前言
本文主要涵蓋了關于訊息佇列的大部分核心知識點,涉及的訊息佇列有 RocketMQ、Kafka,
本文很長,所有內容都為博主原創,純手打,如果覺得不錯的話,來個點贊評論收藏三連呀!
之后還會有迭代版本,當然也會有其他的總結輸出,歡迎關注我,不迷路~
關于這篇文章也整理了 PDF,已上傳至 CSDN,還準備了暗黑版本,更加護眼!
點擊下載訊息佇列核心知識點PDF

排版也是 OK 滴!

本文大綱:
- 從訊息佇列常見面試題入手來決議訊息佇列
- 如何設計一個訊息佇列?
- 訊息佇列設計成推訊息還是拉訊息?RocketMQ和Kafka是怎么做的?
- 訊息佇列之事務訊息?RocketMQ和Kafka是怎么做的?
- 比 RocketMQ 更好的事務訊息實作是什么?
- Kafka的索引設計有什么亮點?
- Kafka日志段如何讀寫決議?
- Kafka控制器事件處理全流程決議
- Kafka請求處理全流程決議
- Kafka為什么要拋棄Zookeeper?
- 進階必看的 RocketMQ,這次一網打盡
- Kafka和RocketMQ底層存盤揭秘,為什么能這么快?
- 未完待更新
從訊息佇列常見面試題入手來決議訊息佇列
今兒咱們就來盤一盤大方向上的訊息佇列有哪些核心注意點,
核心點有很多,為了更貼合實際場景,我從常見的面試問題入手:
- 如何保證訊息不丟失?
- 如果處理重復訊息?
- 如何保證訊息的有序性?
- 如果處理訊息堆積?
當然在剖析這幾個問題之前需要簡單的介紹下什么是訊息佇列,訊息佇列常見的一些基本術語和概念,
接下來進入正文,
什么是訊息佇列
來看看維基百科怎么說的,順帶學學英語這波不虧:
In computer science, message queues and mailboxes are software-engineering components typically used for inter-process communication (IPC), or for inter-thread communication within the same process. They use a queue for messaging – the passing of control or of content. Group communication systems provide similar kinds of functionality.
翻譯一下:在計算機科學領域,訊息佇列和郵箱都是軟體工程組件,通常用于行程間或同一行程內的執行緒通信,它們通過佇列來傳遞訊息-傳遞控制資訊或內容,群組通信系統提供類似的功能,
簡單的概括下上面的定義:訊息佇列就是一個使用佇列來通信的組件,
上面的定義沒有錯,但就現在而言我們日常所說的訊息佇列常常指代的是訊息中間件,它的存在不僅僅只是為了通信這個問題,
為什么需要訊息佇列
從本質上來說是因為互聯網的快速發展,業務不斷擴張,促使技術架構需要不斷的演進,
從以前的單體架構到現在的微服務架構,成百上千的服務之間相互呼叫和依賴,從互聯網初期一個服務器上有 100 個在線用戶已經很了不得,到現在坐擁10億榷訓的微信,我們需要有一個「東西」來解耦服務之間的關系、控制資源合理合時的使用以及緩沖流量洪峰等等,
訊息佇列就應運而生了,它常用來實作:異步處理、服務解耦、流量控制,
異步處理
隨著公司的發展你可能會發現你專案的請求鏈路越來越長,例如剛開始的電商專案,可以就是粗暴的扣庫存、下單,慢慢地又加上積分服務、短信服務等,這一路同步呼叫下來客戶可能等急了,這時候就是訊息佇列登場的好時機,
呼叫鏈路長、回應就慢了,并且相對于扣庫存和下單,積分和短信沒必要這么的 “及時”,因此只需要在下單結束那個流程,扔個訊息到訊息佇列中就可以直接回傳回應了,而且積分服務和短信服務可以并行的消費這條訊息,
可以看出訊息佇列可以減少請求的等待,還能讓服務異步并發處理,提升系統總體性能,
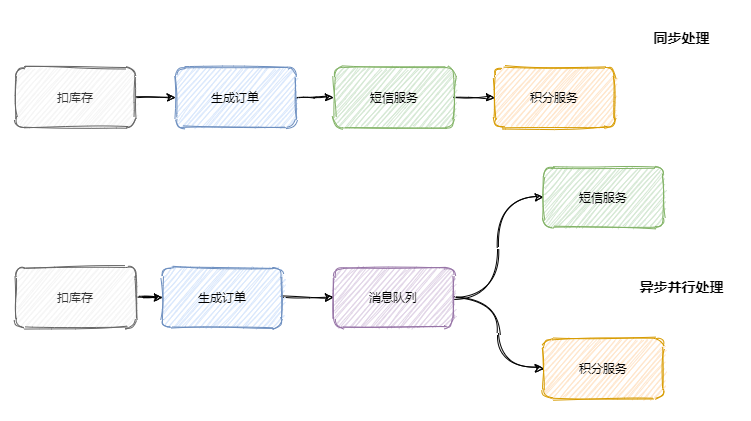
服務解耦
上面我們說到加了積分服務和短信服務,這時候可能又要來個營銷服務,之后領導又說想做個大資料,又來個資料分析服務等等,
可以發現訂單的下游系統在不斷的擴充,為了迎合這些下游系統訂單服務需要經常地修改,任何一個下游系統介面的變更可能都會影響到訂單服務,這訂單服務組可瘋了,真 ·「核心」專案組,

所以一般會選用訊息佇列來解決系統之間耦合的問題,訂單服務把訂單相關訊息塞到訊息佇列中,下游系統誰要誰就訂閱這個主題,這樣訂單服務就解放啦!
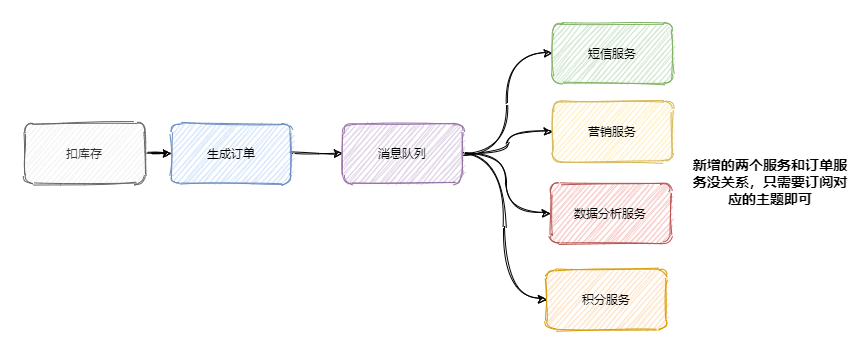
流量控制
想必大家都聽過「削峰填谷」,后端服務相對而言都是比較「弱」的,因為業務較重,處理時間較長,像一些例如秒殺活動爆發式流量打過來可能就頂不住了,因此需要引入一個中間件來做緩沖,訊息佇列再適合不過了,
網關的請求先放入訊息佇列中,后端服務盡自己最大能力去訊息佇列中消費請求,超時的請求可以直接回傳錯誤,
當然還有一些服務特別是某些后臺任務,不需要及時地回應,并且業務處理復雜且流程長,那么過來的請求先放入訊息佇列中,后端服務按照自己的節奏處理,這也是很 nice 的,
上面兩種情況分別對應著生產者生產過快和消費者消費過慢兩種情況,訊息佇列都能在其中發揮很好的緩沖效果,

注意
引入訊息佇列固然有以上的好處,但是多引入一個中間件系統的穩定性就下降一層,運維的難度抬高一層,因此要權衡利弊,系統是演進的,
訊息佇列基本概念
訊息佇列有兩種模型:佇列模型和發布/訂閱模型,
佇列模型
生產者往某個佇列里面發送訊息,一個佇列可以存盤多個生產者的訊息,一個佇列也可以有多個消費者,
但是消費者之間是競爭關系,即每條訊息只能被一個消費者消費,
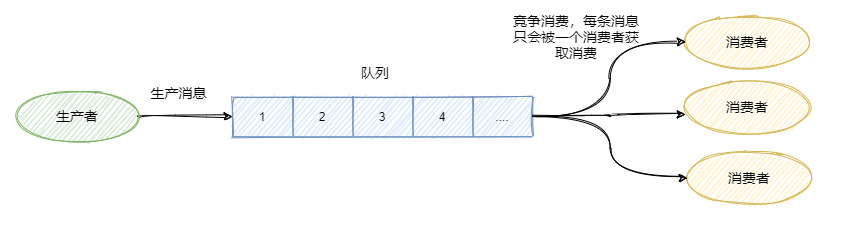
發布/訂閱模型
為了解決一條訊息能被多個消費者消費的問題,發布/訂閱模型就來了,該模型是將訊息發往一個Topic即主題中,所有訂閱了這個 Topic 的訂閱者都能消費這條訊息,
其實可以這么理解,發布/訂閱模型等于我們都加入了一個群聊中,我發一條訊息,加入了這個群聊的人都能收到這條訊息,
那么佇列模型就是一對一聊天,我發給你的訊息,只能在你的聊天視窗彈出,是不可能彈出到別人的聊天視窗中的,
講到這有人說,那我一對一聊天對每個人都發同樣的訊息不就也實作了一條訊息被多個人消費了嘛,
是的,通過多佇列全量存盤相同的訊息,即資料的冗余可以實作一條訊息被多個消費者消費,RabbitMQ 就是采用佇列模型,通過 Exchange 模塊來將訊息發送至多個佇列,解決一條訊息需要被多個消費者消費問題,
這里還能看到假設群聊里除我之外只有一個人,那么此時的發布/訂閱模型和佇列模型其實就一樣了,
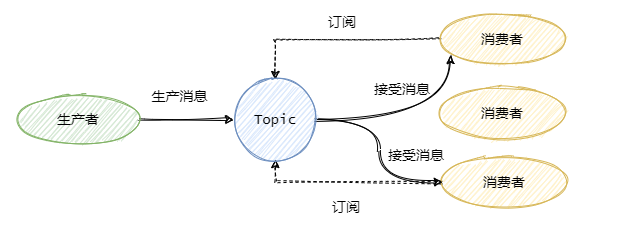
小結一下
佇列模型每條訊息只能被一個消費者消費,而發布/訂閱模型就是為讓一條訊息可以被多個消費者消費而生的,當然佇列模型也可以通過訊息全量存盤至多個佇列來解決一條訊息被多個消費者消費問題,但是會有資料的冗余,
發布/訂閱模型兼容佇列模型,即只有一個消費者的情況下和佇列模型基本一致,
RabbitMQ 采用佇列模型,RocketMQ和Kafka 采用發布/訂閱模型,
接下來的內容都基于發布/訂閱模型,
常用術語
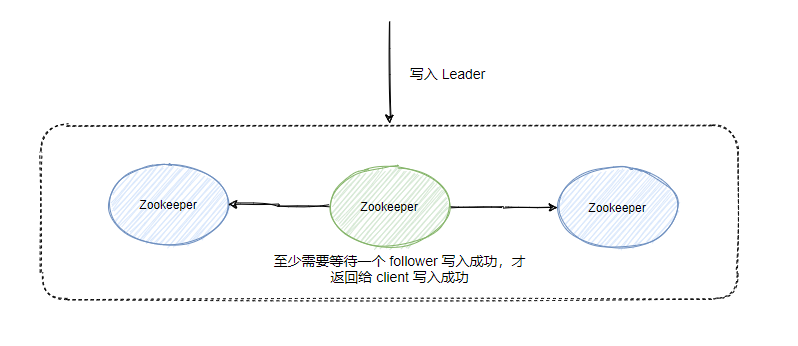
一般我們稱發送訊息方為生產者 Producer,接受消費訊息方為消費者Consumer,訊息佇列服務端為Broker,
訊息從Producer發往Broker,Broker將訊息存盤至本地,然后Consumer從Broker拉取訊息,或者Broker推送訊息至Consumer,最后消費,
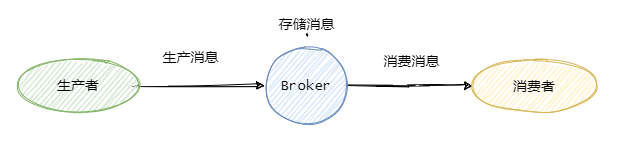
為了提高并發度,往往發布/訂閱模型還會引入佇列或者磁區的概念,即訊息是發往一個主題下的某個佇列或者某個磁區中,RocketMQ中叫佇列,Kafka叫磁區,本質一樣,
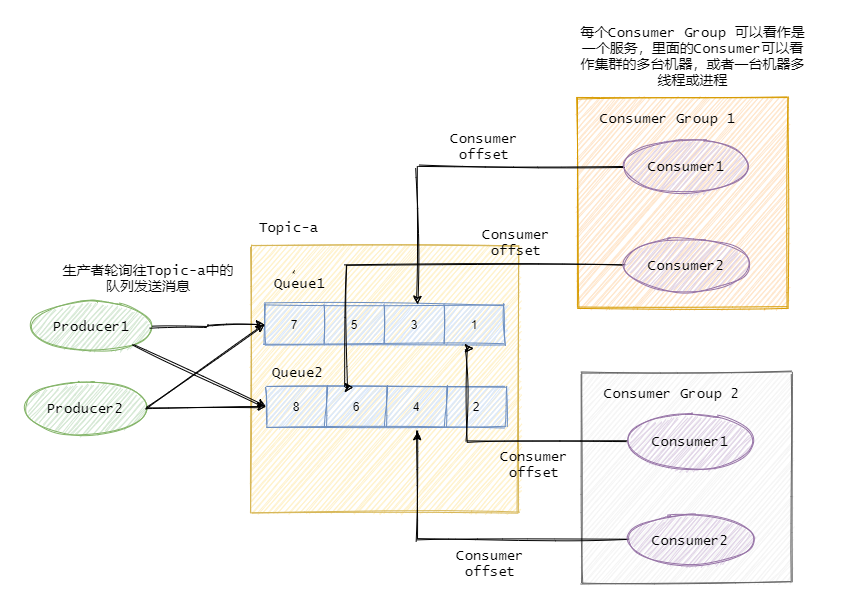
例如某個主題下有 5 個佇列,那么這個主題的并發度就提高為 5 ,同時可以有 5 個消費者并行消費該主題的訊息,一般可以采用輪詢或者 key hash 取余等策略來將同一個主題的訊息分配到不同的佇列中,
與之對應的消費者一般都有組的概念 Consumer Group, 即消費者都是屬于某個消費組的,一條訊息會發往多個訂閱了這個主題的消費組,
假設現在有兩個消費組分別是Group 1 和 Group 2,它們都訂閱了Topic-a,此時有一條訊息發往Topic-a,那么這兩個消費組都能接收到這條訊息,
然后這條訊息實際是寫入Topic某個佇列中,消費組中的某個消費者對應消費一個佇列的訊息,
在物理上除了副本拷貝之外,一條訊息在Broker中只會有一份,每個消費組會有自己的offset即消費點位來標識消費到的位置,在消費點位之前的訊息表明已經消費過了,當然這個offset是佇列級別的,每個消費組都會維護訂閱的Topic下的每個佇列的offset,
來個圖看看應該就很清晰了,
基本上熟悉了訊息佇列常見的術語和一些概念之后,咱們再來看看訊息佇列常見的核心面試點,
如何保證訊息不丟失
就我們市面上常見的訊息佇列而言,只要配置得當,我們的訊息就不會丟,
先來看看這個圖,
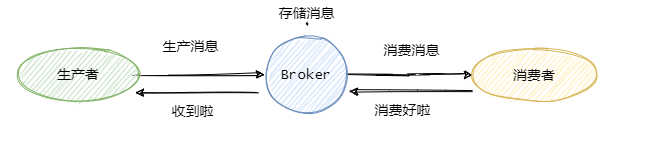
可以看到一共有三個階段,分別是生產訊息、存盤訊息和消費訊息,我們從這三個階段分別入手來看看如何確保訊息不會丟失,
生產訊息
生產者發送訊息至Broker,需要處理Broker的回應,不論是同步還是異步發送訊息,同步和異步回呼都需要做好try-catch,妥善的處理回應,如果Broker回傳寫入失敗等錯誤訊息,需要重試發送,當多次發送失敗需要作報警,日志記錄等,
這樣就能保證在生產訊息階段訊息不會丟失,
存盤訊息
存盤訊息階段需要在訊息刷盤之后再給生產者回應,假設訊息寫入快取中就回傳回應,那么機器突然斷電這訊息就沒了,而生產者以為已經發送成功了,
如果Broker是集群部署,有多副本機制,即訊息不僅僅要寫入當前Broker,還需要寫入副本機中,那配置成至少寫入兩臺機子后再給生產者回應,這樣基本上就能保證存盤的可靠了,一臺掛了還有一臺還在呢(假如怕兩臺都掛了…那就再多些),
那假如來個地震機房機子都掛了呢?emmmmmm…大公司基本上都有異地多活,
那要是這幾個地都地震了呢?emmmmmm…這時候還是先關心關心人吧,

消費訊息
這里經常會有同學犯錯,有些同學當消費者拿到訊息之后直接存入記憶體佇列中就直接回傳給Broker消費成功,這是不對的,
你需要考慮拿到訊息放在記憶體之后消費者就宕機了怎么辦,所以我們應該在消費者真正執行完業務邏輯之后,再發送給Broker消費成功,這才是真正的消費了,
所以只要我們在訊息業務邏輯處理完成之后再給Broker回應,那么消費階段訊息就不會丟失,
小結一下
可以看出,保證訊息的可靠性需要三方配合,
生產者需要處理好Broker的回應,出錯情況下利用重試、報警等手段,
Broker需要控制回應的時機,單機情況下是訊息刷盤后回傳回應,集群多副本情況下,即發送至兩個副本及以上的情況下再回傳回應,
消費者需要在執行完真正的業務邏輯之后再回傳回應給Broker,
但是要注意訊息可靠性增強了,性能就下降了,等待訊息刷盤、多副本同步后回傳都會影響性能,因此還是看業務,例如日志的傳輸可能丟那么一兩條關系不大,因此沒必要等訊息刷盤再回應,
如果處理重復訊息
我們先來看看能不能避免訊息的重復,
假設我們發送訊息,就管發,不管Broker的回應,那么我們發往Broker是不會重復的,
但是一般情況我們是不允許這樣的,這樣訊息就完全不可靠了,我們的基本需求是訊息至少得發到Broker上,那就得等Broker的回應,那么就可能存在Broker已經寫入了,當時回應由于網路原因生產者沒有收到,然后生產者又重發了一次,此時訊息就重復了,
再看消費者消費的時候,假設我們消費者拿到訊息消費了,業務邏輯已經走完了,事務提交了,此時需要更新Consumer offset了,然后這個消費者掛了,另一個消費者頂上,此時Consumer offset還沒更新,于是又拿到剛才那條訊息,業務又被執行了一遍,于是訊息又重復了,
可以看到正常業務而言訊息重復是不可避免的,因此我們只能從另一個角度來解決重復訊息的問題,
關鍵點就是冪等,既然我們不能防止重復訊息的產生,那么我們只能在業務上處理重復訊息所帶來的影響,

冪等處理重復訊息
冪等是數學上的概念,我們就理解為同樣的引數多次呼叫同一個介面和呼叫一次產生的結果是一致的,
例如這條 SQL
update t1 set money = 150 where id = 1 and money = 100; 執行多少遍money都是150,這就叫冪等,
因此需要改造業務處理邏輯,使得在重復訊息的情況下也不會影響最終的結果,
可以通過上面我那條 SQL 一樣,做了個前置條件判斷,即money = 100情況,并且直接修改,更通用的是做個version即版本號控制,對比訊息中的版本號和資料庫中的版本號,
或者通過資料庫的約束例如唯一鍵,例如insert into update on duplicate key...,
或者記錄關鍵的key,比如處理訂單這種,記錄訂單ID,假如有重復的訊息過來,先判斷下這個ID是否已經被處理過了,如果沒處理再進行下一步,當然也可以用全域唯一ID等等,
基本上就這么幾個套路,真正應用到實際中還是得看具體業務細節,
如何保證訊息的有序性
有序性分:全域有序和部分有序,
全域有序
如果要保證訊息的全域有序,首先只能由一個生產者往Topic發送訊息,并且一個Topic內部只能有一個佇列(磁區),消費者也必須是單執行緒消費這個佇列,這樣的訊息就是全域有序的!
不過一般情況下我們都不需要全域有序,即使是同步MySQL Binlog也只需要保證單表訊息有序即可,
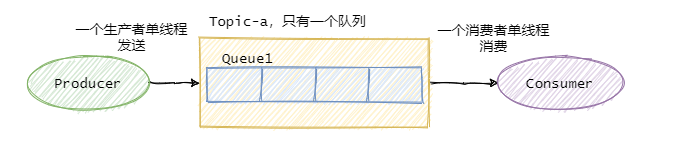
部分有序
因此絕大部分的有序需求是部分有序,部分有序我們就可以將Topic內部劃分成我們需要的佇列數,把訊息通過特定的策略發往固定的佇列中,然后每個佇列對應一個單執行緒處理的消費者,這樣即完成了部分有序的需求,又可以通過佇列數量的并發來提高訊息處理效率,
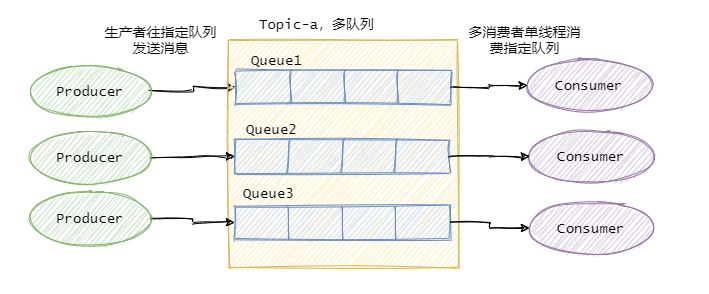
圖中我畫了多個生產者,一個生產者也可以,只要同類訊息發往指定的佇列即可,
如果處理訊息堆積
訊息的堆積往往是因為生產者的生產速度與消費者的消費速度不匹配,有可能是因為訊息消費失敗反復重試造成的,也有可能就是消費者消費能力弱,漸漸地訊息就積壓了,
因此我們需要先定位消費慢的原因,如果是bug則處理 bug ,如果是因為本身消費能力較弱,我們可以優化下消費邏輯,比如之前是一條一條訊息消費處理的,這次我們批量處理,比如資料庫的插入,一條一條插和批量插效率是不一樣的,
假如邏輯我們已經都優化了,但還是慢,那就得考慮水平擴容了,增加Topic的佇列數和消費者數量,注意佇列數一定要增加,不然新增加的消費者是沒東西消費的,一個Topic中,一個佇列只會分配給一個消費者,
當然你消費者內部是單執行緒還是多執行緒消費那看具體場景,不過要注意上面提高的訊息丟失的問題,如果你是將接受到的訊息寫入記憶體佇列之后,然后就回傳回應給Broker,然后多執行緒向記憶體佇列消費訊息,假設此時消費者宕機了,記憶體佇列里面還未消費的訊息也就丟了,
最后
上面的幾個問題都是我們在使用訊息佇列的時候經常能遇到的問題,并且也是面試關于訊息佇列方面的核心考點,今天沒有深入具體訊息佇列的細節,但是套路就是這么個套路,大方向上搞明白很關鍵
如何設計一個訊息佇列?
這種設計類問題想必大家都不陌生,面試時或多或少都能碰到,
比如如何寫一個執行緒池?如何寫一個 HashMap ?如何寫一個 RPC 框架等等,當然這里的寫不是真的叫你用代碼寫出來,只是說說設計理念,整體架構,
這個面試題來自于一個讀者的位元組面試經歷,我會從面試技巧和訊息中間件的設計兩個方面闡述,
我覺得重點在于面試技巧,因為它通用,
兩種極端的情況
大多數同學遇到這種問題會出現兩種極端的情況:
-
第一種:一臉懵逼,兩眼無神,不知從何說起,萬般思緒,都化作一聲嘆息,
-
第二種:夸夸其談,像是口中架起了一把加特林,噠噠噠噠噠噠噠噠,還冒著藍火,

第一種不用說了,好一點的面試官可能會引導你,會問一些提示性的問題,一步一步地帶你漸入佳境,當然你要是胸中無點滴,那還是沒救的,場面就例外地尷尬,
第二種會把面試官整蒙了,或許你真的懂很多,很多細節也都清晰,但是你不能一股腦兒的都拋出來,這會顯得你抓不住重點,
面試官也是人
這點其實很關鍵,很多把面試官當成一個莫得感情的提問機器人,覺得他無所不能可以完全 get 到你的點,殊不知你引以為傲的細節回答,他可能覺得你在說蛇皮,
是人就會有感情,就需要交流,好的面試官會把控整體進度,從拉家常開始,讓場子熱起來再一步一步的深挖,
當然也有一些面試官比較弱,這時候就需要你來特意地流出一點空白,來讓面試官涂鴉,讓面試官感覺你這人就很舒服,你這波就穩了,
當然即使面對著把控全場的面試官你也得主動出擊,每個人都有自己的擅長點,你需要引導面試官來詢問你的長處,
正確的回答姿勢
正確的回答姿勢是 BFS(廣度優先搜索) 而不是 DFS (深度優先搜索),什么意思呢?
就是我們需要先從大局上講出需要設計的東西的重點,然后再等待面試官的繼續提問,深挖,
我們需要揣摩面試官的心理,從他的提問可以看出他想要知道的重點是哪個方向的,
比如就拿 HashMap 來說,你簡單的把獲取、寫入、沖突處理、擴容啥的都說了,然后等待面試官接下來的提問,有可能會往執行緒安全方面深入,也有可能會往擴容方向再挖,比如引出 Redis 的 hash 擴容等等,
所以說給面試官留提問的機會,抓住他的喜好或者說熟知的方向回答,這樣如果你答得好,相互之間談的來,面試官會對你高度認可,
而且在說各設計要點的時候也要注意停頓,要留機會給面試官插話,讓面試官充分參與你的設計,
還是拿 HashMap 作為例子,比如你說了獲取、寫入、沖突之后稍作停頓,這時候大概率面試官還會問還有嗎?讓面試官有參與感,讓他感覺經過他的引導這個設計才逐步地完善,

當然如果不問也沒事,你停頓下繼續說就行,
讓面試成為一場技術交流,這是面試的最高境界,相信面試完了之后雙方都會有意猶未盡的感覺,惺惺相惜就是這么來的,
但是這種場景也不是這么容易碰到的,首先你和面試官得有相同方向的喜好,比如你對 JVM 有很深入的研究,而面試官對存盤方面有很深入的研究,JVM 懂的不深,這樣就碰不出火花了,
所以說會有很多人碰到這么個情況:我面這個公司一面掛,另一家公司面面超神,這都是很正常的,
當然你要是說你全能,那當我沒說,
小結一下面試技巧
首先要正確的看待面試官,你和面試官是同等的,不要一來就低聲下氣的,
其次回答問題需要抓住重點,不要一股腦兒的把你知道的都說了,要留白待面試官提問,
要把控面試的節奏,往自己熟知的方向上引,
如何寫個訊息中間件
接下來咱們再看看如何寫個訊息中間件,
首先我們需要明確地提出訊息中間件的幾個重要角色,分別是生產者、消費者、Broker、注冊中心,
簡述下訊息中間件資料流轉程序,無非就是生產者生成訊息,發送至 Broker,Broker 可以暫緩訊息,然后消費者再從 Broker 獲取訊息,用于消費,
而注冊中心用于服務的發現包括:Broker 的發現、生產者的發現、消費者的發現,當然還包括下線,可以說服務的高可用離不開注冊中心,
然后開始簡述實作要點,可以同通信講起:各模塊的通信可以基于 Netty 然后自定義協議來實作,注冊中心可以利用 zookeeper、consul、eureka、nacos 等等,也可以像 RocketMQ 自己實作簡單的 namesrv (這一句話就都是關鍵詞),
為了考慮擴容和整體的性能,采用分布式的思想,像 Kafka 一樣采取磁區理念,一個 Topic 分為多個 partition,并且為保證資料可靠性,采取多副本存盤,即 Leader 和 follower,根據性能和資料可靠的權衡提供異步和同步的刷盤存盤,
并且利用選舉演算法保證 Leader 掛了之后 follower 可以頂上,保證訊息佇列的高可用,
也同樣為了提高訊息佇列的可靠性利用本地檔案系統來存盤訊息,并且采用順序寫的方式來提高性能,
可根據訊息佇列的特性利用記憶體映射、零拷貝進一步的提升性能,還可利用像 Kafka 這種批處理思想提高整體的吞吐,
至此就差不多了,該說的要點說的都差不多了,面試官心里已經想,這人好像有點東西,

之后可以深挖的點就很多了,比如提到的 Netty,各種注冊中心就能問很多,比如各注冊中心之間的選型對比等,
你還提到了選舉演算法,所以可能會問 Bully 演算法、Raft 演算法、ZAB 演算法等等,
你還提到了磁區,可能會問這個磁區和 RocketMQ 的佇列有什么不同啊?具體磁區要怎么實作?
然后你提到順序寫,可能會問為什么要順序寫啊?你說的記憶體映射和零拷貝又是什么啊?那你知道 RocketMQ 和 Kafka 用了哪個嗎?
當然還有可能問各種細節,比如訊息的寫入如何存盤、訊息的索引如何生成等等,來深挖看你有沒有看過訊息中間件的原始碼,
可以問的還很多,這篇文章我也不可能每個點都延伸開說,這些知識點還是得靠大家榷訓月累和平日的多加思考,
當然日后的文章可以寫一寫今天提到的一些點,比如 Netty、選舉演算法啊,多種注冊中心對比啊啥的,
面試官想問的是什么
再回到這個面試題,其實面試官想問的就是大方向上的設計,包括整體的架構、資料的流轉和一些特性的把握,所以對于這個問題他想聽到的就是那些重點,而不是那些細節,
而繼續的深挖取決于你回答這個問題時提出的各個關鍵詞,對于面試官自身而言熟悉的詞一抓到,他就已經知道下一步要問你什么了,
所以在回答面試官的時候不僅要 get 到他的點,還得為之后的回答鋪路,不會說的點不要提,擅長的點多提提,
最后
之前我已經提到了,這篇文章的重點其實不在于如何回答寫一個訊息中間件,而在于面試的技巧,
因為面試題千千萬,而技巧掌握了那么千千萬的面試題都適用,
我還想提一下關于面試的一些個人看法,我個人是面試驅動學習型選手,我學習的動力就是面試,我享受面試官問我啥我都嘴角一翹微微一笑的那種不羈,
但是我不提倡那種純粹背面試題的做法,學習是一個榷訓月累的程序,就像我每篇文末說的,從一點點到億點點,又像我每篇開頭都會提的,每個時代,都不會虧待會學習的人,
我的面試驅動不僅僅是說為了面試而學習,還要以面試場景來學習,什么意思呢?
學任何一種東西,都模擬一個面試官在你前面,讓他從各種角度向你提問,驅動你全方位的理解一個知識點,這才是我說的面試驅動學習型選手,
所以如果你看過我之前的文章會發現我經常會提出為什么呢,然后再作答,
還有一點要注意,動手能力,這很關鍵,
Talk is cheap, show me the code,
訊息佇列設計成推訊息還是拉訊息?RocketMQ和Kafka是怎么做的?
今天我們就來談一談訊息佇列的推拉模式,這也是一個面試熱點,例如你在簡歷里面寫了 RocketMQ ,基本上會問你 RocketMQ 采用的是推模式還是拉模式啊?是拉模式?不是有 PushConsumer 嗎?
今天我們就來談談推拉模式,并且再來看看 RocketMQ 和 Kafka 是如何做的,
推拉模式
首先明確一下推拉模式到底是在討論訊息佇列的哪一個步驟,一般而言我們在談論推拉模式的時候指的是 Comsumer 和 Broker 之間的互動,
默認的認為 Producer 與 Broker 之間就是推的方式,即 Producer 將訊息推送給 Broker,而不是 Broker 主動去拉取訊息,
想象一下,如果需要 Broker 去拉取訊息,那么 Producer 就必須在本地通過日志的形式保存訊息來等待 Broker 的拉取,如果有很多生產者的話,那么訊息的可靠性不僅僅靠 Broker 自身,還需要靠成百上千的 Producer,
Broker 還能靠多副本等機制來保證訊息的存盤可靠,而成百上千的 Producer 可靠性就有點難辦了,所以默認的 Producer 都是推訊息給 Broker,
所以說有些情況分布式好,而有些時候還是集中管理好,
推模式
推模式指的是訊息從 Broker 推向 Consumer,即 Consumer 被動的接收訊息,由 Broker 來主導訊息的發送,
我們來想一下推模式有什么好處?
訊息實時性高, Broker 接受完訊息之后可以立馬推送給 Consumer,
對于消費者使用來說更簡單,簡單啊就等著,反正有訊息來了就會推過來,
推模式有什么缺點?
推送速率難以適應消費速率,推模式的目標就是以最快的速度推送訊息,當生產者往 Broker 發送訊息的速率大于消費者消費訊息的速率時,隨著時間的增長消費者那邊可能就“爆倉”了,因為根本消費不過來啊,當推送速率過快就像 DDos 攻擊一樣消費者就傻了,
并且不同的消費者的消費速率還不一樣,身為 Broker 很難平衡每個消費者的推送速率,如果要實作自適應的推送速率那就需要在推送的時候消費者告訴 Broker ,我不行了你推慢點吧,然后 Broker 需要維護每個消費者的狀態進行推送速率的變更,
這其實就增加了 Broker 自身的復雜度,
所以說推模式難以根據消費者的狀態控制推送速率,適用于訊息量不大、消費能力強要求實時性高的情況下,
拉模式
拉模式指的是 Consumer 主動向 Broker 請求拉取訊息,即 Broker 被動的發送訊息給 Consumer,
我們來想一下拉模式有什么好處?
拉模式主動權就在消費者身上了,消費者可以根據自身的情況來發起拉取訊息的請求,假設當前消費者覺得自己消費不過來了,它可以根據一定的策略停止拉取,或者間隔拉取都行,
拉模式下 Broker 就相對輕松了,它只管存生產者發來的訊息,至于消費的時候自然由消費者主動發起,來一個請求就給它訊息唄,從哪開始拿訊息,拿多少消費者都告訴它,它就是一個沒有感情的工具人,消費者要是沒來取也不關它的事,
拉模式可以更合適的進行訊息的批量發送,基于推模式可以來一個訊息就推送,也可以快取一些訊息之后再推送,但是推送的時候其實不知道消費者到底能不能一次性處理這么多訊息,而拉模式就更加合理,它可以參考消費者請求的資訊來決定快取多少訊息之后批量發送,
拉模式有什么缺點?
訊息延遲,畢竟是消費者去拉取訊息,但是消費者怎么知道訊息到了呢?所以它只能不斷地拉取,但是又不能很頻繁地請求,太頻繁了就變成消費者在攻擊 Broker 了,因此需要降低請求的頻率,比如隔個 2 秒請求一次,你看著訊息就很有可能延遲 2 秒了,
訊息忙請求,忙請求就是比如訊息隔了幾個小時才有,那么在幾個小時之內消費者的請求都是無效的,在做無用功,

