零、前言
??「 資料結構 」 和 「 演算法 」 是密不可分的,兩者往往是「 相輔相成 」的存在,所以,在學習 「 資料結構 」 的程序中,不免會遇到各種「 演算法 」,
??到底是先學 資料結構 ,還是先學 演算法,我認為不必糾結這個問題,一定是一起學的,
??資料結構 常用的操作一般為:「 增 」「 刪 」「 改 」「 查 」,基本上所有的資料結構都是圍繞這幾個操作進行展開的,
??那么這篇文章,作者將用 「 七張動圖 」 來闡述一種最基礎的鏈式結構
「 單向鏈表 」
🙉飯不食,水不飲,題必須刷🙉
C語言免費動漫教程,和我一起打卡! 🌞《光天化日學C語言》🌞
LeetCode 太難?先看簡單題! 🧡《C語言入門100例》🧡
資料結構難?不存在的! 🌳《畫解資料結構》🌳
LeetCode 太簡單?演算法學起來! 🌌《夜深人靜寫演算法》🌌
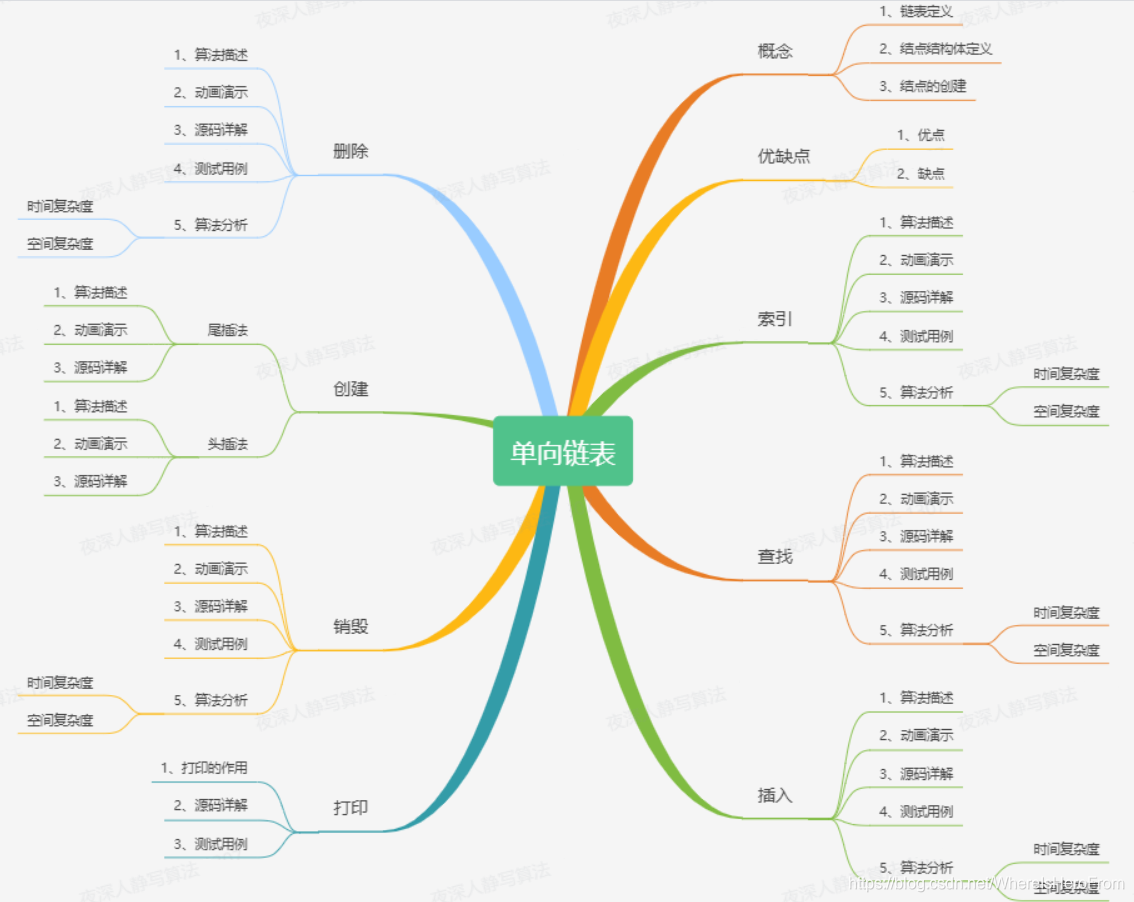
??今天要講的內容,濃縮一下就是下面這張圖:
??看不懂沒有關系,我會把它拆開來一個一個講,首先來看一些簡單的概念,
一、概念
- 對于順序存盤的結構,如陣列,最大的缺點就是:插入 和 洗掉 的時候需要移動大量的元素,所以,基于前人的智慧,他們發明了鏈表,
1、鏈表定義
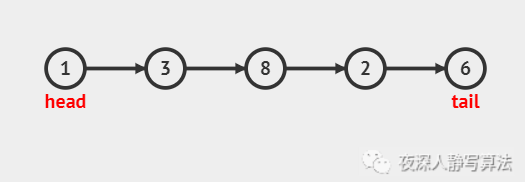
??鏈表 是由一個個 結點 組成,每個 結點 之間通過 鏈接關系 串聯起來,每個 結點 都有一個 后繼節點,最后一個 結點 的 后繼結點 為 空結點,如下圖所示:
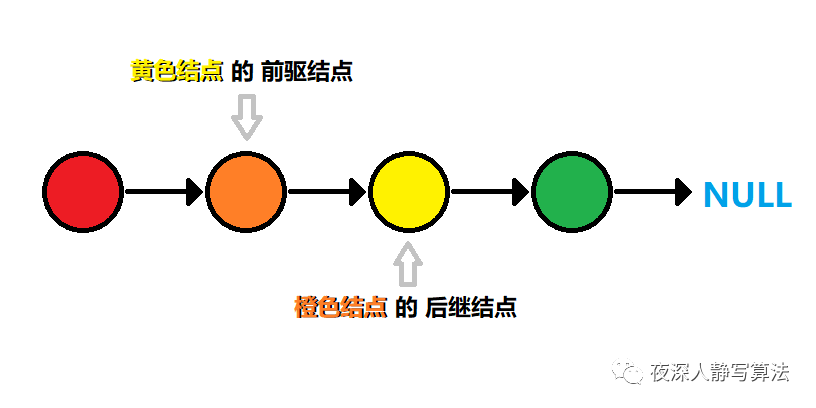
- 由鏈接關系
A -> B組織起來的兩個結點,B被稱為A的后繼結點,A被稱為B的前驅結點, - 鏈表 分為 單向鏈表、雙向鏈表、回圈鏈表 等等,本文要介紹的鏈表是 單向鏈表,
- 由于鏈表是由一個個 結點 組成,所以我們先來看下 結點 的實作,
2、結點結構體定義
typedef int DataType;
struct ListNode {
DataType data; // (1)
ListNode *next; // (2)
};
-
(
1
)
(1)
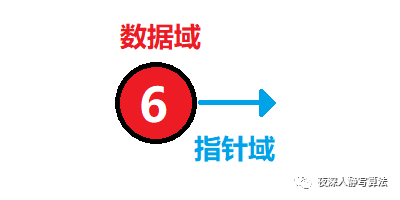
(1) 資料域:可以是任意型別,由編碼的人自行指定;這段代碼中,利用
typedef將它和int同名,本文的 資料域 也會全部采用int型別進行講解; - ( 2 ) (2) (2) 指標域:指向 后繼結點 的地址;
- 一個結點包含的兩部分如下圖所示:
3、結點的創建
- 我們通過 C語言 中的庫函式
malloc來創建一個 鏈表結點,然后對 資料域 和 指標域 進行賦值,代碼實作如下:
ListNode *ListCreateNode(DataType data) {
ListNode *node = (ListNode *) malloc ( sizeof(ListNode) ); // (1)
node->data = data; // (2)
node->next = NULL; // (3)
return node; // (4)
}
-
(
1
)
(1)
(1) 利用系統庫函式
malloc分配一塊記憶體空間,用來存放ListNode即鏈表結點物件; -
(
2
)
(2)
(2) 將 資料域 置為函式傳參
data; - ( 3 ) (3) (3) 將 指標域 置空,代表這是一個孤立的 鏈表結點;
- ( 4 ) (4) (4) 回傳這個結點的指標,
- 創建完畢以后,這個孤立結點如下所示:
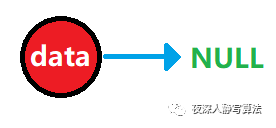
二、鏈表的創建 - 尾插法
