目錄
- 前言
- Encoder-Decoder框架
- Attention怎么來的
- 為什么需要Attention
- Attention的機制原理
- Soft Attention
- Soft Attention的計算程序
- Attention的本質思想
- Self Attention
- Scaled Dot-Product Attention
- Self Attention計算程序
- Soft Attention和Self Attention的區別
- Attention的分類
- Attention模型的優缺點
- 總結
- 展望
- 參考
前言
最近兩年,注意力模型(Attention Model)被廣泛使用在自然語言處理(Natural Language Processing, NLP)、影像識別及語音識別等各種不同型別的深度學習任務中,是深度學習技術中最值得關注與深入了解的核心技術之一,甚至于是傳統的時序資料的預測,都很容易遇到注意力模型的身影,
在NLP領域,BERT(Bidirectional Encoder Representations from Transformers)近期提出之后,作為一個Word2Vec的替代者,其在NLP領域的11個方向大幅重繪了精度,在許多方向甚至都達到了SOTA(state of the art),可以說是近年來自殘差網路(ResNet)最有突破性的一項技術了,在NLP中達到了全新的高度,將已經走向瓶頸期的Word2Vec帶向了一個新的方向,并再一次炒火了《Attention is All you Need》這篇論文(強烈建議大家精讀此文章),而BERT所采用的就是在各領域所霸榜的Transformer,
而Transformer所采用的主要演算法模型即Attention(multi-headed self-attention、masked multi-headed self-attention以及Encoder-Decoder Attention),所以,了解注意力機制的作業原理至關重要,
由于個人接下來的實驗也要用到Attention機制,好記性不如爛筆頭,為了加深印象,也為了分享給大家我的理解和看法,我將把我的理解、心得做個記錄,接下來我還要繼續分享Transformer(主要是對《Attention is All you Need》的深度決議)、BERT以及Word2Vec模型的原理、機制,希望大家多多關注哈,感謝感謝🙏🙏!
ps:盡管我在知乎、簡書、博客園、知乎等收藏了很多博文、專欄,也寫過一些文章,做過很多筆記,但都沒發布過,這是我真正意義上第一次發布文章,如果哪里寫的不好,歡迎大家批評指正!
pps:本人的個人主頁匯總了很多關于機器學習、深度學習、強化學習、自然語言處理、Tensorflow、Java、Python的使用、本人的一些專案開發、部署經驗以及服務器的使用(自己基本都親身嘗試過)等等的一些收藏博文,大家可以自行查看,
ppps:本人目前在攻讀碩士學位,主要研究方向是智慧水務、強化學習、自動控制、數字孿生、智能系統以及預測性維護方面,因此我并不是研究方向為NLP的學生,但我本人對NLP特別感興趣,希望博士期間我可以找到一個主要研究方向為NLP的博導吧😊(任重而道遠啊)
廢話不多說,開講!
提示:上面全是廢話,以下才是本篇文章正文內容
Encoder-Decoder框架