那到底是推還是拉
可以看到推模式和拉模式各有優缺點,到底該如何選擇呢?
RocketMQ 和 Kafka 都選擇了拉模式,當然業界也有基于推模式的訊息佇列如 ActiveMQ,
我個人覺得拉模式更加的合適,因為現在的訊息佇列都有持久化訊息的需求,也就是說本身它就有個存盤功能,它的使命就是接受訊息,保存好訊息使得消費者可以消費訊息即可,
而消費者各種各樣,身為 Broker 不應該有依賴于消費者的傾向,我已經為你保存好訊息了,你要就來拿好了,
雖說一般而言 Broker 不會成為瓶頸,因為消費端有業務消耗比較慢,但是 Broker 畢竟是一個中心點,能輕量就盡量輕量,
那么竟然 RocketMQ 和 Kafka 都選擇了拉模式,它們就不怕拉模式的缺點么? 怕,所以它們操作了一波,減輕了拉模式的缺點,
長輪詢
RocketMQ 和 Kafka 都是利用“長輪詢”來實作拉模式,我們就來看看它們是如何操作的,
為了簡單化,下面我把訊息不滿足本次拉取的條數啊、總大小啊等等都統一描述成還沒有訊息,反正都是不滿足條件,
RocketMQ 中的長輪詢
RocketMQ 中的 PushConsumer 其實是披著拉模式的方法,只是看起來像推模式而已,
因為 RocketMQ 在被背后偷偷的幫我們去 Broker 請求資料了,
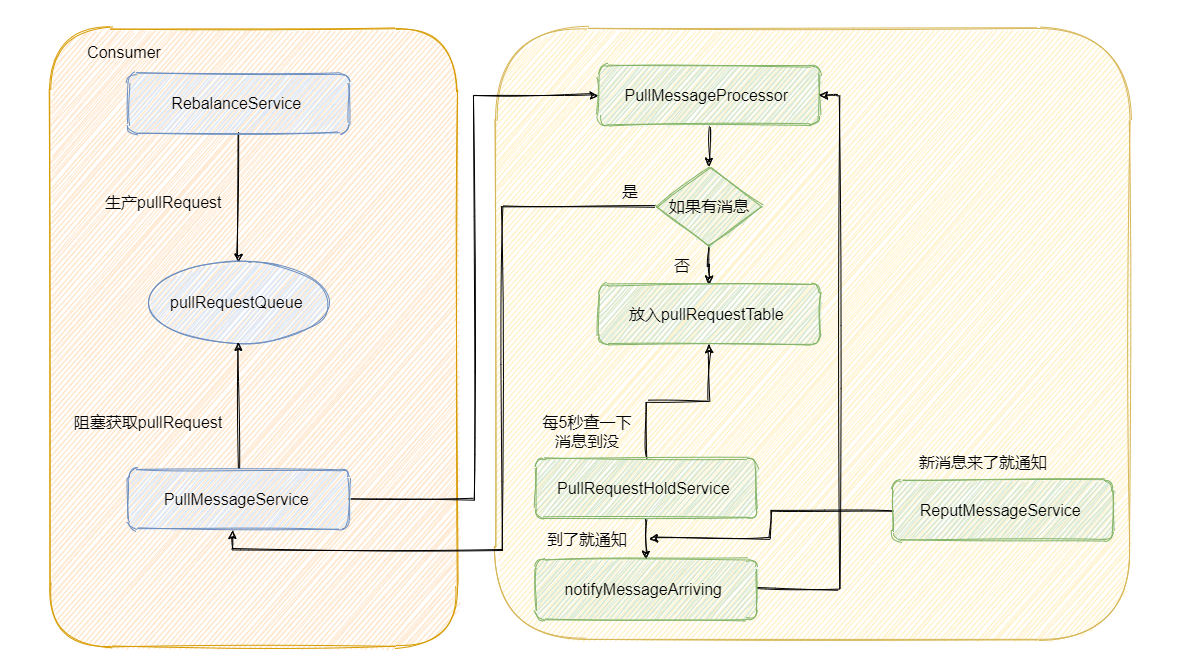
后臺會有個 RebalanceService 執行緒,這個執行緒會根據 topic 的佇列數量和當前消費組的消費者個數做負載均衡,每個佇列產生的 pullRequest 放入阻塞佇列 pullRequestQueue 中,然后又有個 PullMessageService 執行緒不斷的從阻塞佇列 pullRequestQueue 中獲取 pullRequest,然后通過網路請求 broker,這樣實作的準實時拉取訊息,
這一部分代碼我不截了,就是這么個事兒,稍后會用圖來展示,
然后 Broker 的 PullMessageProcessor 里面的 processRequest 方法是用來處理拉訊息請求的,有訊息就直接回傳,如果沒有訊息怎么辦呢?我們來看一下代碼,
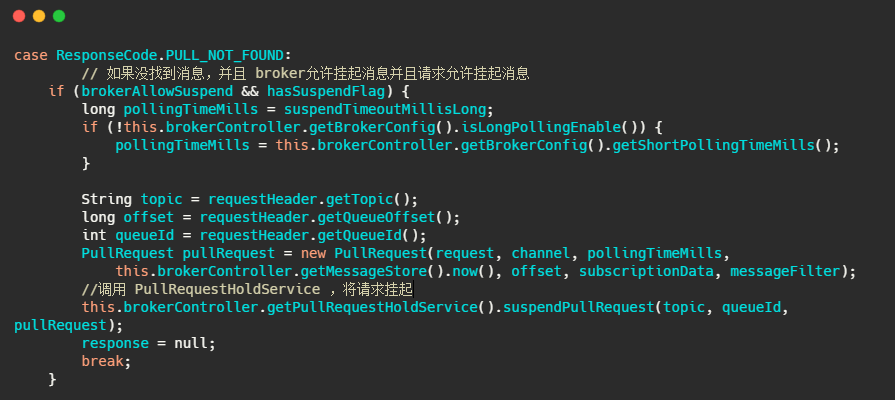
我們再來看下 suspendPullRequest 方法做了什么,
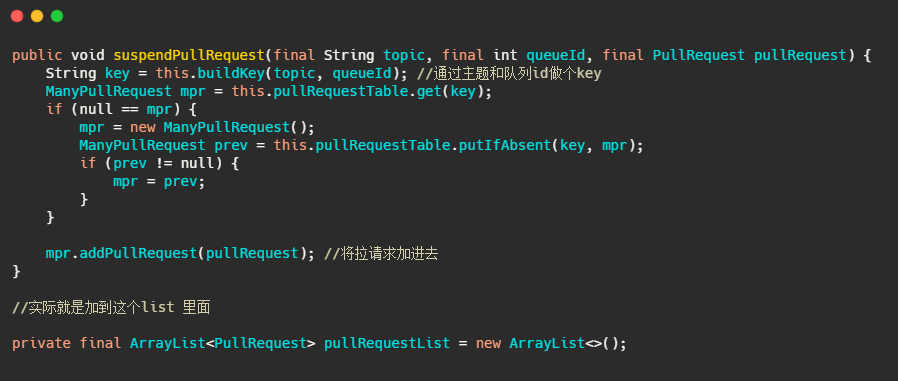
而 PullRequestHoldService 這個執行緒會每 5 秒從 pullRequestTable 取PullRequest請求,然后看看待拉取訊息請求的偏移量是否小于當前消費佇列最大偏移量,如果條件成立則說明有新訊息了,則會呼叫 notifyMessageArriving ,最終呼叫 PullMessageProcessor 的 executeRequestWhenWakeup() 方法重新嘗試處理這個訊息的請求,也就是再來一次,整個長輪詢的時間默認 30 秒,
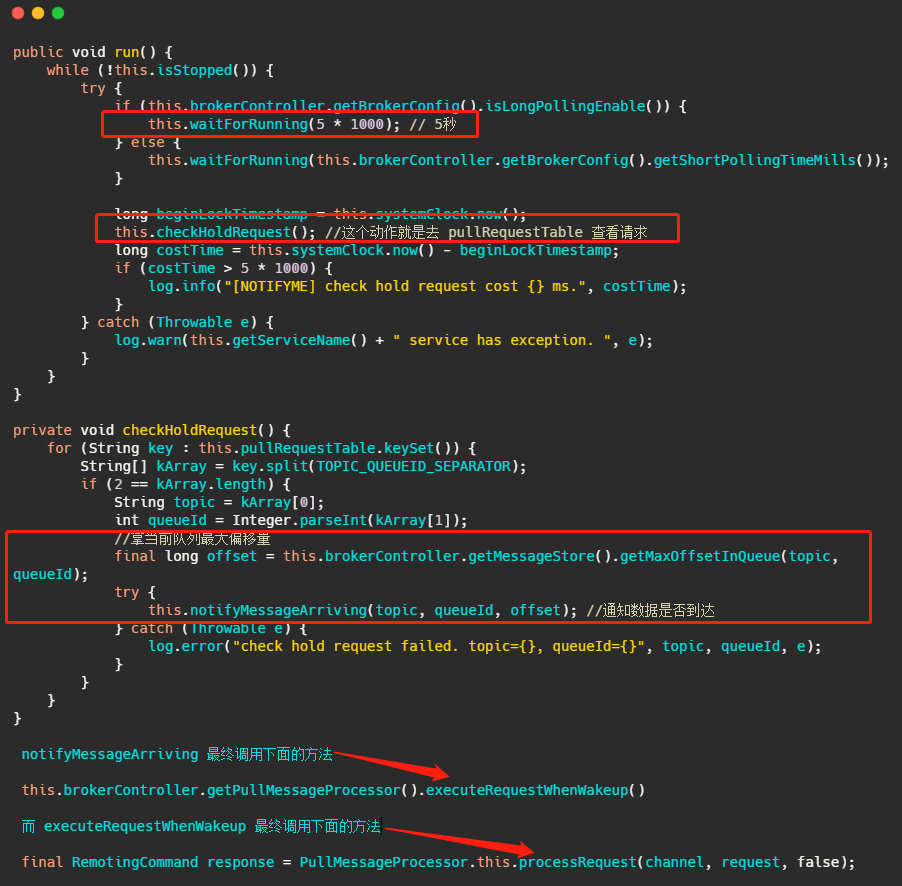
簡單的說就是 5 秒會檢查一次訊息時候到了,如果到了則呼叫 processRequest 再處理一次,這好像不太實時啊? 5秒?
別急,還有個 ReputMessageService 執行緒,這個執行緒用來不斷地從 commitLog 中決議資料并分發請求,構建出 ConsumeQueue 和 IndexFile 兩種型別的資料,并且也會有喚醒請求的操作,來彌補每 5s 一次這么慢的延遲
代碼我就不截了,就是訊息寫入并且會呼叫 pullRequestHoldService#notifyMessageArriving,
最后我再來畫個圖,描述一下整個流程,
Kafka 中的長輪詢
像 Kafka 在拉請求中有引數,可以使得消費者請求在 “長輪詢” 中阻塞等待,
簡單的說就是消費者去 Broker 拉訊息,定義了一個超時時間,也就是說消費者去請求訊息,如果有的話馬上回傳訊息,如果沒有的話消費者等著直到超時,然后再次發起拉訊息請求,
并且 Broker 也得配合,如果消費者請求過來,有訊息肯定馬上回傳,沒有訊息那就建立一個延遲操作,等條件滿足了再回傳,
我們來簡單的看一下原始碼,為了突出重點,我會刪減一些代碼,
先來看消費者端的代碼,
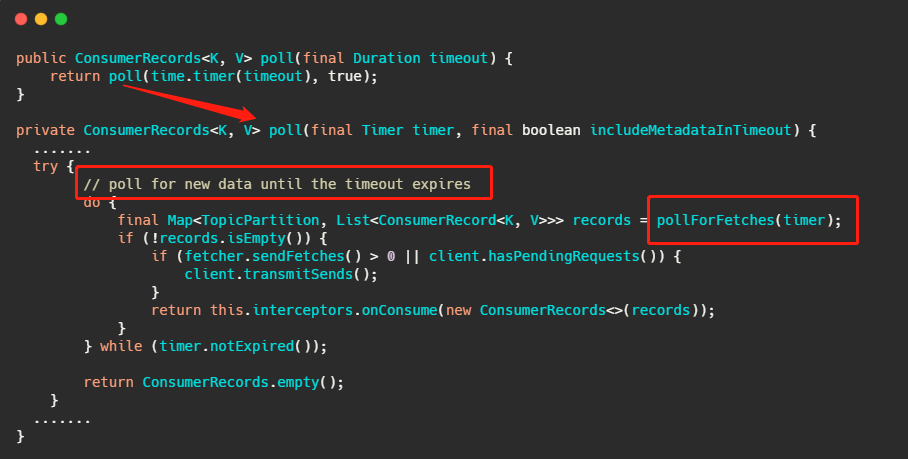
上面那個 poll 介面想必大家都很熟悉,其實從注解直接就知道了確實是等待資料的到來或者超時,我們再簡單的往下看,
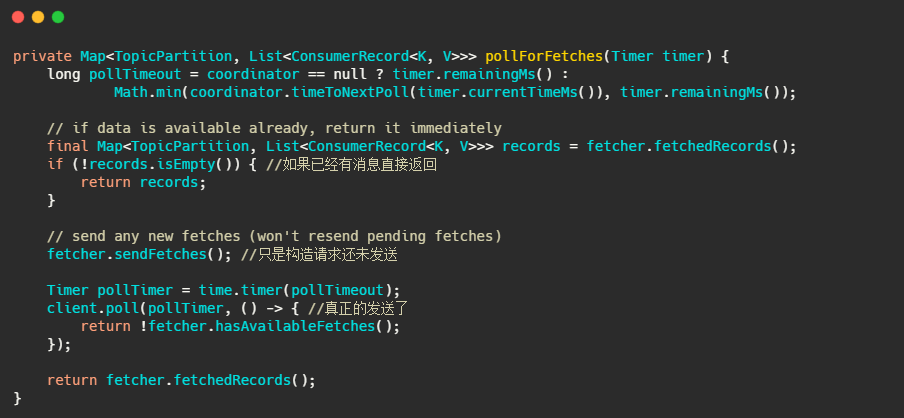
我們再來看下最終 client.poll 呼叫的是什么,
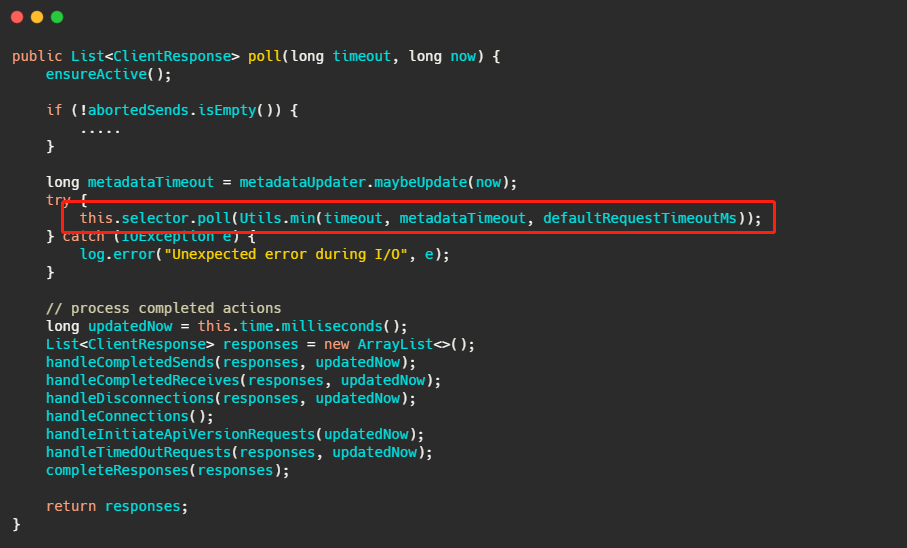
最后呼叫的就是 Kafka 包裝過的 selector,而最侄訓呼叫 Java nio 的 select(timeout),
現在消費者端的代碼已經清晰了,我們再來看看 Broker 如何做的,
Broker 處理所有請求的入口其實我在之前的文章介紹過,就在 KafkaApis.scala 檔案的 handle 方法下,這次的主角就是 handleFetchRequest ,
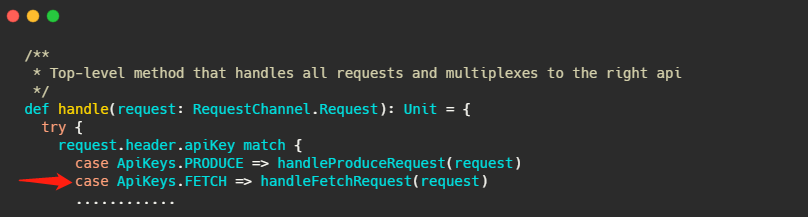
這個方法進來,我截取最重要的部分,
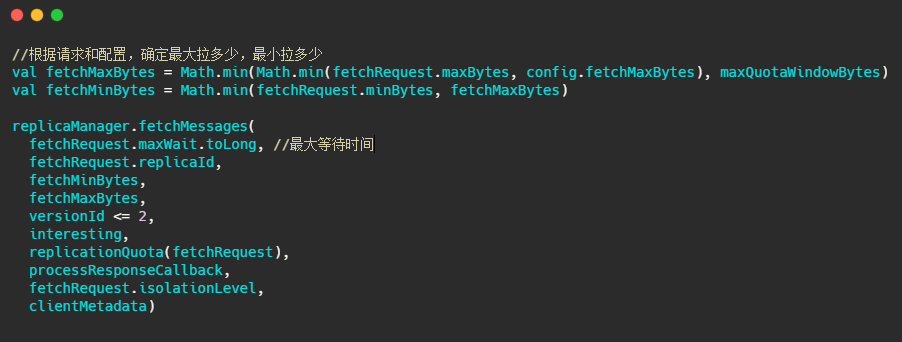
下面的圖片就是 fetchMessages 方法內部實作,原始碼給的注釋已經很清晰了,大家放大圖片看下即可,
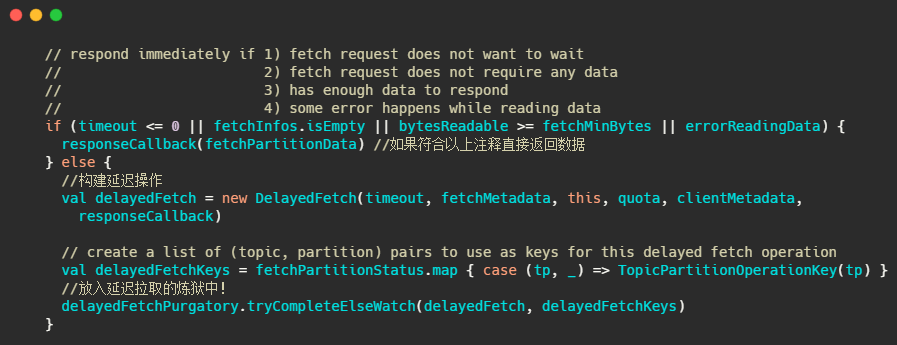
這個煉獄名字取得很有趣,簡單的說就是利用我之前文章提到的時間輪,來執行定時任務,例如這里是delayedFetchPurgatory,專門用來處理延遲拉取操作,
我們先簡單想一下,這個延遲操作都需要實作哪些方法,首先構建的延遲操作需要有檢查機制,來查看訊息是否已經到了,然后呢還得有個訊息到了之后該執行的方法,還需要有執行完畢之后該干啥的方法,當然還得有個超時之后得干啥的方法,
這幾個方法其實對應的就是代碼里的 DelayedFetch ,這個類繼承了 DelayedOperation 內部有:
- isCompleted 檢查條件是否滿足的方法
- tryComplete 條件滿足之后執行的方法
- onComplete 執行完畢之后呼叫的方法
- onExpiration 過期之后需要執行的方法
判斷是否過期就是由時間輪來推動判斷的,但是總不能等過期的時候再去看訊息到了沒吧?
這里 Kafka 和 RocketMQ 的機制一樣,也會在訊息寫入的時候提醒這些延遲請求訊息來了,具體代碼我不貼了, 在 ReplicaManager#appendRecords 方法內部再深入個兩方法可以看到,
不過雖說代碼不貼,圖還是要畫一下的,
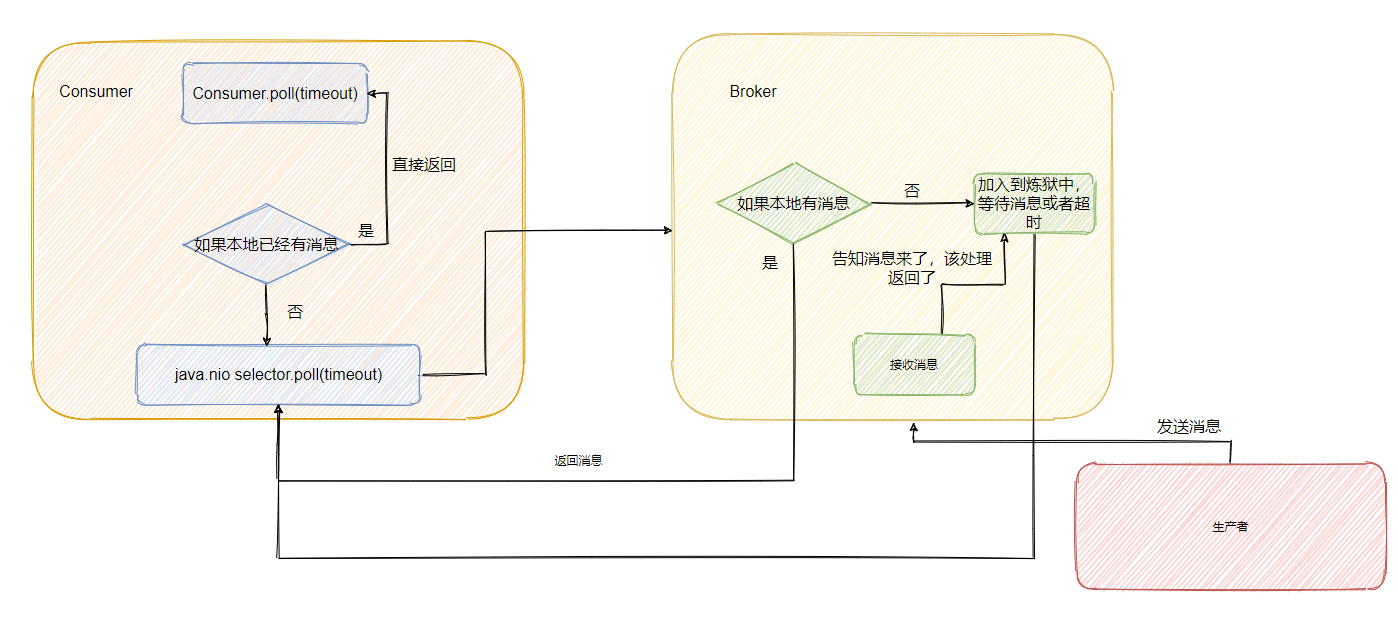
小結一下
可以看到 RocketMQ 和 Kafka 都是采用“長輪詢”的機制,具體的做法都是通過消費者等待訊息,當有訊息的時候 Broker 會直接回傳訊息,如果沒有訊息都會采取延遲處理的策略,并且為了保證訊息的及時性,在對應佇列或者磁區有新訊息到來的時候都會提醒訊息來了,及時回傳訊息,
一句話說就是消費者和 Broker 相互配合,拉取訊息請求不滿足條件的時候 hold 住,避免了多次頻繁的拉取動作,當訊息一到就提醒回傳,
最后
總的而言推拉模式各有優劣,而我個人覺得一般情況下拉模式更適合于訊息佇列,
看了這篇文章相信之后面試官問你推還是拉?建議給他個歪嘴笑,

訊息佇列之事務訊息?RocketMQ和Kafka是怎么做的?
今天我們來談一談訊息佇列的事務訊息,一說起事務相信大家都不陌生,腦海里蹦出來的就是 ACID,
通常我們理解的事務就是為了一些更新操作要么都成功,要么都失敗,不會有中間狀態的產生,而 ACID 是一個嚴格的事務實作的定義,不過在單體系統時候一般都不會嚴格的遵循 ACID 的約束來實作事務,更別說分布式系統了,
分布式系統往往只能妥協到最終一致性,保證資料最終的完整性和一致性,主要原因就是實力不允許…因為可用性為王,
而且要保證完全版的事務實作代價很大,你想想要維護這么多系統的資料,不允許有中間狀態資料可以被讀取,所有的操作必須不可分割,這意味著一個事務的執行是阻塞的,資源是被長時間鎖定的,
在高并發情況下資源被長時間的占用,就是致命的傷害,舉一個有味道的例子,如廁高峰期,好了懂得都懂,

對了, ACID 是什么還不太清楚的同學,趕緊去查一查,這里我就不展開說了,
分布式事務
那說到分布式事務,常見的有 2PC、TCC 和事務訊息,這篇文章重點就是事務訊息,不過 2PC 和 TCC 我稍微提一下,
2PC
2PC 就是二階段提交,分別有協調者和參與者兩個角色,二階段分別是準備階段和提交階段,
準備階段就是協調者向各參與者發送準備命令,這個階段參與者除了事務的提交啥都做了,而提交階段就是協調者看看各個參與者準備階段都 o 不 ok,如果有 ok 那么就向各個參與者發送提交命令,如果有一個不 ok 那么就發送回滾命令,
這里的重點就是 2PC 只適用于資料庫層面的事務,什么意思呢?就是你想在資料庫里面寫一條資料同時又要上傳一張圖片,這兩個操作 2PC 無法保證兩個操作滿足事務的約束,
而且 2PC 是一種強一致性的分布式事務,它是同步阻塞的,即在接收到提交或回滾命令之前,所有參與者都是互相等待,特別是執行完準備階段的時候,此時的資源都是鎖定的狀態,假如有一個參與者卡了很久,其他參與者都得等它,產生長時間資源鎖定狀態下的阻塞,
總體而言效率低,并且存在單點故障問題,協調者是就是那個單點,并且在極端條件下存在資料不一致的風險,例如某個參與者未收到提交命令,此時宕機了,恢復之后資料是回滾的,而其他參與者其實都已經執行了提交事務的命令了,
TCC
TCC 能保證業務層面的事務,也就是說它不僅僅是資料庫層面,上面的上傳圖片這種操作它也能做,
TCC 分為三個階段 try - confirm - cancel,簡單的說就是每個業務都需要有這三個方法,先都執行 try 方法,這一階段不會做真正的業務操作,只是先占個坑,什么意思呢?比如打算加 10 個積分,那先在預添加欄位加上這 10 積分,這個時候用戶賬上的積分其實是沒有增加的,
然后如果都 try 成功了那么就執行 confirm 方法,大家都來做真正的業務操作,如果有一個 try 失敗了那么大家都執行 cancel 操作,來撤回剛才的修改,
可以看到 TCC 其實對業務的耦合性很大,因為業務上需要做一定的改造才能完成這三個方法,這其實就是 TCC 的缺點,并且 confirm 和 cancel 操作要注意冪等,因為到執行這兩步的時候沒有退路,是務必要完成的,因此需要有重試機制,所以需要保證方法冪等,
事務訊息
事務訊息就是今天文章的主角了,它主要是適用于異步更新的場景,并且對資料實時性要求不高的地方,
它的目的是為了解決訊息生產者與訊息消費者的資料一致性問題,
比如你點外賣,我們先選了炸雞加入購物車,又選了瓶可樂,然后下單,付完款這個流程就結束了,

而購物車里面的資料就很適合用訊息通知異步洗掉,因為一般而言我們下完單不會再去點開這個店家的選單,而且就算點開了購物車里還有這些菜品也沒有關系,影響不大,
我們希望的就是下單成功之后購物車的菜品最侄訓被洗掉,所以要點就是下單和發訊息這兩個步驟要么都成功要么都失敗,
RocketMQ 事務訊息
我們先來看一下 RocketMQ 是如何實作事務訊息的,
RocketMQ 的事務訊息也可以被認為是一個兩階段提交,簡單的說就是在事務開始的時候會先發送一個半訊息給 Broker,
半訊息的意思就是這個訊息此時對 Consumer 是不可見的,而且也不是存在真正要發送的佇列中,而是一個特殊佇列,
發送完半訊息之后再執行本地事務,再根據本地事務的執行結果來決定是向 Broker 發送提交訊息,還是發送回滾訊息,
此時有人說這一步發送提交或者回滾訊息失敗了怎么辦?
影響不大,Broker 會定時的向 Producer 來反查這個事務是否成功,具體的就是 Producer 需要暴露一個介面,通過這個介面 Broker 可以得知事務到底有沒有執行成功,沒成功就回傳未知,因為有可能事務還在執行,會進行多次查詢,
如果成功那么就將半訊息恢復到正常要發送的佇列中,這樣消費者就可以消費這條訊息了,
我們再來簡單的看下如何使用,我根據官網示例代碼簡化了下,
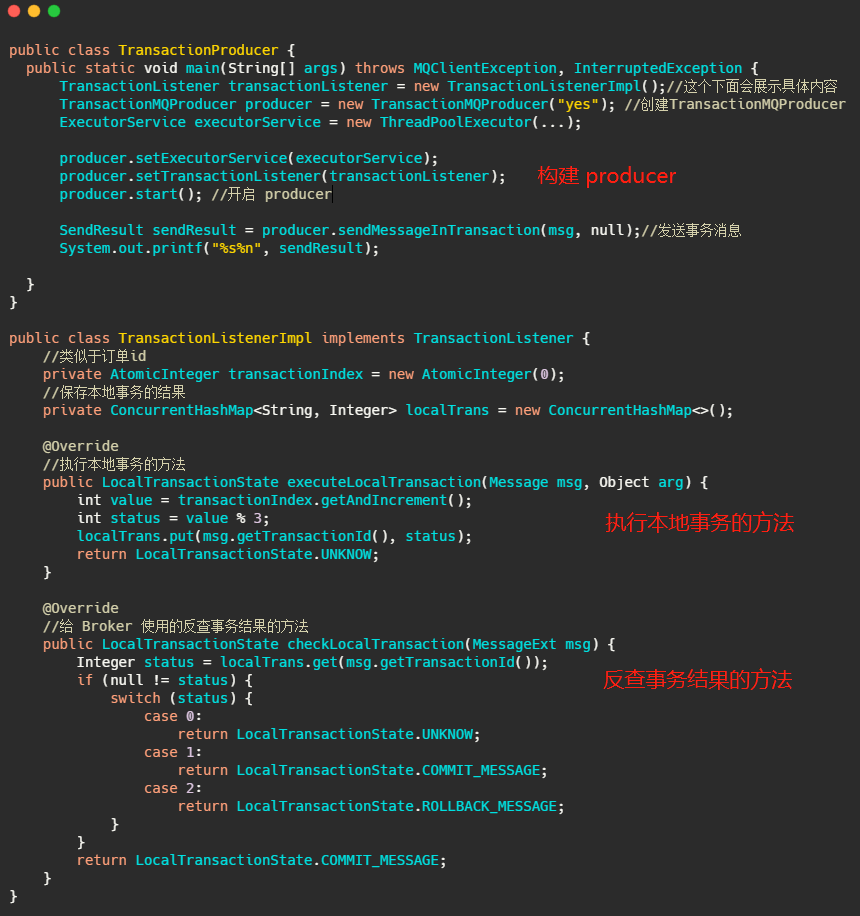
可以看到使用起來還是很簡便直觀的,無非就是多加個反查事務結果的方法,然后把本地事務執行的程序寫在 TransationListener 里面,
至此 RocketMQ 事務訊息大致的流程已經清晰了,我們畫一張整體的流程圖來過一遍,其實到第四步這個訊息要么就是正常的訊息,要么就是拋棄什么都不存在,此時這個事務訊息已經結束它的生命周期了,

