的大小是8個位元組,才能存放一個地
址,
總結:
1、指標是用來存放地址的,地址是唯一標示一塊地址空間的,
2、指標的大小在32位平臺是4個位元組,在64位平臺是8個位元組
指標和指標型別
總結:指標的型別決定了指標向前或者向后走一步有多大(距離),
指標作用域
int main()
{
int n = 0x11223344;
char *pc = (char*)&n;
int *pi = &n;
*pc = 0;
pi = 0;
return 0;
}
總結: 指標的型別決定了,對指標解參考的時候有多大的權限(能操作幾個位元組), 比如: char* 的
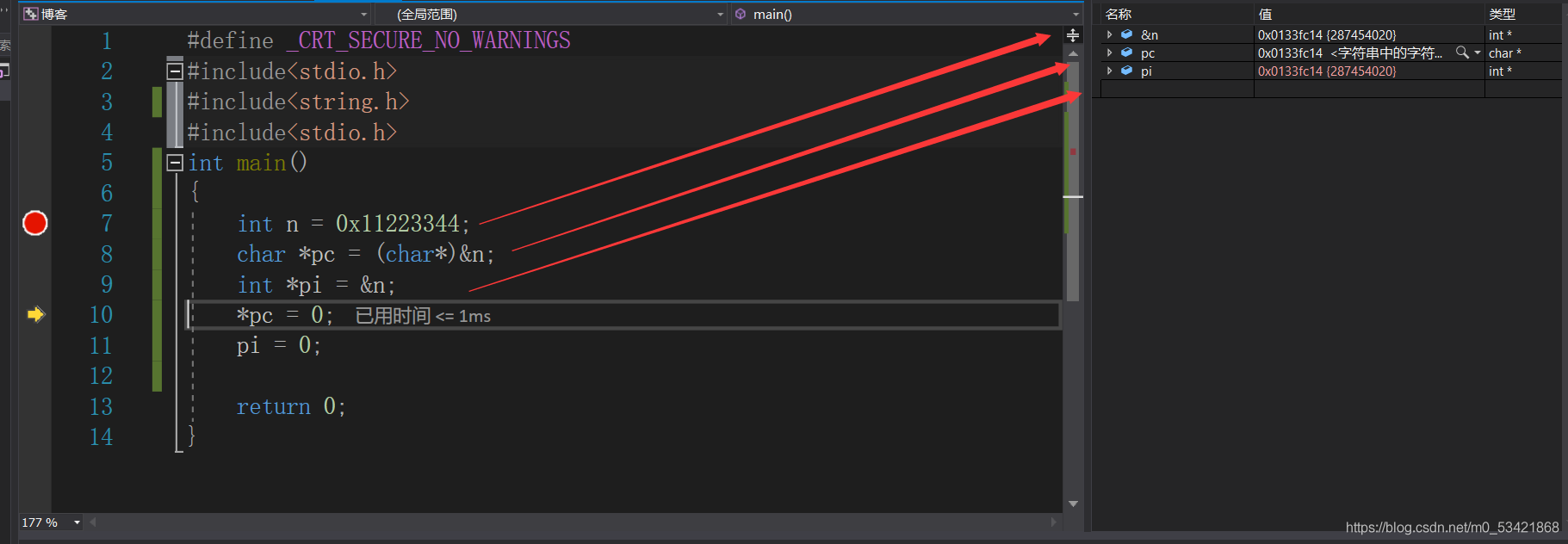
在我們的除錯視窗中可以看到,此時的pi,pc指標都指向著變數n,程式進一步往下走
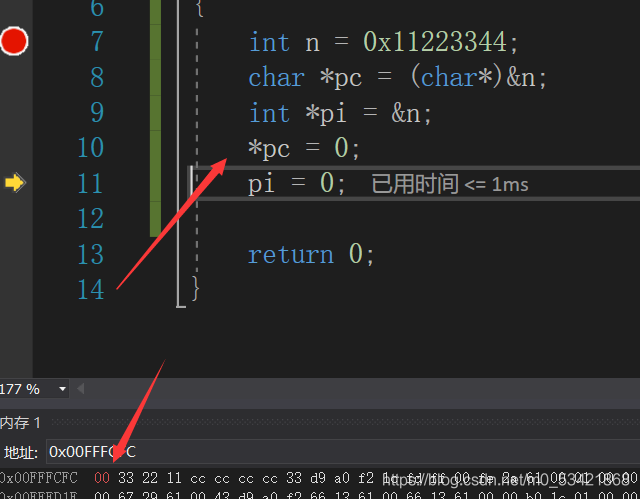
