介紹:CSDN統計字數:
77153字,Java多執行緒從入門到精通,由淺入深,[建議收藏!]
???????????? 點擊主頁發現更多好文????????????
文章目錄
- 引言
- 什么是行程,執行緒?
- 串行、并行的區別
- CPU調度演算法
- 一、Java多執行緒基礎
- 創建執行緒的方式
- 1.繼承`Thread`類創建執行緒
- 2.實作`Runnable`介面創建執行緒
- 3.使用匿名內部類形式創建執行緒
- 4.使用`Lambda`運算式創建
- 5.使用`Callable`和 `Future`創建執行緒
- 6.使用執行緒池創建
- 7.Spring中的`@Async`創建
- `Thread`中的常用的方法
- 執行緒的狀態
- 階段案例:手寫`@Async`異步注解
- 二、執行緒安全原理篇
- 執行緒安全問題
- 原子性(Atomic):
- 可見性(visbility):
- 有序性(Ordering):
- 重排序與happens-before
- 重排序
- happens-before
- JVM與JMM
- JVM運行時資料區
- JMM模型
- JMM與Java記憶體區域劃分的區別與聯系
- 出現執行緒不安全的例子:
- 三、執行緒同步
- 鎖的概念
- 內部鎖:synchronized
- 死鎖的問題
- volatile
- volatile作用
- volatile 與 synchronized比較
- volatile 非原子特性
- 常用原子類進行自增自減操作
- CAS
- 使用CAS實作執行緒安全的計數器
- CAS中的ABA問題
- 原子變數類
- 使用AtomicLong定義計數器
- AtomicIntegerArray
- 多執行緒中使用原子陣列
- AtomicIntegerFieldUpdater更新欄位
- AtomicReference
- AtomicReference的ABA問題
- 四、執行緒間的通信
- 等待/通知機制
- interrupt()方法會中斷wait()
- notify()與notifyAll()
- wait(long)
- 通知過早
- wait() 等待條件發生了變化
- 生產者消費者模式
- 通過管道實作執行緒間的通信
- join()
- 五、Callable與Future
- Callable介面
- Future介面
- FutureTask類
- FutureTask的幾個狀態
- 六、ThreadLocal()
- API介紹
- ThreadLocal使用場景
- 七、顯示鎖Lock
- Lock中的方法
- lock()
- tryLock()
- lockInterruptibly()
- unlock()
- newCondition()
- Condition
- 實體:兩個執行緒交替列印
- ReetntranLock
- 常用方法
- synchronized與ReetntranLock
- ReadWriteLock
- 讀寫鎖和排它鎖
- ReentrantReadWriteLock
- 讀讀共享實體
- 寫寫互斥實體
- 讀寫互斥實體
- AQS
- state狀態
- 自定義資源共享方式
- 八、執行緒的管理
- *執行緒組*
- 執行緒組的基本使用
- 捕獲執行緒的執行例外
- 注入Hook鉤子執行緒
- 執行緒池
- 什么是執行緒池
- ThreadPoolExecutor的構造方法
- ThreadPoolExecutor的策略
- 執行緒池主要的任務處理流程
- ThreadPoolExecutor如何做到執行緒復用的?
- 自定義執行緒工廠
- 監控執行緒池的方法
- 執行緒池中的例外跟蹤
- 四種常見的執行緒池
- **submit()和execut的區別:**
- 1.newCachedThreadPool
- 2.newFixedThreadPool
- 3.newSingleThreadExecutor
- 4.newScheduledThreadPool
- ForkJoinPoll
- 九、保障執行緒安全的設計技術
- 1.Java運行時存盤空間
- 2.無狀態物件
- 3.不可變物件
- 4.執行緒特有物件
- 5.裝飾器模式
- 十、鎖的優化及注意事項
- 減少鎖持有時間
- 減小鎖的粒度
- 使用讀寫分離鎖代替獨占鎖
- 鎖分離
- 粗鎖化
- JVM鎖優化
- 量級鎖
- 自旋鎖
- 鎖消除
- 多執行緒開發良好的實踐
引言
什么是行程,執行緒?
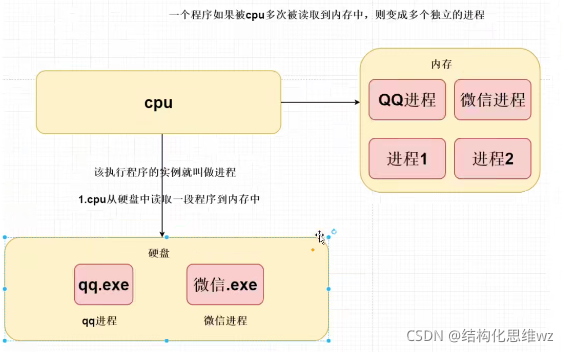
行程 :資源分配的最小單位,cpu從磁盤中讀取一段程式到記憶體中,該執行程式的實體就叫做行程,一個程式如果被cpu多次讀取到記憶體中,則變成多個獨立的行程,
執行緒 : 執行緒是程式執行的最小單位,在一個行程中可以有多個不同的執行緒,
執行緒的應用實體:
同一個應用程式中(行程),更好的并行處理,
例子:手寫一個文本編輯器需要多少個執行緒?
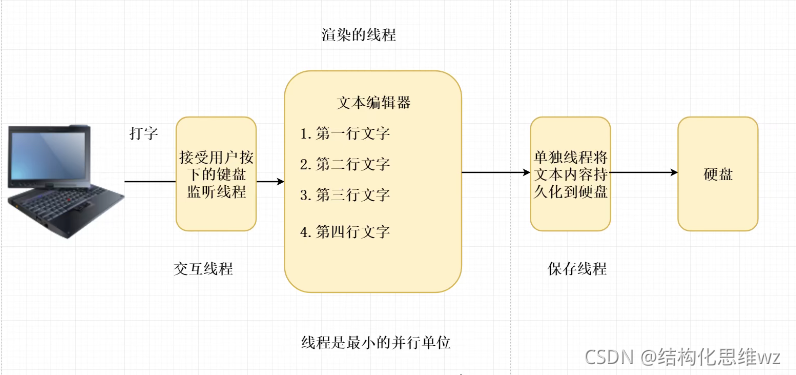
為什么需要使用多執行緒?
采用多執行緒的形式執行代碼,目的是為了提高程式開發的效率,
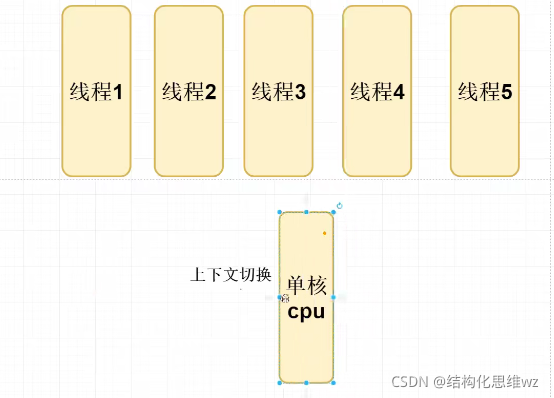
串行、并行的區別
CPU分時間片交替執行,宏觀并行,微觀串行,由OS負責調度,如今的CPU已經發展到了多核CPU,真正存在并行,
CPU調度演算法
多執行緒是不是一定提高效率? 不一定,需要了解cpu調度的演算法,
CPU調度演算法:
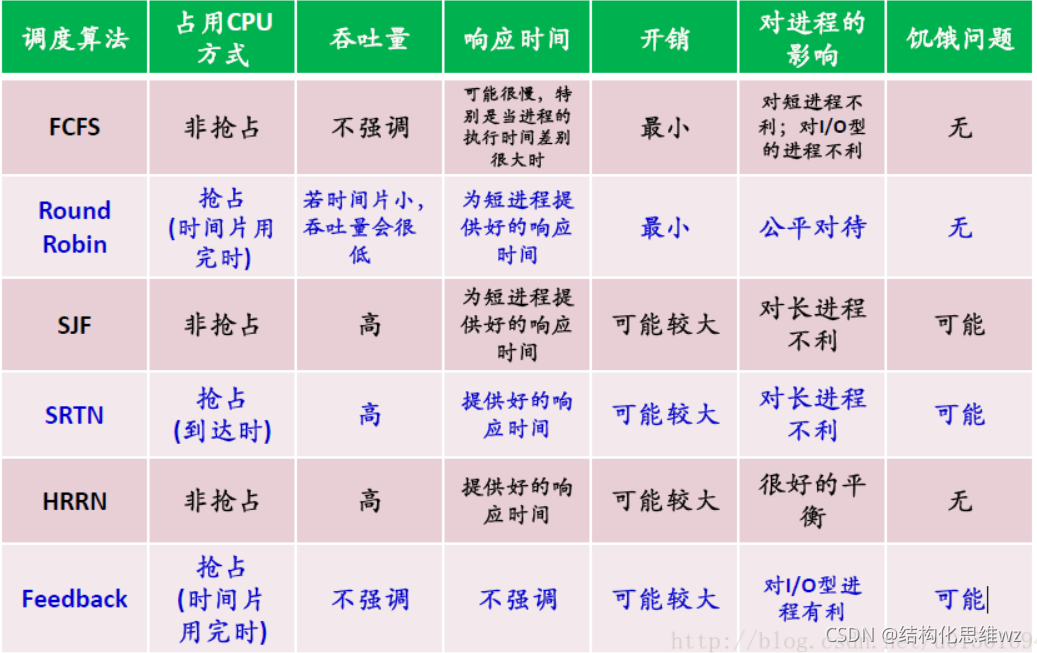
如果在生產環境中,開啟很多執行緒,但是我們的服務器核數很低,我們這么多執行緒會在cpu上做背景關系切換,反而會降低效率,
使用執行緒池來限制執行緒數和cpu數相同會比較好,
一、Java多執行緒基礎
創建執行緒的方式
- 繼承
Thread類創建執行緒 - 實作
Runnable介面創建執行緒 - 使用匿名內部類形式創建執行緒
- 使用
Lambda運算式創建 - 使用
Callable和Future創建執行緒 - 使用執行緒池創建
- Spring中的
@Async創建
1.繼承Thread類創建執行緒
public class ThreadTest extends Thread{
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("子執行緒,執行緒一");
}
}
/* 創建物件進入初始狀態,呼叫start()進入就緒狀態,直接呼叫run()方法,相當于在main中執行run,并不是新執行緒*/
public static void main(String[] args) {
new ThreadTest().start();
}
}
2.實作Runnable介面創建執行緒
public class Thread02 implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"我是子執行緒");
}
public static void main(String[] args) {
new Thread(new Thread02()).start();
}
}
3.使用匿名內部類形式創建執行緒
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"我是子執行緒");
}
}).start();
}
4.使用Lambda運算式創建
public class Thread02 {
public static void main(String[] args) {
new Thread(() -> System.out.println(Thread.currentThread().getName()+"我是子執行緒")).start();
}
}
5.使用Callable和 Future創建執行緒
Callable和Future執行緒可以獲取到回傳結果,底層基于LockSupport, (這里只是略寫,后面有詳細介紹)
Runnable的缺點:
1. run沒有回傳值
2. 不能拋例外
Callable介面允許執行緒有回傳值,也允許執行緒拋出例外
Future介面用來接受回傳值
public class Thread03 implements Callable<Integer> {
/**
* 當前執行緒需要執行的代碼,回傳結果
* @return 1
* @throws Exception
*/
@Override
public Integer call() throws Exception {
System.out.println(Thread.currentThread().getName()+"回傳1");
return 1;
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread03 callable = new Thread03();
FutureTask<Integer> integerFutureTask = new FutureTask<Integer>(callable);
new Thread(integerFutureTask).start();
//通過api獲取回傳結果,主執行緒需要等待子執行緒回傳結果
Integer result = integerFutureTask.get();
System.out.println(Thread.currentThread().getName()+","+result); // main,1
}
6.使用執行緒池創建
public class ThreadExecutor {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"我是子執行緒1");
}
});
executorService.submit(new Thread03()); //submit一個執行緒到執行緒池
}
}
7.Spring中的@Async創建
第一步:在入口類中開啟異步注解
@SpringBootApplication
@EnableAsync
第二步:在當前方法上加上@Async
@Component
@Slf4j
public class Thread01 {
@Async
public void asyncLog(){
try {
Thread.sleep(3000);
log.info("<2>");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
第三步:驗證測驗
@RestController
@Slf4j
public class Service {
@Autowired
private Thread01 thread01;
@RequestMapping("test")
public String Test(){
log.info("<1>");
thread01.asyncLog();
log.info("<3>");
return "test";
}
}
訪問localhost:8080/test查看日志為:

Thread中的常用的方法
1.Thread.currentThread() 方法可以獲得當前執行緒
java中的任何一段代碼都是執行在某個執行緒當中的,執行當前代碼的執行緒就是當前執行緒,
2.setName()/getName
thread.setName(執行緒名稱) //設定執行緒名稱
thread.getName() //回傳執行緒名稱
通過設定執行緒名稱,有助于除錯程式,提高程式的可讀性,建議為每個執行緒都設定一個能夠體現執行緒功能的名稱,
3.isAlive()
thread.isAlive() //判斷當前執行緒是否處于活動狀態
4.sleep()
Thread.sleep(millis); //讓當前執行緒休眠指定的毫秒數
實體:計時器(一分鐘倒計時)
package se.high.thread;
/**
* @author 王澤
* 使用執行緒休眠,實作一個簡單的計數器,
*/
public class SimpleTimer {
public static void main(String[] args) {
int remaining = 10 ; //從60秒開始計時
while(true){
try {
System.out.println("時間: " + remaining);
if (remaining >= 0){ remaining--; }
Thread.sleep(1000); //執行緒休眠
if(remaining == -1){break;}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
5.getId() java中的執行緒都有一個唯一編號
6.yield() 放棄當前的cpu資源
Thread.yield(); //可以讓執行緒由運行轉為就緒狀態
7.setPriority() 設定執行緒的優先級
thread.setPriority(num); 設定執行緒的優先級,取值為1-10,如果超過范圍會拋出例外 IllegalArugumentExption;
優先級越高的執行緒,獲得cpu資源的概率越大,
優先級本質上只是給執行緒調度器一個提示資訊,以便于執行緒調度器決定先調度哪些執行緒,不能保證優先級高的執行緒先運行,
java優先級設定不當,可能導致某些執行緒永遠無法得到運行,產生了執行緒饑餓,
執行緒的優先級并不是設定的越高越好,在開發時不必設定執行緒的優先級,
8.interrupt()中斷執行緒 (Thread中的方法,)
因為interrupt()方法只能中斷阻塞程序中的執行緒而不能中斷正在運行程序中的執行緒,
在運行中的執行緒使用:
注意呼叫此方法僅僅是在當前執行緒打一個停止標志,并不是真正的停止執行緒,
例如在執行緒1中呼叫執行緒b的interrupt(),在b執行緒中監聽b執行緒的中斷標志,來處理結束,
package se.high.thread;
/**
* @author 王澤
*/
public class YieldTest extends Thread {
@Override
public void run() {
for (int i = 1; i < 1000; i++) {
// 判斷中斷標志
if (this.isInterrupted()){
//如果為true,結束執行緒
//break;
return;
}
System.out.println("thread 1 --->"+i);
}
}
}
package se.high.thread;
/**
* @author 王澤
*/
public class Test {
public static void main(String[] args) {
YieldTest t1 = new YieldTest();
t1.start(); //開啟子執行緒
//當前執行緒main執行緒
for (int i = 1; i < 100; i++) {
System.out.println("main --->" + i);
}
//列印完main執行緒中100個后,中斷子執行緒,僅僅是個標記,必須在執行緒中處理
t1.interrupt();
}
}
9.setDaemon() 守護執行緒
//執行緒啟動前
thread.setDaemon(true);
thread.start();
java中的執行緒分為用戶執行緒與守護執行緒
守護執行緒是為其他執行緒提供服務的執行緒,如垃圾回收(GC)就是一個典型的守護執行緒,
守護執行緒不能單獨運行,當jvm中沒有其他用戶執行緒,只有守護執行緒時,守護執行緒會自動銷毀,jvm會自動退出,
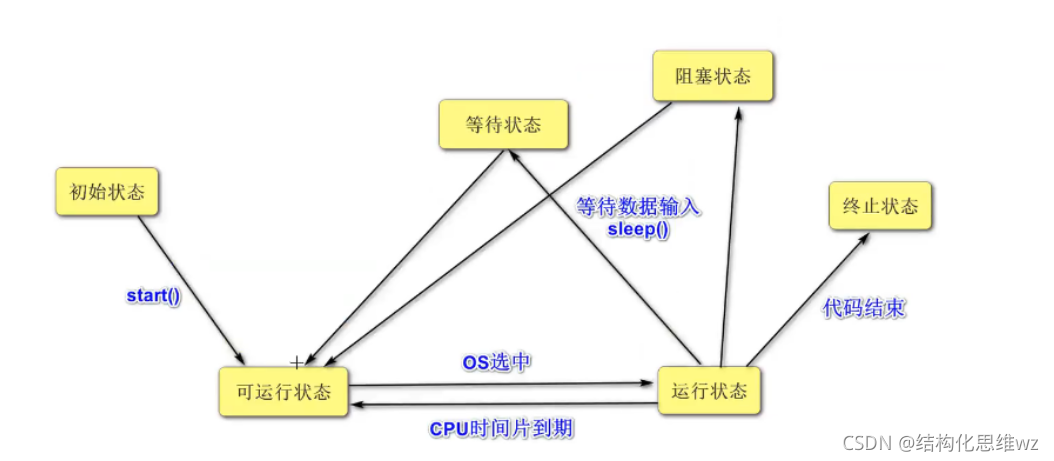
執行緒的狀態
執行緒的狀態:getState()
階段案例:手寫@Async異步注解
思路:通過Aop攔截只要在我們方法上有使用到我們自己定義的異步注解,我們就單獨的開啟一個異步執行緒去執行目標方法,
1.自定義一個注解
/**
* @author 王澤
*/
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MyAsync {
String value() default "";
}
2.Aop編程
@Aspect 用來類上,代表這個類是一個切面
@Before 用在方法上代表這個方法是一個前置通知方法
@After 用在方法上代表這個方法是一個后置通知方法 @Around 用在方法上代表這個方法是一個環繞的方法
@Around 用在方法上代表這個方法是一個環繞的方法
*/
@Component
@Aspect
@Slf4j
public class ExtThreadAsyncAop {
@Around(value ="@annotation(org.spring.annotation.MyAsync)")
public Object around(ProceedingJoinPoint joinPoint){
try {
log.info(">環繞通知開始執行<");
new Thread(new Runnable() {
@SneakyThrows
@Override
public void run() {
joinPoint.proceed();//目標方法
}
}).start();
log.info(">環繞通知結束執行<");
return "環繞通知";
}catch (Throwable throwable){
return "系統錯誤";
}
}
}
3.使用自定義注解
@Component
@Slf4j
public class Thread01 {
@MyAsync
public void asyncLog(){
try {
log.info("目標方法正在執行...阻塞3s");
Thread.sleep(3000);
log.info("<2>");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
4.測驗
/**
* @author 王澤
*/
@RestController
@Slf4j
public class Service {
@Autowired
private Thread01 thread01;
@RequestMapping("test")
public String Test(){
log.info("<1>");
thread01.asyncLog();
log.info("<3>");
return "test";
}
}
5.結果:

二、執行緒安全原理篇
多執行緒的好處:
- 提高了系統的
吞吐量,多執行緒編程可以使一個行程有多個并發(concurrent), - 提高
回應性,服務器會采用一些專門的執行緒負責用戶的請求處理,縮短了用戶的等待時間, 充分利用多核處理器資源,通過多執行緒可以充分的利用CPU資源,
多執行緒的問題:
-
執行緒安全問題,多執行緒共享資料時,如果沒有采取正確的并發訪問控制措施,就可能產生資料一致性問題,如讀取臟資料(過期的資料),如丟失資料更新, -
執行緒活性(thread liveness)問題,由于程式自身的缺陷或者由資源稀缺性導致的執行緒一直處于非RUNNABLE狀態,這就是執行緒活性問題,常見的執行緒活性問題:
1.
