??前面的話??
博主在揭開C語言神秘的面紗,簡單的C語言程式已經簡單的介紹了了C語言中一些簡單的資料型別,在本篇文章中我們繼續深入C語言中的結構型別,了解整型資料,浮點型資料在記憶體中究竟是怎樣儲存的,
📒博客主頁:https://blog.csdn.net/m0_59139260?spm=1011.2124.3001.5343
🎉歡迎關注🔎點贊👍收藏??留言📝
📌本文由未見花聞原創,CSDN首發!
??堅持和努力一定能換來詩與遠方!
🙏作者水平很有限,如果發現錯誤,一定要及時告知作者哦!感謝感謝!
博主的碼云gitee,平常博主寫的程式代碼都在里面,
內容導讀
- 1. 回顧C語言資料型別
- 1.1整型資料型別
- 1.2浮點型資料型別
- 1.3自定義構造型資料型別
- 1.4指標型資料型別
- 1.5空型資料型別
- 2. 整形在記憶體中的存盤
- 2.1原碼,反碼,補碼的概念
- 2.2 大小端位元組序介紹及判斷
- 2.3小試牛刀
- 3. 浮點型在記憶體中的存盤
1. 回顧C語言資料型別
在C語言中基本常見的資料型別有:
char short int long long long float double等等,
現在我們來將C語言中資料型別系統地分一分類,大致可以分為以下幾類:整型 浮點 自定義構造 指標 空,
1.1整型資料型別
🍒字符型char
signed char
unsigned char
🍒短整型short
signed short
unsigned short
🍒整型int
signed short
unsigned int
🍒長整形long
signed long [int]
unsigned long [int]
對于未標明是否帶符號的資料型別,比如就單說int char short long …,一般情況下默認為有符號型,這個具體得看編譯器,大部分編譯器是默認為有符號型,所以本文所有未說明是否帶符號的型別通通默認為帶符號型別,
1.2浮點型資料型別
🍒單精度浮點型:float
🍒雙精度浮點型:double
1.3自定義構造型資料型別
🍒陣列:array[ ]
🍒結構體:struct
🍒聯合:union
🍒列舉:enum
1.4指標型資料型別
🍒整型指標:int*
🍒字符指標:char*
🍒短整型指標:short*
🍒長整型指標:long*
🍒單精度浮點指標:float*
🍒雙精度浮點指標:double*
🍒結構體指標:struct*
🍒萬能指標:void*
1.5空型資料型別
🍒void 表示空型別(無型別)
🍒通常應用于函式的回傳型別、函式的引數、指標型別,
2. 整形在記憶體中的存盤
我們已經知道整型int在記憶體中占四個位元組,但它究竟是怎樣儲存的呢?我們一探究竟,
2.1原碼,反碼,補碼的概念
計算機中的整數有三種表示方法,即原碼、反碼和補碼,
三種表示方法均有符號位和數值位兩部分,符號位都是用0表示“正”,用1表示“負”,而數值位負整數的三種表示方法各不相同,
🍓原碼,就是二進制定點表示法,原碼表示法在數值前面增加了一位符號位,正數該位為0,負數該位為1,其余位表示數值的大小,即最高位為符號位,0表示正,1表示負,其余位表示數值的大小,
🍓反碼,是數值存盤的一種,多應用于系統環境設定,將原碼除符號位外其他位取反就能得到反碼,
🍓補碼,在計算機系統中,數值一律用補碼來表示和存盤,原因在于使用補碼,可以將符號位和數值域統一處理;同時,加法和減法也可以統一處理,將反碼加上1就是補碼,
正整數的原碼,反碼,補碼都相同,負數三者均不同,三者轉換關系為原碼除符號位取反得反碼,反碼加上1就是補碼,
對整型資料來說記憶體中存放的是補碼,
2.2 大小端位元組序介紹及判斷
🍉大端模式,是指資料的高位元組保存在記憶體的低地址中,而資料的低位元組保存在記憶體的高地址中,這樣的存盤模式有點兒類似于把資料當作字串順序處理:地址由小向大增加,而資料從高位往低位放;這和我們的閱讀習慣一致,
🍉小端模式,是指資料的高位元組保存在記憶體的高地址中,而資料的低位元組保存在記憶體的低地址中,這種存盤模式將地址的高低和資料位權有效地結合起來,高地址部分權值高,低地址部分權值低,
比如數字16,將記憶體中的二進制碼轉換成16進制就是00 00 00 10,假設有四個地址0x009FFA60 0x009FFA61 0x009FFA62 0x009FFA63,
如果是大端位元組序進行儲存,則儲存順序如下:
| 記憶體地址 | 存盤內容 |
|---|---|
| 0x009FFA60 | 00 |
| 0x009FFA61 | 00 |
| 0x009FFA62 | 00 |
| 0x009FFA63 | 10 |
如果是小端位元組序進行儲存,則儲存順序如下:
| 記憶體地址 | 存盤內容 |
|---|---|
| 0x009FFA60 | 10 |
| 0x009FFA61 | 00 |
| 0x009FFA62 | 00 |
| 0x009FFA63 | 00 |
🍉為什么會有大小端模式之分呢?這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著一個位元組,一個位元組為8bit,但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于暫存器寬度大于一個位元組,那么必然存在著一個如果將多個位元組安排的問題,因此就導致了大端存盤模式和小端存盤模式,