- 那么接下來,讓我們看下如何通過一個 陣列中的資料 來創建一個鏈表,
1、演算法描述
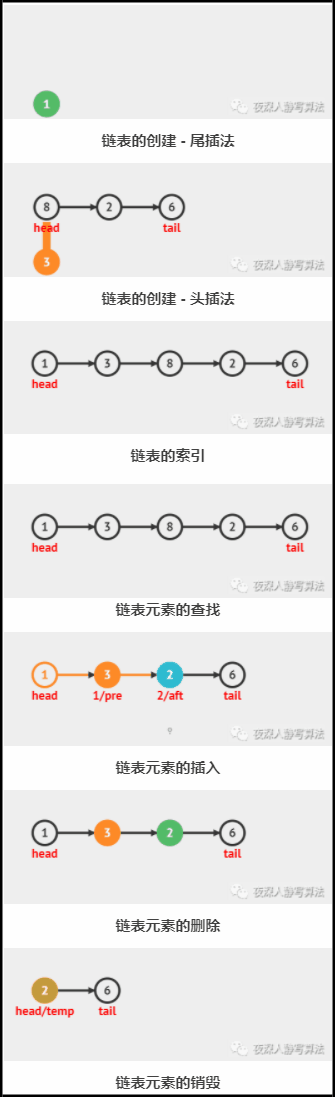
??首先介紹 尾插法 ,顧名思義,即 從鏈表尾部插入 的意思,就是記錄一個 鏈表尾結點,然后遍歷給定陣列,將陣列元素一個一個插到鏈表的尾部,每插入一個結點,則將它更新為新的 鏈表尾結點,注意初始情況下,鏈表尾結點 為空,
2、影片演示

上圖演示的是 尾插法 的整個程序,其中:
??head 代表鏈表頭結點,創建完一個結點以后,它就保持不變了;
??tail 代表鏈表尾結點,即動圖中的 綠色結點;
??vtx 代表正在插入鏈表尾部的結點,即動圖中的 橙色結點,插入完畢以后,vtx 變成 tail;
- 看完這個動圖,你應該已經大致理解了 鏈表的創建程序,那么接下來,我們用程式語言來描述一下整個程序,這里采用的是 C語言 的形式,如果你是 Java、C#、Python 技術堆疊的,也可以試著寫出自己的版本,
- 語言并不是關鍵,思維才是關鍵,
3、原始碼詳解
- C語言 實作如下:
ListNode *ListCreateListByTail(int n, int a[]) {
ListNode *head, *tail, *vtx; // (1)
int idx;
if(n <= 0)
return NULL; // (2)
idx = 0;
vtx = ListCreateNode(a[0]); // (3)
head = tail = vtx; // (4)
while(++idx < n) { // (5)
vtx = ListCreateNode(a[idx]); // (6)
tail->next = vtx; // (7)
tail = vtx; // (8)
}
return head; // (9)
}
對應的注釋如下:
?? ( 1 ) (1) (1)head存盤頭結點的地址,tail存盤尾結點的地址,vtx存盤當前正在插入結點的地址;
?? ( 2 ) (2) (2) 當需要創建的元素個數為 0 時,直接回傳空鏈表;
?? ( 3 ) (3) (3) 創建一個 資料域 為a[0]的鏈表結點;
?? ( 4 ) (4) (4) 由于初始情況下只有一個結點,所以將鏈表頭結點head和鏈表尾結點tail都置為vtx;
?? ( 5 ) (5) (5) 從陣列第 1 個元素 (0 - based) 開始,回圈遍歷陣列;
?? ( 6 ) (6) (6) 由于陣列中第 0 個元素已經創建過了,所以這里只需要對除了第 0 個元素以外的資料創建鏈表結點;
?? ( 7 ) (7) (7) 結點創建出來后,將當前鏈表尾結點tail的 后繼結點 置為vtx;
?? ( 8 ) (8) (8) 將最近創建的結點vtx作為新的 鏈表尾結點;
?? ( 9 ) (9) (9) 回傳鏈表頭結點;
- 尾插法 比較符合直觀的思維邏輯,但是就代碼量來說還是有點長(注意:在實作相同功能的情況下,代碼應該是越簡潔,越簡單越好的),
- 于是,我們引入了另一種創建鏈表的方式 —— 頭插法,
三、鏈表的創建 - 頭插法
1、演算法描述
??頭插法,顧名思義,就是每次從頭結點前面進行插入,但是這樣一來,就會導致插入的資料元素是 逆序 的,所以我們需要 逆序訪問陣列 執行插入,此所謂 負負得正 的思想,
- 它的特點是代碼量短,且 常數時間復雜度 低,雖然沒有 尾插法 那么直觀,但是代碼簡潔,更加容易閱讀,
2、影片演示

上圖所示的是 頭插法 的整個插入程序,其中:
??head 代表鏈表頭結點,即動圖中的 綠色結點,每新加一個結點,頭結點就變成了新加入的結點;
??tail 代表鏈表尾結點,創建完一個結點以后,它就保持不變了;