死鎖 (DeadLock)鷸蚌相爭
2.鎖死 (Lockout)睡美人故事中王子掛啦
3.活鎖 (LiveLock)類似小貓一直咬自己的尾巴,但是咬不到
4.饑餓 (Starvation)類似于健壯的雛鳥總是從母鳥嘴中搶食物, -
背景關系切換(Context Switch)處理器從執行一個執行緒切換到執行另外一個執行緒, -
可靠性可能會由一個執行緒導致JVM意外終止,其他執行緒也無法執行,
執行緒安全問題
什么是執行緒安全問題?
當多個執行緒對同一個物件的實體變數,做寫(修改)的操作時,可能會受到其他執行緒的干擾,發生執行緒安全的問題,
原子性(Atomic):
不可分割,訪問(讀,寫)某個共享變數的時候,從其他執行緒來看,該操作要么已經執行完畢,要么尚未發生,其他執行緒看不到當前操作的中間結果, 訪問同一組共享變數的原子操作是不能夠交錯的,如現實生活中從ATM取款,
java中有兩種方式實作原子性:
1.鎖 :鎖具有排他性,可以保證共享變數某一時刻只能被一個執行緒訪問,
2.CAS指令 :直接在硬體層次上實作,看做是一個硬體鎖,
可見性(visbility):
在多執行緒環境中,一個執行緒對某個共享變數更新之后,后續其他的執行緒可能無法立即讀到這個更新的結果,
如果一個執行緒對共享變數更新之后,后續訪問該變數的其他執行緒可以讀到更新的結果,稱這個執行緒對共享變數的更新對其他執行緒可見,否則稱這個執行緒對共享變數的更新對其他執行緒不可見,
多執行緒程式因為可見性問題可能會導致其他執行緒讀取到舊資料(臟資料),
有序性(Ordering):
是指在什么情況下一個處理器上運行的一個執行緒所執行的 記憶體訪問操作在另外一個處理器運行的其他執行緒來看是亂序的(Out of Order)
亂序: 是指記憶體訪問操作的順序看起來發生了變化,
重排序與happens-before
重排序
一個處理器上執行的多個操作,在其他處理器來看它的順序與目標代碼執行的順序可能不一致,這種現象成為重排序,(不是必然出現)
在多核處理器的環境下,撰寫的順序結構,這種操作執行的順序可能是沒有保障的:
-
編譯器可能會改變兩個程式的先后順序;
-
處理器也可能不會按照目標代碼的順序執行;
重排序是對記憶體訪問有序操作的一種優化,可以在不影響單執行緒程式正確的情況下提升程式的性能,但是可能對多執行緒程式的正確性產生影響,即可能導致執行緒安全問題,
-
指令重排序(確實排序了) JVM
計算機在執行程式時,為了提高性能,編譯器和處理器常常會對指令做重排,
原始碼順序與程式順序不一致,或者程式順序與執行順序不一致的情況下,我們就說發生了指令重排序(Instruction Reorder).
javac編譯器一般不會執行指令重排序,而JIT編譯器可能執行指令重排序,指令重排對于提高CPU處理性能十分必要,雖然由此帶來了亂序的問題,但是這點犧牲是值得的,
指令重排一般分為以下三種:
-
編譯器優化重排
編譯器在不改變單執行緒程式語意的前提下,可以重新安排陳述句的執行順序,
-
指令并行重排
現代處理器采用了指令級并行技術來將多條指令重疊執行,如果不存在資料依賴性(即后一個執行的陳述句無需依賴前面執行的陳述句的結果),處理器可以改變陳述句對應的機器指令的執行順序,
-
記憶體系統重排
由于處理器使用快取和讀寫快取沖區,這使得加載(load)和存盤(store)操作看上去可能是在亂序執行,因為三級快取的存在,導致記憶體與快取的資料同步存在時間差,
-
-
存盤子系統重排序(沒有真正的排序) CPU
存盤子系統是指寫緩沖器與高速快取,
高速快取(Cache)是CPU中為了匹配與主記憶體處理速度不匹配兒設計的一個高速快取,
寫緩沖器(Store buffer,Wirte buffer) 用來提高寫高速快取操作的效率,
即使處理器嚴格按照程式順序執行兩個記憶體訪問操作,在存盤子系統的作用下,其他處理器對這兩個操作的感知順序與程式順序不一致,
從處理器角度來看,讀記憶體就是從指定的RAM地址中加載資料到暫存器,成為Load操作;寫記憶體就是把資料存盤到指定的地址表示的RAM存盤單元中,稱為Store操作,記憶體重排序有以下四中可能:
- LoadLoad重排序,在一個處理器上先后執行兩個讀操作L1和L2,其他處理器對這兩個記憶體操作的感知順序可能是先L2,
- StoreStore重排序,一個處理器上先后執行兩個寫操作W1和W2,其他處理器對兩個記憶體操作的感知順序可能是先W2,
- LoadStore重排序,一個處理器上先執行讀記憶體L1再執行寫記憶體W1,其他記憶體感知順序可能是W1在前,
- StoreLoad重排序,一個處理器上先執行寫操作W1再執行讀記憶體L1,其他記憶體感知順序可能是L1在前,
記憶體重排序與具體的處理器微架構有關,不同架構的處理器所允許的記憶體重排序不同,記憶體重排序可能會導致執行緒的安全問題,
-
貌似串行語意
JIt編譯器,處理器,存盤子系統是按照一定的規則對指令,記憶體操作的結果進行重排序,給單執行緒程式造成一種假象–指令是按照原始碼順序執行的,這種假象稱為貌似串行語意,并不能保證多執行緒環境程式的正確性,
不存在資料依賴關系可能重排序,
存在控制依賴關系的陳述句允許重排,(如先執行if陳述句,在執行判斷條件)
保證記憶體訪問的順序性
可以使用volatile關鍵字,synchronized關鍵字實作有序性,
happens-before
一方面,程式員需要JMM提供一個強的記憶體模型來撰寫代碼;另一方面,編譯器和處理器希望JMM對它們的束縛越少越好,這樣它們就可以最可能多的做優化來提高性能,希望的是一個弱的記憶體模型,
JMM考慮了這兩種需求,并且找到了平衡點,對編譯器和處理器來說,只要不改變程式的執行結果(單執行緒程式和正確同步了的多執行緒程式),編譯器和處理器怎么優化都行,
而對于程式員,JMM提供了happens-before規則(JSR-133規范),滿足了程式員的需求——**簡單易懂,并且提供了足夠強的記憶體可見性保證,**換言之,程式員只要遵循happens-before規則,那他寫的程式就能保證在JMM中具有強的記憶體可見性,
JMM使用happens-before的概念來定制兩個操作之間的執行順序,這兩個操作可以在一個執行緒以內,也可以是不同的執行緒之間,因此,JMM可以通過happens-before關系向程式員提供跨執行緒的記憶體可見性保證,
happens-before關系的定義如下:
- 如果一個操作
happens-before另一個操作,那么第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前, - 兩個操作之間存在happens-before關系,并不意味著Java平臺的具體實作必須要按照happens-before關系指定的順序來執行,如果重排序之后的執行結果,與按happens-before關系來執行的結果一致,那么JMM也允許這樣的重排序,
as-if-serial語意保證單執行緒內重排序后的執行結果和程式代碼本身應有的結果是一致的,happens-before關系保證正確同步的多執行緒程式的執行結果不被重排序改變,
總之,如果操作A happens-before操作B,那么操作A在記憶體上所做的操作對操作B都是可見的,不管它們在不在一個執行緒,
在Java中,有以下天然的happens-before關系:
- 程式順序規則:一個執行緒中的每一個操作,happens-before于該執行緒中的任意后續操作,
- 監視器鎖規則:對一個鎖的解鎖,happens-before于隨后對這個鎖的加鎖,
- volatile變數規則:對一個volatile域的寫,happens-before于任意后續對這個volatile域的讀,
- 傳遞性:如果A happens-before B,且B happens-before C,那么A happens-before C,
- start規則:如果執行緒A執行操作ThreadB.start()啟動執行緒B,那么A執行緒的ThreadB.start()操作happens-before于執行緒B中的任意操作、
- join規則:如果執行緒A執行操作ThreadB.join()并成功回傳,那么執行緒B中的任意操作happens-before于執行緒A從ThreadB.join()操作成功回傳,
JVM與JMM
JVM運行時資料區
先談一下運行時資料區,下面這張圖相信大家一點都不陌生:
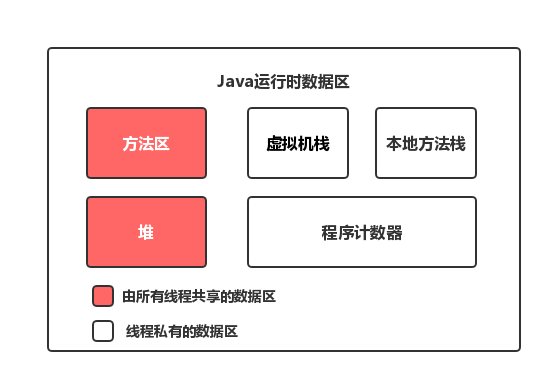
對于每一個執行緒來說,堆疊都是私有的,而堆是共有的,
也就是說在堆疊中的變數(區域變數、方法定義引數、例外處理器引數)不會在執行緒之間共享,也就不會有記憶體可見性(下文會說到)的問題,也不受記憶體模型的影響,而在堆中的變數是共享的,本文稱為共享變數,
所以,記憶體可見性是針對的共享變數,
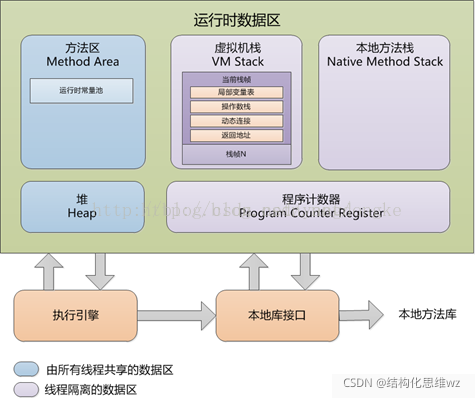
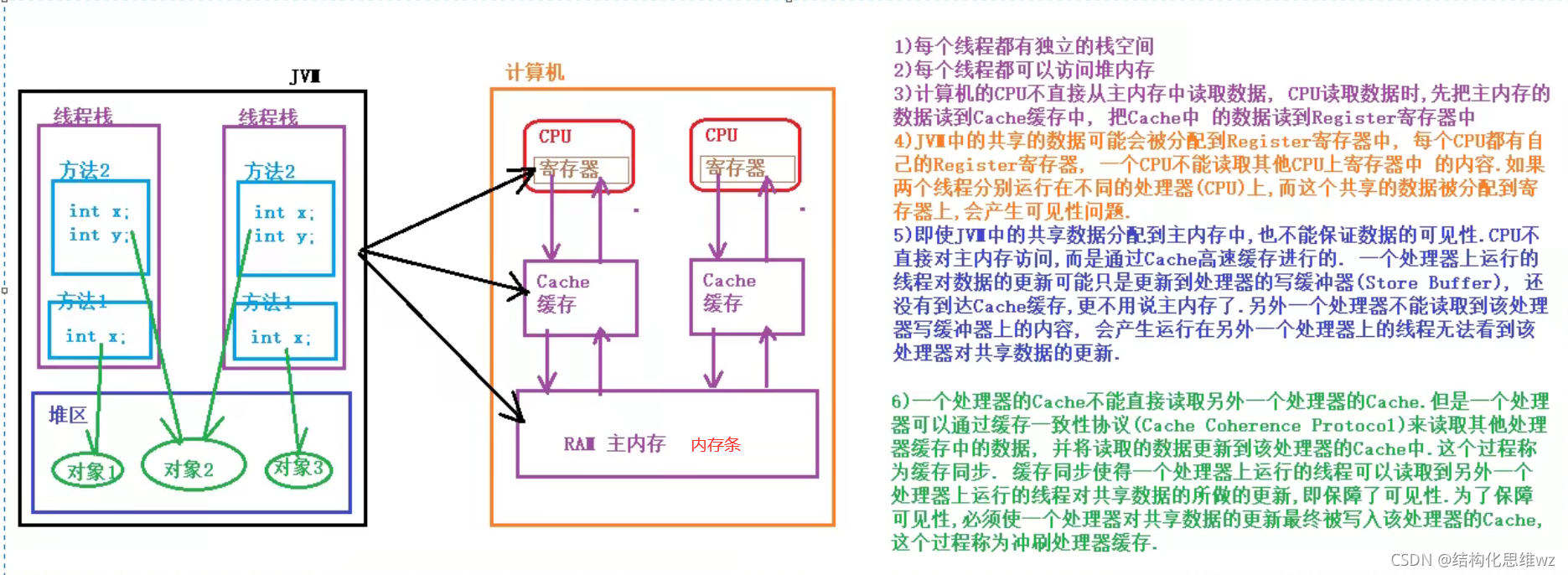
JMM模型
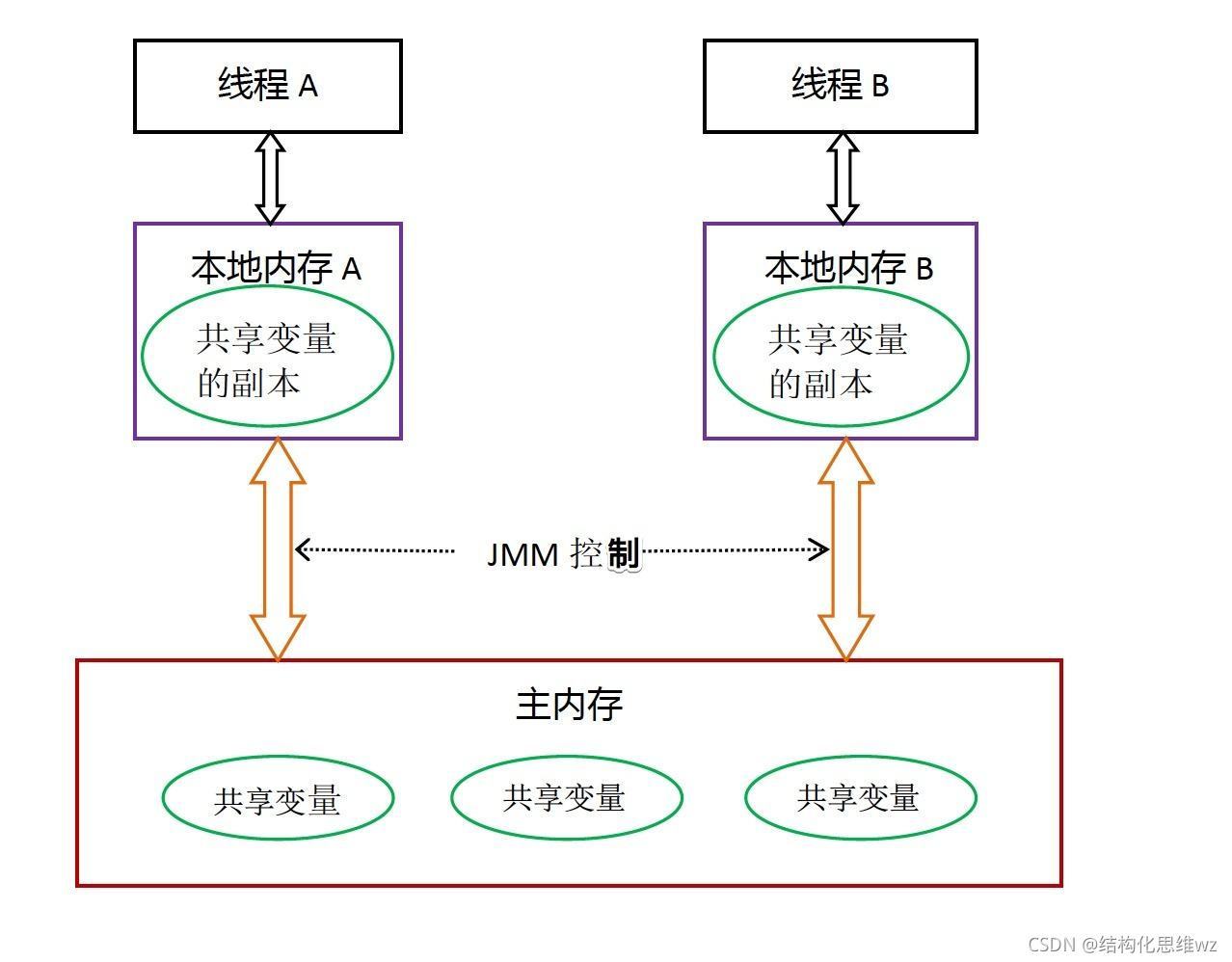
從圖中可以看出:
- 所有的共享變數都存在主記憶體中,
- 每個執行緒都保存了一份該執行緒使用到的共享變數的副本,
- 如果執行緒A與執行緒B之間要通信的話,必須經歷下面2個步驟:
- 執行緒A將本地記憶體A中更新過的共享變數重繪到主記憶體中去,
- 執行緒B到主記憶體中去讀取執行緒A之前已經更新過的共享變數,
所以,執行緒A無法直接訪問執行緒B的作業記憶體,執行緒間通信必須經過主記憶體,
注意,根據JMM的規定,執行緒對共享變數的所有操作都必須在自己的本地記憶體中進行,不能直接從主記憶體中讀取,
所以執行緒B并不是直接去主記憶體中讀取共享變數的值,而是先在本地記憶體B中找到這個共享變數,發現這個共享變數已經被更新了,然后本地記憶體B去主記憶體中讀取這個共享變數的新值,并拷貝到本地記憶體B中,最后執行緒B再讀取本地記憶體B中的新值,
那么怎么知道這個共享變數的被其他執行緒更新了呢?這就是JMM的功勞了,也是JMM存在的必要性之一,JMM通過控制主記憶體與每個執行緒的本地記憶體之間的互動,來提供記憶體可見性保證,
Java中的volatile關鍵字可以保證多執行緒操作共享變數的可見性以及禁止指令重排序,synchronized關鍵字不僅保證可見性,同時也保證了原子性(互斥性),在更底層,JMM通過記憶體屏障來實作記憶體的可見性以及禁止重排序,為了程式員的方便理解,提出了happens-before,它更加的簡單易懂,從而避免了程式員為了理解記憶體可見性而去學習復雜的重排序規則以及這些規則的具體實作方法,
JMM與Java記憶體區域劃分的區別與聯系
上面兩小節分別提到了JMM和Java運行時記憶體區域的劃分,這兩者既有差別又有聯系:
-
區別
兩者是不同的概念層次,JMM是抽象的,他是用來描述一組規則,通過這個規則來控制各個變數的訪問方式,圍繞原子性、有序性、可見性等展開的,而Java運行時記憶體的劃分是具體的,是JVM運行Java程式時,必要的記憶體劃分,
-
聯系
都存在私有資料區域和共享資料區域,一般來說,JMM中的主記憶體屬于共享資料區域,他是包含了堆和方法區;同樣,JMM中的本地記憶體屬于私有資料區域,包含了程式計數器、本地方法堆疊、虛擬機堆疊,
實際上,他們表達的是同一種含義,這里不做區分,
出現執行緒不安全的例子:
public class ThreadCount implements Runnable{
private int count =100;
@Override
public void run() {
while(true){
if (count>0){
count--;
System.out.println(Thread.currentThread().getName()+"---->"+count);
}
}
}
public static void main(String[] args) {
ThreadCount threadCount = new ThreadCount();
new Thread(threadCount).start();
new Thread(threadCount).start();
}
}

如何解決執行緒安全的問題?
