??【2020東京奧運會】 資料分析及可視化 ??
- 寫在前面
- 資料獲取
- 資料預處理
- 資料可視化
- 各地區獎牌數量分布
- 獎牌榜前十
- 中國奪金專案分類
- 中國獎牌實時數量
- 合成看板
- 總結
寫在前面
首先要宣告一點標題沒寫錯哦!是【2020東京奧運會】,應該看過直播的人都知道,至于原因可以自行百度哈,今天給我女朋友看了一下文章,她竟然直接說我標題寫錯了,哈哈,所以感覺在這有必要解釋一下~
8月8日,小日…呃…子過得挺好的日本選手的國家 舉辦的東京奧運會已經結束了,在奧運期間,主辦方種種 奇葩操作 直接把我看傻,最終它們也通過獨特的“手段” 擠入了前三名,在這里首先謝謝他們重繪了我對奧運的認知,同時,借此機會看看我國今年奧運會的獲獎情況,話不多說進入正文,

資料獲取
奧運會相關資料來自以下兩個介面,
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/total-table/15/110000004609
https://app-sc.miguvideo.com/vms-livedata/olympic-medal/detail-total/15/110000004609
1?? 下面通過第一個介面,決議獲取我們所需的資料,主要包含國家的排名與獎牌數,
打開鏈接之后,可以發現主要資訊都在 allMedalData 欄位內,
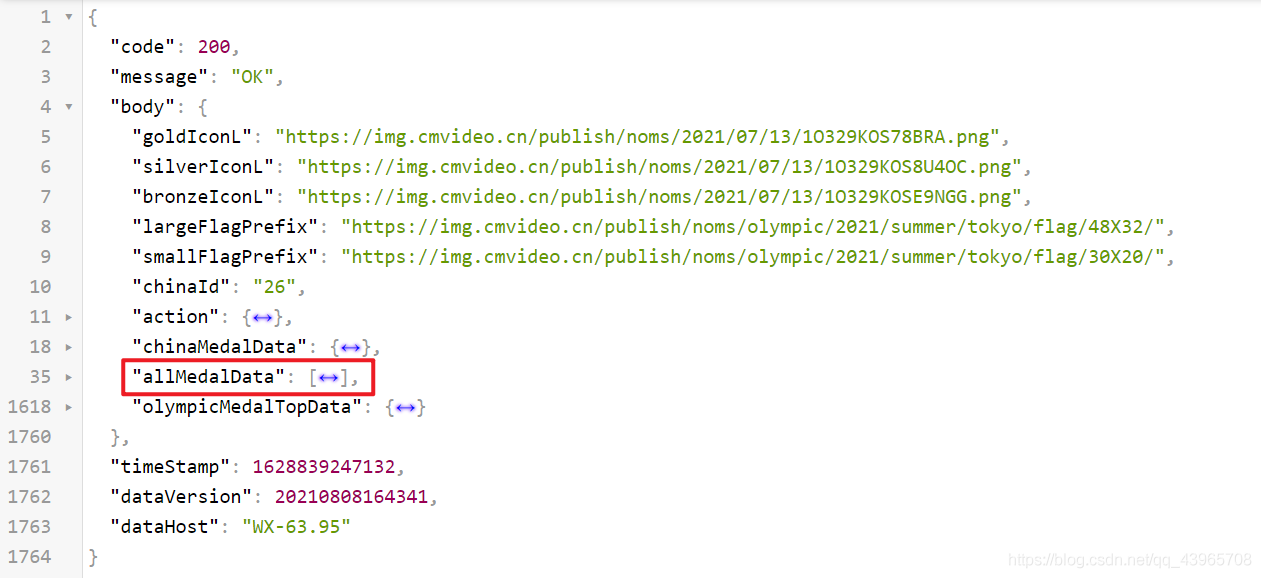
在網頁中確認需要提取的內容,然后通過對應的 key 進行提取,
import requests
import pandas as pd
data_url = 'https://app-sc.miguvideo.com/vms-livedata/olympic\
-medal/total-table/15/110000004609'
# 請求資料
data = requests.get(data_url).json()
df = pd.DataFrame()
for item in data['body']['allMedalData']:
