截止到目前我已經寫了 600多道演算法題,其中部分已經整理成了pdf檔案,目前總共有1000多頁(并且還會不斷的增加),大家可以免費下載
下載鏈接:https://pan.baidu.com/s/1hjwK0ZeRxYGB8lIkbKuQgQ
提取碼:6666



public boolean wordBreak(String s, List<String> dict) {
boolean[] dp = new boolean[s.length() + 1];
for (int i = 1; i <= s.length(); i++) {
//列舉k的值
for (int k = 0; k <= i; k++) {
//如果往前截取全部字串,我們直接判斷子串[0,i-1]
//是否存在于字典wordDict中即可
if (k == i) {
if (dict.contains(s.substring(0, i))) {
dp[i] = true;
continue;
}
}
//遞推公式
dp[i] = dp[i - k] && dict.contains(s.substring(i - k, i));
//如果dp[i]為true,說明前i個字串結果拆解可以讓他的所有子串
//都存在于字典wordDict中,直接終止內層回圈,不用再計算dp[i]了,
if (dp[i]) {
break;
}
}
}
return dp[s.length()];
}
上面代碼有一個判斷,就是截取的是前面全部字串的時候要單獨判斷,其實當截取全部的時候我們只需要判斷這個字串是否存在于字典wordDict中即可,可以讓dp[0]為true,dp[0]表示的是空字串,這樣代碼會簡潔很多,我們來看下
public boolean wordBreak(String s, List<String> dict) {
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;//邊界條件
for (int i = 1; i <= s.length(); i++) {
for (int j = 0; j < i; j++) {
