一般我們在使用 Redis 時,鑒于單機存在的單點故障,容量有限,高并發壓力問題,都不會采用單機模式,那么該如何設計 Redis 的部署方式來解決諸如單點故障,容量有限,高并發壓力這樣的問題呢?
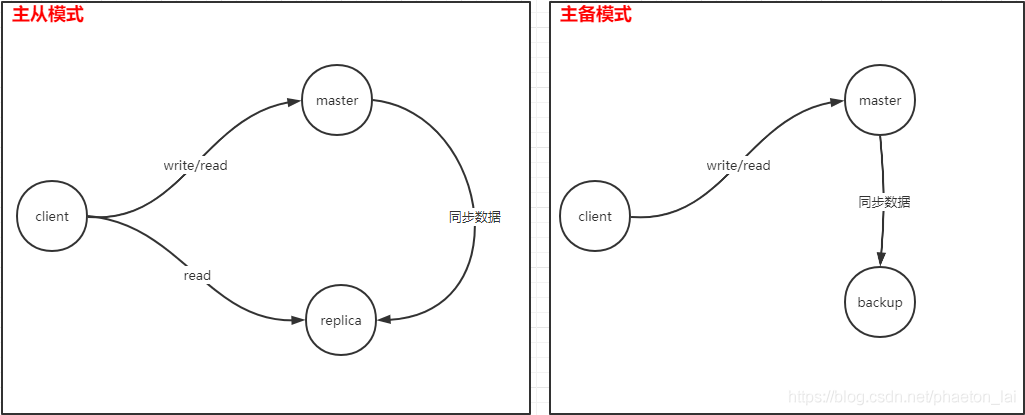
首先來看下單點故障的問題,單點故障一般就是指提供服務的節點或實體只有一個,當這個節點出現故障就導致這個服務不可用,解決這種問題一般會引入主備或主從的概念,主備模式就是主機向外提供服務,備機從主機同步資料,只有當主機出現故障時,備機才代替主機向外提供服務,主從模式下,從節點從主節點同步資料,同時也提供部分服務(對于主從模式的 Redis,從節點一般只提供讀服務 ),這兩種方案都可以很好的解決單點故障的問題,主從模式甚至還可以解決訪問壓力的問題,
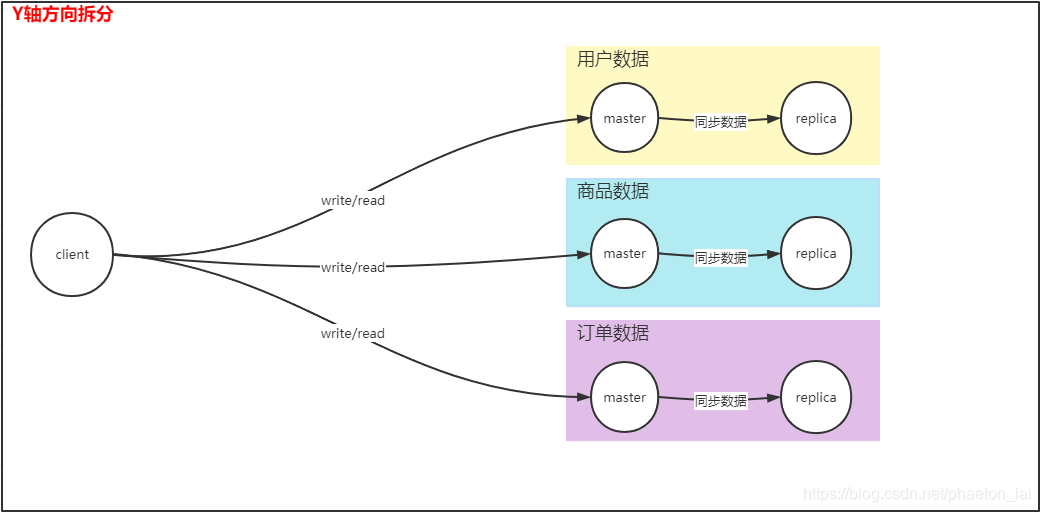
上面提到的方案,都沒有解決容量受限的問題,當系統的資料隨著業務的發展快速增長的時候,我們必須解決容量的問題,那么提升單機的記憶體容量是否可行呢?一般來說,我們不會采用這種方式,因為單機記憶體的提升畢竟有限,另外單節點資料量的提升,勢必會降低 Redis 的性能,既然這種方式并不是很好的方案,那只能一變多,單實體拆分成多實體了,到底該如何進行拆分呢?這里就要了解一下微服務的拆分原則之 AKF 原則,上面提到的主備或者主從其實就對應 AKF 拆分原則的 X 軸方向上的拆分,對 Redis 來說,X 軸方向的拆分只能解決單點故障和訪問壓力的問題,要解決容量有限的問題,必須進行 Y 軸及 Z 軸方向的拆分,先按照 Y 軸方向拆分,我們可以根據業務模塊對資料進行劃分,每個模塊的資料放在一個 Redis 實體中,客戶端可以根據要查詢的資料所屬的業務模塊進行路由查詢,
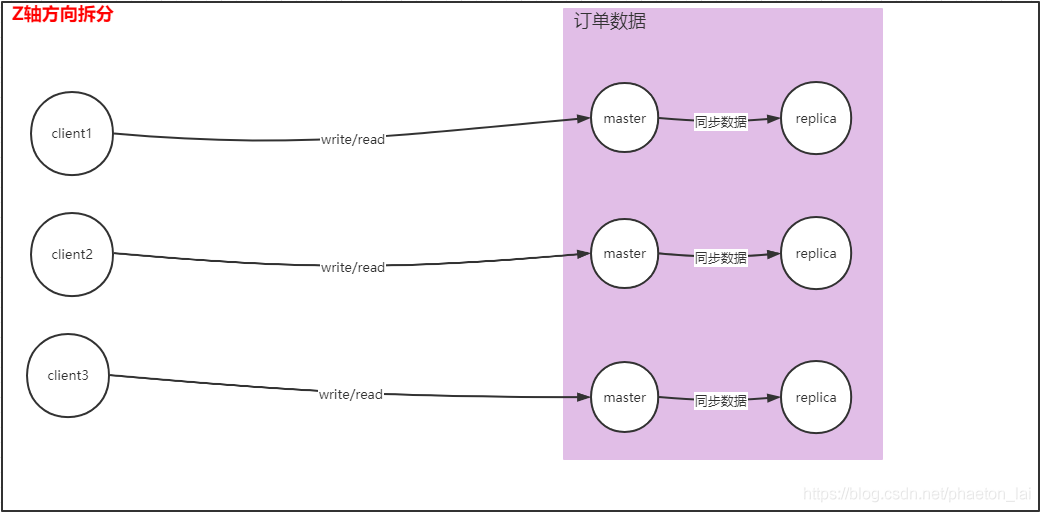
按照 Y 軸方向拆分還存在一個問題,如果某個業務模塊的資料隨著業務的發展而成比例或者指數級增長,存放這部分業務資料的實體也會出現容量受限的問題,這時我們就要進行 Z 軸方向的拆分,即資料分片,X,Y,Z 軸方向的拆分還可以進行隨意的組合來解決單機故障,容量及訪問壓力的問題,X 方向–資料鏡像解決單點故障;Y&Z 或者 Y/Z 方向–資料拆分解決訪問壓力及容量問題,