要了解深度學習中的注意力模型,就不得不先談Encoder-Decoder框架,因為目前大多數注意力模型附著在Encoder-Decoder框架下,當然,其實注意力模型可以看作一種通用的思想,本身并不依賴于任何特定框架,這點需要注意,
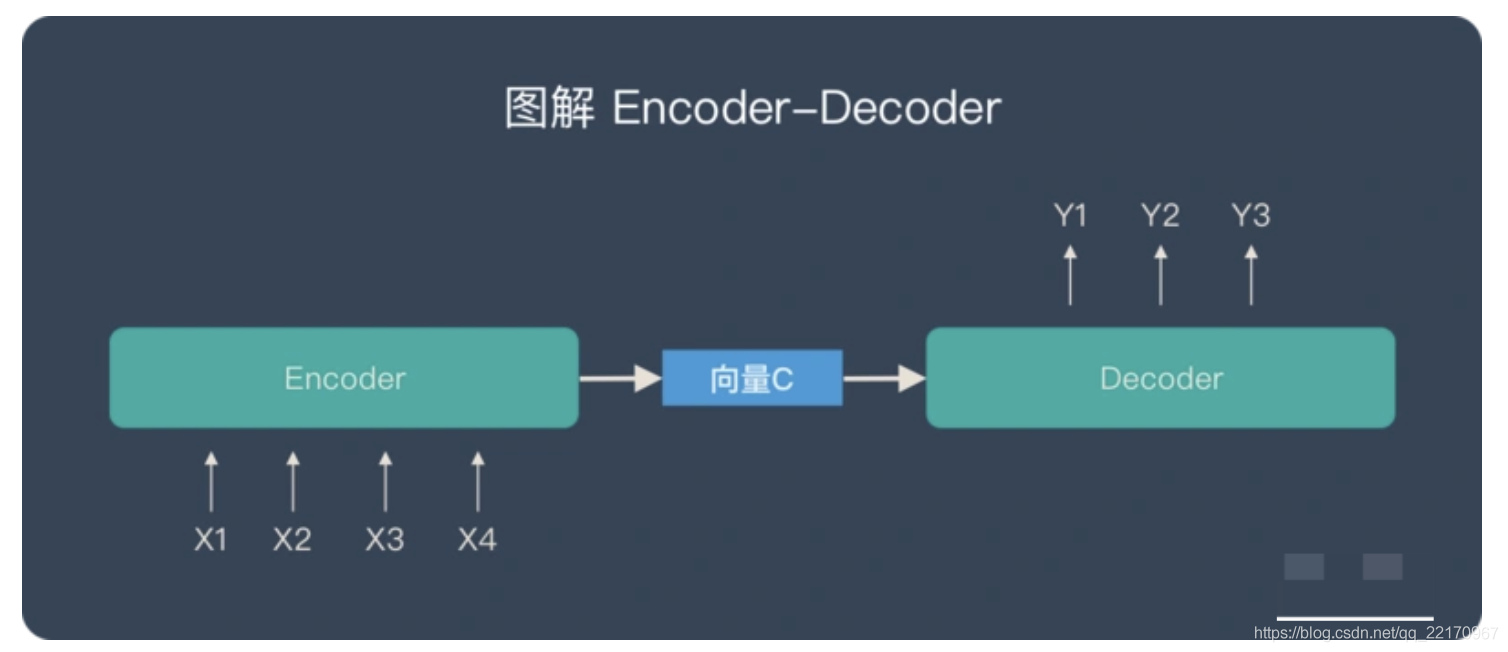
關于 Encoder-Decoder,有2 點需要說明:
-
不論輸入和輸出的長度是什么,中間的「向量 c」 長度都是固定的(這也是它的缺陷)
-
根據不同的任務可以選擇不同的編碼器和解碼器(可以是一個 RNN ,但通常是其變種 LSTM 或者 GRU )
只要是符合上面的框架,都可以統稱為 Encoder-Decoder 模型,說到 Encoder-Decoder 模型就經常提到一個名詞—— Seq2Seq,
Seq2Seq( Sequence-to-sequence),就如字面意思,輸入一個序列,輸出另一個序列,這種結構最重要的地方在于輸入序列和輸出序列的長度是可變的,例如下圖:
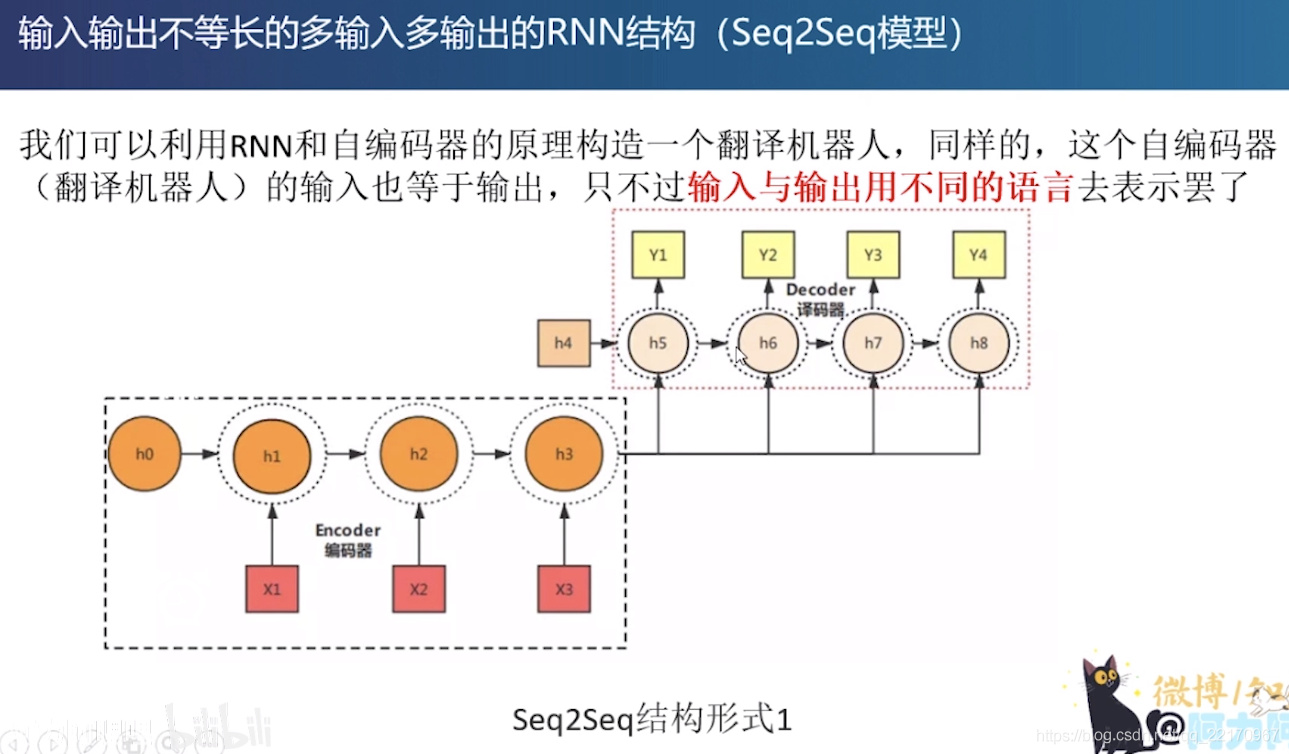
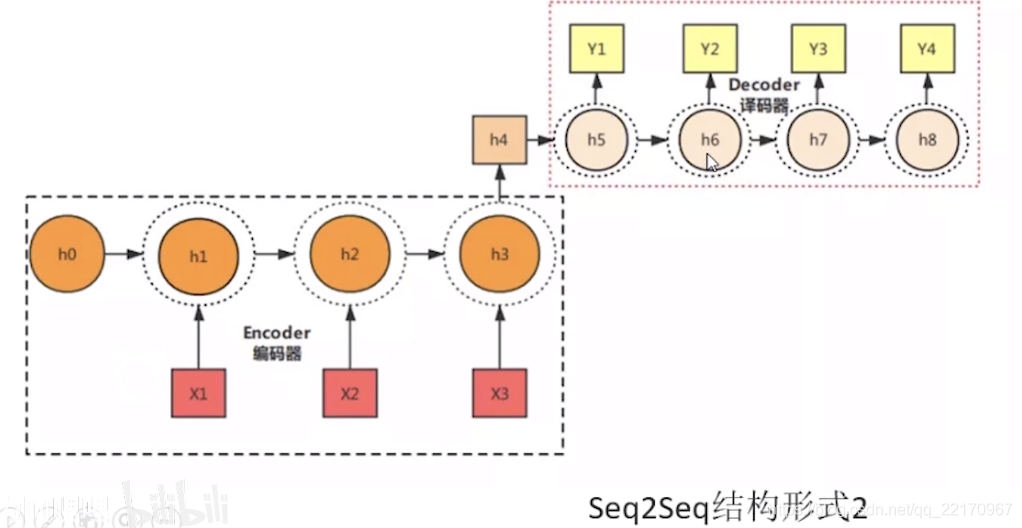
Seq2Seq和Encoder-Decoder的關系
- Seq2Seq(強調目的)不特指具體方法,滿足「輸入序列、輸出序列」的目的,都可以統稱為 Seq2Seq 模型,
- Seq2Seq 使用的具體方法基本都屬于Encoder-Decoder 模型(強調方法)的范疇,
總結一下:
- Seq2Seq 屬于 Encoder-Decoder 的大范疇
- Seq2Seq 更強調目的,Encoder-Decoder 更強調方法
看起來Encoder-Decoder就是根據輸入句子Source生成了目標句子Target,比如:
-
如果Source是中文句子,Target是英文句子,那么這就是解決機器翻譯問題的Encoder-Decoder框架;
-
如果Source是一篇文章,Target是概括性的幾句描述陳述句,那么這是文本摘要的Encoder-Decoder框架;
-
如果Source是一句問句,Target是一句回答,那么這是問答系統或者對話機器人的Encoder-Decoder框架,
由此可見,在文本處理領域,Encoder-Decoder的應用領域相當廣泛,
Encoder-Decoder框架不僅僅在文本領域廣泛使用,在語音識別、影像處理等領域也經常使用,比如對于語音識別來說,該框架完全適用,區別無非是Encoder部分的輸入是語音流,輸出是對應的文本資訊;而對于“影像描述”任務來說,Encoder部分的輸入是一副圖片,Decoder的輸出是能夠描述圖片語意內容的一句描述語,
一般而言,文本處理和語音識別的Encoder部分通常采用RNN模型,影像處理的Encoder一般采用CNN模型,
Attention怎么來的
從注意力模型的命名方式看,很明顯,該模型借鑒了人類的注意力機制,
視覺注意力機制是人類視覺所特有的大腦信號處理機制,人類視覺通過快速掃描全域影像,獲得需要重點關注的目標區域,也就是一般所說的注意力焦點,而后對這一區域投入更多注意力資源,以獲取更多所需要關注目標的細節資訊,而抑制其他無用資訊,
這是人類利用有限的注意力資源從大量資訊中快速篩選出高價值資訊的手段,是人類在長期進化中形成的一種生存機制,人類視覺注意力機制極大地提高了視覺資訊處理的效率與準確性,
為什么需要Attention
前饋網路和回圈網路都有很強的能力,但為什么還要引入注意力機制呢?
