一定要搞定指標啊!!!
- Part I、說在前面兒
- Part II、指標它是個啥?
- 1、地址
- 2、指標的指向作用
- 2、地址與資料
- 3、解參考
- 4、二級指標
- 5、傳址呼叫
- Part III、資料結構里的指標
- 1、不帶頭單鏈表
- 2、帶頭鏈表
- Part IV、總結一下(都是精華啊)
Part I、說在前面兒
正在學習資料結構的同學,尤其是正在學習鏈表的同學往往會有這樣的疑問:為什么有的地方傳一級指標,有的地方傳二級指標?為什么帶頭跟不帶頭差別那么大…對于C語言的基礎,尤其是指標的基礎不是那么好的同學,資料結構簡直就是勸退的攔路虎,
說到這里不知道你的DNA是不是動了一下呢?頭又暈了?沒關系,今天我們就來克服指標恐懼癥!
Part II、指標它是個啥?
我們想理清指標,就先從它的本質說起,別劃過,基礎不牢,地動山搖哈,
1、地址
電腦的記憶體可以按照位元組劃分,為了區分這些位元組,我們用十六進制數字給它們進行編號,這些編號就是所謂的地址,
關鍵字提煉:地址對應記憶體上的一個位元組
2、指標的指向作用
指標,就是個箭頭,生活中我們見過路牌,見過指南針,它們都差不多,都是引路者,路牌和指南針都能帶我們回家,而指標的作用,也是告訴我們地址,
試問:路牌沒了,路還在嗎?
答案是不是很明顯?當然存在!
所以這里就要明白第一個點:指標只能告訴我們地址,指引我們找到一塊記憶體,但是當這個指標被我們銷毀,或者說,讓它指向別的地方了,這塊記憶體上的東西是不是還在?是!
2、地址與資料
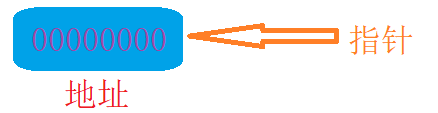
我們知道,指標里存盤的是一塊地址,那這塊地址上存盤的內容是啥呢?
舉個例子,假設我們有一個int型別的變數a,里面存盤著資料1,十六進制表示就是0x00000001,那么他在記憶體中的存盤形式就是這樣的:
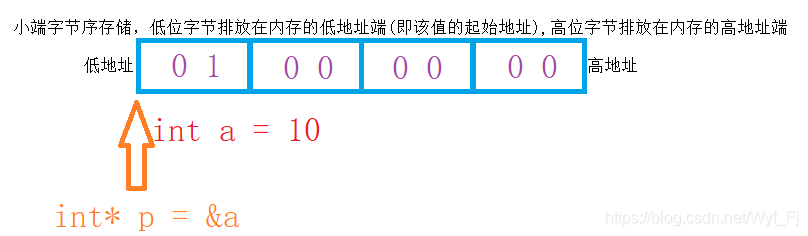
a占四個位元組,而一個變數只對應了一個指標,這個指標保存的是第一個位元組,
可以看到:指標p保存的是地址,而地址對應位元組上的內容,
3、解參考
一個東西的存在讓指標有了新的能力——解參考符號*
如果說指標是路牌,那解參考就是一輛車,有了指向,有了車,我們就可以直達那塊“地址”!
既然到了這塊地址,那么我們能做的就多了:利用這塊地址上的東西,或者改變這塊地址上的東西,
提煉:指標存盤的是地址,對指標解參考其實就是對地址解參考,地址對應記憶體,地址上的東西也就是記憶體上存盤的資料,解參考的操作就是賦予我們訪問和改變這些資料的能力!
4、二級指標
認識了解參考,我們就能學習下一個東西了:二級指標,二級指標又是個啥呢?
首先我們需要清楚一點:指標是不是資料?