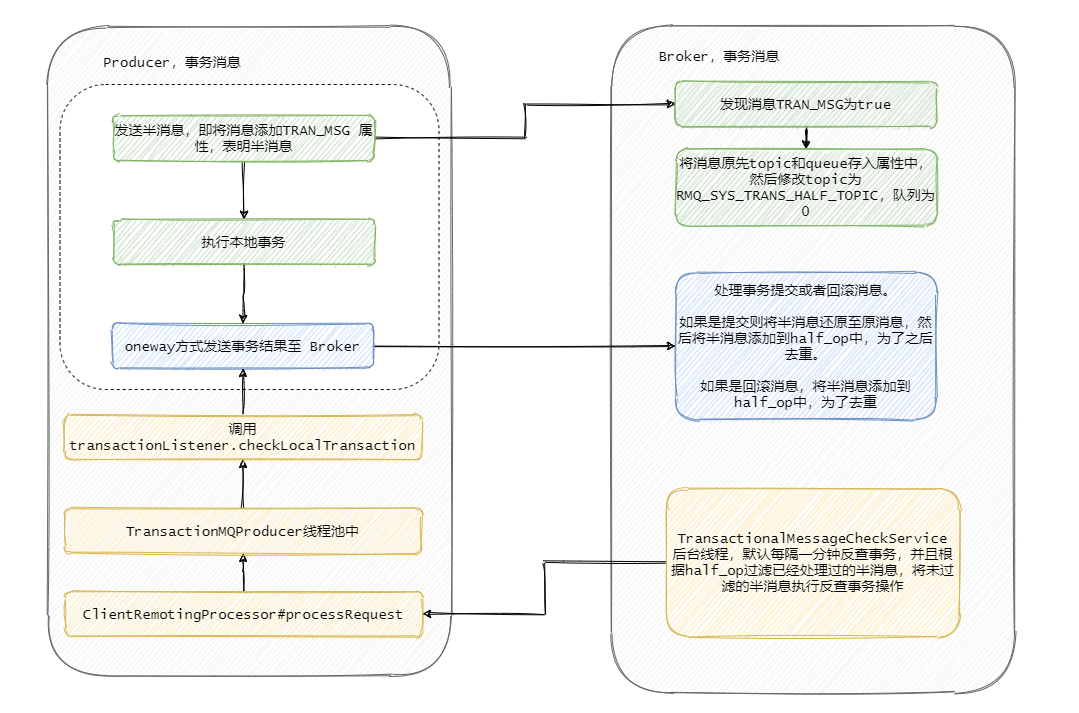
RocketMQ 事務訊息原始碼分析
然后我們再從原始碼的角度來看看到底是怎么做的,首先我們看下sendMessageInTransaction 方法,方法有點長,不過沒有關系結構還是很清晰的,
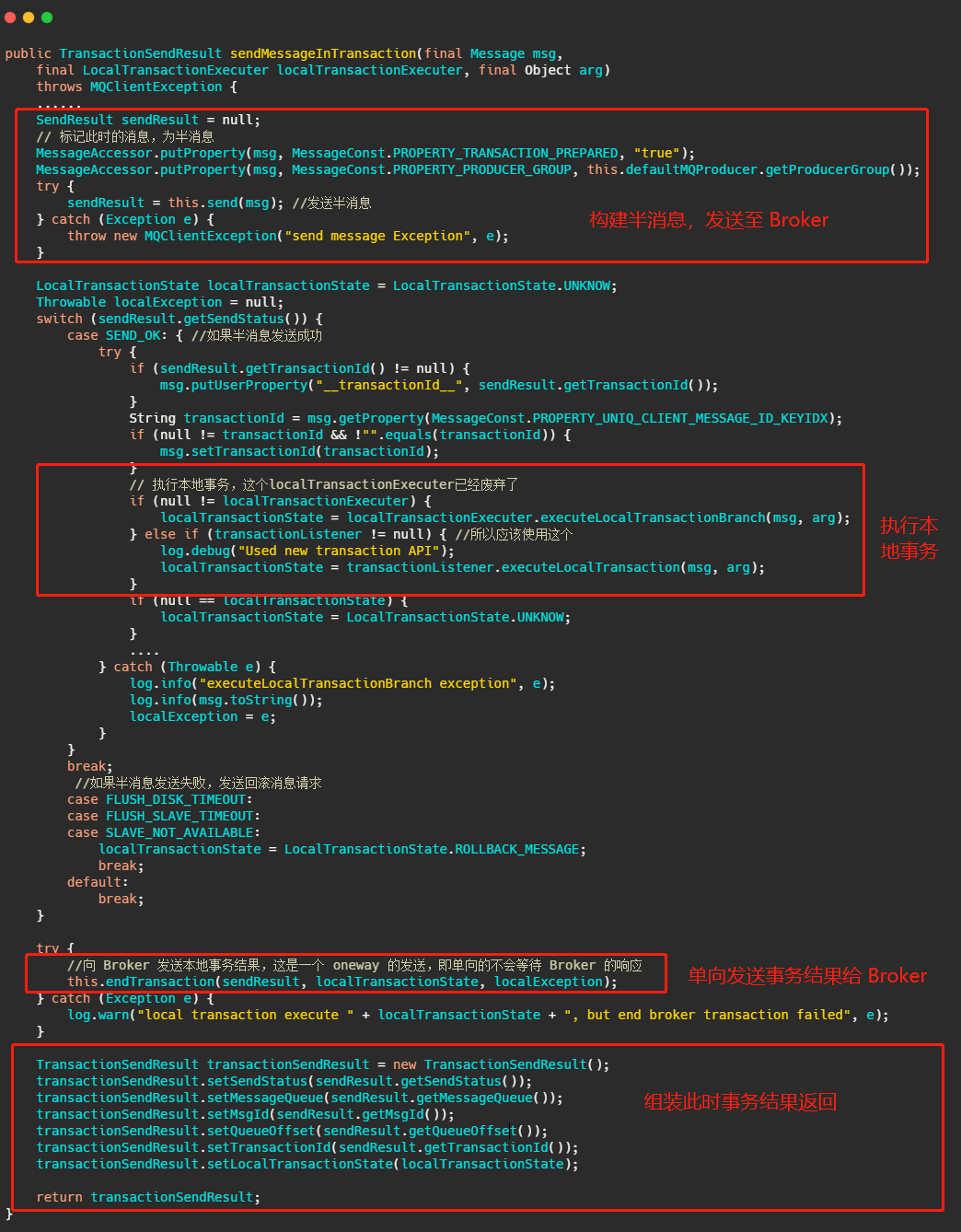
流程也就是我們上面分析的,將訊息塞入一些屬性,標明此時這個訊息還是半訊息,然后發送至 Broker,然后執行本地事務,然后將本地事務的執行狀態發送給 Broker ,我們現在再來看下 Broker 到底是怎么處理這個訊息的,
在 Broker 的 SendMessageProcessor#sendMessage 中會處理這個半訊息請求,因為今天主要分析的是事務訊息,所以其他流程不做分析,我大致的說一下原理,
簡單的說就是 sendMessage 中查到接受來的訊息的屬性里面MessageConst.PROPERTY_TRANSACTION_PREPARED 是 true ,那么可以得知這個訊息是事務訊息,然后再判斷一下這條訊息是否超過最大消費次數,是否要延遲,Broker 是否接受事務訊息等操作后,將這條訊息真正的 topic 和佇列存入屬性中,然后重置訊息的 topic 為RMQ_SYS_TRANS_HALF_TOPIC,并且佇列是 0 的佇列中,使得消費者無法讀取這個訊息,
以上就是整體處理半訊息的流程,我們來看一下原始碼,
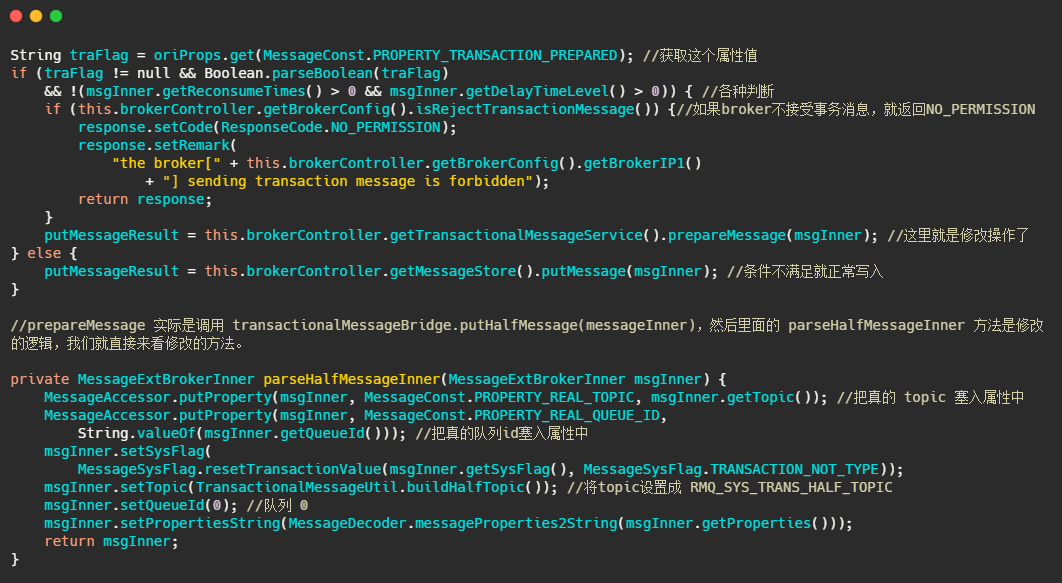
就是來了波貍貓換太子,其實延時訊息也是這么實作的,最終將換了皮的訊息入盤,
Broker 處理提交或者回滾訊息的處理方法是 EndTransactionProcessor#processRequest,我們來看一看它做了什么操作,
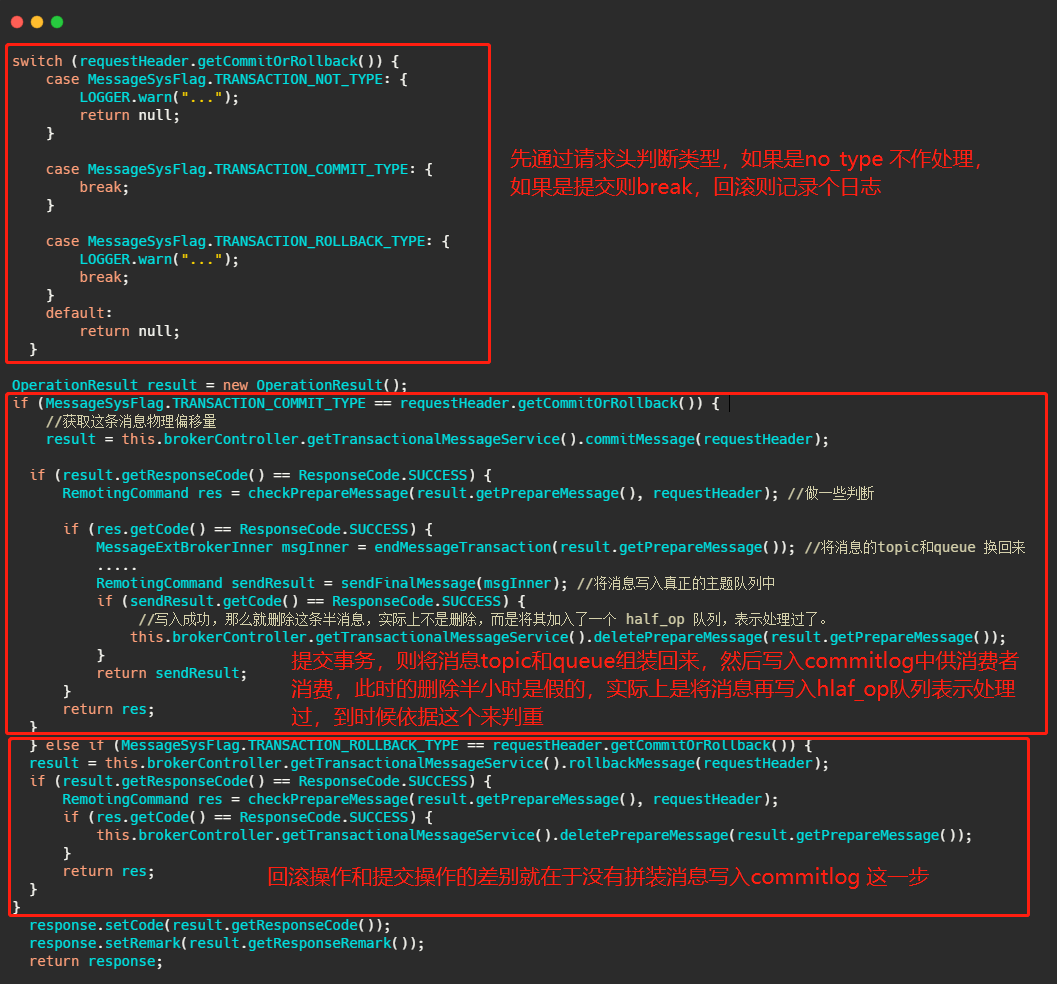
可以看到,如果是提交事務就是把皮再換回來寫入真正的topic所屬的佇列中,供消費者消費,如果是回滾則是將半訊息記錄到一個 half_op 主題下,到時候后臺服務掃描半訊息的時候就依據其來判斷這個訊息已經處理過了,
那個后臺服務就是 TransactionalMessageCheckService 服務,它會定時的掃描半訊息佇列,去請求反查介面看看事務成功了沒,具體執行的就是TransactionalMessageServiceImpl#check 方法,
我大致說一下流程,這一步驟其實涉及到的代碼很多,我就不貼代碼了,有興趣的同學自行了解,不過我相信用語言也是能說清楚的,
首先取半訊息 topic 即RMQ_SYS_TRANS_HALF_TOPIC下的所有佇列,如果還記得上面內容的話,就知道半訊息寫入的佇列是 id 是 0 的這個佇列,然后取出這個佇列對應的 half_op 主題下的佇列,即 RMQ_SYS_TRANS_OP_HALF_TOPIC 主題下的佇列,
這個 half_op 主要是為了記錄這個事務訊息已經被處理過,也就是說已經得知此事務訊息是提交的還是回滾的訊息會被記錄在 half_op 中,
然后呼叫 fillOpRemoveMap 方法,從 half_op 取一批已經處理過的訊息來去重,將那些沒有記錄在 half_op 里面的半訊息呼叫 putBackHalfMsgQueue 又寫入了 commitlog 中,然后發送事務反查請求,這個反查請求也是 oneWay,即不會等待回應,當然此時的半訊息佇列的消費 offset 也會推進,

然后producer中的 ClientRemotingProcessor#processRequest 會處理這個請求,會把任務扔到 TransactionMQProducer 的執行緒池中進行,最侄訓呼叫上面我們發訊息時候定義的 checkLocalTransactionState 方法,然后將事務狀態發送給 Broker,也是用 oneWay 的方式,
看到這里相信大家會有一些疑問,比如為什么要有個 half_op ,為什么半訊息處理了還要再寫入 commitlog 中別急聽我一一道來,
首先 RocketMQ 的設計就是順序追加寫入,所以說不會更改已經入盤的訊息,那事務訊息又需要更新反查的次數,超過一定反查失敗就判定事務回滾,
因此每一次要反查的時候就將以前的半訊息再入盤一次,并且往前推進消費進度,而 half_op 又會記錄每一次反查的結果,不論是提交還是回滾都會記錄,因此下一次還回圈到處理此半訊息的時候,可以從 half_op 得知此事務已經結束了,因此就被過濾掉不需要處理了,
如果得到的反查的結果是 UNKNOW,那 half_op 中也不會記錄此結果,因此還能再次反查,并且更新反查次數,
到現在整個流程已經清晰了,我再畫個圖總結一下 Broker 的事務處理流程,
Kafka 事務訊息
Kafka 的事務訊息和 RocketMQ 的事務訊息又不一樣了,RocketMQ 解決的是本地事務的執行和發訊息這兩個動作滿足事務的約束,
而 Kafka 事務訊息則是用在一次事務中需要發送多個訊息的情況,保證多個訊息之間的事務約束,即多條訊息要么都發送成功,要么都發送失敗,就像下面代碼所演示的,

Kafka 的事務基本上是配合其冪等機制來實作 Exactly Once 語意的,所以說 Kafka 的事務訊息不是我們想的那種事務訊息,RocketMQ 的才是,
講到這我就想扯一下了,說到這個 Exactly Once 其實不太清楚的同學很容易會誤解,
我們知道訊息可靠性有三種,分別是最多一次、恰好一次、最少一次,之前在訊息佇列連環問的文章我已經提到了基本上我們都是用最少一次然后配合消費者端的冪等來實作恰好一次,
訊息恰好被消費一次當然我們所有人追求的,但是之前文章我已經從各方面已經分析過了,基本上難以達到,
而 Kafka 竟說它能實作 Exactly Once?這么牛啤嗎?這其實是 Kafka 的一個噱頭,你要說他錯,他還真沒錯,你要說他對但是他實作的 Exactly Once 不是你心中想的那個 Exactly Once,
它的恰好一次只能存在一種場景,就是從 Kafka 作為訊息源,然后做了一番操作之后,再寫入 Kafka 中,

那他是如何實作恰好一次的?就是通過冪等,和我們在業務上實作的一樣通過一個唯一 Id, 然后記錄下來,如果已經記錄過了就不寫入,這樣來保證恰好一次,
所以說 Kafka 實作的是在特定場景下的恰好一次,不是我們所想的利用 Kafka 來發送訊息,那么這條訊息只會恰巧被消費一次,
這其實和 Redis 說他實作事務了一樣,也不是我們心想的事務,
所以開源軟體說啥啥特性開發出來了,我們一味的相信,因此其往往都是殘血的或者在特殊的場景下才能滿足,不要被誤導了,不能相信表面上的描述,還得詳細的看看檔案或者原始碼,
不過從另一個角度看也無可厚非,作為一個開源軟體肯定是想更多的人用,我也沒說謊呀,我檔案上寫的很清楚的,這標題也沒騙人吧?
確實,比如你點進震驚xxxx標題的文章,人家也沒騙你啥,他自己確實震驚的呢,

再回來談 Kafka 的事務訊息,所以說這個事務訊息不是我們想要的那個事務訊息,其實不是今天的主題了,不過我還是簡單的說一下,
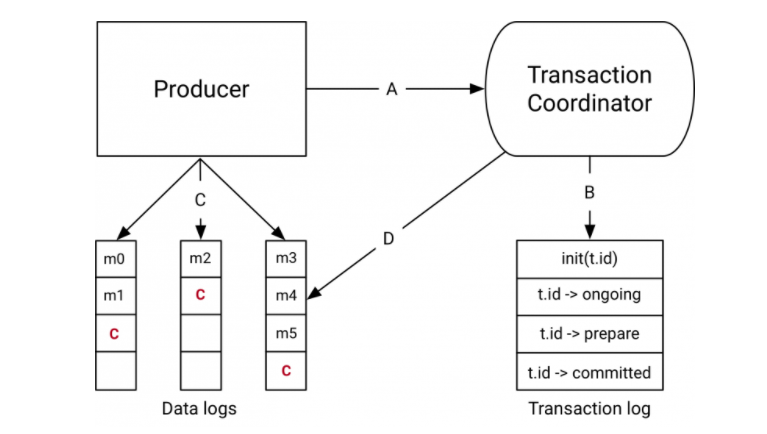
Kafka 的事務有事務協調者角色,事務協調者其實就是 Broker 的一部分,
在開始事務的時候,生產者會向事務協調者發起請求表示事務開啟,事務協調者會將這個訊息記錄到特殊的日志-事務日志中,然后生產者再發送真正想要發送的訊息,這里 Kafka 和 RocketMQ 處理不一樣,Kafka 會像對待正常訊息一樣處理這些事務訊息,由消費端來過濾這個訊息,
然后發送完畢之后生產者會向事務協調者發送提交或者回滾請求,由事務協調者來進行兩階段提交,如果是提交那么會先執行預提交,即把事務的狀態置為預提交然后寫入事務日志,然后再向所有事務有關的磁區寫入一條類似事務結束的訊息,這樣消費端消費到這個訊息的時候就知道事務好了,可以把訊息放出來了,
最后協調者會向事務日志中再記一條事務結束資訊,至此 Kafka 事務就完成了,我拿 confluent.io 上的圖來總結一下這個流程,
最后
至此我們已經知道了 RocketMQ 和 Kakfa 的事務訊息全流程,可以看到 RocketMQ 的事務訊息才是我們想要的,當然你要是用的流式計算那么 Kakfa 的事務訊息也是你想要的,
比 RocketMQ 更好的事務訊息實作是什么?
先拋出的一個問題:一個事務涉及 mysql 和 mq,到底哪個寫入成功重要?
假如線上 mq 集群網路故障,導致發訊息失敗,即使 mysql 還是活著的,但是無法進行事務,
所以其實這個問題問的是:mysql 和 mq 之間的寫入順序,
在 RocketMQ 中,事務訊息的實作方案是先發半訊息(半訊息對消費者不可見),待半訊息發送成功之后,才能執行本地事務,等本地事務執行成功之后,再向 Broker 發送請求將半訊息轉成正常訊息,這樣消費者就可以消費此訊息,
這種順序等于先得成功寫入 mq,然后再寫入資料庫,這樣的模式會出現一個問題:即 mq 集群掛了,事務就無法繼續進行了,等于整個應用無法正常執行了,
看一下我之前畫的 RocketMQ 事務訊息流程圖:
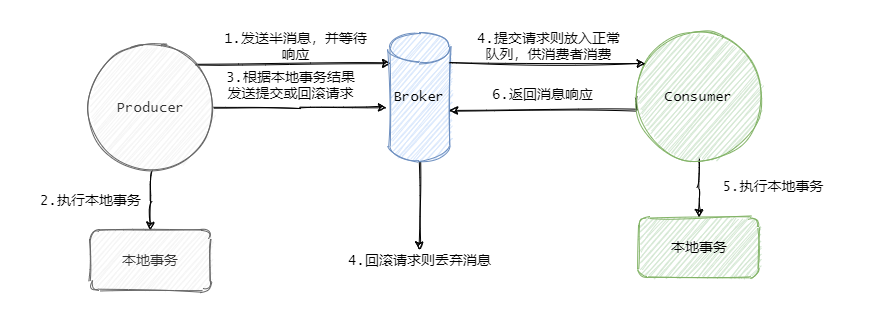
第一步是需要等待半訊息的回應,如果回應失敗就無法執行本地事務,
看下偽代碼,可能更清晰:
result = sendHalfMsg();//發送半訊息
if(result.success) {
執行本地事務
} else {
回滾此次事務
}
所以,先寫 mq 后寫 mysql 就會發生 mysql 還好好的,但是 mq 掛了事務就無法正常執行的情況,
那 qmq 怎么做的呢?
PS: QMQ是去哪兒網內部廣泛使用的訊息中間件,自2012年誕生以來在去哪兒網所有業務場景中廣泛的應用,包括跟交易息息相關的訂單場景; 也包括報價搜索等高吞吐量場景,目前在公司內部日常訊息qps在60W左右,生產上承載將近4W+訊息topic,訊息的端到端延遲可以控制在10ms以內,
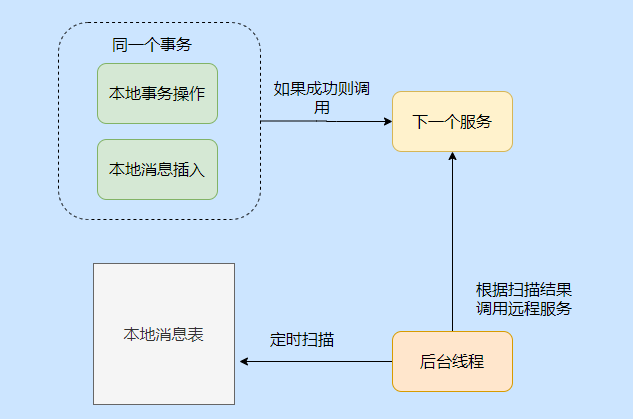
在說 qmq 的事務訊息之前,先來說下本地訊息表這個分布式事務實作方式,
本地訊息就是利用了關系型資料庫的事務能力,會在資料庫中存放一張本地事務訊息表,在進行本地事務操作中加入了本地訊息表的插入,即將業務的執行和將訊息放入到訊息表中的操作放在同一個事務中提交,
這樣本地事務執行成功的話,訊息肯定也插入成功,然后再呼叫其他服務,如果其他服務呼叫成功就修改這條本地訊息的狀態,
如果失敗也不要緊,會有一個后臺執行緒掃描,發現這些狀態的訊息,會一直呼叫相應的服務,一般會設定重試的次數,如果一直不行則特殊記錄,待人工介入處理,
可以看到,本地事務訊息表還是很簡單的,也是一種最大努力通知的思想,
在理解本地訊息表之后,我們再來看一下 qmq 的事務訊息是如何設計的,
首先,想要用 qmq 的事務訊息,需要在資料庫中建一張表,就是如下這樣的表:

是不是有本地訊息表那味兒了?
沒錯核心思想就是本地訊息表!利用關系型資料庫的事務能力,將業務的寫入和訊息表的寫入融在一個事務中,這樣業務成功則訊息表肯定寫入成功,
然后在事務提交之后,立刻發送事務訊息,如果發送成功,則洗掉本地訊息表中的記錄,來看一下偽代碼的實作,應該就很清晰了:
@Transactional // 在一個事務中
public void yes(){
Order order = buildOrder();
orderDao.insert(order);
Message message = buildMessage(order);
messageDao.insert(message);
//異步,在事務提交后執行
triggerAfterTransactionCommit(()->{
messageClient.send(message);
messageDao.delete(message);
});
}
當然,這是我剖開來寫的實作思路,qmq的使用沒這么麻煩,直接在 sendMessage 里把上面的邏輯都包裝好了,所以使用起來直接就是一個發送訊息:
@Transactional // 在一個事務中
public void yes(){
Order order = buildOrder();
orderDao.insert(order);
//封裝插入訊息、發送訊息、洗掉訊息的邏輯
producer.sendMessage(buildMessage(order));
}
如果訊息發送失敗,也就是比如 mq 集群掛了,并不會影響事務的執行,業務的執行和事務訊息的插入都已經成功了,那此時待訊息已經安安靜靜的在訊息庫里等著,后臺能會有一個補償任務,會將這些訊息撈出來重新發送,直到發送成功,
想必,現在你應該對 qmq 的事務訊息流程應該很清晰了,它的順序就屬于先寫資料庫,再發mq,即使 mq 集群掛了,也不會影響事務的進行,不會導致應用無法正常執行了,
這里可能有人會問,那如果 mysql 掛了呢?
我只能說資料庫都掛了,那就都沒了,別想啥別的了,
再來看 RocketMQ 和 QMQ
至此,想必你已經清楚 RocketMQ 和 QMQ 事務訊息的區別,我們再來盤下 QMQ 事務訊息更優的原因,
RocketMQ 只支持單事務訊息,也就是無法在一個事務內發送多種事務訊息,
而 QMQ 可以在一次事務中發多個訊息,來看下偽代碼:
@Transactional // 在一個事務中
public void yes(){
Order order = buildOrder();
orderDao.insert(order);
producer.sendMessage(buildMessageA(order));
producer.sendMessage(buildMessageB(order));
producer.sendMessage(buildMessageC(order));
}
這樣的實作就比 RocketMQ 靈活多了,
然后 RocketMQ 事務訊息的實作還需要提供一個反查機制,因為RocketMQ 事務訊息的提交是 oneway 的發送方式,有可能 Broker 沒有接收到事務提交的訊息,所以 Broker 會定時去生產者那邊查看事務是否已經執行完成,因此生產者需要保存本地事務執行結果,簡單的就是用一個 map 保存,讓 Broker 可以通過訊息的事務 id 查找到事務執行的結果,
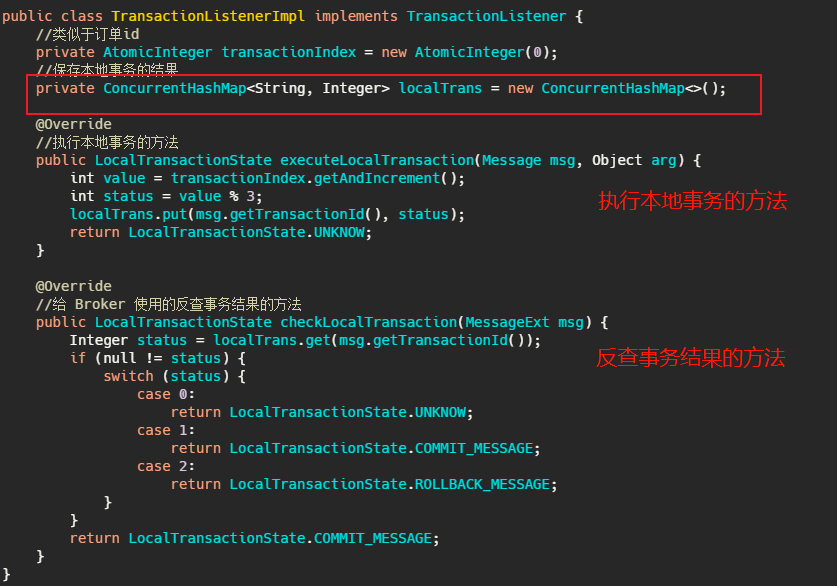
如果還要考慮發送事務訊息的生產者掛了,那么 Broker 會找同個生產組的其他生產者來查詢事務結果,所以這個存盤還得提出來放到第三方,而不是本地記憶體保存,
因此,RocketMQ 得多維護一個本地事務執行結果,是稍微有點麻煩的,
當然,QMQ 還得建表呢,不過按照 QMQ 說的:如果公司方便的話,可以直接合并進DBA的初始化資料庫的自動化流程中,這樣就透明了,
還有一點 RocketMQ 的 api 不太友好,改造有點大,之后的遷移不太方便,
貼一下完整的使用 RocketMQ 事務訊息的代碼:
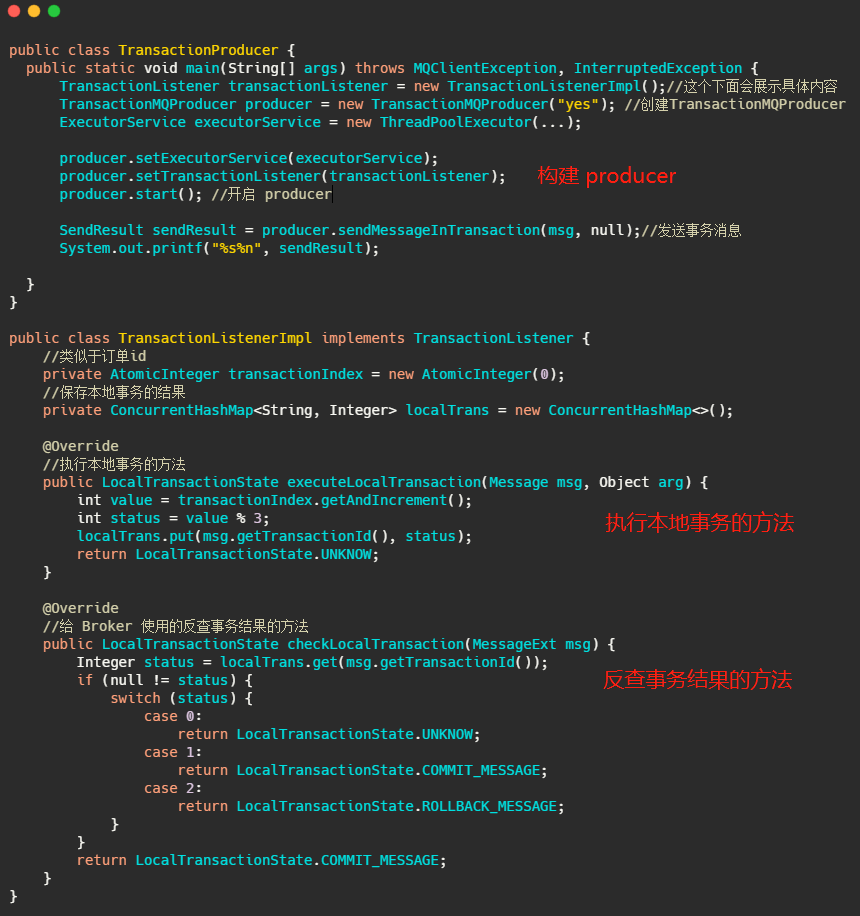
可以看到,如果想要搞事務訊息,首先新建 transationMQproducer,然后再新建一個 transcationListenerImpl,再覆寫 listener 執行事務的方法和回查事務的方法,等于你得把業務邏輯實作在 transcationListenerImpl 內部,這和我們平日里在 service 里面實作事務的差距就有點大了,
而 QMQ 提供了內置 Spring 事務的方式,所以就直接在 service 實作就行了,
@Transactional // 在一個事務中
public void yes(){
Order order = buildOrder();
orderDao.insert(order);
producer.sendMessage(buildMessageA(order));
}
這就很貼合我們平日的使用方式了,這樣對業務的改造很小,并且遷移也很方便,
最后
暫時就分析這么多了,對 QMQ 有興趣的同學可以再自己研究一下,包括 QMQ 的訊息模型多了個 pull log,便于解決 consumer 的動態擴容縮容問題,這也是比 RocketMQ 更靈活的一個地方,
當然,多了個中間層,效率應該會有所降低,這個我還沒試驗過,
還有 QMQ 的 Exactly once 消費等等,有機會之后再寫一篇盤一盤,
Kafka 系列
Kafka的索引設計有什么亮點?
其實這篇文章只是從Kafka索引入手,來講述演算法在工程上基于場景的靈活運用,單單是因為看原始碼的時候有感而寫之,
索引的重要性
索引對于我們來說并不陌生,每一本書籍的目錄就是索引在現實生活中的應用,通過寥寥幾頁紙就得以讓我等快速查找需要的內容,冗余了幾頁紙,縮短了查閱的時間,空間和時間上的互換,包含著宇宙的哲學,
工程領域上資料庫的索引更是不可或缺,沒有索引很難想象如此龐大的資料該如何檢索,
明確了索引的重要性,咱再來看看索引在Kafka里是如何實作的,
索引在Kafka中的實踐
首先Kafka的索引是稀疏索引,這樣可以避免索引檔案占用過多的記憶體,從而可以在記憶體中保存更多的索引,對應的就是Broker 端引數log.index.interval.bytes 值,默認4KB,即4KB的訊息建一條索引,
Kafka中有三大類索引:位移索引、時間戳索引和已中止事務索引,分別對應了.index、.timeindex、.txnindex檔案,
與之相關的原始碼如下:
1、AbstractIndex.scala:抽象類,封裝了所有索引的公共操作
2、OffsetIndex.scala:位移索引,保存了位移值和對應磁盤物理位置的關系
3、TimeIndex.scala:時間戳索引,保存了時間戳和對應位移值的關系
4、TransactionIndex.scala:事務索引,啟用Kafka事務之后才會出現這個索引(本文暫不涉及事務相關內容)
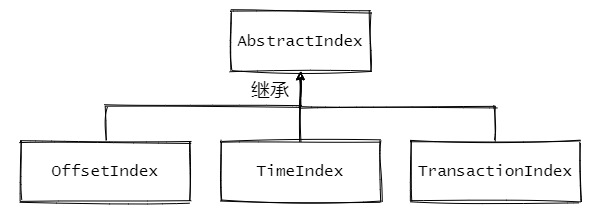
先來看看AbstractIndex的定義