dp[i] = dp[j] && dict.contains(s.substring(j, i));
if (dp[i]) {
break;
}
}
}
return dp[s.length()];
}
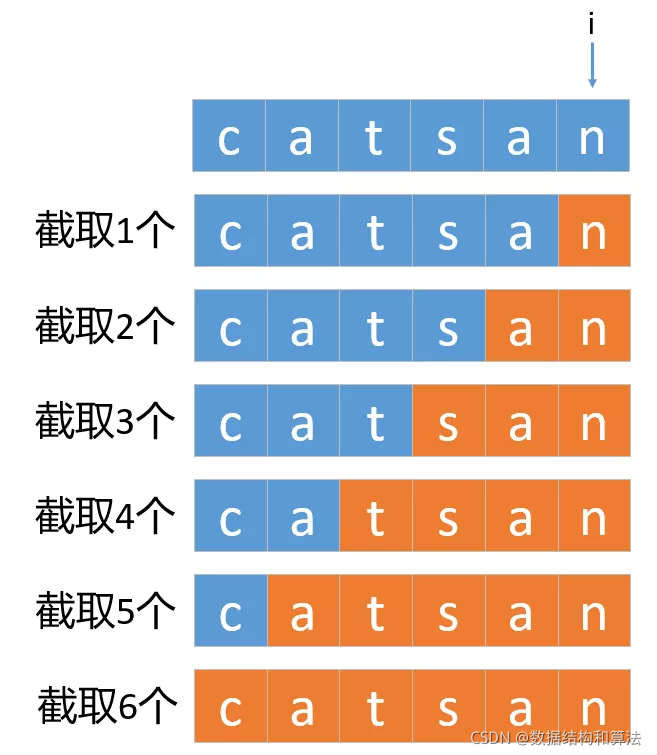
這個和第一種寫法不太一樣,這個每次截取的方式如下圖所示,
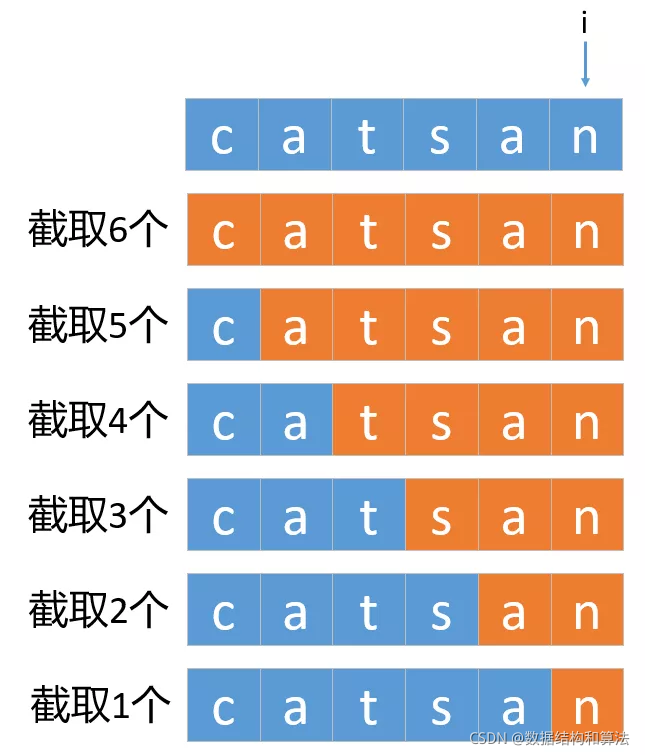


每次截取一個子串,判斷他是否存在于字典中,如果不存在于字典中,繼續截取更長的子串……如果存在于字典中,然后遞回拆分剩下的子串,這是一個遞回的程序,上面的執行程序我們可以把它看做是一棵n叉樹的DFS遍歷,所以大致代碼我們可以列出來
public boolean wordBreak(String s, List<String> wordDict) {
return dfs(s, wordDict);
}
public boolean dfs(String s, List<String> wordDict) {
if (最終條件,都截取完了,直接回傳true)
return true;
//開始拆分字串s
for (int i = 開始截取的位置; i <= s.length(); i++) {
//如果截取的子串不在字典中,繼續截取更大的子串
if (!wordDict.contains(截取子串))
continue;
//如果截取的子串在字典中,繼續剩下的拆分,如果剩下的可以拆分成
//在字典中出現的單詞,直接回傳true,如果不能則繼續
//截取更大的子串判斷
if (dfs(s, wordDict))
return true;
}
//如果都不能正確拆分,直接回傳false
return false;
}
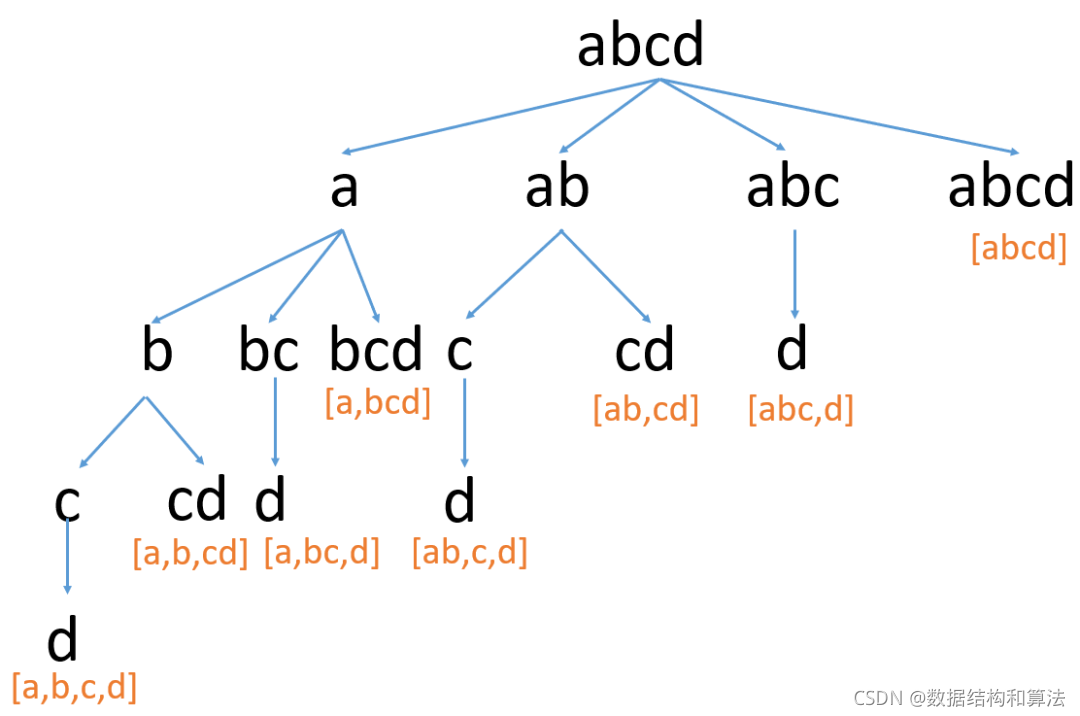
上面代碼中因為遞回必須要有終止條件,通過上面的圖我們可以發現,終止條件就是把字串s中的所有字符都遍歷完了,這個時候說明字串s可以拆分成一些子串,并且這些子串都存在于字典中,我們來看個圖