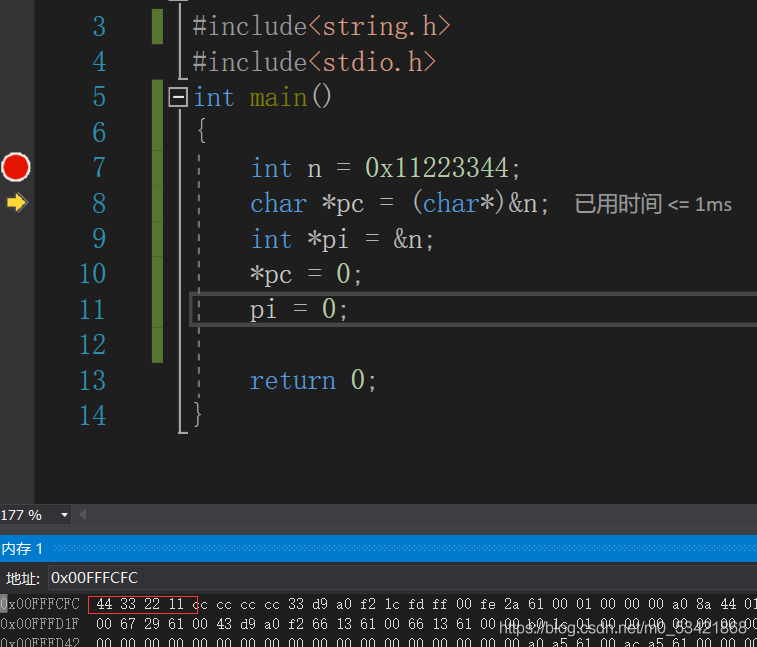
注意:斷點走到哪一行表示這一行還沒執行,斷點的上一行剛剛執行,此時的斷點走到了11行,表示第10行已經執行,這個程序我們記錄了*pc只改變了變數n在記憶體中的第一個位元組,
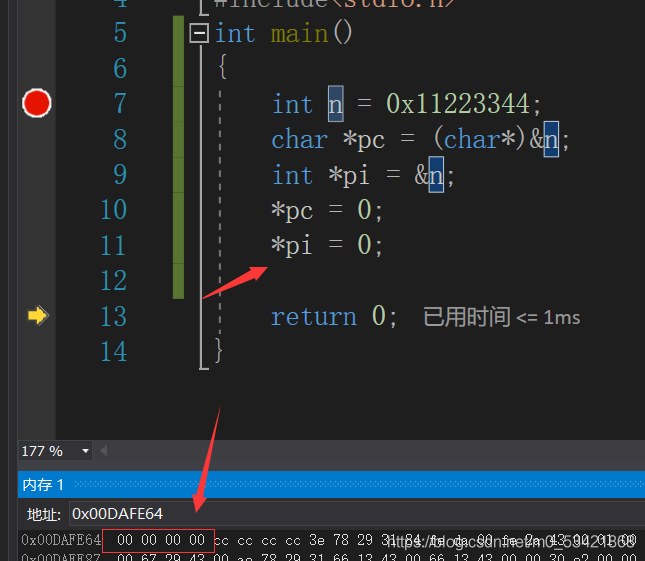
而指標*pi卻能改變四個位元組
總結:char指標解參考就只能訪問一個位元組,而 int 的指標的解參考就能訪問四個位元組,
指標的關系比較
以下代碼的作用是遍歷修改陣列中的每一個元素
#define N_VALUES 5
float values[N_VALUES];
float *vp;
for (vp = &values[0]; vp < &values[N_VALUES];)
{
*vp++ = 0;
}
眼尖的小伙伴可能會覺得這樣一弄不是就越界了嗎?