核心思想:上鎖
在同一個JVM中,多個執行緒需要競爭鎖的資源,最終只能夠有一個執行緒能夠獲取到鎖,多個執行緒同時搶一把鎖,哪個執行緒能夠獲得到鎖,誰就可以執行該代碼,如果沒有獲取鎖成功,中間需要經歷鎖的升級程序,如果一直沒有獲取到鎖則會一直阻塞等待,
例如上述情況下如何上鎖呢??
public class ThreadCount implements Runnable{
private int count =100;
@Override
public void run() {
while(true){
if (count>0){
/*執行緒0 執行緒1 同時獲取this鎖,假設執行緒0 獲取到this鎖,意味著執行緒1沒有獲取到鎖則會等待,等執行緒0執行完count-- 釋放鎖資源后,就會喚醒執行緒1 從新進入到獲取鎖的資源, 獲取鎖與釋放鎖全部由虛擬機實作*/
synchronized (this){
count--;
System.out.println(Thread.currentThread().getName()+"----"+count);
}
}
}
}
public static void main(String[] args) {
ThreadCount threadCount = new ThreadCount();
new Thread(threadCount).start();
new Thread(threadCount).start();
}
}
三、執行緒同步
執行緒同步可以理解為執行緒之間按照一定的順序執行,
在我們的執行緒之間,有一個同步的概念,什么是同步呢,假如我們現在有2位正在抄暑假作業答案的同學:執行緒A和執行緒B,當他們正在抄的時候,老師突然來修改了一些答案,可能A和B最后寫出的暑假作業就不一樣,我們為了A,B能寫出2本相同的暑假作業,我們就需要讓老師先修改答案,然后A,B同學再抄,或者A,B同學先抄完,老師再修改答案,這就是執行緒A,執行緒B的執行緒同步,
執行緒安全的產生就是因為多執行緒之間沒有同步,執行緒同步機制是一套用于協調執行緒之間的資料訪問機制,該機制可以保證執行緒安全,
Java平臺提供的執行緒機制包括鎖,volatile關鍵字,final關鍵字,static關鍵字,以及相關的API,Objet.wait(); Object.notify()等,
鎖的概念
執行緒安全問題的產生前提是多個執行緒并發訪問共享資料,將多個執行緒對共享資料的并發訪問轉為串行訪問,即一個共享資料一次只能被一個執行緒訪問,鎖就是用這種思路來保證執行緒安全的.
一個執行緒只能有鎖的時候才能對共享資料進項訪問,結束訪問后必須釋放鎖,
持有鎖和釋放鎖之間所執行的代碼叫做臨界區(CriticalSection)
鎖具有排他性,即一個鎖只能被一個執行緒持有,這種鎖被稱為互斥鎖
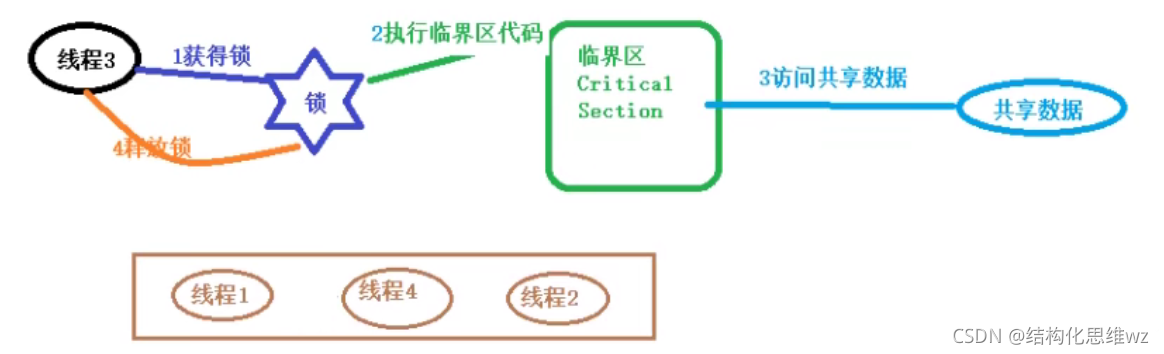
JVM把鎖分為內部鎖和顯示鎖兩種,內部所通過synchronized關鍵字實作;顯示鎖通過java.concurrent.locks.lock介面實作類實作的,
**鎖的作用:**鎖可以實作對共享資料的安全訪問,保障執行緒的
原子性,可見性,與有序性,
- 鎖是通過互斥保障原子性,一個鎖只能被一個執行緒持有,這就保證臨界區的代碼一次只能被一個執行緒執行,使得操作不可分割,保證原子性,
- 可見性的保障是通過寫執行緒沖刷處理器的快取和讀執行緒重繪處理器快取這兩個動作實作的,在java中,鎖的獲得隱含著重繪處理器快取的動作,鎖的釋放隱含著沖刷處理器快取的動作,保證寫執行緒對資料的修改,第一時間推送到處理器的高速快取中,保證讀執行緒第一時間可見,
- 鎖能夠保證有序性,寫執行緒在臨界區所執行的在讀執行緒所執行的臨界區看來像是完全按照原始碼順序執行的,
注意:使用鎖來保證執行緒的安全性必須滿足以下條件:
- 這些執行緒在訪問共享資料時,必須使用同一個鎖,
- 這些執行緒即使僅僅是讀共享資料,也需要使用鎖,
鎖相關的概念:
-
可重入性(Reentrancy)
一個執行緒持有一個鎖的時候,能否再次申請該鎖?
void methodA(){ void methodB(){ 申請a鎖 申請a鎖; methodB(); ... 釋放a鎖 釋放a鎖 } } A執行緒 重復申請了a鎖, -
鎖的爭用與調度
java平臺中內部鎖屬于非公平鎖,顯示Lock既支持公平鎖又支持非公平鎖,
-
鎖的粒度
一個鎖可以保護的共享資料的數量大小稱為鎖的粒度,(粗,細)
鎖的粒度過粗,導致執行緒在申請鎖的時候會進行不必要的等待,鎖的粒度過細會增加鎖調度的開銷,(例如銀行柜臺的功能越多就會等待時間越長)
內部鎖:synchronized
java中的每個物件都有一個與之關聯的內部鎖(這種鎖也被稱為監視器Monitor),這種鎖是一種排他鎖,可以保證原子性,可見性,有序性,
所謂``“臨界區”,指的是某一塊代碼區域,它同一時刻只能由一個執行緒執行,如果synchronized`關鍵字在方法上,那臨界區就是整個方法內部,而如果是使用synchronized代碼塊,那臨界區就指的是代碼塊內部的區域,
synchronized的幾種使用場景:
1、synchronized修飾一個代碼塊,被修飾的代碼塊稱為同步陳述句塊,其作用的范圍是大括號{}括起來的代碼,作用的物件是呼叫這個代碼塊的物件;
synchronized(物件鎖){
同步代碼塊,可以在同步代碼塊中訪問共享資料
}
-------------------------------------------------------------------------------
package se.high.thread.intrinsiclock;
/**
* @author 王澤
* 同步代碼塊
*/
public class Test01 {
public static void main(String[] args) {
//創建兩個執行緒,分別呼叫mm()方法
//先創建Test01物件,通過物件名呼叫mm()方法
Test01 obj = new Test01();
new Thread(new Runnable() {
@Override
public void run() {
obj.mm(); //使用的鎖物件this就是obj物件
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
obj.mm(); // 使用的鎖物件this就是obj物件
}
}).start();
}
//定義一個方法,列印100行字串
public void mm(){
//使用this當前物件作為鎖物件
synchronized (this){
for (int i = 0; i <100; i++) {
System.out.println(Thread.currentThread().getName()+"---->"+i);
}}
}
}
2、synchronized修飾一個方法,被修飾的方法稱為同步方法,其作用的范圍是整個方法,作用的物件是呼叫這個方法的物件;
package se.high.thread.intrinsiclock;
/**
* @author 王澤
* 同步實體方法,把整個方法體作為同步代碼塊,
* 默認的鎖物件是this鎖物件,
*/
public class Test02 {
public static void main(String[] args) {
//創建兩個執行緒,分別呼叫mm()方法 mm2
Test02 obj = new Test02();
new Thread(new Runnable() {
@Override
public void run() {
obj.mm(); //使用的鎖物件this就是obj物件
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
obj.mm2(); // 使用的鎖物件this就是obj物件
}
}).start();
}
public void mm(){
//使用this當前物件作為鎖物件
synchronized (this){
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName()+"---->"+i);
}}
}
/**
* 同步實體方法,同步實體方法,默認this作為鎖物件,
*/
public synchronized void mm2(){
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName()+"--->"+i);
}
}
}
3、synchronized修飾一個靜態的方法,其作用的范圍是整個靜態方法,作用的物件是這個類的所有物件;
// 關鍵字在靜態方法上,鎖為當前Class物件
public static synchronized void classLock() {
// code
}
等價于===
// 關鍵字在代碼塊上,鎖為括號里面的物件
public void blockLock() {
synchronized (this.getClass()) {
// code
}
}
4、synchronized修飾一個類,其作用的范圍是synchronized后面括號括起來的部分,作用的物件是這個類的所有物件,
總結:
- 同步代碼塊比同步方法效率更高,
- 臟讀出現的原因是對共享資料的修改與對共享資料的讀取不同步,需要對讀取資料的代碼塊同步,
- 執行緒出現例外會自動釋放鎖,
多執行緒訪問同步方法的7種情況
1、兩個執行緒同時訪問一個物件的同步方法
答:串行執行
2、兩個執行緒訪問的是兩個物件的同步方法
答:并行執行,因為兩個執行緒持有的是各自的物件鎖,互補影響,
3、兩個執行緒訪問的是synchronized的static方法
答:串行執行,持有一個類鎖
4、同時訪問同步方法和非同步方法
答:并行執行,無論是同一物件還是不同物件,普通方法都不會受到影響
5、訪問同一物件的不同的普通同步方法
答:串行執行,持有相同的鎖物件
6、同時訪問靜態的synchronized方法和非靜態的synchronized方法
答:并行執行,因為一個是持有的class類鎖,一個是持有的是this物件鎖,不同的鎖,互補干擾,
7、方法拋出例外后,會釋放鎖
答:synchronized無論是正常結束還是拋出例外后,都會釋放鎖,而lock必須手動釋放鎖才可以,
死鎖的問題
死鎖是這樣一種情形:多個執行緒同時被阻塞,它們中的一個或者全部都在等待某個資源被釋放,由于執行緒被無限期地阻塞,因此程式不可能正常終止,
java 死鎖產生的四個必要條件:
- 1、互斥使用,即當資源被一個執行緒使用(占有)時,別的執行緒不能使用
- 2、不可搶占,資源請求者不能強制從資源占有者手中奪取資源,資源只能由資源占有者主動釋放,
- 3、請求和保持,即當資源請求者在請求其他的資源的同時保持對原有資源的占有,
- 4、回圈等待,即存在一個等待佇列:P1占有P2的資源,P2占有P3的資源,P3占有P1的資源,這樣就形成了一個等待環路,
當上述四個條件都成立的時候,便形成死鎖,當然,死鎖的情況下如果打破上述任何一個條件,便可讓死鎖消失,下面用java代碼來模擬一下死鎖的產生:
package se.high.thread.intrinsiclock;
import javax.security.auth.Subject;
/**
* @author 王澤
* 演示死鎖問題,
* 在多執行緒程式中,同步時可能需要使用多個鎖,如果獲得鎖的順序不一致,可能會導致死鎖,
*/
public class DeadLock {
public static void main(String[] args) {
SubThread t1 =new SubThread();
t1.setName("a");
t1.start();
SubThread t2 = new SubThread();
t2.setName("b");
t2.start();
}
static class SubThread extends Thread{
private static final Object yitian = new Object();
private static final Object tulong = new Object();
@Override
public void run() {
if ("a".equals(Thread.currentThread().getName())){
synchronized (yitian){
System.out.println("a執行緒獲得了倚天劍,爽翻了,再來個屠龍刀就好了...");
synchronized (tulong){
System.out.println("a執行緒獲得了倚天劍和屠龍刀,直接稱霸武林...");
}
}
}
if ("b".equals(Thread.currentThread().getName())){
synchronized (tulong){
System.out.println("b執行緒獲得了屠龍寶刀,得勁,誰也不給....");
synchronized (yitian){
System.out.println("b執行緒獲得了屠龍后又來把倚天劍....b稱霸武林");
}
}
}
}
}
}
a執行緒獲得了倚天劍,爽翻了,再來個屠龍刀就好了...
b執行緒獲得了屠龍寶刀,得勁,誰也不給....
解決死鎖:
當需要獲得多個鎖時,所有執行緒獲得鎖的順序保持一致,
volatile
在Java記憶體模型那一章我們介紹了JMM有一個主記憶體,每個執行緒有自己私有的作業記憶體,作業記憶體中保存了一些變數在主記憶體的拷貝,
記憶體可見性,指的是執行緒之間的可見性,當一個執行緒修改了共享變數時,另一個執行緒可以讀取到這個修改后的值,
Java中的volatile關鍵字可以保證多執行緒操作共享變數的可見性以及禁止指令重排序,synchronized關鍵字不僅保證可見性,同時也保證了原子性(互斥性),
volatile作用
volatile可以保證記憶體可見性且禁止重排序
可以強制執行緒從公共記憶體中讀取變數的值,而不是從作業記憶體中讀取,
package se.high.thread.volatilekw;
/**
* @author 王澤
*/
public class Test01 {
public static void main(String[] args) {
PrintString printString = new PrintString();
//列印字串的方法
new Thread(new Runnable() {
@Override
public void run() {
printString.printStringMethod();
}
}).start();
//main執行緒睡眠1000毫秒
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("在main執行緒中修改列印標志");
printString.setContinuePrint(false);
//在main修改玩列印標志后,子執行緒是否結束列印,
}
static class PrintString{
private volatile boolean continuePrint = true;
public void printStringMethod(){
while (continuePrint){
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void setContinuePrint(boolean continuePrint) {
this.continuePrint = continuePrint;
}
}
}
Thread-0
Thread-0
在main執行緒中修改列印標志
行程已結束,退出代碼為 0
而如果flag變數沒有用volatile修飾,在main中修改的標志就不會更新到主記憶體,
volatile 與 synchronized比較
1)volatile 關鍵字是執行緒同步的輕量級實作,所以volatile性能比synchronized更好,volatile只能修飾變數,而synchronized可以修飾方法,代碼塊,隨著JDK新版本的發布,synchronized的執行效率也有了很大的提升,
在開發中我們使用synchronized的比例較大,
2)多執行緒訪問volatile變數不會發生阻塞,而synchronized可能會阻塞,
3)volatile能保證資料的可見性,不能保證原子性,synchronized都可以保證,會資料同步,
4)volatile解決的是變數在多個執行緒之間的可見性;synchronized解決多個執行緒之間訪問公共資源的同步性,
volatile 非原子特性
volatile 關鍵字增加了實體變數在多個執行緒之間的可見性,但是不具備原子性,
package se.high.thread.volatilekw;
/**
* @author 王澤
* 看volatile的非原子性
*/
public class Test02 {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Mythread().start();
}
}
static class Mythread extends Thread{
volatile public static int count;
public static void addCount(){
for (int i = 0; i < 1000; i++) {
count++;
}
System.out.println(Thread.currentThread().getName()+"count="+count);
}
@Override
public void run() {
addCount();
}
}
}
Thread-3count=4000
Thread-2count=4000
Thread-1count=4000
Thread-0count=4000
Thread-4count=6894
Thread-5count=6493
Thread-6count=6320
Thread-7count=7894
Thread-8count=8894
Thread-9count=9894
行程已結束,退出代碼為 0
發現有不是整千的,說明某個執行緒的for回圈不是原子操作,
常用原子類進行自增自減操作
我們知道i++不是原子操作,除了使用Synchornized進行同步外,也可以使用Atomiclnteger/AtomicLong原子類進行實作,
java.util.concurrent.atomic的包里有``AtomicBoolean, AtomicInteger,AtomicLong,AtomicLongArray,
AtomicReference`等原子類的類,主要用于在高并發環境下的高效程式處理,來幫助我們簡化同步處理.
在Java語言中,++i和i++操作并不是執行緒安全的,在使用的時候,不可避免的會用到synchronized關鍵字,而AtomicInteger則通過一種執行緒安全的加減操作介面,
CAS
CAS的全稱是:比較并交換(Compare And Swap),在CAS中,有這樣三個值:
- V:要更新的變數(var)
- E:預期值(expected)
- N:新值(new)
比較并交換的程序如下:
判斷V是否等于E,如果等于,將V的值設定為N;如果不等,說明已經有其它執行緒更新了V,則當前執行緒放棄更新,什么都不做,
CAS(Compare And Swap)協議/演算法是由硬體實作的,
CAS可以將 read - modify -write 這類的操作轉換為 原子操作,
i++ 包括三個原子操作:
- 從主記憶體讀取i變數的值
- 對i的值加1
- 再把加一之后的值保存到主記憶體
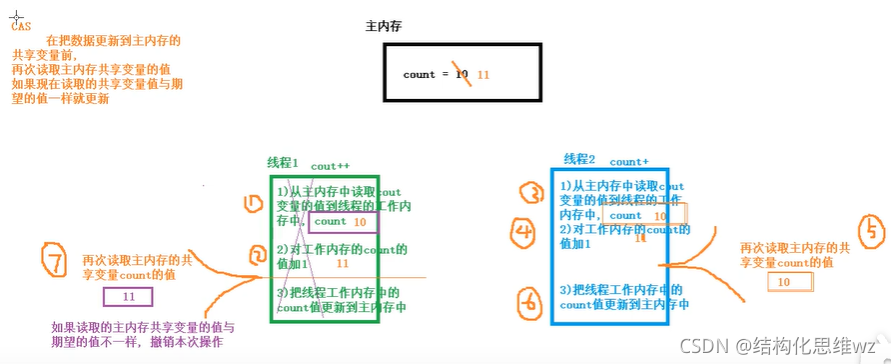
CAS原理:
在把資料更新到主記憶體時,再次讀取主記憶體變數的值,如果現在變數的值與期望的值(操作起始時讀取的值)一致就更新,
理想狀態:
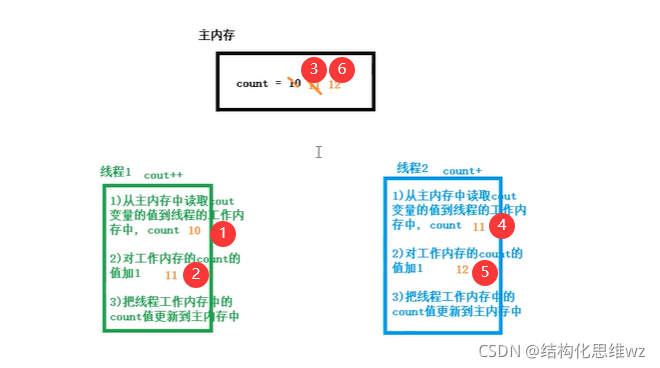
并發問題可能的狀態:
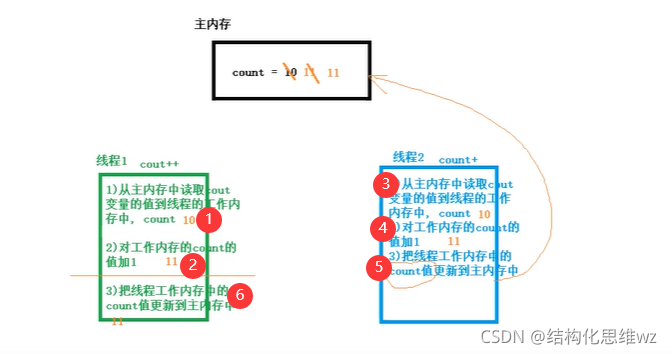
CAS就是把資料更新到主記憶體的共享變數前,再次讀取主記憶體共享變數的值,如果現在讀取的共享變數的值與期望的值一樣就更新:
使用CAS實作執行緒安全的計數器
package se.high.thread.cas;
/**
* @author 王澤
* 使用CAS實作一個執行緒安全的計數器
*/
public class CasTest {
public static void main(String[] args) {
CASCounter cas = new CASCounter();
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"----->"+cas.incrementAndGet());
}
}).start();
}
}
}
class CASCounter{
//使用volatile修飾value的值,使執行緒可見
volatile private long value;
public long getValue(){
return value;
}
private boolean compareAndSwap(long expectedValue,long newValue){
//如果當前value的值與情網的expectedValue值一樣,就把當時的Value欄位替換為newValue值
synchronized (this){
if (value == expectedValue){
value = newValue;
return true;
}else {
return false;
}
}
}
//定義自增的方法
public long incrementAndGet(){
long oldValue;
long newValue;
do {
oldValue = value;
newValue = oldValue+1;
}while(!compareAndSwap(oldValue,newValue));
return newValue;
}
}
CAS中的ABA問題
CAS實作原子操作背后有一個假設:共享變數的當前值與當前執行緒提供的期望值相同,就認為這個變數沒有被其他執行緒修改過,
實際上這個假設不一定總成立,
例如:有一個共享變數 count =0,A執行緒對count的值修改為10,B執行緒對count修改為20,C執行緒對count修改為10; 如果當前執行緒看到count變數的值為10,我們是否認為count變數的值沒有被其他執行緒更新呢??這種結果是否能接受??
