分庫分表之第二篇
- 2. Sharding-JDBC快速入門
- 2.1需求說明
- 2.2. 環境建設
- 2.2.1環境說明
- 2.2.2創建資料庫
- 2.2.3約會maven依賴
- 2.3 撰寫程式
- 2.3.1 分片規則配置
- 2.3.2 資料操作
- 2.3.3 測驗
- 2.4. 流程分析
- 2.5 其他集成方式
2. Sharding-JDBC快速入門
2.1需求說明
使用Sharding-JDBC完成對訂單表的水平分表,通過快速入門程式的開發,快速體驗Sharding-JDBC的使用,人工創建兩張表,t_order_1和t_order_2,這張表是訂單表替換后的表,通過Shading-JDBC向訂單表插入資料,按照一定的分片規則,主鍵為偶數的盡入t_order_1,另一部分資料進入t_order_2,通過Shading-Jdbc查詢資料,根據SQL陳述句的內容從t_order_1或order_2查詢資料,
2.2. 環境建設
2.2.1環境說明
作業系統:Win10資料庫:MySQL-5.7.25 JDK:64位jdk1.8.0_201應用框架:spring-boot-2.1.3.RELEASE,Mybatis3.5.0 Sharding-JDBC:sharding-jdbc-spring-boot-starter-4.0 .0-RC1
2.2.2創建資料庫
創建訂單表
CREATE DATABASE`order_db`字符集'UTF8'COLLATE'utf8_general_ci'; ```在order_db中創建t_order_1,t_order_2表如果存在java DROP TABLE t_order_1; CREATE TABLE`t_order_1`(`order_id` BIGINT(20)非空注釋'訂單ID',`price`十進制(10,2)非空注釋'訂單價格',`user_id` BIGINT(20)非空注釋“下一個單用戶id”,“狀態” varchar(50)字符集utf8集合utf8_general_ci NOT NULL COMMENT“訂單狀態”,主鍵(`order_id`)使用BTREE)引擎= InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = 如果存在表t_order_2; CREATE TABLE`t_order_2`(`order_id` BIGINT(20)非空注釋'訂單ID',`price`十進制(10,2)非空注釋'訂單價格',`user_id` BIGINT(20)非空注釋'下一個單用戶id',`status` varchar(50)字符集utf8集合utf8_general_ci NOT NULL COMMENT'訂單狀態',主鍵(`order_id`)使用BTREE
)ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT =動態;
2.2.3約會maven依賴
sharding-jdbc和SpringBoot整合的Jar包:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding‐jdbc‐spring‐boot‐starter</artifactId>
<version>4.0.0‐RC1</version>
</dependency>
2.3 撰寫程式
2.3.1 分片規則配置
分片規則配置是sharding-jdbc進行分庫分表操作的重要依據,配置內容包括 :資料源、主鍵生成策略等,
在application.properties中配置
server.port=56081
spring.application.name = sharding‐jdbc‐simple‐demo
server.servlet.context‐path = /sharding‐jdbc‐simple‐demo spring.http.encoding.enabled = true spring.http.encoding.charset = UTF‐8 spring.http.encoding.force = true
spring.main.allow‐bean‐definition‐overriding = true
mybatis.configuration.map‐underscore‐to‐camel‐case = true # 以下是分片規則配置
# 定義資料源
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true spring.shardingsphere.datasource.m1.username = root spring.shardingsphere.datasource.m1.password = root
# 指定t_order表的資料分布情況,配置資料節點 spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes = m1.t_order_$‐>{1..2}
# 指定t_order表的主鍵生成策略為SNOWFLAKE spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片鍵和分片演算法 spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column = order_id spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression = t_order_$‐>{order_id % 2 + 1}
# 打開sql輸出日志 spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info logging.level.org.springframework.web = info logging.level.com.itheima.dbsharding = debug logging.level.druid.sql = debug
- 首先定義資料源m1,并對m1進行實際的引數配置
- 指定t_order表的資料分布情況,它分布在m1.t_order_1、m1.t_order_2
- 指定t_order表的主鍵生成策略為SNOWFLAKE,SNOWFLAKE是一種分布式自增演算法,保證id全域唯一
- 定義t_order分片策略,order_id為偶數的資料落在t_order_1,為奇數的落在t_order_2,分表策略的運算式為t_order_$->{order_id % 2 + 1}
