文章目錄
- 1.指標是什么
- 2.指標和指標型別
- 3.野指標
- 3.1.野指標的成因
- 3.2.如何規避野指標
- 4.指標運算
- 4.1. 指標 +/- 整數
- 4.2. 指標 - 指標
- 4.3 指標的關系運算
- 5. 指標和陣列
- 6.二級指標
1.指標是什么
在計算機科學中,指標(Pointer)是編程語言中的一個物件,利用地址,它的值直接指向(points to)存在電腦存盤器中另一個地方的值,由于通過地址能找到所需的變數單元,可以說,地址指向該變數單元,因此,將地址形象化的稱為“指標”,意思是通過它能找到以它為地址的記憶體單元,
可以這樣理解:
記憶體被細分為一個個大小為一個位元組的記憶體單元(即一個記憶體單位為一個位元組),每一個記憶體單元都有自己對應的地址,
圖解如下

所以指標是變數,用來存放記憶體記憶體單元的地址編號(存放在指標中的值都被當成地址處理)
對應代碼:
#include <stdio.h>
int main()
{
int a = 10; //在記憶體中開辟一塊空間
int *p = &a; //這里我們對變數a,取出它的地址,可以使用&運算子
//將a的地址存放在p變數中,p就是一個之指標變數
return 0;
}
那么一個指標的大小是多少呢?
C語言規定:
針的大小在32位平臺是4個位元組,在64位平臺是8個位元組
2.指標和指標型別
我們知道,變數有不同的型別,整形,浮點型等,那指標有沒有型別呢?
準確的說:sure !當然是有的,
指標的定義方式是: type + *
例如:
char* 型別的指標是為了存放 char 型別變數的地址,
short* 型別的指標是為了存放 short 型別變數的地址,
int* 型別的指標是為了存放 int 型別變數的地址,
指標型別有什么意義呢?
看如下代碼運行結果:
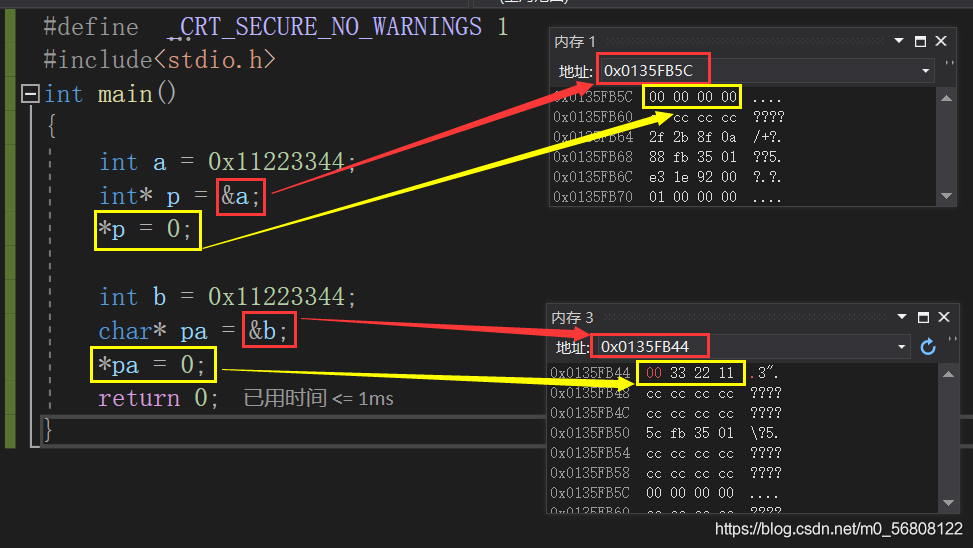
當我們觀察記憶體時會發現,指標 p 的型別為 int * 時,*p=0 的結果是四個位元組全部變為0;而同樣的數字,當指標 pa 的型別為 char * 時,改變使 *pa=0,可以看出記憶體中只改變了一個位元組為0;
所以,指標型別決定了指標解參考的權限有多大,
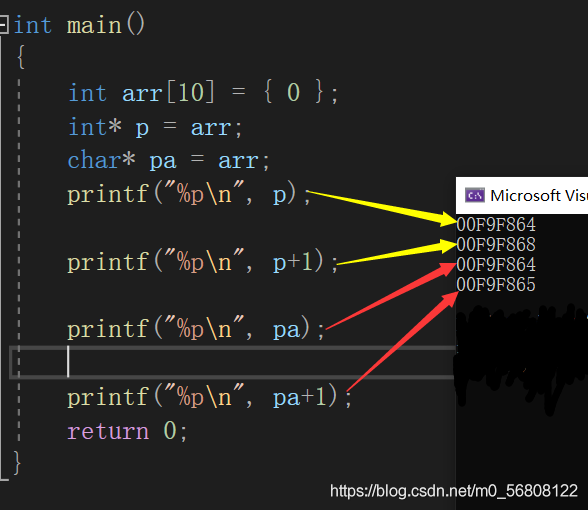
由上圖我們可以看出,當指標p為 int* 型別時,p+1 的地址就加上了4個的位元組的單位;而當型別為char* 的指標 pa+1時,相對pa只加上了1個位元組的單位,
所以,指標的型別還決定了指標走一步,能走多遠(步長);即當指標型別為 double* 時,走一步就跳過了8個位元組的單位長度(走 n 步就跳過了 n x 8 個位元組的長度),其他型別以此類推,