df = df.append([[item['countryName'],
item['countryId'],
item['rank'],
item['goldMedalNum'],
item['silverMedalNum'],
item['bronzeMedalNum'],
item['totalMedalNum']]])
# 修改列名
df.columns = ['國家', '國家id', '排名', '金牌', '銀牌', '銅牌', '獎牌']
# 重置索引
df.reset_index(drop=True, inplace=True)
df.head()
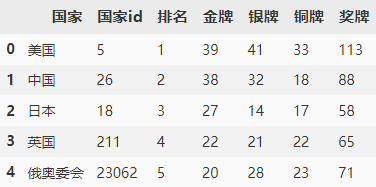
2?? 第二個鏈接同樣如此,
data_url = 'https://app-sc.miguvideo.com/\
vms-livedata/olympic-medal/detail-total/15/110000004609'
data = requests.get(data_url).json()
detail_df = pd.DataFrame()
# 請求資料
for item in data['body']['medalTableDetail']:
detail_df = detail_df.append([[item['awardTime'],
item['medalType'],
item['sportsName'],
item['countryId'],
item['bigItemName']]])
# 修改列名
detail_df.columns = ['獲獎時間', '獎牌型別', '運動員', '國家id', '運動類別']
# 重置索引
detail_df.reset_index(drop=True, inplace=True)
detail_df.head()
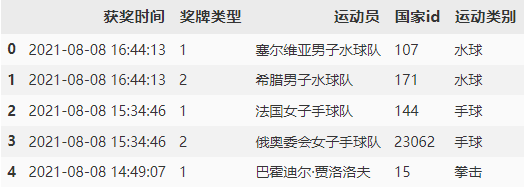
資料預處理