AbstractIndex的定義在代碼里已經注釋了,成員變數里面還有個entrySize,這個變數其實是每個索引項的大小,每個索引項的大小是固定的,
entrySize
在OffsetIndex中是override def entrySize = 8,8個位元組,
在TimeIndex中是override def entrySize = 12,12個位元組,
為何是8 和12?
在OffsetIndex中,每個索引項存盤了位移值和對應的磁盤物理位置,因此4+4=8,但是不對啊,磁盤物理位置是整型沒問題,但是AbstractIndex的定義baseOffset來看,位移值是長整型,不是因為8個位元組么?
因此存盤的位移值實際上是相對位移值,即真實位移值-baseOffset的值,
相對位移用整型存盤夠么?夠,因為一個日志段檔案大小的引數log.segment.bytes是整型,因此同一個日志段對應的index檔案上的位移值-baseOffset的值的差值肯定在整型的范圍內,
為什么要這么麻煩,還要存個差值?
1、為了節省空間,一個索引項節省了4位元組,想想那些日訊息處理數萬億的公司,
2、因為記憶體資源是很寶貴的,索引項越短,記憶體中能存盤的索引項就越多,索引項多了直接命中的概率就高了,這其實和MySQL InnoDB 為何建議主鍵不宜過長一樣,每個輔助索引都會存盤主鍵的值,主鍵越長,每條索引項占用的記憶體就越大,快取頁一次從磁盤獲取的索引數就越少,一次查詢需要訪問磁盤次數就可能變多,而磁盤訪問我們都知道,很慢,
互相轉化的原始碼如下,就這么個簡單的操作:
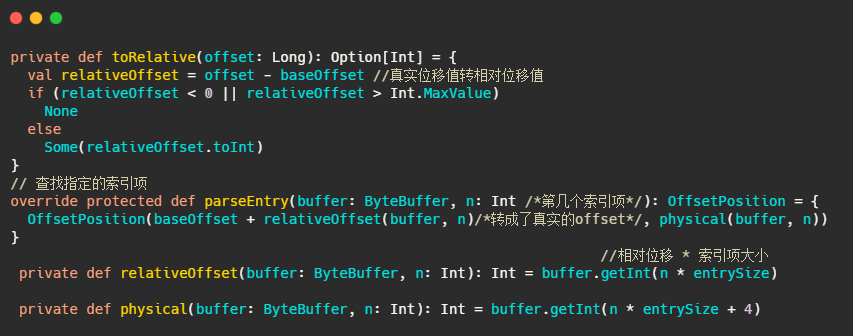
上述解釋了位移值是4位元組,因此TimeIndex中時間戳8個位元組 + 位移值4位元組 = 12位元組,
_warmEntries
這個是干什么用的?
首先思考下我們能通過索引項快速找到日志段中的訊息,但是我們如何快速找到我們想要的索引項呢?一個索引檔案默認10MB,一個索引項8Byte,因此一個檔案可能包含100多W條索引項,
不論是訊息還是索引,其實都是單調遞增,并且都是追加寫入的,因此資料都是有序的,在有序的集合中快速查詢,腦海中突現的就是二分查找了!
那就來個二分!
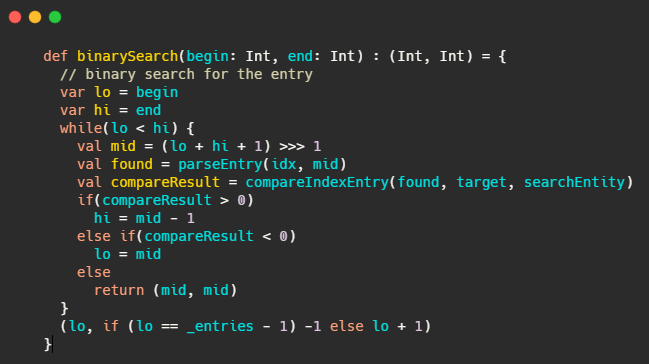
這和_warmEntries有什么關系?首先想想二分有什么問題?
就Kafka而言,索引是在檔案末尾追加的寫入的,并且一般寫入的資料立馬就會被讀取,所以資料的熱點集中在尾部,并且作業系統基本上都是用頁為單位快取和管理記憶體的,記憶體又是有限的,因此會通過類LRU機制淘汰記憶體,
看起來LRU非常適合Kafka的場景,但是使用標準的二分查找會有缺頁中斷的情況,畢竟二分是跳著訪問的,
這里要說一下kafka的注釋寫的是真的清晰,咱們來看看注釋怎么說的
when looking up index, the standard binary search algorithm is not cache friendly, and can cause unnecessary
page faults (the thread is blocked to wait for reading some index entries from hard disk, as those entries are not
cached in the page cache)
翻譯下:當我們查找索引的時候,標準的二分查找對快取不友好,可能會造成不必要的缺頁中斷(執行緒被阻塞等待從磁盤加載沒有被快取到page cache 的資料)
注釋還友好的給出了例子
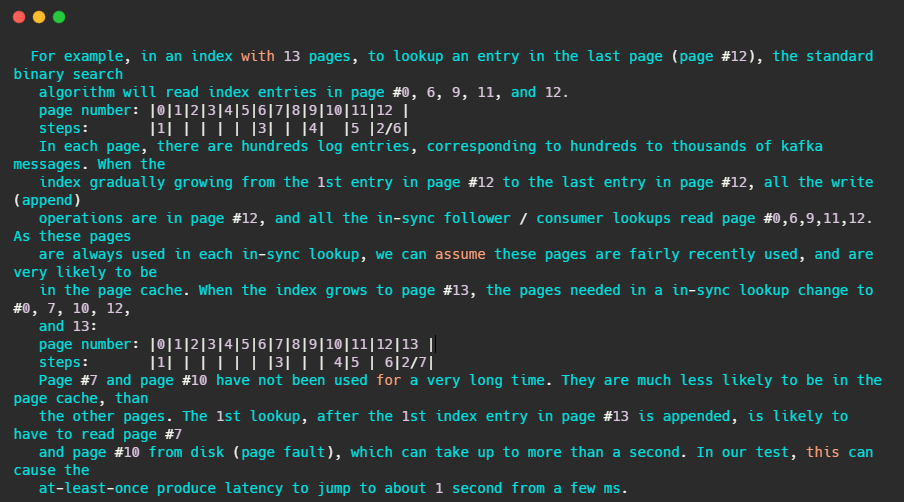
簡單的來講,假設某索引占page cache 13頁,此時資料已經寫到了12頁,按照kafka訪問的特性,此時訪問的資料都在第12頁,因此二分查找的特性,此時快取頁的訪問順序依次是0,6,9,11,12,因為頻繁被訪問,所以這幾頁一定存在page cache中,
當第12頁不斷被填充,滿了之后會申請新頁第13頁保存索引項,而按照二分查找的特性,此時快取頁的訪問順序依次是:0,7,10,12,這7和10很久沒被訪問到了,很可能已經不再快取中了,然后需要從磁盤上讀取資料,注釋說:在他們的測驗中,這會導致至少會產生從幾毫秒跳到1秒的延遲,
基于以上問題,Kafka使用了改進版的二分查找,改的不是二分查找的內部,而且把所有索引項分為熱區和冷區
這個改進可以讓查詢熱資料部分時,遍歷的Page永遠是固定的,這樣能避免缺頁中斷,
看到這里其實我想到了一致性hash,一致性hash相對于普通的hash不就是在node新增的時候快取的訪問固定,或者只需要遷移少部分資料,
好了,讓我們先看看原始碼是如何做的
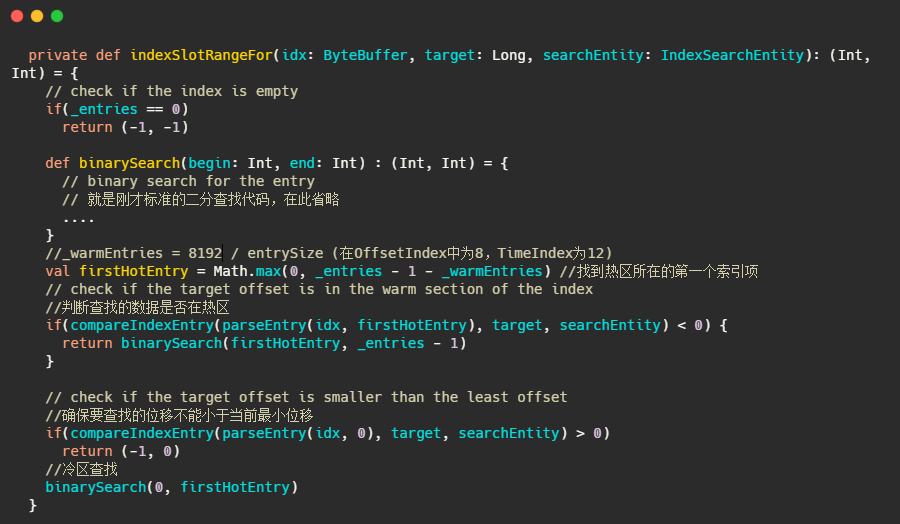
實作并不難,但是為何是把尾部的8192作為熱區?
這里就要再提一下原始碼了,講的很詳細,
- This number is small enough to guarantee all the pages of the “warm” section is touched in every warm-section lookup. So that, the entire warm section is really “warm”.
When doing warm-section lookup, following 3 entries are always touched: indexEntry(end), indexEntry(end-N), and indexEntry((end*2 -N)/2). If page size >= 4096, all the warm-section pages (3 or fewer) are touched, when we
touch those 3 entries. As of 2018, 4096 is the smallest page size for all the processors (x86-32, x86-64, MIPS, SPARC, Power, ARM etc.).
大致內容就是現在處理器一般快取頁大小是4096,那么8192可以保證頁數小于等3,用于二分查找的頁面都能命中
- This number is large enough to guarantee most of the in-sync lookups are in the warm-section. With default Kafka settings, 8KB index corresponds to about 4MB (offset index) or 2.7MB (time index) log messages.
8KB的索引可以覆寫 4MB (offset index) or 2.7MB (time index)的訊息資料,足夠讓大部分在in-sync內的節點在熱區查詢
以上就解釋了什么是_warmEntries,并且為什么需要_warmEntries,
可以看到樸素的演算法在真正工程上的應用還是需要看具體的業務場景的,不可生搬硬套,并且徹底的理解演算法也是很重要的,例如死記硬背二分,怕是看不出來以上的問題,還有底層知識的重要性,不然也是看不出來對快取不友好的,
從Kafka的索引冷熱磁區到MySQL InnoDB的緩沖池管理
從上面這波冷熱磁區我又想到了MySQL的buffer pool管理,MySQL的將緩沖池分為了新生代和老年代,默認是37分,即老年代占3,新生代占7,即看作一個鏈表的尾部30%為老年代,前面的70%為新生代,替換了標準的LRU淘汰機制,

MySQL的緩沖池磁區是為了解決預讀失效和快取污染問題,
1、預讀失效:因為會預讀頁,假設預讀的頁不會用到,那么就白白預讀了,因此讓預讀的頁插入的是老年代頭部,淘汰也是從老年代尾部淘汰,不會影響新生代資料,
2、快取污染:在類似like全表掃描的時候,會讀取很多冷資料,并且有些查詢頻率其實很少,因此讓這些資料僅僅存在老年代,然后快速淘汰才是正確的選擇,MySQL為了解決這種問題,僅僅分代是不夠的,還設定了一個時間視窗,默認是1s,即在老年代被再次訪問并且存在超過1s,才會晉升到新生代,這樣就不會污染新生代的熱資料,
小結
文章先從索引入手,這就是時間和空間的互換,然后引出Kafka中索引存盤使用了相對位移值,節省了空間,并且講述了索引項的訪問是由二分查找實作的,并結合Kafka的使用場景解釋了Kafka中使用的冷熱磁區實作改進版的二分查找,并順帶提到了下一致性Hash,再由冷熱磁區聯想到了MySQL緩沖池變形的LRU管理,
這一步步實際上都體現演算法在工程中的靈活運用和變形實作,有些同學認為演算法沒用,刷演算法題只是為了面試,實際上各種中間件和一些底層實作都體現了演算法的重要性,
不說了,頭有點冷,
Kafka日志段如何讀寫決議?
Kafka的存盤結構
眾所周知,Kafka的Topic可以有多個磁區,磁區其實就是最小的讀取和存盤結構,即Consumer看似訂閱的是Topic,實則是從Topic下的某個磁區獲得訊息,Producer也是發送訊息也是如此,
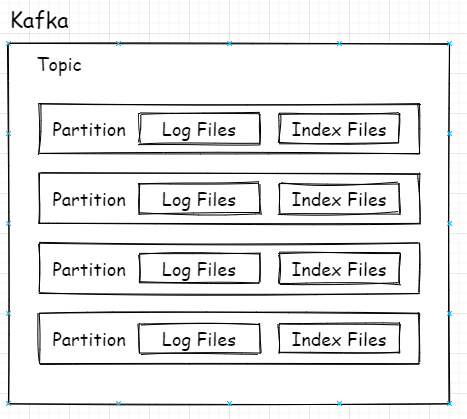
上圖是總體邏輯上的關系,映射到實際代碼中在磁盤上的關系則是如下圖所示:
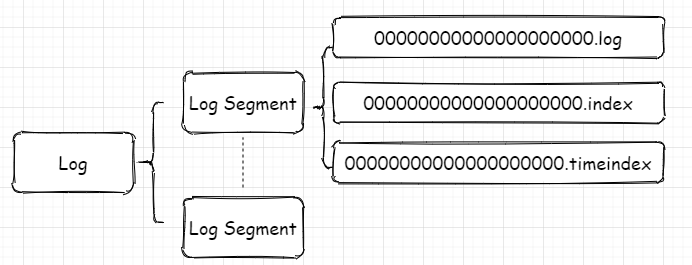
每個磁區對應一個Log物件,在磁盤中就是一個子目錄,子目錄下面會有多組日志段即多Log Segment,每組日志段包含:訊息日志檔案(以log結尾)、位移索引檔案(以index結尾)、時間戳索引檔案(以timeindex結尾),其實還有其它后綴的檔案,例如.txnindex、.deleted等等,篇幅有限,暫不提起,
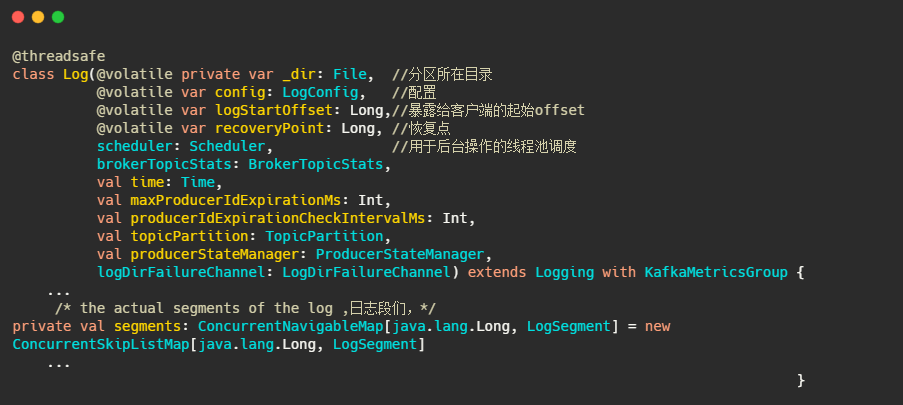
以下為日志的定義
以下為日志段的定義
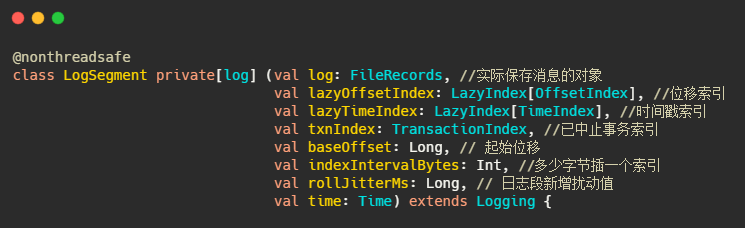
indexIntervalBytes可以理解為插了多少訊息之后再建一個索引,由此可以看出Kafka的索引其實是稀疏索引,這樣可以避免索引檔案占用過多的記憶體,從而可以在記憶體中保存更多的索引,對應的就是Broker 端引數log.index.interval.bytes 值,默認4KB,
實際的通過索引查找訊息程序是先通過offset找到索引所在的檔案,然后通過二分法找到離目標最近的索引,再順序遍歷訊息檔案找到目標檔案,這波操作時間復雜度為O(log2n)+O(m),n是索引檔案里索引的個數,m為稀疏程度,
這就是空間和時間的互換,又經過資料結構與演算法的平衡,妙啊!
再說下rollJitterMs,這其實是個擾動值,對應的引數是log.roll.jitter.ms,這其實就要說到日志段的切分了,log.segment.bytes,這個引數控制著日志段檔案的大小,默認是1G,即當檔案存盤超過1G之后就新起一個檔案寫入,這是以大小為維度的,還有一個引數是log.segment.ms,以時間為維度切分,
那配置了這個引數之后如果有很多很多磁區,然后因為這個引數是全域的,因此同一時刻需要做很多檔案的切分,這磁盤IO就頂不住了啊,因此需要設定個rollJitterMs,來岔開它們,
怎么樣有沒有聯想到redis快取的過期時間?過期時間加個亂數,防止同一時刻大量快取過期導致快取擊穿資料庫, 看看知識都是通的啊!
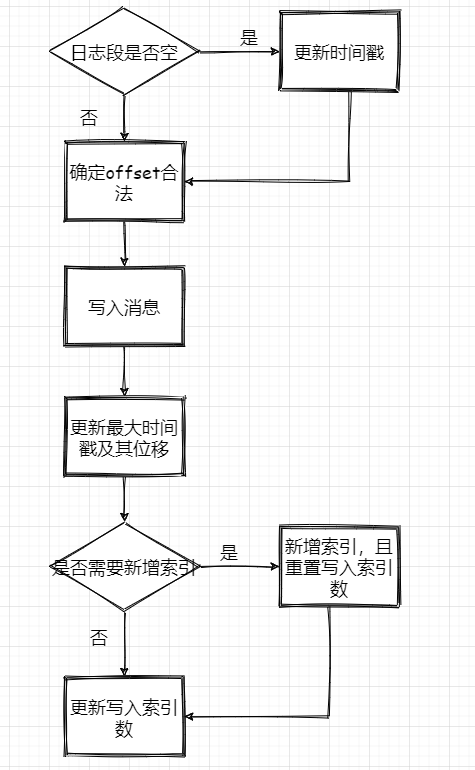
日志段的寫入
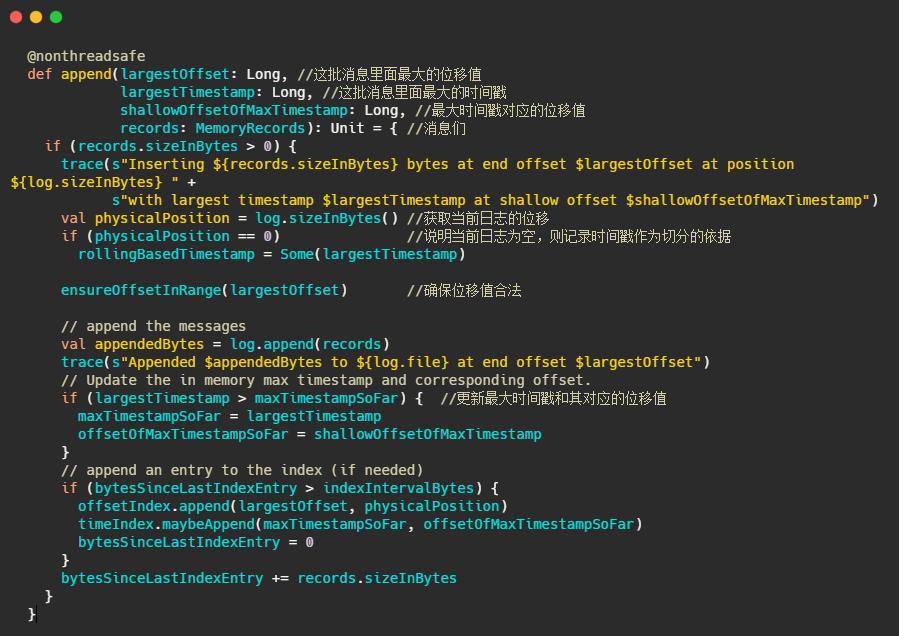
1、判斷下當前日志段是否為空,空的話記錄下時間,來作為之后日志段的切分依據
2、確保位移值合法,最終呼叫的是AbstractIndex.toRelative(..)方法,即使判斷offset是否小于0,是否大于int最大值,
3、append訊息,實際上就是通過FileChannel將訊息寫入,當然只是寫入記憶體中及頁快取,是否刷盤看配置,
4、更新日志段最大時間戳和最大時間戳對應的位移值,這個時間戳其實用來作為定期洗掉日志的依據
5、更新索引項,如果需要的話(bytesSinceLastIndexEntry > indexIntervalBytes)
最后再來個流程圖
日志段的讀取
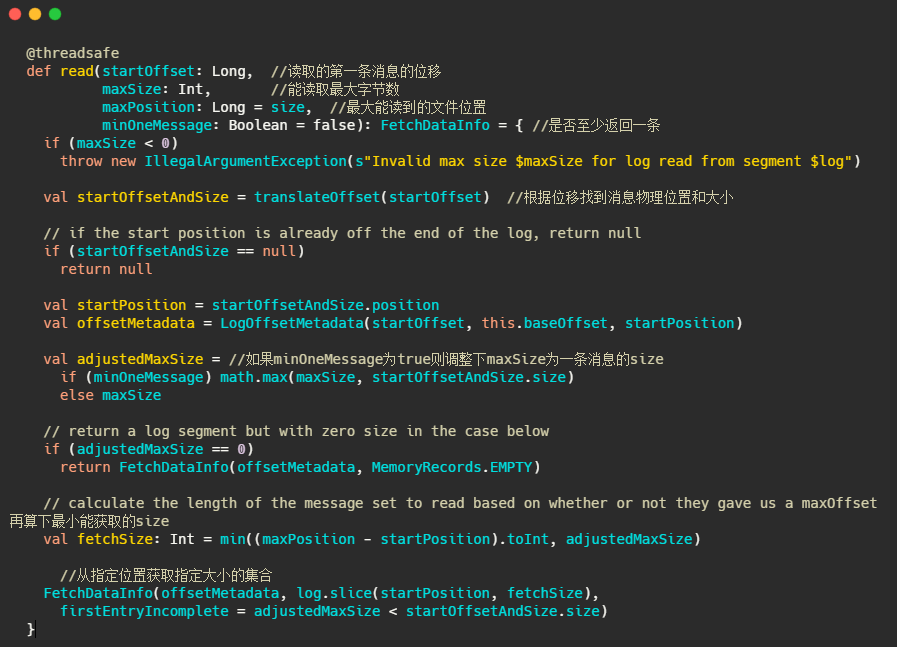
1、根據第一條訊息的offset,通過OffsetIndex找到對應的訊息所在的物理位置和大小,
2、獲取LogOffsetMetadata,元資料包含訊息的offset、訊息所在segment的起始offset和物理位置
3、判斷minOneMessage是否為true,若是則調整為必定回傳一條訊息大小,其實就是在單條訊息大于maxSize的情況下得以回傳,防止消費者餓死
4、再計算最大的fetchSize,即(最大物理位移-此訊息起始物理位移)和adjustedMaxSize的最小值(這波我不是很懂,因為以上一波操作adjustedMaxSize已經最小為一條訊息的大小了)
5、呼叫 FileRecords 的 slice 方法從指定位置讀取指定大小的訊息集合,并且構造FetchDataInfo回傳
再來個流程圖:
情景劇
老白正目不轉睛盯著監控大屏,“為什么?為什么Kafka Broker物理磁盤 I/O 負載突然這么高?”,寥寥無幾的秀發矗立在老白的頭上,顯得如此的無助,
“是不是設定了 log.segment.ms引數 ? 試試 log.roll.jitter.ms吧”,老白抬頭間我已走出了辦公室,留下了一個偉岸的背影和一顆锃亮的光頭!
“我變禿了,也變強了”
Kafka控制器事件處理全流程決議
前言
這篇文章我分為兩部分,第一部分就是直接圖文來說清整個 Kafka 控制器事件處理全流程,然后再通過Controller選舉流程進行一波原始碼分析,再來走一遍處理全流程,
正文
在深入原始碼之前我們得先搞明白 Controller是什么?它有什么用?這樣在看原始碼的時候才能有的放矢,
Controller是核心組件,它的作用是管理和協調整個Kafka集群,
具體管理和協調什么呢?
- 主題的管理,創建和洗掉主題;
- 磁區管理,增加或重分配磁區;
- 磁區
Leader選舉; - 監聽
Broker相關變化,即Broker新增、關閉等; - 元資料管理,向其他
Broker提供元資料服務;
為什么需要Controller??
我個人理解:凡是管理或者協調某樣東西,都需要有個Leader,由他來把控全域,管理內部,對接外部,咱們就跟著Leader干就完事了,這其實對外也是好的,外部不需要和我們整體溝通,他只要和一個決策者交流,效率更高,
再來看看朱大是怎么說的,以下內容來自《深入理解Kafka:核心設計與實踐原理》,
在Kafka的早期版本中,并沒有采用 Kafka Controller 這樣一概念來對磁區和副本的狀態進行管理,而是依賴于 ZooKeeper,每個 broker都會在 ZooKeeper 上為磁區和副本注冊大量的監聽器(Watcher),
當磁區或副本狀態變化時,會喚醒很多不必要的監聽器,這種嚴重依賴 ZooKeeper 的設計會有腦裂、羊群效應,以及造成 ZooKeeper 過載的隱患,在目前的新版本的設計中,只有 Kafka Controller 在 ZooKeeper 上注冊相應的監聽器,其他的 broker 極少需要再監聽 ZooKeeper 中的資料變化,這樣省去了很多不必要的麻煩,
簡單說下ZooKeeper
了解了 Controller的作用之后我們還需要在簡單的了解下ZooKeeper,因為Controller是極度依賴ZooKeeper的,(不過社區準備移除ZooKeeper,文末再提一下)
ZooKeeper是一個開源的分布式協調服務框架,最常用來作為注冊中心等,ZooKeeper的資料模型就像檔案系統一樣,以根目錄 “/” 開始,結構上的每個節點稱為znode,可以存盤一些資訊,節點分為持久節點和臨時節點,臨時節點會隨著會話結束而自動被洗掉,
并且有Watcher功能,節點自身資料變更、節點新增、節點洗掉、子節點數量變更都可以通過變更監聽器通知客戶端,
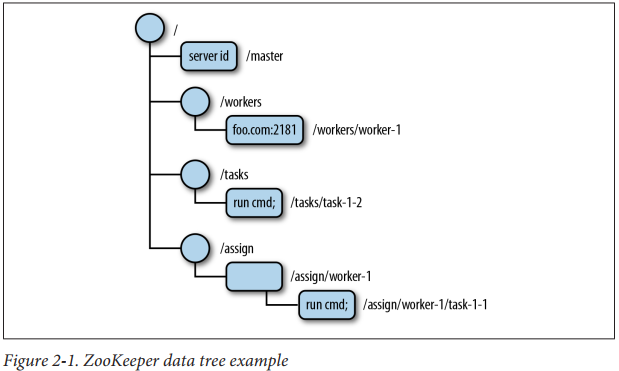
Controller是如何依賴ZooKeeper的
每個Broker在啟動時會嘗試向ZooKeeper注冊/controller節點來競選控制器,第一個創建/controller節點的Broker會被指定為控制器,這就是是控制器的選舉,
/controller節點是個臨時節點,其他Broker會監聽著此節點,當/controller節點所在的Broker宕機之后,會話就結束了,此節點就被移除,其他Broker伺機而動,都來爭當控制器,還是第一個創建/controller節點的Broker被指定為控制器,這就是控制器故障轉移,即Failover,
當然還包括各種節點的監聽,例如主題的增減等,都通過Watcher功能,來實作相關的監聽,進行對應的處理,
Controller在初始化的時候會從ZooKeeper拉取集群元資料資訊,保存在自己的快取中,然后通過向集群其他Broker發送請求的方式將資料同步給對方,
Controller 底層事件模型
不管是監聽Watcher的ZooKeeperWatcher執行緒,還是定時任務執行緒亦或是其他執行緒都需要訪問或更新Controller從集群拉取的元資料,多執行緒 + 資料競爭 = 執行緒不安全,因此需要加鎖來保證執行緒安全,
一開始Kafka就是用大量的鎖來保證執行緒間的同步,各種加鎖使得性能下降,并且多執行緒加鎖的方式使得代碼復雜度急劇上升,一不小心就會出各種問題,bug難修復,
因此在0.11版本之后將多執行緒并發訪問改成了單執行緒事件佇列模式,將涉及到共享資料競爭相關方面的訪問抽象成事件,將事件塞入阻塞佇列中,然后單執行緒處理,
也就是說其它執行緒還是在的,只是把涉及共享資料的操作封裝成事件由專屬執行緒處理,
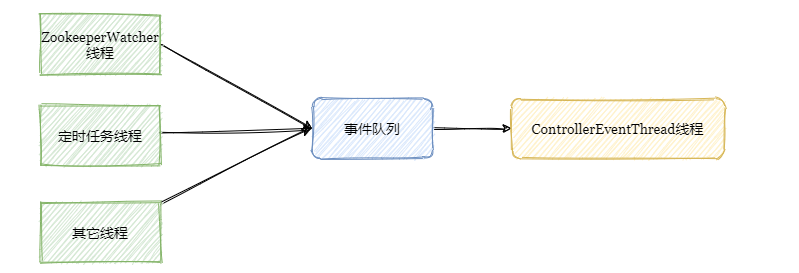
先小結一下
到這我們已經清楚了Controller主要用來管理和協調集群,具體是通過ZooKeeper臨時節點和Watcher機制來監控集群的變化(當然還有來自定時任務或其他執行緒的事件驅動),更新集群的元資料,并且通知集群中的其他Broker進行相關的操作(這部分下文會講),
而由于集群元資料會有并發修改問題,因此將操作抽象成事件,由阻塞佇列和單執行緒處理來替換之前的多執行緒處理,降低代碼的復雜度,提升代碼的可維護性和性能,
接下來我們再講講Controller通知集群中的其他Broker的相關操作,
Controller的請求發送
Controller從ZooKeeper那兒得到變更通知之后,需要告知集群中的Broker(包括它自身)做相應的處理,
Controller只會給集群的Broker發送三種請求:分別是 LeaderAndIsrRequest、StopReplicaRequest和 UpdateMetadataRequest
LeaderAndIsrRequest
告知Broker主題相關磁區Leader和ISR副本都在哪些 Broker上,
StopReplicaRequest
告知Broker停止相關副本操作,用于洗掉主題場景或磁區副本遷移場景,
UpdateMetadataRequest
更新Broker上的元資料,
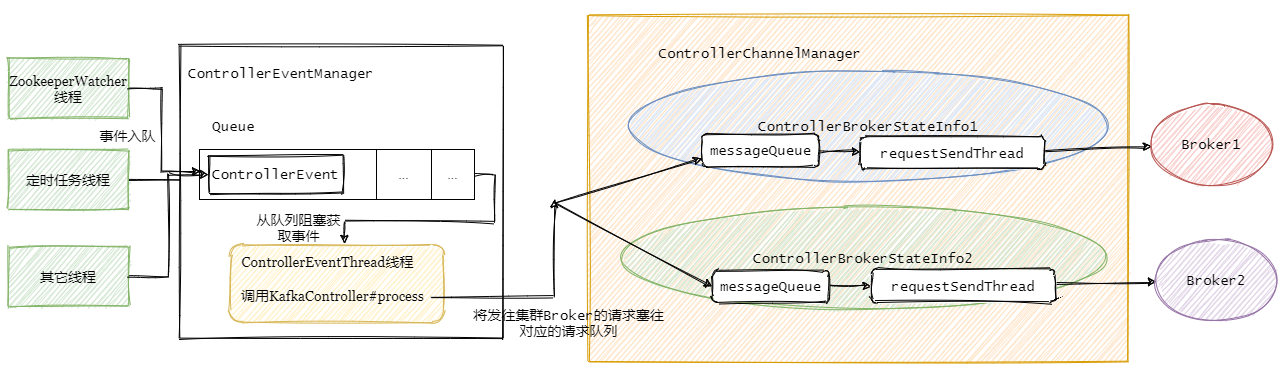
Controller事件處理執行緒會把事件封裝成對應的請求,然后將請求寫入對應的Broker的請求阻塞佇列,然后RequestSendThread不斷從阻塞佇列中獲取待發送的請求,

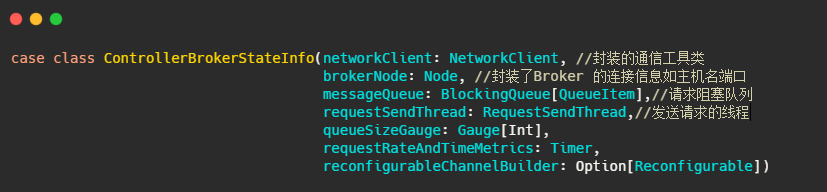
先解釋下controllerBrokerStateInfo,它就是個 POJO類,可以理解為集群每個broker對應一個controllerBrokerStateInfo.
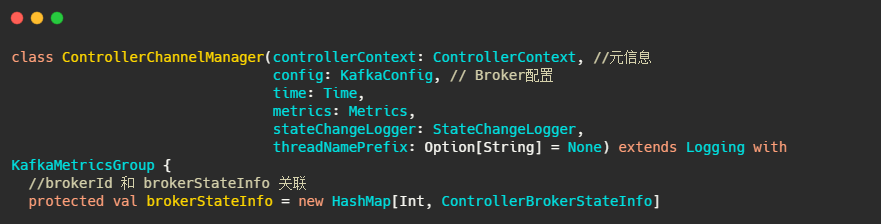
然后再看下ControllerChannelManager,從名字可以看出它管理Controller和集群Broker之間的連接,并為每個Broker創建一個RequestSendThread執行緒,
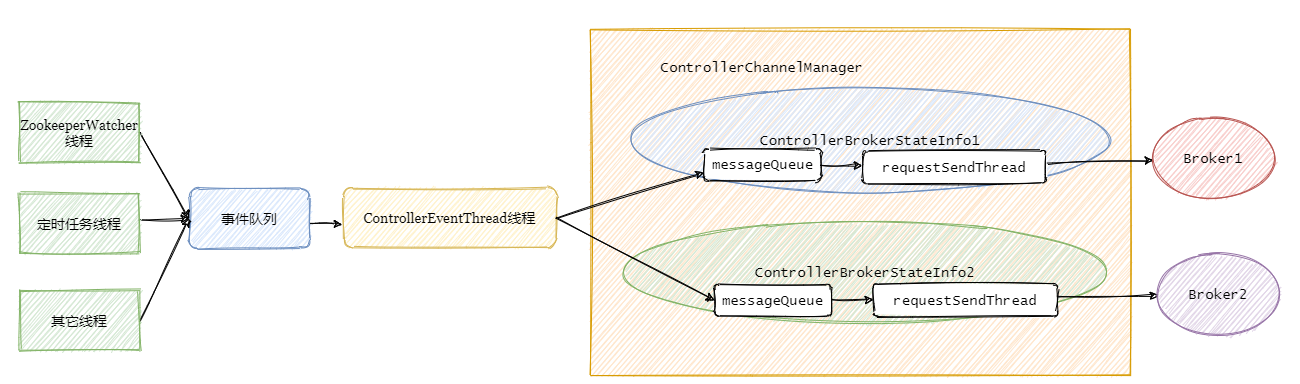
再小結一下
接著上個小結,事件處理執行緒將事件佇列里面的事件處理之后再進行對應的請求封裝,塞入需要通知的集群Broker對應的阻塞佇列中,然后由每個Broker專屬的requestSendThread發送請求至對應的Broker,
總的步驟如下圖:
現在應該已經清楚Controller大概是如何運作的,整體看起來還是生產者-消費者模型,
接下來就進入原始碼環節,
Controller選舉流程原始碼分析
事件處理的流程都是一樣的,只是具體處理的事件邏輯不同,我們從Controller選舉入手,來走一遍處理流程,
ControllerChangeHandler
選舉會觸發此handler,可以看到直接往ControllerEventManager的事件佇列里塞,
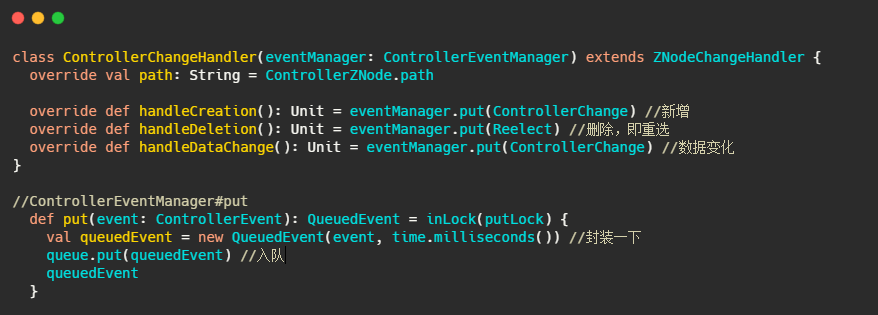
這個QueueEvent和ControllerEventManager,我們先來看看是啥,不過在此之前先了解下ControllerEvent和ControllerEventProcessor,
ControllerEvent:事件

