目錄
一、前言
二、什么是LDA?
三、LDA原理
1.二分類問題
2.多分類問題
3.幾點說明
四、演算法實作
一、前言
之前我們已經介紹過PCA演算法,這是一種無監督的降維方法,可以將高維資料轉化為低維資料處理,然而,PCA總是能適用嗎?
考慮如下資料點:
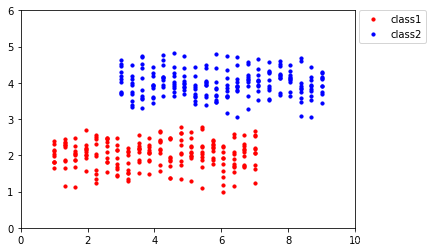
由PCA的原理我們可知,這些資料點在經PCA處理后會被映射到x軸上,如下所示:
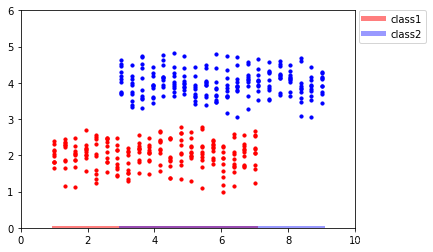
可以發現,投影后,紅色資料點和藍色資料點并不能很好地區分開,思考其背后的原因,在這個例子中,我們的資料點有了類別標簽,而PCA是一種無監督學習演算法,它會對所有類別的資料點 一視同仁,所以在分類問題中,PCA總是顯得乏力,事實上,相比于X軸,將資料點投影到Y軸是一個更優選擇:
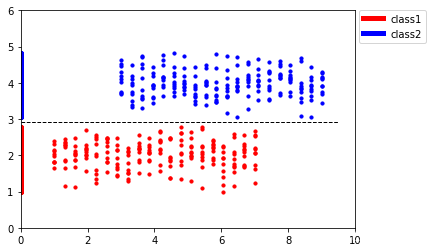
如上圖所示,將資料點投影到Y軸可以將兩個類別的資料點很好地區分開來,那么我們該如何找到這種投影方式呢,下面我們將介紹一種新的降維方法——LDA演算法,
二、什么是LDA?
線性判別分析(LDA),同PCA類似,也是一種降維演算法,不一樣的是,LDA是一種監督演算法,它需要用到類別資訊,LDA演算法的思路同PCA一致,即通過某種線性投影,將原本高維空間中的一些資料,映射到更低維度的空間中,但LDA演算法要求投影后的資料滿足:1.同類別的資料之間盡可能地接近,2.不同類別的資料之間盡可能地遠離,
三、LDA原理
1.二分類問題
從最簡單的二分類問題開始討論,根據LDA的投影目標,我們可以得到我們要優化的目標如下:
其中,代表投影后兩個類別的資料的中心點,
代表投影后兩個類別的資料的標準差,同PCA一致,我們一般用方差來表示資料的離散散程度,觀察優化目標
,分子衡量的是投影后兩個類別的資料中心點的距離,而分母衡量的是投影后兩個類別的資料各自的離散程度,同類別的資料越接近(LDA投影目標1),分母越小,
越大;不同類別的資料越遠離(LDA投影目標2),分子越大,
越大,目標合理,
方便起見,設為原始資料點,
分別為原始資料的中心點,
為投影向量,則有:
優化目標即為:
不妨設,則
可簡化為
,
對求導,應有:
化簡,得:
等式兩邊同除以,得:
變形,得:
顯然,這又是一個矩陣分解問題,是矩陣
的特征值,同時也是我們優化的目標,而
即為對應的特征值,也是投影向量,所以我們將矩陣分解得到的特征值從大到小排列,然后取最大的幾個特征值對應的特征向量作為我們的投影向量,
觀察式子,由于
,代入,得:
由于代表的是投影后兩類資料中心點間的距離,我們可以用常數
代替,于是有:
對于投影向量,我們只需要求得它的方向,對于它的大小(縮放程度)并無要求,所以我們最終求得的投影向量
即為
,通過這種方法,我們并不需要對矩陣進行分解便能求得投影向量,大大減少了計算量,
2.多分類問題
對二分類問題進行推廣,考慮多分類問題,同樣,投影的目的仍是使得同類資料點盡可能近,不同類別的資料點盡可能遠,這里需要對優化目標做適當改變,如下:
其中,和二分類問題一致,仍是第i類資料的中心點和標準差,而
則代表所有資料的中心,
代表第i個類別的資料個數,仔細觀察,可以發現,目標
的分母仍為各類別資料投影后的離散程度,而分子則是投影后各類別資料中心距所有資料中心點的距離的加權平方和,同樣是衡量不同類別資料點的分離程度,優化的目標同二分類問題一致,重點關注LDA投影目標,萬變不離其宗,
以二分類問題為例進行驗證,有:
同樣,我們只需要知道投影的方向,所以對于常數項,其只控制投影后資料點的縮放,并不影響最終結果,可以忽略,可以發現,用多分類問題的公式計算出來的結果同二分類的計算公式完全一致,
3.幾點說明
(1).維度必減少
PCA演算法降維可以理解為旋轉坐標軸,新的坐標下每條軸作為一個維度也即成分,對于差距不大的維度可以略去從而達到降維的目的,也就是說實際上PCA演算法可以將N維資料仍然變換為N維資料,然后可視情況刪減維度,但LDA演算法不盡然,使用LDA演算法時,新的坐標維度必會減少,
以二分類為例,觀察式子,由于
,可知
為奇異矩陣(它的秩最多為C-1),從而可以知道
也必為奇異矩陣,所以它分解后必有一個特征值為0,我們只能得到C-1個投影向量,C為類別個數,
(2).投影后各維度之間不一定正交
不一定是實對稱矩陣,所以它分解后得到的特征向量未必正交,
(3).可能無解
當樣本點個數少于樣本維度時,會變為奇異矩陣,無法求逆,在這種情況下可能需要先用PCA降維,再使用LDA,
(4).無法適用
LDA并不是萬能的,當同類別資料組成對角時,如下所示:
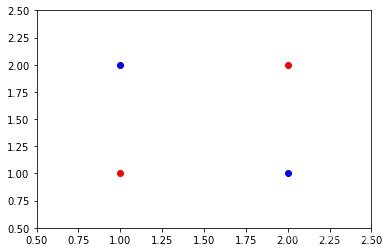
對于這種情況,我們可以發現,無論怎么投影均無法將兩類資料點很好地區分開來,事實上,對于這種情況,普通的線性投影均束手無策,應該先增加維度再考慮區分,
此外,當不同類別的資料的中心重合,即時,有
=0,此時LDA也不再適用,
(5).對某些分類問題,PCA性能可能優于LDA
當資料重合度過高時,如下所示:
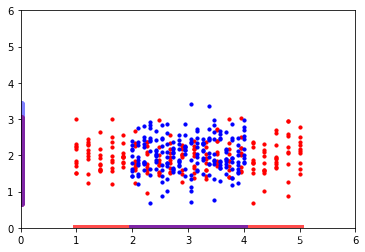
LDA會選擇往Y軸方向進行投影,而PCA 由于不考慮類別資訊,它會選擇往X軸上進行投影,在這種情境下,PCA不失為一種更優選擇,
四、演算法實作
同樣,根據前面的介紹,我們可以得到線性判別分析的一般步驟:給定樣本,先中心化,然后求矩陣和
,再對矩陣
進行特征分解,代碼實作如下:

當然,也可以不進行特征分解,直接套用公式 :

sklearn庫里直接封裝好了模型,可以直接使用:
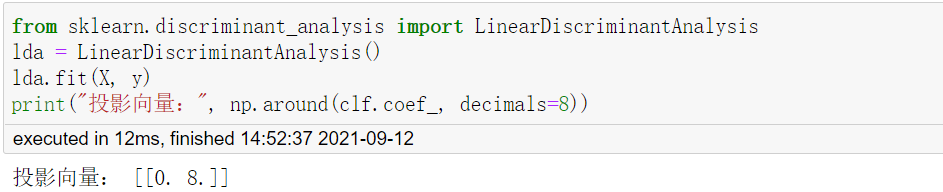
三種方法得到的特征向量分別為[0, -1],[0,-2],[0,8],標準化之后均為[0, 1],結果一致,即均投影到y軸上,觀察特征分解結果,可以發現,有一個特征值為0,與前面對LDA的探討一致, ,
,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/299725.html
標籤:其他
上一篇:編程之美-字串函式
下一篇:Python基礎語法回顧