內容導讀
- 1.一分鐘搞懂指標是什么
- 2.指標
- 2.1指標型別
- 2.2指標變數的參考
- 2.3指標加減運算
- 3.野指標
- 3.1野指標的成因
- 3.2如何規避野指標
- 4.二級指標
- 5.指標與陣列
- 6.指標與結構體
- 6.1定義和使用結構體變數
- 6.2結構體的初始化與訪問
- 6.3結構體指標
前面的話:
作者水平很有限,如果發現錯誤,一定要及時告知作者哦!感謝感謝!
博主的碼云gitee,平常博主寫的程式代碼都在里面,
1.一分鐘搞懂指標是什么
如果在程式中定義了一個變數,在對程式進行編譯時,系統就會給這個變數分配記憶體單元,編譯系統根據程式中定義的變數型別,分配一定長度的空間,記憶體區的每一個位元組有一個編號,這就是“地址”,
由于通過地址能找到所需的變數單元,可以說,地址指向該變數單元,將地址形象化地稱為“指標”,
#include <stdio.h>
int main()
{
int a = 10;//在記憶體中開辟一塊空間
int *p = &a;//這里我們對變數a,取出它的地址,可以使用&運算子,
//將a的地址存放在p變數中,p就是一個之指標變數,
return 0; }
對于一個變數我們可以使用取地址符&獲取這個變數的地址,對一個指標使用解參考符*可以訪問指標所指向的那塊空間,
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
比如一個陣列,它的每個元素都有一個指向其元素的地址,陣列名通常指該陣列首元素的地址(指標),
| 儲存單元的地址(指標) | 儲存單元的內容 |
|---|---|
| 0x00EFFB30 | 01 00 00 00 |
| 0x00EFFB34 | 02 00 00 00 |
| 0x00EFFB38 | 03 00 00 00 |
| 0x00EFFB3C | 04 00 00 00 |
| 0x00EFFB40 | 05 00 00 00 |
| 0x00EFFB44 | 06 00 00 00 |
| 0x00EFFB48 | 07 00 00 00 |
| 0x00EFFB4C | 08 00 00 00 |
| 0x00EFFB50 | 09 00 00 00 |
| 0x00EFFB54 | 00 00 00 00 |
C語言中的地址包括位置資訊(記憶體編號,或稱純地址)和它所指向的資料的型別資訊,或者說它是“帶型別的地址”,
存盤單元的地址和存盤單元的內容是兩個不同的概念,
在程式中一般是通過變數名來參考變數的值,
直接按變數名進行的訪問,稱為“直接訪問”方式,
//直接訪問
arr[0];
arr[2];
//...
還可以采用另一種稱為“間接訪問”的方式,即將變數的地址存放在另一變數(指標變數)中,然后通過該指標變數來找到對應變數的地址,從而訪問變數,
//間接訪問
*(arr);//arr[0]
*(arr+2);//arr[2]
2.指標
2.1指標型別
指標和變數一樣有不同種類的型別,變數有字符型,整型,浮點型…;指標也有字符型指標,整型指標,浮點型指標…
char*:字符指標型別,指向資料型別為字符型的指標
int*:整型指標型別,指向資料型別為整型的指標
double*:雙精度浮點型指標,
float*:單精度浮點型指標,
unsigned int*:無符號整型指標,
int (*arr)[10]:陣列指標,指向一個陣列的指標,
使用指標型別定義的變數稱為指標變數,如,
int* a = 8;
double* b = 8.6;
char* ch = 'A';
像上面所定義的變數a b ch就稱為指標變數,
正如上舉例所示定義指標變數的格式就是型別名 * 變數名;,
對于指標變數的定義,要注意以下幾點:
💡 指標變數前面的*表示該變數為指標型變數,指標變數名則不包含*
💡 在定義指標變數時必須指定基型別,一個變數的指標的含義包括兩個方面,一是以存盤單元編號表示的純地址(如編號為2000的位元組),一是它指向的存盤單元的資料型別(如int,char,float等),
💡 如何表示指標型別,指向整型資料的指標型別表示為“int *”,讀作“指向int的指標”或簡稱“int指標”,
💡 指標變數中只能存放地址(指標),不要將一個整數賦給一個指標變數,
2.2指標變數的參考
了解指標型別,那指標能干什么呢?