上文提到:Encoder(編碼器)和 Decoder(解碼器)之間只有一個「向量 c」來傳遞資訊,且 c 的長度固定,因此Encoder-Decoder 存在一個問題:當輸入資訊太長時,會丟失掉一些資訊,
-
計算能力的限制:當要記住很多“資訊“,模型就要變得更復雜,然而目前計算能力依然是限制神經網路發展的瓶頸,
-
優化演算法的限制:雖然區域連接、權重共享以及pooling等優化操作可以讓神經網路變得簡單一些,有效緩解模型復雜度和表達能力之間的矛盾;但是,如回圈神經網路中的長距離以來問題,資訊“記憶”能力并不高,
可以借助人腦處理資訊過載的方式,例如Attention機制可以提高神經網路處理資訊的能力,
Attention 機制就是為了解決“資訊過長,資訊丟失”的問題,
Attention模型的特點是 Eecoder 不再將整個輸入序列編碼為固定長度的「中間向量 C」,而是編碼成一個向量的序列,目標句子中的每個單詞都應該學會其對應的源陳述句子中單詞的注意力分配概率資訊,這意味著在生成每個單詞的時候,原先都是相同的中間語意表示C會被替換成根據當前生成單詞而不斷變化的 C i C_{i} Ci?,
理解Attention模型的關鍵就是這里,即由固定的中間語意表示C換成了根據當前輸出單詞并調整成加入注意力模型的變化的 C i C_{i} Ci?,增加了注意力模型的Encoder-Decoder框架理解起來如下圖所示:
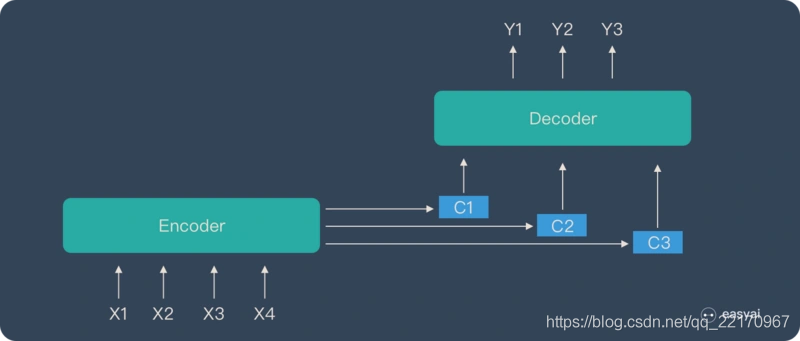
這樣,在產生每一個輸出的時候,都能夠做到充分利用輸入序列攜帶的資訊,而且這種方法在翻譯任務中取得了非常不錯的成果,并已延伸到很多非NLP領域的任務當中,
Attention的思想如同它的名字一樣,就是“注意力”,在預測結果時把注意力放在不同的特征上,
舉個例子,比如在預測“我媽今天做的這頓飯真好吃”的情感時,如果只預測正向還是負向,那真正影響結果的只有“真好吃”這三個字,前面說的“我媽今天做的這頓飯”基本沒什么用,如果是直接對token embedding進行平均去求句子表示,會引入不少噪聲,所以引入attention機制,讓我們可以根據任務目標賦予輸入token不同的權重,理想情況下前半句的權重相應的降低,后三個字的權重則會提高,比如是“0.3, 0.3, 0.3”,那么在計算句子表示時就變成了:
最終表示 C i C_{i} Ci?= 0.01x我+0.01x媽+0.01x今+0.01x天+0.01x做+0.01x的+0.01x這+0.01x頓+0.02x飯+0.3x真+0.3x好+0.3x吃
并且所有的權重之和必須為1,這就不得不提到老生常談的softmax函式了,
現在我們已經大概知道Attention是什么東東了,怎么用也大概清楚了,那么問題來了,這個權重具體應該怎么計算呢?
Attention的機制原理
本節先以機器翻譯作為例子講解目前最常見的Soft Attention模型的基本原理,之后拋離Encoder-Decoder框架抽象出了注意力機制的本質思想,然后介紹一下Transformer所采用也是最近廣為使用的Self Attention的基本思路,
這是本文的最最最重點的內容了,廢話不多說,開始!