ControllerEventProcessor : 事件處理介面
此介面的唯一實作類是 KafkaController,
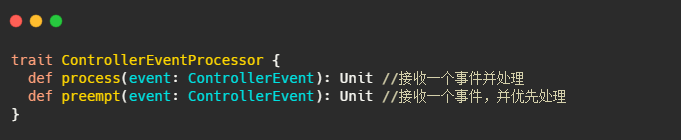
ControllerEventManager:事件處理器
此類主要用來管理事件處理執行緒和事件佇列,
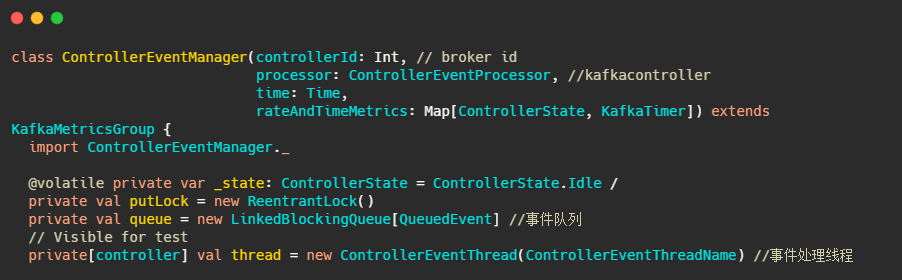
QueuedEvent:封裝了ControllerEvent的類
主要是記錄了下入隊時間,并且提供了事件需要呼叫的方法,
ControllerEventThread:事件處理執行緒
整體而言還是很簡單的,從佇列拿事件,然后處理,
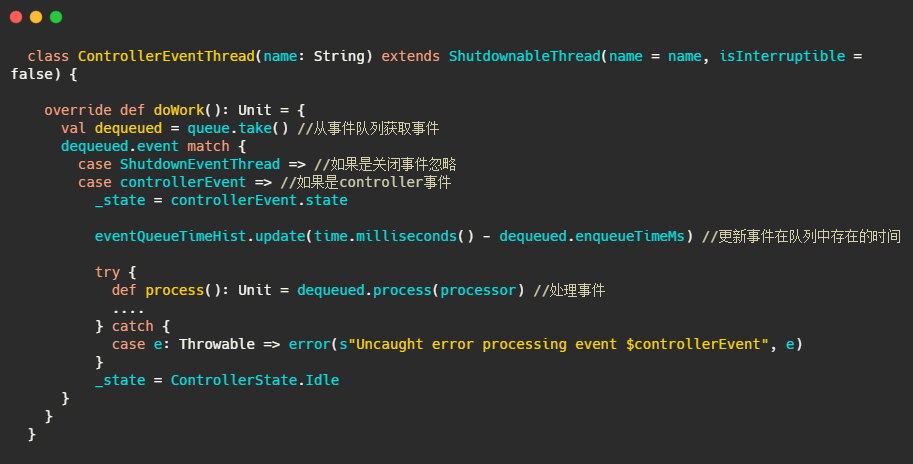
KafkaController#process
就是個switch,根據事件呼叫對應的processXXXX方法,
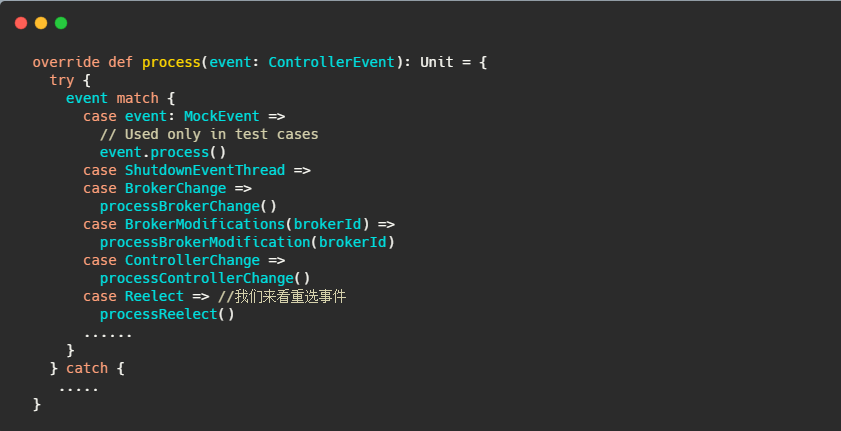
來關注下controller 重選事件
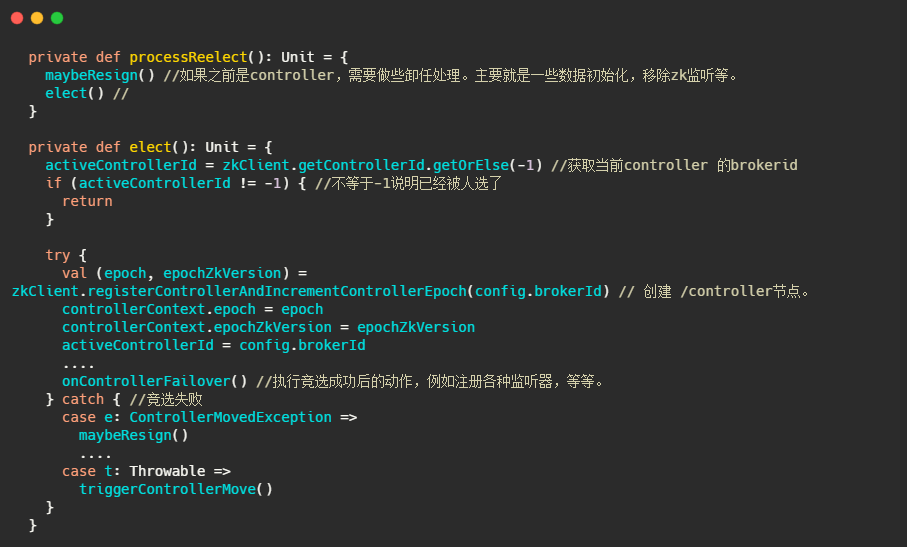
然后在onControllerFailover里面會呼叫sendUpdateMetadataRequest方法
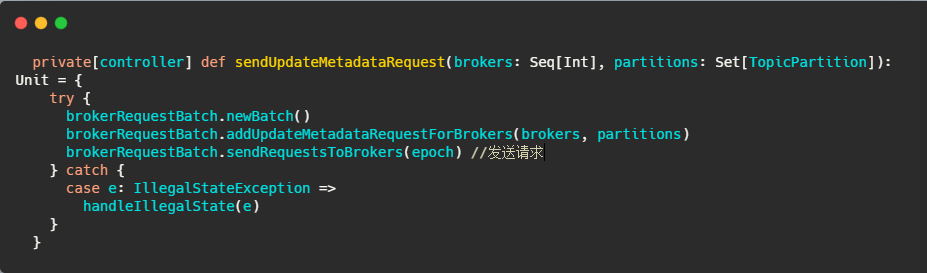
中間省略呼叫,內容太多了,不是重點,到后來呼叫ControllerBrokerRequestBatch#sendRequest
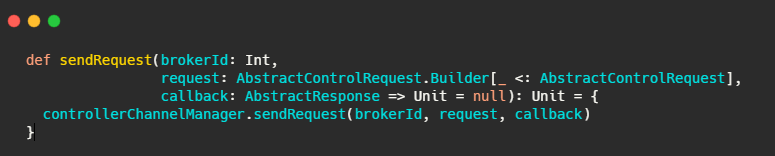
最后還是呼叫了controllerChannelManager#sendRequest.

然后 RequestSendThread#doWork,不斷從請求佇列里拿請求,發送請求,
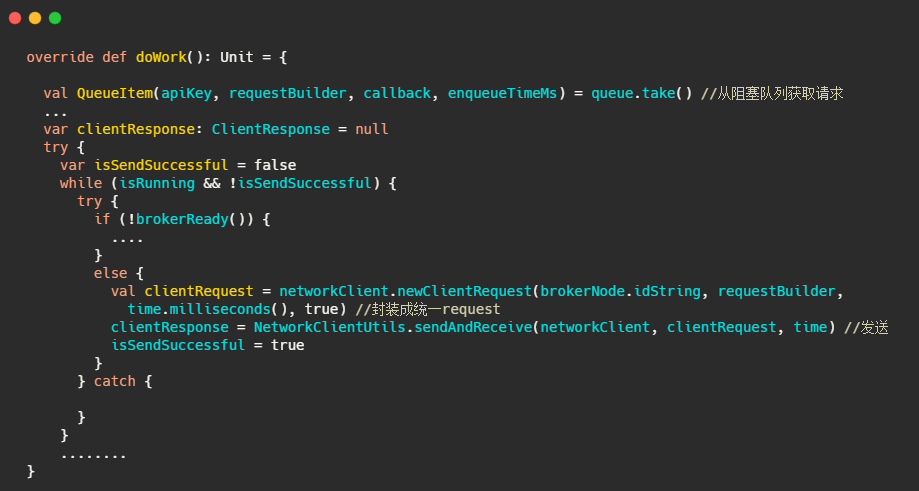
一個環節完成了!我們來看下整體流程圖
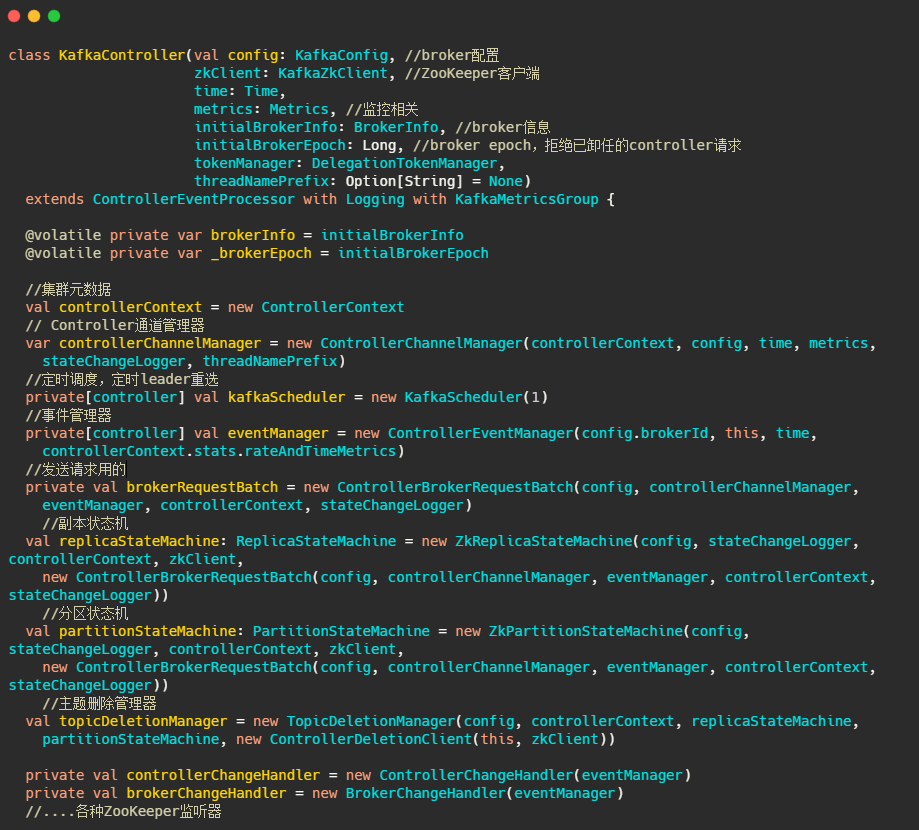
最后我們來看下元資料到底有啥和KafkaController的一些欄位,
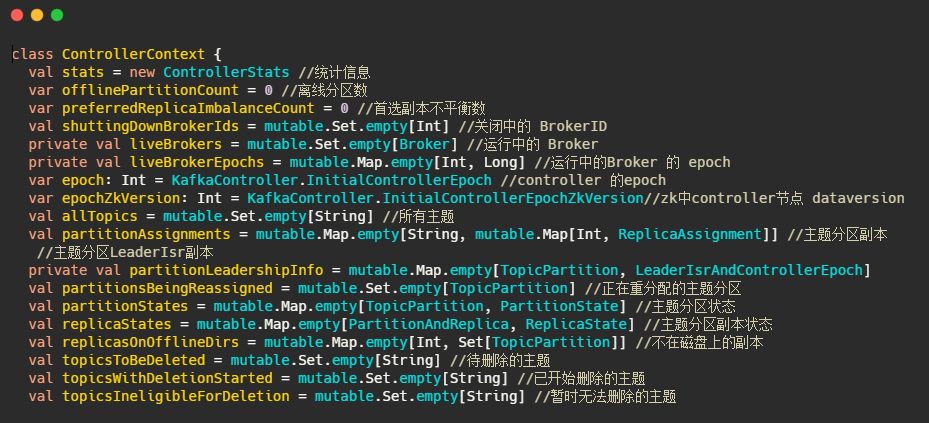
ControllerContext:元資料
主要有運行中的Broker、所有主題資訊、主題磁區副本資訊等,
KafkaController
基本上關鍵的欄位都解釋了,關于狀態機那一塊篇幅有限,之后再說,
最后
整體的流程就是將Controller相關操作都封裝成一個個事件,然后將事件入隊,由一個事件處理執行緒來處理,保證資料的安全(從這也可以看出,不是多執行緒就是好,有利有弊最侄訓是看場景),
最后在通知集群中Broker的程序是每個Broker配備一個發送執行緒,因為發送是同步的,因此每個Broker執行緒隔離可以防止某個Broker阻塞而導致整體都阻塞的情況,
前面有說到Kafka Controller 強依賴 ZooKeeper,但是現在社區打算移除 ZooKeeper,因為ZooKeeper不適合頻繁寫,并且是CP的,而且用Kafka還需要維護ZooKeeper集群,提升了系統的復雜度和運維難度,降低了系統的穩定性,
像位移資訊,已經通過內部主題的方式保存,繞開了ZooKeeper,
社區打算通過類 Raft 共識演算法來選舉Controller,并且把元資料存盤在 Log 中的方式來做,
Kafka請求處理全流程決議
今天來講講 Kafka Broker端處理請求的全流程,剖析下底層的網路通信是如何實作的、Reactor在kafka上的應用,
再說說社區為何在2.3版本將請求型別劃分成兩大類,又是如何實作兩類請求處理的優先級,
在原始碼分析之前我先總結性的說了說Kafka底層的通信模型,應對面試官詢問Kafka請求全程序已經夠了,
Reactor模式
在扯到Kafka之前我們先來說說Reactor模式,基本上只要是底層的高性能網路通信就離不開Reactor模式,像Netty、Redis都是使用Reactor模式,
像我們以前剛學網路編程的時候以下代碼可是非常的熟悉,新來一個請求,要么在當前執行緒直接處理了,要么新起一個執行緒處理,

在早期這樣的編程是沒問題的,但是隨著互聯網的快速發展,單執行緒處理不過來,也不能充分的利用計算機資源,
而每個請求都新起一個執行緒去處理,資源的要求就太高了,并且創建執行緒也是一個重操作,
說到這有人想到了,那搞個執行緒池不就完事了嘛,還要啥Reactor,
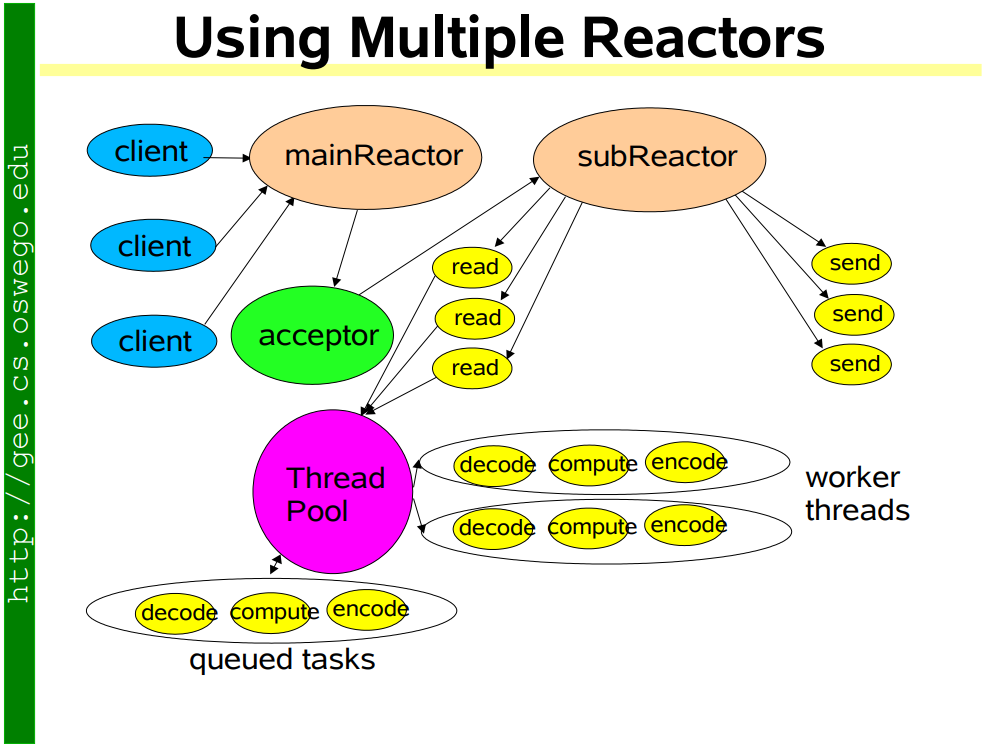
池化技術確實能緩解資源的問題,但是池子是有限的,池子里的一個執行緒不還是得候著某個連接,等待指示嘛,現在的互聯網時代早已突破C10K了,
因此引入的IO多路復用,由一個執行緒來監視一堆連接,同步等待一個或多個IO事件的到來,然后將事件分發給對應的Handler處理,這就叫Reactor模式,
網路通信模型的發展如下
單執行緒 => 多執行緒 => 執行緒池 => Reactor模型
Kafka所采用的Reactor模型如下
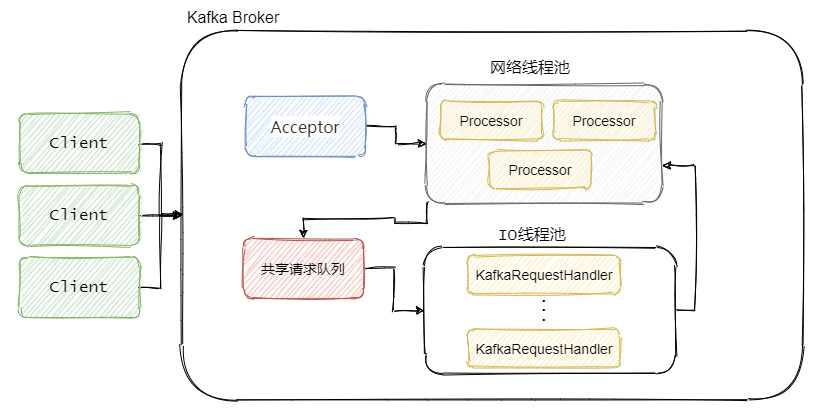
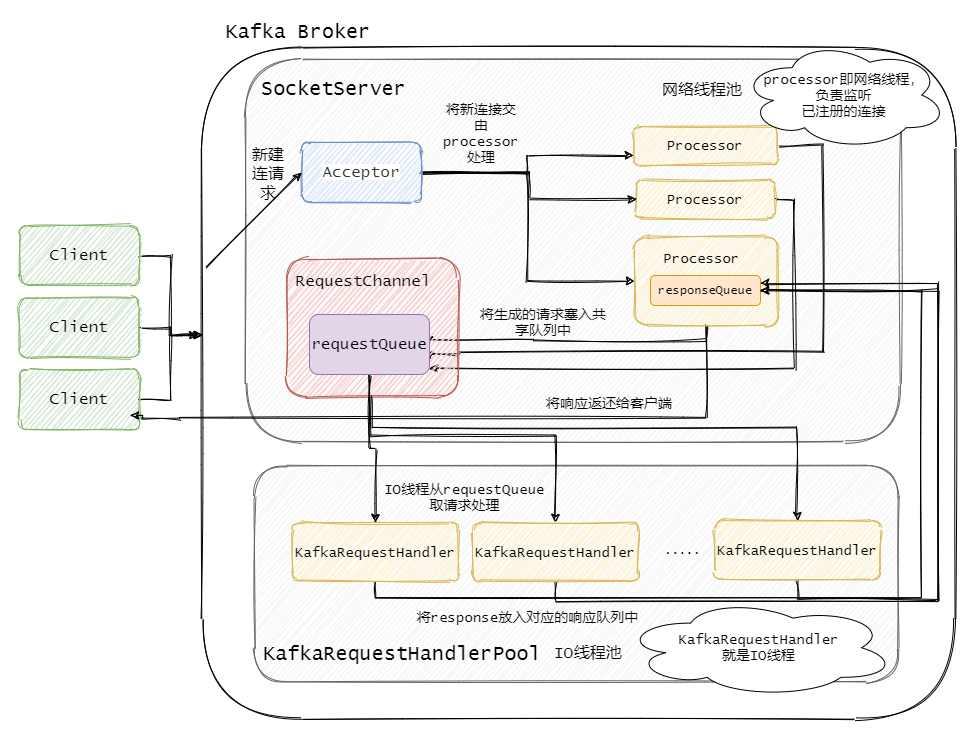
Kafka Broker 網路通信模型
簡單來說就是,Broker 中有個Acceptor(mainReactor)監聽新連接的到來,與新連接建連之后輪詢選擇一個Processor(subReactor)管理這個連接,
而Processor會監聽其管理的連接,當事件到達之后,讀取封裝成Request,并將Request放入共享請求佇列中,
然后IO執行緒池不斷的從該佇列中取出請求,執行真正的處理,處理完之后將回應發送到對應的Processor的回應佇列中,然后由Processor將Response返還給客戶端,
每個listener只有一個Acceptor執行緒,因為它只是作為新連接建連再分發,沒有過多的邏輯,很輕量,一個足矣,
Processor 在Kafka中稱之為網路執行緒,默認網路執行緒池有3個執行緒,對應的引數是num.network.threads,并且可以根據實際的業務動態增減,
還有個 IO 執行緒池,即KafkaRequestHandlerPool,執行真正的處理,對應的引數是num.io.threads,默認值是 8,IO執行緒處理完之后會將Response放入對應的Processor中,由Processor將回應返還給客戶端,
可以看到網路執行緒和IO執行緒之間利用的經典的生產者 - 消費者模式,不論是用于處理Request的共享請求佇列,還是IO處理完回傳的Response,
這樣的好處是什么?生產者和消費者之間解耦了,可以對生產者或者消費者做獨立的變更和擴展,并且可以平衡兩者的處理能力,例如消費不過來了,我多加些IO執行緒,
如果你看過其他中間件原始碼,你會發現生產者-消費者模式真的是太常見了,所以面試題經常會有手寫一波生產者-消費者,
原始碼級別剖析網路通信模型
Kafka 網路通信組件主要由兩大部分構成:SocketServer 和 KafkaRequestHandlerPool,
##SocketServer
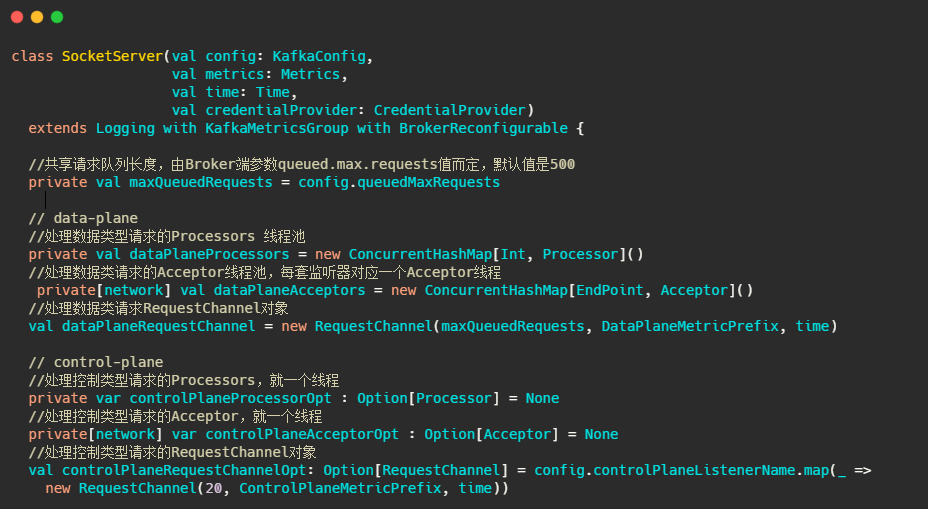
可以看出SocketServer旗下管理著,Acceptor 執行緒、Processor 執行緒和 RequestChannel等物件,
data-plane和control-plane稍后再做分析,先看看RequestChannel是什么,
RequestChannel
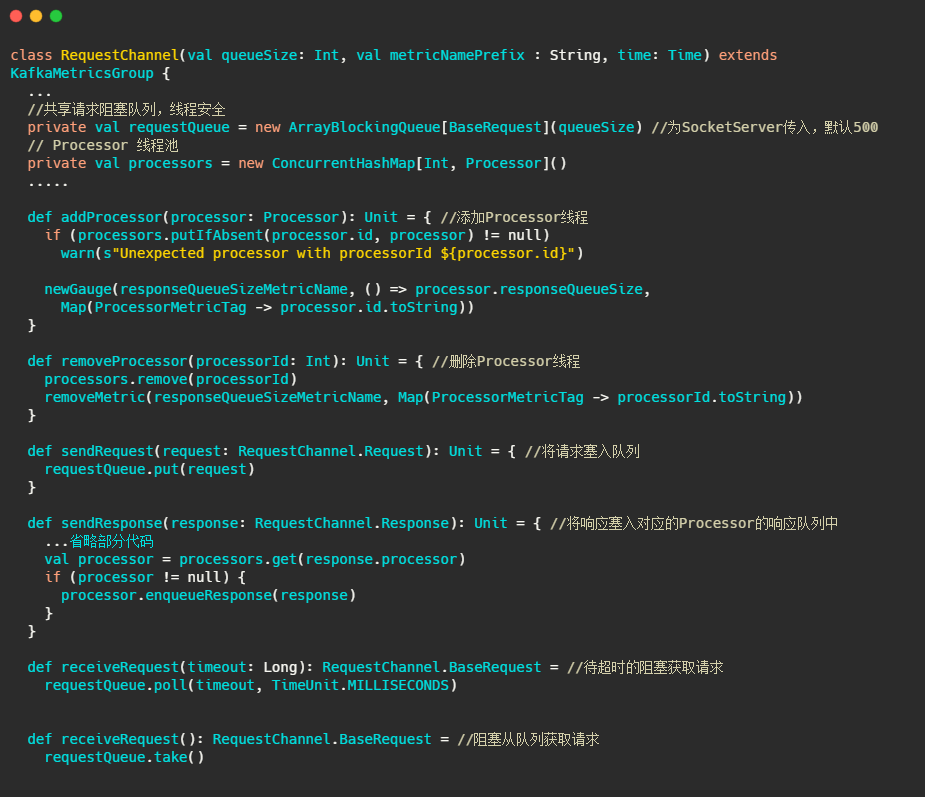
關鍵的屬性和方法都已經在下面代碼中注釋了,可以看出這個物件主要就是管理Processor和作為傳輸Request和Response的中轉站,
##Acceptor
接下來我們再看看Acceptor
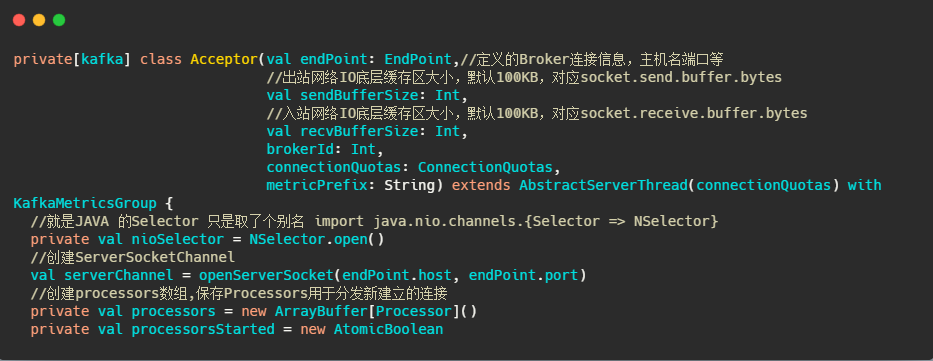
可以看到它繼承了AbstractServerThread,接下來再看看它run些啥
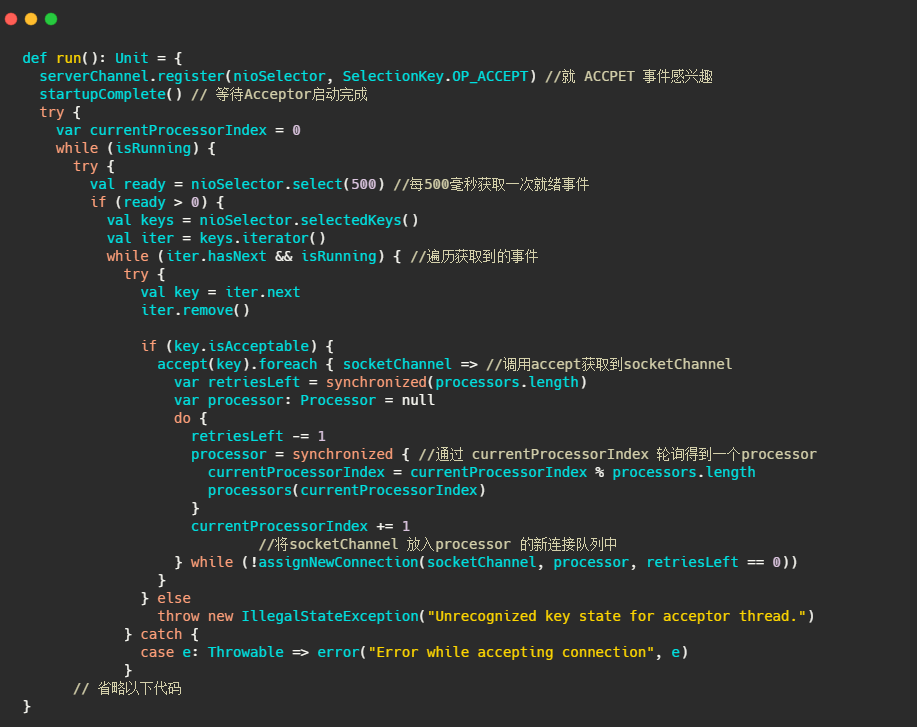
再來看看accept(key) 做了啥

很簡單,標準selector的處理,獲取準備就緒事件,呼叫serverSocketChannel.accept()得到socketChannel,將socketChannel交給通過輪詢選擇出來的Processor,之后由它來處理IO事件,
##Processor
接下來我們再看看Processor,相對而言比Acceptor 復雜一些,
先來看看三個關鍵的成員