??vtx 代表正在插入鏈表頭部的結點,即動圖中的 橙色結點,插入完畢以后,vtx 變成 head;
3、原始碼詳解
ListNode *ListCreateListByHead(int n, int *a) {
ListNode *head = NULL, *vtx; // (1)
while(n--) { // (2)
vtx = ListCreateNode(a[n]); // (3)
vtx->next = head; // (4)
head = vtx; // (5)
}
return head; // (6)
}
對應的注釋如下:
?? ( 1 ) (1) (1)head存盤頭結點的地址,初始為空鏈表,vtx存盤當前正在插入結點的地址;
?? ( 2 ) (2) (2) 總共需要插入 n n n 個結點,所以采用逆序的 n n n 次回圈;
?? ( 3 ) (3) (3) 創建一個元素值為a[i]的鏈表結點,注意,由于逆序,所以這里 i i i 的取值為 n ? 1 → 0 n-1 \to 0 n?1→0;
?? ( 4 ) (4) (4) 將當前創建的結點的 后繼結點 置為 鏈表的頭結點head;
?? ( 5 ) (5) (5) 將鏈表頭結點head置為vtx;
?? ( 6 ) (6) (6) 回傳鏈表頭結點;
- 頭插法 的代碼量比 尾插法 少了三分之一,而且將 創建結點的邏輯 統一起來了,這句話什么意思呢?仔細觀察可以發現,尾插法 在實作程序中,
ListCreateNode在代碼里出現了兩次,而 頭插法 只出現了一次,將流程簡化了,所以還是推薦使用 頭插法,
四、鏈表的列印
1、列印的作用
- 可視化 能夠幫助我們更好的理解資料結構,所以,對于一種資料結構,如何通過 輸出函式 將它 列印到控制臺 上,就成了我們接下來要做的事情,
- 我會用 C語言 來實作,但是只要你掌握了這套自己驗證的方法,那么就算用其他語言,一樣可以驗證自己代碼的正確性,
那么,如何列印一個鏈表呢?我們可以這么思考:
??鏈表的每個結點都有一個 后繼結點 ,我們可以用A -> B代表結點B是結點A的 后繼結點,而對于最后一個結點而言,它的后繼可以用NULL表示,所以,我們可以回圈輸出所有結點并且帶上->,然后在最后加上NULL,
2、原始碼詳解
- C語言實作如下:
void ListPrint(ListNode *head) {
ListNode *vtx = head;
while(vtx) { // (1)
printf("%d -> ", vtx->data); // (2)
vtx = vtx->next; // (3)
}
printf("NULL\n"); // (4)
}
對應的注釋如下:
?? ( 1 ) (1) (1) 從頭結點開始,回圈遍歷所有結點;
?? ( 2 ) (2) (2) 遍歷到的結點,將結點的 資料域 帶上->后輸出;
?? ( 3 ) (3) (3) 將 當前結點 置為 當前結點 的 后繼結點,繼續迭代;
?? ( 4 ) (4) (4) 最后輸出一個NULL,代表一個完整的鏈表;
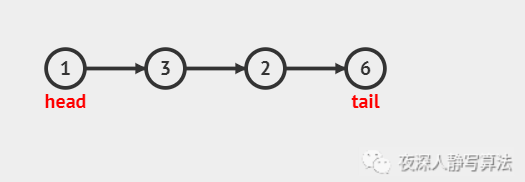
- 對于上面例子中的鏈表,呼叫這個函式,得到的結果為:
1 -> 3 -> 8 -> 2 -> 6 -> NULL
3、測驗用例
- 例如,我們在 頭插法 的實作程序中,加上一句 鏈表的列印 陳述句,代碼實作如下:
ListNode *ListCreateListByHead(int n, int *a) {
ListNode *head = NULL, *vtx;
while(n--) {
vtx = ListCreateNode(a[n]);
vtx->next = head;
head = vtx;
ListPrint(head); /*看這里,看這里!*/
