文章目錄
- 字串函式
- 求字串長度
- 原格式
- 1.計數器方法
- 2.遞回
- 3.指標-指標
- ==長度不受限制==的字串函式
- strcpy字串拷貝
- 原格式
- 開始分析
- strcat字串追加
- 原格式
- 開始分析
- 注意:(絕對不可以自加)
- strcmp字串比較
- 原格式
- ==長度受限制==的字串函式
- strncpy
- 原格式
- 分析
- strncat
- 原格式
- 分析
- strncmp
- 原格式
- 分析
- 字串查找
- strstr找子字串
- 原格式
- 分析
- strtok
- 原格式
- 分析
- 錯誤資訊報告
- strerror
- 原格式
- 分析
- 總結:
字串函式
c語言中對字符和字串的處理很是頻繁,但是c語言本身是沒有字串型別的,字串通常放在常量字串中或者字符陣列中,字串常量適用于那些對他不做修改的字串函式
求字串長度
strlen
- 字串以 ‘\0’ 作為結束標志,strlen函式回傳的是在字串中 ‘\0’ 前面出現的字符個數(不包含 ‘\0’ ),
- 引數指向的字串必須要以 ‘\0’ 結束,
- 注意函式的回傳值為size_t,是無符號的
- 學會模擬實作,
原格式

有三種自寫方法
1.計數器方法
size_t my_strlen(const char* parr)
{
assert(parr);