① 給指標變數賦值,
②參考指標變數指向的變數,
③參考指標變數的值,
int a = 8;
int *p = NULL;
p=&a; //把a的地址賦給指標變數p ①
printf("%d\n",*p); //以整數形式輸出指標變數p所指向的變數的值,即a的值 ②
*p=1; //將整數1賦給p當前所指向的變數,由于p指向變數a,相當于把1賦給a,即a=1 ②
printf("%p\n",p); //以輸出指標變數p的值,由于p指向a,相當于輸出a的地址,即&a ③
例題:
輸入a和b兩個整數,不交換a,b變數的值,通過交換a,b地址的方式實作按先大后小的順序輸出a和b,
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
int main()
{
int* p1 = NULL;
int* p2 = NULL;
int* p = NULL; //p1,p2,p的型別是int *型別
int a = 0;
int b = 0;
printf("請輸入兩個整數:\n");
scanf("%d%d", &a, &b); //輸入兩個整數
p1 = &a; //使p1指向變數a
p2 = &b; //使p2指向變數b
if (a < b) //如果a<b
{
p = p1;
p1 = p2;
p2 = p;
} //使p1與p2的值互換
printf("a=%d,b=%d\n", a, b); //輸出a,b
printf("max=%d,min=%d\n", *p1, *p2); //輸出p1和p2所指向的變數的值
return 0;
}
輸出結果:
請輸入兩個整數:
6 8
a=6,b=8
max=8,min=6
D:\gtee\C-learning-code-and-project\test_807\Debug\test_807.exe (行程 10556)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
2.3指標加減運算
我們不難從記憶體中發現,指標實質上也是數字,在記憶體中我們可以觀察到指標是一個十六進制數,既然是一個數,那就可以進行運算,但是我們要進行有意義的運算而不是無意義的運算,比如可以通過指標的加法進行陣列元素的訪問,使用指標的減法可以得到陣列的元素個數,
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
int i = 0;
int size = &arr[10] - &arr[0];//只是獲取arr[10]的地址,并沒有對它進行越界訪問
//使用指標減法獲取陣列元素個數
printf("arr陣列元素個數為:%d\n", size);
for (i = 0; i < size; i++)
{
printf("%d ", *(arr + i));//使用指標加法訪問陣列元素
}
return 0;
}
運行結果:
arr陣列元素個數為:10
1 2 3 4 5 6 7 8 9 0
D:\gtee\C-learning-code-and-project\test_807\Debug\test_807.exe (行程 15840)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
3.野指標
野指標就是指標指向的位置是不可知的(隨機的、不正確的、沒有明確限制的)指標變數在定義時如果未初始化,其值是隨機的,指標變數的值是別的變數的地址,意味著指標指向了一個地址是不確定的變數,此時去解參考就是去訪問了一個不確定的地址,所以結果是不可知的,
3.1野指標的成因
野指標主要是因為這些疏忽而出現的洗掉或申請訪問受限記憶體區域的指標,
💡指標變數未初始化
任何指標變數剛被創建時不會自動成為NULL指標,它的預設值是隨機的,它會亂指一氣,所以,指標變數在創建的同時應當被初始化,要么將指標設定為NULL,要么讓它指向合法的記憶體,如果沒有初始化,部分編譯器會報錯" ‘point’ may be uninitializedin the function ",
#include <stdio.h>
int main()
{
int *p;//區域變數指標未初始化,默認為隨機值
*p = 20;
return 0; }
💡指標釋放后之后未置空
有時指標在free或delete后未賦值 NULL,便會使人以為是合法的,別看free和delete的名字(尤其是delete),它們只是把指標所指的記憶體給釋放掉,但并沒有把指標本身干掉,此時指標指向的就是"垃圾"記憶體,釋放后的指標應立即將指標置為NULL,防止產生"野指標",
#include <stdio.h>
#include <malloc.h>
#include <assert.h>
int main()
{