2.3.2 資料操作
@Mapper
@Component
public interface OrderDao {
/**
* 新增訂單
* @param price 訂單價格 * @param userId 用戶id * @param status 訂單狀態 * @return
*/
@Insert("insert into t_order(price,user_id,status) value(#{price},#{userId},#{status})")
int insertOrder(@Param("price") BigDecimal price, @Param("userId")Long userId, @Param("status")String status);
/**
* 根據id串列查詢多個訂單
* @param orderIds 訂單id串列 * @return
*/
@Select({"<script>" + "select " +
"*"+
" from t_order t" +
" where t.order_id in " +
"<foreach collection='orderIds' item='id' open='(' separator=',' close=')'>" + " #{id} " +
"</foreach>"+
"</script>"})
List<Map> selectOrderbyIds(@Param("orderIds")List<Long> orderIds);
}
2.3.3 測驗
撰寫單元測驗 :
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleDemoBootstrap.class}) public class OrderDaoTest {
@Autowired
private OrderDao orderDao;
@Test
public void testInsertOrder(){
for (int i = 0 ; i<10; i++){
orderDao.insertOrder(new BigDecimal((i+1)*5),1L,"WAIT_PAY");
}
}
@Test
public void testSelectOrderbyIds(){
List<Long> ids = new ArrayList<>(); ids.add(373771636085620736L); ids.add(373771635804602369L);
List<Map> maps = orderDao.selectOrderbyIds(ids); System.out.println(maps);
}
}
執行testInsertOrder: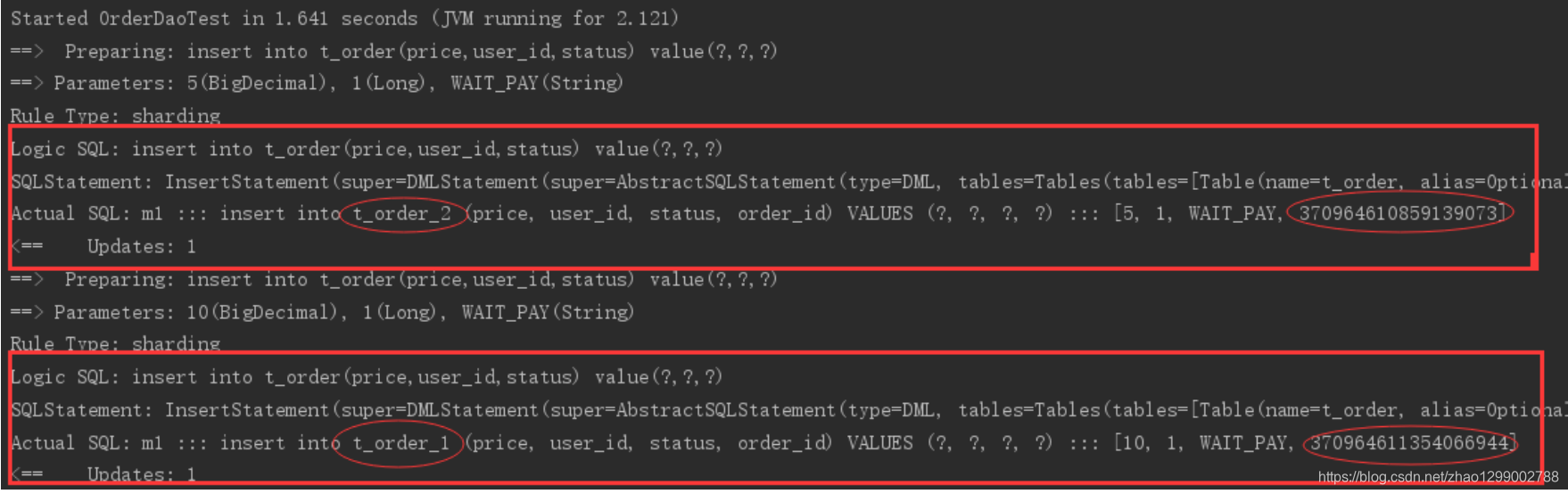
通過日志可以發現order_id為奇數的被插入到t_order_2表,為偶數的被插入到t_order_1表,達到預期目標,
執行testSelectOrderbyIds:
通過日志可以發現,根據傳入的order_id的奇偶不同,分片-JDBC分別去不同的表檢索資料,達到預期目標,
2.4. 流程分析
通過日志分析,Sharding-JDBC在拿到用戶要執行的sql之后干了那些事兒 :
(1)決議sql,獲取片鍵值,在本例中是order_id
(2)Sharding-JDBC通過規則配置t_order_$->{order_id% 2 + 1},知道類當order_id為偶數時,應該往t_order_1表插資料,為奇數時,往t_order_2插資料,
(3)于是Sharding-JDBC根據order_id的值改寫sql陳述句,改寫后的SQL陳述句是真實所要執行的SQL陳述句,
(4)執行改寫后的真實sql陳述句
(5)將所有真正執行sql的結果進行匯總合并,回傳,
2.5 其他集成方式
Sharding-JDBC不僅可以與Spring boot良好集成,它還支持其他配置方式,共支持以下四種集成方式,
Spring Boot Yaml配置
定義application.yml,內容如下 :
server:
port: 56081
servlet:
context‐path: /sharding‐jdbc‐simple‐demo spring:
application:
name: sharding‐jdbc‐simple‐demo
http:
encoding:
enabled: true charset: utf‐8 force: true
main:
allow‐bean‐definition‐overriding: true
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/order_db?useUnicode=true username: root
password: mysql
sharding:
tables:
t_order:
actualDataNodes: m1.t_order_$‐>{1..2} tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_$‐>{order_id % 2 + 1}
keyGenerator:
type: SNOWFLAKE
column: order_id
props: sql:
show: true
mybatis:
configuration: map‐underscore‐to‐camel‐case: true
swagger:
enable: true
logging:
level:
root: info
org.springframework.web: info
com.itheima.dbsharding: debug
druid.sql: debug
如果使用application.yml則需要屏蔽原來的application.properties檔案,
Java配置
添加配置類 :
@Configuration
public class ShardingJdbcConfig {
// 定義資料源
Map<String, DataSource> createDataSourceMap() {
DruidDataSource dataSource1 = new DruidDataSource(); dataSource1.setDriverClassName("com.mysql.jdbc.Driver"); dataSource1.setUrl("jdbc:mysql://localhost:3306/order_db?useUnicode=true"); dataSource1.setUsername("root");