共享變數經歷了 A -> B -> A 的更新
是否能夠接受ABA的問題跟實作演算法有關,如果想要規避ABA問題,可以為共享變數引入一個修訂號(時間戳),每次修改共享變數時,相應的修訂號就會增加1,
[A,0] -> [B,1] -> [A,2]
這也是AtomicStampedReference類就是基于這種思想產生的,
原子變數類
原子變數類基于CAS實作的,當對共享變數進行 read-modify-writer更新操作時,通過原子變數類可以保障操作的原子性與可見性,對變數的read-modify-writer更新操作是指當前操作不是一個簡單的賦值,而是一個變數的新值依賴變數的舊值,
例如 i++ 的操作就是 讀 -> +1 -> 賦值;
由于volatile無法保證原子性,只能保證可見性,原子變數類內部就是借助一個volatile變數,并且保障了該變數的 read-modify-writer 操作的原子性,有時把原子變數類看做增強的 volatile變數,
原子變數類:
| 分組 | 原子變數類 |
|---|---|
| 基礎資料型別 | AtomicInteger,AtomicLong,AtomicBoolean |
| 陣列型 | AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray |
| 欄位更新器 | AtomicIntegerFieldUpdater,AtomicLongFieldUpdater,AtomicReferenceFieldUpdater |
| 參考型 | AtomicReference,AtomicStampedReference,AtomicMarkableReference |
使用AtomicLong定義計數器
開發一個程式統計請求的總數,成功數,失敗數,模擬多用戶多執行緒訪問,
package se.high.thread.atomic.atomiclong;
import java.util.concurrent.atomic.AtomicLong;
/**
* @author 結構化思維wz
* 使用原子變數類定義一個計數器
* 統計計數器,在整個程式中都能使用,并且所有地方都使用這一計數器,這個計數器可以設計為單例
*/
public class Indicator {
//構造方法私有化
private Indicator(){}
//定義一個私有的本類靜態物件
private static final Indicator INSTANCE = new Indicator();
//提供一個公共靜態方法回傳該類的唯一實體
public static Indicator getInstance(){
return INSTANCE;
}
/**
* 記錄原子變數類保存請求總數,成功數,失敗數,
*/
private final AtomicLong requestCount = new AtomicLong(0); //記錄請求總數
private final AtomicLong successCount = new AtomicLong(0); //記錄請求成功數
private final AtomicLong fialureCount = new AtomicLong(0); //記錄請求失敗數
/**
* 有新的請求的時候
*/
public void newRequestReceive(){
requestCount.incrementAndGet(); //總數增長
}
/**
* 處理成功的時候
*/
public void requestSuccess(){
successCount.incrementAndGet(); //成功數+1
}
/**
* 處理失敗的時候
*/
public void requestFialure(){
fialureCount.incrementAndGet(); //失敗數+1
}
/**
* 查看總數,成功數,失敗數
*/
public long getRequestCount(){
return requestCount.get();
}
public long getRequestSuccess(){
return successCount.get();
}
public long getRequestFialure(){
return fialureCount.get();
}
}
package se.high.thread.atomic.atomiclong;
import java.util.Random;
/**
* @author 王澤
* 模擬服務器的請求總數,處理成功數,處理失敗數,
*/
public class AtomicTest {
public static void main(String[] args) {
// 通過執行緒模擬請求
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
//每個執行緒都是一個請求
Indicator.getInstance().newRequestReceive();
int num = new Random().nextInt();
if (num %2 == 0){
//偶數模擬成功
Indicator.getInstance().requestSuccess();
}else {Indicator.getInstance().requestFialure();}
}
}).start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//列印結果
System.out.println("請求的總數--->"+Indicator.getInstance().getRequestCount());
System.out.println("請求成功數--->"+Indicator.getInstance().getRequestSuccess());
System.out.println("請求失敗數--->"+Indicator.getInstance().getRequestFialure());
}
}
請求的總數--->10000
請求成功數--->5035
請求失敗數--->4965
行程已結束,退出代碼為 0
AtomicIntegerArray
原子更新陣列
package se.high.thread.atomic.atomicIntegerArray;
import java.util.concurrent.atomic.AtomicIntegerArray;
/**
* @author 結構化思維wz
* 原子更新陣列
*/
public class Test {
public static void main(String[] args) {
//1.創建一個指定長度的陣列
AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10);
System.out.println(atomicIntegerArray);
//2.回傳指定位置的元素
System.out.println("回傳指定下標的元素"+atomicIntegerArray.get(2));
//3.設定指定位置的元素、
atomicIntegerArray.set(0,10);
//4.在設定陣列元素的新值時,同時回傳陣列元素,
System.out.println("回傳1下標原來的元素并設定一個元素"+atomicIntegerArray.getAndSet(1,11));
System.out.println(atomicIntegerArray);
System.out.println("設定之后的元素"+atomicIntegerArray.get(1));
//5.修改陣列元素把陣列加上某個值
System.out.println("先加20,再回傳:"+atomicIntegerArray.addAndGet(0,20));
System.out.println("先回傳再加"+atomicIntegerArray.getAndAdd(1,20));
System.out.println(atomicIntegerArray);
//6.CAS操作
System.out.println("如果0下標元素是30--->"+atomicIntegerArray.compareAndSet(0,30,222)+"-->就設定為222");
System.out.println(atomicIntegerArray);
//7.自增、自減
System.out.println(atomicIntegerArray.incrementAndGet(3)); //先自增
System.out.println(atomicIntegerArray.getAndIncrement(3)); //先使用再自增
System.out.println(atomicIntegerArray.get(3));
System.out.println(atomicIntegerArray.getAndDecrement(3));
System.out.println(atomicIntegerArray.get(3));
}
}
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
回傳指定下標的元素0
回傳1下標原來的元素并設定一個元素0
[10, 11, 0, 0, 0, 0, 0, 0, 0, 0]
設定之后的元素11
先加20,再回傳:30
先回傳再加11
[30, 31, 0, 0, 0, 0, 0, 0, 0, 0]
如果0下標元素是30--->true-->就設定為222
[222, 31, 0, 0, 0, 0, 0, 0, 0, 0]
1
1
2
2
1
行程已結束,退出代碼為 0
多執行緒中使用原子陣列
package se.high.thread.atomic.atomicIntegerArray;
import java.util.concurrent.atomic.AtomicIntegerArray;
/**
* @author 結構化思維wz
* 在多執行緒中使用原子陣列
*/
public class Test02 {
/**
* 定義原子陣列
*/
static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10);
public static void main(String[] args) {
//定義一個執行緒陣列
Thread[] threads = new Thread[10];
//給執行緒陣列元素賦值
for (int i = 0; i < threads.length; i++) {
threads[i]= new AddThread();
}
//開啟子執行緒
for (Thread thread : threads) {
thread.start();
}
//在主執行緒中查看自增以后原子陣列中的各個元素的值,在主執行緒中需要在所欲子執行緒中列印執行后再查看
//把所有子執行緒合并到當前主執行緒
for (Thread thread:threads) {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(atomicIntegerArray);
}
/**
* 定義一個執行緒類,在執行緒中修改原子陣列
*/
static class AddThread extends Thread{
@Override
public void run() {
//把原子陣列的每個元素自增1000次
for (int i = 0; i < 1000; i++) {
for (int j = 0; j < atomicIntegerArray.length(); j++) {
atomicIntegerArray.getAndIncrement(j%atomicIntegerArray.length());
}
}
}
}
}
AtomicIntegerFieldUpdater更新欄位
AtomicIntegerUpdater可以對原子正整數欄位進行更新,要求:
- 欄位必須使用volatile修飾 ,使執行緒之間可見,
- 只能是實體變數,不能是靜態變數,也不能使用final修飾,
AtomicIntegerFieldUpdater<User> updater = AtmoicIntegerFieldUpdater.newUpdater(User.class,"age"); //對user中的age欄位修改
AtomicReference
可以原子讀寫一個物件,
package se.high.thread.atomic.atomicreference;
import java.util.concurrent.atomic.AtomicReference;
/**
* @author 結構化思維wz
* 用原子物件操作字串
*/
public class Test01 {
static AtomicReference<String> atomicReference = new AtomicReference<>("abc");
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(new Runnable() {
@Override
public void run() {
if(atomicReference.compareAndSet("abc","def")){
System.out.println(Thread.currentThread().getName()+"把字串abc更改為def");
}
}
}).start();
}
//再創建100個執行緒
for (int i = 0; i<100; i++){
new Thread(new Runnable() {
@Override
public void run() {
if (atomicReference.compareAndSet("def","abc")){
System.out.println(Thread.currentThread().getName()+"把字串還原為abc");
}
}
}).start();
}
}
}
AtomicReference的ABA問題
使用AtomicStampedreference (帶時間戳)
? AtomicMarkableReference(帶標志)
四、執行緒間的通信
眾所周知執行緒都有自己的執行緒堆疊,那么執行緒之間是如何保證通信的呢?下面來分析:
等待/通知機制
什么是等待通知機制?
舉例:吃自助的時候吃現做的一些飯,放到臺子上才能拿,
在單執行緒編程中,要執行的操作需要滿足一定的條件才能執行,可以把這個操作放在if陳述句快中,
在多執行緒編程中,可能A執行緒條件沒有滿足只是暫時的,稍后其他的執行緒B可能會更新條件使得A執行緒的條件得到滿足,可以將A執行緒暫停,直到他的條件得到滿足后再將A執行緒喚醒,
偽代碼:
atomic{
while(條件不成立){
等待
}
條件滿足后當前執行緒被喚醒,繼續執行下面的操作
}
等待通知機制的實作:
Object類中的wait()方法,可以使當前執行代碼的執行緒等待,暫停執行,知道接受到通知或被中斷為止,
注意:
- wait()方法只能在同步代碼塊中由鎖物件呼叫,
- 呼叫wait()方法后,當前執行緒會釋放鎖,
偽代碼:
//在呼叫wait()方法前獲得物件的內部鎖
synchronized(鎖物件){
while(條件不成立){
//通過鎖物件呼叫wait()方法暫停執行緒,釋放鎖物件
鎖物件.wait();
}
//執行緒的條件滿足了繼續向下執行
}
Object類的 notify()可以喚醒執行緒,該方法也必須在同步代碼塊中由鎖物件呼叫,沒有使用鎖物件呼叫wait()/notify()會拋出例外,
如果有多個等待的執行緒,**notify()方法只能喚醒其中的一個,并不會立即釋放鎖物件,**一般將notify方法放在同步代碼塊的最后,
偽代碼:
synchronized(鎖物件){
執行修改保護條件的代碼
喚醒其他執行緒
鎖物件.notify();
}
實體:
package se.high.thread.wait;
/**
* @author 結構化思維wz
* 用notify喚醒等待的執行緒
*/
public class Test01 {
public static void main(String[] args) {
String lock = "wzjiayou"; //定義一個字串作為鎖物件
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock){
System.out.println("執行緒1開始等待-->"+System.currentTimeMillis());
try {
lock.wait(); //執行緒等待
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("執行緒1結束等待-->"+System.currentTimeMillis());
}
}
});
/**
* 定義執行緒2,用來喚醒執行緒1
*/
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
//notify需要在同步代碼塊中由鎖物件呼叫
synchronized (lock){
System.out.println("執行緒2開始喚醒"+System.currentTimeMillis());
lock.notify();
System.out.println("執行緒2結束喚醒"+System.currentTimeMillis());
}
}
});
t1.start(); //開啟t1執行緒,main執行緒誰3秒,確保t1等待
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
執行緒1開始等待-->1633345984896
執行緒2開始喚醒1633345987897
執行緒2結束喚醒1633345987897
執行緒1結束等待-->1633345987897
行程已結束,退出代碼為 0
interrupt()方法會中斷wait()
當執行緒處于wait()等待狀態時,呼叫執行緒物件的interrupt()方法會中斷執行緒等待狀態,會產生InterruptedExceptiont例外,
notify()與notifyAll()
notify()一次只能喚醒一個執行緒,如果有多個等待的執行緒,只能隨機喚醒其中的某一個;想要喚醒所有的執行緒,需要呼叫notifyAll();
wait(long)
如果在引數指定的時間內沒有被喚醒,超時后會自動喚醒,
通知過早
執行緒wait()等待后,可以呼叫notify()喚醒執行緒,如果notify()喚醒過早,在等待之前就呼叫了notify()可能會打亂程式正常的執行邏輯,
在應用中,我們為了保證t1等待后才讓t2喚醒,如果t2執行緒先喚醒,就不讓t1等待了,
可以設定一個Boolean變數,通知后設為false,如果為true再等待,
wait() 等待條件發生了變化
在使用wait(),notify(),注意wait條件發生的了變化,也可能導致邏輯的混亂,
生產者消費者模式
生產者消費者問題(Producer-consumer problem),也稱有限緩沖問題(Bounded-buffer problem),是一個多執行緒同步問題的經典案例,生產者生成一定量的資料放到緩沖區中,然后重復此程序;與此同時,消費者也在緩沖區消耗這些資料,生產者和消費者之間必須保持同步,要保證生產者不會在緩沖區滿時放入資料,消費者也不會在緩沖區空時消耗資料,不夠完善的解決方法容易出現死鎖的情況,此時行程都在等待喚醒,
示意圖:
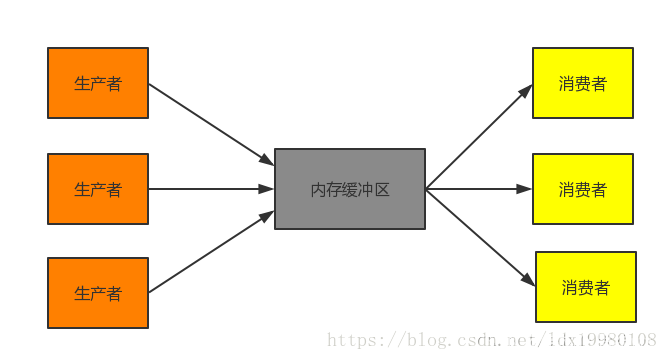
解決思路:
- 采用某種機制保護生產者和消費者之間的同步,有較高的效率,并且易于實作,代碼的可控制性較好,屬于常用的模式,
- 在生產者和消費者之間建立一個管道,管道緩沖區不易控制,被傳輸資料物件不易于封裝等,實用性不強,
解決問題的核心:
? 保證同一資源被多個執行緒并發訪問時的完整性,常用的同步方法是采用信號或加鎖機制,保證資源在任意時刻至多被一個執行緒訪問,
wait() / notify()方法
當緩沖區已滿時,生產者執行緒停止執行,放棄鎖,使自己處于等待狀態,讓其他執行緒執行;
當緩沖區已空時,消費者執行緒停止執行,放棄鎖,使自己處于等待狀態,讓其他執行緒執行,
當生產者向緩沖區放入一個產品時,向其他等待的執行緒發出可執行的通知,同時放棄鎖,使自己處于等待狀態;
當消費者從緩沖區取出一個產品時,向其他等待的執行緒發出可執行的通知,同時放棄鎖,使自己處于等待狀態,
倉庫Storage.java
import java.util.LinkedList;
public class Storage {
// 倉庫容量
private final int MAX_SIZE = 10;
// 倉庫存盤的載體
private LinkedList<Object> list = new LinkedList<>();
public void produce() {
synchronized (list) {
/*倉庫滿的情況*/
while (list.size() + 1 > MAX_SIZE) {
System.out.println("【生產者" + Thread.currentThread().getName()
+ "】倉庫已滿");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/*生產者生產*/
list.add(new Object());
System.out.println("【生產者" + Thread.currentThread().getName()
+ "】生產一個產品,現庫存" + list.size());
list.notifyAll();
}
}
public void consume() {
synchronized (list) {
/*倉庫空了*/
while (list.size() == 0) {
System.out.println("【消費者" + Thread.currentThread().getName()
+ "】倉庫為空");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/*消費者消費*/
list.remove();
System.out.println("【消費者" + Thread.currentThread().getName()
+ "】消費一個產品,現庫存" + list.size());
list.notifyAll();
}
}}
生產者:
public class Producer implements Runnable{
private Storage storage;
public Producer(){}
public Producer(Storage storage){
this.storage = storage;
}
@Override
public void run(){
while(true){
try{
Thread.sleep(1000);
storage.produce();
}catch (InterruptedException e){
e.printStackTrace();
}
}
}}
消費者
public class Consumer implements Runnable{
private Storage storage;
public Consumer(){}
public Consumer(Storage storage){
this.storage = storage;
}
@Override
public void run(){
while(true){
try{
Thread.sleep(3000);
storage.consume();
}catch (InterruptedException e){
e.printStackTrace();
}
}
}}
Main:
public class Main {
public static void main(String[] args) {
Storage storage = new Storage();
Thread p1 = new Thread(new Producer(storage));
Thread p2 = new Thread(new Producer(storage));
Thread p3 = new Thread(new Producer(storage));
Thread c1 = new Thread(new Consumer(storage));
Thread c2 = new Thread(new Consumer(storage));
Thread c3 = new Thread(new Consumer(storage));
p1.start();
p2.start();
p3.start();
c1.start();
c2.start();
c3.start();
}}
運行結果
【生產者p1】生產一個產品,現庫存1
【生產者p2】生產一個產品,現庫存2
【生產者p3】生產一個產品,現庫存3
【生產者p1】生產一個產品,現庫存4
【生產者p2】生產一個產品,現庫存5
【生產者p3】生產一個產品,現庫存6
【生產者p1】生產一個產品,現庫存7
【生產者p2】生產一個產品,現庫存8
【消費者c1】消費一個產品,現庫存7
【生產者p3】生產一個產品,現庫存8
【消費者c2】消費一個產品,現庫存7
【消費者c3】消費一個產品,現庫存6
【生產者p1】生產一個產品,現庫存7
【生產者p2】生產一個產品,現庫存8
【生產者p3】生產一個產品,現庫存9
【生產者p1】生產一個產品,現庫存10
【生產者p2】倉庫已滿
【生產者p3】倉庫已滿
【生產者p1】倉庫已滿
【消費者c1】消費一個產品,現庫存9
【生產者p1】生產一個產品,現庫存10
【生產者p3】倉庫已滿
,,,,,,以下省略
一個生產者執行緒運行produce方法,睡眠1s;一個消費者運行一次consume方法,睡眠3s,此次實驗程序中,有3個生產者和3個消費者,也就是我們說的多對多的情況,倉庫的容量為10,可以看出消費的速度明顯慢于生產的速度,符合設定,
