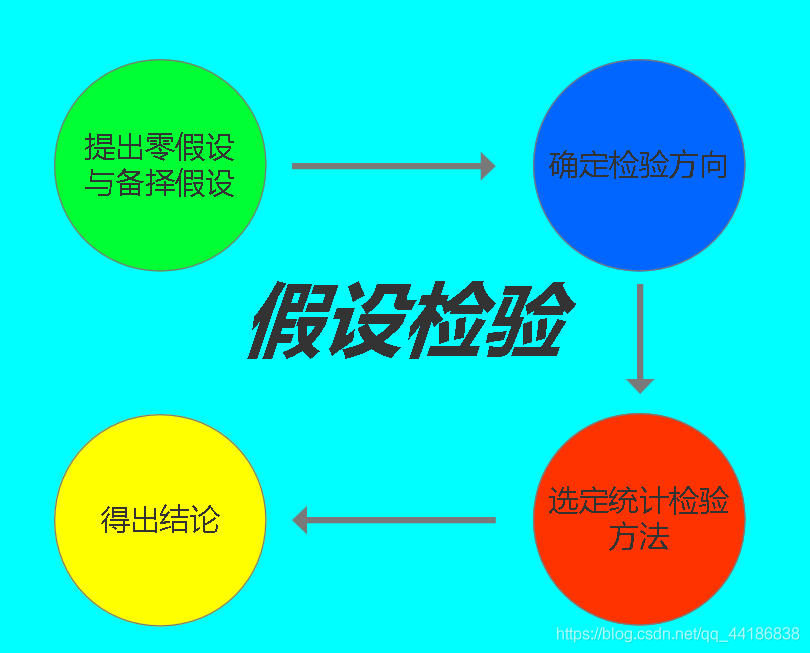
我在上一篇博客中提到了什么是ABTest,并參考了一個專案,感興趣的朋友可以再去看看,
不過,當進一步了解資料分析師的真實作業場景時,我發現參與一項需要用到ABTest的業務時,往往并比我在上一篇專案實戰時所說的復雜太多,
今天這篇是本新手認為的資料分析師在實際遇到的需要ABTest的業務時,對應的作業內容,同時也給出了每個作業所需接觸的部門和通過的標準,
平日練習題給的任務
實際遇到的需要ABTest的業務
由上述圖不難發現,實際上需要考慮的問題實在是太多太多,而不是像練習的時候懂得假設檢驗就可以了,
具體專案流程
下面,我整理了實際業務的ABTest流程(并不權威哈哈哈),大家可以看一看,
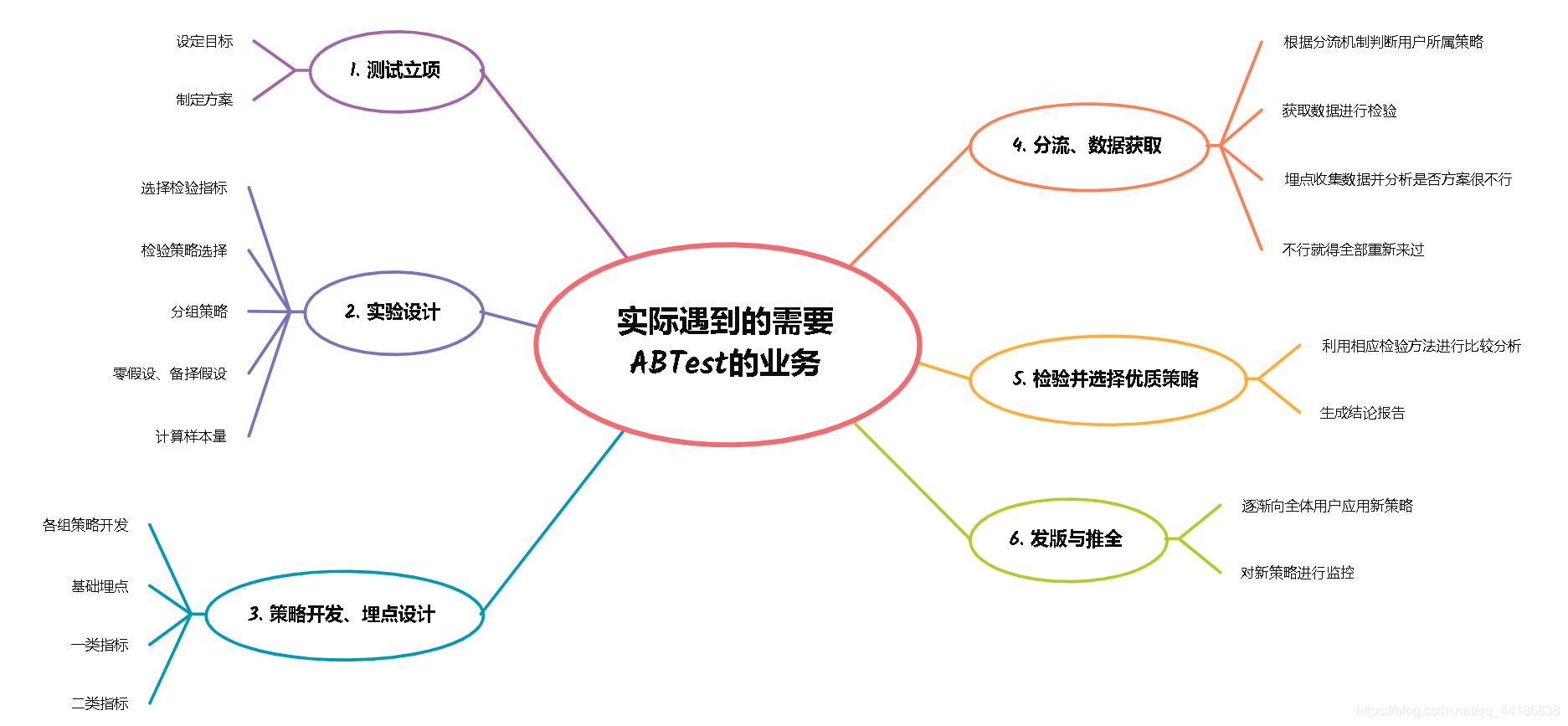
一、測驗立項
作業內容:1. 說明測驗目的:包括改進目的,改進產品位置,改進的一類、二類關鍵指標.產品改進與目的的邏輯關系;2. 說明測驗影響人群:是否是特殊人群,分流是使用正常分流還是特殊分流;3. 說明專案周期:預計分流啟動時間,預計AA測驗時間,預計灰度發布時間,預計測驗結束時間,預計結果分析時間,預計測驗復盤時間,預計發版時間,
