用python爬取去哪兒游記攻略為十月假期做準備,,,爬蟲之路,永無止境!
熱熱鬧鬧的開學季又來了,小伙伴們又可以在一起玩耍了,不對是在一起學習了,哈哈,

再過幾周就是國慶假期,想想還是很激動的,我決定給大家做個游記爬蟲,大家早做準備,,嘿嘿

代碼操作展示:
今天目標地址:https://travel.qunar.com/place/
開發環境:
windows10
python3.6
開發工具:
pycharm
庫:
tkinter、re、os、lxml、threading、xlwt、xlrd
1.首先先將全國所有的城市名稱和id拿到
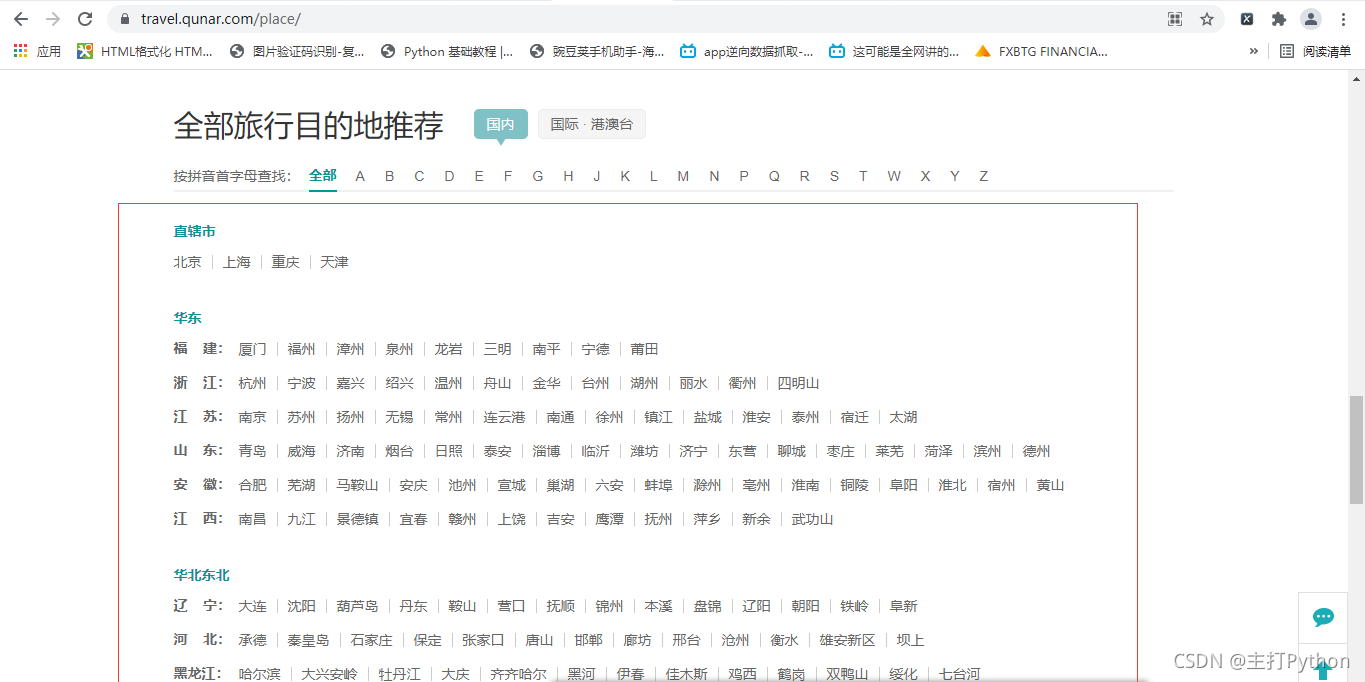
2.右擊檢查,進行抓包,找到資料所在的包
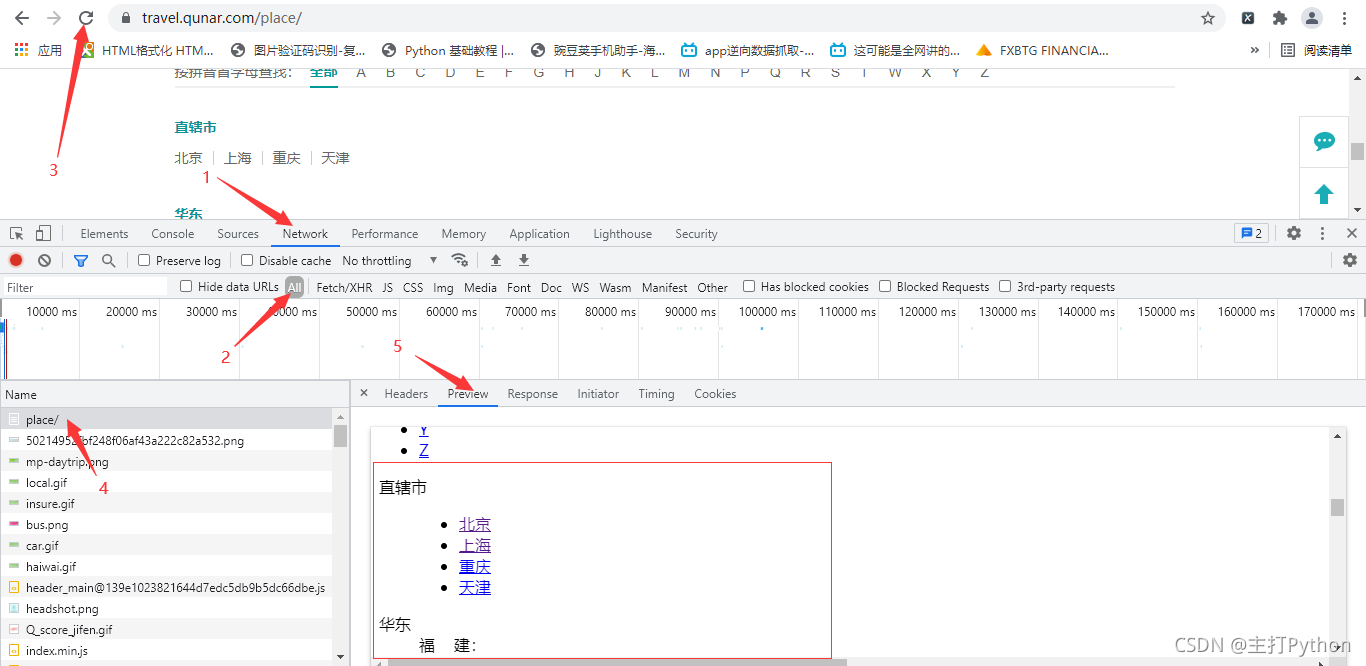
3.發送請求,獲取回應,決議回應
# 發送請求,獲取回應,決議回應
response = session.get(self.start_url, headers=self.headers).html
# 提取所有目的地(城市)的url
city_url_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href')
city_id_list = [''.join(re.findall(r'-cs(.*?)-', i)) for i in city_url_list]
# 提取所有的城市名稱
city_name_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()')
4.隨機點一個城市,進入該城市,查看游記攻略,本文選的是上海
5.進行抓包,查找需要的資訊
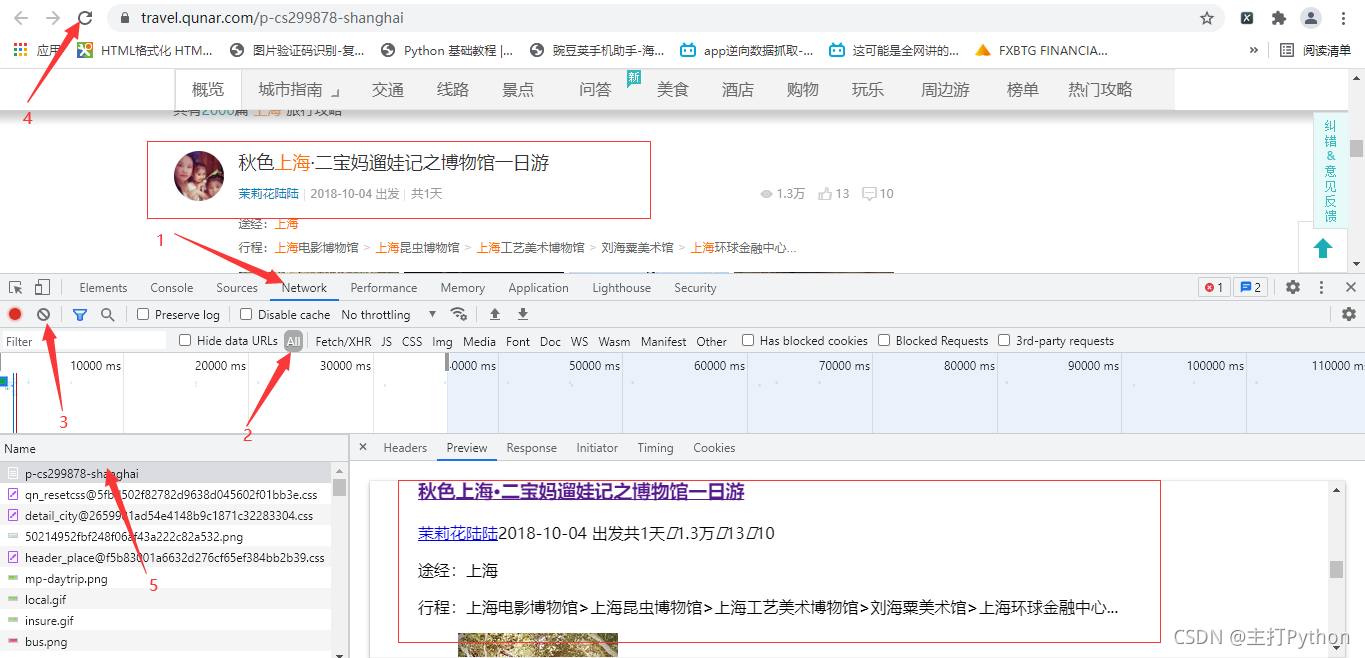
# 提取游記作者
author_list = html.xpath('//span[@class="user_name"]/a/text()')