注意:
notifyAll()方法可使所有正在等待佇列中等待同一共享資源的“全部”執行緒從等待狀態退出,進入可運行狀態,此時,優先級最高的哪個執行緒最先執行,但也有可能是隨機執行的,這要取決于JVM虛擬機的實作,即最終也只有一個執行緒能被運行,上述執行緒優先級都相同,每次運行的執行緒都不確定是哪個,后來給執行緒設定優先級后也跟預期不一樣,還是要看JVM的具體實作吧,
通過管道實作執行緒間的通信
在
java.io中的PIpeStream管道流,用于在執行緒之間傳送資料,一個執行緒發送資料到輸出管道,另一個執行緒從輸入管道中讀取資料,
PipeInputStream , PipeOutStream, PipeReader , PipedWriter,
package se.high.thread.pipestream;
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
/**
* @author 結構化思維wz
*/
public class Test {
public static void main(String[] args) throws IOException {
/*定義管道位元組流*/
PipedInputStream inputStream = new PipedInputStream();
PipedOutputStream outputStream = new PipedOutputStream();
inputStream.connect(outputStream);
/*創建兩個執行緒向管道流中讀寫資料*/
new Thread(new Runnable() {
@Override
public void run() {
try {
writeData(outputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
readData(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
/**
* 定義方法向管道流中寫入資料
*/
public static void writeData(PipedOutputStream out) throws IOException {
/*把0-100 之間的數寫入管道中*/
for (int i = 0; i < 100; i++) {
String data = "-" + i;
out.write(data.getBytes()); //把位元組陣列寫入到輸出管道流中
}
out.close();
}
/**
* 定義方法從管道中讀取資料
*/
public static void readData(PipedInputStream input) throws IOException {
/*從管道中讀取0-100*/
byte[] bytes = new byte[1024];
int len = input.read(bytes); //回傳讀到的位元組數,如果沒有讀到任何資料回傳-1
while(len != -1){
//把bytes陣列中從0開始到len個位元組轉換為字串列印出來
System.out.println(new String(bytes,0,len));
len = input.read(bytes); //繼續從管道中讀取資料
}
input.close();
}
}
join()
join()方法是Thread類的一個實體方法,它的作用是讓當前執行緒陷入“等待”狀態,等join的這個執行緒執行完成后,再繼續執行當前執行緒,
有時候,主執行緒創建并啟動了子執行緒,如果子執行緒中需要進行大量的耗時運算,主執行緒往往將早于子執行緒結束之前結束,
如果主執行緒想等待子執行緒執行完畢后,獲得子執行緒中的處理完的某個資料,就要用到join方法了,(插隊)
示例代碼:
public class Join {
static class ThreadA implements Runnable {
@Override
public void run() {
try {
System.out.println("我是子執行緒,我先睡一秒");
Thread.sleep(1000);
System.out.println("我是子執行緒,我睡完了一秒");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new ThreadA());
thread.start();
thread.join();
System.out.println("如果不加join方法,我會先被打出來,加了就不一樣了");
}
}
注意join()方法有兩個多載方法,一個是join(long), 一個是join(long, int),
實際上,通過原始碼你會發現,join()方法及其多載方法底層都是利用了wait(long)這個方法,
對于join(long, int),通過查看原始碼(JDK 1.8)發現,底層并沒有精確到納秒,而是對第二個引數做了簡單的判斷和處理,
五、Callable與Future
通常來說,我們使用Runnable和Thread來創建一個新的執行緒,但是它們有一個弊端,就是run方法是沒有回傳值的,而有時候我們希望開啟一個執行緒去執行一個任務,并且這個任務執行完成后有一個回傳值,
JDK提供了Callable介面與Future介面為我們解決這個問題,這也是所謂的“異步”模型,
Callable介面
Callable與Runnable類似,同樣是只有一個抽象方法的函式式介面,不同的是,Callable提供的方法是有回傳值的,而且支持泛型,
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
那一般是怎么使用Callable的呢?Callable一般是配合執行緒池工具ExecutorService來使用的,我們會在后續章節解釋執行緒池的使用,這里只介紹ExecutorService可以使用submit方法來讓一個Callable介面執行,它會回傳一個Future,我們后續的程式可以通過這個Future的get方法得到結果,
這里可以看一個簡單的使用demo:
// 自定義Callable
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
// 模擬計算需要一秒
Thread.sleep(1000);
return 2;
}
public static void main(String args[]) throws Exception {
// 使用
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
Future<Integer> result = executor.submit(task);
// 注意呼叫get方法會阻塞當前執行緒,直到得到結果,
// 所以實際編碼中建議使用可以設定超時時間的多載get方法,
System.out.println(result.get());
}
}
輸出結果:
2
Future介面
Future介面只有幾個比較簡單的方法:
public abstract interface Future<V> {
public abstract boolean cancel(boolean paramBoolean);
public abstract boolean isCancelled();
public abstract boolean isDone();
public abstract V get() throws InterruptedException, ExecutionException;
public abstract V get(long paramLong, TimeUnit paramTimeUnit)
throws InterruptedException, ExecutionException, TimeoutException;
}
cancel方法是試圖取消一個執行緒的執行,
注意是試圖取消,并不一定能取消成功,因為任務可能已完成、已取消、或者一些其它因素不能取消,存在取消失敗的可能,boolean型別的回傳值是“是否取消成功”的意思,引數paramBoolean表示是否采用中斷的方式取消執行緒執行,
所以有時候,為了讓任務有能夠取消的功能,就使用Callable來代替Runnable,如果為了可取消性而使用 Future但又不提供可用的結果,則可以宣告 Future<?>形式型別、并回傳 null作為底層任務的結果,
FutureTask類
上面介紹了Future介面,這個介面有一個實作類叫FutureTask,FutureTask是實作的RunnableFuture介面的,而RunnableFuture介面同時繼承了Runnable介面和Future介面:
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
那FutureTask類有什么用?為什么要有一個FutureTask類?前面說到了Future只是一個介面,而它里面的cancel,get,isDone等方法要自己實作起來都是非常復雜的,所以JDK提供了一個FutureTask類來供我們使用,
示例代碼:
// 自定義Callable,與上面一樣
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
// 模擬計算需要一秒
Thread.sleep(1000);
return 2;
}
public static void main(String args[]) throws Exception {
// 使用
ExecutorService executor = Executors.newCachedThreadPool();
FutureTask<Integer> futureTask = new FutureTask<>(new Task());
executor.submit(futureTask);
System.out.println(futureTask.get());
}
}
使用上與第一個Demo有一點小的區別,首先,呼叫submit方法是沒有回傳值的,這里實際上是呼叫的submit(Runnable task)方法,而上面的Demo,呼叫的是submit(Callable<T> task)方法,
然后,這里是使用FutureTask直接取get取值,而上面的Demo是通過submit方法回傳的Future去取值,
在很多高并發的環境下,有可能Callable和FutureTask會創建多次,FutureTask能夠在高并發環境下確保任務只執行一次,這塊有興趣的同學可以參看FutureTask原始碼,
FutureTask的幾個狀態
/**
*
* state可能的狀態轉變路徑如下:
* NEW -> COMPLETING -> NORMAL
* NEW -> COMPLETING -> EXCEPTIONAL
* NEW -> CANCELLED
* NEW -> INTERRUPTING -> INTERRUPTED
*/
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
state表示任務的運行狀態,初始狀態為NEW,運行狀態只會在set、setException、cancel方法中終止,COMPLETING、INTERRUPTING是任務完成后的瞬時狀態,
以上就是Java多執行緒幾個基本的類和介面的介紹,可以打開JDK看看原始碼,體會這幾個類的設計思路和用途吧!
六、ThreadLocal()
ThreadLocal類顧名思義可以理解為執行緒本地變數,也就是說如果定義了一個ThreadLocal, 每個執行緒往這個ThreadLocal中讀寫是執行緒隔離,互相之間不會影響的,它提供了一種將可變資料通過每個執行緒有自己的獨立副本從而實作執行緒封閉的機制,
如果一百個同學搶一根筆,這個筆就是共享資源,作為王老師,一定得處理這個事不然學生容易打起來,讓他們一個一個的來, ===內部鎖的原理
*如果給同學提供100支筆,能更快的完成任務,====ThreadLocal()的思路*
ThreadLocal ThreadLocal的作用主要是做資料隔離,填充的資料只屬于當前執行緒,變數的資料對別的執行緒而言是相對隔離的,在多執行緒環境下,如何防止自己的變數被其它執行緒篡改,
每個Thread物件都有一個ThreadLocalMap,每個ThreadLocalMap可以存盤多個ThreadLocal
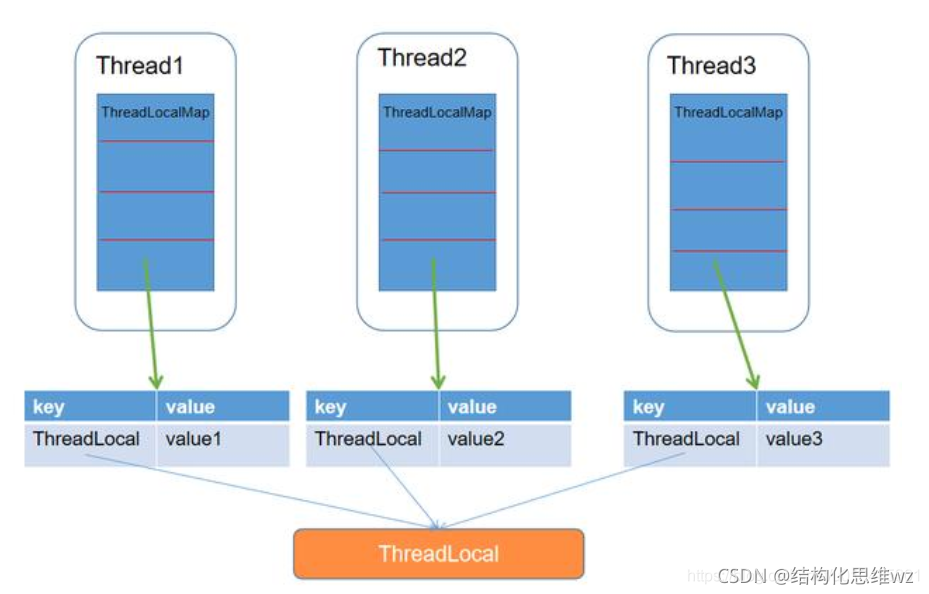
API介紹
主要是
initialValue、set、get、remove這幾個方法
initialValue
-
initialValue方法會回傳當前執行緒對應的“初始值”,這是一個延遲加載的方法,只有在呼叫get的時候,才會觸發,
-
當執行緒第一次使用get方法訪問變數時,將呼叫initialValue方法,除非執行緒先前呼叫了set方法,在這種情況下,不會為執行緒呼叫本initialValue方法,
-
通常,每個執行緒最多呼叫一次initialValue()方法,但如果已經呼叫了一次remove()后,再呼叫get(),則可以再次呼叫initialValue(),相當于第一次呼叫get(),
-
如果不重寫initialValue()方法,這個方法會回傳null,一般使用匿名內部類的方法來重寫initialValue()方法,以便在后續使用中可以初始化副本物件,
set
// 把當前執行緒需要全域共享的value傳入
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// map物件為空就創建,不為空就覆寫
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
get
-
get方法是先取出當前執行緒的ThreadLocalMap,然后呼叫map.getEntry方法,把本ThreadLocal的參考作為引數傳入,取出map中屬于本ThreadLocal的value
-
注意:這個map以及map中的key和value都是保存在執行緒中ThreadLocalMap的,而不是保存在ThreadLocal中
-
getMap方法:獲取到當前執行緒內的ThreadLocalMap物件
每個執行緒內都有ThreadLocalMap物件,名為threadLocals,初始值為null
remove
// 洗掉對應這個執行緒的值
public void remove() {
// 獲取當前執行緒的ThreadLocalMap
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// 移除這個ThreadLocal對應的值
m.remove(this);
}
ThreadLocal使用場景
典型場景1:每個執行緒需要一個獨享的物件(通常是工具類,典工具型別需要使用的類有SimpleDateFormat和Random)
使用ThreadLocal(不僅執行緒安全,而且也沒有synchronized帶來的性能問題,每個執行緒內有自己獨享的SimpleDateFormat物件)
package se.high.thread.threadlocal;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author 結構化思維wz
* Threadlocal 應用, 在多執行緒當中,把一個字串轉換為日期物件,SimpleDateFormat
*/
public class Test02 {
/**
* 定義SimpleDateFormat,該物件可以把字串轉換為日期
*/
private static SimpleDateFormat time = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
/**
* 為每個執行緒指定自己的SimpleDateFormat
*/
static ThreadLocal<SimpleDateFormat> threadLocal = new ThreadLocal<>();
/**
* 定義Runnable介面的實作類
*/
static class ParseDate implements Runnable{
private int i = 0;
public ParseDate(int i) {
this.i = i;
}
/**
* 把字串轉為日期
*/
@Override
public void run() {
String text = "2021年10月5日 20:10:"+String.valueOf(i%60); //構建一個表示日期的字串
try {
//先判斷當前執行緒是否含有日期物件,如果沒有就創建一個
if (threadLocal.get()== null){
threadLocal.set(new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss"));
}
Date date = threadLocal.get().parse(text);
System.out.println(i+"-"+date); //列印日期
} catch (ParseException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
//創建100個執行緒
for (int i = 0; i < 100; i++) {
Thread thread= new Thread(new ParseDate(i));
thread.start();
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
典型場景2:每個執行緒內需要保存全域變數(例如在攔截器中獲取用戶資訊),可以讓不同方法直接使用,避免引數傳遞的麻煩
七、顯示鎖Lock
在JDK5中新增了
java.util.concurrent.locks包下的Lock介面,有ReentrantLock實作類,ReentrantLock鎖稱為可重入鎖, 它功能比synchronized多,
鎖的可重入是指,當一個執行緒獲得一個物件鎖后,再次請求該物件鎖時是可以獲得該物件的鎖的,synchronized關鍵字就是使用的重入鎖,
1??我們先來看看synchronized有什么不足之處,
- 如果臨界區是只讀操作,其實可以多執行緒一起執行,但使用synchronized的話,同一時間只能有一個執行緒執行,
- synchronized無法知道執行緒有沒有成功獲取到鎖
- 使用synchronized,如果臨界區因為IO或者sleep方法等原因阻塞了,而當前執行緒又沒有釋放鎖,就會導致所有執行緒等待,
而這些都是locks包下的鎖可以解決的,
2??公平鎖與非公平鎖
這里的“公平”,其實通俗意義來說就是“先來后到”,也就是FIFO,如果對一個鎖來說,先對鎖獲取請求的執行緒一定會先被滿足,后對鎖獲取請求的執行緒后被滿足,那這個鎖就是公平的,反之,那就是不公平的,
一般情況下,非公平鎖能提升一定的效率,但是非公平鎖可能會發生執行緒饑餓(有一些執行緒長時間得不到鎖)的情況,所以要根據實際的需求來選擇非公平鎖和公平鎖,
ReentrantLock支持非公平鎖和公平鎖兩種,(可以根據構造方法的多載選擇不同的鎖),
Lock中的方法
| 方法名 | 回傳值 | 作用 |
|---|---|---|
lock() | void | 獲得鎖 |
unlock() | void | 釋放鎖 |
tryLock() | boolean | 僅在呼叫時鎖為空閑狀態才獲取該鎖,可以回應中斷 |
tryLock(long time, TimeUnit unit) | boolean | 如果鎖在給定的等待時間內空閑,并且當前執行緒未被中斷,則獲取鎖 |
lockInterruptibly() | void | 如果當前執行緒未被中斷,則獲取鎖,可以回應中斷 |
newCondition() | Condition | 回傳系結到此 Lock 實體的新 Condition 實體 |
lock()
lock()方法是平常使用得最多的一個方法,就是用來獲取鎖,**如果鎖已被其他執行緒獲取,則進行等待,**在前面已經講到,如果采用Lock,必須主動去釋放鎖,并且在發生例外時,不會自動釋放鎖,因此,一般來說,使用Lock必須在try…catch…塊中進行,并且將釋放鎖的操作放在finally塊中進行,以保證鎖一定被被釋放,防止死鎖的發生,通常使用Lock來進行同步的話,是以下面這種形式去使用的:
Lock lock = ...;
lock.lock();
try{
//處理任務
}catch(Exception ex){
}finally{
lock.unlock(); //釋放鎖
}
tryLock()
tryLock()方法是有回傳值的,它表示用來嘗試獲取鎖,如果獲取成功,則回傳true;如果獲取失敗(即鎖已被其他執行緒獲取),則回傳false,也就是說,這個方法無論如何都會立即回傳(在拿不到鎖時不會一直在那等待),
tryLock(long time, TimeUnit unit)方法和tryLock()方法是類似的,只不過區別在于這個方法在拿不到鎖時會等待一定的時間,在時間期限之內如果還拿不到鎖,就回傳false,同時可以回應中斷,如果一開始拿到鎖或者在等待期間內拿到了鎖,則回傳true,
一般情況下,通過tryLock來獲取鎖時是這樣使用的:
Lock lock = ...;
if(lock.tryLock()) {
try{
//處理任務
}catch(Exception ex){
}finally{
lock.unlock(); //釋放鎖
}
}else {
//如果不能獲取鎖,則直接做其他事情
}
lockInterruptibly()
lockInterruptibly()方法比較特殊,當通過這個方法去獲取鎖時,如果執行緒 正在等待獲取鎖,則這個執行緒能夠 回應中斷,即中斷執行緒的等待狀態,例如,當兩個執行緒同時通過lock.lockInterruptibly()想獲取某個鎖時,假若此時執行緒A獲取到了鎖,而執行緒B只有在等待,那么對執行緒B呼叫threadB.interrupt()方法能夠中斷執行緒B的等待程序,
由于lockInterruptibly()的宣告中拋出了例外,所以lock.lockInterruptibly()必須放在try塊中或者在呼叫lockInterruptibly()的方法外宣告拋出 InterruptedException,但推薦使用后者,原因稍后闡述,因此,lockInterruptibly()一般的使用形式如下:
public void method() throws InterruptedException {
lock.lockInterruptibly();
try {
//.....
}
finally {
lock.unlock();
}
}
當一個執行緒獲取了鎖之后,是不會被interrupt()方法中斷的,因為interrupt()方法只能中斷阻塞程序中的執行緒而不能中斷正在運行程序中的執行緒,因此,當通過lockInterruptibly()方法獲取某個鎖時,如果不能獲取到,那么只有進行等待的情況下,才可以回應中斷的,與 synchronized 相比,當一個執行緒處于等待某個鎖的狀態,是無法被中斷的,只有一直等待下去,
unlock()
釋放鎖,在finally中第一句執行,
newCondition()
關鍵字synchronized與wait()/notify這兩個方法一起使用可以實作等待通知模式,
在Lock顯示鎖中,newConditon()方法回傳Condition物件,Condition類也可以用await/signal實作等待通知模式,
使用notify()通知時,JVM會隨機喚醒某個等待的執行緒;使用Condition可以選擇性的通知,
Condition
-
await()await() 會使當前執行緒等待,同時釋放鎖,當前其他執行緒呼叫signal()時,執行緒會重新獲得鎖,并繼續執行,
-
signal()/signalAll()用于喚醒等待的執行緒,
注意:在呼叫
await/signal前,也需要執行緒持有相關的鎖,
package se.high.thread.lock;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 結構化思維wz
*/
public class ConditionTest {
//定義鎖
static Lock lock = new ReentrantLock();
//獲得Condition物件
static Condition condition = lock.newCondition();
//定義執行緒子類
static class SubThread extends Thread{
@Override
public void run() {
try {
lock.lock();
System.out.println("子執行緒獲得鎖...");
System.out.println("子執行緒即將等待等待....");
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
System.out.println("子執行緒釋放鎖....");
}
}
}
public static void main(String[] args) throws InterruptedException {
SubThread t1 = new SubThread();
t1.start();
System.out.println("子執行緒啟動....");
Thread.sleep(3000);
System.out.println("主執行緒睡了3s,現在喚醒子執行緒...");
/*注意===== 在呼叫方法之前需要持有鎖=========*/
try {
lock.lock();
condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
子執行緒啟動....
子執行緒獲得鎖...
子執行緒即將等待等待....
主執行緒睡了3s,現在喚醒子執行緒...
子執行緒釋放鎖....