Soft Attention
先看幾張圖,圖片來自吳恩達所講授的線上deeplearning.ai,視頻鏈接:179 & 180
(推薦大家看一下吳恩達教授的機器學習以及深度學習課程,講的很不錯,B站均有資源,建議觀看順序:ML–CS229–DL–CS230),
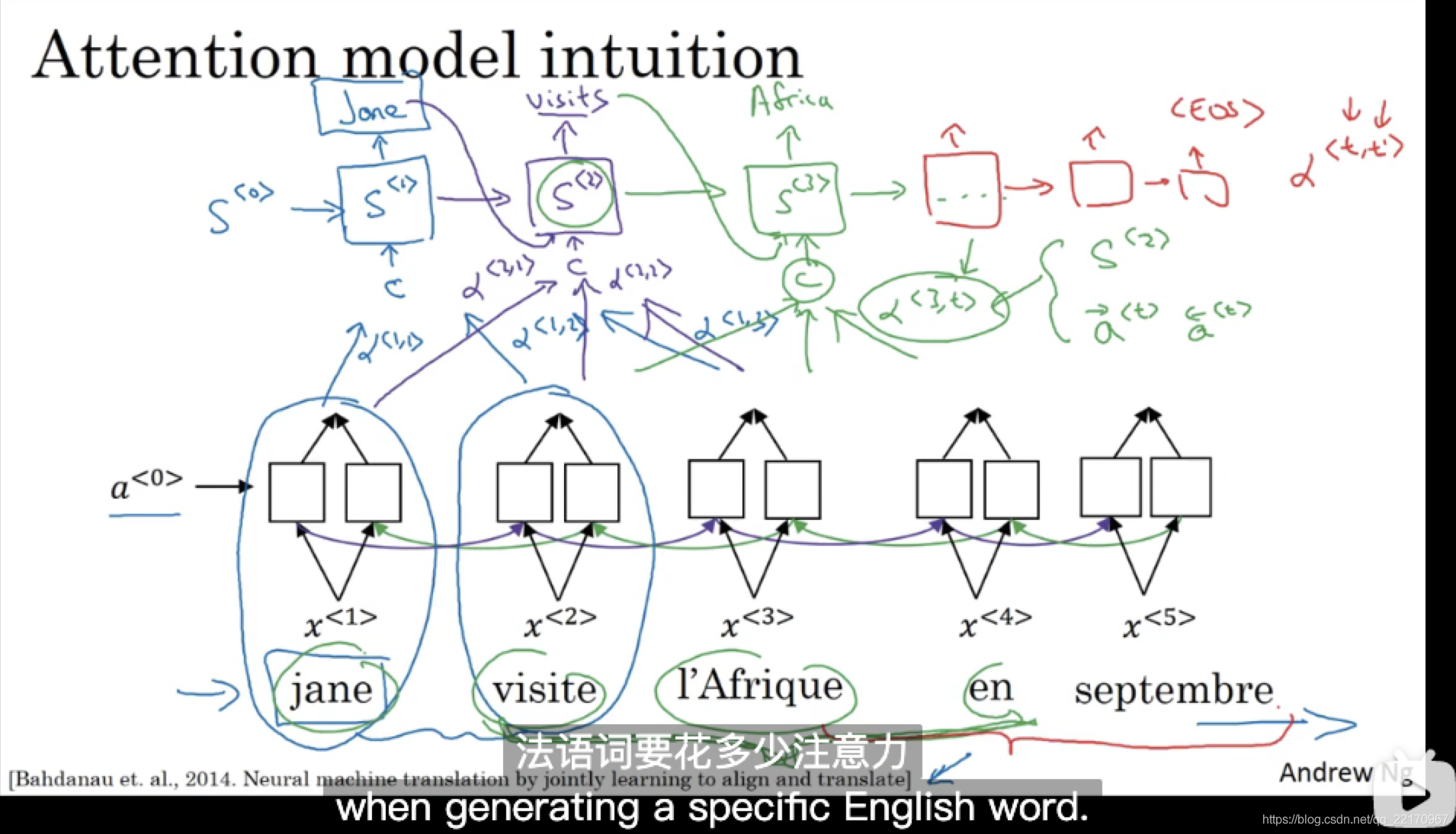
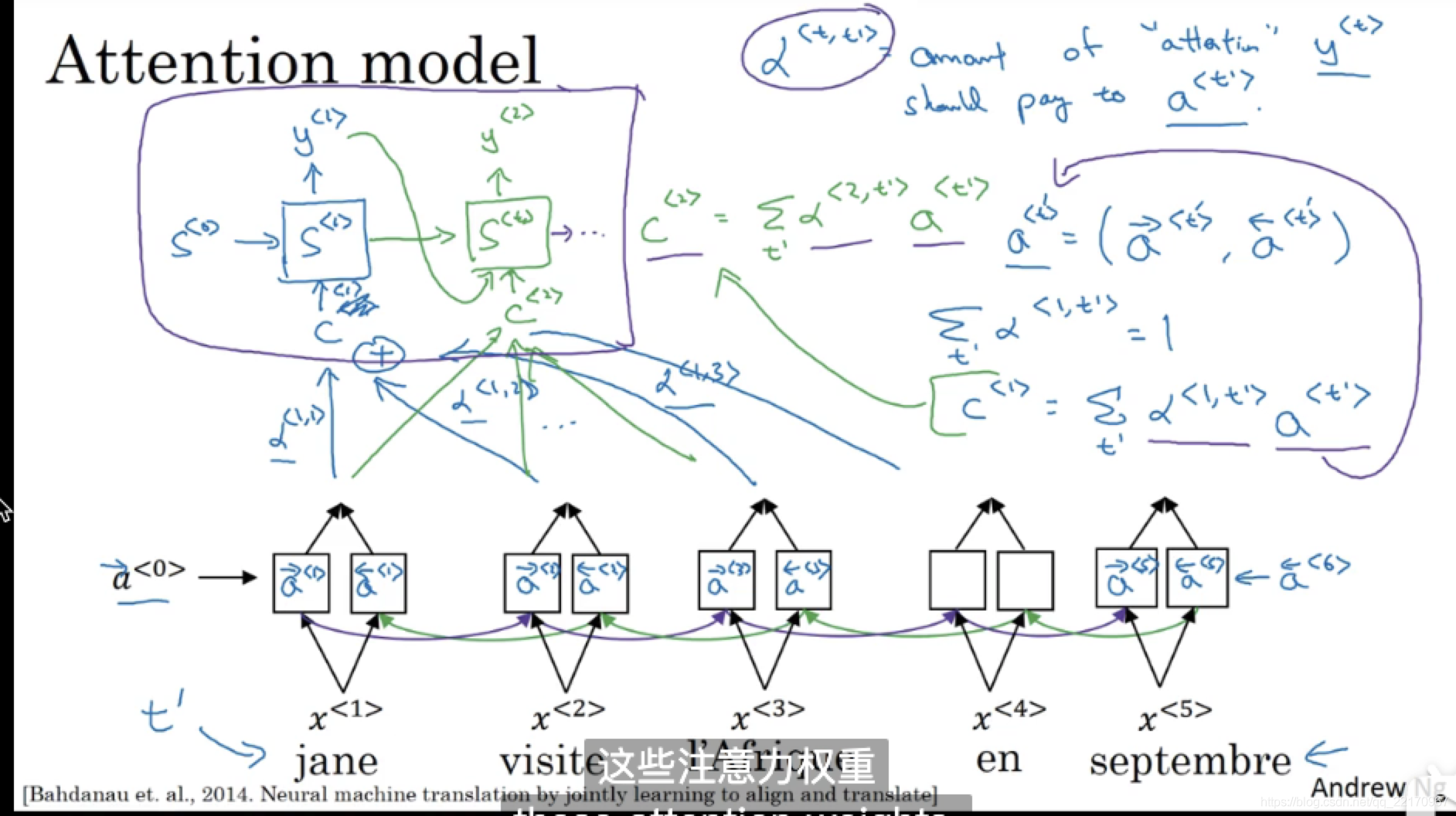
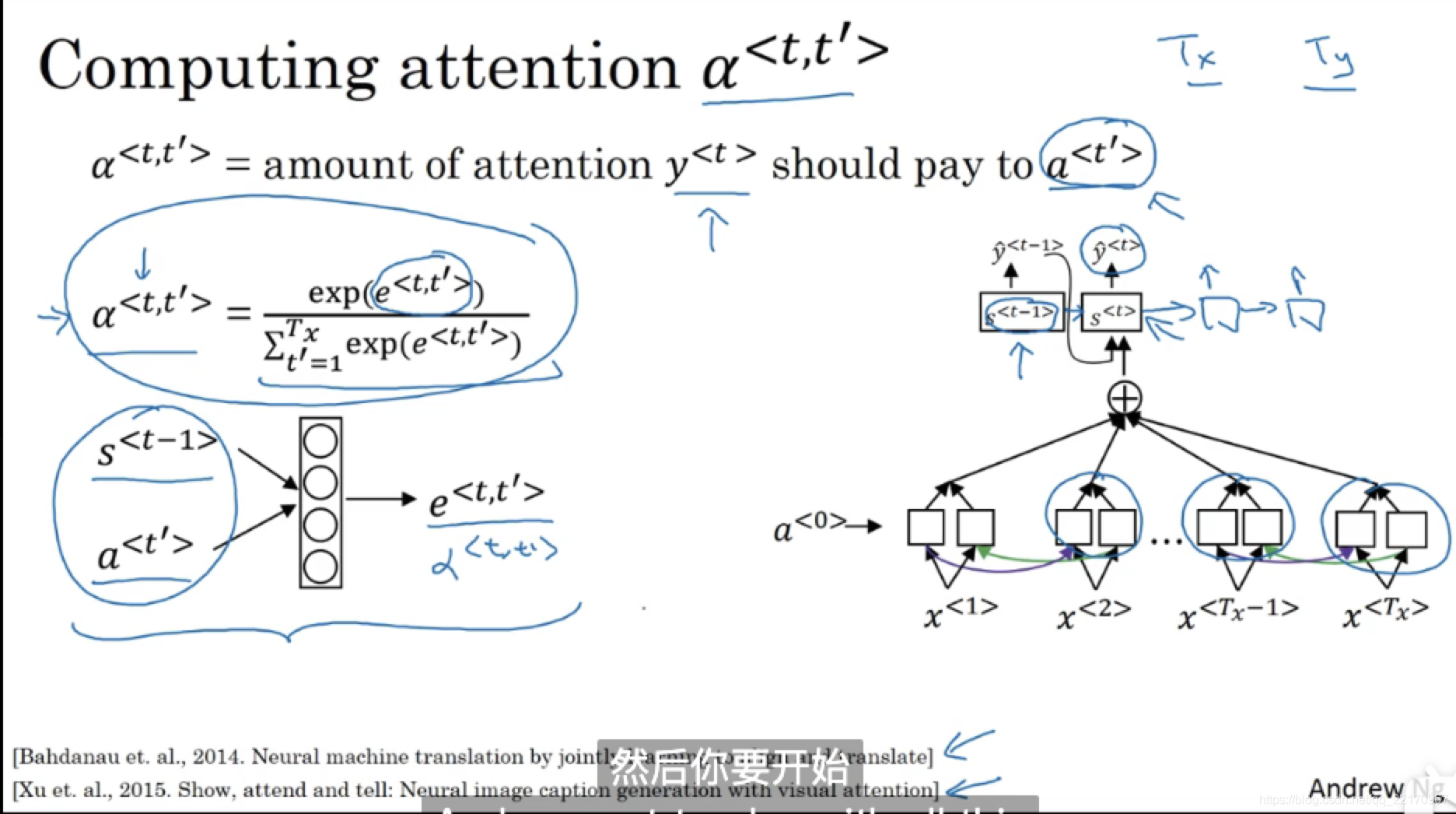
不得不說,吳教授的筆記就是這么不拘一格但又一目了然,下面我用一張圖大概描述一下上面的程序,
Soft Attention的計算程序
比如將機器翻譯中的“機器學習”變成"machine learning",計算程序如圖所示:
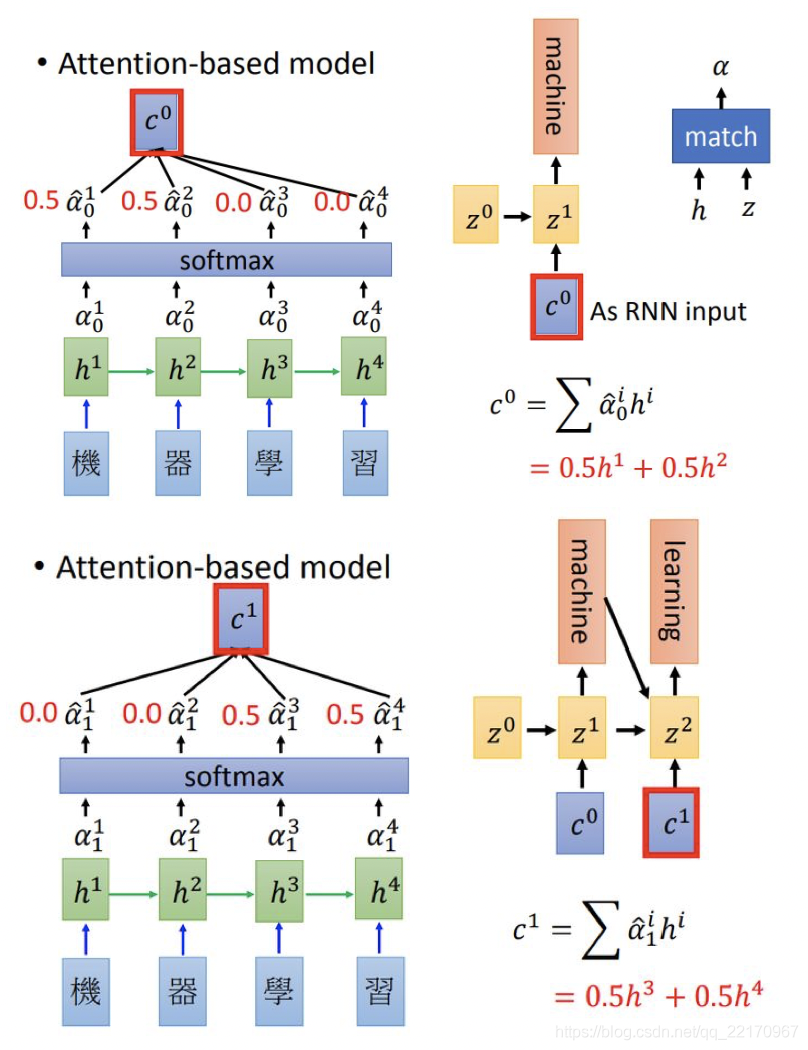
其中
h
i
h^{i}
hi是編碼器每個step的輸出,
z
i
z^{i}
zi是解碼器每個step的輸出,計算步驟是這樣的:
Encoder:通過Word Embedding方式(如Word2vec,glove等)將漢字轉化成詞向量,然后通過模型訓練,得到 [ h 1 h^{1} h1, h 2 h^{2} h2, h 3 h^{3} h3, h 4 h^{4} h4],此處一般采用RNN模型,LSTM/GRU居多,
Decoder:開始解碼了,先用固定的start token也就是 z 0 z^{0} z0和每個 h i h^{i} hi計算(在不同論文里可能會采取不同的方法進行計算,一般采用神經網路即可),然后通過softmax函式,得到加權的 c 0 c^{0} c0, z 0 z^{0} z0可以隨機初始化,不過一般采用的是Encoder的最后一個輸出,
用 c 0 c^{0} c0作為解碼的RNN輸入(同時還有上一步的 z 0 z^{0} z0),得到 z 1 z^{1} z1 并預測出第一個詞是machine,
再繼續預測的話,就是用
z
1
z^{1}
z1 去求attention,需要注意的是,上一個Decoder輸出
y
i
?