# 出發時間
date_list = html.xpath('//span[@class="date"]/text()')
# 游玩時間
days_list = html.xpath('//span[@class="days"]/text()')
# 閱讀量
read_list = html.xpath('//span[@class="icon_view"]/span/text()')
# 點贊量
like_count_list = html.xpath('//span[@class="icon_love"]/span/text()')
# 評論量
icon_list = html.xpath('//span[@class="icon_comment"]/span/text()')
# 游記地址
text_url_list = html.xpath('//h3[@class="tit"]/a/@href')
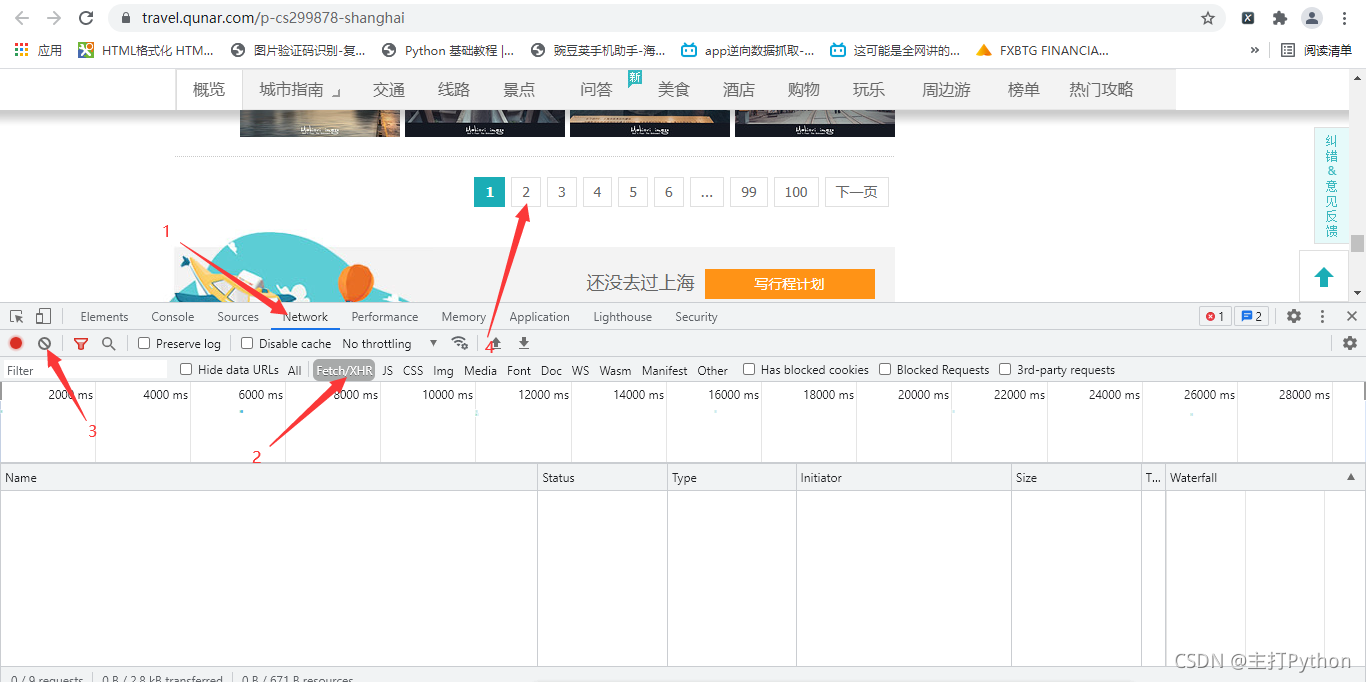
6.進行翻頁抓包,第二頁為異步加載
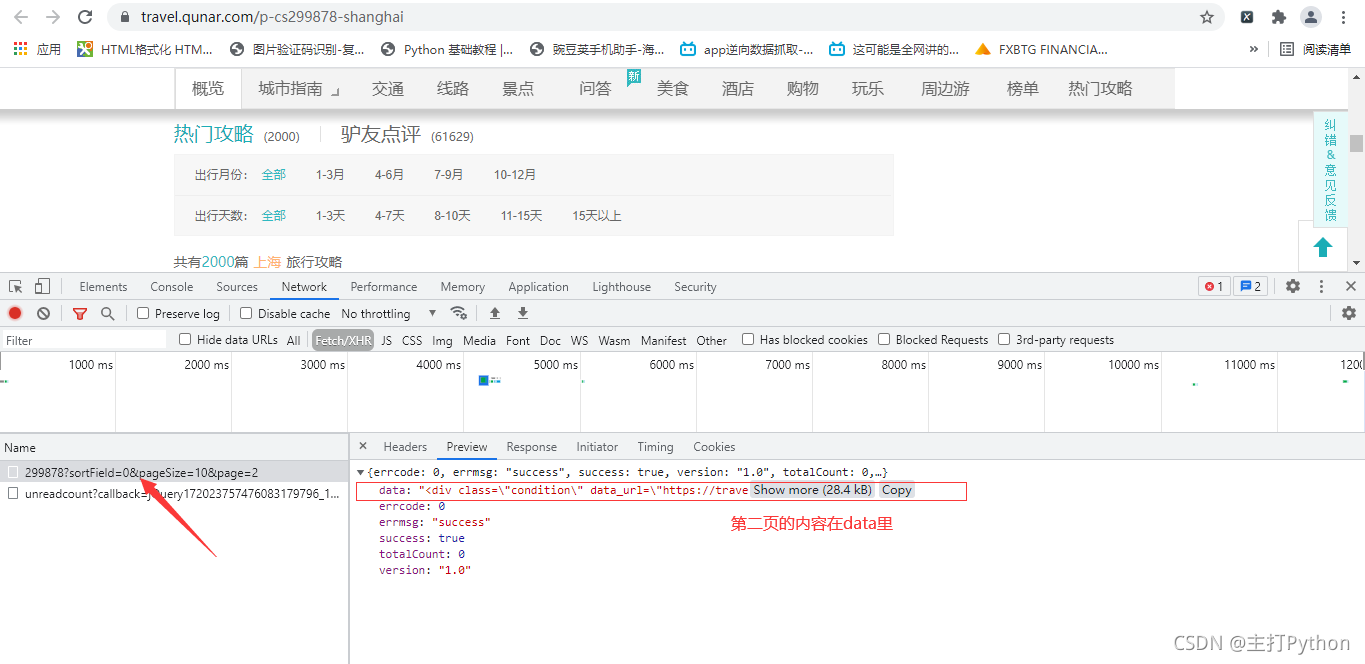
7.在上一張圖中點擊Headers,獲取游記攻略的請求地址
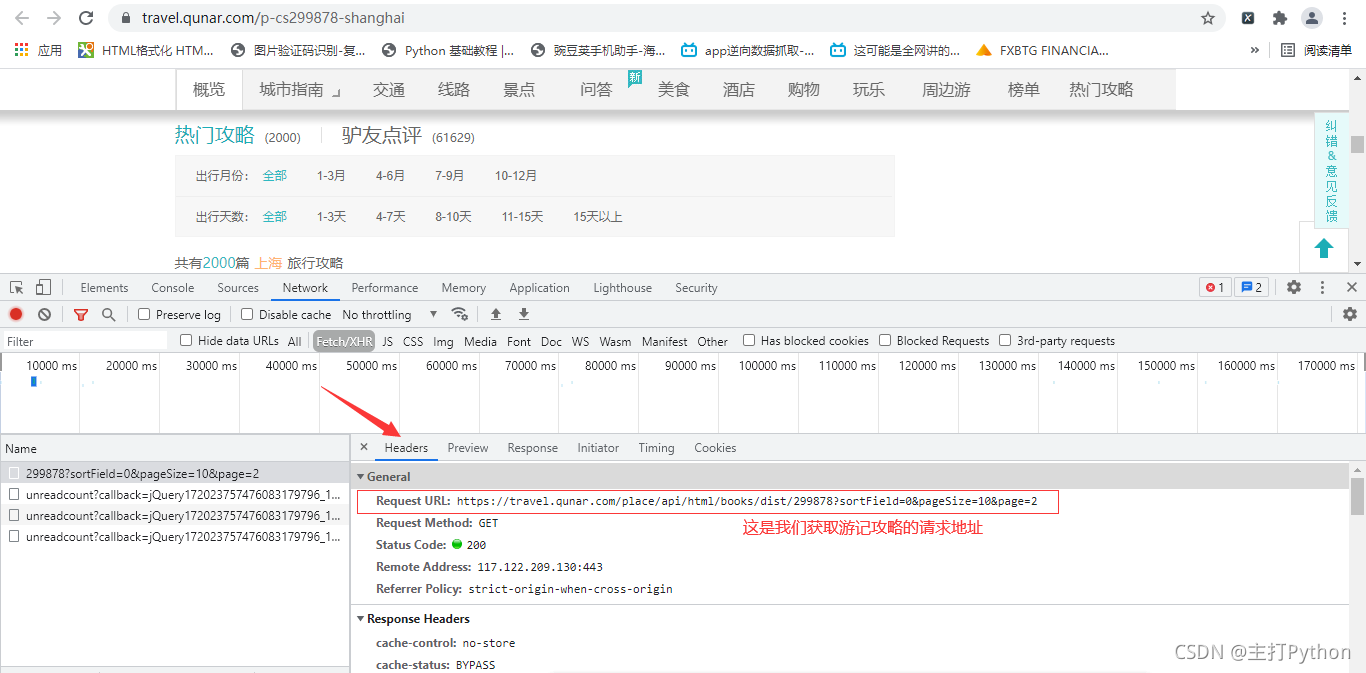
這樣思路是不是清晰一點,來觀察一下請求地址https://travel.qunar.com/place/api/html/books/dist/299878?sortField=0&pageSize=10&page=2
其中299878是上海城市的id page是頁數
原始碼展示:
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
import re
from lxml import etree
import tkinter.messagebox as msgbox