}
return head;
}
- 運行后得到的結果如下:
6 -> NULL
2 -> 6 -> NULL
8 -> 2 -> 6 -> NULL
3 -> 8 -> 2 -> 6 -> NULL
1 -> 3 -> 8 -> 2 -> 6 -> NULL
- 這樣,我們就能更加進一步的確保我們實作 頭插法 這個演算法的正確性了,
驗證演算法的正確性有兩個有效的辦法:
?? ( 1 ) (1) (1) 構造大量的 測驗資料 進行輸入輸出測驗;
?? ( 2 ) (2) (2) 列印每一個操作后,資料結構的 當前狀態,看是否和預期相符;
- 對 鏈表 進行列印,就是利用了這里的第 ( 2 ) (2) (2) 點,這個方法雖然原始,但是能夠讓你對每一步操作都了然于胸, 尤其是寫到后面,代碼量爆炸的時候,這個方法往往能夠讓你規避很多不必要的邏輯錯誤,
五、鏈表元素的索引
1、演算法描述
??給定一個鏈表頭結點
head,并且給定一個索引值 i ( i ≥ 0 ) i (i \ge 0) i(i≥0),求這個鏈表的第 i i i 個結點(為了和 C語言 的陣列下標保持一致,我們假定鏈表頭結點代表第 0 個結點),
- 這實際上是一個 遍歷鏈表 的程序,我們先來看下影片演示,
2、影片演示
上圖演示的是通過遍歷,索引到第 3 個結點(下標從 0 開始計數)的程序,其中:
??head 代表鏈表頭結點;
??tail 代表鏈表尾結點;
??j / temp 代表當前列舉到的第 j ( j ≥ 0 ) j (j \ge 0) j(j≥0)個結點,即動圖中的 橙色實心結點;
3、原始碼詳解
ListNode *ListGetNode(ListNode *head, int i) {
ListNode *temp = head; // (1)
int j = 0; // (2)
while(temp && j < i) { // (3)
temp = temp->next; // (4)
++j; // (5)
}
if(!temp || j > i) {
return NULL; // (6)
}
return temp; // (7)
}
-
(
1
)
(1)
(1)
temp代表從鏈表頭開始的 游標指標,用于對鏈表進行 遍歷 操作; -
(
2
)
(2)
(2)
j代表當前訪問到了第 j j j 個結點; -
(
3
)
(3)
(3) 如果 游標指標 非空,并且
j < i,則代表還沒訪問到目標結點,繼續執行回圈; - ( 4 ) (4) (4) 將 游標指標 的 后繼結點 作為新一輪的 游標指標,繼續迭代;
-
(
5
)
(5)
(5)
j自增,等價于j = j + 1; -
(
6
)
(6)
(6) 當 游標指標 為空,或者
j > i,則說明給定的i超過了鏈表長度,回傳 空結點; -
(
7
)
(7)
(7) 最后,回傳找到的第
i個結點;
4、測驗用例
void testListGetNode(ListNode *head) {
int i;
for(i = 0; i < 7; ++i) {
ListNode *node = ListGetNode(head, i);
if(!node)
printf("index(%d) is out of range.\n", i);
else
printf("node(%d) is %d.\n", i, node->data);
}
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a); // (1)
testListGetNode(head); // (2)
return 0;
}