size_t count = 0;
while (*parr++)
{
count++;
}
return count;
}
先把該講的都講一下把size_t就是unsigned int無符號整形,他的數永遠也不可能是負數,所以有一個坑你就過去了.
strlen("asd")-strlen("asdfg")不可能為負數的根本原因就是size_t
2.遞回
size_t my_strlen(const char* parr)
{
assert(parr);//這是良好的代碼規范
if (*parr)
return 1 + my_strlen(++parr);
else
return 0;
}
3.指標-指標
size_t my_strlen(const char* parr)
{
assert(parr);//這是良好的代碼規范
char* head = parr;
char* tail = parr;
while (*tail)
{
tail++;
}
return tail - head;
}
長度不受限制的字串函式
strcpy字串拷貝
- 源字串必須以 ‘\0’ 結束,
- 會將源字串中的 ‘\0’ 拷貝到目標空間,
- 目標空間必須足夠大,以確保能存放源字串,
- 目標空間必須可變,
- 學會模擬實作,
原格式
開始分析

為了簡潔與高效那offer你得仿照原格式
但回傳值型別還有點不一樣,所以回傳值型別得變成char*型別
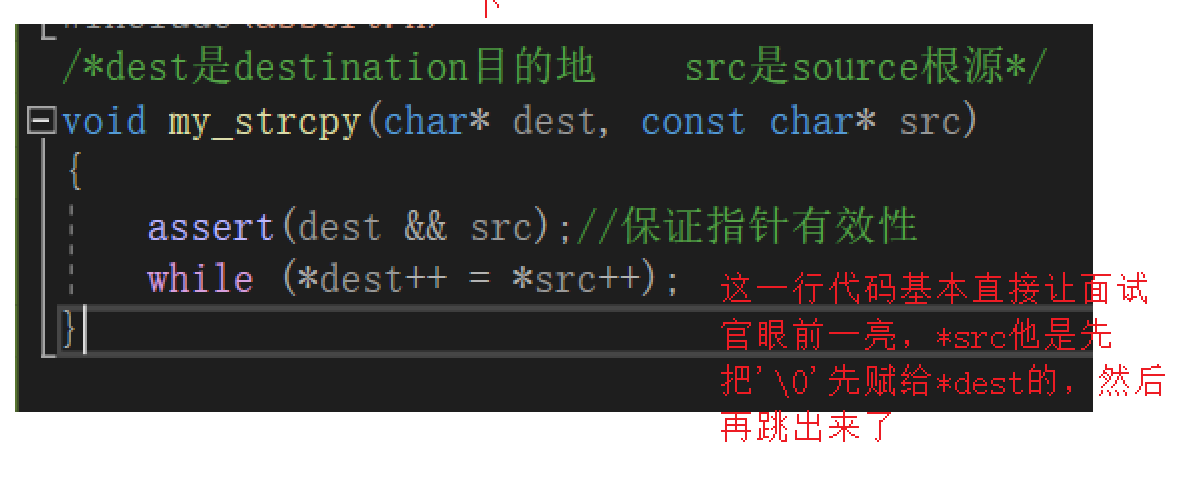
/*dest是destination目的地 src是source根源*/
char* my_strcpy(char* dest, const char* src)
{
assert(dest && src);//保證指標有效性
char* ret = dest;
while (*dest++ = *src++);
return ret;
}
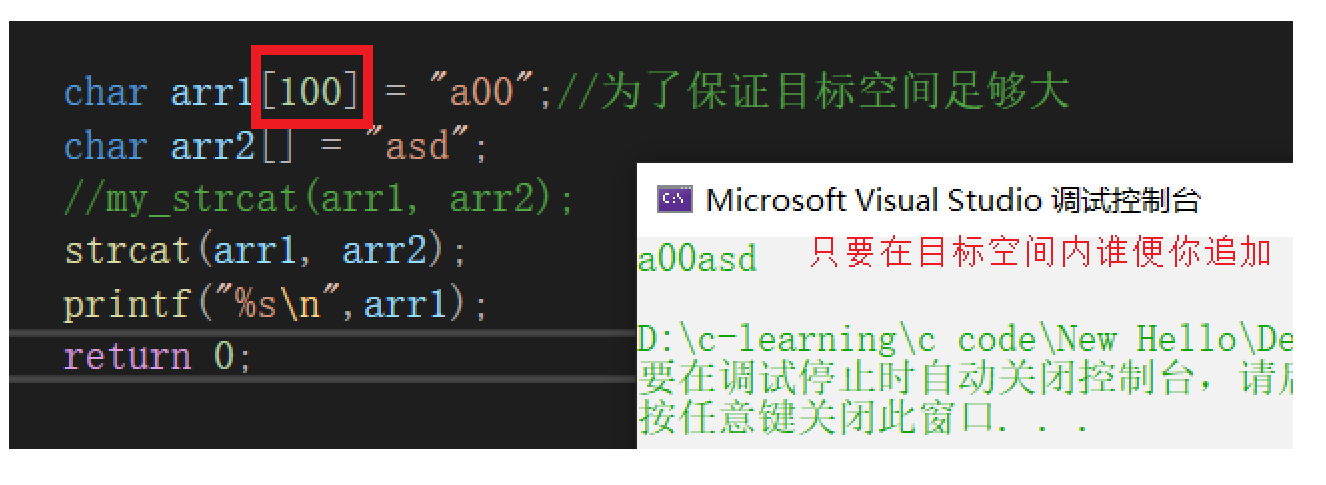
strcat字串追加
-
源字串必須以 ‘\0’ 結束,
-
目標空間必須有足夠的大,能容納下源字串的內容,
-
目標空間必須可修改,
-
字串自己給自己追加,如何?
原格式
開始分析
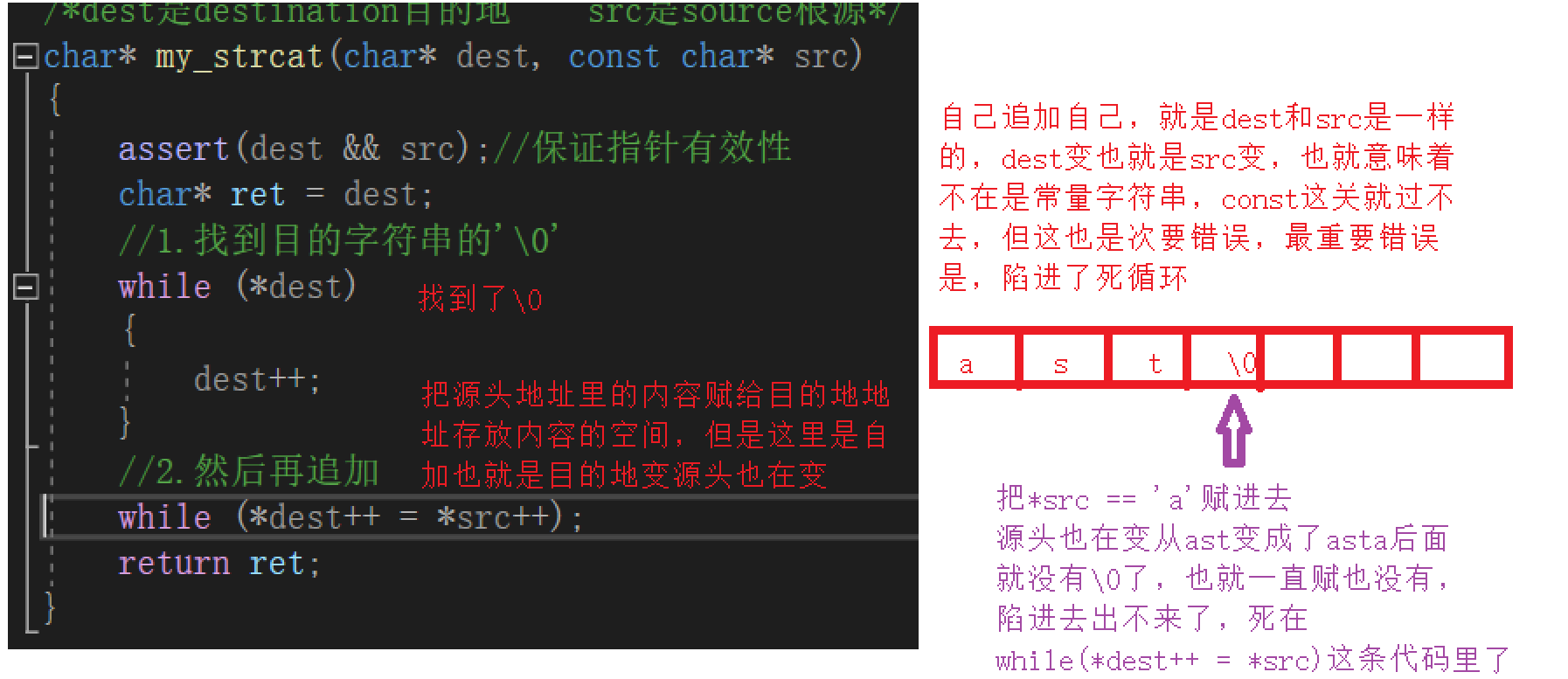
/*dest是destination目的地 src是source根源*/
char* my_strcat(char* dest, const char* src)
{
assert(dest && src);//保證指標有效性
char* ret = dest;
//1.找到目的字串的'\0'
while (*dest)
{
dest++;
}
//2.然后再追加