from requests_html import HTMLSession
from threading import Thread
import os, xlwt, xlrd
from xlutils.copy import copy
session = HTMLSession()
class TKSpider(object):
def __init__(self):
# 定義回圈條件
self.is_running = True
# 定義起始的頁碼
self.start_page = 1
"""定義可視化視窗,并設定視窗和主題大小布局"""
self.window = tk.Tk()
self.window.title('爬蟲資料采集')
self.window.geometry('1000x800')
"""創建label_user按鈕,與說明書"""
self.label_user = tk.Label(self.window, text='請選擇城市輸入序號:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""創建label_user關聯輸入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""創建Text富文本框,用于按鈕操作結果的展示"""
# 定義富文本框滑動條
scroll = tk.Scrollbar()
# 放到視窗的右側, 填充Y豎直方向
scroll.pack(side=tk.RIGHT, fill=tk.Y)
self.text1 = tk.Text(self.window, font=('Arial', 12), width=75, height=20)
self.text1.pack()
# 兩個控制元件關聯
scroll.config(command=self.text1.yview)
self.text1.config(yscrollcommand=scroll.set)
"""定義按鈕1,系結觸發事件方法"""
self.button_1 = tk.Button(self.window, text='下載游記', font=('Arial', 12), width=10, height=1, command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定義按鈕2,系結觸發事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1, command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
"""定義富文本文字的顯示"""
self.start_url = 'https://travel.qunar.com/place/'
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 發送請求,獲取回應,決議回應
response = session.get(self.start_url, headers=self.headers).html
# 提取所有目的地(城市)的url
city_url_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href')
city_id_list = [''.join(re.findall(r'-cs(.*?)-', i)) for i in city_url_list]
# 提取所有的城市名稱
city_name_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()')
self.dict_data = dict(zip(city_id_list, city_name_list))
text_info = ''