接下來我們重點聊一下 Redis 的資料分片(磁區),Redis 的資料磁區整體上可以分為兩種,一種范圍磁區,另一種散列磁區,范圍磁區,舉個例子,可以根據用戶的 id 所在區間,將用戶所關聯的資料分配到不同的 Redis 實體,比如用戶 id 在 0-9999 之間的用戶關聯的資料分配到 Redis 實體 1 上,用戶 id 在 10000-19999 之間的用戶所關聯的資料分配到實體 2 上,以此類推,這種磁區方案的維護成本比較高,需要專門的張表來維護映射關系,而且維護的成本隨著業務的復雜度成比例增加,散列磁區要比范圍磁區高效得多,它只需要對資料的 key 進行一次哈希運算,根據具體方案的不同進行不同的計算即可得到 key 應在的實體,常用的散列磁區方案一般有兩種:哈希取模和一致性哈希,
哈希取模就是將前面提到的哈希運算得到的數值,對 Redis 實體數取模,便得到資料應在的節點位置,比如一個 key 哈希運算后得到的值是 93024922,Redis 實體數為 4,那么這個 key 應在的節點位置為 93024922 % 4 = 2,即第三個節點上,了解了哈希取模的實作之后,我們可以發現,這種方案分布式下的擴展性不好,如果最初我們采用 5 個實體進行資料磁區,后面需要增加實體數,就需要將所有的資料進行重新磁區,在資料量大的情況下,這將是非常耗時的操作,這樣也同時破壞了可用性,
一致性哈希同樣是對 key 先進性哈希運算得到一個散列值 h0,同時對每個節點節點的唯一標識(如 ip)也采用相同的散列函式,得到哈希值 hx,將 h0 依次同每個節點得到的哈希值進行比較,得到哈希值大于 h0 的最小的節點位置,比如 h0 為 5,hx 的值依次為 1,3,6,8,10,最終這個 key 會被分配到 hx 為 6 的實體,一致性哈希是分布式應用常用的演算法,這里不做過多詳細介紹,在增加節點時,一致性哈希不需要將全部資料重新計算,磁區,增加節點只會影響到與新節點相鄰的下一個節點的資料分布,
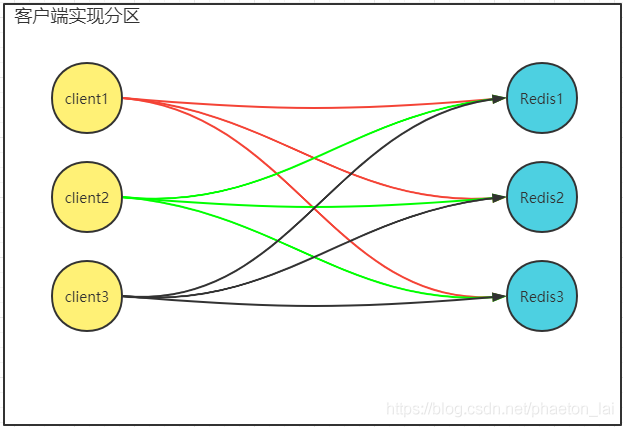