第二個介面獲取的資料中沒有國家名稱,需要參照第一個介面的資料按照 “國家id” 列進行匹配,修改 “獎牌型別”,將“1,2,3” 修改為 “金牌,銀牌,銅牌”,
detail_df.loc[detail_df['獎牌型別'] == 1, '獎牌型別'] = '金牌'
detail_df.loc[detail_df['獎牌型別'] == 2, '獎牌型別'] = '銀牌'
detail_df.loc[detail_df['獎牌型別'] == 3, '獎牌型別'] = '銅牌'
courtry_df = df.loc[:, ['國家', '國家id']]
detail_df = pd.merge(detail_df, courtry_df, on='國家id', how = "inner")
detail_df.head()
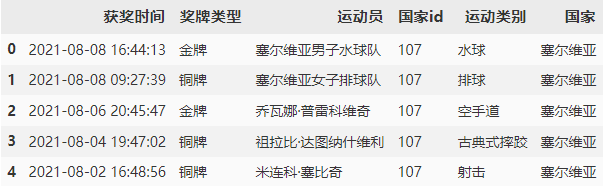
資料整理完畢可以將資料保存到本地,方便可視化,
df.to_csv('東京奧運會國家排名.csv', index=False)
detail_df.to_csv('東京奧運會獲獎詳情.csv', index=False)
資料可視化
各地區獎牌數量分布
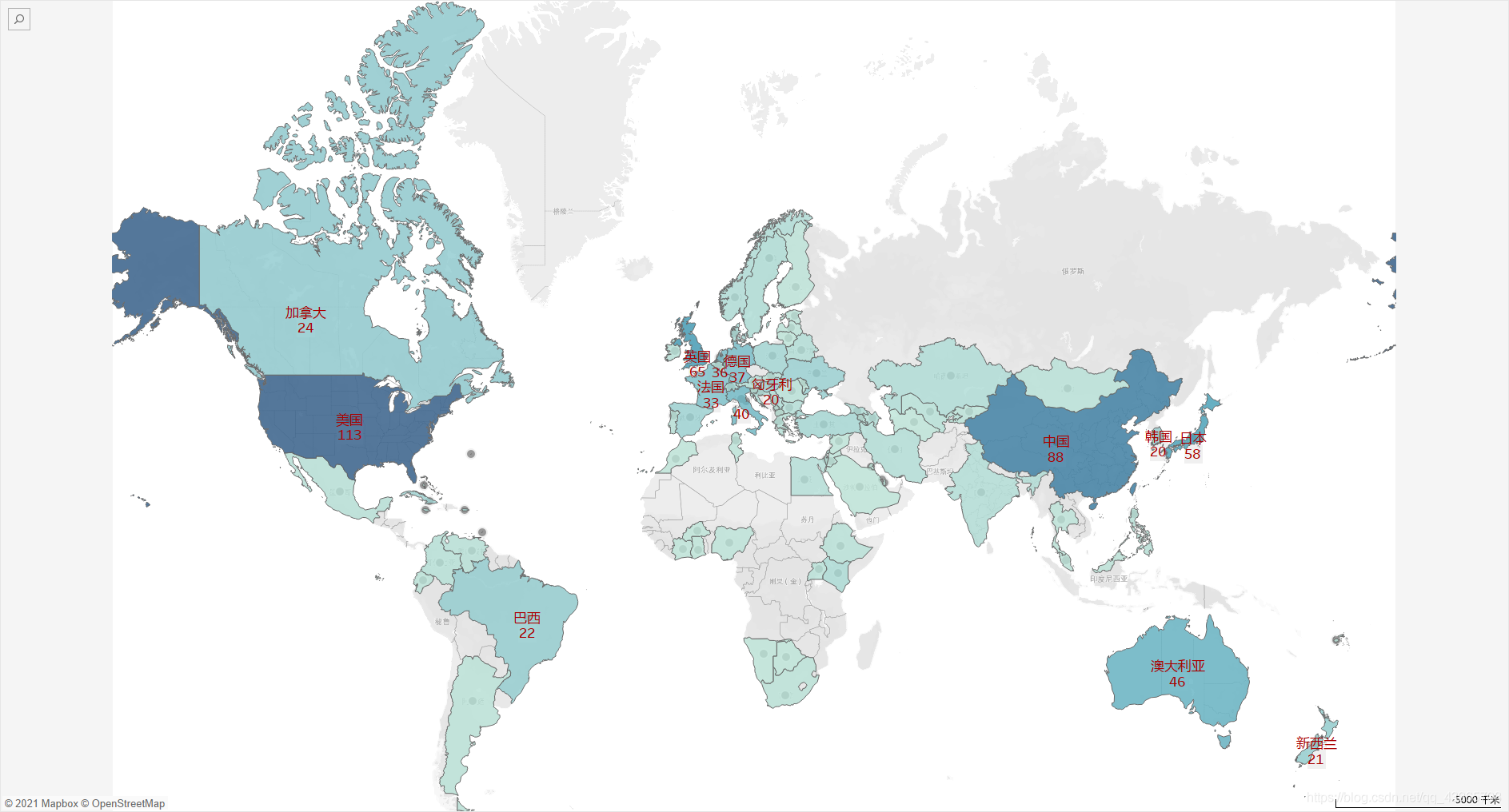
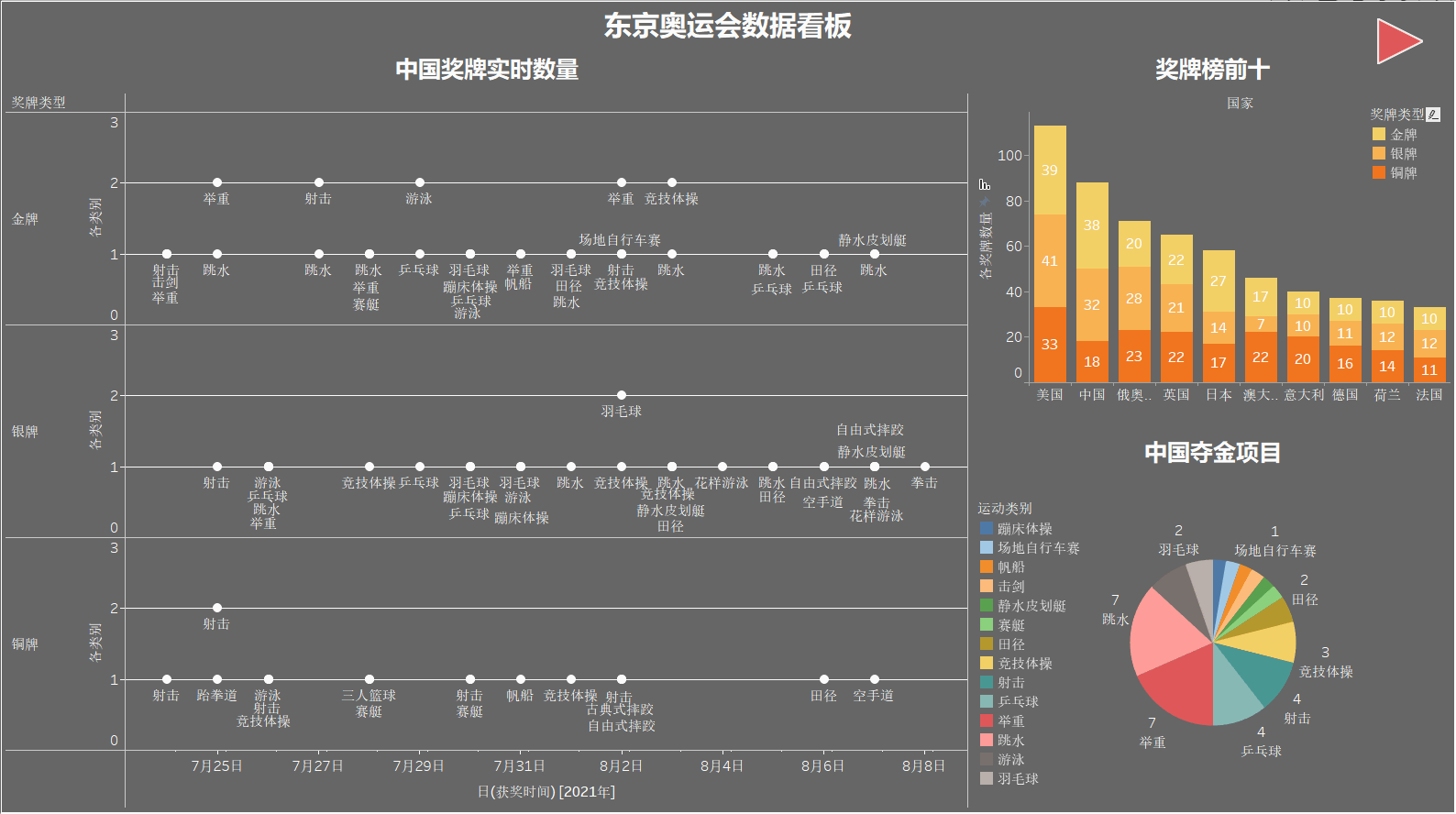
先看一下各地區獎牌數量分布,顏色越深獎牌數(總數)越多,得獎多的地區也側面反映了國家的實力,
獎牌榜前十
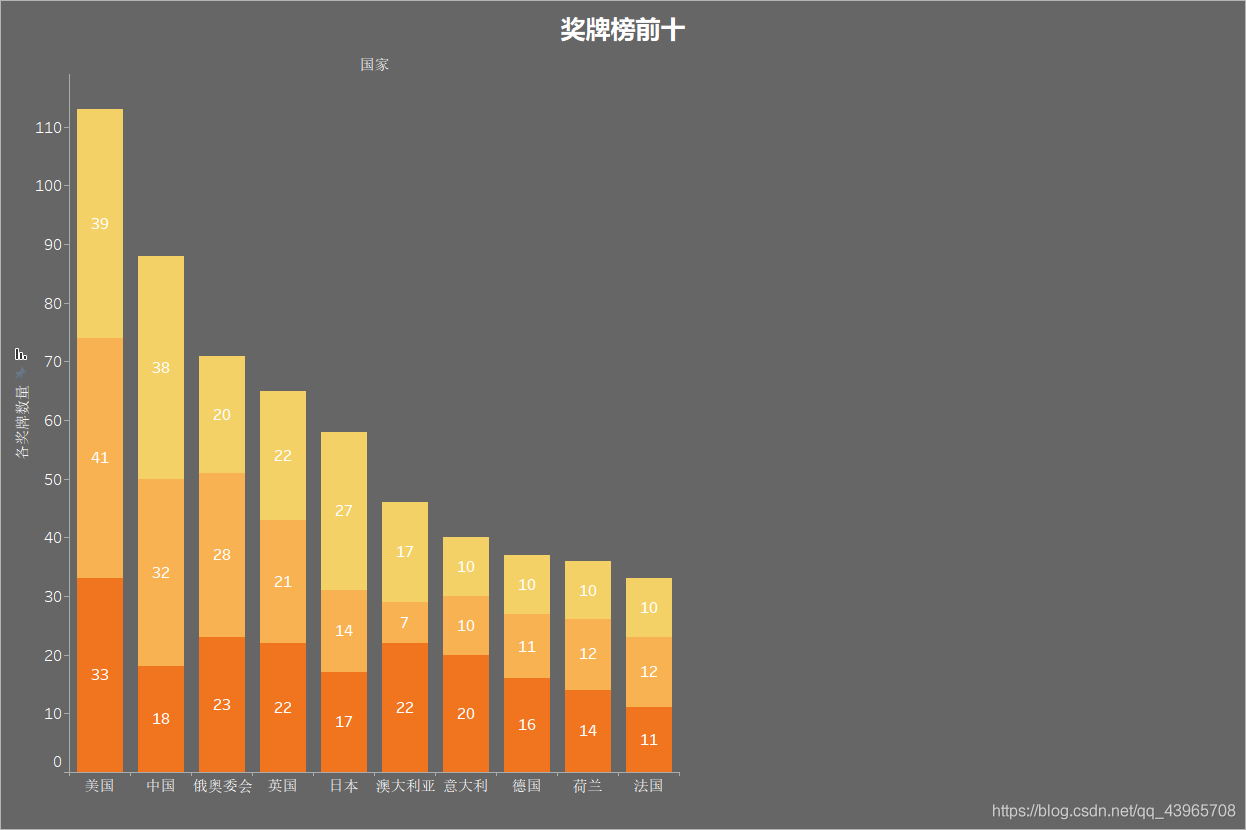
制作堆疊條形圖,展示獎牌榜前十名,每個柱子從上到下依次為金牌、銀牌、銅牌的數量,圖例沒在邊上沒截進去,見諒~
中國奪金專案分類
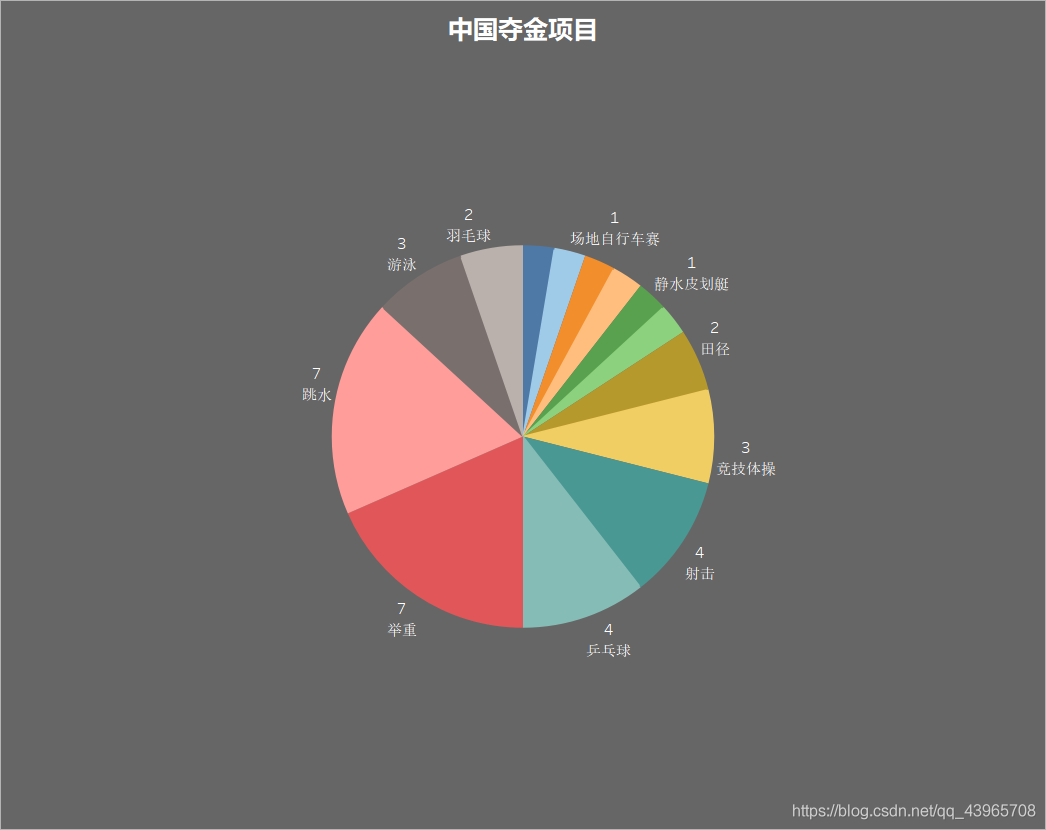
使用餅圖來顯示我國奪金的專案分類,像 舉重、跳水、乒乓球 一直都是我們的奪金熱門專案,
中國獎牌實時數量
該圖展示我國每日金銀銅獲取的實時情況,可以清晰地看出每天各個專案的獲獎情況,

合成看板
將上面制作的圖示合成在一個儀表盤中,提高觀賞性~