接觸部門:增長部門、產品部門、運營部門、開發部門、產品VP(負責產品管理的重要角色)
通過標準:會議通過/VP郵件通過
二、實驗設計
實驗設計之所以不在一開始做是因為立項可能不被通過(當然啦,如果專案本身很成熟就問題不大),
作業內容:1.確定實驗方案,準備原假設與備擇假設;2.計算最小樣本,確定分流大小;
接觸部門:無
通過標準:資料分析主管通過
三、策略開發、埋點設計、分流機制
作業內容:1.開發對比策略;2設計主要埋點產出資料;3.設計存盤表結構;4.設計展示報表結構;5.設計分流機制;4.提交以上需求
接觸部門:前端開發部門、后端開發部門、資料開發部門
通過標準:各開發領導通過
四、AA測驗
作業內容:1.在分流啟動后分析各分組是否符合流量分配大小比例;2.分析各組的用戶屬性,是否符合整體用戶屬性分布,
接觸部門:前端開發部門
通過標準:資料分析主管通過
五、AB測驗、埋點資料收集
作業內容:1.在灰度策略啟動后分析各分組是否符合流量分配大小比例;2.分析各組的用戶屬性,是否符合整體用戶屬性分布;3.分析各組的埋點資料,各埋點是否正確打到對應策略組,各埋點資料是否屬性完備,
接觸部門:無