再來看看主要的處理邏輯,
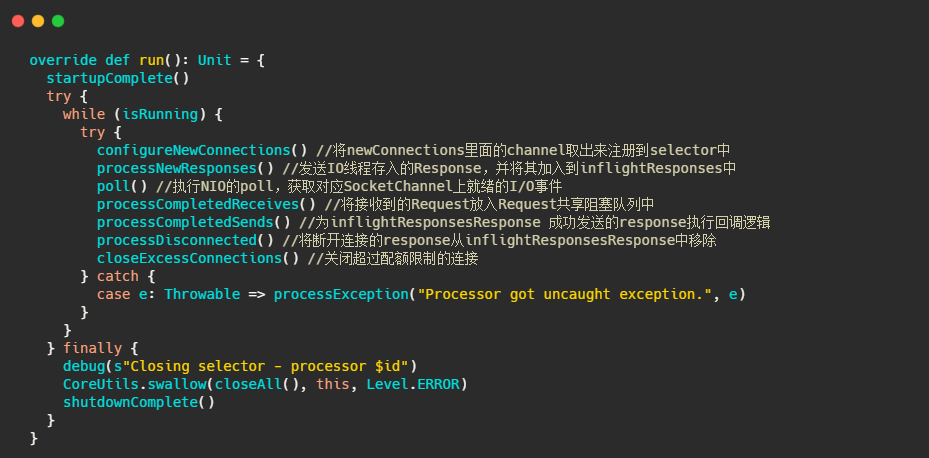
可以看到Processor主要是將底層讀事件IO資料封裝成Request存入佇列中,然后將IO執行緒塞入的Response,返還給客戶端,并處理Response 的回呼邏輯,
#KafkaRequestHandlerPool
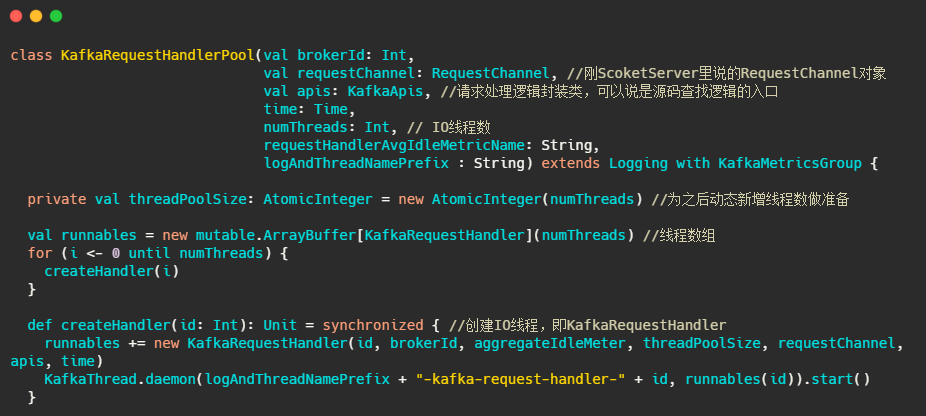
IO執行緒池,實際處理請求的執行緒,
再來看看IO執行緒都干了些啥
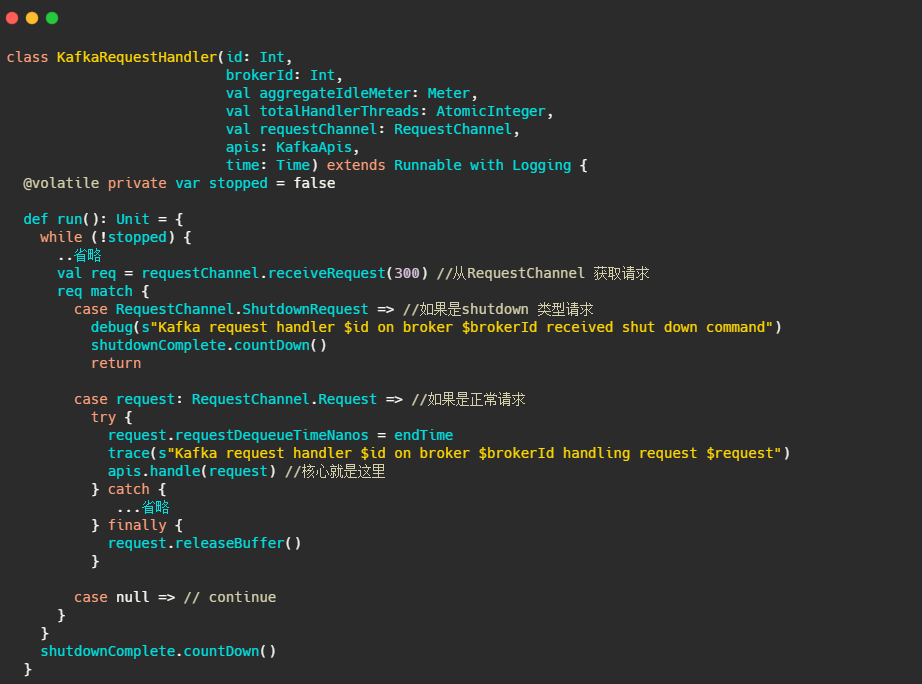
很簡單,核心就是不斷的從requestChannel拿請求,然后呼叫handle處理請求,
handle方法是位于KafkaApis類中,可以理解為通過switch,根據請求頭里面不同的apikey呼叫不同的handle來處理請求,
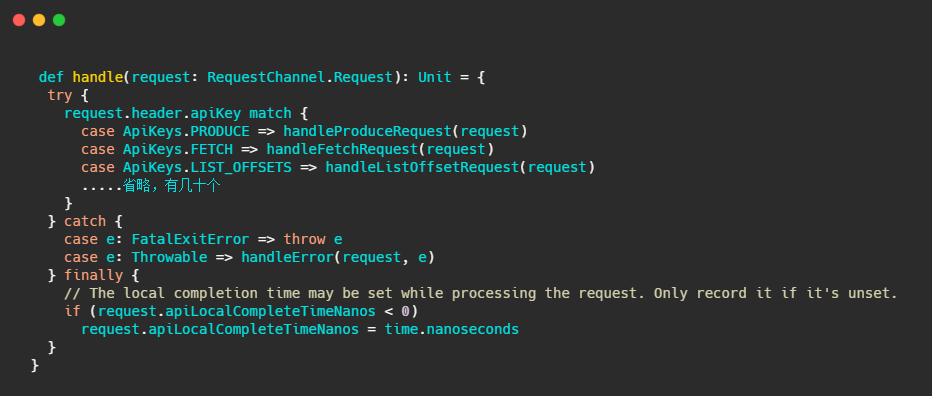
我們再舉例看下較為簡單的處理LIST_OFFSETS的程序,即handleListOffsetRequest,來完成一個請求的倍訓,
我用紅色箭頭標示了呼叫鏈,表明處理完請求之后是塞給對應的Processor的,
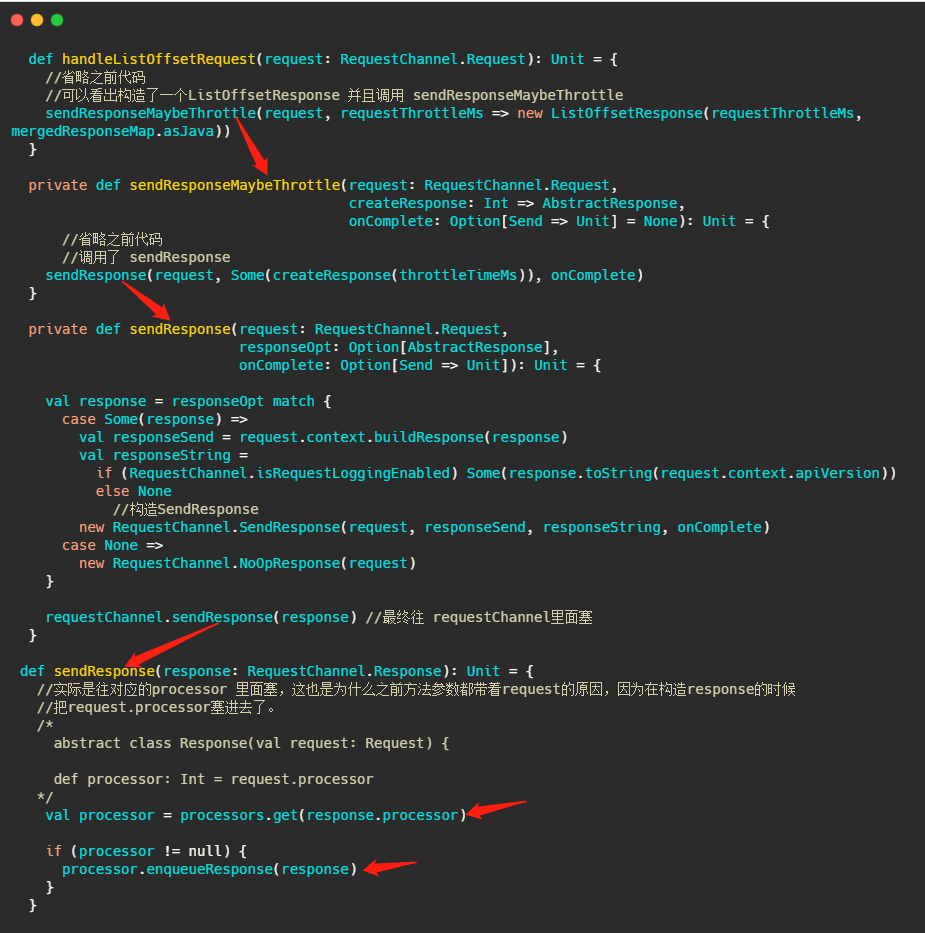
最后再來個更詳細的總覽圖,把原始碼分析到的類基本上都對應的加上去了,
請求處理優先級
上面提到的data-plane和control-plane是時候揭開面紗了,這兩個對應的就是資料類請求和控制類請求,
為什么需要分兩類請求呢?直接在請求里面用key標明請求是要讀寫資料啊還是更新元資料不就行了嗎?
簡單點的說比如我們想洗掉某個topic,我們肯定是想這個topic馬上被洗掉的,而此時producer還一直往這個topic寫資料,那這個情況可能是我們的洗掉請求排在第N個…等前面的寫入請求處理好了才輪到洗掉的請求,實際上前面哪些往這個topic寫入的請求都是沒用的,平白的消耗資源,
再或者說進行Preferred Leader選舉時候,producer將ack設定為all時候,老leader還在等著follower寫完資料向他報告呢,誰知follower已經成為了新leader,而通知它leader已經變更的請求由于被一堆資料型別請求堵著呢,老leader就傻傻的在等著,直到超時,
就是為了解決這種情況,社區將請求分為兩類,
那如何讓控制類的請求優先被處理?優先佇列?
社區采取的是兩套Listener,即資料型別一個listener,控制類一個listener,
對應的就是我們上面講的網路通信模型,在kafka中有兩套! kafka通過兩套監聽變相的實作了請求優先級,畢竟資料型別請求肯定很多,控制類肯定少,這樣看來控制類肯定比大部分資料型別先被處理!
迂回戰術啊,
控制類的和資料類區別就在于,就一個Porcessor執行緒,并且請求佇列寫死的長度為20,
最后
看原始碼主要就是得耐心,耐心跟下去,然后再跳出來看,你會發現不過如此,哈哈哈,

Kafka為什么要拋棄Zookeeper?
ZooKeeper 的作用
ZooKeeper 是一個開源的分布式協調服務框架,你也可以認為它是一個可以保證一致性的分布式(小量)存盤系統,特別適合存盤一些公共的配置資訊、集群的一些元資料等等,
它有持久節點和臨時節點,而臨時節點這個玩意再配合 Watcher 機制就很有用,
當創建臨時節點的客戶端與 ZooKeeper 斷連之后,這個臨時節點就會消失,并且訂閱了節點狀態變更的客戶端會收到這個節點狀態變更的通知,
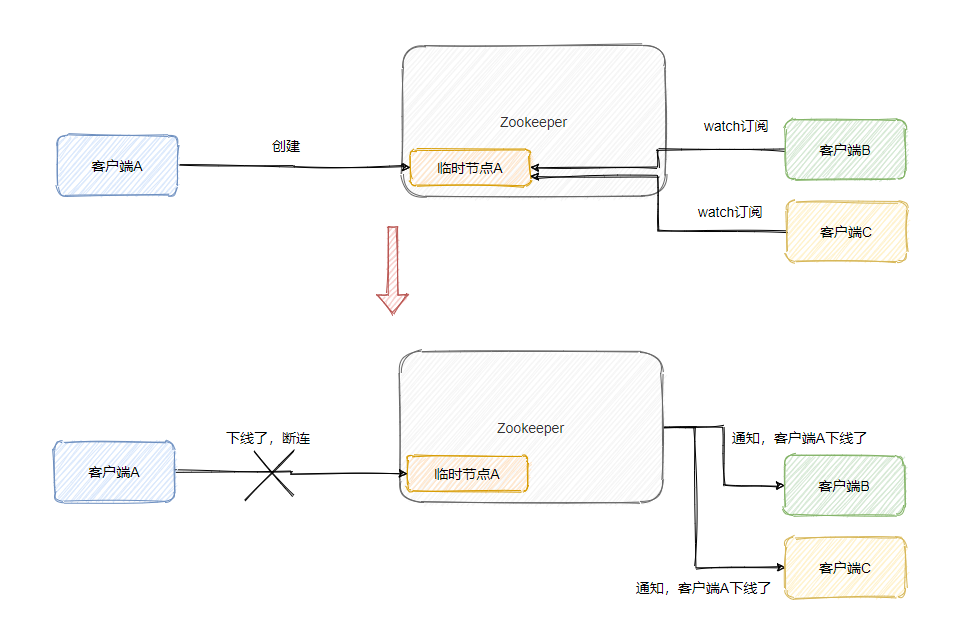
所以集群中某一服務上線或者下線,都可以被檢測到,因此可以用來實作服務發現,也可以實作故障轉移的監聽機制,
Kafka 就是強依賴于 ZooKeeper,沒有 ZooKeeper 的話 Kafka 都無法運行,
ZooKeeper 為 Kafka 提供了元資料的管理,例如一些 Broker 的資訊、主題資料、磁區資料等等,
在每個 Broker 啟動的時候,都會和 ZooKeeper 進行互動,這樣 ZooKeeper 就存盤了集群中所有的主題、配置、副本等資訊,
還有一些選舉、擴容等機制也都依賴 ZooKeeper ,
例如控制器的選舉:每個 Broker 啟動都會嘗試在 ZooKeeper 注冊/controller臨時節點來競選控制器,第一個創建/controller節點的 Broker 會被指定為控制器,
競爭失敗的節點也會依賴 watcher 機制,監聽這個節點,如果控制器宕機了,那么其它 Broker 會繼續來爭搶,實作控制器的 failover,
從上面就可以得知 ZooKeeper 對 Kafka 來說,很重要,
那為什么要拋棄 ZooKeeper
軟體架構都是演進的,之所以要變更那肯定是因為出現了瓶頸,
先來看看運維的層面的問題,
首先身為一個中間件,需要依賴另一個中間件,這就感覺有點奇怪,
你要說依賴 Netty 這種,那肯定是沒問題的,
但是 Kafka 的運行需要提供 ZooKeeper 集群,這其實有點怪怪的,
就等于如果你公司要上 Kafka 就得跟著上 ZooKeeper ,被動了增加了運維的復雜度,
好比你去商場買衣服,要買個上衣,服務員說不單賣,要買就得買一套,這錢是不是多花了?
所以運維人員不僅得照顧 Kafka 集群,還得照顧 ZooKeeper 集群,
再看性能層面的問題,
ZooKeeper 有個特點,強一致性,
如果 ZooKeeper 集群的某個節點的資料發生變更,則會通知其它 ZooKeeper 節點同時執行更新,就得等著大家(超過半數)都寫完了才行,這寫入的性能就比較差了,
然后看到上面我說的小量存盤系統了吧,一般而言,ZooKeeper 只適用于存盤一些簡單的配置或者是集群的元資料,不是真正意義上的存盤系統,
如果寫入的資料量過大,ZooKeeper 的性能和穩定性就會下降,可能導致 Watch 的延時或丟失,
所以在 Kafka 集群比較大,磁區數很多的時候,ZooKeeper 存盤的元資料就會很多,性能就差了,
還有,ZooKeeper 也是分布式的,也需要選舉,它的選舉也不快,而且發生選舉的那段時候是不提供服務的!
基于 ZooKeeper 的性能問題 Kafka 之前就做了一些升級,
例如以前 Consumer 的位移資料是保存在 ZooKeeper 上的,所以當提交位移或者獲取位移的時候都需要訪問 ZooKeeper ,這量一大 ZooKeeper 就頂不住,
所以后面引入了位移主題(Topic是__consumer_offsets),將位移的提交和獲取當做訊息一樣來處理,存盤在日志中,避免了頻繁訪問 ZooKeeper 性能差的問題,
還有像一些大公司,可能要支持百萬磁區級別,這目前的 Kafka 單集群架構下是無法支持穩定運行的,也就是目前單集群可以承載的磁區數有限,
所以 Kafka 需要去 ZooKeeper ,
所以沒了 Zookeeper 之后的 Kafka 的怎樣的?
沒了 Zookeeper 的 Kafka 把元資料就存盤到自己內部了,利用之前的 Log 存盤機制來保存元資料,
就和上面說到的位移主題一樣,會有一個元資料主題,元資料會像普通訊息一樣保存在 Log 中,
所以元資料和之前的位移一樣,利用現有的訊息存盤機制稍加改造來實作了功能,完美!
然后還搞了個 KRaft 來實作 Controller Quorum,
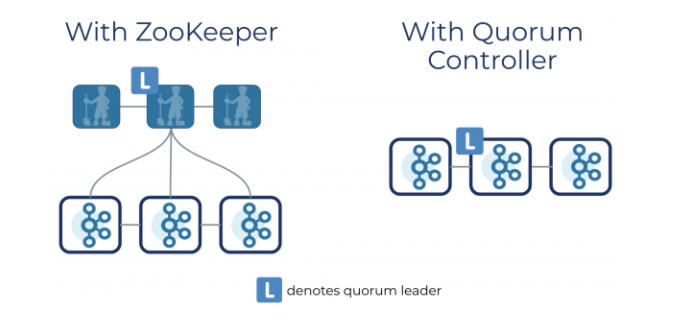
這個協議是基于 Raft 的,協議具體就不展開了,就理解為它能解決 Controller Leader 的選舉,并且讓所有節點達成共識,
在之前基于 Zookeeper 實作的單個 Controller 在磁區數太大的時候還有個問題,故障轉移太慢了,
當 Controller 變更的時候,需要重新加載所有的元資料到新的 Controller 身上,并且需要把這些元資料同步給集群內的所有 Broker,
而 Controller Quorum 中的 Leader 選舉切換則很快,因為元資料都已經在 quorum 中同步了,也就是 quorum 的 Broker 都已經有全部了元資料,所以不需要重新加載元資料!
并且其它 Broker 已經基于 Log 存盤了一些元資料,所以只需要增量更新即可,不需要全量了,
這波改造下來就解決了之前元資料過多的問題,可以支持更多的磁區!
最后
可能看到這里有人會說,那為何一開始不這么實作?
因為 ZooKeeper 是一個功能強大且經過驗證的工具,在早期利用它來實作一些功能,多簡單喲,都不需要自己實作,
要不是 ZooKeeper 的機制導致了這個瓶頸,也不可能會有這個改造的,
軟體就是這樣,沒必要重復造輪子,合適就好,
參考資料:
- https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/
- https://time.geekbang.org/column/article/253202
- https://www.infoq.cn/article/PHF3gFjUTDhWmctg6kXe
進階必看的 RocketMQ,這次一網打盡
今天就和大家一起深入生產級別訊息中間件 - RocketMQ 的內核實作,來看看真正落地能支撐萬億級訊息容量、低延遲的訊息佇列到底是如何設計的,
這篇文章我會先介紹整體的架構設計,然后再深入各核心模塊的詳細設計、核心流程的剖析,
還會提及使用的一些注意點和最佳實踐,
話不多說,上車,
RocketMQ 整體架構設計
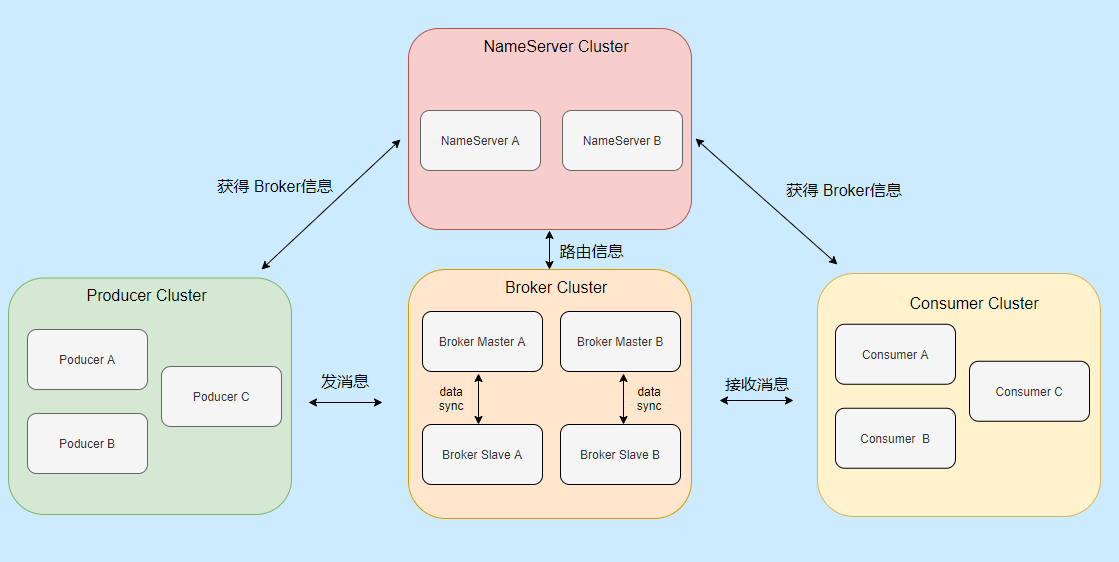
整體的架構設計主要分為四大部分,分別是:Producer、Consumer、Broker、NameServer,
為了更貼合實際,我畫的都是集群部署,像 Broker 我還畫了主從,
-
Producer:就是訊息生產者,可以集群部署,它會先和 NameServer 集群中的隨機一臺建立長連接,得知當前要發送的 Topic 存在哪臺 Broker Master上,然后再與其建立長連接,支持多種負載平衡模式發送訊息,
-
Consumer:訊息消費者,也可以集群部署,它也會先和 NameServer 集群中的隨機一臺建立長連接,得知當前要訊息的 Topic 存在哪臺 Broker Master、Slave上,然后它們建立長連接,支持集群消費和廣播消費訊息,
-
Broker:主要負責訊息的存盤、查詢消費,支持主從部署,一個 Master 可以對應多個 Slave,Master 支持讀寫,Slave 只支持讀,Broker 會向集群中的每一臺 NameServer 注冊自己的路由資訊,
-
NameServer:是一個很簡單的 Topic 路由注冊中心,支持 Broker 的動態注冊和發現,保存 Topic 和 Borker 之間的關系,通常也是集群部署,但是各 NameServer 之間不會互相通信, 各 NameServer 都有完整的路由資訊,即無狀態,
我再用一段話來概括它們之間的互動:

先啟動 NameServer 集群,各 NameServer 之間無任何資料互動,Broker 啟動之后會向所有 NameServer 定期(每 30s)發送心跳包,包括:IP、Port、TopicInfo,NameServer 會定期掃描 Broker 存活串列,如果超過 120s 沒有心跳則移除此 Broker 相關資訊,代表下線,
這樣每個 NameServer 就知道集群所有 Broker 的相關資訊,此時 Producer 上線從 NameServer 就可以得知它要發送的某 Topic 訊息在哪個 Broker 上,和對應的 Broker (Master 角色的)建立長連接,發送訊息,
Consumer 上線也可以從 NameServer 得知它所要接收的 Topic 是哪個 Broker ,和對應的 Master、Slave 建立連接,接收訊息,
簡單的作業流程如上所述,相信大家對整體資料流轉已經有點印象了,我們再來看看每個部分的詳細情況,
NameServer
它的特點就是輕量級,無狀態,角色類似于 Zookeeper 的情況,從上面描述知道其主要的兩個功能就是:Broker 管理、路由資訊管理,
總體而言比較簡單,我再貼一些欄位,讓大家有更直觀的印象知道它存盤了些什么,

Producer
Producer 無非就是訊息生產者,那首先它得知道訊息要發往哪個 Broker ,于是每 30s 會從某臺 NameServer 獲取 Topic 和 Broker 的映射關系存在本地記憶體中,如果發現新的 Broker 就會和其建立長連接,每 30s 會發送心跳至 Broker 維護連接,
并且會輪詢當前可以發送的 Broker 來發送訊息,達到負載均衡的目的,在同步發送情況下如果發送失敗會默認重投兩次(retryTimesWhenSendFailed = 2),并且不會選擇上次失敗的 broker,會向其他 broker 投遞,
在異步發送失敗的情況下也會重試,默認也是兩次 (retryTimesWhenSendAsyncFailed = 2),但是僅在同一個 Broker 上重試,
Producer 啟動流程
然后我們再來看看 Producer 的啟動流程看看都干了些啥,
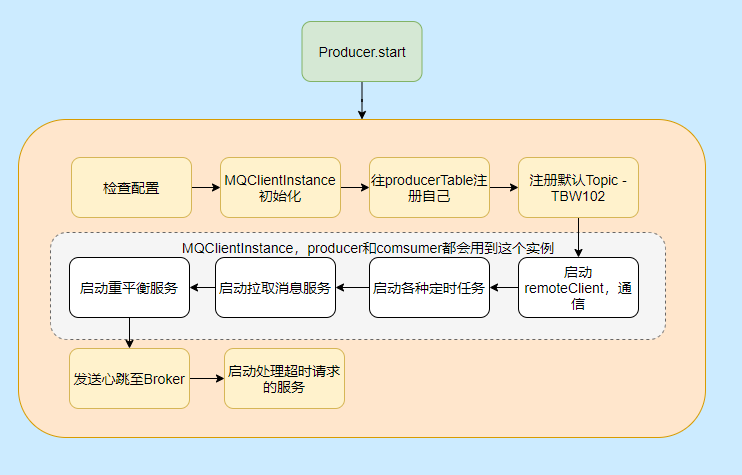
大致啟動流程圖中已經表明的很清晰的,但是有些細節可能還不清楚,比如重平衡啊,TBW102 啥玩意啊,有哪些定時任務啊,別急都會提到的,
有人可能會問這生產者為什么要啟拉取服務、重平衡?
因為 Producer 和 Consumer 都需要用 MQClientInstance,而同一個 clientId 是共用一個 MQClientInstance 的, clientId 是通過本機 IP 和 instanceName(默認值 default)拼起來的,所以多個 Producer 、Consumer 實際用的是一個MQClientInstance,
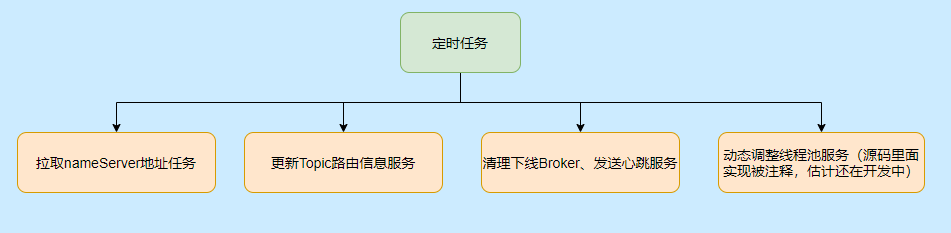
至于有哪些定時任務,請看下圖:
Producer 發訊息流程
我們再來看看發訊息的流程,大致也不是很復雜,無非就是找到要發送訊息的 Topic 在哪個 Broker 上,然后發送訊息,
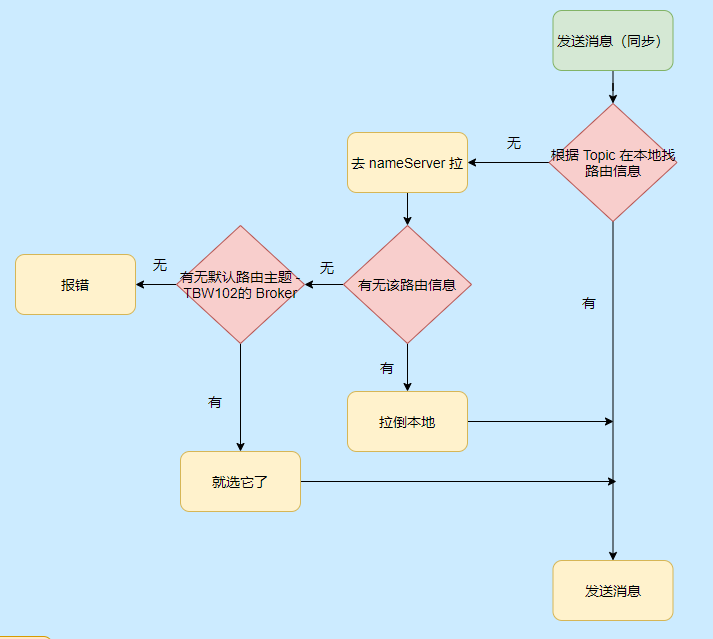
現在就知道 TBW102 是啥用的,就是接受自動創建主題的 Broker 啟動會把這個默認主題登記到 NameServer,這樣當 Producer 發送新 Topic 的訊息時候就得知哪個 Broker 可以自動創建主題,然后發往那個 Broker,
而 Broker 接受到這個訊息的時候發現沒找到對應的主題,但是它接受創建新主題,這樣就會創建對應的 Topic 路由資訊,
自動創建主題的弊端
自動創建主題那么有可能該主題的訊息都只會發往一臺 Broker,起不到負載均衡的作用,
因為創建新 Topic 的請求到達 Broker 之后,Broker 創建對應的路由資訊,但是心跳是每 30s 發送一次,所以說 NameServer 最長需要 30s 才能得知這個新 Topic 的路由資訊,
假設此時發送方還在連續快速的發送訊息,那 NameServer 上其實還沒有關于這個 Topic 的路由資訊,所以有機會讓別的允許自動創建的 Broker 也創建對應的 Topic 路由資訊,這樣集群里的 Broker 就能接受這個 Topic 的資訊,達到負載均衡的目的,但也有個別 Broker 可能,沒收到,
如果發送方這一次發了之后 30s 內一個都不發,之前的那個 Broker 隨著心跳把這個路由資訊更新到 NameServer 了,那么之后發送該 Topic 訊息的 Producer 從 NameServer 只能得知該 Topic 訊息只能發往之前的那臺 Broker ,這就不均衡了,如果這個新主題訊息很多,那臺 Broker 負載就很高了,
所以不建議線上開啟允許自動創建主題,即 autoCreateTopicEnable 引數,
發送訊息故障延遲機制
有一個引數是 sendLatencyFaultEnable,默認不開啟,這個引數的作用是對于之前發送超時的 Broker 進行一段時間的退避,
發送訊息會記錄此時發送訊息的時間,如果超過一定時間,那么此 Broker 就在一段時間內不允許發送,

