文章目錄
- 直接插入排序
- 代碼實作
- 復雜度的計算
- 希爾排序
- 希爾排序的預排序
- 代碼實作
- 選擇排序
- 代碼實作
- 堆排序
- 冒泡排序
- 代碼實作
💢 注:以下排序都是以排升序為例,
直接插入排序
直接插入排序的主要思路就是:
1.首先默認第一個元素是有序的,
2.然后將其下一個元素作為待排序的元素,插入到前面有序序列的相應位置,至于插入的程序,如果遇到比待排序大的元素,則這個元素后移,直到遇到比其小的元素,然后將待插入元素放入其前一個位置,

代碼實作
void Insertsort(int *a, int sz)
{
int i = 0;
for (i = 0; i < sz-1; i++)
{
//用j來記錄i的位置,這樣可以省得到時候有些情況i從頭或接近從頭開始走
int j = i;
int temp = a[i + 1];
while (i >= 0)
{
if (temp<a[i])
{
a[i + 1] = a[i];
i--;
}
else
{
break;
}
}
a[i + 1] = temp;
i = j;
}
}
注:絕大部分的直接插入排序演算法其實是沒有在代碼中記錄i的位置的,其實記錄了i的位置可以提高執行效率,因為這樣可以省得到時候有些情況i從頭或接近從頭開始走,

復雜度的計算
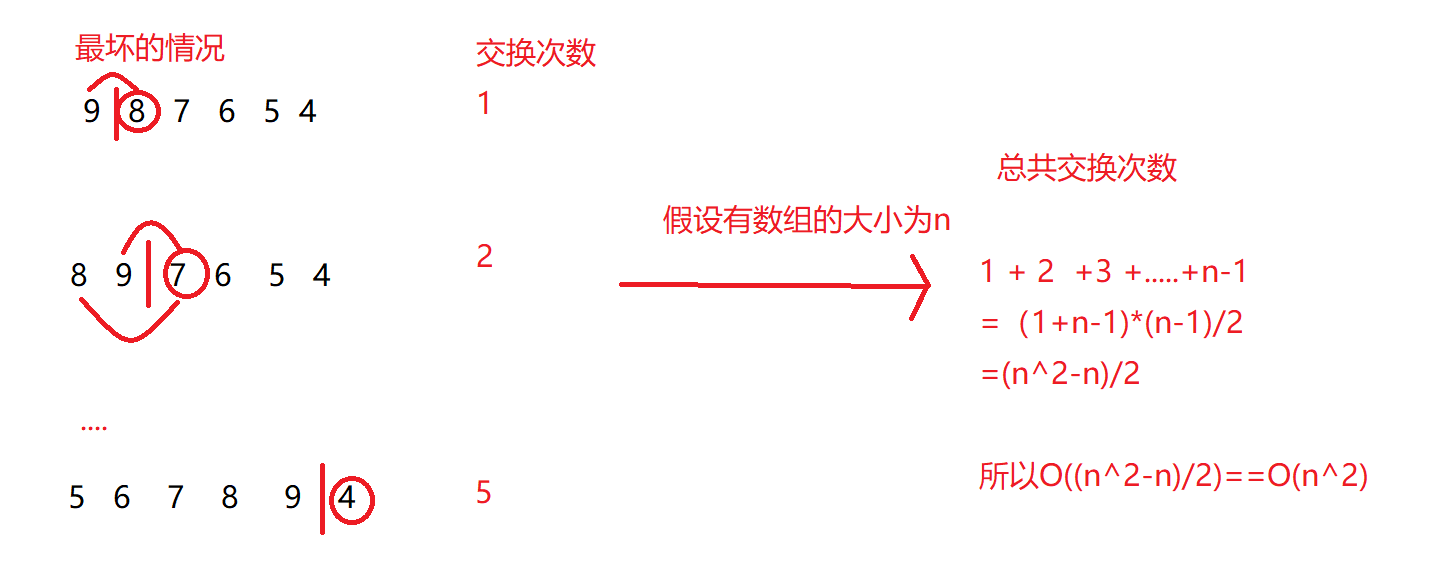
在代碼中,創建的臨時變數個數是常數個,所以空間復雜度為O(1),
希爾排序
在上面的直接插入排序中我們會發現:
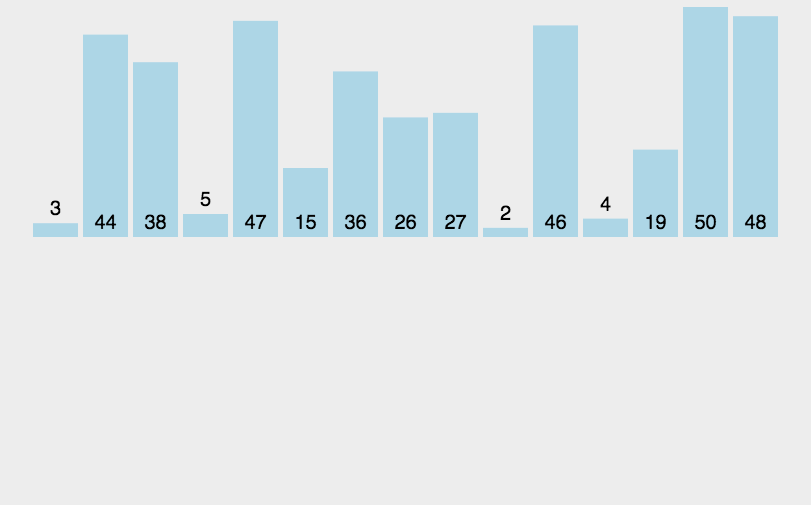
1.普通插入排序的時間復雜度最壞情況下為O(N2),此時待排序列為逆序,或者說接近逆序,
2.普通插入排序的時間復雜度最好情況下為O(N),此時待排序列為升序,或者說接近升序,