- 這個測驗用例,首先第 ( 1 ) (1) (1) 步,利用 頭插法 對給定陣列創建了一個鏈表;然后第 ( 2 ) (2) (2) 步,列舉 i ∈ [ 0 , 6 ] i \in [0, 6] i∈[0,6],分別去取鏈表的第 i i i 個結點,運行結果如下:
node(0) is 1.
node(1) is 3.
node(2) is 8.
node(3) is 2.
node(4) is 6.
index(5) is out of range.
index(6) is out of range.
- 這表明當下標在鏈表元素個數范圍內時,能夠找到對應結點;否則,回傳的是空節點;進一步驗證了程式實作的正確性,
5、演算法分析
1)時間復雜度
- 索引結點的操作,最壞情況下需要遍歷整個鏈表,所以時間復雜度為 O ( n ) O(n) O(n),
2)空間復雜度
- 整個索引程序只記錄了兩個變數:游標結點 和 當前索引值,和鏈表長度無關,所以空間復雜度為 O ( 1 ) O(1) O(1),
六、鏈表元素的查找
1、演算法描述
??給定一個鏈表頭
head,并且給定一個值 v v v,查找出這個鏈表上 資料域 等于 v v v 的第一個結點,
- 查找的程序,基本和索引類似,也是對鏈表的遍歷操作,首先請看影片演示,
2、影片演示
上圖演示的是通過遍歷,查找到值為 2 的結點的程序,其中:
??head 代表鏈表頭結點;
??tail 代表鏈表尾結點;
??j / temp 代表當前列舉到的第 j ( j ≥ 0 ) j (j \ge 0) j(j≥0)個結點,即動圖中的 橙色實心結點;
3、原始碼詳解
ListNode *ListFindNodeByValue(ListNode *head, DataType v) {
ListNode *temp = head; // (1)
while(temp) { // (2)
if(temp->data == v) {
return temp; // (3)
}
temp = temp->next; // (4)
}
return NULL; // (5)
}
-
(
1
)
(1)
(1)
temp代表從 鏈表頭 開始遍歷的 游標指標; - ( 2 ) (2) (2) 如果 游標指標 非空,繼續回圈 ;
-
(
3
)
(3)
(3) 一旦發現 資料域 和 給定的 引數
v相等,立即回傳該結點對應的指標; - ( 4 ) (4) (4) 否則,將 游標指標 的 后繼結點 作為新一輪的 游標指標,繼續迭代;
- ( 5 ) (5) (5) 一直到鏈表尾都找不到,回傳 NULL;
4、測驗用例
void testListFindNodeByValue(ListNode *head) {
int i;
for(i = 1; i <= 6; ++i) {
ListNode *node = ListFindNodeByValue(head, i);
if(!node)
printf("value(%d) is not found!\n", i);
else
printf("value(%d) is found!\n", i);
}
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a);
testListFindNodeByValue(head);
return 0;
}
- 這個測驗用例,就是選擇了
[
1
,
6
]
[1, 6]
[1,6] 這六個數,然后依次利用
ListFindNodeByValue去鏈表中查找,運行結果如下:
value(1) is found!
value(2) is found!
value(3) is found!
value(4) is not found!
value(5) is not found!
value(6) is found!