for city_id, city_name in zip(city_id_list, city_name_list):
text_info += city_id + ":" + city_name + '\t\t'
self.text1.insert("insert", text_info)
def parse_hit_click_1(self):
"""執行緒關聯:定義觸發事件1, 將執行結果顯示在文本框中"""
Thread(target=self.parse_start_url_job).start()
def parse_city_id_name_info(self):
"""
富文本內容展示:
:return:
"""
# 發送請求,獲取回應,決議回應
response = session.get(self.start_url, headers=self.headers).html
# 提取所有目的地(城市)的url
city_url_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href')
city_id_list = [''.join(re.findall(r'-cs(.*?)-', i)) for i in city_url_list]
# 提取所有的城市名稱
city_name_list = response.xpath(
'//*[@id="js_destination_recommend"]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()')
self.dict_data = dict(zip(city_id_list, city_name_list))
text_info = ''
for city_id, city_name in zip(city_id_list, city_name_list):
text_info += city_id + ":" + city_name + '\t\t****'
self.text1.insert("insert", text_info)
def parse_start_url_job(self):
# 從輸入視窗獲取輸入
city_id = self.entry_user.get()
self.text1.delete("1.0", "end")
# 例外捕捉,是否存在key值
try:
city_name = self.dict_data[city_id]
self.parse_request_yj(city_id, city_name)
except:
# 報錯提示
msgbox.showerror(title='錯誤', message='檢測到瞎搞,請重新輸入!')
def parse_request_yj(self, city_id, city_name):
"""
拼接游記地址,進行翻頁
:param city_id: 城市的id
:param city_name: 城市的名稱
:return:
"""
while self.is_running:
yj_url = f'https://travel.qunar.com/place/api/html/books/dist/{city_id}?sortField=0&pageSize=10&page={self.start_page}'
response = session.get(yj_url, headers=self.headers).json()['data'].replace('\\', '')
html = etree.HTML(response)
# 提取游記的標題:
title_list = html.xpath('//h3[@class="tit"]/a/text()')
# 死回圈的終止條件
if not title_list:
print("該城市已經采集到最后一頁----------城市切換中---------logging!!!")