指標當然是資料!這個資料就是地址,而地址的本質其實是十六進制的資料,這些資料存放在一種叫指標的變數當中,
既然要存盤資料,那么指標是不是也占記憶體?既然是記憶體,那么它是不是也有一個地址?這個地址就可以存放在一個二級指標當中,
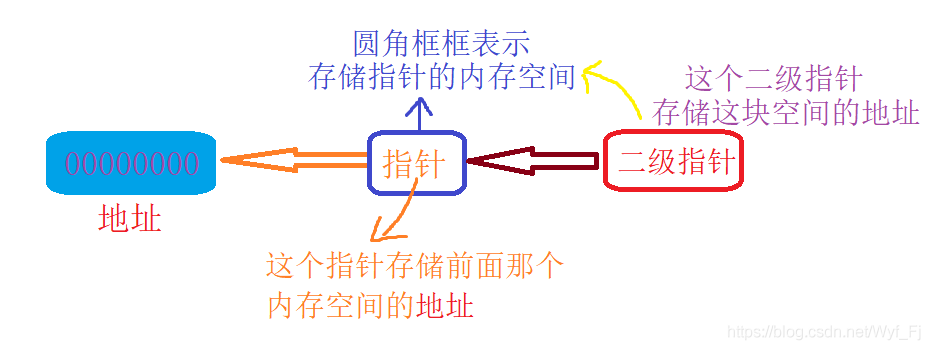
如果我們對二級指標解參考,就可以獲得一級指標上存盤的內容(也是一個地址),然后再解參考,就能獲得一級指標存盤的地址上存盤的資料,(有點繞哦,對應這上面的圖理一下)
ok,繼續!
5、傳址呼叫
這個很重要!!!這個很重要!!!這個很重要!!!
為什么有傳址呼叫這個東西?因為形參與實參之間幾乎沒有任何聯系,實參對應一個地址,形參對應另外一個地址,當我們改變形參,只是把它的地址上存的資料改了,但是實參對應的地址上的東西還是沒變,
那如果我們傳的是實參的地址呢?此時形參就是一級指標,這個指標存盤的是實參的地址,對它進行解參考,就能訪問或修改實參的地址上存盤的資料了!
典型的例子就是交換兩個數的Swap函式,
void Swap(int* x , int*y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
認識了這些,就讓我們直接進入資料結構的正題,
Part III、資料結構里的指標
1、不帶頭單鏈表
鏈表的節點的定義一上來就會給我們一個下馬威:
typedef struct Node
{
int data;
struct Node* next;
}Node;
這里有一個自參考next,它指向的也是一個Node型別的指標,
意思就是說:
一個節點存一個資料,然后又存了一個指標,這個指標的內容是下一個節點的地址,換句話說,這個指標指向下一個節點,因此鏈表才能真正意義上“鏈接”起來,

我們定義了一個pList指標專門指向鏈表的第一個節點,也就是頭(head),因為它指向一個節點,所以它是一個Node型別的指標,即Node*,
由于一開始鏈表沒有元素,自然也沒有頭結點,所以我們令pList = NULL,讓它指向空,
緊接著我們就會寫頭插頭刪和尾插尾刪函式,于是,詭異的二級指標就來了,
我們不妨看一個頭插函式的原型:
void SListPushFront(Node** ppList, int x);
而我們呼叫它時就要這樣:
void SListPushFront(&pList,0);
為什么要取地址呢?換句話說,為什么要傳址呢?
原因很簡單:因為我們的操作會改變這里的pList,(注意改變二字)
頭插意味著鏈表的頭不再是當前pList指向的那個節點,而是另一個新插入的newnode,我們讓newnode的next指向當前的pList,然后再讓pList指向newnode,
但是,如果傳的是pList而不是&pList,那么由于傳值呼叫,形參的改變不影響實參——盡管你讓形參指向了newnode,但是pList存盤的還是之前的那個節點的地址,然后出現這樣的窘境:
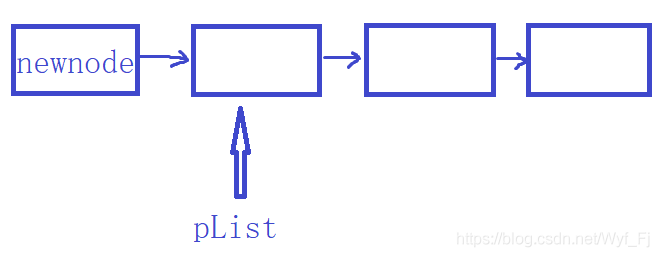
pList指向鏈表的第二個結點而非第一個,
以后我們遍歷鏈表都是從pList指向的位置開始的,但是pList由于是傳值,它永遠都指向同一塊地方,不會改變,因此我們能遍歷到的,也永遠只有從當前位置開始,到NULL結束,
那么為什么尾插尾刪這些函式也要傳二級指標呢?設想:如果鏈表為空,尾插的那個元素就是新的頭結點,是不是就會改變pList?如果鏈表只有一個元素,此時它就是鏈表的頭,那尾刪是不是也會改變pList?