因為是拆分,所以字串截取的時候不能有重疊,那么[開始截取的位置]實際上就是上次截取位置的下一個,來看下代碼,
public boolean wordBreak(String s, List<String> wordDict) {
return dfs(s, wordDict, 0);
}
//start表示的是從字串s的哪個位置開始
public boolean dfs(String s, List<String> wordDict, int start) {
//字串中的所有字符都遍歷完了,也就是到葉子節點了,說明字串s可以拆分成
//在字典中出現的單詞,直接回傳true
if (start == s.length())
return true;
//開始拆分字串s,
for (int i = start + 1; i <= s.length(); i++) {
//如果截取的子串不在字典中,繼續截取更大的子串
if (!wordDict.contains(s.substring(start, i)))
continue;
//如果截取的子串在字典中,繼續剩下的拆分,如果剩下的可以拆分成
//在字典中出現的單詞,直接回傳true,如果不能則繼續
//截取更大的子串判斷
if (dfs(s, wordDict, i))
return true;
}
return false;
}
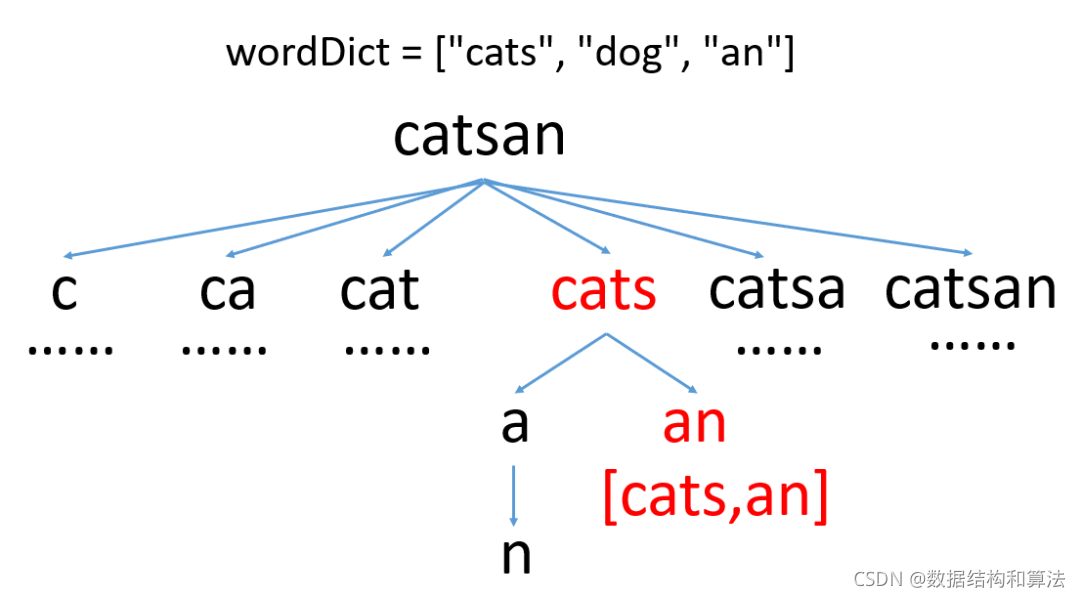
實際上上面代碼運行效率很差,這是因為如果字串s比較長的話,這里會包含大量的重復計算,我們還用上面的圖來看下
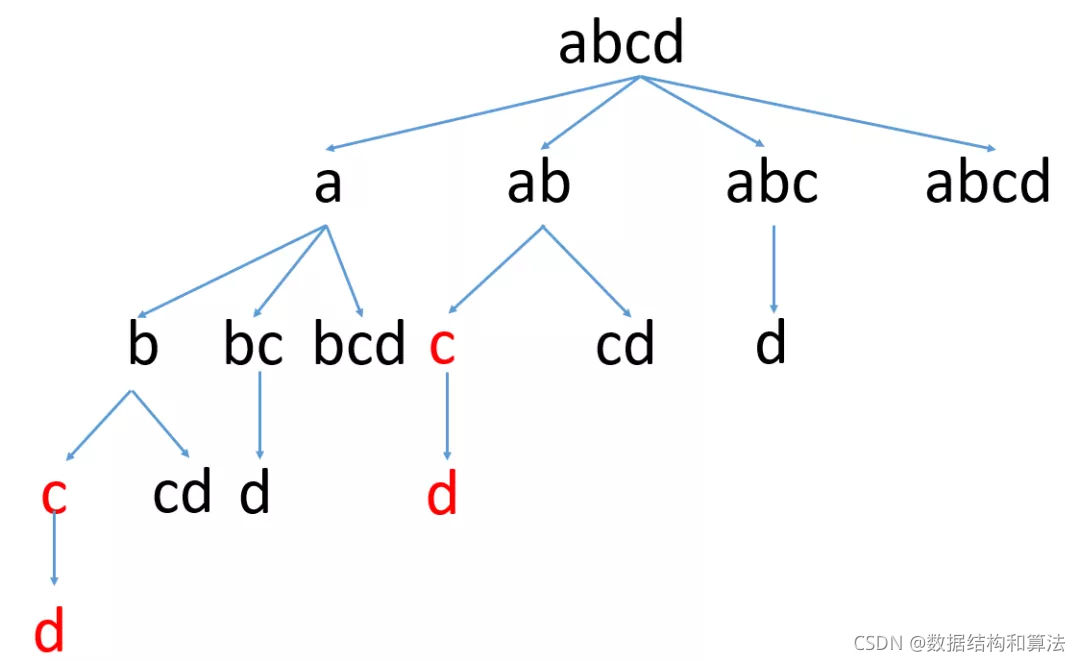
我們看到紅色的就是重復計算,這里因為字串比較短,不是很明顯,當字串比較長的時候,這里的重復計算非常多,我們可以使用一個變數,來記錄計算過的位置,如果之前判斷過,就不在重復判斷,直接跳過即可,代碼如下
public boolean wordBreak(String s, List<String> wordDict) {
return dfs(s, wordDict, new HashSet<>(), 0);