總結
指標型別的意義:
1.指標型別決定了,指標解參考的權限有多大
2.指標型別決定了,指標走一步,能走多遠
注意一點:指標型別的意義與指標大小沒聯系,無論指標為什么型別,它的大小始終只為 4 / 8 個位元組
應用:
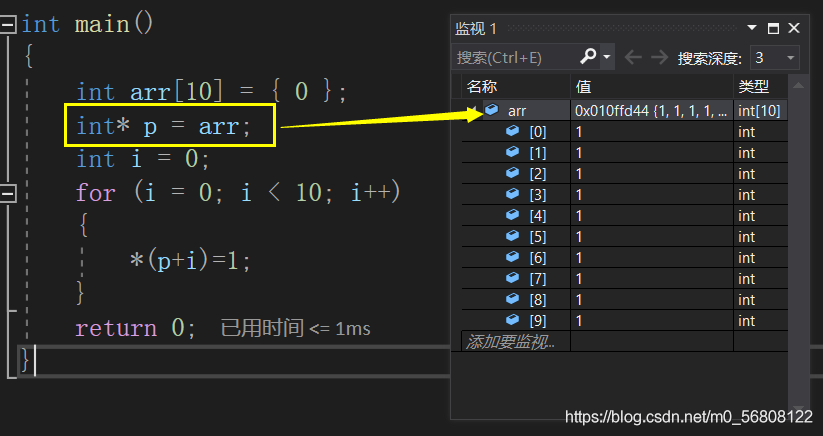
因為p 為int* 型指標,p+i 相當于跳過 int 型大小的位元組個數(即4個位元組),而陣列arr為整型陣列,每個元素為 int 型,所以當回圈結束后 arr 中的每個元素都變成了1,
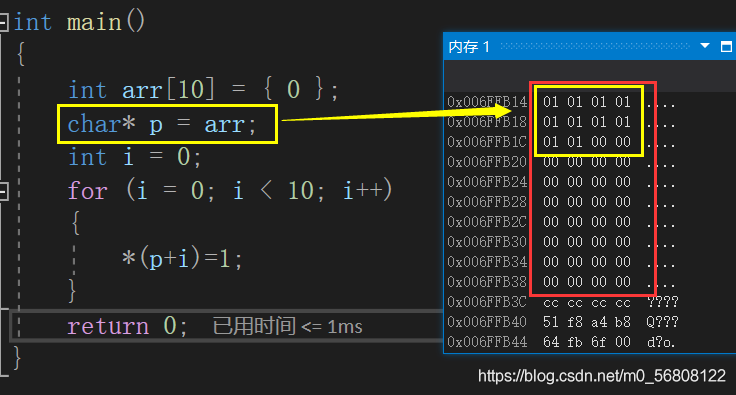
此時的 p 為 char* 型,p+i 就相當于跳過 char 型大小的位元組個數(即1個位元組),arr 中每個元素為 int 型,所以每個元素占 4 個位元組的大小,當回圈結束后,指標p就總共跳過了10個位元組,即將10個位元組賦值為1,如上圖所示,
3.野指標
概念: 野指標就是指標指向的位置是不可知的(隨機的、不正確的、沒有明確限制的)
3.1.野指標的成因
野指標的成因主要有三種情況
1.指標未初始化
#include <stdio.h>
int main()
{
int *p;//區域變數指標未初始化,默認為隨機值
*p = 20;
return 0;
}
導致結果:
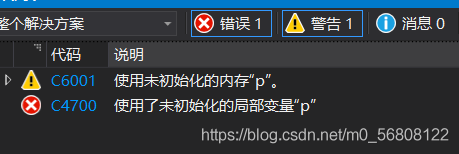
2.指標越界訪問
#include <stdio.h>
int main()
{
int arr[10] = {0};
int *p = arr;
int i = 0;
for(i=0; i<=11; i++)
{
//當指標指向的范圍超出陣列arr的范圍時,p就是野指標
*(p++) = i;
}
return 0;
}
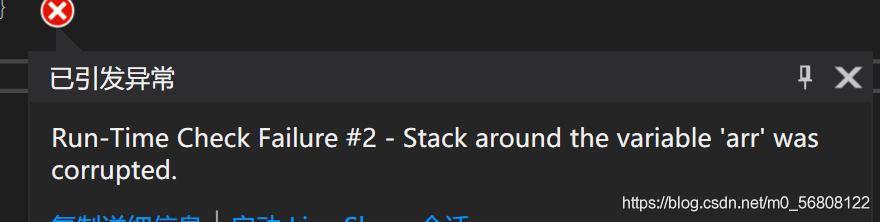
即當指標指向的范圍超出陣列arr的范圍時,p就是野指標,
3.指標指向的空間釋放
即當一個指標指向的空間被釋放后,在次使用這個指標時,此時這個指標就成為了野指標,
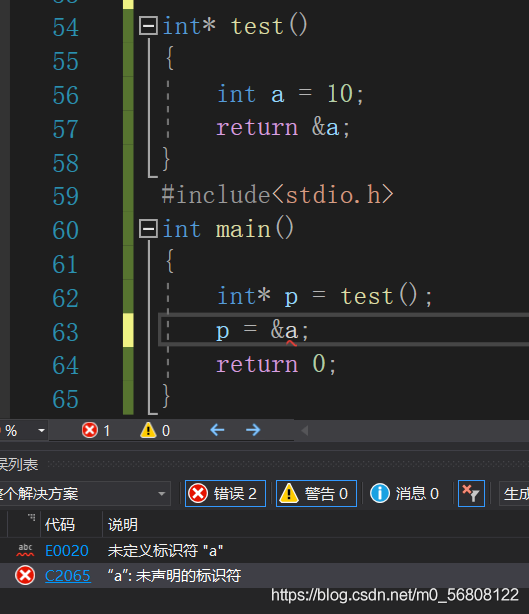
由上圖可以看出,當a為區域變數在函式內部時,在主函式中再取出a的地址就會發生錯誤,原因是當函式用完后函式中的變數就會自動銷毀,當再取出函式中變數的地址時就會造成野指標,
那么我們平時寫程式時又該如何規避野指標呢?
3.2.如何規避野指標
這里給出幾點建議:
指標初始化
當不知道將指標初始化為何值時,就初始化為NULL(空指標)小心指標越界
指標指向空間釋放及時置NULL
避免回傳區域變數的地址