5、演算法分析
1)時間復雜度
- 查找結點的操作,最壞情況下就是找不到,需要遍歷整個鏈表,所以時間復雜度為 O ( n ) O(n) O(n),
2)空間復雜度
- 整個查找程序只記錄了一個變數:游標指標,和鏈表長度無關,所以空間復雜度為 O(1),
七、鏈表結點的插入
1、演算法描述
??給定一個鏈表頭
head,并且給定一個位置 i ( i ≥ 0 ) i(i \ge 0) i(i≥0) 和 一個值 v v v,求生成一個值為 v v v 的結點,并且將它插入到 鏈表 第 i i i 個結點之后,
- 首先,我們需要找到第 i i i 個位置,可以利用上文提到的 鏈表結點的索引;然后,再執行插入操作,而插入操作分為兩步:第一步就是 創建結點 的程序;第二步,是斷開之前第 i i i 個結點 和 第 i + 1 i+1 i+1 個結點之間的 “鏈”,并且將創建出來的結點 “鏈接” 到兩者之間,來看下動圖演示,
2、影片演示
上圖演示的是通過遍歷,將資料為 8 的結點插入到鏈表第 1 個(下標從 0 開始)結點后的程序,其中:
??head 代表鏈表頭結點;
??tail 代表鏈表尾結點;
??pre 代表待插入結點的 前驅結點,也是 游標指標 指代的結點,即動圖中的 橙色實心結點;
??aft 代表 待插入結點 的 后繼結點,即動圖中的 藍色實心結點;
??vtx 代表將要插入的結點,即動圖中的 綠色實心結點;
3、原始碼詳解
ListNode *ListInsertNode(ListNode *head, int i, DataType v) {
ListNode *pre, *vtx, *aft; // (1)
int j = 0; // (2)
pre = head; // (3)
while(pre && j < i) { // (4)
pre = pre->next; // (5)
++j; // (6)
}
if(!pre) {
return NULL; // (7)
}
vtx = ListCreateNode(v); // (8)
aft = pre->next; // (9)
vtx->next = aft; // (10)
pre->next = vtx; // (11)
return vtx; // (12)
}
-
(
1
)
(1)
(1) 預先定義三個指標,當結點插入完畢后,
pre -> vtx -> aft; -
(
2
)
(2)
(2) 定義一個計數器,當
j == i時,表明找到要插入的位置; - ( 3 ) (3) (3) 從 鏈表頭結點 開始迭代遍歷鏈表;
- ( 4 ) (4) (4) 如果還沒有到鏈表尾,或者沒有找到插入位置則繼續回圈;
- ( 5 ) (5) (5) 將 游標指標 的 后繼結點 作為新一輪的 游標指標,繼續迭代;
- ( 6 ) (6) (6) 計數器加 1;
- ( 7 ) (7) (7) 元素個數不足,無法找到給定位置,回傳 NULL;
-
(
8
)
(8)
(8) 創建一個值為
v的 孤立結點; -
(
9
)
→
(
11
)
(9) \to (11)
(9)→(11) 這三步就是為了將
vtx插入到pre -> aft之間,插入完畢后pre -> vtx -> aft, - ( 12 ) (12) (12) 最后,回傳插入的那個結點;
4、測驗用例
void testListInsertNode(ListNode *head) {
ListPrint(head);
ListInsertNode(head, 1, 8);
ListPrint(head);
}
int main() {
int a[5] = {1, 3, 2, 6};
ListNode *head = ListCreateListByHead(4, a);
testListInsertNode(head);
return 0;
}
- 這個測驗用例,就是在原鏈表
1 -> 3 -> 2 -> 6的基礎上,在第 1 個結點(0 - based)的后面插入一個值為 8 的結點,并且回傳這個結點,這個例子的運行結果如下:
1 -> 3 -> 2 -> 6 -> NULL
執行插入操作!
1 -> 3 -> 8 -> 2 -> 6 -> NULL
5、演算法分析
1)時間復雜度
- 雖然插入操作本身是 O ( 1 ) O(1) O(1) 的,但是這里有一步 索引結點 的操作,最壞情況下就是找不到對應的結點,需要遍歷整個鏈表,所以時間復雜度為 O ( n ) O(n) O(n),
2)空間復雜度
- 整個查找和插入的程序只記錄了三個變數,和鏈表長度無關,所以空間復雜度為 O ( 1 ) O(1) O(1),
八、鏈表結點的洗掉
1、演算法描述
??給定一個鏈表頭