總而言之,對于不帶頭的鏈表來說,可能改變鏈表的頭的函式,都要用二級指標,只有傳二級指標,也就是pList的地址,才能在函式的內部改變pList,讓pList指向新的頭!
2、帶頭鏈表
同學們好不容易弄清鏈表需要傳二級指標,突然又遇到了一種不用傳二級指標的鏈表,啥情況??不讓人活了?別慌,讓我們一起看看,
帶頭的鏈表與不帶頭的鏈表的區別就是:不帶頭的鏈表用一個pList指標來維護,而帶頭的鏈表用一個哨兵位來維護,什么是哨兵位?其實哨兵位也是一個結點,但是它并不存盤任何的有效資料,
與不帶頭的單鏈表相比,帶哨兵位的好處多多,這個在各位刷到鏈表相關的演算法題之后就能察覺到,它能帶來很多代碼上的優化,可以少考慮很多邊界情況,
不過當前, 它的最大的優點就是:不用傳二級指標,為啥?
ListNode* list = ListCreate();
我們先創建一個哨兵位list,
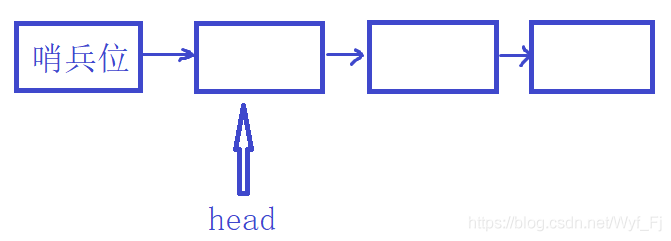
可以看到,哨兵位是頭結點前的一個節點,頭結點的地址就是哨兵位的next指標存盤的內容,
當我們進行傳參時,直接把list這個指標傳給形參,形參作為實參的臨時拷貝,里面存盤的內容就跟list指標完全一樣,也就是說:
形參里也有一個指標,這個指標存盤的內容跟哨兵位的next指標存盤的內容一樣,都是頭結點的地址!有了這個地址,我們就可以修改這個地址上的內容,也就是說:修改頭結點,
看到這里,我們應該明白:1、形參和實參的next指標肯定是兩個不同的變數,但是它們存盤的內容是相同的,都是頭結點的地址,2、只要有地址,我們就能修改地址上的內容,無所謂存盤這個地址的指標是誰,
剛剛不帶哨兵位的情況下,pList需要傳二級指標,因為它需要始終保持指向頭指標,而這里的list永遠指向的是哨兵位,head的改變只會影響list的next,當我們直接傳list時,形參部分接收的就是list的內容(包括那個指向頭結點的指標),通過它我們就可以直接訪問list里的next,從而改變它,
Part IV、總結一下(都是精華啊)
想玩轉指標,最重要的是什么?是要知道:
1、指標存盤的是地址
2、地址對應記憶體
3、只要我們能得到這個地址,就能通過解參考訪問或修改對應記憶體上的資料
4、如果傳址,形參接收實參的地址,對形參解參考得到的就是實參這個物體,
5、如果是傳值,形參會復刻實參的內容,如果內容中存在指標,那么我們同樣可以通過這個指標修改對應記憶體上的資料,
6、如果我們想通過形參達到修改實參的目的,必須要傳址!
最重要的一點:對于實參是指標的情況,如果我們僅僅想操作它存盤的地址上的內容,那么傳值就足夠了,如果還想額外地改變實參,讓實參存盤別的地址,那么就需要傳地址了!
不知道讀者聽懂了嘛,有任何問題可以在評論區反饋給我哦
關注筆者,一起學習,一起進步!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/292998.html
標籤:其他