通過標準:資料分析主管通過
六、檢驗結果計算
作業內容:1.以計劃驗證試驗結果顯著性,做出資料決策;⒉推導業務層面收益,做出報告;3.試驗復盤會議,收集反饋,
接觸部門:增長部門、產品部門、運營部門、開發部門、產品VP
通過標準:會議通過/VP郵件通過
七、發版與推全
作業內容:1.對優質策略逐漸擴大流量,分階段檢驗策略有效性;2.對推全后的策略保持監控,
接觸部門:無
通過標準:資料分析師通過
資料分析師專場
在上述流程中,與資料分析師最最最密切相關的就是實驗設計和檢驗結果計算了,而這也是企業的ABTest的關鍵流程,
學習企業的ABTest的關鍵流程
1 整體實驗設計與分析流程
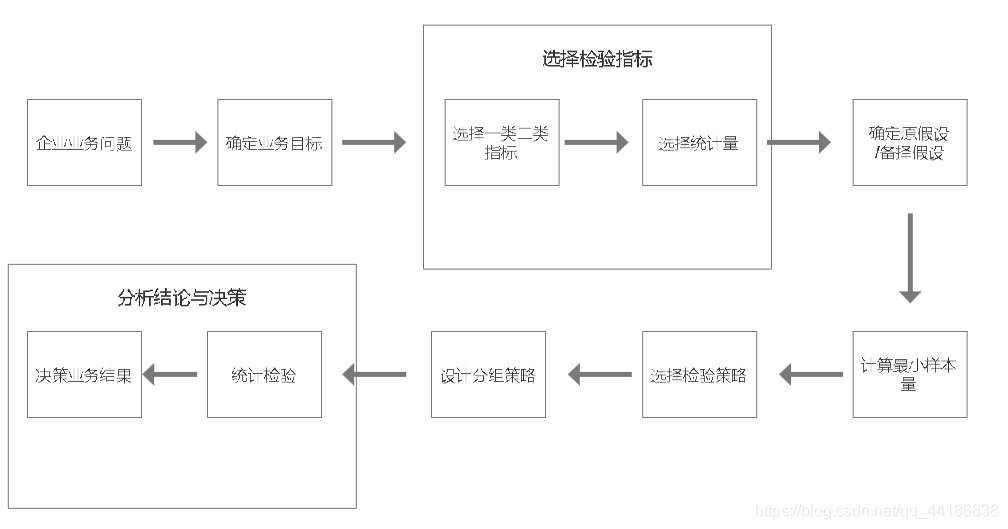
2 實驗設計
2.0 確定業務目標
- 明確我們要提升的業務指標,如日營業額提升2%或2.5%,如果明確這個部分,實驗會顯得比較精簡,目標明確;
- 明確我們要改進的產品/策略,
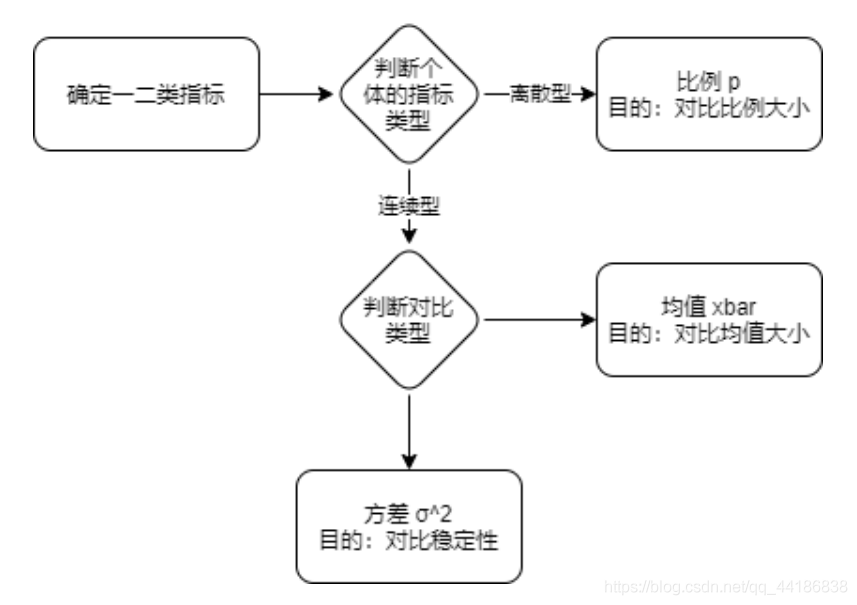
2.1 選擇檢驗指標
2.1.1 選擇一類指標
一類指標:不能容忍變差的指標;
二類指標:目標提升的指標,
如何確定一類指標?