于是希爾這個科學家就想:若是能先將待排序列進行一次預排序,使待排序列接近有序(接近我們想要的順序),然后再對該序列進行一次直接插入排序,因為此時直接插入排序的時間復雜度為O(N),那么只要控制預排序階段的時間復雜度不超過O(N^2),那么整體的時間復雜度就比直接插入排序的時間復雜度低了,
希爾排序的預排序
希爾排序,又稱縮小增量法,那么如何縮小增量了?
1.先選定一個小于N的整數gap作為第一增量,然后將所有距離為gap的元素分在同一組,并對每一組的元素進行直接插入排序,然后再取一個比第一增量小的整數作為第二增量,重復上述操作 (一般情況下我們取得第一增量大小是序列長度的一半)
2.當增量的大小減到1時,其實此時預排序已經完成了,這時已經達到我們一開始要的目的:讓序列接近我們要的順序,
3.最后對整個序列進行直接插入排序即可,
舉個例子來看下,
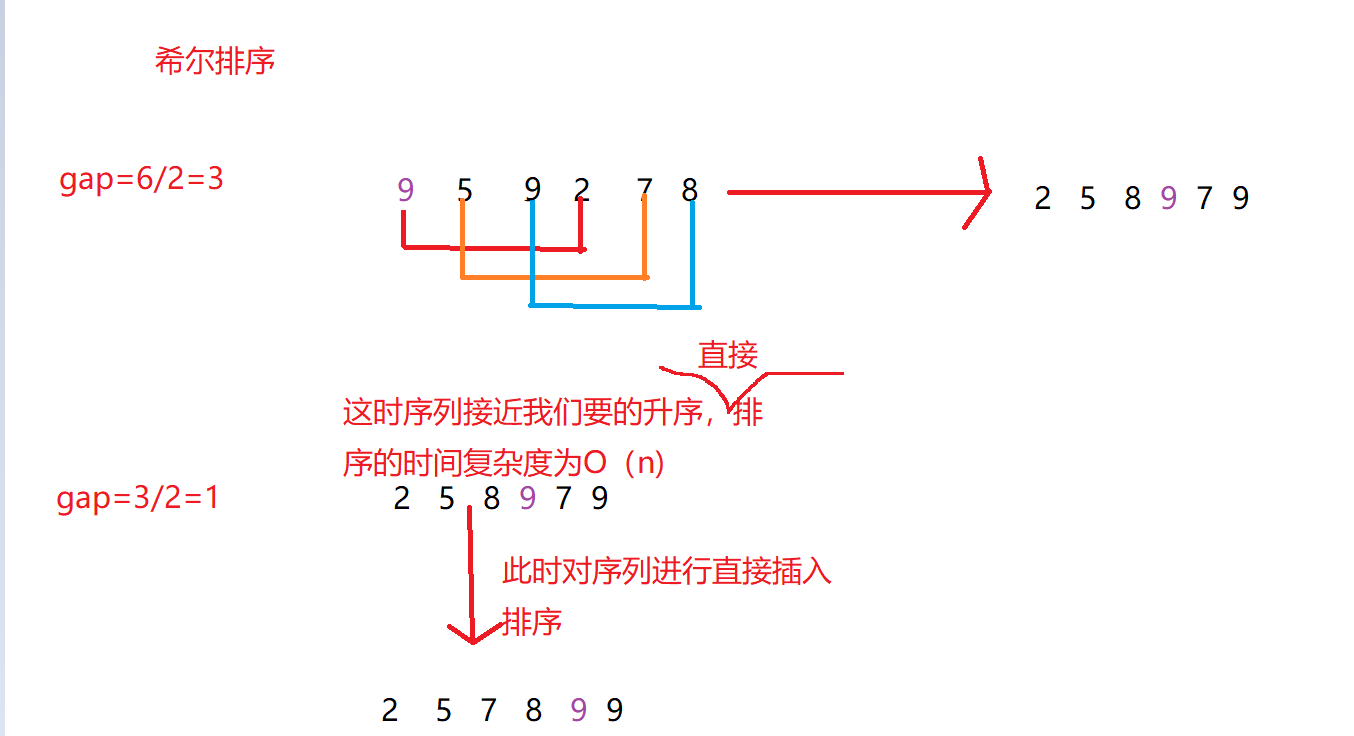
在這個序列中,gap=3時其實就是對原序列進行了預排序,使其接近我們要的升序,方便之后的直接排序,
注:希爾排序和直接插入排序是穩定排序:我們可以發現,在希爾排序的程序中,序列中兩個9的相對位置沒有發生改變,具有這樣特性的排序,我們稱之為穩定排序,
代碼實作
void Shellsort(int *a, int sz)
{
int i = 0;
int gap = sz / 2;
while (gap >= 1)
{
for (i = 0; i < sz-gap; i++)
{
int j = i;
int end = i;
int temp = a[i + gap]; //這兒一定要記錄下那個位置的資料,而不是寫成temp=i+gap記錄下標的形式,因為之后那個記錄的下標的位置的資料可能被前面的資料前移占據了,
while (end >= 0)
{
if (temp < a[end])
{
//a[temp] = a[end]; 因為下面要用到a[end+gap]=a[temp],所以這兒不能寫成a[temp]