在這里可以注意的是下標為5的陣列地址可以用來必較VP地址間的關系,這是因為標準規定
vp < &values[N_VALUES],指標的關系運算,兩個指標之間比較大小
指標-指標
指標 - 指標 得到的數字的絕對值是指標和指標之間元素的個數,這句話是什么意思?
讀代碼理解
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
printf("%d\n",&arr[9] - &arr[0]);//9
printf("%d\n",&arr[0] - &arr[9]);//-9
return 0;
}
這句話的意思其實無非就是說,在一段連續的空間里(我這里是陣列),有了地址頭(&arr[0]),又有了地址尾(&arr[9]),這兩個指標一減,得到的結果值其實就是我們的元素個數
模擬strlen函式(指標減指標)
以下是通過模擬strlen函式的實作,也是通過兩地址相減,取得字符間的個數
int my_strlen(char *str)
{
char* start = str;//指標備份
if(*str != '\0')
{
str++;
}
return str - start;//兩指標相減得到字符個數
}
指標和陣列的關系
陣列名是陣列首地址,但是有兩個例外
1、sizeof(陣列名) - 陣列名不是首元素地址,是表示整個陣列,這里計算的是整個陣列的大小,單位是位元組
2、&陣列名 - 這里的陣列名不是首元素的地址,是表示整個陣列的,拿到的是這個陣列的地址 -
額外補充(圖解):
以上觀察貌似區別不大,似乎也不足以證明&arr就是整個陣列的地址,看下一步
我們直到arr 跟 &arr[0]都是陣列首地址(陣列首元素地址),當它們 + 1后是跳過一個整形的地址,而&arr表示的是整個陣列的地址,整個陣列的地址不就是40位元組嗎?在視窗中可以看到游標選中的那一行,跟它的下一行之間是相差了40個位元組的,因為16進制的28 就是十進制的40,這一點足以證明&arr取出的是整個陣列的地址
既然可以把陣列名當成地址存放到一個指標中,那么我們就可以使用指標來訪問一個陣列
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
int len = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for(i = 0; i < len; i++)
{
printf("%d",*(p + i));
}
return 0;
}
二級指標
int main()
{
int a = 10;
int *p = a; //指標變數存放a的地址
int **pp = &p;//二級指標存放一級指標的地址
int ***ppp = &pp;//三級指標存放二級指標的地址
return 0;
}
上述代碼可以這么理解和記憶
int *p = a ==》 *p表示的是一個指標變數,指標變數指向的物件型別是int型別
int* *pp = &p ==》 *p表示的是一個指標變數,指標變數指向的物件型別是int*型別
int** *ppp = &pp ==》*p表示的是一個指標變數,指標變數指向的物件型別是int**型別
以下主要講解到二級指標的邏輯,因為二級指標已經是我們理解和使用的極限了,代碼書寫的時候并不是寫的越復雜,才越是高質量,恰恰是以最能讓別人能夠看得懂才是優質的代碼,因為這樣大大便于軟體的維護和測驗
這是以上代碼得到的測驗結果,為了便于大家理解,簡單的打個比方
1、假設我們現在有3個抽屜和2把鑰匙
2、抽屜1存放的是區域變數a
3、抽屜2存放的是*p
4、抽屜3存放的是**pp
邏輯梳理:首先我們如果想改變區域變數a的值是可以的并且有兩種方法,
方法一:直接修改變數a的值
方法二:通過一級指標*p拿到變數a的地址,從而修改變數a
方法三:通過二級指標 *pp 一解參考拿到了一級指標,再通過對一級指標解參考就會找到區域變數a,從而修改變數a的值
主要講解二級指標:如果我們把二級指標看成一個抽屜的話,那么打開抽屜的第一時間就會找到一把鑰匙,這把鑰匙就是&p
鑰匙對應打開的箱子是序號2吧,當我們打開了第二個箱子的話,此時2號箱子里存放的就是&a鑰匙了,那有了這一把鑰匙于是乎就可以再去打開1號箱子了,1號箱子里存放的是變數a,那么是不是就可以直接操作變數a了?答案是可以
指標陣列
如何理解指標陣列呢?