比如發送時間超過 15000ms 則在 600000 ms 內無法向該 Broker 發送訊息,
這個機制其實很關鍵,發送超時大概率表明此 Broker 負載高,所以先避讓一會兒,讓它緩一緩,這也是實作訊息發送高可用的關鍵,
小結一下
Producer 每 30s 會向 NameSrv 拉取路由資訊更新本地路由表,有新的 Broker 就和其建立長連接,每隔 30s 發送心跳給 Broker ,
不要在生產環境開啟 autoCreateTopicEnable,
Producer 會通過重試和延遲機制提升訊息發送的高可用,
Broker
Broker 就比較復雜一些了,但是非常重要,大致分為以下五大模塊,我們來看一下官網的圖,
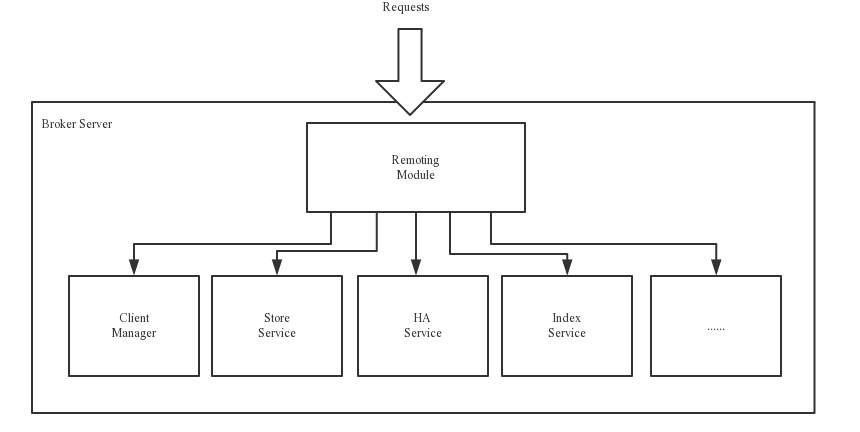
- Remoting 遠程模塊,處理客戶請求,
- Client Manager 管理客戶端,維護訂閱的主題,
- Store Service 提供訊息存盤查詢服務,
- HA Serivce,主從同步高可用,
- Index Serivce,通過指定key 建立索引,便于查詢,
有幾個模塊沒啥可說的就不分析了,先看看存盤的,
Broker 的存盤
RocketMQ 存盤用的是本地檔案存盤系統,效率高也可靠,
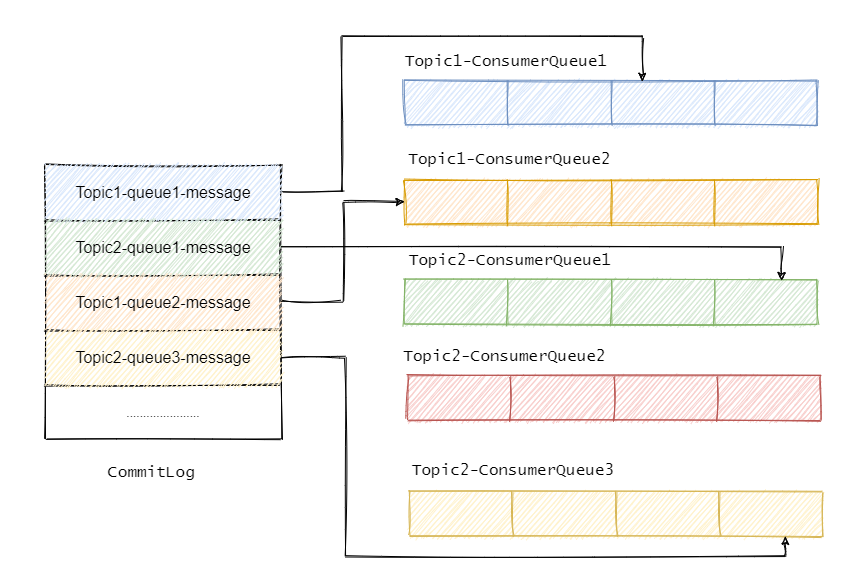
主要涉及到三種型別的檔案,分別是 CommitLog、ConsumeQueue、IndexFile,
CommitLog
RocketMQ 的所有主題的訊息都存在 CommitLog 中,單個 CommitLog 默認 1G,并且檔案名以起始偏移量命名,固定 20 位,不足則前面補 0,比如 00000000000000000000 代表了第一個檔案,第二個檔案名就是 00000000001073741824,表明起始偏移量為 1073741824,以這樣的方式命名用偏移量就能找到對應的檔案,
所有訊息都是順序寫入的,超過檔案大小則開啟下一個檔案,
ConsumeQueue
ConsumeQueue 訊息消費佇列,可以認為是 CommitLog 中訊息的索引,因為 CommitLog 是糅合了所有主題的訊息,所以通過索引才能更加高效的查找訊息,
ConsumeQueue 存盤的條目是固定大小,只會存盤 8 位元組的 commitlog 物理偏移量,4 位元組的訊息長度和 8 位元組 Tag 的哈希值,固定 20 位元組,
在實際存盤中,ConsumeQueue 對應的是一個Topic 下的某個 Queue,每個檔案約 5.72M,由 30w 條資料組成,
消費者是先從 ConsumeQueue 來得到訊息真實的物理地址,然后再去 CommitLog 獲取訊息,
IndexFile
IndexFile 就是索引檔案,是額外提供查找訊息的手段,不影響主流程,
通過 Key 或者時間區間來查詢對應的訊息,檔案名以創建時間戳命名,固定的單個 IndexFile 檔案大小約為400M,一個 IndexFile 存盤 2000W個索引,
我們再來看看以上三種檔案的內容是如何生成的:
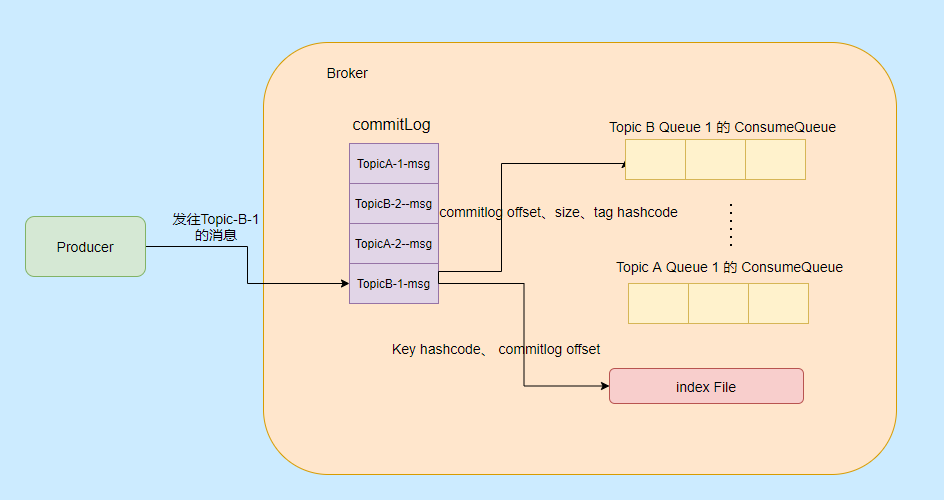
訊息到了先存盤到 Commitlog,然后會有一個 ReputMessageService 執行緒接近實時地將訊息轉發給訊息消費佇列檔案與索引檔案,也就是說是異步生成的,
訊息刷盤機制
RocketMQ 提供訊息同步刷盤和異步刷盤兩個選擇,關于刷盤我們都知道效率比較低,單純存入記憶體中的話效率是最高的,但是可靠性不高,影響訊息可靠性的情況大致有以下幾種:
- Broker 被暴力關閉,比如 kill -9
- Broker 掛了
- 作業系統掛了
- 機器斷電
- 機器壞了,開不了機
- 磁盤壞了
如果都是 1-4 的情況,同步刷盤肯定沒問題,異步的話就有可能丟失部分訊息,5 和 6就得依靠副本機制了,如果同步雙寫肯定是穩的,但是性能太差,如果異步則有可能丟失部分訊息,
所以需要看場景來使用同步、異步刷盤和副本雙寫機制,
頁快取與記憶體映射
Commitlog 是混合存盤的,所以所有訊息的寫入就是順序寫入,對檔案的順序寫入和記憶體的寫入速度基本上沒什么差別,
并且 RocketMQ 的檔案都利用了記憶體映射即 Mmap,將程式虛擬頁面直接映射到頁快取上,無需有內核態再往用戶態的拷貝,來看一下我之前文章畫的圖,
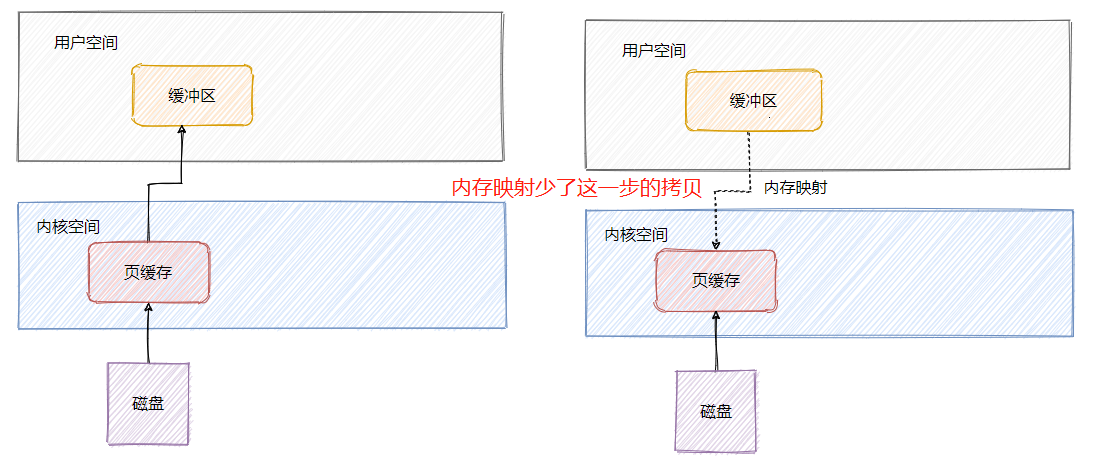
頁快取其實就是作業系統對檔案的快取,用來加速檔案的讀寫,也就是說對檔案的寫入先寫到頁快取中,作業系統會不定期刷盤(時間不可控),對檔案的讀會先加載到頁快取中,并且根據區域性原理還會預讀臨近塊的內容,
其實也是因為使用記憶體映射機制,所以 RocketMQ 的檔案存盤都使用定長結構來存盤,方便一次將整個檔案映射至記憶體中,
檔案預分配和檔案預熱
而記憶體映射也只是做了映射,只有當真正讀取頁面的時候產生缺頁中斷,才會將資料真正加載到記憶體中,所以 RocketMQ 做了一些優化,防止運行時的性能抖動,
檔案預分配
CommitLog 的大小默認是1G,當超過大小限制的時候需要準備新的檔案,而 RocketMQ 就起了一個后臺執行緒 AllocateMappedFileService,不斷的處理 AllocateRequest,AllocateRequest 其實就是預分配的請求,會提前準備好下一個檔案的分配,防止在訊息寫入的程序中分配檔案,產生抖動,
檔案預熱
有一個 warmMappedFile 方法,它會把當前映射的檔案,每一頁遍歷多去,寫入一個0位元組,然后再呼叫mlock 和 madvise(MADV_WILLNEED),
mlock:可以將行程使用的部分或者全部的地址空間鎖定在物理記憶體中,防止其被交換到 swap 空間,
madvise:給作業系統建議,說這檔案在不久的將來要訪問的,因此,提前讀幾頁可能是個好主意,
小結一下
CommitLog 采用混合型存盤,也就是所有 Topic 都存在一起,順序追加寫入,檔案名用起始偏移量命名,
訊息先寫入 CommitLog 再通過后臺執行緒分發到 ConsumerQueue 和 IndexFile 中,
消費者先讀取 ConsumerQueue 得到真正訊息的物理地址,然后訪問 CommitLog 得到真正的訊息,
利用了 mmap 機制減少一次拷貝,利用檔案預分配和檔案預熱提高性能,
提供同步和異步刷盤,根據場景選擇合適的機制,
Broker 的 HA
從 Broker 會和主 Broker 建立長連接,然后獲取主 Broker commitlog 最大偏移量,開始向主 Broker 拉取訊息,主 Broker 會回傳一定數量的訊息,回圈進行,達到主從資料同步,
消費者消費訊息會先請求主 Broker ,如果主 Broker 覺得現在壓力有點大,則會回傳從 Broker 拉取訊息的建議,然后消費者就去從服務器拉取訊息,
Consumer
消費有兩種模式,分別是廣播模式和集群模式,
廣播模式:一個分組下的每個消費者都會消費完整的Topic 訊息,
集群模式:一個分組下的消費者瓜分消費Topic 訊息,
一般我們用的都是集群模式,
Consumer 端的負載均衡機制
Consumer 會定期的獲取 Topic 下的佇列數,然后再去查找訂閱了該 Topic 的同一消費組的所有消費者資訊,默認的分配策略是類似分頁排序分配,
將佇列排好序,然后消費者排好序,比如佇列有 9 個,消費者有 3 個,那消費者-1 消費佇列 0、1、2 的訊息,消費者-2 消費佇列 3、4、5,以此類推,
所以如果負載太大,那么就加佇列,加消費者,通過負載均衡機制就可以感知到重平衡,均勻負載,
Consumer 訊息消費的重試
難免會遇到訊息消費失敗的情況,所以需要提供消費失敗的重試,而一般的消費失敗要么就是訊息結構有誤,要么就是一些暫時無法處理的狀態,所以立即重試不太合適,
RocketMQ 會給每個消費組都設定一個重試佇列,Topic 是 %RETRY%+consumerGroup,并且設定了很多重試級別來延遲重試的時間,
為了利用 RocketMQ 的延時佇列功能,重試的訊息會先保存在 Topic 名稱為“SCHEDULE_TOPIC_XXXX”的延遲佇列,在訊息的擴展欄位里面會存盤原來所屬的 Topic 資訊,
delay 一段時間后再恢復到重試佇列中,然后 Consumer 就會消費這個重試佇列主題,得到之前的訊息,
如果超過一定的重試次數都消費失敗,則會移入到死信佇列,即 Topic %DLQ%" + ConsumerGroup 中,存盤死信佇列即認為消費成功,因為實在沒轍了,暫時放過,
然后我們可以通過人工來處理死信佇列的這些訊息,
訊息的全域順序和區域順序
全域順序就是消除一切并發,一個 Topic 一個佇列,Producer 和 Consuemr 的并發都為一,
區域順序其實就是指某個佇列順序,多佇列之間還是能并行的,
可以通過 MessageQueueSelector 指定 Producer 某個業務只發這一個佇列,然后 Comsuer 通過MessageListenerOrderly 接受訊息,其實就是加鎖消費,
在 Broker 會有一個 mqLockTable ,順序訊息在創建拉取訊息任務的時候需要在 Broker 鎖定該訊息佇列,之后加鎖成功的才能消費,
而嚴格的順序訊息其實很難,假設現在都好好的,如果有個 Broker 宕機了,然后發生了重平衡,佇列對應的消費者實體就變了,就會有可能會出現亂序的情況,如果要保持嚴格順序,那此時就只能讓整個集群不可用了,
一些注意點
1、訂閱訊息是以 ConsumerGroup 為單位存盤的,所以ConsumerGroup 中的每個 Consumer 需要有相同的訂閱,
因為訂閱訊息是隨著心跳上傳的,如果一個 ConsumerGroup 中 Consumer 訂閱資訊不一樣,那么就會出現互相覆寫的情況,
比如消費者 A 訂閱 Topic a,消費者 B 訂閱 Topic b,此時消費者 A 去 Broker 拿訊息,然后 B 的心跳包發出了,Broker 更新了,然后接到 A 的請求,一臉懵逼,沒這訂閱關系啊,
2、RocketMQ 主從讀寫分離
從只能讀,不能寫,并且只有當前客戶端讀的 offset 和 當前 Broker 已接受的最大 offset 超過限制的物理記憶體大小時候才會去從讀,所以正常情況下從分擔不了流量
3、單單加機器提升不了消費速度,佇列的數量也需要跟上,
4、之前提到的,不要允許自動創建主題
RocketMQ 的最佳實踐
這些最佳實踐部分參考自官網,
Tags的使用
建議一個應用一個 Topic,利用 tages 來標記不同業務,因為 tages 設定比較靈活,且一個應用一個 Topic 很清晰,能直觀的辨別,
Keys的使用
如果有訊息業務上的唯一標識,請填寫到 keys 欄位中,方便日后的定位查找,
提高 Consumer 的消費能力
1、提高消費并行度:增加佇列數和消費者數量,提高單個消費者的并行消費執行緒,引數 consumeThreadMax,
2、批處理消費,設定 consumeMessageBatchMaxSize 引數,這樣一次能拿到多條訊息,然后比如一個 update陳述句之前要執行十次,現在一次就執行完,
3、跳過非核心的訊息,當負載很重的時候,為了保住那些核心的訊息,設定那些非核心的訊息,例如此時訊息堆積 1W 條了之后,就直接回傳消費成功,跳過非核心訊息,
NameServer 的尋址
請使用 HTTP 靜態服務器尋址(默認),這樣 NameServer 就能動態發現,
JVM選項
以下抄自官網:
如果不關心 RocketMQ Broker的啟動時間,通過“預觸摸” Java 堆以確保在 JVM 初始化期間每個頁面都將被分配,
那些不關心啟動時間的人可以啟用它:? -XX:+AlwaysPreTouch
禁用偏置鎖定可能會減少JVM暫停,? -XX:-UseBiasedLocking
至于垃圾回收,建議使用帶JDK 1.8的G1收集器,
-XX:+UseG1GC -XX:G1HeapRegionSize=16m
-XX:G1ReservePercent=25
-XX:InitiatingHeapOccupancyPercent=30
另外不要把-XX:MaxGCPauseMillis的值設定太小,否則JVM將使用一個小的年輕代來實作這個目標,這將導致非常頻繁的minor GC,所以建議使用rolling GC日志檔案:
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=30m
Linux內核引數
以下抄自官網:
- vm.extra_free_kbytes,告訴VM在后臺回收(kswapd)啟動的閾值與直接回收(通過分配行程)的閾值之間保留額外的可用記憶體,RocketMQ使用此引數來避免記憶體分配中的長延遲,(與具體內核版本相關)
- vm.min_free_kbytes,如果將其設定為低于1024KB,將會巧妙的將系統破壞,并且系統在高負載下容易出現死鎖,
- vm.max_map_count,限制一個行程可能具有的最大記憶體映射區域數,RocketMQ將使用mmap加載CommitLog和ConsumeQueue,因此建議將為此引數設定較大的值,(agressiveness --> aggressiveness)
- vm.swappiness,定義內核交換記憶體頁面的積極程度,較高的值會增加攻擊性,較低的值會減少交換量,建議將值設定為10來避免交換延遲,
- File descriptor limits,RocketMQ需要為檔案(CommitLog和ConsumeQueue)和網路連接打開檔案描述符,我們建議設定檔案描述符的值為655350,
- Disk scheduler,RocketMQ建議使用I/O截止時間調度器,它試圖為請求提供有保證的延遲,
最后
其實還有很多沒講,比如流量控制、訊息的過濾、定時訊息的實作,包括底層通信 1+N+M1+M2 的 Reactor 多執行緒設計等等,
主要是內容太多了,而且也不太影響主流程,所以還是剝離出來之后寫吧,大致的一些實作還是講了的,
包括元資訊的互動、訊息的發送、存盤、消費等等,
關于事務訊息的那一塊我之前文章也分析過了,所以這個就不再貼了,
可以看到要實作一個生產級別的訊息佇列還是有很多很多東西需要考慮的,不過大致的架構和涉及到的模塊差不多就這些了,
至于具體的細節深入,還是得靠大家自行研究了,我就起個拋磚引玉的作用,
最后個人能力有限,如果哪里有紕漏請抓緊聯系鞭撻我!
Kafka和RocketMQ底層存盤揭秘,為什么能這么快?
我們都知道 RocketMQ 和 Kafka 訊息都是存在磁盤中的,那為什么訊息存磁盤讀寫還可以這么快?有沒有做了什么優化?都是存磁盤它們兩者的實作之間有什么區別么?各自有什么優缺點?
今天我們就來一探究竟,
存盤介質-磁盤
一般而言訊息中間件的訊息都存盤在本地檔案中,因為從效率來看直接放本地檔案是最快的,并且穩定性最高,畢竟要是放類似資料庫等第三方存盤中的話,就多一個依賴少一份安全,并且還有網路的開銷,
那對于將訊息存入磁盤檔案來說一個流程的瓶頸就是磁盤的寫入和讀取,我們知道磁盤相對而言讀寫速度較慢,那通過磁盤作為存盤介質如何實作高吞吐呢?
順序讀寫
答案就是順序讀寫,
首先了解一下頁快取,頁快取是作業系統用來作為磁盤的一種快取,減少磁盤的I/O操作,
在寫入磁盤的時候其實是寫入頁快取中,使得對磁盤的寫入變成對記憶體的寫入,寫入的頁變成臟頁,然后作業系統會在合適的時候將臟頁寫入磁盤中,
在讀取的時候如果頁快取命中則直接回傳,如果頁快取 miss 則產生缺頁中斷,從磁盤加載資料至頁快取中,然后回傳資料,
并且在讀的時候會預讀,根據區域性原理當讀取的時候會把相鄰的磁盤塊讀入頁快取中,在寫入的時候會后寫,寫入的也是頁快取,這樣存著可以將一些小的寫入操作合并成大的寫入,然后再刷盤,
而且根據磁盤的構造,順序 I/O 的時候,磁頭幾乎不用換道,或者換道的時間很短,
根據網上的一些測驗結果,順序寫盤的速度比隨機寫記憶體還要快,
當然這樣的寫入存在資料丟失的風險,例如機器突然斷電,那些還未刷盤的臟頁就丟失了,不過可以呼叫 fsync 強制刷盤,但是這樣對于性能的損耗較大,
因此一般建議通過多副本機制來保證訊息的可靠,而不是同步刷盤,
可以看到順序 I/O 適應磁盤的構造,并且還有預讀和后寫, RocketMQ 和 Kafka 都是順序寫入和近似順序讀取,它們都采用檔案追加的方式來寫入訊息,只能在日志檔案尾部寫入新的訊息,老的訊息無法更改,
mmap-檔案記憶體映射
從上面可知訪問磁盤檔案會將資料加載到頁快取中,但是頁快取屬于內核空間,用戶空間訪問不了,因此資料還需要拷貝到用戶空間緩沖區,
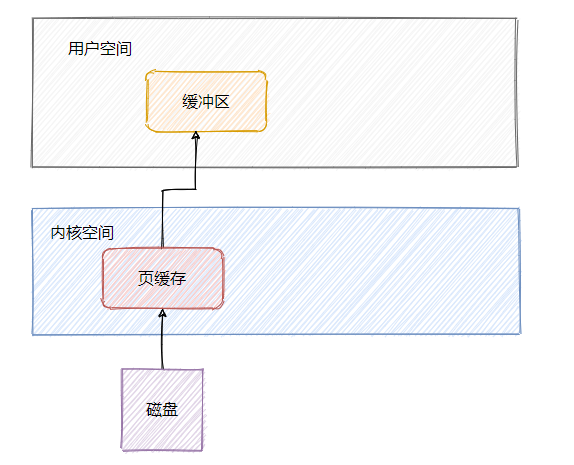
可以看到資料需要從頁快取再經過一次拷貝程式才能訪問的到,因此還可以通過mmap來做一波優化,利用記憶體映射檔案來避免拷貝,
簡單的說檔案映射就是將程式虛擬頁面直接映射到頁快取上,這樣就無需有內核態再往用戶態的拷貝,而且也避免了重復資料的產生,并且也不必再通過呼叫read或write方法對檔案進行讀寫,可以通過映射地址加偏移量的方式直接操作,

sendfile-零拷貝
既然訊息是存在磁盤中的,那消費者來拉訊息的時候就得從磁盤拿,我們先來看看一般發送檔案的流程是如何的,
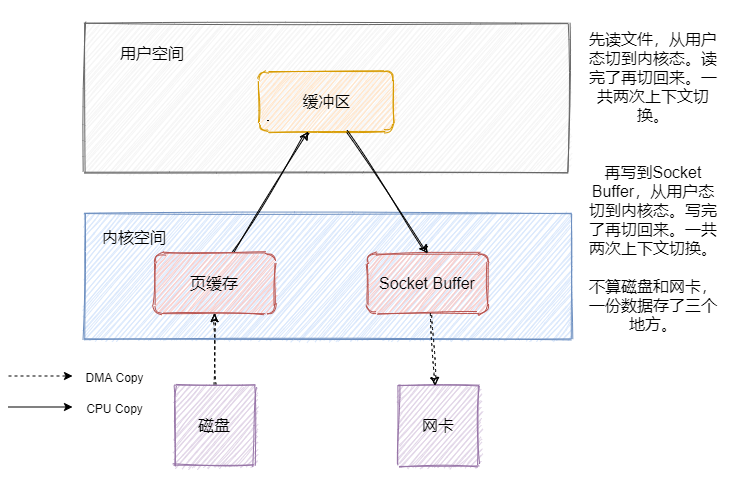
簡單說下DMA是什么,全稱 Direct Memory Access ,它可以獨立地直接讀寫系統記憶體,不需要 CPU 介入,像顯卡、網卡之類都會用DMA,
可以看到資料其實是冗余的,那我們來看看mmap之后的發送檔案流程是怎樣的,
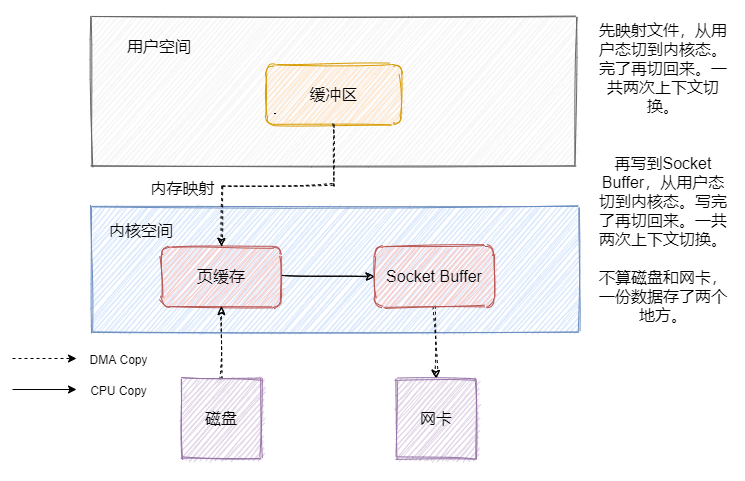
可以看到背景關系切換的次數沒有變化,但是資料少拷貝一份,這和我們上文提到的mmap能達到的效果是一樣的,
但是資料還是冗余了一份,這不是可以直接把資料從頁快取拷貝到網卡不就好了嘛?sendfile就有這個功效,我們先來看看Linux2.1版本中的sendfile,
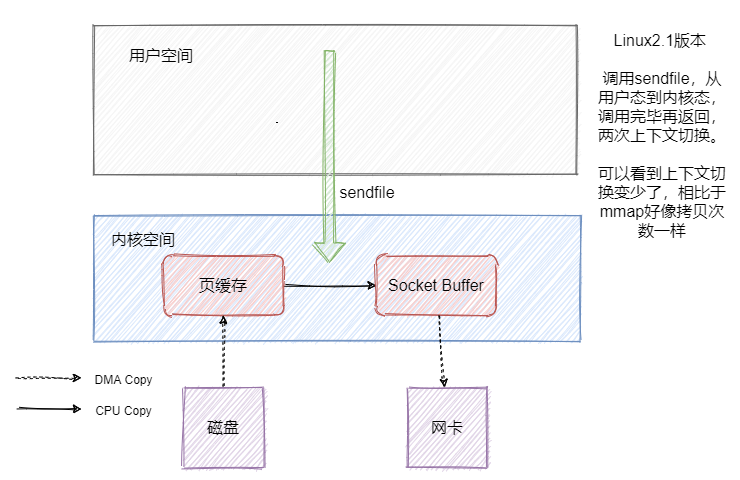
因為就一個系統呼叫就滿足了發送的需求,相比 read + write 或者 mmap + write 背景關系切換肯定是少了的,但是好像資料還是有冗余啊,是的,因此 Linux2.4 版本的 sendfile + 帶 「分散-收集(Scatter-gather)」的DMA,實作了真正的無冗余,
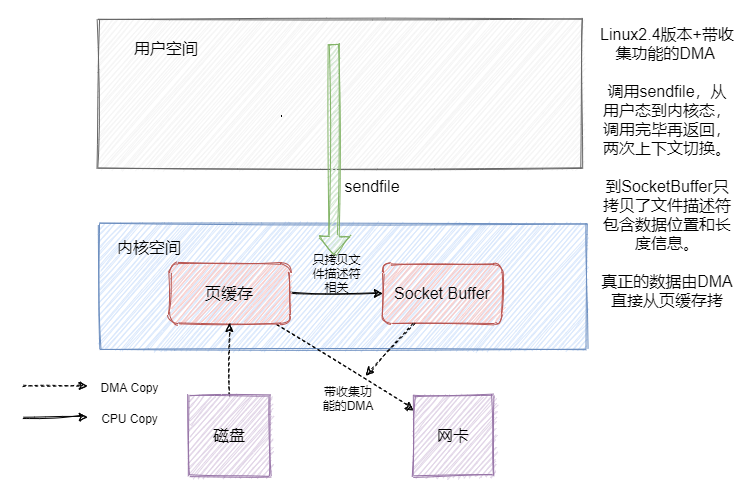
這就是我們常說的零拷貝,在 Java 中FileChannal.transferTo()底層用的就是sendfile,
接下來我們看看以上說的幾點在 RocketMQ 和 Kafka中是如何應用的,
RocketMQ 和 Kafka 的應用
RocketMQ
采用Topic混合追加方式,即一個 CommitLog 檔案中會包含分給此 Broker 的所有訊息,不論訊息屬于哪個 Topic 的哪個 Queue ,
所以所有的訊息過來都是順序追加寫入到 CommitLog 中,并且建立訊息對應的 CosumerQueue ,然后消費者是通過 CosumerQueue 得到訊息的真實物理地址再去 CommitLog 獲取訊息的,可以將 CosumerQueue 理解為訊息的索引,
在 RocketMQ 中不論是 CommitLog 還是 CosumerQueue 都采用了 mmap,

在發訊息的時候默認用的是將資料拷貝到堆記憶體中,然后再發送,我們來看下代碼,

可以看到這個配置 transferMsgByHeap 默認是 true ,那我們再看消費者拉訊息時候的代碼,

可以看到 RocketMQ 默認把訊息拷貝到堆內 Buffer 中,再塞到回應體里面發送,但是可以通過引數配置不經過堆,不過也并沒有用到真正的零拷貝,而是通過mapedBuffer 發送到 SocketBuffer ,
所以 RocketMQ 用了順序寫盤、mmap,并沒有用到 sendfile ,還有一步頁快取到 SocketBuffer 的拷貝,
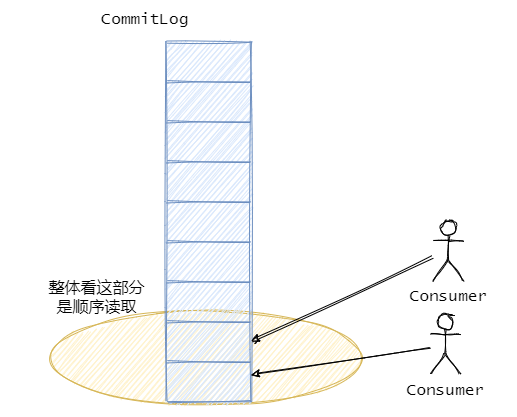
然后拉訊息的時候嚴格的說對于 CommitLog 來說讀取是隨機的,因為 CommitLog 的訊息是混合的存盤的,**但是從整體上看,訊息還是從 CommitLog 順序讀的,都是從舊資料到新資料有序的讀取,**并且一般而言訊息存進去馬上就會被消費,因此訊息這時候應該還在頁快取中,所以不需要讀盤,
而且我們在上面提到,頁快取會定時刷盤,這刷盤不可控,并且記憶體是有限的,會有swap等情況,而且**mmap其實只是做了映射,當真正讀取頁面的時候產生缺頁中斷,才會將資料真正加載到記憶體中,**這對于訊息佇列來說可能會產生監控上的毛刺,
因此 RocketMQ 做了一些優化,有:檔案預分配和檔案預熱,
檔案預分配
CommitLog 的大小默認是1G,當超過大小限制的時候需要準備新的檔案,而 RocketMQ 就起了一個后臺執行緒 AllocateMappedFileService,不斷的處理 AllocateRequest,AllocateRequest其實就是預分配的請求,會提前準備好下一個檔案的分配,防止在訊息寫入的程序中分配檔案,產生抖動,
檔案預熱
有一個warmMappedFile方法,它會把當前映射的檔案,每一頁遍歷多去,寫入一個0位元組,然后再呼叫mlock 和 madvise(MADV_WILLNEED),
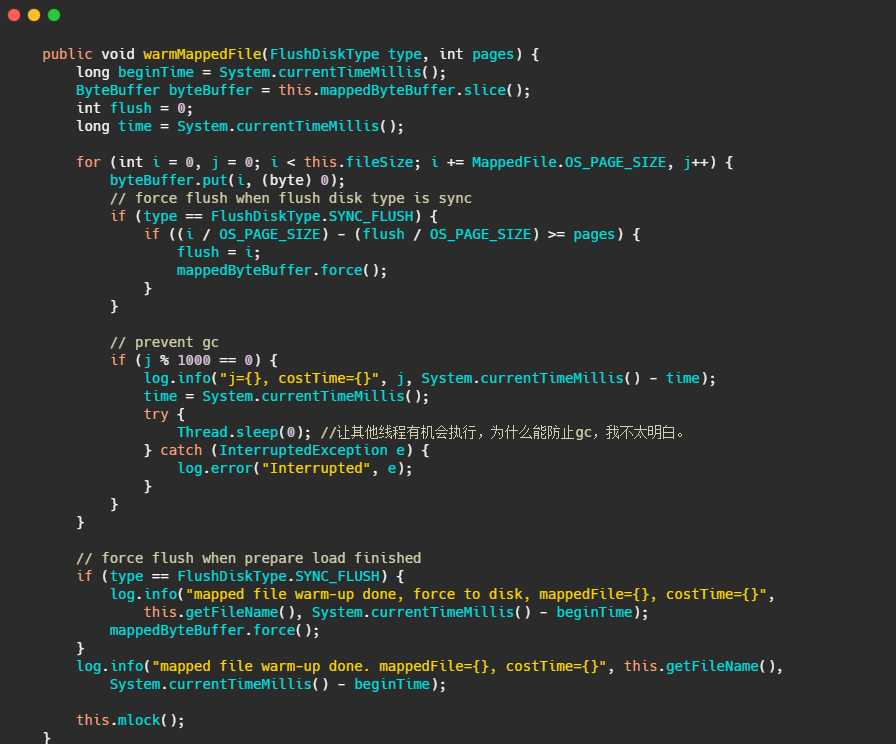
我們再來看下this.mlock,內部其實就是呼叫了mlock 和 madvise(MADV_WILLNEED),
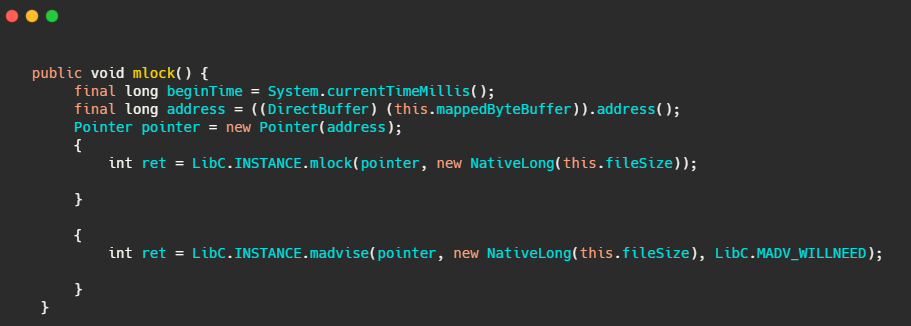
mlock:可以將行程使用的部分或者全部的地址空間鎖定在物理記憶體中,防止其被交換到swap空間,
madvise:給作業系統建議,說這檔案在不久的將來要訪問的,因此,提前讀幾頁可能是個好主意,
RocketMQ 小結
順序寫盤,整體來看是順序讀盤,并且使用了 mmap,不是真正的零拷貝,又因為頁快取的不確定性和 mmap 惰性加載(訪問時缺頁中斷才會真正加載資料),用了檔案預先分配和檔案預熱即每頁寫入一個0位元組,然后再呼叫mlock 和 madvise(MADV_WILLNEED),
Kafka
Kafka 的日志存盤和 RocketMQ 不一樣,它是一個磁區一個檔案,
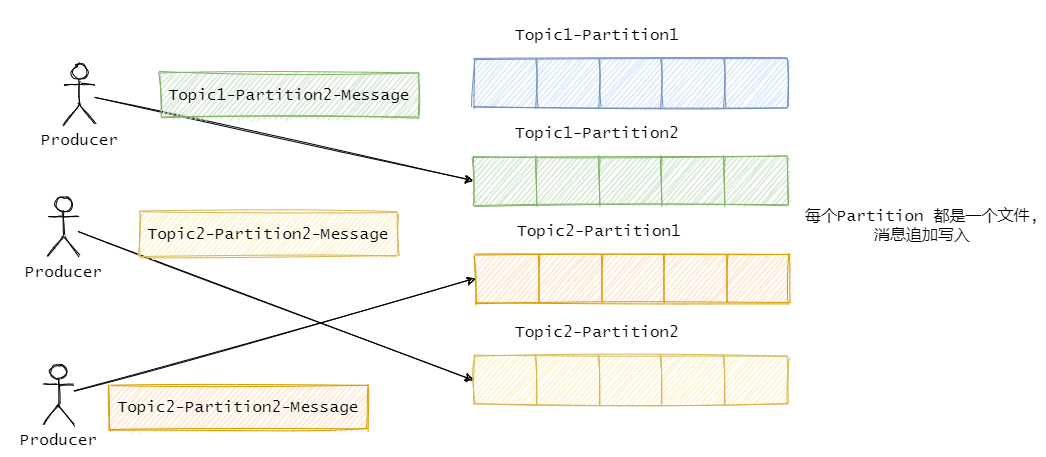
Kafka 的訊息寫入對于單磁區來說也是順序寫,如果磁區不多的話從整體上看也算順序寫,它的日志檔案并沒有用到 mmap,而索引檔案用了 mmap,但發訊息 Kafka 用到了零拷貝,
對于訊息的寫入來說 mmap 其實沒什么用,因為訊息是從網路中來,而對于發訊息來說 sendfile 對比 mmap+write 我覺得效率更高,因為少了一次頁快取到 SocketBuffer 中的拷貝,
來看下Kafka發訊息的原始碼,最終呼叫的是 FileChannel.transferTo,底層就是 sendfile,
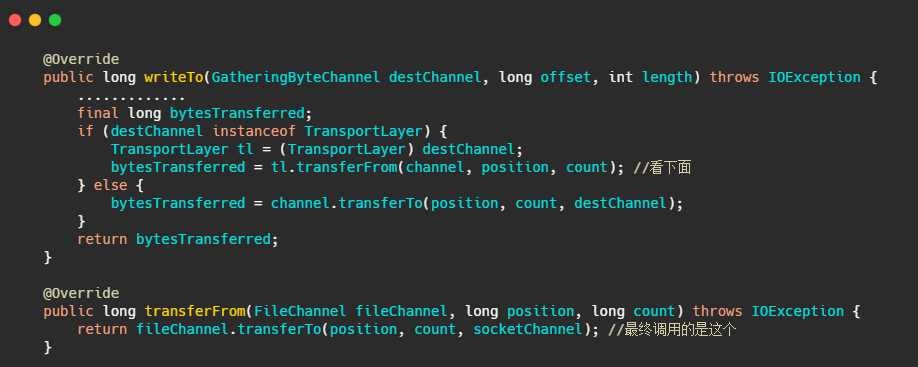
從 Kafka 原始碼中我沒看到有類似于 RocketMQ的 mlock 等操作,我覺得原因是首先日志也沒用到 mmap,然后 swap 其實可以通過 Linux 系統引數 vm.swappiness 來調節,這里建議設定為1,而不是0,
假設記憶體真的不足,設定為 0 的話,在記憶體耗盡的情況下,又不能 swap,則會突然中止某些行程,設定個 1,起碼還能拖一下,如果有良好的監控手段,還能給個機會發現一下,不至于突然中止,
RocketMQ & Kafka 對比
首先都是順序寫入,不過 RocketMQ 是把訊息都存一個檔案中,而 Kafka 是一個磁區一個檔案,
每個磁區一個檔案在遷移或者資料復制層面上來說更加得靈活,
但是磁區多了的話,寫入需要頻繁的在多個檔案之間來回切換,對于每個檔案來說是順序寫入的,但是從全域看其實算隨機寫入,并且讀取的時候也是一樣,算隨機讀,而就一個檔案的 RocketMQ 就沒這個問題,
從發送訊息來說 RocketMQ 用到了 mmap + write 的方式,并且通過預熱來減少大檔案 mmap 因為缺頁中斷產生的性能問題,而 Kafka 則用了 sendfile,相對而言我覺得 kafka 發送的效率更高,因為少了一次頁快取到 SocketBuffer 中的拷貝,
并且 swap 問題也可以通過系統引數來設定,
番外篇:定時任務的終極實作–時間輪,在Netty和Kafka中如何應用的?為什么不用Timer、延時執行緒池?
最近看 Kafka 看到了時間輪演算法,記得以前看 Netty 也看到過這玩意,沒太過關注,今天就來看看時間輪到底是什么東西,
為什么要用時間輪演算法來實作延遲操作?
延時操作 Java 不是提供了 Timer 么?
還有 DelayQueue 配合執行緒池或者 ScheduledThreadPool 不香嗎?
我們先來簡單看看 Timer、DelayQueue 和 ScheduledThreadPool 的相關實作,看看它們是如何實作延時任務的,原始碼之下無秘密,再來剖析下為何 Netty 和 Kafka 特意實作了時間輪來處理延遲任務,
Timer
Timer 可以實作延時任務,也可以實作周期性任務,我們先來看看 Timer 核心屬性和構造器,