(因為區域變數在使用后就會被銷毀,若在函式中作為回傳值被使用就相當于使用了野指標)指標使用之前檢查有效性(即使用前為初始化為NULL,使用時先判斷是否為NULL,若為,則不能使用,不為NULL才能使用這塊地址空間)
如:
#include <stdio.h>
int main()
{
int *p = NULL;
//…
int a = 10;
p = &a;
if(p != NULL)
{
*p = 20;
}
return 0;
}
4.指標運算
4.1. 指標 +/- 整數
如下情形:
#include<stdio.h>
int main()
{
int arr[5] = { 0 };
int* p = arr;
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = i;
}
return 0;
}
前面提到過,指標 + / - 整數 就相當于向前 / 向后移動,
4.2. 指標 - 指標
指標 - 指標的值是是兩個指標之間的元素個數
前提:兩個指標指向的是同一塊空間
int my_strlen(char* p)
{
char* pc = p;
while (*p != '\0')
p++;
return p - pc;
}
其中 my_strle n函式為模擬的實作求字串長度的函式,函式通過求得字串的首地址和尾地址,而后相減求得字串的長度
4.3 指標的關系運算
指標的關系運算,即指標之間比較大小,
例如:我們如果要將一個陣列中的元素全部置0,可以有兩種方法
法1.由前向后置0法
#include<stdio.h>
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
int* p = &arr[0];
for (p = &arr[0]; p <= &arr[4]; p++)
{
*p = 0;
}
return 0;
}
即當最后一個 p > arr [ 4 ] 時結束回圈
法2.由后向前置0法
#include<stdio.h>
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
int* p = &arr[4];
for (p = &arr[4]; p >= &arr[0]; p--)
{
*p = 0;
}
return 0;
}
即當最后指標 p < arr [ 0 ] 時,回圈結束
以上兩種方法都利用了指標大小的比較,但通常情況下,我們應該避免使用第二種方法,原因在于
標準規定:
允許指向陣列元素的指標與指向陣列最后一個元素后面的那個記憶體位置的指標比較,但是不允許與指向第一個元素之前的那個記憶體位置的指標進行較,

即指向元素的指標能與>arr[4] 的部分的地址進行比較而不能與<arr[0]進行比較,
5. 指標和陣列
首先弄明白,陣列名是什么?