首先指標陣列的本質上是一個陣列,指標陣列的屬性是每一個元素都是一個指標變數,既然他是一個陣列的話想必一定是一塊連續存盤的空間了,每一個元素都是一個指標變數?那么是不是每一個元素都可以用來存放一個變數的地址,指向這個變數?
#include<stdio.h>
int main()
{
int a = 0;
int b = 2;
int c = 4;
int *arr[3] = {&a,&b,&c};
int len = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < len; i++)
{
printf("%d ",*(arr[i]));
}
return 0;
}
注意不要寫成 int len = sizeof(arr) / sizeof(*(arr[0]));這種形式,陣列型別是整形陣列時必然不會存在什么問題但是如果是char 型別呢,
在我們的除錯視窗下可以很清晰的看得到len的值居然是12,所以不要寫成這種方式的,原因也很簡單,因為指標在32位系統下是默認占4位元組,我們測驗的環境就是在
32系統下,那么sizeof(arr)計算的是整個陣列的大小(位元組),而 sizeof((arr[0]))他是取出指標變數指向的那個地址上對應的值,由于這里涉及到隱士型別轉換,所以最終sizeof((arr[0]))求得的是1個位元組,12 / 1 = 12,答案不就出來了嗎,這里交代的是一個細節問題
回歸到正題想必大家應該知道這段代碼的功能吧,沒錯就是依次取出陣列中的指標,再對指標解參考,找到指標指向的那個變數逐個列印出來
看到這里大家應該已經明白了,指標陣列是一個陣列,由于指標陣列的每一個元素都是一個指標變數,指標變數具有指向性
野指標
概念: 野指標就是指標指向的位置是不可知的(隨機的、不正確的、沒有明確限制的)
野指標的原因
1、指標未初始化
2、指標越界訪問
3、指標指向的空間釋放
避免野指標的方法
1、指標初始化
2、小心指著越界
3、指標指向空間釋放即使置NULL
4、指標使用之前檢查有效性
結構體
結構的基礎知識
結構是一些值的集合,這些值稱為成員變數,結構的每個成員可以是不同型別的變數
結構體的宣告和定義
struct Stu //結構體的宣告,創建一個結構體型別
{
char name[20];
int age;
char id[20];
};
struct Stu //創建一個結構體型別
{
char name[20];
char author[15];
float price;
}b1,b2; //創建兩個全域的結構體變數
struct Point //創建一個結構體型別
{
int x;
int y;
}p1,p2; //創建兩個個全域的結構體變數
int main()
{
struct Stu b1;//創建一個區域的結構體變數
struct Stu b2;//創建一個區域的結構體變數
return 0;
}
以上兩種創建結構體變數的方式都是允許的,只不過再main中創建的結構體變數是存放在堆疊上的,而b1、b2、p1、p2是全域的結構體變數,全域變數是存放在靜態區的,注意創建一個結構體型別時分號不能丟
創建結構體的偷懶式寫法(簡潔版)
例如描述一個動物
typedef struct Animal //創建一個結構體型別
{
char families[20] // 描述動物科
char skill[20] //動物技能
char breed[20] //動物的繁殖方式
}Animal;
int main()
{
struct Animal tiger //創建一個老虎物件
Animal mew //創建一個海鷗物件
return 0;
}
在主函式中使用以上兩種定義結構體變數的方式都可以,這里值得一提的是Animal是一個型別使用typedef給整個結構體型別取了一個別名叫Animal,簡單說明以下typedef關鍵字,這個關鍵字是給型別取別名的,比如int型別是一個整形,我也可以使用typedef給int型別取別名為intjj,此時的
intjj 表示的還是一個整形,未來在使用的時候intjj型別定義一個變數,這個變數就是一個整形
值得一提的是使用typedef定義出的新型別,只是一個型別而并不是一個變數,跟之前的在末尾定義結構體變數的意義是截然不同的,一種是宣告結構體型別的時候定義結構體變數,而第二種使用typedef只是給原先的結構體型別取別名
結構體變數定義初始化
為了便于大家理解還是采用之前的代碼
typedef struct Animal //創建一個結構體型別