1
y_{i-1}
yi?1?也會當成輸入之一,即:
z
i
=
f
(
y
i
?
1
,
c
i
?
1
,
z
i
?
1
)
y
i
=
g
(
z
i
)
z^{i} = f(y_{i-1},c^{i-1},z^{i-1})\\ y_{i} = g(z^{i})
zi=f(yi?1?,ci?1,zi?1)yi?=g(zi)
注意:索引
i
i
i從0開始
絕大多數Soft Attention模型都是采取上述的計算框架來計算注意力分配概率分布資訊,區別只是在Attention的定義及計算方式上可能有所不同而已,
上述內容就是經典的Soft Attention模型的基本思想,那么怎么理解Attention模型的物理含義呢?一般在自然語言處理應用里會把Attention模型看作是輸出Target句子中某個單詞和輸入Source句子每個單詞的對齊模型,這是非常有道理的,
目標句子生成的每個單詞對應輸入句子單詞的概率分布可以理解為輸入句子單詞和這個目標生成單詞的對齊概率,這在機器翻譯語境下是非常直觀的:傳統的統計機器翻譯一般在做的程序中會專門有一個短語對齊的步驟,而注意力模型其實起的是相同的作用,
Attention的本質思想
如果把Attention機制從上文講述例子中的Encoder-Decoder框架中剝離,并進一步做抽象,可以更容易看懂Attention機制的本質思想,
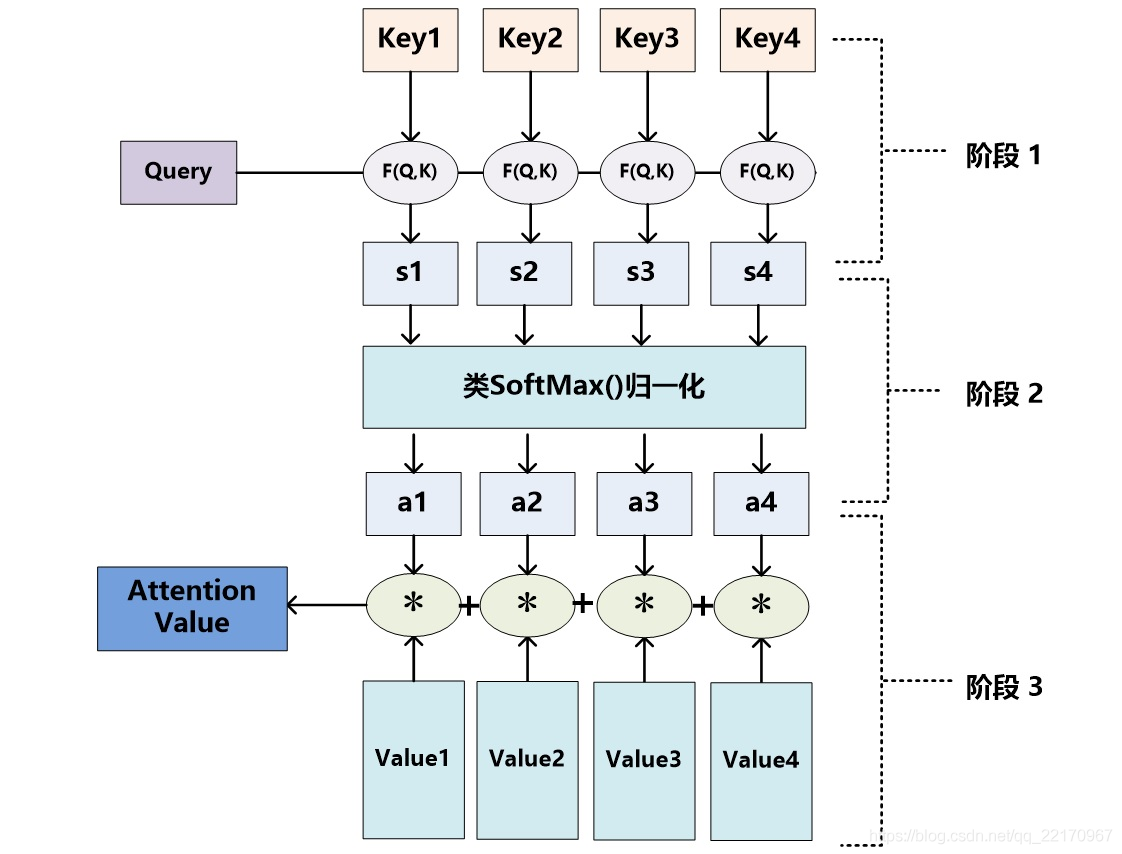
我們可以這樣來看待Attention機制:將Source中的構成元素想象成是由一系列的<Key,Value>資料對構成,此時給定Target中的某個元素Query,通過計算Query和各個Key的相似性或者相關性,再利用softmax函式,得到每個Key對應Value的權重系數,然后對Value進行加權求和,即得到了最終的Attention數值,所以本質上Attention機制是對Source中元素的Value值進行加權求和,而Query和Key用來計算對應Value的權重系數,即:
A
t
t
e
n
t
i
o
n
v
a
l
u
e
=
∑
s
o
f
t
m
a
x
(
F
(
Q
u
e
r
y
,
K
e
y
i
)
?
V
a
l
u
e
i
)
Attention \ value=\sum{softmax (F(Query,Key_{i})*Value_{i})}
Attention value=∑softmax(F(Query,Keyi?)?Valuei?)
