基本介紹
散串列(Hash table,也叫哈希表),是根據關鍵碼值(Key value)而直接進行訪問的資料結構,也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找的速度,這個映射函式叫做散列函式,存放記錄的陣列叫做散串列,
哈希表的作用相當于一個快取層
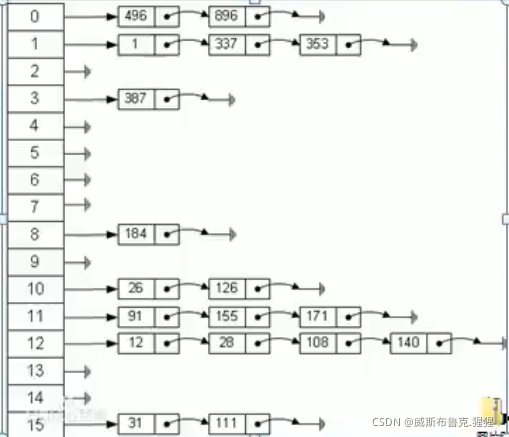
哈希表的記憶體布局圖
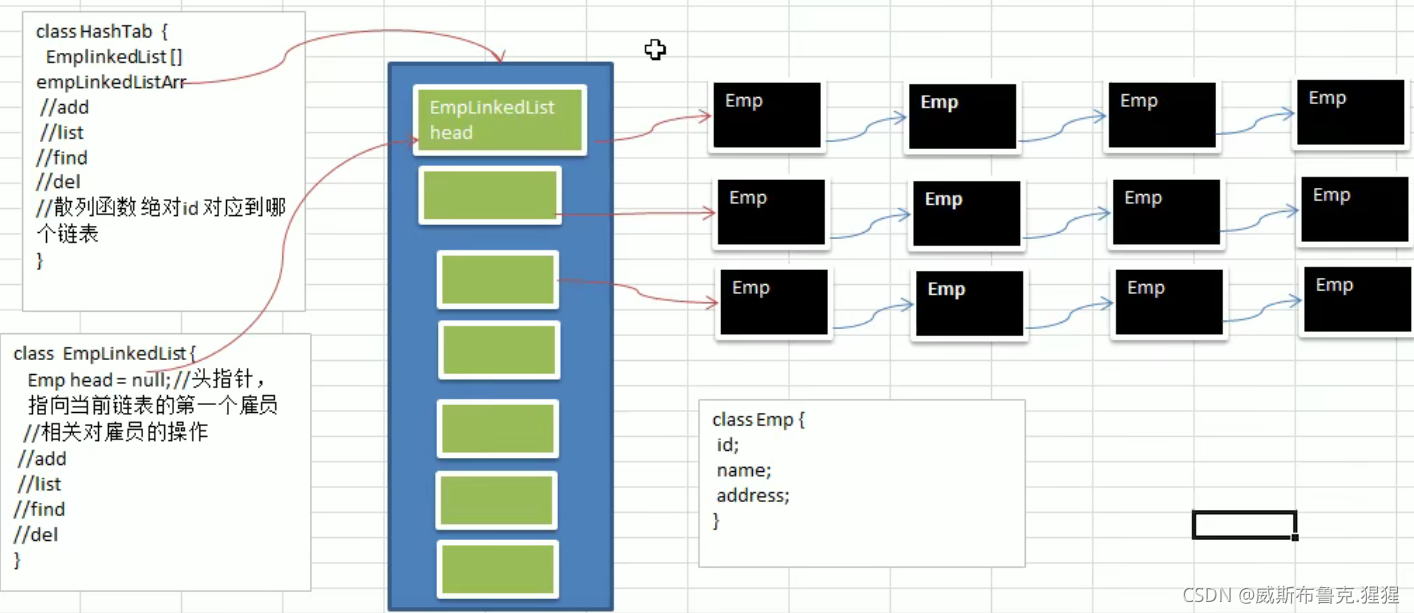
哈希表例題代碼實作
有一個公司,當有新的員工來報道時,要求將該員工的資訊加入(id,性別,年齡,名字,住址...),當輸入該員工的id時,要求查找到該員工所有資訊,
要求:
不使用資料庫,速度越快越好 => 哈希值(散列)
添加時,保證按照id從低到高插入
使用鏈表來實作哈希表,該鏈表不帶頭【即:鏈表的第一個結點就存放雇員資訊】
示意圖
public class HashTabDemo {
public static void main(String[] args) {
// 創建哈希表
HashTab hashTab = new HashTab(7);
// 寫一個簡單的選單
String key = "";
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("add: 添加雇員");
System.out.println("list:顯示雇員");
System.out.println("find:查找雇員");
System.out.println("exit:退出系統");
key = scanner.next();
switch (key) {
case "add":
System.out.println("輸入id");
int id = scanner.nextInt();
System.out.println("輸入名字");
String name = scanner.next();
// 創建雇員
Emp emp = new Emp(id, name);
hashTab.add(emp);
break;
case "list":
hashTab.list();
break;
case "find":
System.out.println("請輸入要查找的id");
id = scanner.nextInt();
hashTab.findEmpById(id);
break;
case "exit":
scanner.close();
System.exit(0);
default:
break;
}
}
}
}
//創建HashTab管理多條鏈表
class HashTab {
private EmpLinkedList[] empLinkedListArray;
private int size;// 表示有多少條鏈表
// 構造器
public HashTab(int size) {
this.size = size;
// 初始化empLinkedListArray
empLinkedListArray = new EmpLinkedList[size];
// 這時不要分別初始化每個鏈表
for (int i = 0; i < size; i++) {
empLinkedListArray[i] = new EmpLinkedList();
}
}
// 添加雇員
public void add(Emp emp) {
// 根據員工的id,得到該員工應當添加到那條鏈表
int empLinkedListNO = hashFun(emp.id);
// 將emp添加到對應的鏈表中
empLinkedListArray[empLinkedListNO].add(emp);
}
// 遍歷所有的鏈表,遍歷hashtab
public void list() {
for (int i = 0; i < size; i++) {
empLinkedListArray[i].list(i);
}
}
// 根據輸入的id,查找雇員