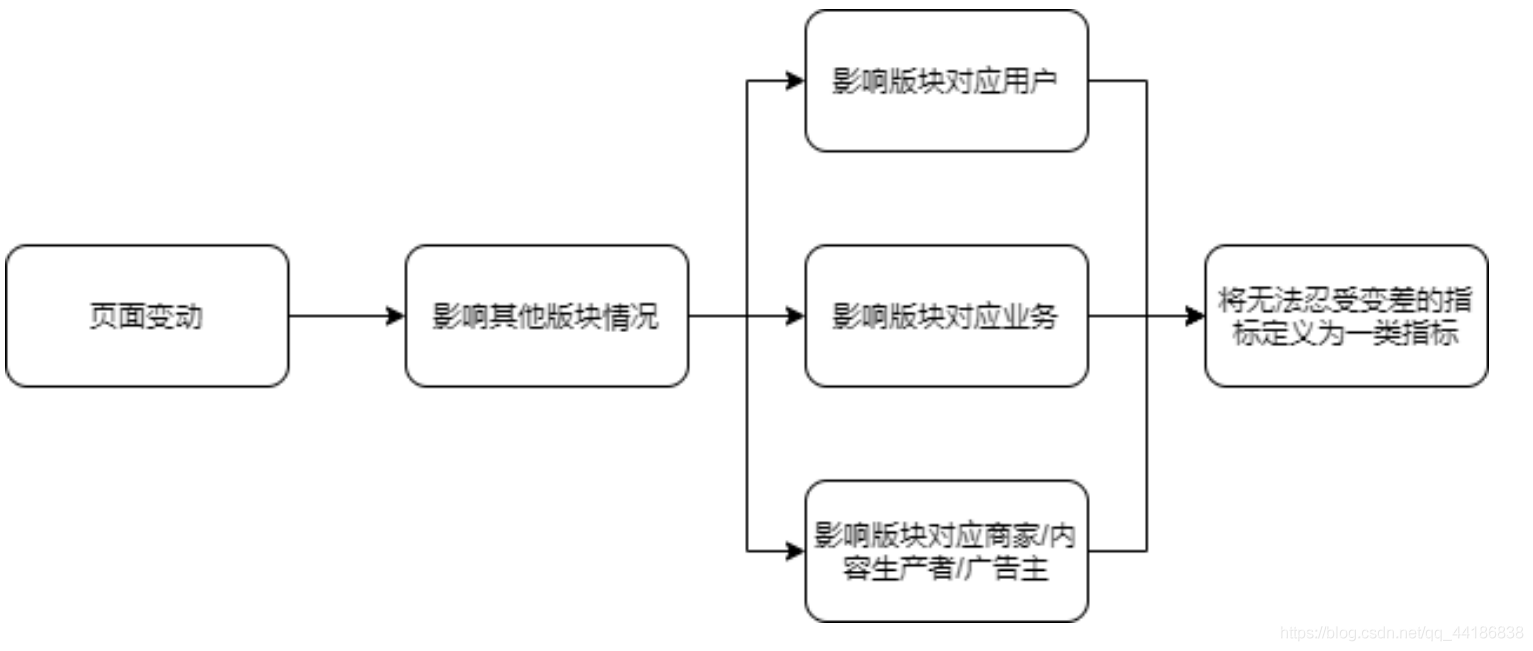
如圖,比方說我們現在想要在原本的頁面增加一個搜索框,那對應的可能會導致用戶的體驗感收到影響,原本頁面可以提供8個子鏈接可能就變成了6個子鏈接(即影響板塊對應業務),可以展示的廣告也會收到影響,這也就是圖中的三大影響(即人貨場:分析平臺類的產品,我們要將消費者、平臺方、供給方分開討論),最終選擇哪些是我們無法忍受變差的指標,將其定義為一類指標,當然,你可以考慮給對應的指標設定閾值,
場景舉例:

2.1.2 選擇統計量
2.2 確定原假設與備擇假設
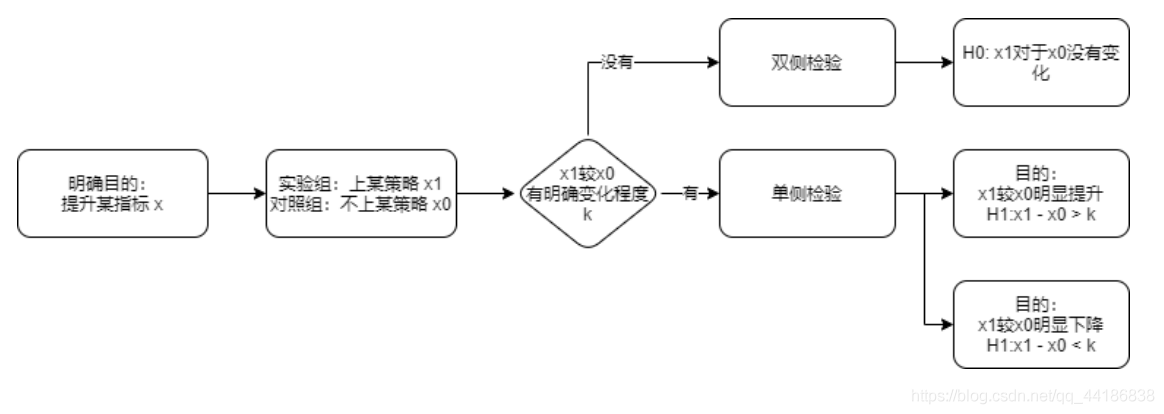
這里的x1是上策略后的水平,x0是原水平,
x1較x0有沒有明確變化程度指的是定目標的時候,除了定指標定方向外,還有沒有定優化程度,這里其實我在上篇博客講到的就是說如果明確是要提升或者明確下降的話(有>或<),就是有,反之就是沒有,而下降(<)就是左尾,提升(>)是右尾,也就是判斷位于左拒絕域還是右拒絕域,
2.3 兩類統計錯誤的防范