while (*dest++ = *src++);
return ret;
}
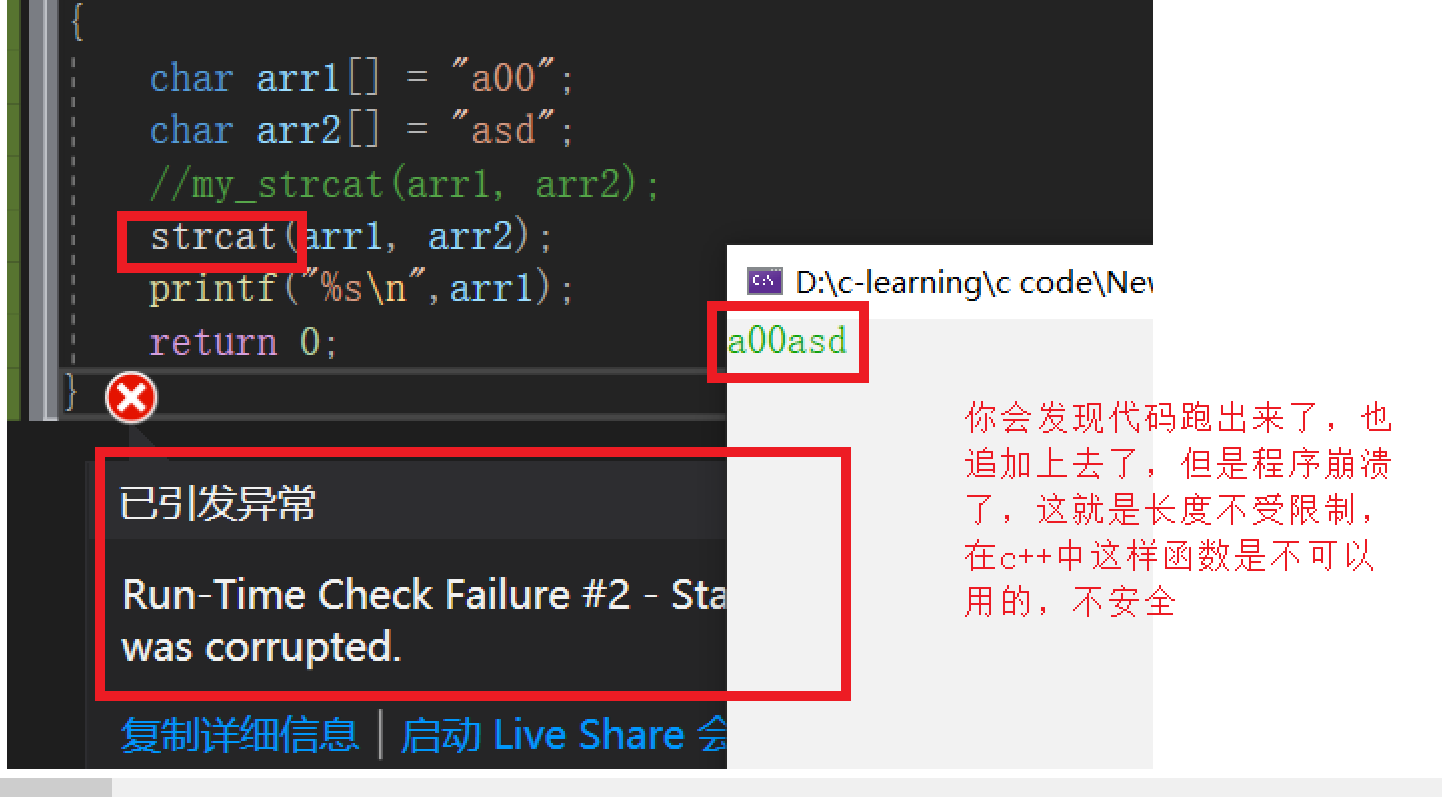
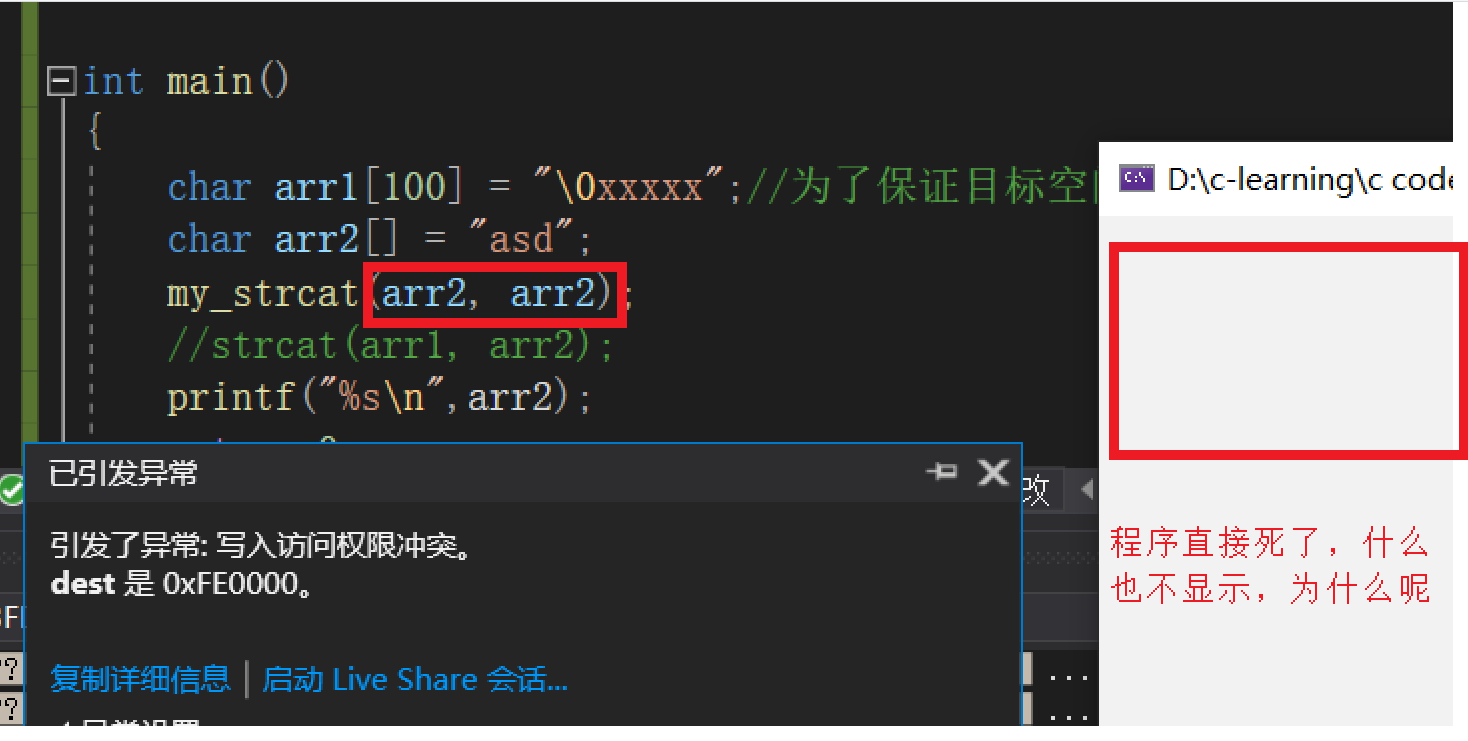
注意:(絕對不可以自加)
自己給自己追加呢
會出現兩個自己的情況嗎
strcmp字串比較
-
第一個字串大于第二個字串,則回傳大于0的數字
-
第一個字串等于第二個字串,則回傳0
-
第一個字串小于第二個字串,則回傳小于0的數字
-
那么如何判斷兩個字串?
原格式
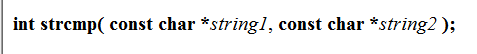
/*我們僅僅就是比較兩個字串,不希望改變他們,所以const*/
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2);//保證指標有效性
while (*str1 == *str2)
{
if (!*str1)
return 0;//相等
str1++;
str2++;
}
if (*str1 > *str2)
return 1;//大于
else
return -1;//小于
}
長度受限制的字串函式
為了彌補長度不受限制的字串函式的安全性
strncpy
-
拷貝num個字符從源字串到目標空間,
-
如果源字串的長度小于num,則拷貝完源字串之后,在目標的后邊追加0,直到num個,