上文所舉的機器翻譯的例子里,因為在計算Attention的程序中,Source中的Key和Value合二為一,指向的是同一個東西,也即輸入句子中每個單詞對應的語意編碼,F則為MLP,
Self Attention
傳統的Attention是計算Q和K之間的依賴關系以及相關性,而self attention則是分別計算Q和K自身的依賴關系,
了解了模型大致原理,我們可以詳細的看一下究竟Self-Attention結構是怎樣的,
Scaled Dot-Product Attention
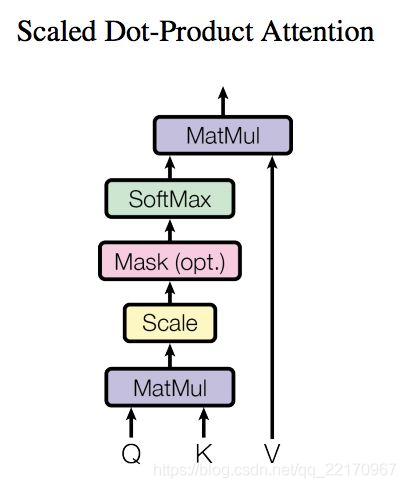

上述attention可以被描述為將query和key-value鍵值對的一組集合映到輸出,其中 query,keys,values和輸出都是向量,輸出被計算為values的加權和,其中分配給每個value的權重由query與對應key的相似性函式計算得來,這種attention的形式被稱為“Scaled Dot-Product Attention”,
Self Attention計算程序
上面說的可能比較抽象,我們來看一個具體的例子(圖片來源于https://jalammar.github.io/illustrated-transformer/,該博客講解的極其清晰,強烈推薦),
假如我們要翻譯一個詞組Thinking Machines,其中Thinking的輸入的embedding vector用 x 1 x_{1} x1?表示,Machines的embedding vector用 x 2 x_{2} x2?表示,
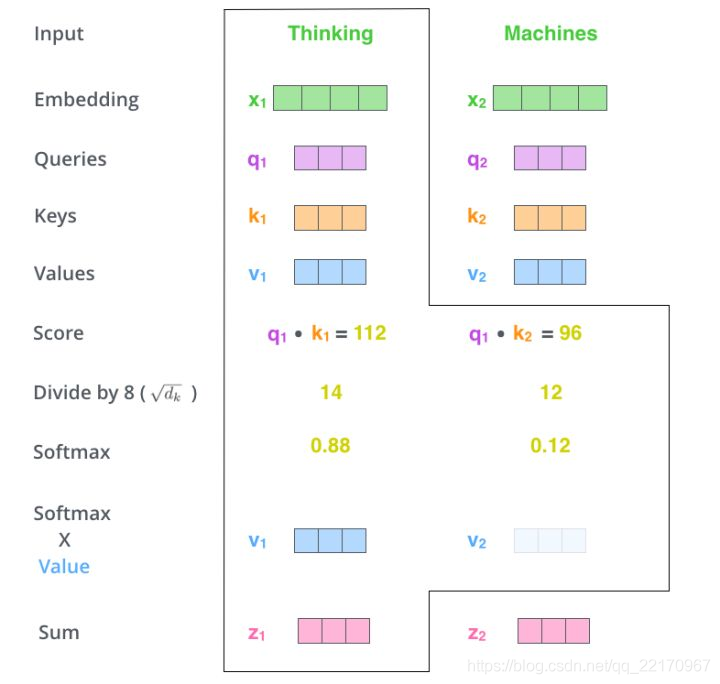
-
當我們處理Thinking這個詞時,我們需要計算句子中所有詞與它的Attention Score,這就像將當前詞作為搜索的Query,去和句子中所有詞(包含該詞本身)的key去匹配,看看相關度有多高,
-
我們用q1代表Thinking對應的query vector,k1和k2分別代表Thinking以及Machines對應的key vector,則計算Thinking的attention score的時候我們需要計算q1與k1,k2的點乘,同理,我們計算Machines的attention score的時候需要計q2與k1,k2的點乘,
-
如上圖中所示我們分別得到q1與k1,k2的點乘積,然后我們進行尺度縮放與softmax歸一化,顯然,當前單詞與其自身的attention score一般最大,其他單詞根據與當前單詞重要程度有相應的score,然后我們在用這些attention score與value vector相乘,得到加權的向量,
-
如果將輸入的所有向量合并為矩陣形式,則所有query, key, value向量也可以合并為矩陣形式表示
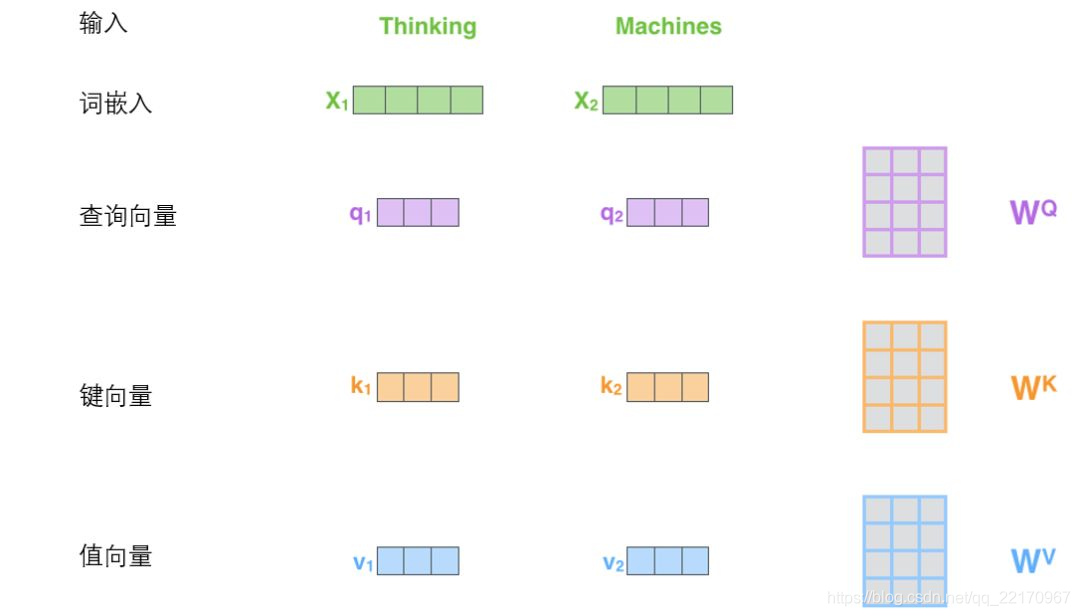
也就是說, x 1 x_{1} x1?與 W Q W^{Q} WQ權重矩陣相乘得到 q 1 q_{1} q1?, 就是與這個單詞相關的查詢向量,最終使得輸入序列的每個單詞的創建一個查詢向量、一個鍵向量和一個值向量,
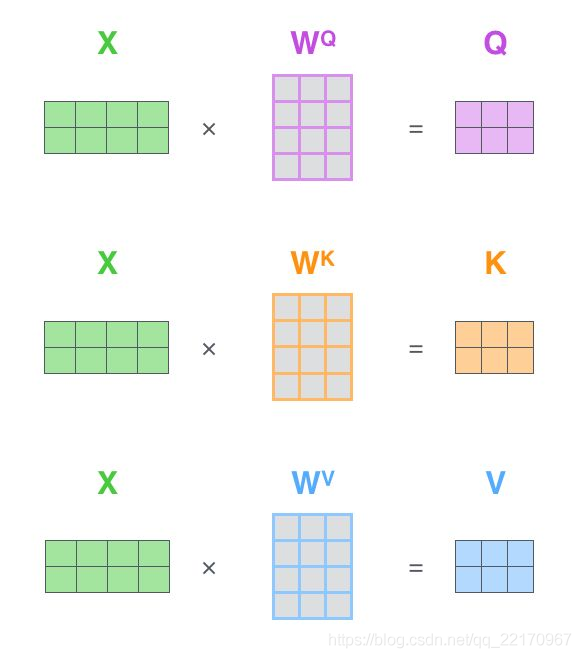
6. 上述操作即可簡化為矩陣形式
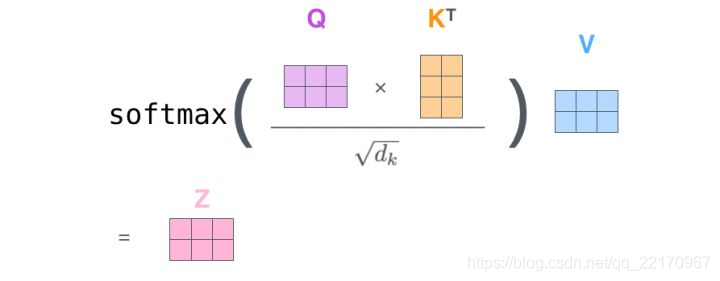
以上就是self attention的具體計算程序,
Soft Attention和Self Attention的區別
| Name | Description |
|---|---|
| Soft Attention | 在一般任務的Encoder-Decoder框架中,輸入Source和輸出Target內容是不一樣的,比如對于英-中機器翻譯來說,Source是英文句子,Target是對應的翻譯出的中文句子,Attention機制發生在Target的元素Query和Source中的所有元素之間, |
| Self Attention | 1. Self Attention顧名思義,指的不是Target和Source之間的Attention機制,而是Source內部元素之間或者Target內部元素之間發生的Attention機制,也可以理解為Target=Source這種特殊情況下的注意力計算機制,其具體計算程序是一樣的,只是計算物件發生了變化而已,2. 其次,很明顯,引入Self Attention后會更容易捕獲句子中長距離的相互依賴的特征,因為如果是RNN或者LSTM,需要依次序序列計算,對于遠距離的相互依賴的特征,要經過若干時間步步驟的資訊累積才能將兩者聯系起來,而距離越遠,有效捕獲的可能性越小,但是Self Attention在計算程序中會直接將句子中任意兩個單詞的聯系通過一個計算步驟直接聯系起來,所以遠距離依賴特征之間的距離被極大縮短,有利于有效地利用這些特征,除此外,Self Attention對于增加計算的并行性也有直接幫助作用,這是為何Self Attention逐漸被廣泛使用的主要原因, |