行程已結束,退出代碼為 0
實體:兩個執行緒交替列印
package se.high.thread.lock;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 結構化思維wz
* 實作兩個執行緒交替列印
*/
public class ConditionTest02 {
public static void main(String[] args) {
MyService myService = new MyService();
//創建列印執行緒
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
myService.printOne();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
myService.printTwo();
}
}
}).start();
}
static class MyService{
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
private boolean flag = true; //列印標志
/**
* 列印方法 ----
*/
public void printOne(){
try {
lock.lock();
while(!flag){
condition.await();
}
System.out.println(Thread.currentThread().getName()+"----------One-------");
flag=false;
condition.signal(); //通知領完的執行緒列印
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
/**
* 列印方法2
*/
public void printTwo(){
try {
lock.lock();
while(flag){
condition.await();
}
System.out.println(Thread.currentThread().getName()+"**********TWO********");
flag=true;
condition.signal(); //通知領完的執行緒列印
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
Thread-0----------One-------
Thread-1**********TWO********
Thread-0----------One-------
Thread-1**********TWO********
Thread-0----------One-------
Thread-1**********TWO********
ReetntranLock
ReentrantLock 是 java.util.concurrent(J.U.C)包中的鎖,是Lock的一個介面,
ReentrantLock,即 可重入鎖,ReentrantLock是唯一實作了Lock介面的類,并且ReentrantLock提供了更多的方法,下面通過一些實體學習如何使用 ReentrantLock,
構造方法(不帶引數 和帶引數 true: 公平鎖; false: 非公平鎖)
package se.high.thread.lock.reentrant;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author 結構化思維wz
* Reentrantlock的基本使用
*/
public class Test02 {
//首先定義一個顯示鎖
private Lock lock = new ReentrantLock();
//定義方法
public void func() {
//先獲得鎖
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.println(i + "---"+Thread.currentThread().getName());
}
} finally {
lock.unlock(); // 確保釋放鎖,從而避免發生死鎖,
}
}
public static void main(String[] args) {
//多個執行緒呼叫同一個方法
Test02 lockTest = new Test02();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(lockTest::func);
executorService.execute(lockTest::func);
}
}
常用方法
| 方法名 | 回傳值 | 作用 |
|---|---|---|
getHoldCount() | int | 回傳當前執行緒呼叫 lock()的次數; |
getQueueLength() | int | 回傳正等待獲得鎖的執行緒預估數; |
getWaitQueueLength(Condition condition) | int | 回傳與 condition 條件相關的執行緒的預估數; |
hasQueueThread(Thread thread) | boolean | 查看引數指定的執行緒是否在等待獲得鎖; |
hasQueuedThreads() | boolean | 查詢是否還有執行緒在等待獲得鎖; |
hasWaiters | boolean | 查詢是否有執行緒正在等待指定的Condition條件; |
isFair() | boolean | 判斷鎖是否為公平鎖; |
isHeldByCurrentThread() | boolean | 判斷當前執行緒是否持有該鎖; |
isLocked() | boolean | 判斷鎖是否被執行緒持有; |
synchronized與ReetntranLock
1. 鎖的實作
synchronized 是 JVM 實作的,而 ReentrantLock 是 JDK 實作的,
2. 性能
新版本 Java 對 synchronized 進行了很多優化,例如自旋鎖等,synchronized 與 ReentrantLock 大致相同,
3. 等待可中斷
當持有鎖的執行緒長期不釋放鎖的時候,正在等待的執行緒可以選擇放棄等待,改為處理其他事情,
ReentrantLock 可中斷,而 synchronized 不行,
4. 公平鎖
公平鎖是指多個執行緒在等待同一個鎖時,必須按照申請鎖的時間順序來依次獲得鎖,
synchronized 中的鎖是非公平的,ReentrantLock 默認情況下也是非公平的,但是也可以是公平的,
5. 鎖系結多個條件
一個 ReentrantLock 可以同時系結多個 Condition 物件,
使用選擇
除非需要使用 ReentrantLock 的高級功能,否則優先使用 synchronized,這是因為 synchronized 是 JVM 實作的一種鎖機制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持,并且使用 synchronized 不用擔心沒有釋放鎖而導致死鎖問題,因為 JVM 會確保鎖的釋放,
ReadWriteLock
ReadWriterLock介面中定義了 readLock() 回傳讀鎖;writeLock()方法回傳寫鎖,該介面的實作類是ReentrantReadWriteLock.
讀寫鎖和排它鎖
我們前面講到的 synchronized用的鎖和 ReentrantLock,其實都是==“排它鎖”==,也就是說,這些鎖在同一時刻只允許一個執行緒進行訪問,
而讀寫鎖可以在同一時刻允許多個讀執行緒訪問,Java提供了ReentrantReadWriteLock類作為讀寫鎖的默認實作,內部維護了兩個鎖:一個讀鎖,一個寫鎖,通過分離讀鎖和寫鎖,使得在“讀多寫少”的環境下,大大地提高了性能,
注意,即使用讀寫鎖,在寫執行緒訪問時,所有的讀執行緒和其它寫執行緒均被阻塞,
讀鎖共享,寫鎖排它,
ReentrantReadWriteLock
這個類也是一個非抽象類,它是ReadWriteLock介面的JDK默認實作,它與ReentrantLock的功能類似,同樣是可重入的,支持非公平鎖和公平鎖,不同的是,它還支持”讀寫鎖“,
注意: readLock() 與 writeLock() 回傳的鎖物件是同一個鎖物件的兩個不同的角色,不是分別獲得兩個不同的鎖,
public class Test {
//定義讀寫鎖
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
//獲得讀鎖
Lock readlock = readWriteLock.readLock();
//獲得寫鎖
Lock writelock = readWriteLock.writeLock();
/**
* 讀資料的方法
*/
void read(){
try {
readlock.lock(); //申請讀鎖
} catch (Exception e) {
e.printStackTrace();
} finally {
readlock.unlock();
}
}
/**
* 寫資料的方法
*/
void write(){
try {
writelock.lock(); //申請寫鎖
} catch (Exception e) {
e.printStackTrace();
} finally {
writelock.unlock();
}
}
}
讀讀共享實體
package se.high.thread.lock.readwrite;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author 結構化思維wz
* 讀讀共享
*/
public class Test01 {
public static void main(String[] args) {
Service service = new Service();
//創建五個執行緒呼叫read方法;
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
service.read();
}
}).start();
}
}
static class Service{
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
public void read(){
try {
readWriteLock.readLock().lock();
System.out.println("獲取到讀鎖,開始讀取資料"+System.currentTimeMillis());
TimeUnit.SECONDS.sleep(3); //模擬讀取資料用時3s;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}
}
獲取到讀鎖,開始讀取資料1633505485461
獲取到讀鎖,開始讀取資料1633505485461
獲取到讀鎖,開始讀取資料1633505485461
獲取到讀鎖,開始讀取資料1633505485461
獲取到讀鎖,開始讀取資料1633505485461
寫寫互斥實體
package se.high.thread.lock.readwrite;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author 結構化思維wz
* 寫寫互斥
*/
public class Test02 {
public static void main(String[] args) {
Service service = new Service();
//創建五個執行緒呼叫write方法;
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
service.write();
}
}).start();
}
}
static class Service{
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
public void write(){
try {
readWriteLock.writeLock().lock();
System.out.println("獲取到寫鎖,開始寫資料"+System.currentTimeMillis());
TimeUnit.SECONDS.sleep(3); //模擬寫取資料用時3s;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
}
}
獲取到寫鎖,開始寫資料1633505890868
獲取到寫鎖,開始寫資料1633505893869
獲取到寫鎖,開始寫資料1633505896878
獲取到寫鎖,開始寫資料1633505899885
獲取到寫鎖,開始寫資料1633505902899
讀寫互斥實體
package se.high.thread.lock.readwrite;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author 結構化思維wz
* 寫寫互斥
*/
public class Test02 {
public static void main(String[] args) {
Service service = new Service();
//創建五個執行緒呼叫write方法;
new Thread(new Runnable() {
@Override
public void run() {
service.read();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
service.write();
}
}).start();
}
static class Service{
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
public void write(){
try {
readWriteLock.writeLock().lock();
System.out.println("獲取到寫鎖,開始寫資料"+System.currentTimeMillis());
TimeUnit.SECONDS.sleep(3); //模擬寫取資料用時3s;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
public void read(){
try {
readWriteLock.readLock().lock();
System.out.println("獲取到讀鎖,開始讀取資料"+System.currentTimeMillis());
TimeUnit.SECONDS.sleep(3); //模擬讀取資料用時3s;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}
}
獲取到讀鎖,開始讀取資料1633506170089
獲取到寫鎖,開始寫資料1633506173104
AQS
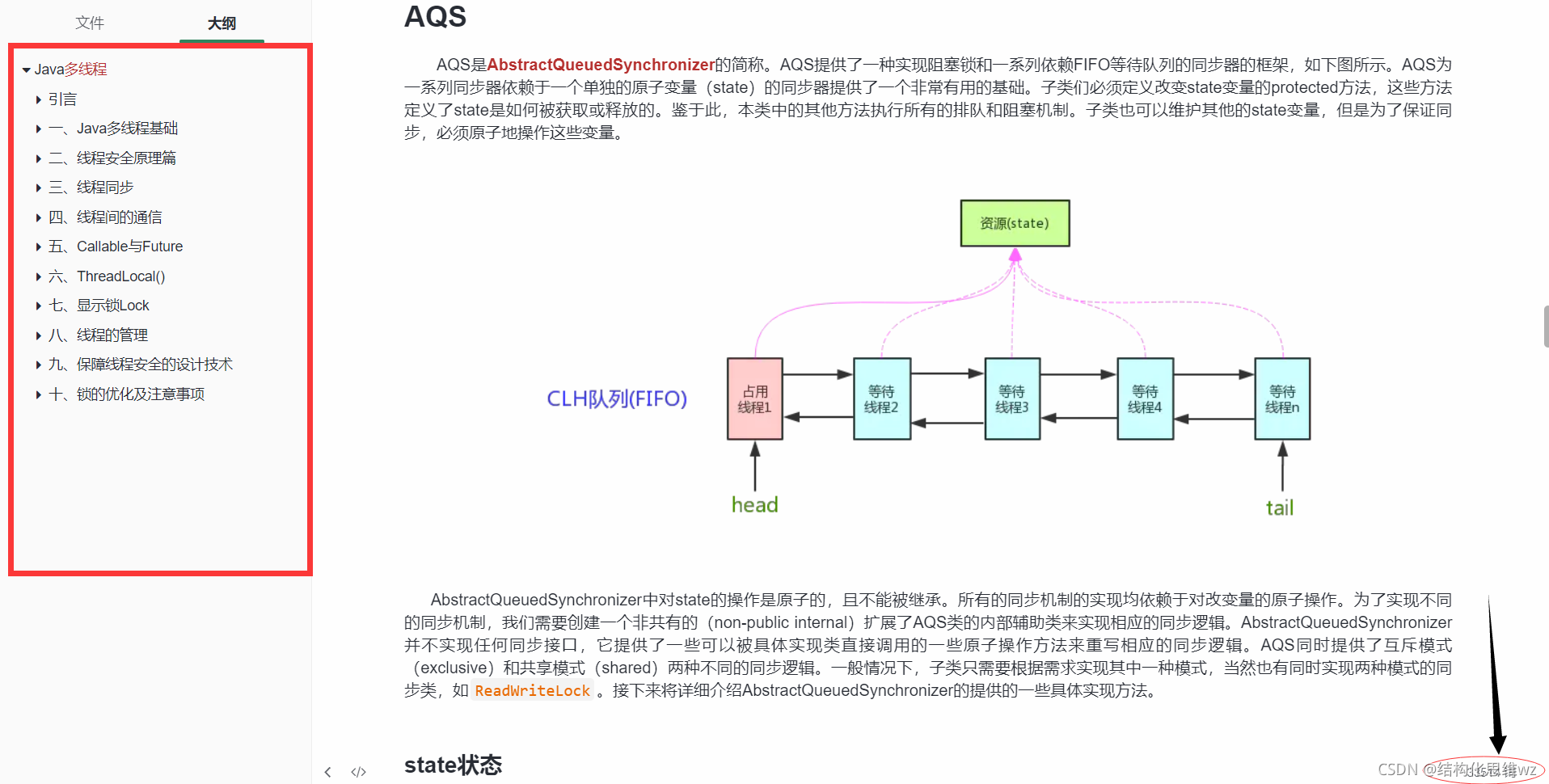
此處僅僅是略寫,可以看敖丙的博客
AQS是AbstractQueuedSynchronizer的簡稱,AQS提供了一種實作阻塞鎖和一系列依賴FIFO等待佇列的同步器的框架,如下圖所示,AQS為一系列同步器依賴于一個單獨的原子變數(state)的同步器提供了一個非常有用的基礎,子類們必須定義改變state變數的protected方法,這些方法定義了state是如何被獲取或釋放的,鑒于此,本類中的其他方法執行所有的排隊和阻塞機制,子類也可以維護其他的state變數,但是為了保證同步,必須原子地操作這些變數,
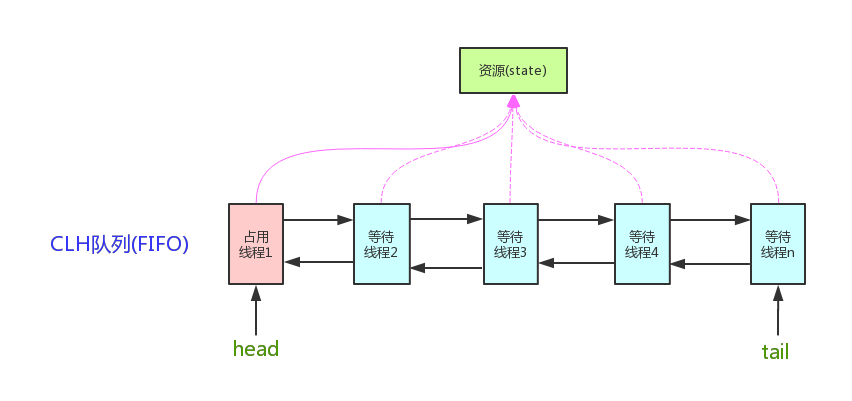
AbstractQueuedSynchronizer中對state的操作是原子的,且不能被繼承,所有的同步機制的實作均依賴于對改變數的原子操作,為了實作不同的同步機制,我們需要創建一個非共有的(non-public internal)擴展了AQS類的內部輔助類來實作相應的同步邏輯,AbstractQueuedSynchronizer并不實作任何同步介面,它提供了一些可以被具體實作類直接呼叫的一些原子操作方法來重寫相應的同步邏輯,AQS同時提供了互斥模式(exclusive)和共享模式(shared)兩種不同的同步邏輯,一般情況下,子類只需要根據需求實作其中一種模式,當然也有同時實作兩種模式的同步類,如ReadWriteLock,接下來將詳細介紹AbstractQueuedSynchronizer的提供的一些具體實作方法,
state狀態
AbstractQueuedSynchronizer維護了一個volatile int型別的變數,用戶表示當前同步狀態,volatile雖然不能保證操作的原子性,但是保證了當前變數state的可見性,state的訪問方式有三種:
- getState()
- setState()
- compareAndSetState()
這三種叫做均是原子操作,其中compareAndSetState的實作依賴于Unsafe的compareAndSwapInt()方法,代碼實作如下:
/**
* The synchronization state.
*/
private volatile int state;
/**
* Returns the current value of synchronization state.
* This operation has memory semantics of a {@code volatile} read.
* @return current state value
*/
protected final int getState() {
return state;
}
/**
* Sets the value of synchronization state.
* This operation has memory semantics of a {@code volatile} write.
* @param newState the new state value
*/
protected final void setState(int newState) {
state = newState;
}
/**
* Atomically sets synchronization state to the given updated
* value if the current state value equals the expected value.
* This operation has memory semantics of a {@code volatile} read
* and write.
*
* @param expect the expected value
* @param update the new value
* @return {@code true} if successful. False return indicates that the actual
* value was not equal to the expected value.