原格式
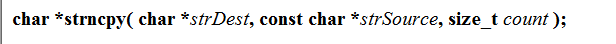
分析
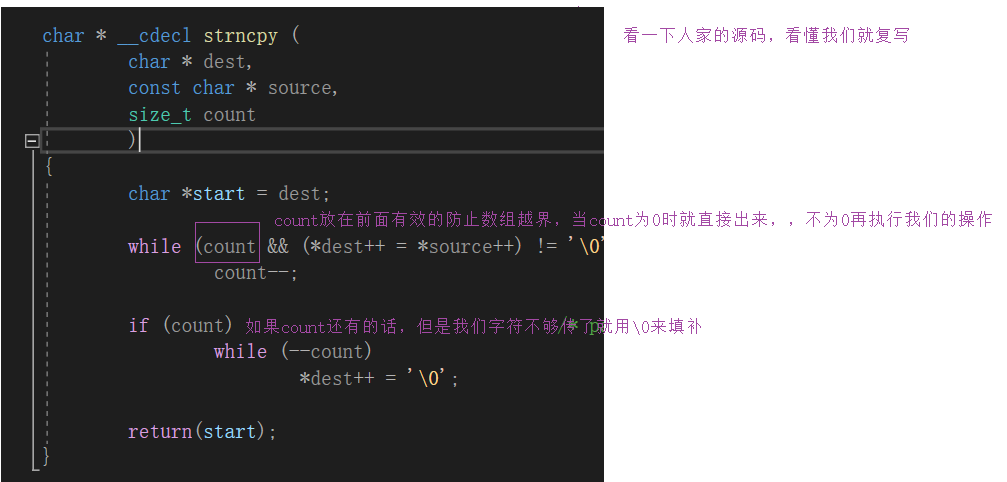
/*dest是destination目的地 src是source根源*/
char* my_strncpy(char* dest, const char* src,size_t count)
{
assert(dest && src);//保證指標有效性
char* ret = dest;
while (count && (*dest++ = *src++))//count為0直接跳不會管你還有沒有需要傳的
{
count--;
}
if (count)//傳完了用'\0'來補
{
while (count--)//這邊不管先--還是后--都沒事因為操作物件就是'\0'
*dest = '\0';
}
return ret;
}
strncat
原格式
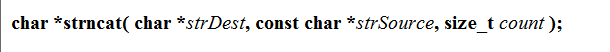
分析
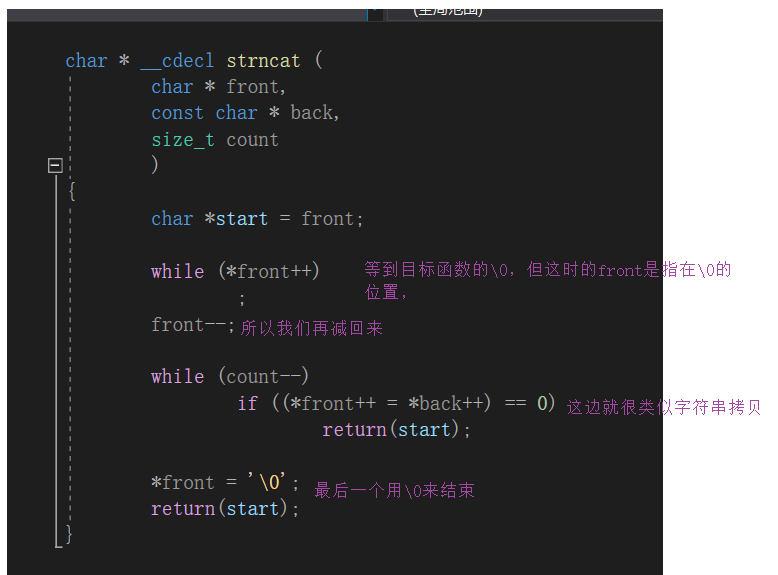
/*dest是destination目的地 src是source根源*/
char* my_strncat(char* dest, const char* src,size_t count)
{
assert(dest && src);//保證指標有效性
char* ret = dest;
//1.找到目的字串的'\0'
while (*dest)
{
dest++;
}
//2.然后再追加
while (count--)
{
if ((*dest++ = *src++) == 0)//count還沒到0的時候已經賦\0去了就可以回傳來了
{
return ret;
}
}
*dest = '\0';//這是還沒有賦\0,但count變成了0,就直接賦\0然后回傳
return ret;
}
strncmp
原格式
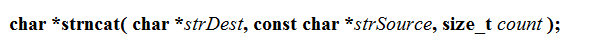
分析
分什么析,原始碼我都不想看有點花
int __cdecl strncmp
(
const char *first,
const char *last,
size_t count
)
{
size_t x = 0;
if (!count)
{
return 0;
}
/*
* This explicit guard needed to deal correctly with boundary
* cases: strings shorter than 4 bytes and strings longer than
* UINT_MAX-4 bytes .