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
printf("%p\n", arr);
printf("%p\n", &arr[0]);
return 0;
}
我們可以看出,arr與arr[0]的地址一樣
結論:陣列名表示的是陣列首元素的地址,
那么我們就可以通過將陣列的陣列名存放在一個指標中,進而通過指標就可以對整個陣列進行操作
例如:
#include <stdio.h>
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,0};
int *p = arr; //指標存放陣列首元素的地址
int sz = sizeof(arr)/sizeof(arr[0]);
int i=0;
for(i=0; i<sz; i++)
{
printf("&arr[%d] = %p <====> p+%d = %p\n", i, &arr[i], i, p+i);
}
return 0;
}
運行結果
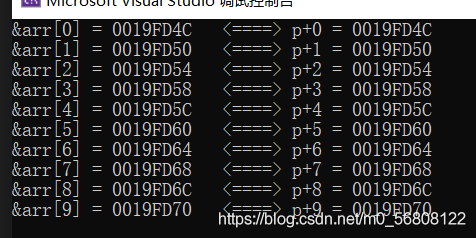
所以可見 p + i 其實計算的是陣列 arr 下標為 i 的地址
那我們就可以直接通過指標來訪問陣列,
如下:
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
int *p = arr; //指標存放陣列首元素的地址
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i<sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}

即通過 p + i 來實作對陣列的訪問,
延伸:
int main()
{
int arr[10]={1,2,3,4,5,6,7,8,9,10};
int* p=arr;
}
對于以上代碼,陣列名和指標之間可做如下操作:
因為arr就是首元素地址,指標p=arr,就相當于兩者對等,所以可以做如下轉換:
arr [ 2 ] = *( arr + 2) = *( p + 2 ) = *( 2 + p ) = *( 2 + arr ) =2 [ arr ]
以上等式均成立,除此之外,arr [ 2 ] = p [ 2 ] = 2 [ p ], 但這種形式很少見
6.二級指標
我們知道,指標變數是用于存放地址的變數,但是指標變數也是變數,是變數就有地址,那么存放指標變數的地址的變數是什么呢?
其實,存放普通變數的地址的指標叫一級指標,存放一級指標變數的地址的指標叫二級指標,存放二級指標變數地址的指標叫三級指標…以此類推 n 級指標,
例如:
#include<stdio.h>
int main()
{
int a = 10;
int* p = &a;
int** pa = &p;
return 0;
}
這里a為普通變數,p為一級指標變數,pa 就為二級指標變數,此時,想要得到a 的值就有兩種方法:
1.對一級指標p解參考, 即 *p ,
2.對二級指標 pa 進行一次解參考操作即可得到 p 的值,而p的值就是 a 的地址,所以再對 p 進行一次解參考操作即可得到 a 的值,也就是對二級指標 pa 進行兩次解參考操作即可得到a的值,即 ** pa ,
OK,初級指標的講解就到這,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/293396.html
標籤:其他
上一篇:計算機是如何儲存人類所認知的資料呢?C語言資料的儲存
下一篇:解決跨域問題