head,并且給定一個位置 i ( i ≥ 0 ) i(i \ge 0) i(i≥0),將位置為 i i i 的結點洗掉,并且回傳新鏈表的頭結點(為什么要回傳頭結點?因為被刪掉的有可能是原來的頭結點),
- 鏈表結點的洗掉問題可以分為三種情況進行討論,如下:
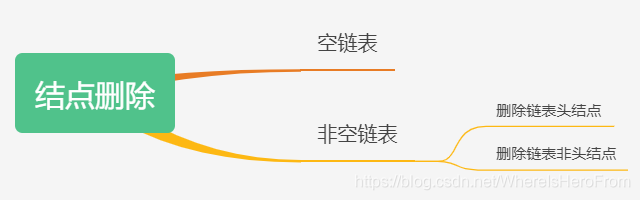
- ( 1 ) (1) (1) 空鏈表:無法進行洗掉,直接回傳 空結點;
- ( 2 ) (2) (2) 非空鏈表洗掉頭結點:快取下 頭結點 的 后繼結點,釋放 頭結點 記憶體,再回傳這個 后繼結點;
- ( 3 ) (3) (3) 非空鏈表洗掉非頭結點:通過遍歷,找到 需要洗掉結點 的 前驅結點,如果 需要洗掉結點 自身為 空,則回傳 鏈表頭結點;否則,快取 需要洗掉結點 以及它的 后繼結點,將 前驅結點 指向 后繼結點,然后再釋放 需要洗掉結點 的記憶體,回傳 鏈表頭結點;
2、影片演示
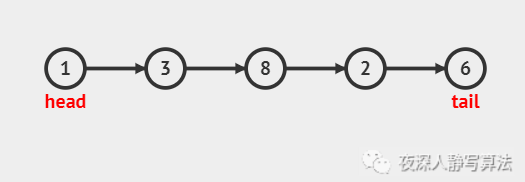
上圖演示的是通過遍歷,將第 2 號結點(下標從 0 開始)洗掉的程序,其中:
??head 代表鏈表頭結點;
??tail 代表鏈表尾結點;
??pre 代表待洗掉結點的前驅結點,也是游走指標指代的結點,即動圖中的 橙色實心結點;
??aft 代表待洗掉結點的后繼結點,即動圖中的 綠色實心結點;
??del 代表將要洗掉的結點,即動圖中的 紅色實心結點;
3、原始碼詳解
ListNode *ListDeleteNode(ListNode *head, int i) {
ListNode *pre, *del, *aft;
int j = 0;
if(head == NULL) {
return NULL; // (1)
}
if(i == 0) { // (2)
del = head; // (3)
head = head->next; // (4)
free(del); // (5)
return head; // (6)
}
pre = head; // (7)
while(pre && j < i - 1) { // (8)
pre = pre->next;
++ j;
}
if(!pre || !pre->next) { // (9)
return head;
}
del = pre->next; // (10)
aft = del->next; // (11)
pre->next = aft; // (12)
free(del); // (13)
return head; // (14)
}
- ( 1 ) (1) (1) 空鏈表,無法執行洗掉,直接回傳;
- ( 2 ) (2) (2) 需要洗掉鏈表第 0 個結點;
- ( 3 ) (3) (3) 快取第 0 個結點;
- ( 4 ) (4) (4) 將新的 鏈表頭結點 變為 當前頭結點 的 后繼結點;
-
(
5
)
(5)
(5) 呼叫系統庫函式
free釋放記憶體; - ( 6 ) (6) (6) 回傳新的 鏈表頭結點;
- ( 7 ) (7) (7) 從 鏈表頭結點 開始遍歷鏈表;
-
(
8
)
(8)
(8) 找到將要被洗掉結點的 前驅結點
pre; - ( 9 ) (9) (9) 如果 前驅結點 為空,或者 需要洗掉的結點 為空,則直接回傳當前 鏈表頭結點;
-
(
10
)
(10)
(10) 快取需要洗掉的結點到
del; -
(
11
)
(11)
(11) 快取需要洗掉結點的后繼結點到
aft; - ( 12 ) (12) (12) 將需要洗掉的結點的前驅結點指向它的后繼結點;
- ( 13 ) (13) (13) 釋放需要洗掉結點的記憶體空間;
- ( 14 ) (14) (14) 回傳鏈表頭結點;
4、測驗用例
void testListDeleteNode(ListNode *head) {
ListPrint(head);
printf("執行 2 號結點洗掉操作!\n");
head = ListDeleteNode(head, 2);
ListPrint(head);
printf("執行 0 號結點洗掉操作!\n");
head = ListDeleteNode(head, 0);
ListPrint(head);
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a); // (1)
testListDeleteNode(head); // (2)
return 0;
}
- 這個用例的第
(
1
)
(1)
(1) 步通過 頭插法 創建了一個
1 -> 3 -> 8 -> 2 -> 6的鏈表, 然后將 2 號結點洗掉,再將 頭結點洗掉,運行結果如下:
1 -> 3 -> 8 -> 2 -> 6 -> NULL
執行 2 號結點洗掉操作!
1 -> 3 -> 2 -> 6 -> NULL
執行 0 號結點洗掉操作!