*/
if( count >= 4 )
{
/* unroll by four */
for (; x < count-4; x+=4)
{
first+=4;
last +=4;
if (*(first-4) == 0 || *(first-4) != *(last-4))
{
return(*(unsigned char *)(first-4) - *(unsigned char *)(last-4));
}
if (*(first-3) == 0 || *(first-3) != *(last-3))
{
return(*(unsigned char *)(first-3) - *(unsigned char *)(last-3));
}
if (*(first-2) == 0 || *(first-2) != *(last-2))
{
return(*(unsigned char *)(first-2) - *(unsigned char *)(last-2));
}
if (*(first-1) == 0 || *(first-1) != *(last-1))
{
return(*(unsigned char *)(first-1) - *(unsigned char *)(last-1));
}
}
}
/* residual loop */
for (; x < count; x++)
{
if (*first == 0 || *first != *last)
{
return(*(unsigned char *)first - *(unsigned char *)last);
}
first+=1;
last+=1;
}
return 0;
}
看到頭大還不如我自己寫呢
/*我們僅僅就是比較兩個字串,不希望改變他們,所以const*/
int my_strncmp(const char* str1, const char* str2,size_t count)
{
assert(str1 && str2);//保證指標有效性
while (count--)
{
if (*str1 - *str2 > 0)
return 1;//大于
else if (*str1 - *str2 < 0)
return -1;//小于
else
{
if (*str1 == *str2 == '\0')
return 0;//相等
str1++;
str2++;
}
}
return 0;//不在count內統統相等
}
字串查找

strstr找子字串
原格式
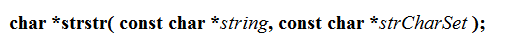
分析
他這個回傳值型別的意思是:這些函式都回傳一個指向strCharSet在string中第一次出現的指標,如果strCharSet沒有在string中出現,則回傳NULL(空指標),如果strCharSet指向一個長度為0的字串,則函式回傳string
看我垃圾代碼

改完后
/*我們僅僅就是找子字串,不會改變他們,所以const*/
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);//保證指標有效性
char* s1 = str1;//設定一個跟蹤指標變數來代替str1
char* s2 = str2;//設定一個跟蹤指標變數來代替str2
char* cur = str1;//設定一個原點指標變數來標置原來的查找位置,類似匯編中的call指令
//排除空字串
if (!*str2)
return str1;//這個是原函式規定的,所查字串是空字串的話回傳str1
//真正的查找程序
while (*cur)
{
s1 = cur;//先把標記立在這cur
s2 = str2;
while (*s1 == *s2 && *s1 && *s2)
{
s1++;
s2++;
}
if (!*s2)
return cur;//找到就直接回傳把標記地址回傳
cur++;//這是回到標記的下一個空間
}
return NULL;//沒找到就回傳空指標
}
strtok
-
strDelimit引數是個字串,定義了用作分隔符的字符集合(Delimit 界限)
-
第一個引數指定一個字串,它包含了0個或者多個由strDelimit字串中一個或者多個分隔符分割的標記,
-
strtok函式找到strToken中的下一個標記,并將其用\0結尾,回傳一個指向這個標記的指標,(注:strtok函式會改變被操作的字串,所以在使用strtok函式切分的字串一般都是臨時拷貝的內容并且可修改,)
-
strtok函式的第一個引數不為NULL,函式將找到strToken中第一個標記,strtok函式將保存它在字串中的位置,
-
strtok函式的第一個引數為NULL,函式將在同一個字串中被保存的位置開始,查找下一個標記,
-
如果字串中不存在更多的標記,則回傳 NULL 指標,
原格式
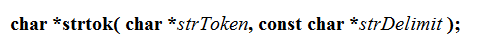
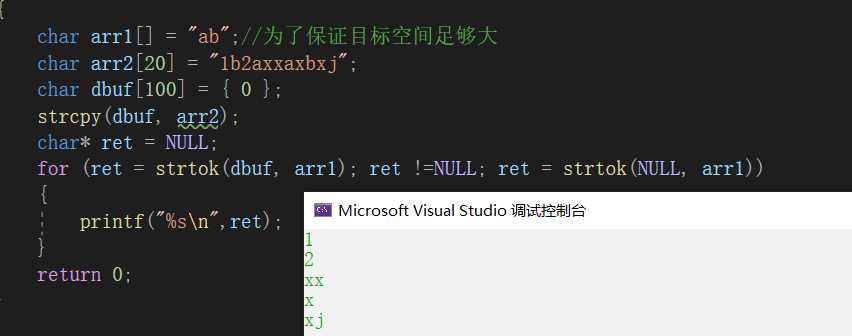
分析
不分析了,會用就行
錯誤資訊報告
strerror
- 回傳錯誤碼,所對應的錯誤資訊
原格式
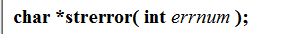
分析
不要想著重寫這個函式,會用就行

總結:
字串函式重要的就到這里了
下一章記憶體函式,敬請期待
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/299724.html
標籤:其他
下一篇:LDA演算法——線性判別