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = temp;
i = j;
}
gap = gap / 2;
}
}
選取這種增量方法的時間復雜度:O(nlogn),具體這個我是這么理解的,首先預排序階段,你每次都將gap除以2,其實也就是高度次:logn,預處理中的交換次數可以看成常量,然后預處理完,這時已經接近最好情況的直接排序了,時間復雜度為O(n),所以最終的時間復雜度為O(nlogn),具體的證明程序等后序會補充更新,
空間復雜度:這里我們只定義了常數個常量,故空間復雜度為O(1),
選擇排序
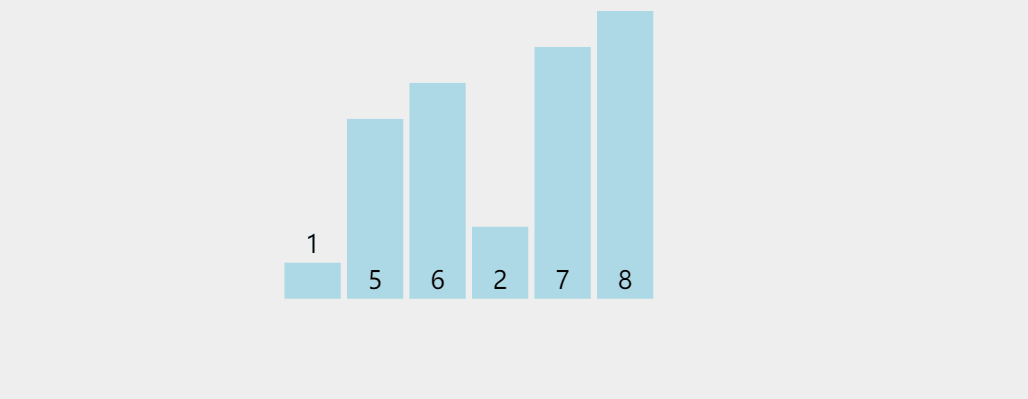
選擇排序
1.首先從整個陣列中選出最小值,記錄下最小值位置的下標與第一個位置交換,這樣相當于最小值就到了頭上,
2.此時將除最小值之后的元素再來選出次小的數,與第二個位置交換,之后迭代這個程序,最終就可以排成升序,
代碼實作
void chosesort(int *a, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
int min = i;
for (int j = i; j < sz; j++)
{
if (a[j] < a[min])
{
min = j;
}
}
swap(&a[i], &a[min]);
}
}
時間復雜度:最壞的情況下是一個等引數列為O(n^2)
空間復雜度:創建了常數個變數,為O(1)
實際上,我們可以一趟選出兩個值,一個最大值一個最小值,然后將其放在序列開頭和末尾,這樣可以使選擇排序的效率快一倍,
void chosesort(int* a, int sz)
{
int start = 0;
int end = sz - 1;
while (start < end)
{
int min = start;
int max = start;
for (int j=start; j <= end; j++)