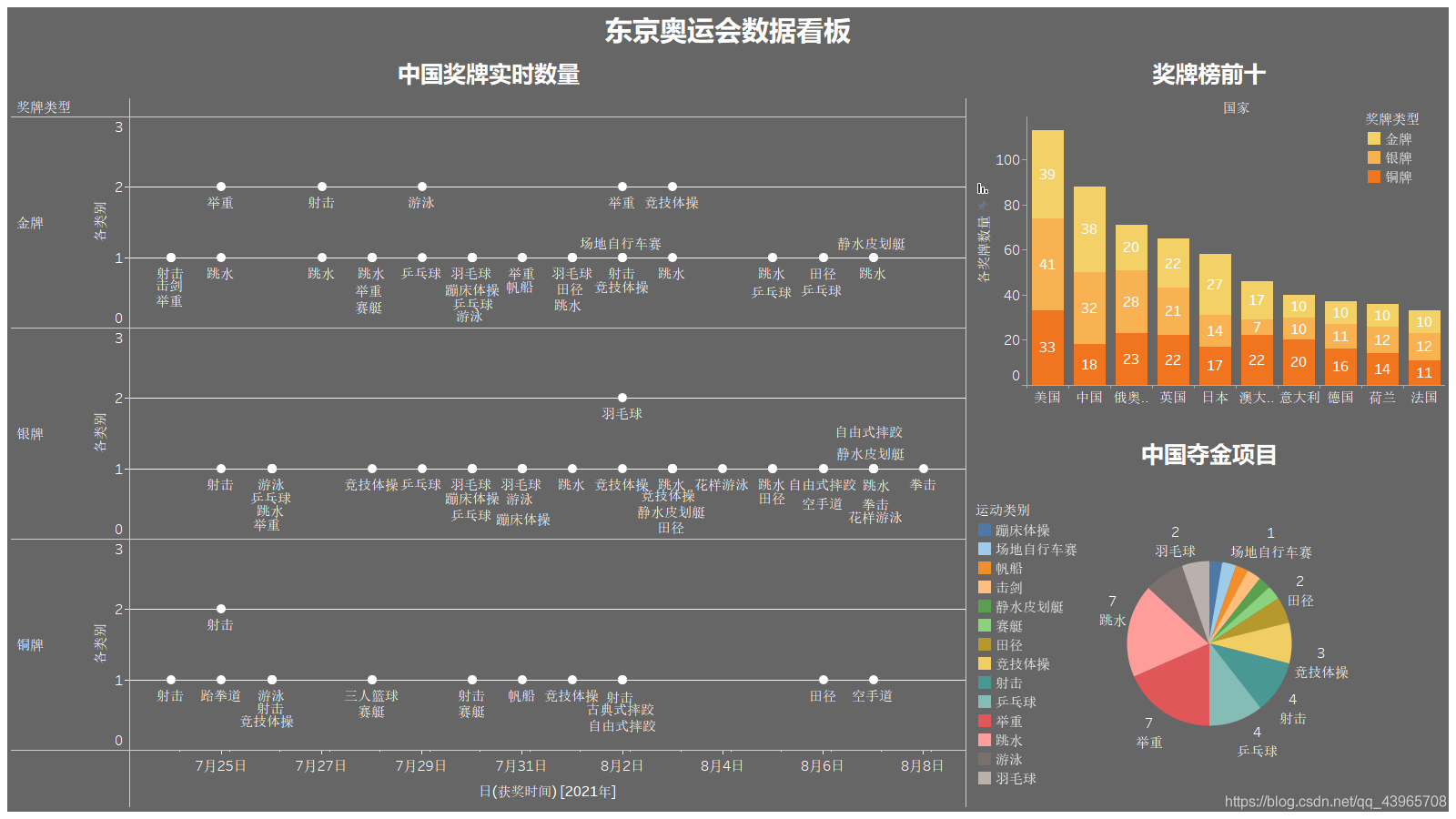
由于地圖太大,就在兩個看板中添加了跳轉按鈕,以此實作看板跳轉,效果如下,
總結
在此次奧運會中,我國代表隊在大部分專案都有出色的表現,傳統優勢專案也保持了優勢地位,舉重共8個小專案獲得 7金1銀 ,跳水8個小專案獲得 7金5銀 ,均取得歷史最好成績,在整體上來看我國奪金專案覆寫面寬,除優勢專案外,還獲取 蹦床體操、場地自行車賽、帆船、擊劍、凈水皮劃艇、賽艇、田徑、羽毛球 等專案的金牌,
由于資料量不多,不能夠較全面的分析整個比賽,這發表一下自己的看法,同時在這里期待下屆奧運會我國運動健兒的表現~
這就是本文所有的內容了,如果感徑訓不錯的話,? 點個贊再走吧!!!?
后續會繼續分享《Python資料分析及可視化》方面文章,如果感興趣的話可以點個關注不迷路哦~,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/294014.html
標籤:其他
上一篇:初識C語言(一)
下一篇:函式堆疊幀的創建與銷毀