break
else:
# 提取游記作者
author_list = html.xpath('//span[@class="user_name"]/a/text()')
# 出發時間
date_list = html.xpath('//span[@class="date"]/text()')
# 游玩時間
days_list = html.xpath('//span[@class="days"]/text()')
# 閱讀量
read_list = html.xpath('//span[@class="icon_view"]/span/text()')
# 點贊量
like_count_list = html.xpath('//span[@class="icon_love"]/span/text()')
# 評論量
icon_list = html.xpath('//span[@class="icon_comment"]/span/text()')
# 游記地址
text_url_list = html.xpath('//h3[@class="tit"]/a/@href')
"""構造保存資料格式字典"""
for a, b, c, d, e, f, g, h in zip(title_list, author_list, date_list, days_list, read_list, like_count_list, icon_list, text_url_list):
dict_dd = {
city_name: [a, b, c, d, e, f, g, h]
}
self.text1.insert("insert", f"{a}-----------采集完成!!!" + '\n')
self.SaveExcels(dict_dd)
self.start_page += 1
def SaveExcels(self, data):
# 獲取表的名稱
sheet_name = [i for i in data.keys()][0]
# 創建保存excel表格的檔案夾
# os.getcwd() 獲取當前檔案路徑
os_mkdir_path = os.getcwd() + '/資料/'
# 判斷這個路徑是否存在,不存在就創建
if not os.path.exists(os_mkdir_path):
os.mkdir(os_mkdir_path)
# 判斷excel表格是否存在 作業簿檔案名稱
os_excel_path = os_mkdir_path + '資料.xls'
if not os.path.exists(os_excel_path):
# 不存在,創建作業簿(也就是創建excel表格)
workbook = xlwt.Workbook(encoding='utf-8')
"""作業簿中創建新的sheet表""" # 設定表名
worksheet1 = workbook.add_sheet(sheet_name, cell_overwrite_ok=True)
"""設定sheet表的表頭"""
sheet1_headers = ('游記標題', '發布游記的作者名稱', '出發時間', '游玩時間', '閱讀量', '點贊量', '評論量', '游記地址')
# 將表頭寫入作業簿
for header_num in range(0, len(sheet1_headers)):
# 設定表格長度
worksheet1.col(header_num).width = 2560 * 3
# 寫入表頭 行, 列, 內容
worksheet1.write(0, header_num, sheet1_headers[header_num])
# 回圈結束,代表表頭寫入完成,保存作業簿
workbook.save(os_excel_path)
"""=============================已有作業簿添加新表==============================================="""
# 打開作業薄
workbook = xlrd.open_workbook(os_excel_path)
# 獲取作業薄中所有表的名稱
sheets_list = workbook.sheet_names()
# 如果表名稱:字典的key值不在作業簿的表名串列中
if sheet_name not in sheets_list:
# 復制先有作業簿物件
work = copy(workbook)
# 通過復制過來的作業簿物件,創建新表 -- 保留原有表結構
sh = work.add_sheet(sheet_name)
# 給新表設定表頭
excel_headers_tuple = ('游記標題', '發布游記的作者名稱', '出發時間', '游玩時間', '閱讀量', '點贊量', '評論量', '游記地址')
for head_num in range(0, len(excel_headers_tuple)):
sh.col(head_num).width = 2560 * 3
# 行,列, 內容, 樣式
sh.write(0, head_num, excel_headers_tuple[head_num])
work.save(os_excel_path)
"""========================================================================================="""
# 判斷作業簿是否存在
if os.path.exists(os_excel_path):
# 打開作業簿
workbook = xlrd.open_workbook(os_excel_path)
# 獲取作業薄中所有表的個數
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 獲取作業薄中所有表中的表名與資料名對比
if worksheet.name == name:
# 獲取表中已存在的行數
rows_old = worksheet.nrows
# 將xlrd物件拷貝轉化為xlwt物件
new_workbook = copy(workbook)
# 獲取轉化后的作業薄中的第i張表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_excel_path)
def parse_hit_click_2(self):
"""定義觸發事件2,洗掉文本框中內容"""
self.entry_user.delete(0, "end")
# self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
self.parse_city_id_name_info()
def center(self):
"""創建視窗居中函式方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改表單大小規格"""
self.window.resizable(False, False)
"""視窗居中"""
self.center()
"""視窗維持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
t = TKSpider()
t.run_loop()
代碼僅供學習!!
代碼僅供學習!!
代碼僅供學習!!
祝大家學習python順利!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/298159.html
標籤:其他
上一篇:匈牙利演算法尋找最大匹配