}
//start表示的是從字串s的哪個位置開始
public boolean dfs(String s, List<String> wordDict, Set<Integer> indexSet, int start) {
//字串都拆分完了,回傳true
if (start == s.length())
return true;
for (int i = start + 1; i <= s.length(); i++) {
//如果已經判斷過了,就直接跳過,防止重復判斷
if (indexSet.contains(i))
continue;
//截取子串,判斷是否是在字典中
if (wordDict.contains(s.substring(start, i))) {
if (dfs(s, wordDict, indexSet, i))
return true;
//標記為已判斷過
indexSet.add(i);
}
}
return false;
}

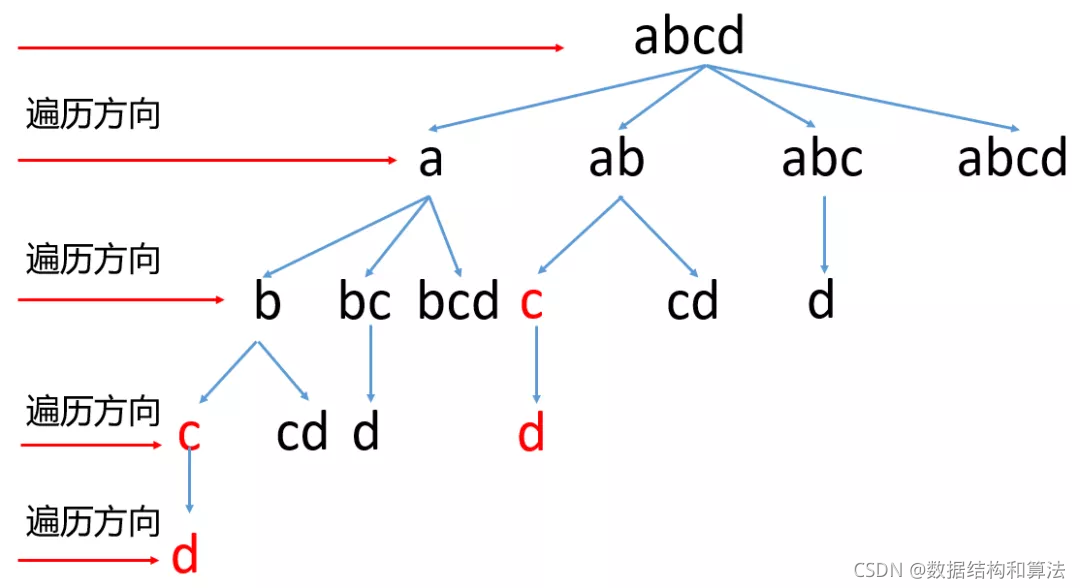
BFS一般不需要遞回,只需要使用一個佇列記錄每一層需要記錄的值即可,BFS中在截取的時候,如果截取的子串存在于字典中,我們就要記錄截取的位置,到下一層的時候就從這個位置的下一個繼續截取,來看下代碼,
public boolean wordBreak(String s, List<String> wordDict) {
//這里為了提高效率,把list轉化為set,因為set的查找效率要比list高
Set<String> setDict = new HashSet<>(wordDict);
//記錄當前層開始遍歷字串s的位置
Queue<Integer> queue = new LinkedList<>();
queue.add(0);
int length = s.length();
while (!queue.isEmpty()) {
int index = queue.poll();
//如果字串到遍歷完了,自己回傳true
if (index == length)
return true;
for (int i = index + 1; i <= length; i++) {
if (setDict.contains(s.substring(index, i))) {
queue.add(i);
}
}
}
return false;
}
這種也會出現重復計算的情況,所以這里我們也可以使用一個變數來記錄下,
public boolean wordBreak(String s, List<String> wordDict) {
//這里為了提高效率,把list轉化為set,因為set的查找效率要比list高
Set<String> setDict = new HashSet<>(wordDict);
//記錄當前層開始遍歷字串s的位置
Queue<Integer> queue = new LinkedList<>();
queue.add(0);
int length = s.length();
//記錄訪問過的位置,減少重復判斷
boolean[] visited = new boolean[length];
while (!queue.isEmpty()) {
int index = queue.poll();
//如果字串都遍歷完了,直接回傳true
if (index == length)
return true;
//如果被訪問過,則跳過
if (visited[index])
continue;
//標記為訪問過
visited[index] = true;
for (int i = index + 1; i <= length; i++) {
if (setDict.contains(s.substring(index, i))) {
queue.add(i);
}
}
}
return false;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/298160.html
標籤:其他
上一篇:用python爬取去哪兒游記攻略為十月假期做準備。。。爬蟲之路,永無止境!
下一篇:重新認識HTML(一)別來無恙