public void findEmpById(int id) {
// 使用散列函式確定到那條鏈表查找
int empLinkedListNO = hashFun(id);
Emp emp = empLinkedListArray[empLinkedListNO].findEmpById(id);
if (emp != null) {// 找到
System.out.printf("在第%d條鏈表中找到雇員 id = %d\n", (empLinkedListNO + 1), id);
} else {
System.out.println("在哈希表中,沒有找到該雇員~");
}
}
// 撰寫散列函式,使用一個簡單取模法
public int hashFun(int id) {
return id % size;
}
}
//表示一個雇員
class Emp {
public int id;
public String name;
public Emp next;// next默認為null
public Emp(int id, String name) {
super();
this.id = id;
this.name = name;
}
}
//創建EmplinkedList,表示鏈表
class EmpLinkedList {
// 頭指標,執行第一個Emp,因此這個鏈表的head是直接指向第一個Emp
private Emp head;// 默認null
// 添加雇員到鏈表
// 說明
// 1. 假定,當添加雇員時,id是自增長,即id的分配總是從小到大
// 因此將該雇員直接加入到本鏈表的最后即可,
public void add(Emp emp) {
// 如果是添加一個雇員
if (head == null) {
head = emp;
return;
}
// 如果不是第一個雇員,則使用一個輔助的指標,幫助定位到最后
Emp curEmp = head;
while (true) {
if (curEmp.next == null) {// 說明到鏈表最后
break;
}
curEmp = curEmp.next;// 后移
}
// 退出時直接將emp加入鏈表
curEmp.next = emp;
}
// 遍歷鏈表的雇員資訊
public void list(int no) {
if (head == null) {// 說明鏈表為空
System.out.println("第 " + (no + 1) + " 鏈表為空");
return;
}
System.out.print("第 " + (no + 1) + " 鏈表的資訊為");
Emp curEmp = head;// 輔助指標
while (true) {
System.out.printf(" => id=%d name =%s\t", curEmp.id, curEmp.name);
if (curEmp.next == null) {// 說明curEmp已經是最后節點
break;
}
curEmp = curEmp.next;// 后移,遍歷
}
System.out.println();
}
// 根據id查找雇員
// 如果查找到,就回傳Emp,如果沒有找到,就回傳null
public Emp findEmpById(int id) {
// 判斷鏈表是否為空
if (head == null) {
System.out.println("鏈表為空");
return null;
}
// 輔助指標
Emp curEmp = head;
while (true) {
if (curEmp.id == id) {// 找到
break;// 這時curEmp就指向要查找的雇員
}
// 退出
if (curEmp.next == null) {// 說明遍歷當前鏈表沒有找到該雇員
curEmp = null;
break;
}
curEmp = curEmp.next;
}
return curEmp;
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/302543.html
標籤:其他