例如一個 16bit 的 short 型 x,在記憶體中的地址為 0x0010, x的值為0x1122 ,那么0x11為高位元組,0x22為低位元組,對于大端模式,就將0x11放在低地址中,即 0x0010中, 0x22放在高地址中,即 0x0011中,小端模式,剛好相反,我們常用的 X86結構是小端模式,而 KEIL C51 則為大端模式,很多的ARM,DSP都為小端模式,有些ARM處理器還可以由硬體來選擇是大端模式還是小端模式,
🍉總結:整型資料大端模式儲存,高位在低地址,低位在高地址,小端模式儲存則相反,高位在高地址,低位在低地址,
🍉筆試題:
請簡述大端位元組序和小端位元組序的概念,設計一個小程式來判斷當前機器的位元組序,
//判斷是大端還是小端儲存
#include <stdio.h>
int check()
{
int i = 1;
//1的十六進序列為 00 00 00 01
//使用char*的方式訪問&i的空間,如果是1,說明低位存盤在低地址,為小端,
//如果是0,說明高位存盤在低地址,為大端,
return *((char*)&i);
}
int main()
{
int ret = check();
if (ret)
printf("小端!\n");
else
printf("大端!\n");
return 0;
}
2.3小試牛刀
🌽小試牛刀1:下面程式會輸出什么?
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
🔑:a為char型-1默認為有符號型,它的二進制原碼為1000 0001 ,記憶體中儲存的為補碼所以先要轉成補碼,除最高位取反得反碼1111 1110,加1的補碼1111 1111,在輸出的時候以%d形式輸出,程序中會發生整型提升(對于不了解整型提升的小伙伴可以閱讀博主的一篇文章C語言中奇妙又有趣的符號——運算子(運算子)!C語言運算(操作)符最全集合(建議收藏)最后3.1.2部分,那里有說明整型提升),a的補碼會先整型提升為1111 1111 1111 1111 1111 1111 1111 1111,它的原碼為1000 0000 0000 0000 0000 0000 0000 0001為數字-1,b為有符號型char型-1,所以結果與a一致,為-1,c為無符號char型,值為-1,記憶體中存為補碼,無符號型整數類原碼,反碼,補碼相同,-1補碼為1111 1111,同理以%d形式輸出需先進行整型提升,無符號型整型提升統一補0,所以c整型提升后補碼為0000 0000 0000 0000 0000 0000 1111 1111,因為原反補碼相同,所以原碼也是補碼,所以輸出c的值為255,
💡運行結果:
a=-1,b=-1,c=255
D:\gtee\C-learning-code-and-project\test_810\Debug\test_810.exe (行程 30452)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
🌽小試牛刀2:下面程式會輸出什么?
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n",a);
return 0;
}
🔑:a為有符號char型,值為-128,它比較特殊,在計算機內的補碼為1000 0000,當以%u形式列印時會發生整型提升,補碼會變為1111 1111 1111 1111 1111 1111 1000 0000,因為是以無符號型整數輸出,無符號整型原反補碼相同,通過計算器可以得出輸出的值為4294967168,
💡運行結果:
4294967168
D:\gtee\C-learning-code-and-project\test_810\Debug\test_810.exe (行程 38812)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
🌽小試牛刀3:下面程式會輸出什么?
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n",a);
return 0;
}
🔑:有符號char型的范圍為-128 到127,a為有符號char型,賦值128明顯超出資料范圍了,整數128的二進制序列為0000 0000 0000 0000 0000 0000 1000 0000將此值賦值給a時會發生截斷,所以儲存在a中的補碼為1000 0000,這樣的話就和小試牛刀2那題一模一樣了,所以結果會輸出4294967168,
💡運行結果:
4294967168
D:\gtee\C-learning-code-and-project\test_810\Debug\test_810.exe (行程 37444)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
🌽小試牛刀4:下面程式會輸出什么?