{
if (a[j] < a[min])
{
min = j;
}
if (a[j]>a[max])
{
max = j;
}
}
swap(&a[start], &a[min]);
//萬一最大的值在最左邊,這樣max的位置的值就被最小值覆寫了,如果沒有這個處理,會導致下面交換時出錯,
if (max == start)
{
max = min;
}
swap(&a[end], &a[max]);
start++;
end--;
}
}
注:這里要小心一種極端情況:萬一最大的值在最左邊,這樣max的位置的值就被最小值覆寫了,如果沒有if這個處理,會導致下面交換時出錯,
堆排序
博主之前專門寫了一篇關于堆排序以及堆的文章,由于是最近不久寫的,這里就不再贅述了,💢堆排序以及堆相關的知識
冒泡排序
相信冒泡排序是很多小伙伴第一個知道的排序演算法,
其實它的思想正和他的取名一樣,它就是每趟排序冒出一個最大(最小)值,那么它是如何冒的了?很簡單,相鄰兩個元素比較,前一個比后一個大,則交換,
代碼實作
void Bubblesort(int *a, int sz)
{
int i = 0;
int flag = 0; //記錄原序列是否有序
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
if (a[j]>a[j + 1])
{
swap(&a[j], &a[j + 1]);
flag = 1; //交換過了,說明原序列無序
}
}
if (flag == 0) //原序列一次交換都沒有發生,說明原序列本來就有序,無需在繼續進行
{
break;
}
}
}
注:這里可以自己定義一個識別符號flag來記錄原序列是否發生過交換,如果沒有發生過,則說明原序列本來就有序,無需再進行之后的趟數,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/299722.html
標籤:其他