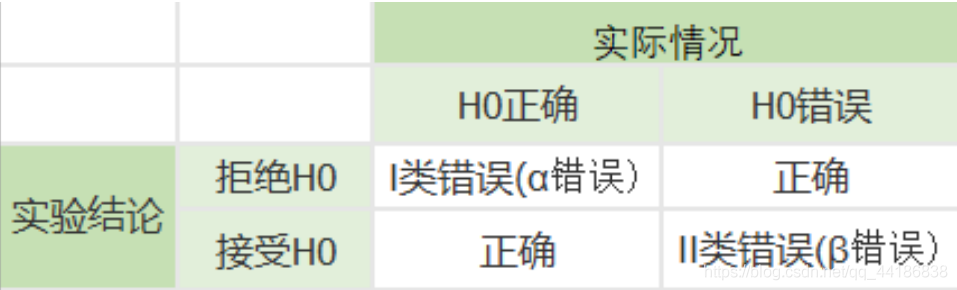
1、 α+β不一定等于1,
2、在樣本容量確定的情況下,α與β不能同時增加或減少,
3、統計檢驗效力(1-β)當H0為假時,得出拒絕H0的正確結論的概率,被稱做檢驗的效力
- I類錯誤防范 :
- 小概率α設定小些( 避免小概率的觸發)
- 增加樣本量(使例外資料的影響降低)
- II類錯誤防范:
- 調大α(增加小概率的觸發) 但是接受I類錯誤的代價遠比II類錯誤的代價要大,所以不予使用;
- II類錯誤概率只能在實驗結束后才能計算發生二類錯誤的概率,這是一個事后值,所以在事前設計我們一般不考慮這個問題,默認二類錯誤的概率為20%,
2.4 樣本量計算
統計學上根據統計量抽樣分布和邊際誤差確定樣本量,
樣本量計算工具:https://www.evanmiller.org/ab-testing/sample-size.html
業務層面是以一類錯誤臨界值二類錯誤臨界值計算,
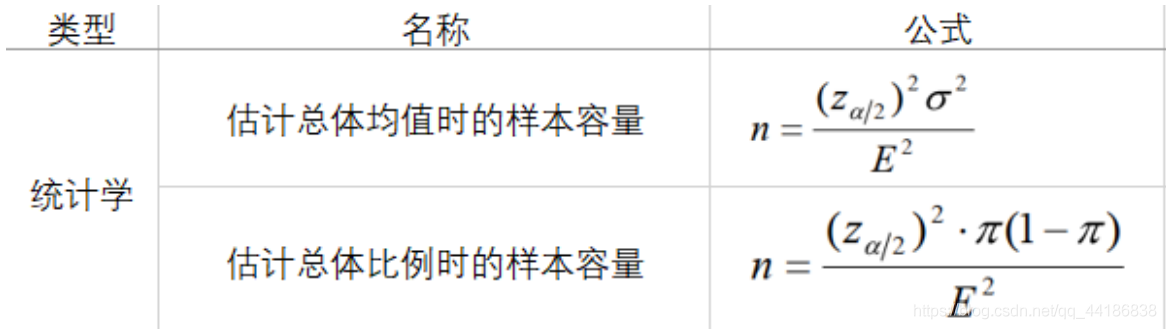
其中,區間估計算式