#include <stdio.h>
int main()
{
int i= -20;
unsigned int j = 10;
printf("%d\n", i+j);
return 0;
}
//按照補碼的形式進行運算,最后格式化成為有符號整數
🔑:i為有符號整型,值為-20,二進制原碼為1000 0000 0000 0000 0000 0000 0001 0100除符號位取反加一得補碼1111 1111 1111 1111 1111 1111 1110 1100
j為無符號型整數,值為10,原碼補碼相同,補碼為0000 0000 0000 0000 0000 0000 0000 1010,將倆個補碼相加得i+j的補碼1111 1111 1111 1111 1111 1111 1111 0110,以%d形式輸出,由于符號位為1所以需計算原碼,減一取反后得1000 0000 0000 0000 0000 0000 0000 1010,為數字-10,
💡運行結果:
-10
D:\gtee\C-learning-code-and-project\test_810\Debug\test_810.exe (行程 27368)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
🌽小試牛刀5:下面程式會輸出什么?
#include <stdio.h>
int main()
{
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
return 0;
}
🔑:i為無符號整型,范圍為0~2^32 -1,所以這個i隨著for回圈到0后再減減,i在記憶體中儲存的補碼為1111 1111 1111 1111 1111 1111 1111 1111,由于無符號整型原反補碼相同,所以i實際值是一個非常大的數,因此這個回圈為死回圈,因為i永遠不會小于0,回圈永遠跳不出去,
🌽小試牛刀6:下面程式會輸出什么?
#include <stdio.h>
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
🔑:定義了一個元素為有符號型char大小為1000的陣列a,有符號char型別的范圍為-128~127,strlen函式遇到\0后才會停止計數,\0的ASCII碼為0,所以strlen會計算從開始到陣列a中第一個0的地方,
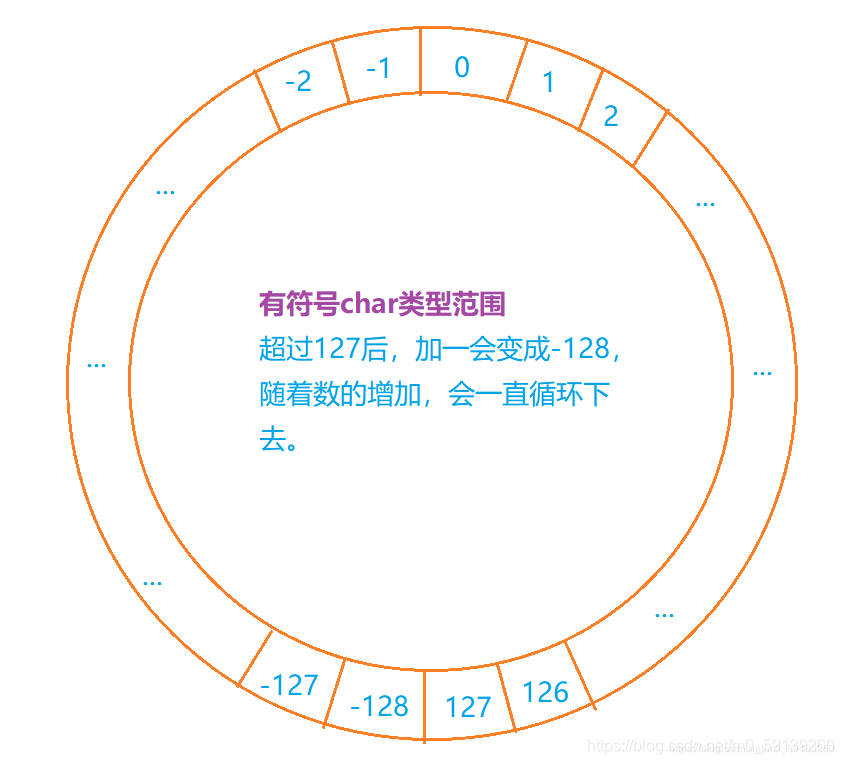
整數i從0開始增加,則陣列a內的元素隨著下標增大會減小,初始值為-1,所以就相當于繞著如圖這個圈逆時針旋轉,陣列a中首個0出現時,i應該為128+127=255,所以strlen能夠計算在i為0~254所對應字符陣列a的字符長度,即255,
根據這個圖我們可以類推其他型別的整數的范圍,以及超出范圍后會一樣進行一個類似的回圈進行資料值的‘轉換’,
💡運行結果:
255
D:\gtee\C-learning-code-and-project\test_810\Debug\test_810.exe (行程 42544)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
🌽小試牛刀7:下面程式會輸出什么?
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
🔑:無符號char型別的范圍為0 ~ 255,i是一個無符號char型別,無論i怎么加加,它的有效值一定在0 ~ 255范圍內,而回圈能進行的條件就是i的值在0 ~ 255所以這是一個死回圈,會一直輸出hello world,
3. 浮點型在記憶體中的存盤
進入正題之前先來看一道例題,通過這道題來引出浮點數在記憶體中究竟是這么存盤的,
🌽例題:下面程式會輸出什么?