介紹完了資料磁區的方案之后,還有一個問題需要考慮:資料磁區的實作方式,一種比較原始的方式就是客戶端自己取實作磁區邏輯,即客戶端磁區,這種方式增加了客戶端代碼的復雜度,不過卻方便開發人員進行除錯與調優,通過下圖我們可以發現,每個客戶端都要與每個 Redis 實體至少建立一個連接,不管查詢的資料在那個實體,這樣當大量并發請求過來時,很容易導致服務端壓力過大而影響性能,
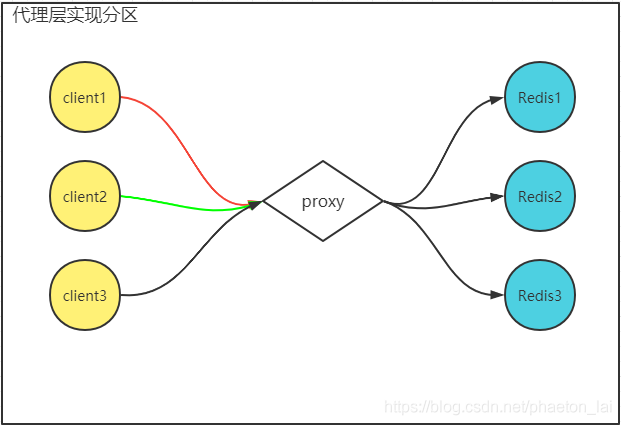
要解決客戶端磁區方式存在的問題,只需要在客戶端與服務端之間增加一個代理層,這種方式被稱為代理磁區,采用這種方式,后端服務層的架構對客戶端來說是透明的,客戶端只需要與代理層建立連接即可,分片的邏輯由代理層取實作,目前有較多開源的解決方案,比如推特的 twemproxy,國內開源的 predixy,豌豆莢的 codis,
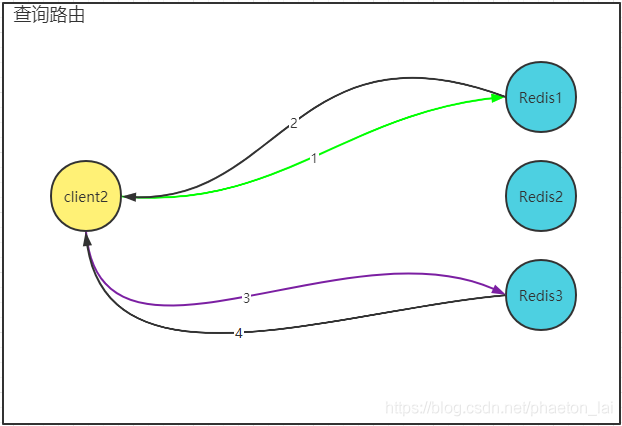
除了上面兩種磁區的方式,第三種是查詢路由方式,采用這種方式時,客戶端可以與集群中的任意一個節點建立連接并操作資料,如果要操作的資料碰巧就在這個節點上,直接處理并回傳即可,如果不在這個節點,則將此資料所在的節點資訊回傳客戶端,客戶端重定向到目標節點進行資料操作(如下圖),這便是 Redis-Cluster 的作業方式,Redis-Cluster 采用預磁區的方式降低了資料遷移的成本,Redis-Cluster 將資料提前分到 16384 個槽位中,資料對應的槽位是固定的,每個節點管理的槽位可以進行動態分配,這樣很方便的實作了在線擴縮容,
由于哈希取模和一致性哈希的方案在擴縮容時,存在資料丟失或者資料遷移的成本較高,一般我們只有在使用 Redis 作為快取時才采用,增加節點時不進行資料遷移,出現擊穿時從資料庫查詢一下再寫入快取即可,對于應該遷移走的資料,可以采用淘汰策略進行冷資料的淘汰,在使用 Redis 作為資料庫時,一般只能選擇 Redis-Cluster 作為磁區方式,這樣可以保證運行時的資料再平衡,
參考資料:磁區:怎樣將資料分布到多個redis實體
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/294668.html
標籤:其他
下一篇:gRPC-go原始碼剖析五十一之場景三:在同一條鏈路上,發起多次rpc呼叫時,為什么第二次之后的頭幀位元組數非常小呢?