3 -> 2 -> 6 -> NULL
5、演算法分析
1)時間復雜度
- 洗掉結點本身的時間復雜度為 O ( 1 ) O(1) O(1),
- 但是由于需要查找到需要洗掉的結點,所以總的時間復雜度還是 O ( n ) O(n) O(n) 的,
2)空間復雜度
- 不需要用到額外空間,所以總的時間復雜度為 O ( 1 ) O(1) O(1),
九、鏈表的銷毀
1、演算法描述
??鏈表的銷毀,就是需要將 所有結點 的記憶體空間進行釋放,并且需要將 鏈表的頭結點 置空,
- 鏈表的銷毀,可以理解成不斷洗掉第 0 號結點的程序,直到鏈表頭為空位置,只是一個回圈呼叫,這里就不多做介紹,有興趣的朋友可以自行實作一下,
2、影片演示
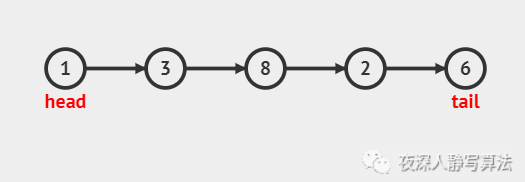
上圖所示的是 鏈表銷毀 的整個插入程序,其中:
??head 代表鏈表頭結點,即動圖中的 綠色結點,每洗掉一個結點,頭結點 就變成了之前頭結點的 后繼結點;
??tail 代表鏈表尾結點;
??temp 代表 待洗掉結點,即動圖中的 橙色結點,執行洗掉后,它的記憶體空間就釋放了;
3、原始碼詳解
void ListDestroyList(ListNode **pHead) { // (1)
ListNode *head = *pHead; // (2)
while(head) { // (3)
head = ListDeleteNode(head, 0); // (4)
}
*pHead = NULL; // (5)
}
- ( 1 ) (1) (1) 這里必須用二級指標,因為洗掉后需要將鏈表頭置空,普通的指標傳參無法影響外部指標變數;
- ( 2 ) (2) (2) 給 鏈表頭結點 解參考,即通過 鏈表頭結點的地址 獲取 鏈表頭結點;
- ( 3 ) (3) (3) 如果鏈表非空,則繼續回圈;
- ( 4 ) (4) (4) 每次迭代,洗掉 鏈表頭結點,并且回傳其 后繼結點 作為新的 鏈表頭結點;
-
(
5
)
(5)
(5) 最后,將 鏈表頭結點 置空,這樣當函式回傳時,傳參的
head才能是NULL,否則外部會得到一個記憶體已經釋放了的 野指標;
4、測驗用例
void ListDestroyList(ListNode **pHead) {
ListNode *head = *pHead;
while(head) {
head = ListDeleteNode(head, 0);
}
*pHead = NULL;
}
void testListDestroyList(ListNode **head) {
ListPrint(*head);
ListDestroyList(head);
ListPrint(*head);
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a);
testListDestroyList(&head);
return 0;
}
- 測驗用例主要是先創建了一個鏈表,然后通過不斷洗掉 鏈表頭結點,并且列印當前鏈表的程序,所以運行結果中我們可以看到整個鏈表的洗掉程序,當所有結點都被洗掉以后,
head變為NULL,
1 -> 3 -> 8 -> 2 -> 6 -> NULL
3 -> 8 -> 2 -> 6 -> NULL
8 -> 2 -> 6 -> NULL
2 -> 6 -> NULL
6 -> NULL
NULL
NULL
5、演算法分析
1)時間復雜度
- 洗掉鏈表頭結點的程序,每次從頭部開始洗掉,所以時間復雜度為 O ( 1 ) O(1) O(1),
- 總共遍歷 n n n 次洗掉,是乘法關系,所以總的時間復雜度是 O ( n ) O(n) O(n) 的,
2)空間復雜度
- 全程只需要一個 游標指標 用于遍歷鏈表,和鏈表長度無關,所以總的時間復雜度為 O ( 1 ) O(1) O(1),
十、鏈表的優缺點
1、優點
記憶體分配:
??由于是鏈式存盤,隨時增加元素隨時分配記憶體,不需要像陣列那樣進行預分配存盤空間;
插入:
??當擁有鏈表某個結點的指標時,在它 后繼位置 插入一個新的結點的的時間復雜度為 O ( 1 ) O(1) O(1);
洗掉:
??當擁有鏈表某個結點的指標時,洗掉它的 后繼結點 的時間復雜度為 O ( 1 ) O(1) O(1);
2、缺點
索引:
??索引第幾個結點時,時間復雜度為 O ( n ) O(n) O(n);
查找:
??查找是否存在某個結點時,時間復雜度為 O ( n ) O(n) O(n);
- 關于 「 單向鏈表」 的內容到這里就結束了,
- 如果還有不懂的問題,可以 「 想方設法 」找到作者的「 聯系方式 」 ,線上溝通交流,
- 有關🌳《畫解資料結構》🌳 的原始碼均開源,鏈接如下:《畫解資料結構》

🙉飯不食,水不飲,題必須刷🙉
C語言免費動漫教程,和我一起打卡! 🌞《光天化日學C語言》🌞
LeetCode 太難?先看簡單題! 🧡《C語言入門100例》🧡
資料結構難?不存在的! 🌳《畫解資料結構》🌳
LeetCode 太簡單?演算法學起來! 🌌《夜深人靜寫演算法》🌌
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293221.html
標籤:其他
上一篇:光立方原理圖理解