int* arr = (int*)malloc(sizeof(int) * 4);
assert(arr);
int* p = arr;//拷貝arr地址給p
int i = 0;
for (i = 0; i < 4; i++)
{
*(p + i) = i + 2;
printf("%d ", *(p + i));
}
free(arr);//arr釋放后,p未置空,造成p為野指標
return 0;
}
💡指標操作超越變數作用域
不要回傳指向堆疊記憶體的指標或參考,因為堆疊記憶體在函式結束時會被釋放,
#include <stdio.h>
int main()
{
int arr[10] = {0};
int *p = arr;
int i = 0;
for(i=0; i<=11; i++)
{
//當指標指向的范圍超出陣列arr的范圍時,p就是野指標
*(p++) = i;
}
return 0; }
3.2如何規避野指標
💡指標初始化
💡小心指標越界
💡指標指向空間釋放即使置NULL
💡避免回傳區域變數的地址
💡指標使用之前檢查有效性
4.二級指標
指標變數也是變數,是變數就會有地址,指向指標變數的指標稱為
二級指標,
如果在一個指標變數中存放一個目標變數的地址,這就是單級指標或一級指標;
指向指標資料的指標用的是“二級指標”方法;

從理論上說,間址方法可以延伸到更多的級,即多重指標,

int a = 12;
int* pa = &a;//一級指標
int** ppa = &pa;//二級指標
int*** pppa = &ppa;//三級指標
//各級指標如何訪問a變數
//*pa;
//*ppa = pa; **ppa= a;
//*pppa = ppa; **ppa = pa; ***pppa = a;
5.指標與陣列
陣列名是什么?陣列和指標有什么關系?我們先來運行一個簡單的程式
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
printf("%p\n", arr);
printf("%p\n", &arr[0]);
return 0; }
運行結果
00D0F874
00D0F874
D:\gtee\C-learning-code-and-project\test_807\Debug\test_807.exe (行程 2864)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
唉!我們發現陣列名和陣列首元素地址是一模一樣的,這就說明陣列名存放的是陣列首元素地址,
既然陣列名就是陣列首元素地址,那使用陣列名訪問陣列元素就成了可能,
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
//printf("%d ", *(arr + i));
}
printf("\n");
for (i = 0; i < 10; i++)
{
//printf("%d ", arr[i]);
printf("%d ", *(arr + i));
}
return 0;
}
運行結果
1 2 3 4 5 6 7 8 9 0
1 2 3 4 5 6 7 8 9 0
D:\gtee\C-learning-code-and-project\test_807\Debug\test_807.exe (行程 28064)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%p == %p\n", &arr[i], arr + i);
}
return 0;
}
00D6FC74 == 00D6FC74
00D6FC78 == 00D6FC78
00D6FC7C == 00D6FC7C
00D6FC80 == 00D6FC80
00D6FC84 == 00D6FC84
00D6FC88 == 00D6FC88
00D6FC8C == 00D6FC8C
00D6FC90 == 00D6FC90
00D6FC94 == 00D6FC94
00D6FC98 == 00D6FC98
D:\gtee\C-learning-code-and-project\test_807\Debug\test_807.exe (行程 30132)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
通過上面兩個程式我們可以知道可以使用解參考陣列名的方式訪問陣列的每一個元素,
但是我們發現arr+1并不是將陣列首元素地址加1,而是加了4,
前面,我們討論過了指標的型別,但是你會發現所有型別指標的大小都是一樣的,那現在就有疑問,既然指標大小是一樣的,我使用其他型別的指標來訪問整型陣列會發生什么呢?
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