dataSource1.setPassword("root");
Map<String, DataSource> result = new HashMap<>(); result.put("m1", dataSource1);
return result;
}
// 定義主鍵生成策略
private static KeyGeneratorConfiguration getKeyGeneratorConfiguration() {
KeyGeneratorConfiguration result = new KeyGeneratorConfiguration("SNOWFLAKE","order_id");
return result;
}
// 定義t_order表的分片策略
TableRuleConfiguration getOrderTableRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration("t_order","m1.t_order_$‐> {1..2}");
result.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_$‐>{order_id % 2 + 1}"));
result.setKeyGeneratorConfig(getKeyGeneratorConfiguration()); return result;
}
// 定義sharding‐Jdbc資料源
@Bean
DataSource getShardingDataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration()); //spring.shardingsphere.props.sql.show = true
Properties properties = new Properties();
properties.put("sql.show","true");
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(),
shardingRuleConfig,properties);
}
}
由于采用類配置類所以需要屏蔽原來application.properties檔案中spring.shardingsphere開頭的配置資訊,還需要在SpringBoot啟動類中屏蔽使用spring.shardingsphere配置項的類 :
@SpringBootApplication(exclude = {SpringBootConfiguration.class}) public class ShardingJdbcSimpleDemoBootstrap {....}
Spring命名空間配置 此方式使用xml方式配置,不推薦使用,
<?xml version="1.0" encoding="UTF‐8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema‐instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:sharding="http://shardingsphere.apache.org/schema/shardingsphere/sharding"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring‐beans.xsd
http://shardingsphere.apache.org/schema/shardingsphere/sharding
http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding.xsd http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring‐context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring‐tx.xsd">
<context:annotation‐config />
<!‐‐定義多個資料源‐‐>
<bean id="m1" class="com.alibaba.druid.pool.DruidDataSource" destroy‐method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/order_db_1?useUnicode=true" />
<property name="username" value="root" />
<property name="password" value="root" />
</bean>
<!‐‐定義分庫策略‐‐>
<sharding:inline‐strategy id="tableShardingStrategy" sharding‐column="order_id" algorithm‐
expression="t_order_$‐>{order_id % 2 + 1}" />
<!‐‐定義主鍵生成策略‐‐>
<sharding:key‐generator id="orderKeyGenerator" type="SNOWFLAKE" column="order_id" />
<!‐‐定義sharding‐Jdbc資料源‐‐> <sharding:data‐source id="shardingDataSource">
<sharding:sharding‐rule data‐source‐names="m1">
<sharding:table‐rules>
<sharding:table‐rule logic‐table="t_order" table‐strategy‐ ref="tableShardingStrategy" key‐generator‐ref="orderKeyGenerator" />
</sharding:table‐rules>
</sharding:sharding‐rule>
</sharding:data‐source>
</beans>轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/29224.html
標籤:架構設計
下一篇:分庫分表之第三篇