{
char families[20] // 描述動物科
char skill[20] //動物技能
char breed[20] //動物的繁殖能力
}Animal; //結構體型別別名,表示的是同一種型別
int main()
{
struct Animal tiger = {"貓科","捕獵","***"};
Animal mew = {"歐科","飛翔","**"};
return 0;
}
是不是非常簡單的初始化方式?沒錯
結構體嵌套
typedef struct birthday //生日
{
int year;//年
int month;//月
int day;//日
}birthday;
typedef struct Student //學生
{
int age;//年齡
char name[20];//姓名
birthday b1;
char occupation[20];//職業
}Student;
int main()
{
Student s1 = { 18,"張三",{2002,4,8},"經理", };//結構體嵌套初始化
printf("%d %s %d %d %d %s",s1.age,s1.name,s1.b1.year,s1.b1.month,s1.b1.day,s1.occupation);
return 0;
}
使用運算子訪問結構體成員
typedef struct birthday
{
int year;
int month;
int day;
}birthday;
typedef struct Student
{
int age;
char name[20];
birthday b1;
char occupation[20];
}Student;
int main()
{
Student s1 = { 18,"張三",{2002,4,8},"經理", };
printf("%d %s %d %d %d %s\n",s1.age,s1.name,s1.b1.year,s1.b1.month,s1.b1.day,s1.occupation);
Student *p = &s1;
printf("%d %s %d %d %d %s\n", p->age,p->name,p->b1.year,p->b1.month,p->b1.day,p->occupation);
printf("%d %s %d %d %d %s\n", (*p).age, (*p).name, (*p).b1.year, (*p).b1.month, (*p).b1.day, (*p).occupation);
return 0;
}
結構體變數傳參
1、值傳遞
2、地址傳遞
首先先看值傳遞
void print(Student s1)
{
printf("%d %s %d %d %d %s\n", s1.age, s1.name, s1.b1.year, s1.b1.month, s1.b1.day, s1.occupation);
}
int main()
{
Student s1 = { 18,"張三",{2002,4,8},"經理", };
print(s1);
return 0;
}
引數傳遞以值傳遞的方式,就是一次資料的拷貝(每次都會拷貝sizeof(結構體變數)),將實參s1拷貝到形參s1,值拷貝是會額外地分配一塊空間的(sizeof(結構體變數)),結構體變數的大小(位元組)一般來講都會比較大一些,如果每次都是以值拷貝的方式將實參的成員變數挨個拷貝至形參的成員變數,這對于運行效率和空間占用來講是會大大損耗的(不推薦),
解決方案:地址傳遞
地址傳遞
void print(Student *p)
{
printf("%d %s %d %d %d %s\n", p->age, p->name, p->b1.year, p->b1.month, p->b1.day, p->occupation);
}
int main()
{
Student s1 = { 18,"張三",{2002,4,8},"經理", };
print(&s1);
return 0;
}
但是如果是地址傳遞的話,那就不一樣了,因為指標的默認位元組數是看作業系統的,那如果是在32位平臺下的話,指標默認4位元組,每次都只需要傳遞一個地址過去,只占四位元組,極大地提升了效率,減少了空間的浪費
總結:地址傳遞效率更高

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292234.html
標籤:其他