核心就是一個優先佇列和封裝的執行任務的執行緒,從這我們也可以看到一個 Timer 只有一個執行緒執行任務,
再來看看如何實作延時和周期性任務的,我先簡單的概括一下,首先維持一個小頂堆,即最快需要執行的任務排在優先佇列的第一個,根據堆的特性我們知道插入和洗掉的時間復雜度都是 O(logn),
然后 TimerThread 不斷地拿排著的第一個任務的執行時間和當前時間做對比,如果時間到了先看看這個任務是不是周期性執行的任務,如果是則修改當前任務時間為下次執行的時間,如果不是周期性任務則將任務從優先佇列中移除,最后執行任務,如果時間還未到則呼叫 wait() 等待,
再看下圖,整理下流程,
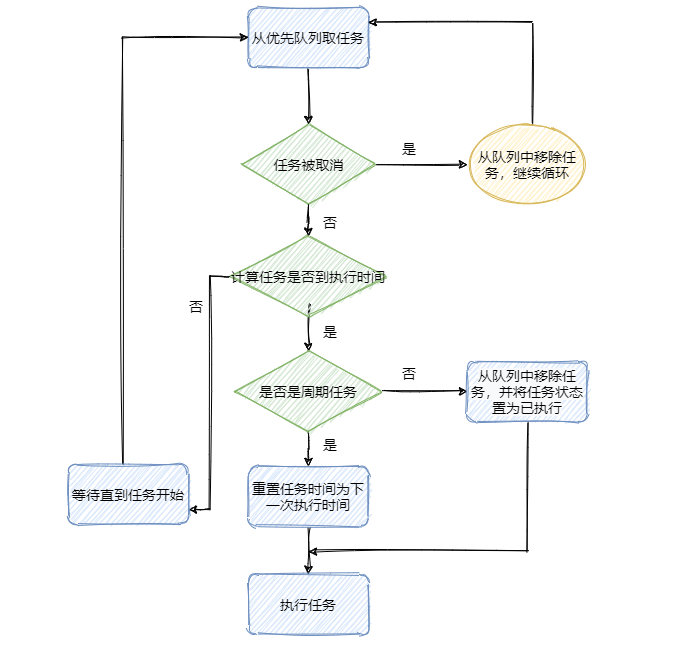
流程知道了再對著看下代碼,這塊就差不多了,看代碼不爽的可以跳過代碼部分,影響不大,
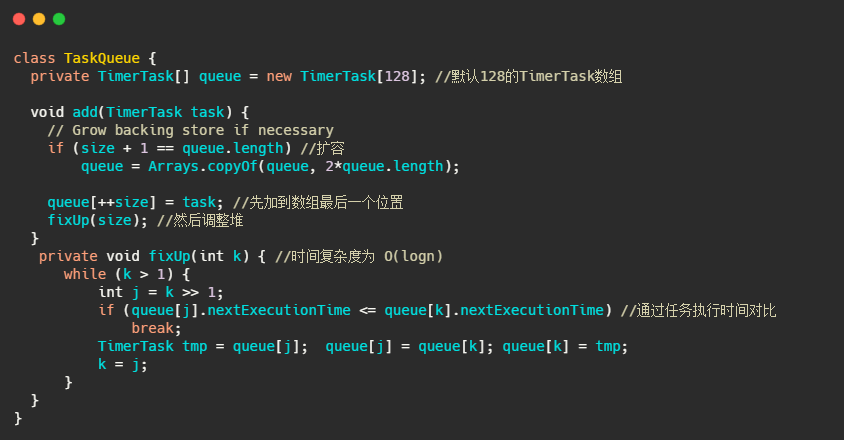
先來看下 TaskQueue,就簡單看下插入任務的程序,就是個普通的堆插入操作,
再來看看 TimerThread 的 run 操作,
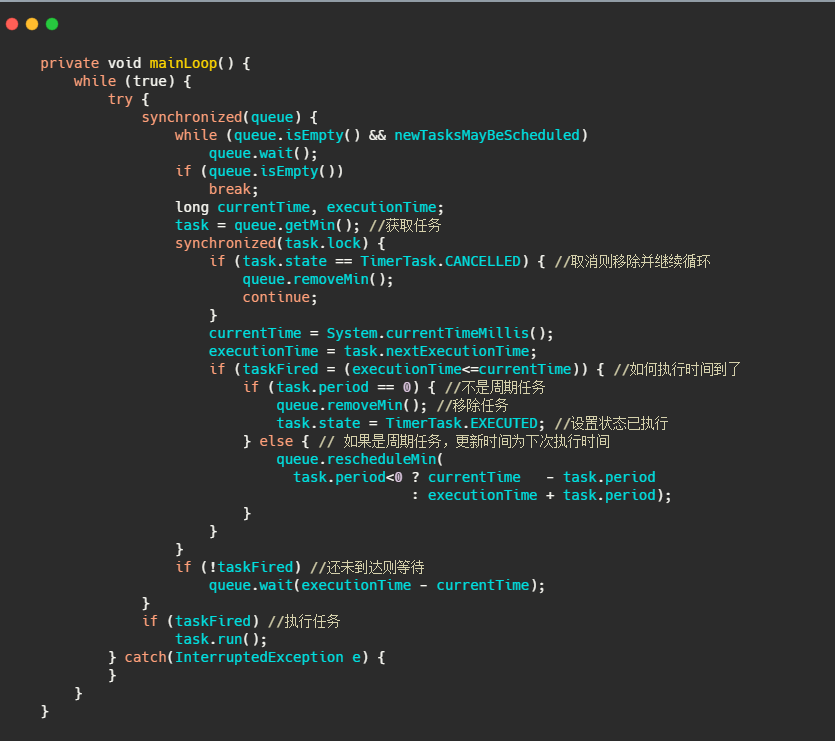
小結一下
可以看出 Timer 實際就是根據任務的執行時間維護了一個優先佇列,并且起了一個執行緒不斷地拉取任務執行,
有什么弊端呢?
首先優先佇列的插入和洗掉的時間復雜度是O(logn),當資料量大的時候,頻繁的入堆出堆性能有待考慮,
并且是單執行緒執行,那么如果一個任務執行的時間過久則會影響下一個任務的執行時間(當然你任務的run要是異步執行也行),
并且從代碼可以看到對例外沒有做什么處理,那么一個任務出錯的時候會導致之后的任務都無法執行,
ScheduledThreadPoolExecutor
在說 ScheduledThreadPoolExecutor 之前我們再看下 Timer 的注釋,注釋可都是干貨千萬不要錯過,我做了點修改,突出了下重點,
Java 5.0 introduced ScheduledThreadPoolExecutor, It is effectively a more versatile replacement for the Timer, it allows multiple service threads. Configuring with one thread makes it equivalent to Timer,
簡單翻譯下:1.5 引入了 ScheduledThreadPoolExecutor,它是一個具有更多功能的 Timer 的替代品,允許多個服務執行緒,如果設定一個服務執行緒和 Timer 沒啥差別,
從注釋看出相對于 Timer ,可能就是單執行緒跑任務和多執行緒跑任務的區別,我們來看下,
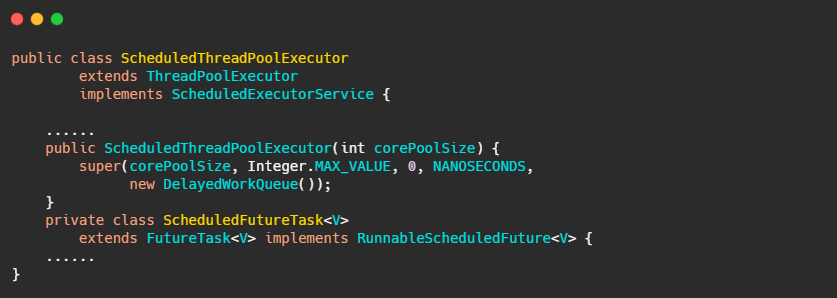
繼承了 ThreadPoolExecutor,實作了 ScheduledExecutorService,可以定性操作就是正常執行緒池差不多了,區別就在于兩點,一個是 ScheduledFutureTask ,一個是 DelayedWorkQueue,
其實 DelayedWorkQueue 就是優先佇列,也是利用陣列實作的小頂堆,而 ScheduledFutureTask 繼承自 FutureTask 重寫了 run 方法,實作了周期性任務的需求,
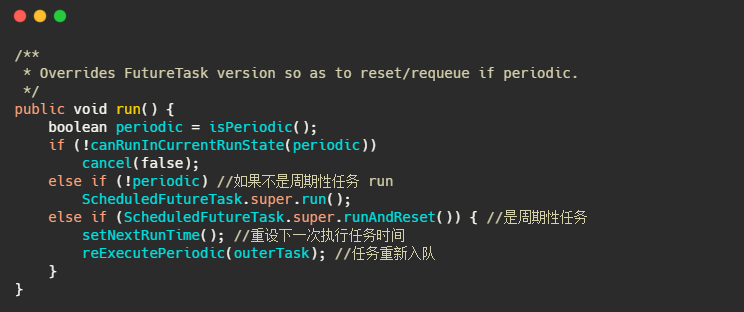
小結一下
ScheduledThreadPoolExecutor 大致的流程和 Timer 差不多,也是維護一個優先佇列,然后通過重寫 task 的 run 方法來實作周期性任務,主要差別在于能多執行緒運行任務,不會單執行緒阻塞,
并且 Java 執行緒池的設定是 task 出錯會把錯誤吃了,無聲無息的,因此一個任務出錯也不會影響之后的任務,
DelayQueue
Java 中還有個延遲佇列 DelayQueue,加入延遲佇列的元素都必須實作 Delayed 介面,延遲佇列內部是利用 PriorityQueue 實作的,所以還是利用優先佇列!Delayed 介面繼承了Comparable 因此優先佇列是通過 delay 來排序的,

然后我們再來看下延遲佇列是如何獲取元素的,
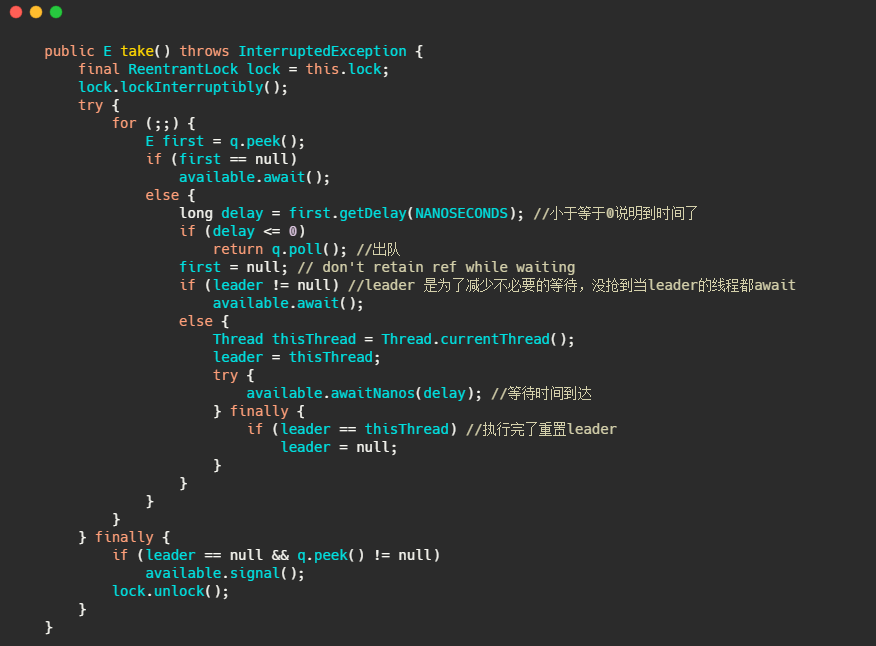
小結一下
也是利用優先佇列實作的,元素通過實作 Delayed 介面來回傳延遲的時間,不過延遲佇列就是個容器,需要其他執行緒來獲取和執行任務,
這下是搞明白了 Timer 、ScheduledThreadPool 和 DelayQueue,總結的說下它們都是通過優先佇列來獲取最早需要執行的任務,因此插入和洗掉任務的時間復雜度都為O(logn),并且 Timer 、ScheduledThreadPool 的周期性任務是通過重置任務的下一次執行時間來完成的,
問題就出在時間復雜度上,插入洗掉時間復雜度是O(logn),那么假設頻繁插入洗掉次數為 m,總的時間復雜度就是O(mlogn),這種時間復雜度滿足不了 Kafka 這類中間件對性能的要求,而時間輪演算法的插入洗掉時間復雜度是O(1),我們來看看時間輪演算法是如何實作的,
時間輪演算法
俗話說藝術源于生活,技術也能從日常生活中找到靈感,咱們先來看塊表,嗯金色的表,

都看清楚了吧,時間輪就是和手表時鐘很相似的存在,時間輪用環形陣列實作,陣列的每個元素可以稱為槽,和 HashMap一樣稱呼,
槽的內部用雙向鏈表存著待執行的任務,添加和洗掉的鏈表操作時間復雜度都是 O(1),槽位本身也指代時間精度,比如一秒掃一個槽,那么這個時間輪的最高精度就是 1 秒,
也就是說延遲 1.2 秒的任務和 1.5 秒的任務會被加入到同一個槽中,然后在 1 秒的時候遍歷這個槽中的鏈表執行任務,
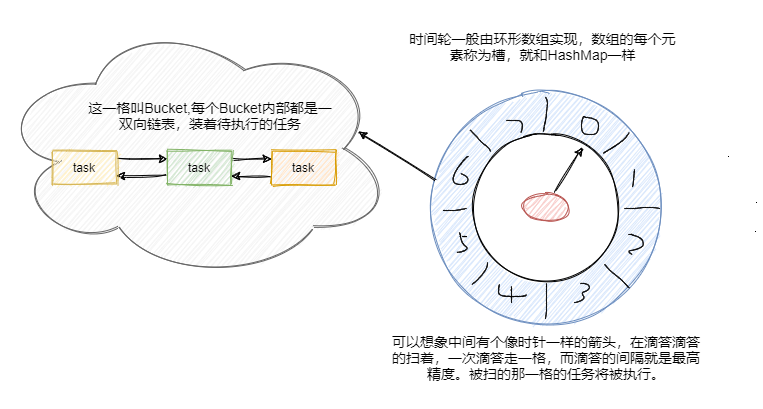
從圖中可以看到此時指標指向的是第一個槽,一共有八個槽0~7,假設槽的時間單位為 1 秒,現在要加入一個延時 5 秒的任務,計算方式就是 5 % 8 + 1 = 6,即放在槽位為 6,下標為 5 的那個槽中,更具體的就是拼到槽的雙向鏈表的尾部,
然后每秒指標順時針移動一格,這樣就掃到了下一格,遍歷這格中的雙向鏈表執行任務,然后再回圈繼續,
可以看到插入任務從計算槽位到插入鏈表,時間復雜度都是O(1),那假設現在要加入一個50秒后執行的任務怎么辦?這槽好像不夠啊?難道要加槽嘛?和HashMap一樣擴容?
不是的,常見有兩種方式,一種是通過增加輪次的概念,50 % 8 + 1 = 3,即應該放在槽位是 3,下標是 2 的位置,然后 (50 - 1) / 8 = 6,即輪數記為 6,也就是說當回圈 6 輪之后掃到下標的 2 的這個槽位會觸發這個任務,Netty 中的 HashedWheelTimer 使用的就是這種方式,
還有一種是通過多層次的時間輪,這個和我們的手表就更像了,像我們秒針走一圈,分針走一格,分針走一圈,時針走一格,
多層次時間輪就是這樣實作的,假設上圖就是第一層,那么第一層走了一圈,第二層就走一格,可以得知第二層的一格就是8秒,假設第二層也是 8 個槽,那么第二層走一圈,第三層走一格,可以得知第三層一格就是 64 秒,那么一格三層,每層8個槽,一共 24 個槽時間輪就可以處理最多延遲 512 秒的任務,
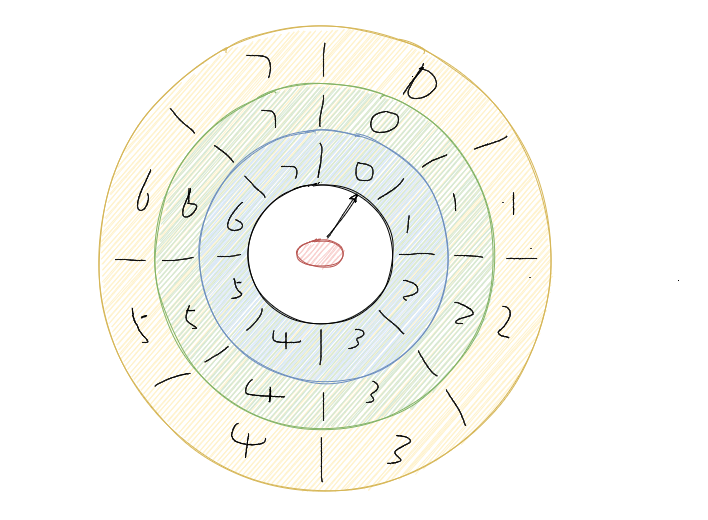
而多層次時間輪還會有降級的操作,假設一個任務延遲 500 秒執行,那么剛開始加進來肯定是放在第三層的,當時間過了 436 秒后,此時還需要 64 秒就會觸發任務的執行,而此時相對而言它就是個延遲 64 秒后的任務,因此它會被降低放在第二層中,第一層還放不下它,
再過個 56 秒,相對而言它就是個延遲 8 秒后執行的任務,因此它會再被降級放在第一層中,等待執行,
降級是為了保證時間精度一致性,Kafka內部用的就是多層次的時間輪演算法,
Netty中的時間輪
在 Netty 中時間輪的實作類是 HashedWheelTimer,代碼中的 wheel 就是上圖畫的回圈陣列,mask 的設計和HashMap一樣,通過限制陣列的大小為2的次方,利用位運算來替代取模運算,提高性能,tickDuration 就是每格的時間即精度,可以看到配備了一個作業執行緒來處理任務的執行,
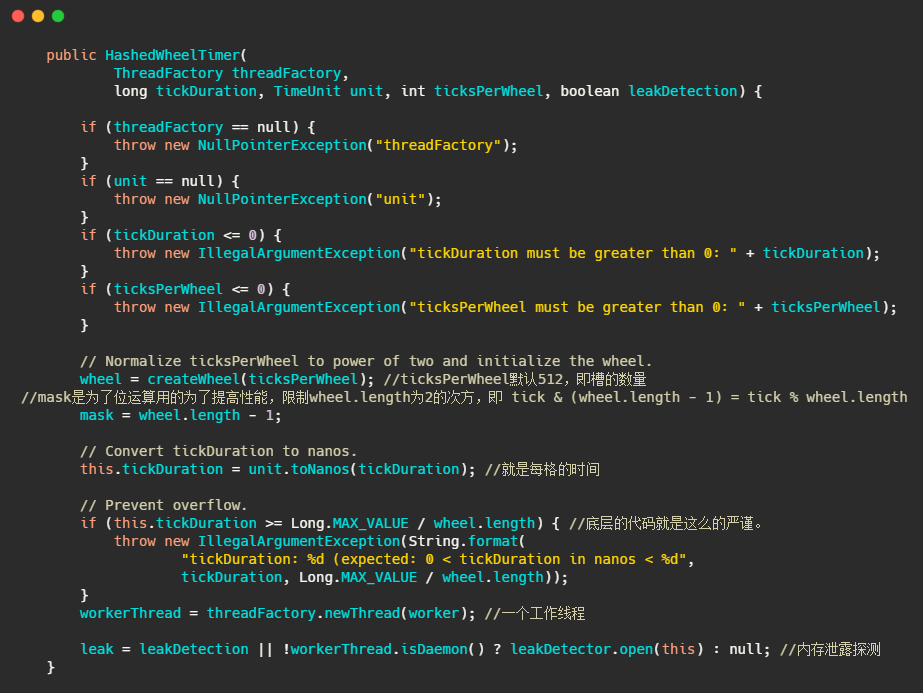
接下來我們再來看看任務是如何添加的,
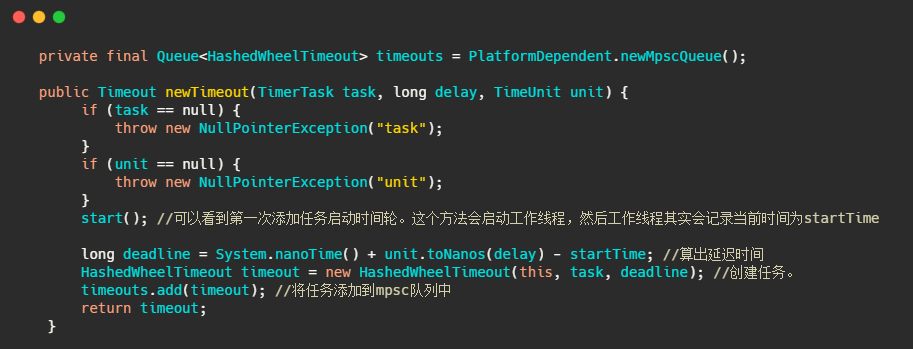
可以看到任務并沒有直接添加到時間輪中,而是先入了一個 mpsc 佇列,我簡單說下 mpsc 是 JCTools 中的并發佇列,用在多個生產者可同時訪問佇列,但只有一個消費者會訪問佇列的情況,篇幅有限,有興趣的朋友自行了解實作,
然后我們再來看看作業執行緒是如何運作的,

很直觀沒什么花頭,我們先來看看 waitForNextTick,是如何得到下一次執行時間的,
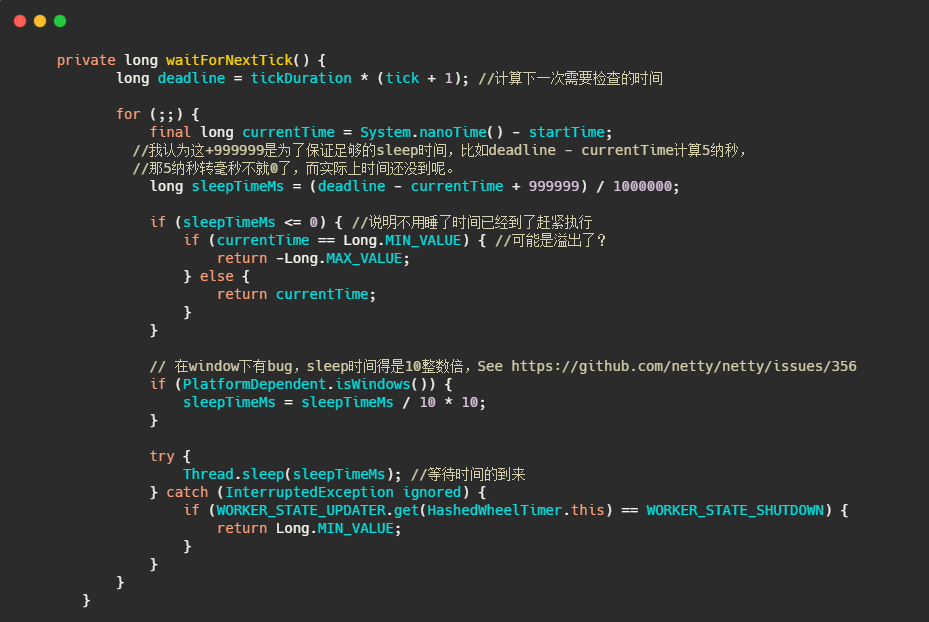
簡單的說就是通過 tickDuration 和此時已經滴答的次數算出下一次需要檢查的時間,時候未到就sleep等著,
再來看下任務如何入槽的,
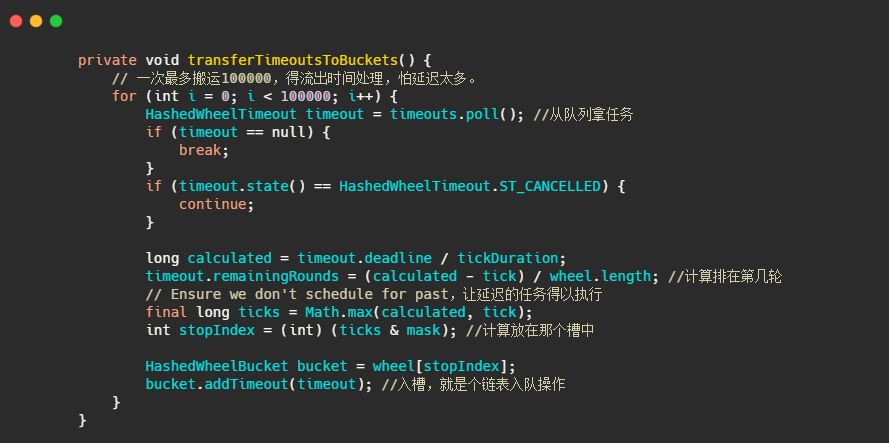
注釋的很清楚了,實作也和上述分析的一致,
最后再來看下如何執行的,
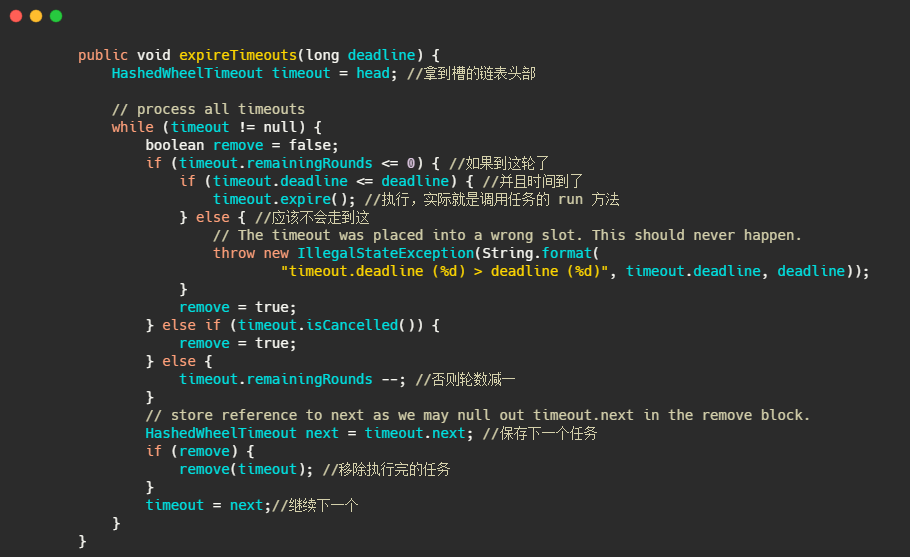
就是通過輪數和時間雙重判斷,執行完了移除任務,
小結一下
總體上看 Netty 的實作就是上文說的時間輪通過輪數的實作,完全一致,可以看出時間精度由 TickDuration 把控,并且作業執行緒的除了處理執行到時的任務還做了其他操作,因此任務不一定會被精準的執行,
而且任務的執行如果不是新起一個執行緒,或者將任務扔到執行緒池執行,那么耗時的任務會阻塞下個任務的執行,
并且會有很多無用的 tick 推進,例如 TickDuration 為1秒,此時就一個延遲350秒的任務,那就是有349次無用的操作,
但是從另一面來看,如果任務都執行很快(當然你也可以異步執行),并且任務數很多,通過分批執行,并且增刪任務的時間復雜度都是O(1)來說,時間輪還是比通過優先佇列實作的延時任務來的合適些,
Kafka 中的時間輪
上面我們說到 Kafka 中的時間輪是多層次時間輪實作,總的而言實作和上述說的思路一致,不過細節有些不同,并且做了點優化,
先看看添加任務的方法,在添加的時候就設定任務執行的絕對時間,

那么時間輪是如何推動的呢?Netty 中是通過固定的時間間隔掃描,時候未到就等待來進行時間輪的推動,上面我們分析到這樣會有空推進的情況,
而 Kafka 就利用了空間換時間的思想,通過 DelayQueue,來保存每個槽,通過每個槽的過期時間排序,這樣擁有最早需要執行任務的槽會有優先獲取,如果時候未到,那么 delayQueue.poll 就會阻塞著,這樣就不會有空推進的情況發送,
我們來看下推進的方法,

從上面的 add 方法我們知道每次對比都是根據expiration < currentTime + interval 來進行對比的,而advanceClock 就是用來推進更新 currentTime 的,
小結一下
Kafka 用了多層次時間輪來實作,并且是按需創建時間輪,采用任務的絕對時間來判斷延期,并且對于每個槽(槽記憶體放的也是任務的雙向鏈表)都會維護一個過期時間,利用 DelayQueue 來對每個槽的過期時間排序,來進行時間的推進,防止空推進的存在,
每次推進都會更新 currentTime 為當前時間戳,當然做了點微調使得 currentTime 是 tickMs 的整數倍,并且每次推進都會把能降級的任務重新插入降級,
可以看到這里的 DelayQueue 的元素是每個槽,而不是任務,因此數量就少很多了,這應該是權衡了對于槽操作的延時佇列的時間復雜度與空推進的影響,
總結
首先介紹了 Timer、DelayQueue 和 ScheduledThreadPool,它們都是基于優先佇列實作的,O(logn) 的時間復雜度在任務數多的情況下頻繁的入隊出隊對性能來說有損耗,因此適合于任務數不多的情況,
Timer 是單執行緒的會有阻塞的風險,并且對例外沒有做處理,一個任務出錯 Timer 就掛了,而 ScheduledThreadPool 相比于 Timer 首先可以多執行緒來執行任務,并且執行緒池對例外做了處理,使得任務之間不會有影響,
并且 Timer 和 ScheduledThreadPool 可以周期性執行任務, 而 DelayQueue 就是個具有優先級的阻塞佇列,
對比而言時間輪更適合任務數很大的延時場景,它的任務插入和洗掉時間復雜度都為O(1),對于延遲超過時間輪所能表示的范圍有兩種處理方式,一是通過增加一個欄位-輪數,Netty 就是這樣實作的,二是多層次時間輪,Kakfa 是這樣實作的,
相比而言 Netty 的實作會有空推進的問題,而 Kafka 采用 DelayQueue 以槽為單位,利用空間換時間的思想解決了空推進的問題,
可以看出延遲任務的實作都不是很精確的,并且或多或少都會有阻塞的情況,即使你異步執行,執行緒不夠的情況下還是會阻塞,
未完待續~
哈哈,0.1版本暫時就更新到這里啦~過段時間會再進行糾錯和補充,關注我不迷路!
這個系列一共近 7W 字+ 張圖,全部是我個人手打原創的,希望文章對你有所幫助,
如果覺得文章不錯的話,來個點贊評論收藏三連呀!
關于這篇文章也整理了 PDF,已上傳至 CSDN,還準備了暗黑版本,更加護眼!
點擊下載訊息佇列核心知識點PDF

我是yes,從一點點到億點點,我們下篇見!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/294525.html
標籤:其他