*/
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
自定義資源共享方式
AQS定義兩種資源共享方式:Exclusive(獨占,只有一個執行緒能執行,如ReentrantLock)和Share(共享,多個執行緒可同時執行,如Semaphore/CountDownLatch),
?不同的自定義同步器爭用共享資源的方式也不同,自定義同步器在實作時只需要實作共享資源state的獲取與釋放方式即可,至于具體執行緒等待佇列的維護(如獲取資源失敗入隊/喚醒出隊等),AQS已經在頂層實作好了,自定義同步器實作時主要實作以下幾種方法:
- isHeldExclusively():該執行緒是否正在獨占資源,只有用到condition才需要去實作它,
- tryAcquire(int):獨占方式,嘗試獲取資源,成功則回傳true,失敗則回傳false,
- tryRelease(int):獨占方式,嘗試釋放資源,成功則回傳true,失敗則回傳false,
- tryAcquireShared(int):共享方式,嘗試獲取資源,負數表示失敗;0表示成功,但沒有剩余可用資源;正數表示成功,且有剩余資源,
- tryReleaseShared(int):共享方式,嘗試釋放資源,如果釋放后允許喚醒后續等待結點回傳true,否則回傳false,
八、執行緒的管理
執行緒組
類似于使用檔案夾管理檔案,也可以使用執行緒組來管理執行緒,(了解即可)
在執行緒組中表示一組相似(先關)的執行緒,在執行緒組中也可以定義子執行緒組,
Thread類有幾個構造方法允許在創建執行緒時指定執行緒組,如果在創建執行緒時沒有指定執行緒組,則該執行緒就屬于父線層所在的執行緒組,
JVM在創建main執行緒時,會為它指定一個執行緒組,因此每個Java執行緒都有一個執行緒組與之關聯,可以呼叫getThreadGroup()方法回傳執行緒組,
執行緒組的作用:
- 執行緒組開始是處于安全的考慮設計來用區分不同的 Applet ,然而ThreadGroup 并未實作這一目標,
- 新開發的專案中已經不常用了,
新時代的開發方式:
現在一般會將一組相關的執行緒存入一個陣列或一個集合中,如果僅僅是用來區分執行緒時,可以使用執行緒名稱來區分,
執行緒組的基本使用
創建執行緒組的兩個構造:
ThreadGroup(String name)//指定執行緒組的名稱
ThreadGroup(ThreadGroup parent,Stirng name)//指定父執行緒組and執行緒組的名稱
package se.high.thread.threadgroup;
/**
* @author 結構化思維wz
*/
public class Test01 {
public static void main(String[] args) {
ThreadGroup mainGroup = Thread.currentThread().getThreadGroup(); //main執行緒組
System.out.println(mainGroup);
/*定義執行緒組*/
ThreadGroup group1 = new ThreadGroup("group1");
System.out.println(group1);
/*定義執行緒組,同時指定父組*/
ThreadGroup group2 = new ThreadGroup(group1,"group2");
System.out.println(group2);
System.out.println(group2.getParent()== group1 ? "2的父執行緒組是1" :"2的父執行緒組不是1");
/*創建執行緒時指定執行緒組*/
Thread t1 = new Thread(group1,new Runnable(){
@Override
public void run() {
System.out.println(Thread.currentThread().getThreadGroup()== group1 ? "執行緒組是1" :"執行緒組不是1");
}
});
t1.start();
}
}
捕獲執行緒的執行例外
在執行緒的run方法中,如果有受檢例外必須進行捕獲處理,如果想要獲得run()方法中出現的運行時例外資訊,可以通過回呼介面
UncaughtExceptionhandler獲得哪個執行緒出現了運行時例外,
Thread中有關處理運行例外的方法有:
-getDefaultUncaughtException() 獲得全域的(默認的)例外處理器
getUncaughtExceptionHandler()獲得當前執行緒的UncaughtExceptionHandler,
-setDefaultUncaughtExceptionHandler(Thread.UncaughtExceptionHandler eh)設定全域的UncaughtExceptionHandler,setUncaughtExceptionHandler(Thread.UncaughtExceptionHandler eh)設定當前執行緒的UncaughtExceptionHandler,
當執行緒運行程序中出現例外,JVM會呼叫Thread類的dispatchUncaughtException(Throwable e)方法, 該方法會呼叫getUncaughtExceptionHandler().uncaughtException(this, e); 如果想要獲得執行緒中出現例外的資訊,就需要設定執行緒的UncaughtExceptionHandler,
package se.high.thread.threadexception;
/**
* @author 結構化思維wz
*/
public class Test01 {
public static void main(String[] args) {
//1)設定執行緒全域的回呼介面
Thread.setDefaultUncaughtExceptionHandler((t, e) -> {
//t引數接收發生例外的執行緒, e就是該執行緒中的例外
System.out.println(t.getName() + "執行緒產生了例外: " + e.getMessage());
});
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "開始運行");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
//執行緒中的受檢例外必須捕獲處理
e.printStackTrace();
}
System.out.println(12 / 0 ); //會產生算術例外
});
t1.start();
new Thread(() -> {
String txt = null;
System.out.println( txt.length()); //會產生空指標例外
}).start();
/*
在實際開發中,這種設計例外處理的方式還是比較常用的,尤其是例外執行的方法
如果執行緒產生了例外, JVM會呼叫dispatchUncaughtException()方法,在該方法中呼叫了getUncaughtExceptionHandler().uncaughtException(this, e); 如果當前執行緒設定了UncaughtExceptionHandler回呼介面就直接呼叫它自己的uncaughtException方法, 如果沒有設定則呼叫當前執行緒所在執行緒組UncaughtExceptionHandler回呼介面的uncaughtException方法,如果執行緒組也沒有設定回呼介面,則直接把例外的堆疊資訊定向到System.err中
*/
}
}
Thread-0開始運行
Thread-1執行緒產生了例外: null
Thread-0執行緒產生了例外: / by zero
行程已結束,退出代碼為 0
注入Hook鉤子執行緒
很多軟體都包括MySQL,ZK,kafka等都存在Hook執行緒的校驗機制,目的是校驗行程是否已啟動,防止重復啟動程式,
Hook執行緒也稱為鉤子執行緒,當JVM退出的時候會執行Hook執行緒,
經常在程式啟動時創建一個.lock檔案,用.lock檔案消炎程式是否啟動,在JVM退出時再洗掉.lock檔案,在Hook執行緒中處理防止重新啟動行程外,還可以做資源釋放,盡量避免在Hook執行緒中進行復雜的操作,
通過Hook執行緒防止程式重復啟動
package se.high.thread.hook;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.concurrent.TimeUnit;
/**
* 通過Hook執行緒防止程式重復啟動
*/
public class Test {
public static void main(String[] args) {
//1)注入Hook執行緒,在程式退出時洗掉.lock檔案
Runtime.getRuntime().addShutdownHook(new Thread(){
@Override
public void run() {
System.out.println("JVM退出,會啟動當前Hook執行緒,在Hook執行緒中洗掉.lock檔案");
getLockFile().toFile().delete();
}
});
//2)程式運行時,檢查lock檔案是否存在,如果lock檔案存在,則拋出例外
if ( getLockFile().toFile().exists()){
throw new RuntimeException("程式已啟動");
}else { //檔案不存在,說明程式是第一次啟動,創建lock檔案
try {
getLockFile().toFile().createNewFile();
System.out.println("程式在啟動時創建了lock檔案");
} catch (IOException e) {
e.printStackTrace();
}
}
//模擬程式運行
for (int i = 0; i < 10; i++) {
System.out.println("程式正在運行");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static Path getLockFile(){
return Paths.get("", "tmp.lock");
}
}
程式運行的時候創建:

程式運行結束,檔案自動洗掉,
執行緒池
什么是執行緒池
可以以 new Thread( () -> { 執行緒執行的任務 }).start(); 這種形式開啟一個執行緒. 當run()方法運行結束,執行緒物件會被GC釋放,
在真實的生產環境中,可能需要很多執行緒來支撐整個應用,當執行緒數量非常多時 ,反而會耗盡CPU資源. 如果不對執行緒進行控制與管理,反而會影響程式的性能. 執行緒開銷主要包括: 創建與啟動執行緒的開銷; 執行緒銷毀開銷; 執行緒調度的開銷; 執行緒數量受限CPU處理器數量,
執行緒池就是有效使用執行緒的一種常用方式. 執行緒池內部可以預先創建一定數量的作業執行緒,客戶端代碼直接將任務作為一個物件提交給執行緒池, 執行緒池將這些任務快取在作業佇列中, 執行緒池中的作業執行緒不斷地從佇列中取出任務并執行,
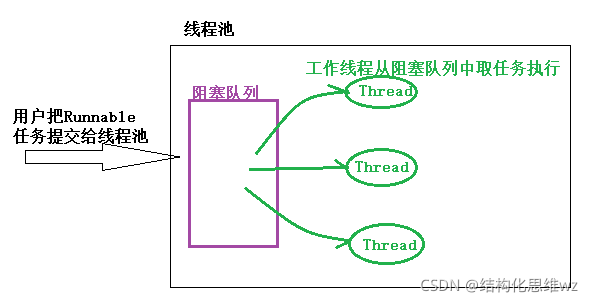
使用執行緒池主要有以下三個原因:
- 創建/銷毀執行緒需要消耗系統資源,執行緒池可以復用已創建的執行緒,
- 控制并發的數量,并發數量過多,可能會導致資源消耗過多,從而造成服務器崩潰,(主要原因)
- 可以對執行緒做統一管理,
ThreadPoolExecutor的構造方法
Java中的執行緒池頂層介面是Executor介面,ThreadPoolExecutor是這個介面的實作類,
// 五個引數的建構式
public ThreadPoolExecutor(int corePoolSize, //該執行緒池中核心執行緒數最大值
int maximumPoolSize,//該執行緒池中執行緒總數最大值
long keepAliveTime,//非核心執行緒閑置超時時長
TimeUnit unit,//keepAliveTime的單位,
BlockingQueue<Runnable> workQueue)//阻塞佇列,維護著等待執行的Runnable任務物件,
// 六個引數的建構式-1
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory)//創建執行緒的工廠 ,用于批量創建執行緒,統一在創建執行緒時設定一些引數,如是否守護線 程、執行緒的優先級等,如果不指定,會新建一個默認的執行緒工廠,
// 六個引數的建構式-2
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)//拒絕處理策略,執行緒數量大于最大執行緒數就會采用拒絕處理策略
// 七個引數的建構式
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
-
int corePoolSize:該執行緒池中核心執行緒數最大值
核心執行緒:執行緒池中有兩類執行緒,核心執行緒和非核心執行緒,核心執行緒默認情況下會一直存在于執行緒池中,即使這個核心執行緒什么都不干(鐵飯碗),而非核心執行緒如果長時間的閑置,就會被銷毀(臨時工),
-
int maximumPoolSize:該執行緒池中執行緒總數最大值 ,
該值等于核心執行緒數量 + 非核心執行緒數量,
-
long keepAliveTime:非核心執行緒閑置超時時長,
非核心執行緒如果處于閑置狀態超過該值,就會被銷毀,如果設定allowCoreThreadTimeOut(true),則會也作用于核心執行緒,
-
TimeUnit unit:keepAliveTime的單位,
TimeUnit是一個列舉型別 ,包括以下屬性:
NANOSECONDS : 1微毫秒 = 1微秒 / 1000 ; MICROSECONDS :1微秒 = 1毫秒 / 1000 ;MILLISECONDS : 1毫秒 = 1秒 /1000 ;SECONDS : 秒; MINUTES : 分 ;HOURS : 小時 ;DAYS : 天
-
BlockingQueue workQueue:阻塞佇列,維護著等待執行的Runnable任務物件,
常用的幾個阻塞佇列:
-
LinkedBlockingQueue
鏈式阻塞佇列,底層資料結構是鏈表,默認大小是
Integer.MAX_VALUE,也可以指定大小, -
ArrayBlockingQueue
陣列阻塞佇列,底層資料結構是陣列,需要指定佇列的大小,
-
SynchronousQueue
同步佇列,內部容量為0,每個put操作必須等待一個take操作,反之亦然,
-
DelayQueue
延遲佇列,該佇列中的元素只有當其指定的延遲時間到了,才能夠從佇列中獲取到該元素 ,
-
-
ThreadFactory threadFactory
創建執行緒的工廠 ,用于批量創建執行緒,統一在創建執行緒時設定一些引數,如是否守護執行緒、執行緒的優先級等,如果不指定,會新建一個默認的執行緒工廠,
-
RejectedExecutionHandler handler
拒絕處理策略,執行緒數量大于最大執行緒數就會采用拒絕處理策略,四種拒絕處理的策略為 :
- ThreadPoolExecutor.AbortPolicy:默認拒絕處理策略,丟棄任務并拋出RejectedExecutionException例外,
- ThreadPoolExecutor.DiscardPolicy:丟棄新來的任務,但是不拋出例外,
- ThreadPoolExecutor.DiscardOldestPolicy:丟棄佇列頭部(最舊的)的任務,然后重新嘗試執行程式(如果再次失敗,重復此程序),
- ThreadPoolExecutor.CallerRunsPolicy:由呼叫執行緒處理該任務,
ThreadPoolExecutor的策略
執行緒池本身有一個調度執行緒,這個執行緒就是用于管理布控整個執行緒池里的各種任務和事務,例如創建執行緒、銷毀執行緒、任務佇列管理、執行緒佇列管理等等,
故執行緒池也有自己的狀態,ThreadPoolExecutor類中使用了一些final int常量變數來表示執行緒池的狀態 ,分別為RUNNING、SHUTDOWN、STOP、TIDYING 、TERMINATED,
-
執行緒池創建后處于RUNNING狀態,
-
呼叫shutdown()方法后處于SHUTDOWN狀態,執行緒池不能接受新的任務,清除一些空閑worker,會等待阻塞佇列的任務完成,
-
呼叫shutdownNow()方法后處于STOP狀態,執行緒池不能接受新的任務,中斷所有執行緒,阻塞佇列中沒有被執行的任務全部丟棄,此時,poolsize=0,阻塞佇列的size也為0,
-
當所有的任務已終止,ctl記錄的”任務數量”為0,執行緒池會變為**TIDYING(整潔)**狀態,接著會執行 終止terminated()函式,
ThreadPoolExecutor中有一個控制狀態的屬性叫
ctl,它是一個AtomicInteger型別的變數,執行緒池狀態就是通過AtomicInteger型別的成員變數ctl來獲取的,獲取的
ctl值傳入runStateOf方法,與~CAPACITY位與運算(CAPACITY是低29位全1的int變數),~CAPACITY在這里相當于掩碼,用來獲取ctl的高3位,表示執行緒池狀態;而另外的低29位用于表示作業執行緒數 -
執行緒池處在TIDYING狀態時,執行完terminated()方法之后,就會由 TIDYING -> TERMINATED, 執行緒池被設定為TERMINATED狀態,
執行緒池主要的任務處理流程
總結一下處理流程
- 執行緒總數量 < corePoolSize(核心執行緒),無論執行緒是否空閑,都會新建一個核心執行緒執行任務(讓核心執行緒數量快速達到corePoolSize,在核心執行緒數量 < corePoolSize時),注意,這一步需要獲得全域鎖,
- 執行緒總數量 >= corePoolSize時,新來的執行緒任務會進入任務佇列中等待,然后空閑的核心執行緒會依次去快取佇列中取任務來執行(體現了執行緒復用),
- 當快取佇列滿了,說明這個時候任務已經多到爆棚,需要一些“臨時工”來執行這些任務了,于是會創建非核心執行緒去執行這個任務,注意,這一步需要獲得全域鎖,
- 快取佇列滿了, 且總執行緒數達到了maximumPoolSize,則會采取上面提到的拒絕策略進行處理,
整個程序如圖所示:
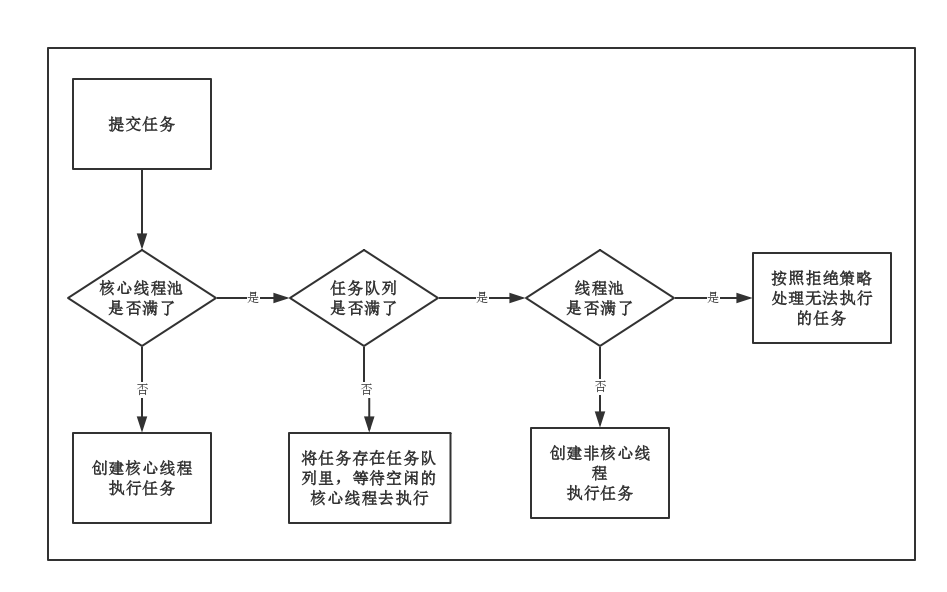
ThreadPoolExecutor如何做到執行緒復用的?
我們知道,一個執行緒在創建的時候會指定一個執行緒任務,當執行完這個執行緒任務之后,執行緒自動銷毀,但是執行緒池卻可以復用執行緒,即一個執行緒執行完執行緒任務后不銷毀,繼續執行另外的執行緒任務,那么,執行緒池如何做到執行緒復用呢?
原來,ThreadPoolExecutor在創建執行緒時,會將執行緒封裝成作業執行緒worker,并放入作業執行緒組中,然后這個worker反復從阻塞佇列中拿任務去執行,
自定義執行緒工廠
package se.high.thread.executor;
import java.util.Date;
import java.util.Random;
import java.util.concurrent.*;
/**
* @author 結構化思維wz
*/
public class Test05 {
public static void main(String[] args) throws InterruptedException {
//定義任務
Runnable r = new Runnable() {
@Override
public void run() {
int num = new Random().nextInt(10);
System.out.println(Thread.currentThread().getName() + "號執行緒-->" + System.currentTimeMillis() + "開始睡眠:" + num + "秒");
try {
TimeUnit.SECONDS.sleep(num);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
//創建執行緒池, 使用自定義執行緒工廠, 采用默認的拒絕策略是拋出例外
ExecutorService executorService = new ThreadPoolExecutor(5, 5, 0, TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadFactory() {
//自定義執行緒工廠
@Override
public Thread newThread(Runnable r) {
//根據引數r接收的任務,創建一個執行緒
Thread t = new Thread( r );
t.setDaemon(true); //設定為守護執行緒, 當主執行緒運行結束,執行緒池中的執行緒會自動退出
System.out.println("創建了執行緒: " + t);
return t ;
}
});
//提交5個任務, 當給當前執行緒池提交的任務超過5個時,執行緒池默認拋出例外
for (int i = 0; i < 5; i++) {
executorService.execute(r);
}
//主執行緒睡眠
Thread.sleep(10000);
//主執行緒睡眠超時, 主執行緒結束, 執行緒池中的執行緒會自動退出
}
}
創建了執行緒: Thread[Thread-0,5,main]
創建了執行緒: Thread[Thread-1,5,main]
創建了執行緒: Thread[Thread-2,5,main]
創建了執行緒: Thread[Thread-3,5,main]
創建了執行緒: Thread[Thread-4,5,main]
Thread-0號執行緒-->1633525975792開始睡眠:4秒
Thread-4號執行緒-->1633525975792開始睡眠:9秒
Thread-1號執行緒-->1633525975792開始睡眠:1秒
Thread-3號執行緒-->1633525975792開始睡眠:6秒
Thread-2號執行緒-->1633525975792開始睡眠:4秒
行程已結束,退出代碼為 0
監控執行緒池的方法
ThreadPoolExecutor提供了一組方法用于監控執行緒池,
- int
getActiveCount()獲得執行緒池中當前活動執行緒的數量, - long
getCompletedTaskCount()回傳執行緒池完成任務的數量, - int
getCorePoolSize()執行緒池中核心執行緒的數量, - int
getLargestPoolSize()回傳執行緒池曾經達到的執行緒的最大數, - int
getMaximumPoolSize()回傳執行緒池的最大容量, - int
getPoolSize()當前執行緒池的大小, - BlockingQueue
getQueue()回傳阻塞佇列, - long
getTaskCount()回傳執行緒池收到的任務總數,
有時需要對執行緒池進行擴展,如在監控每個任務的開始和結束時間,或者自定義一些其他增強的功能,
ThreadPoolExecutor執行緒池提供了兩個方法:
● protected void afterExecute(Runnable r, Throwable t)
● protected void beforeExecute(Thread t, Runnable r)
在執行緒池執行任務前會呼叫beforeExecute()方法,在任務結束后(任務例外退出)會執行afterExecute()方法,
執行緒池中的例外跟蹤
在使用ThreadPoolExecutor進行submit提交任務時,有的任務拋出了例外,但是執行緒池并沒有進行提示,即執行緒池把任務中的例外給吃掉了,可以把submit提交改為execute執行,也可以對ThreadPoolExecutor執行緒池進行擴展.對提交的任務進行包裝:
//自定義執行緒池類
private static class TraceThreadPollExecutor extends ThreadPoolExecutor{
public TraceThreadPollExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
//定義方法,對執行的任務進行包裝,接收兩個引數,第一個引數接收要執行的任務,第二個引數是一個Exception例外
public Runnable wrap( Runnable task, Exception exception){
return new Runnable() {
@Override
public void run() {
try {
task.run();
}catch (Exception e ){
exception.printStackTrace();
throw e;
}
}
};
}
//重寫submit方法
@Override
public Future submit(Runnable task) {
return super.submit(wrap(task, new Exception("客戶跟蹤例外")));
}
@Override
public void execute(Runnable command) {
super.execute(wrap(command, new Exception("客戶跟蹤例外")));
}
}
//定義類實作Runnable介面,用于計算兩個數相除
private static class DivideTask implements Runnable{
private int x;
private int y;
public DivideTask(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "計算:" + x + " / " + y + " = " + (x/y));
}
}
public static void main(String[] args) {
//創建執行緒池
// ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 0, TimeUnit.SECONDS, new SynchronousQueue<>());
//使用自定義的執行緒池
ThreadPoolExecutor poolExecutor = new TraceThreadPollExecutor(0, Integer.MAX_VALUE, 0, TimeUnit.SECONDS, new SynchronousQueue<>());
//向執行緒池中添加計算兩個數相除的任務
for (int i = 0; i < 5; i++) {
poolExecutor.submit(new DivideTask(10, i));
// poolExecutor.execute(new DivideTask(10, i));
}
}
四種常見的執行緒池
Executors類中提供的幾個靜態方法來創建執行緒池,
主要有四種 Executor:
- CachedThreadPool:一個任務創建一個執行緒;
- FixedThreadPool:所有任務只能使用固定大小的執行緒;
- SingleThreadExecutor:相當于大小為 1 的 FixedThreadPool,
- newScheduledThreadPool:創建一個定長執行緒池,支持定時及周期性任務執行,
submit()和execut的區別:
1、execut()可以添加一個Runable任務,submit()不僅可以添加Runable任務還可以添加Callable任務,
2、execut()沒有回傳值,而submit()在添加Callable任務時會有回傳值(再添加Runable任務時也有,不過無意義),可以通過回傳值來查看執行緒執行的情況,
3、如果發生例外submit()可以通過捕獲Future.get拋出的例外,而execute()會終止這個執行緒,
4、submit中拋出例外不管提交的是Runnable還是Callable型別的任務,如果不對回傳值Future呼叫get()方法,都會吃掉例外
1.newCachedThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
CacheThreadPool的運行流程如下:
- 提交任務進執行緒池,
- 因為corePoolSize為0的關系,不創建核心執行緒,執行緒池最大為Integer.MAX_VALUE,
- 嘗試將任務添加到SynchronousQueue佇列,
- 如果SynchronousQueue入列成功,等待被當前運行的執行緒空閑后拉取執行,如果當前沒有空閑執行緒,那么就創建一個非核心執行緒,然后從SynchronousQueue拉取任務并在當前執行緒執行,
- 如果SynchronousQueue已有任務在等待,入列操作將會阻塞,
當需要執行很多短時間的任務時,CacheThreadPool的執行緒復用率比較高, 會顯著的提高性能,而且執行緒60s后會回收,意味著即使沒有任務進來,CacheThreadPool并不會占用很多資源,
應用實體:
public class Test02 {
public static void main(String[] args) {
//創建執行緒池
ExecutorService fixed = Executors.newCachedThreadPool();
//向執行緒池中提交18個任務
for (int i = 0; i < 18; i++) {
fixed.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId()+"編號的任務正在執行"+System.currentTimeMillis());
try {
Thread.sleep(3000); //模擬任務
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
結果:直接創建18個執行緒
12編號的任務正在執行1633523743560
15編號的任務正在執行1633523743560
14編號的任務正在執行1633523743560
13編號的任務正在執行1633523743560
17編號的任務正在執行1633523743560
16編號的任務正在執行1633523743560
18編號的任務正在執行1633523743560
20編號的任務正在執行1633523743560
19編號的任務正在執行1633523743560
21編號的任務正在執行1633523743560
22編號的任務正在執行1633523743560
23編號的任務正在執行1633523743560
24編號的任務正在執行1633523743560
25編號的任務正在執行1633523743560
26編號的任務正在執行1633523743560
27編號的任務正在執行1633523743561
28編號的任務正在執行1633523743561
29編號的任務正在執行1633523743561
2.newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }核心執行緒數量和總執行緒數量相等,都是傳入的引數nThreads,所以只能創建核心執行緒,不能創建非核心執行緒,因為LinkedBlockingQueue的默認大小是Integer.MAX_VALUE,故如果核心執行緒空閑,則交給核心執行緒處理;如果核心執行緒不空閑,則入列等待,直到核心執行緒空閑,
與CachedThreadPool的區別:
- 因為 corePoolSize == maximumPoolSize ,所以FixedThreadPool只會創建核心執行緒, 而CachedThreadPool因為corePoolSize=0,所以只會創建非核心執行緒,
- 在 getTask() 方法,如果佇列里沒有任務可取,執行緒會一直阻塞在 LinkedBlockingQueue.take() ,執行緒不會被回收, CachedThreadPool會在60s后識訓,
- 由于執行緒不會被回收,會一直卡在阻塞,所以沒有任務的情況下, FixedThreadPool占用資源更多,
- 都幾乎不會觸發拒絕策略,但是原理不同,FixedThreadPool是因為阻塞佇列可以很大(最大為Integer最大值),故幾乎不會觸發拒絕策略;CachedThreadPool是因為執行緒池很大(最大為Integer最大值),幾乎不會導致執行緒數量大于最大執行緒數,故幾乎不會觸發拒絕策略,
使用案例:
package se.high.thread.executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author 結構化思維wz
* 執行緒池耳釘基本使用
*/
public class Test01 {
public static void main(String[] args) {
//創建執行緒池
ExecutorService fixed = Executors.newFixedThreadPool(5);
//向執行緒池中提交18個任務
for (int i = 0; i < 18; i++) {
fixed.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId()+"編號的任務正在執行"+System.currentTimeMillis());
try {
Thread.sleep(3000); //模擬任務
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
結果:執行緒池中一直有5個執行緒,而且不會結束,
3.newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }有且僅有一個核心執行緒( corePoolSize == maximumPoolSize=1),使用了LinkedBlockingQueue(容量很大),所以,不會創建非核心執行緒,所有任務按照先來先執行的順序執行,如果這個唯一的執行緒不空閑,那么新來的任務會存盤在任務佇列里等待執行,
public class Test03 {
public static void main(String[] args) {
//創建執行緒池
ExecutorService fixed = Executors.newSingleThreadExecutor();
//向執行緒池中提交18個任務
for (int i = 0; i < 18; i++) {
fixed.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getId()+"編號的任務正在執行"+System.currentTimeMillis());
try {
Thread.sleep(3000); //模擬任務
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
12編號的任務正在執行1633523971042
12編號的任務正在執行1633523974053
12編號的任務正在執行1633523977066
12編號的任務正在執行1633523980077
12編號的任務正在執行1633523983086
.....