E
2
E^2
E2為:
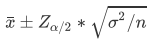
z
α
/
2
z_{\alpha/2}
zα/2?可用EXCEL中的NORM.INV算出,
不過真實業務一般是下面的情況:
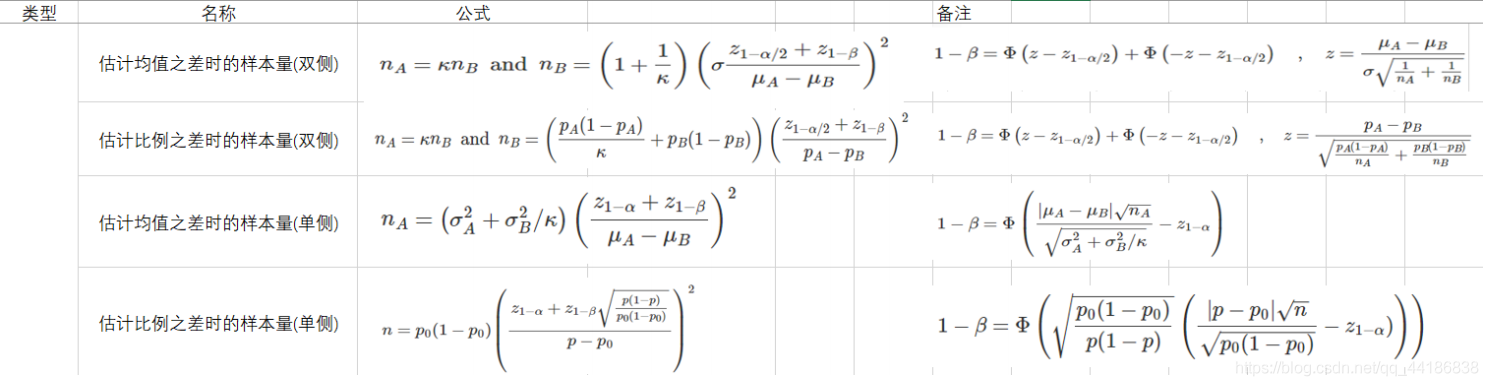
這里的
k
k
k指的是a組樣本量與b組樣本量之比,
μ
A
?
μ
B
\mu_A-\mu_B
μA??μB?是提高/降低的目標,
當沒有做抽樣,不知道實驗組總體方差時,可以用現有總體的方差代替,
2.5 檢驗策略選擇、設計分組策略
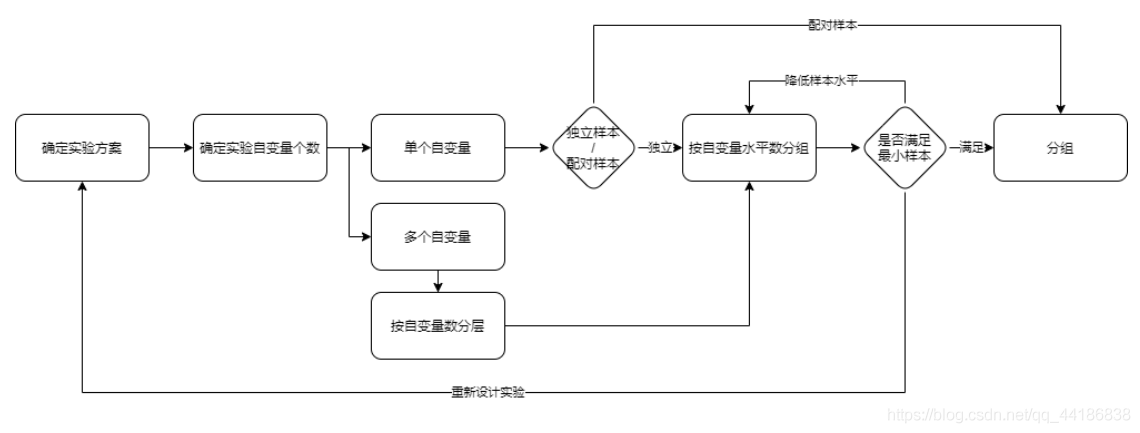
實驗自變數個數指的是我們采用策略的個數,比方說我們策略1是改變字體大小,策略2是改變字體顏色,那么此時實驗自變數個數就是2,而自變數水平數指的是策略中的幾種方案,比方改變顏色這個策略中我選擇改成紅藍綠三種顏色,那么策略2的自變數水平數就是3+1個原水平,也就是4,
通常情況下我們都算采用獨立樣本,那么什么時候會選擇配對樣本呢?