char* a = (char*)arr;
int i = 0;
for (i = 0; i < 10; i++)
{
*(a + i) = 0;
}
return 0;
}
陣列初始化后,陣列各元素是這樣的
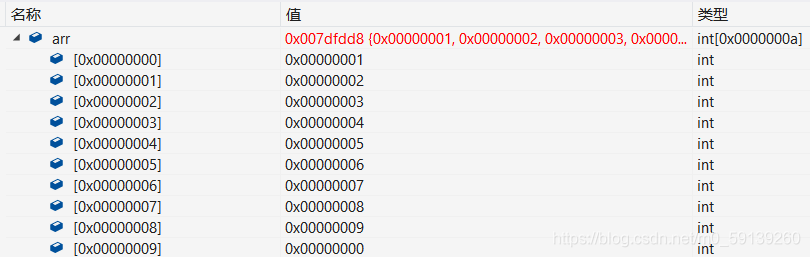
然后我們嘗試使用char型別的指標對陣列進行訪問
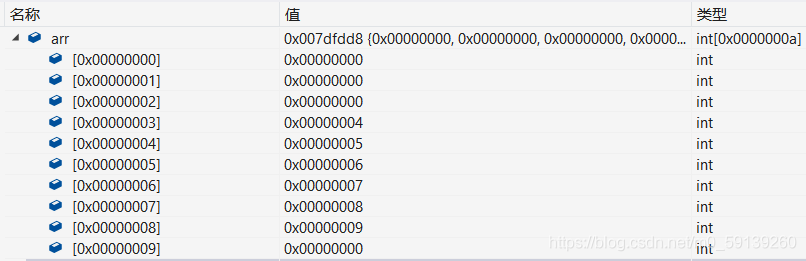
改為0,但是如果各類指標作用一樣應該是10個元素全部被改為0才對,
其實,雖然各類指標大小都一樣(在相同位數平臺下指標大小相同,32位指標大小為4位元組,64位平臺指標大小為8位元組),但是在對不同型別指標進行操作時是有區別的,當指標進行加減運算時,指標加1會加上相應資料型別記憶體大小,比如一個地址0x00000001,char型別指標加1,結果是0x00000002,int型別指標加1是0x00000005,所以也就解釋了上面使用指標加法運算可以順利訪問整型陣列元素,并且每次指標加1,地址都比原來高了4,
總結:
💡在指標已指向一個陣列元素時,可以對指標進行以下運算:
🔑加一個整數(用+或+=),如p+1,表示指向同一陣列中的下一個元素;
🔑減一個整數(用-或-=),如p-1,表示指向同一陣列中的上一個元素;
🔑自加運算,如p++,++p;
🔑自減運算,如p--,--p,
💡兩個指標相減,如p1-p2(只有p1和p2都指向同一陣列中的元素時才有意義),結果是兩個地址之差除以陣列元素的長度,注意: 兩個地址不能相加,如p1+p2是無實際意義的,
💡如果p的初值為&a[0],則p+i和a+i就是陣列元素a[i]的地址,或者說,它們指向a陣列序號為i的元素,
💡*(p+i)或*(a+i)是p+i或a+i所指向的陣列元素,即a[i],[]實際上是變址運算子,即將a[i]按a+i計算地址,然后找出此地址單元中的值,

💡用下標法比較直觀,能直接知道是第幾個元素,適合初學者使用,
💡用地址法或指標變數的方法不直觀,難以很快地判斷出當前處理的是哪一個元素,單用指標變數的方法進行控制,可使程式簡潔、高效,
💡在使用指標變數指向陣列元素時,有以下幾個問題要注意:
🔑可以通過改變指標變數的值指向不同的元素,
如果不用p變化的方法而用陣列名a變化的方法(例如,用a++)行不行呢?
因為陣列名a代表陣列首元素的地址,它是一個指標型常量,它的值在程式運行期間是固定不變的,既然a是常量,所以a++是無法實作的,
🔑 要注意指標變數的當前值,
6.指標與結構體
6.1定義和使用結構體變數
C語言允許用戶自己建立由不同型別資料組成的組合型的資料結構,它稱為
結構體(structure),
struct 結構體名
{
成員表列;
};
結構體型別的名字是由一個關鍵字struct和結構體名組合而成的,結構體名由用戶指定,又稱結構體標記(structure tag) ,
花括號內是該結構體所包括的子項,稱為結構體的成員(member),對各成員都應進行型別宣告,即
型別名 成員名;
比如自定義一個學生資訊的結構體
struct Student
{ int num; //學號為整型
char name[20]; //姓名為字串
char sex; //性別為字符型
int age; //年齡為整型
float score; //成績為實型
char addr[30]; //地址為字串
}; //注意最后有一個分號
💡結構體型別并非只有一種,而是可以設計出許多種結構體型別,各自包含不同的成員,
💡成員可以屬于另一個結構體型別,

struct Date //宣告一個結構體型別 struct Date
{ int month; //月
int day; //日
int year; //年
};
struct Student //宣告一個結構體型別 struct Student
{ int num;
char name[20];
char sex;
int age;
struct Date birthday; //成員birthday屬于struct Date型別
char addr[30];
};
💡先宣告結構體型別,再定義該型別的變數
struct Student
{ int num; //學號為整型
char name[20]; //姓名為字串
char sex; //性別為字符型
int age; //年齡為整型
float score; //成績為實型
char addr[30]; //地址為字串
}; //注意最后有一個分號
struct Student student;
| |
結構體型別名 結構體變數名
💡在宣告型別的同時定義變數
struct 結構體名
{
成員表列
}變數名表列;
struct Student