Attention的分類
Soft Attention和Self Attention是現如今最為常用的Attention模型,但并不代表只有這兩種模型,在茫茫計算機科學當中,依舊存在很多不常用但是活躍在各大NLP任務當中的Attention模型,具體分為以下幾類:
-
Soft/Hard Attention
soft attention:傳統attention,可被嵌入到模型中去進行訓練并傳播梯度
hard attention:不計算所有輸出,依據概率對encoder的輸出采樣,在反向傳播時需采用蒙特卡洛進行梯度估計,主要采用了強化學習(RL)的思想,相當于在soft attention的情況下,對這個概率進行采樣,即是hard attention的一個樣本,輸出為one-hot向量,并聚焦于某一點,MC sampling是RL常用的一種方法(如Policy gradient的實作中依賴MC方法來估計梯度) -
Global/Local Attention
global attention:傳統attention,對所有encoder輸出進行計算
local attention:介于soft和hard之間,會預測一個位置并選取一個視窗進行計算 -
Self Attention
傳統attention是計算Q和K之間的依賴關系,而self attention則分別計算Q和K自身的依賴關系,
其余Attention模型的具體計算邏輯,大家可以自行百度,在此不多贅述,
Attention模型的優缺點
-
優點:
一步到位獲取全域與區域的聯系,不會像RNN網路那樣對長期依賴的捕捉會收到序列長度的限制,
由固定的中間語意表示C換成了根據當前輸出單詞并調整成加入注意力模型的變化的 C i C_{i} Ci?,有效解決“資訊過長,資訊丟失”的問題
每步的結果不依賴于上一步,可以做成并行的模式
相比CNN與RNN,引數少,模型復雜度低,(根據attention實作方式不同,復雜度不一)
-
缺點:
沒有任何東西是完美的,再好的模型肯定會存在缺點的,Attention的缺點就是沒法捕捉位置資訊,即沒法學習序列中的順序關系,也就是缺少位置資訊,比方說有十個輸入詞向量,我會將10個輸入均等看待,哪個先哪個后,Attention不關心,解決辦法就是通過加入位置資訊,如通過位置向量來改善,在每一個輸入里面再加一個位置向量,告訴模型哪個第一個,哪個第二個等,具體可以參考最近大火的BERT模型(后期我也會進行講解,敬請期待喲!),
總結
現如今,Attention大有替代傳統RNN的架勢,由于其卓越的實際效果,目前在深度學習領域里得到了廣泛的使用,了解并熟練使用對于解決實際問題會有極大幫助,
第一次寫文章,參考了很多大佬的筆記、博文,文章鏈接都附在參考當中,我在此均表示萬分感謝🙏,!
如果哪里寫的不對,歡迎大家批評指正,共同進步!
展望
本章所講述的主要是原理分析以及計算程序,缺少一定的實戰演練,
接下來我將根據本章的attention模型原理給出代碼分析以及效果展示,希望大家繼續關注,感謝!
參考
- https://zhuanlan.zhihu.com/p/43493999
- https://blog.csdn.net/malefactor/article/details/78767781 (特別感謝張俊林博士!)
- https://segmentfault.com/a/1190000020843265
- https://blog.csdn.net/fkyyly/article/details/104881616?utm_source=app&app_version=4.13.0&code=app_1562916241&uLinkId=usr1mkqgl919blen
- https://zhuanlan.zhihu.com/p/53682800
- https://zhuanlan.zhihu.com/p/48612853
- https://jalammar.github.io/illustrated-transformer/
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008 鏈接
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/294991.html
標籤:其他
上一篇:cgb2106-day19