- 實驗物件十分特殊,都有某種特點;
- 實驗物件的狀態持續時間比較長;
- 實驗物件數量較少,
舉個例子,我想出了一個治療罕見疾病的方法,想做ABTest,可病人實在太少了,那這個時候就可以考慮配對樣本,(例子隨便舉的)
2.6 當企業沒有AB測驗的條件的時候,如何解決問題?
可以大致分為3中情況:
- 沒有系統,
沒有灰度發布的系統,即沒有向不同群體提供不同服務的系統,
解決方法:人工劃分群體或者線下測驗, - 用戶量不夠
解決方法:如果統計量是比例資料的話,可以提高測驗周期,如統計滴滴每日出事故的比例,可以提取一周的訂單資料;如果產品本身針對的就是小眾用戶的話,那就有點難搞了,只能考慮用簡單的對照法試著解決問題, - 時間成本高
解決方法:如果是時間跨度過長的話,考慮縮小時間跨度,比方說用周活躍率代替月活躍率;如果是轉化周期過長的話,這時候就難搞一點,比方說用戶留存率往往就需要較長時間,很難用縮短時間的方法來替代,
實驗結論分析
1 決策統計檢驗
做實驗決策可以通過統計量 及 統計量的P值來實作,
同時也可以通過樣本量分布和顯著性水平來確定拒絕域和接受域,從而拒絕或者接受結果,這里可以參考我上一篇博客,
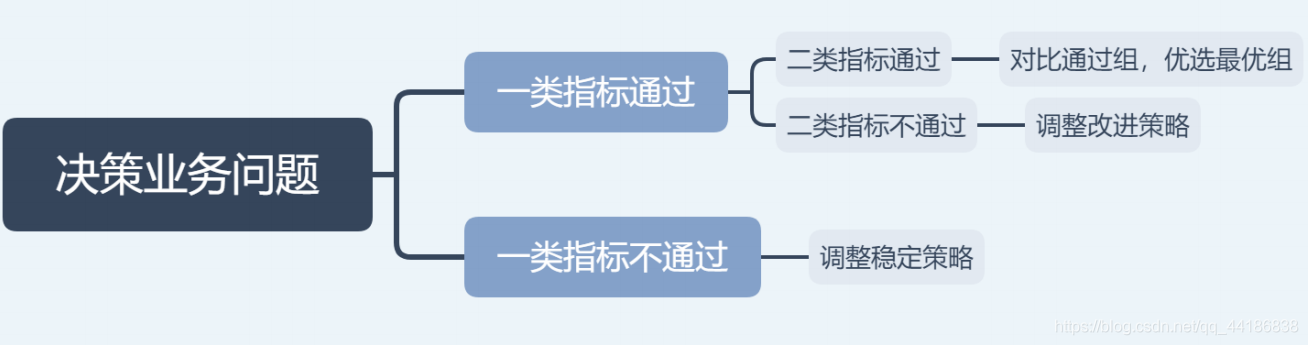
2 決策業務問題
結束語
按我目前的理解來看,以上提到的七大流程并非全由資料分析師來執行,如測驗立項中的測驗目的可能由專門的產品人員負責,專案周期可能由專案經理來負責,
資料分析師主要就是跟資料打交道,但是一個只懂資料的資料分析師不是好的資料分析師,同樣的要掌握好業務知識,懂得與產品人員溝通,
對以上內容有不認同的朋友,一切以你為準,本人新手一枚,內容僅供參考,
推薦關注的專欄
👨?👩?👦?👦 機器學習:分享機器學習實戰專案和常用模型講解
👨?👩?👦?👦 資料分析:分享資料分析實戰專案和常用技能整理
CSDN@報告,今天也有好好學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/306028.html
標籤:其他