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
return 0;
}
如果你不知道浮點數在記憶體中怎么存盤的,你可能會覺得會輸出:
n的值為:9
*pFloat的值為:9.000000
num的值為:9
*pFloat的值為:9.000000
但是,實際上會得出以下結果:
n的值為:9
*pFloat的值為:0.000000
num的值為:1091567616
*pFloat的值為:9.000000
D:\gtee\C-learning-code-and-project\test_810\Debug\test_810.exe (行程 3232)已退出,代碼為 0,
按任意鍵關閉此視窗. . .
那是為什么呢?要解釋這個問題就要弄清楚浮點數在記憶體中的儲存方式,
💡根據國際標準IEEE(電氣和電子工程協會) 754,任意一個二進制浮點數V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符號位,當s=0,V為正數;當s=1,V為負數,
M表示有效數字,大于等于1,小于2,
2^E表示指數位,
舉例來說: 十進制的5.0,寫成二進制是101.0,相當于 1.01×2^2 , 那么,按照上面V的格式,可以得出s=0,
M=1.01,E=2,
十進制的-5.0,寫成二進制是-101.0 ,相當于-1.01×2^2,那么,s=1,M=1.01,E=2,
💡IEEE 754規定: 對于32位的浮點數,最高的1位是符號位S,接著的8位是指數E,剩下的23位為有效數字M,
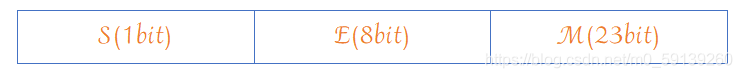
對于64位的浮點數,最高的1位是符號位S,接著的11位是指數E,剩下的52位為有效數字M,

IEEE 754對有效數字M和指數E,還有一些特別規定, 前面說過,
1≤M<2,也就是說,M可以寫成1.xxxxxx的形式,其中xxxxxx表示小數部分,
IEEE 754規定,在計算機內部保存M時,默認這個數的第一位總是1,因此可以被舍去,只保存后面的xxxxxx部分,
比如保存1.01的時候,只保存01,等到讀取的時候,再把第一位的1加上去,這樣做的目的,是節省1位有效數字,
以32位浮點數為例,留給M只有23位,將第一位的1舍去以后,等于可以保存24位有效數字,
至于指數E,情況就比較復雜,
首先,E為一個無符號整數(unsigned int) 這意味著,如果E為8位,它的取值范圍為0~255;如果E為11位,它的取值范圍為0~2047,但是,我們知道,科學計數法中的E是可以出現負數的,所以IEEE 754規定,存入記憶體時E的真實值必須再加上一個中間數,對于8位的E,這個中間數是127;對于11位的E,這個中間數是1023,比如,2^10的E是10,所以保存成32位浮點數時,必須保存成10+127=137,即10001001,
指數E從記憶體中取出還可以再分成三種情況:
🍇E不全為0或不全為1
這時,浮點數就采用下面的規則表示,即指數E的計算值減去127(1023),得到真實值,再將有效數字M前加上第一位的1, 比如: 0.5(1/2)的二進制形式為0.1,由于規定正數部分必須為1,即將小數點右移1位,則為1.0*2^(-1),其階碼為-1+127=126,表示為01111110,而尾數1.0去掉整數部分為0,補齊0到23位00000000000000000000000,則其二進制表示形式為: 0 01111110 00000000000000000000000,
🍇E全為0
這時,浮點數的指數E等于1-127(或者1-1023)即為真實值, 有效數字M不再加上第一位的1,而是還原為0.xxxxxx的小數,這樣做是為了表示±0,以及接近于0的很小的數字,
🍇E全為1
這時,如果有效數字M全為0,表示±無窮大(正負取決于符號位s),
下面,讓我們回到一開始的問題:為什么 0x00000009 還原成浮點數,就成了0.000000? 首先,將 0x00000009 拆分,得到第一位符號位s=0,后面8位的指數E=00000000 ,最后23位的有效數字M=000 0000 0000 0000 0000 1001,
9 -> 0000 0000 0000 0000 0000 0000 0000 1001
由于指數E全為0,所以符合上一節的第二種情況,因此,浮點數V就寫成: V=(-1)^0 ×0.00000000000000000001001×2^(-126)=1.001×2^(-146)顯然,V是一個很小的接近于0的正數,所以用十進制小數表示就是0.000000,
再看例題的第二部分, 請問浮點數9.0,如何用二進制表示?還原成十進制又是多少? 首先,浮點數9.0等于二進制的1001.0,即1.001×2^3,
9.0 -> 1001.0 ->(-1)^01.0012^3 -> s=0, M=1.001,E=3+127=130
那么,第一位的符號位s=0,有效數字M等于001后面再加20個0,湊滿23位,指數E等于3+127=130,即10000010, 所以,寫成二進制形式,應該是s+E+M,即
0 10000010 001 0000 0000 0000 0000 0000
這個32位的二進制數,還原成十進制,正是1091567616,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293395.html
標籤:其他