{ int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
}student;
💡不指定型別名而直接定義結構體型別變數
struct
{
成員表列
}變數名表列;
💡結構體型別與結構體變數是不同的概念,不要混淆,只能對變數賦值、存取或運算,而不能對一個型別賦值、存取或運算,在編譯時,對型別是不分配空間的,只對變數分配空間,
💡結構體型別中的成員名可以與程式中的變數名相同,但二者不代表同一物件,
💡對結構體變數中的成員(即“域”),可以單獨使用,它的作用與地位相當于普通變數,
6.2結構體的初始化與訪問
💡在定義結構體變數時可以對它的成員初始化,初始化串列是用花括號括起來的一些常量,這些常量依次賦給結構體變數中的各成員,對結構體變數初始化,不是對結構體型別初始化,
💡可以參考結構體變數中成員的值,參考方式為結構體變數名.成員名或結構體指標->成員名
💡“.”是成員運算子,它在所有的運算子中優先級最高,結構體變數名.成員名或結構體指標->成員名作為一個整體來看待,相當于一個變數,
💡不能企圖通過輸出結構體變數名來輸出結構體變數所有成員的值,只能對結構體變數中的各個成員分別進行輸入和輸出,
💡如果成員本身又屬一個結構體型別,則要用若干個成員運算子,一級一級地找到最低的一級的成員,只能對最低級的成員進行賦值或存取以及運算,
💡對結構體變數的成員可以像普通變數一樣進行各種運算(根據其型別決定可以進行的運算),
💡同類的結構體變數可以互相賦值,
💡可以參考結構體變數成員的地址,也可以參考結構體變數的地址(結構體變數的地址主要用作函式引數,傳遞結構體變數的地址),但不能用以下陳述句整體讀入結構體變數,
//結構體初始化與訪問
struct st
{
int a;
double b;
};
struct st c = {24,78.89};//初始化
c.a = 12;
c.b = 86.98;//使用結構體變數名進行結構體訪問
(&c) -> a =14;
(&c) -> b = 99.88;//使用指標進行結構體訪問
例題:
建立一個結構體,把一個學生的資訊(包括學號、姓名、性別、年齡,成績,住址)放在一個結構體變數中,然后輸出這個學生的資訊,

#include <stdio.h>
struct Student //宣告結構體型別struct Student
{
long int num; //以下6行為結構體的成員
char name[20];
char sex[4];
int age;
double score;
char addr[20];
}; //定義結構體
int main()
{
struct Student a = { 123456,"張三","男",18,99.5,"湖南"}; //定義結構體變數a并初始化
printf("num:%ld\nname:%s\nsex:%s\nage:%d\nscore:%.2lf\naddr:%s\n", a.num, a.name, a.sex,a.age,a.score, a.addr);
return 0;
}
運行結果
num:123456
name:張三
sex:男
age:18
score:99.50
addr:湖南
D:\gtee\C-learning-code-and-project\test_807\Debug\test_807.exe (行程 24868)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
6.3結構體指標
所謂
結構體指標就是指向結構體變數的指標,一個結構體變數的起始地址就是這個結構體變數的指標,如果把一個結構體變數的起始地址存放在一個指標變數中,那么,這個指標變數就指向該結構體變數,
將一個結構體變數的值傳遞給另一個函式,有3個方法:
🔑用結構體變數的成員作引數,
例如,用st1.mame或st2.name作函式實參,將實參值傳給形參,用法和用普通變數作實參是一樣的,屬于“值傳遞”方式,應當注意實參與形參的型別保持一致,
🔑用結構體變數作實參,
用結構體變數作實參時,采取的也是“值傳遞”的方式,將結構體變數所占的記憶體單元的內容全部按順序傳遞給形參,形參也必須是同型別的結構體變數,在函式呼叫期間形參也要占用記憶體單元,這種傳遞方式在空間和時間上開銷較大,如果結構體的規模很大時,開銷是巨大的,此外,由于采用值傳遞方式,如果在執行被呼叫函式期間改變了形參(也是結構體變數)的值,該值不能回傳主調函式,這往往造成使用上的不便,因此一般較少用這種方法,
🔑用指向結構體變數(或陣列元素)的指標作實參,將結構體變數(或陣列元素)的地址傳給形參,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292777.html
標籤:其他
上一篇:函式堆疊幀詳解
下一篇:尋找那些神奇的自冪數---C語言