4.newScheduledThreadPool
創建一個定長執行緒池,支持定時及周期性任務執行,
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } //ScheduledThreadPoolExecutor(): public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS, new DelayedWorkQueue()); }
package se.high.thread.executor;
import java.text.SimpleDateFormat;
import java.time.format.DateTimeFormatter;
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* @author 結構化思維wz
*/
public class Test04 {
static SimpleDateFormat date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
//回圈周期執行
/**
* Runnable–要執行的任務
* initialDelay–延遲第一次執行的時間
* period–一次執行終止與下一次執行開始之間的延遲
* unit–initialDelay和delay引數的時間單位
*/
System.out.println(date.format(System.currentTimeMillis()));
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
String time = date.format(System.currentTimeMillis());
System.out.println("延遲一秒,每3s運行一次"+time);
}
}, 1, 3, TimeUnit.SECONDS);
}
}
2021-10-06 21:22:48
延遲一秒,每3s運行一次2021-10-06 21:22:49
延遲一秒,每3s運行一次2021-10-06 21:22:52
延遲一秒,每3s運行一次2021-10-06 21:22:55
延遲一秒,每3s運行一次2021-10-06 21:22:58
延遲一秒,每3s運行一次2021-10-06 21:23:01
延遲一秒,每3s運行一次2021-10-06 21:23:04
延遲一秒,每3s運行一次2021-10-06 21:23:07
延遲一秒,每3s運行一次2021-10-06 21:23:10
四種常見的執行緒池基本夠我們使用了,但是《阿里巴巴開發手冊》不建議我們直接使用Executors類中的執行緒池,而是通過ThreadPoolExecutor的方式,這樣的處理方式讓寫的同學需要更加明確執行緒池的運行規則,規避資源耗盡的風險,
ForkJoinPoll
“分而治之”是一個有效的處理大資料的方法,著名的MapReduce就是采用這種分而治之的思路. 簡單點說,如果要處理的1000個資料,但是我們不具備處理1000個資料的能力,可以只處理10個資料, 可以把這1000個資料分階段處理100次,每次處理10個,把100次的處理結果進行合成,形成最后這1000個資料的處理結果,
把一個大任務呼叫fork()方法分解為若干小的任務,把小任務的處理結果進行join()合并為大任務的結果,
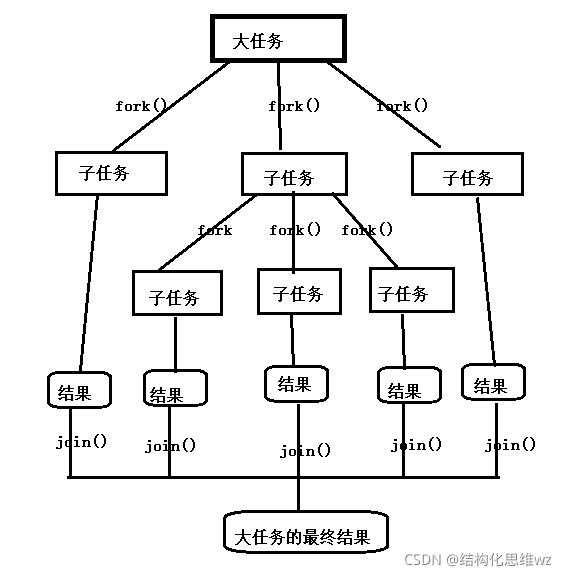
系統對ForkJoinPool執行緒池進行了優化,提交的任務數量與執行緒的數量不一定是一對一關系.在多數情況下,一個物理執行緒實際上需要處理多個邏輯任務,
ForkJoinPool執行緒池中最常用的方法是:
ForkJoinTask submit(ForkJoinTask task) 向執行緒池提交一個ForkJoinTask任務. ForkJoinTask任務支持fork()分解與 join()等待的任務. ForkJoinTask有兩個重要的子類:RecursiveAction和 RecursiveTask ,它們的區別在于RecursiveAction任務沒有回傳值, RecursiveTask 任務可以帶有回傳值,
package se.high.thread.executor;
import java.util.ArrayList;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* @author 結構化思維wz
* 演示ForkJoinPool執行緒池的使用
* 使用該執行緒池模擬數列求和
*/
public class Test07 {
//計算數列的和, 需要回傳結果,可以定義任務繼承RecursiveTask
private static class CountTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000; //定義資料規模的閾值,允許計算10000個數內的和,超過該閾值的數列就需要分解
private static final int TASKNUM = 100; //定義每次把大任務分解為100個小任務
private long start; //計算數列的起始值
private long end; //計算數列的結束值
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
//重寫RecursiveTask類的compute()方法,計算數列的結果
@Override
protected Long compute() {
long sum = 0 ; //保存計算的結果
//判斷任務是否需要繼續分解,如果當前數列end與start范圍的數超過閾值THRESHOLD,就需要繼續分解
if ( end - start < THRESHOLD){
//小于閾值可以直接計算
for (long i = start ; i <= end; i++){
sum += i;
}
}else { //數列范圍超過閾值,需要繼續分解
//約定每次分解成100個小任務,計算每個任務的計算量
long step = (start + end ) / TASKNUM;
//start = 0 , end = 200000, step = 2000, 如果計算[0,200000]范圍內數列的和, 把該范圍的數列分解為100個小任務,每個任務計算2000個數即可
//注意,如果任務劃分的層次很深,即THRESHOLD閾值太小,每個任務的計算量很小,層次劃分就會很深,可能出現兩種情況:一是系統內的執行緒數量會越積越多,導致性能下降嚴重; 二是分解次數過多,方法呼叫過多可能會導致堆疊溢位
//創建一個存盤任務的集合
ArrayList<CountTask> subTaskList = new ArrayList<>();
long pos = start; //每個任務的起始位置
for (int i = 0; i < TASKNUM; i++) {
long lastOne = pos + step; //每個任務的結束位置
//調整最后一個任務的結束位置
if ( lastOne > end ){
lastOne = end;
}
//創建子任務
CountTask task = new CountTask(pos, lastOne);
//把任務添加到集合中
subTaskList.add(task);
//呼叫for()提交子任務
task.fork();
//調整下個任務的起始位置
pos += step + 1;
}
//等待所有的子任務結束后,合并計算結果
for (CountTask task : subTaskList) {
sum += task.join(); //join()會一直等待子任務執行完畢回傳執行結果
}
}
return sum;
}
}
public static void main(String[] args) {
//創建ForkJoinPool執行緒池
ForkJoinPool forkJoinPool = new ForkJoinPool();
//創建一個大的任務
CountTask task = new CountTask(0L, 200000L);
//把大任務提交給執行緒池
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
Long res = result.get(); //呼叫任務的get()方法回傳結果
System.out.println("計算數列結果為:" + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//驗證
long s = 0L;
for (long i = 0; i <= 200000 ; i++) {
s += i;
}
System.out.println(s);
}
}
九、保障執行緒安全的設計技術
從面向物件設計的角度出發介紹幾種保障執行緒安全的設計技術,這些技術可以使得我們在不必借助鎖的情況下保障執行緒安全,避免鎖可能導致的問題及開銷,
1.Java運行時存盤空間
Java運行時(Java runtime)記憶體可以分為堆疊區,堆區與方法區(非堆空間),
**堆疊空間(Stack Space)**為執行緒的執行準備一段固定大小的存盤空間,每個執行緒都有獨立的執行緒堆疊空間,創建執行緒時就為執行緒分配堆疊空間.在執行緒堆疊中每呼叫一個方法就給方法分配一個堆疊幀,堆疊幀用于存盤方法的區域變數,回傳值等私有資料, 即區域變數存盤在堆疊空間中, 基本型別變數也是存盤在堆疊空間中, 參考型別變數值也是存盤在堆疊空間中,參考 的物件存盤在堆中. 由于執行緒堆疊是相互獨立的,一個執行緒不能訪問另外一個執行緒的堆疊空間,因此執行緒對區域變數以及只能通過當前執行緒的區域變數才能訪問的物件進行的操作具有固定的執行緒安全性,
堆空間(Heap Space)用于存盤物件,是在JVM啟動時分配的一段可以動態擴容的記憶體空間. 創建物件時,在堆空間中給物件分配存盤空間,實體變數就是存盤在堆空間中的, 堆空間是多個執行緒之間可以共享的空間,因此實體變數可以被多個執行緒共享. 多個執行緒同時操作實體變數可能存在執行緒安全問題,
**非堆空間(Non-Heap Space)**用于存盤常量,類的元資料等, 非堆空間也是在JVM啟動時分配的一段可以動態擴容的存盤空間.類的元資料包括靜態變數,類有哪些方法及這些方法的元資料(方法名,引數,回傳值等). 非堆空間也是多個 執行緒可以共享的, 因此訪問非堆空間中的靜態變數也可能存在執行緒安全問題,
堆空間與非堆空間是執行緒可以共享的空間,即實體變數與靜態變數是執行緒可以共享的,可能存在執行緒安全問題. 堆疊空間是執行緒私有的存盤空間,區域變數存盤在堆疊空間中,區域變數具有固定的執行緒安全性,
2.無狀態物件
Java無狀態物件
物件就是資料及對資料操作的封裝, 物件所包含的資料稱為物件的狀態(State), 實體變數與靜態變數稱為狀態變數,
如果一個類的同一個實體被多個執行緒共享并不會使這些執行緒存盤共享的狀態,那么該類的實體就稱為無狀態物件(Stateless Object). 反之如果一個類的實體被多個執行緒共享會使這些執行緒存在共享狀態,那么 該類的實體稱為有狀態物件. 實際上無狀態物件就是不包含任何實體變數也不包含任何靜態變數的物件,
執行緒安全問題的前提是多個執行緒存在共享的資料,實作執行緒安全的一種辦法就是避免在多個執行緒之間共享資料,使用無狀態物件就是這種方法,
3.不可變物件
不可變物件是指一經創建它的狀態就保持不變的物件,不可變物件具有固有的執行緒安全性. 當不可變物件現實物體的狀態發生變化時,系統會創建一個新的不可變物件,就如String字串物件. 一個不可變物件需要滿足以下條件:
1、類本身使用final修飾,防止通過創建子類來改變它的定義,
2、所有的欄位都是final修飾的,final欄位在創建物件時必須顯示初始化,不能被修改,
3、如果欄位參考了其他狀態可變的物件(集合,陣列),則這些欄位必須是private私有的,
不可變物件主要的應用場景:
1、被建模物件的狀態變化不頻繁,
2、同時對一組相關資料進行寫操作,可以應用不可變物件,既可以保障原子性也可以避免鎖的使用,
3、使用不可變物件作為安全可靠的Map鍵, HashMap鍵值對的存盤位置與鍵的hashCode()有關,如果鍵的內部狀態發生了變化會導致鍵的哈希碼不同,可能會影響鍵值對的存盤位置. 如果HashMap的鍵是一個不可變物件,則hashCode()方法的回傳值恒定,存盤位置是固定的,
4.執行緒特有物件
我們可以選擇不共享非執行緒安全的物件,對于非執行緒安全的物件,每個執行緒都創建一個該物件的實體,各個執行緒執行緒訪問各自創建的實體,一個執行緒不能訪問另外一個執行緒創建的實體. 這種各個執行緒創建各自的實體,一個實體只能被一個執行緒訪問的物件就稱為執行緒特有物件. 執行緒特有物件既保障了對非執行緒安全物件的訪問的執行緒安全,又避免了鎖的開銷.執行緒特有物件也具有固有的執行緒安全性,
ThreadLocal類相當于執行緒訪問其特有物件的代理,即各個執行緒通過ThreadLocal物件可以創建并訪問各自的執行緒特有物件,泛型T指定了執行緒特有物件的型別. 一個執行緒可以使用不同的ThreadLocal實體來創建并訪問不同的執行緒特有物件,
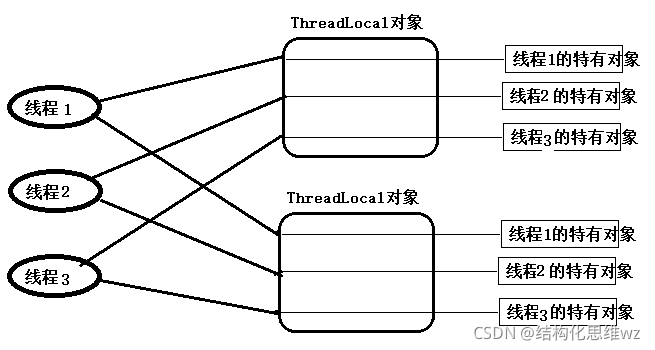
ThreadLocal實體為每個訪問它的執行緒都關聯了一個該執行緒特有的物件, ThreadLocal實體都有當前執行緒與特有實體之間的一個關聯,
5.裝飾器模式
裝飾器模式可以用來實作執行緒安全,基本思想是為非執行緒安全的物件創建一個相應的執行緒安全的外包裝物件,客戶端代碼不直接訪問非執行緒安全的物件而是訪問它的外包裝物件. 外包裝物件與非執行緒安全的物件具有相同的介面,即外包裝物件的使用方式與非執行緒安全物件的使用方式相同,而外包裝物件內部通常會借助鎖,以執行緒安全的方式呼叫相應的非執行緒安全物件的方法,
在java.util.Collections`工具類中提供了一組`synchronizedXXX(xxx)可以把不是執行緒安全的xxx集合轉換為執行緒安全的集合,它就是采用了這種裝飾器模式. 這個方法回傳值就是指定集合的外包裝物件.這類集合又稱為同步集合,
使用裝飾器模式的一個好處就是實作關注點分離,在這種設計中,實作同一組功能的物件的兩個版本:非執行緒安全的物件與執行緒安全的物件. 對于非執行緒安全的在設計時只關注要實作的功能,對于執行緒安全的版本只關注執行緒安全性,
十、鎖的優化及注意事項
多核CPU時代,多執行緒能明顯提高效率,但是鎖的不當使用,會讓效率下降,
減少鎖持有時間
對于使用鎖進行并發控制的應用程式來說,如果單個執行緒特有鎖的時間過長,會導致鎖的競爭更加激烈,會影響系統的性能.在程式中需要盡可能減少執行緒對鎖的持有時間,如下面代碼:
public synchronized void syncMethod(){
othercode1();
mutexMethod();
othercode();
}
在syncMethod同步方法中,假設只有mutexMethod()方法是需要同步的, othercode1()方法與othercode2()方法不需要進行同步. 如果othercode1與othercode2這兩個方法需要花費較長的CPU時間,在并發量較大的情況下,這種同步方案會導致等待執行緒的大量增加. 一個較好的優化方案是,只在必要時進行同步,可以減少鎖的持有時間,提高系統的吞吐量,如把上面的代碼改為:
public void syncMethod(){
othercode1();
synchronized (this) {
mutexMethod();
}
othercode();
}
只對mutexMethod()方法進行同步,這種減少鎖持有時間有助于降低鎖沖突的可能性,提升系統的并發能力,
減小鎖的粒度
一個鎖保護的共享資料的數量大小稱為鎖的粒度. 如果一個鎖保護的共享資料的數量大就稱該鎖的粒度粗,否則稱該鎖的粒度細.鎖的粒度過粗會導致執行緒在申請鎖時需要進行不必要的等待.
例如某柜臺的業務太多,導致要等待很長時間,現實中把不同業務分為不同柜臺,減少等待時間,
減少鎖粒度是一種削弱多執行緒鎖競爭的一種手段,可以提高系統的并發性,
應用實體:在JDK7前,java.util.concurrent.ConcurrentHashMap類采用分段鎖協議,可以提高程式的并發性,
使用讀寫分離鎖代替獨占鎖
使用 ReadWriteLock讀寫分離鎖可以提高系統性能, 使用讀寫分離鎖也是減小鎖粒度的一種特殊情況. 第二條建議是能分割資料結構實作減小鎖的粒度,那么讀寫鎖是對系統功能點的分割,
在多數情況下都允許多個執行緒同時讀,在寫的使用采用獨占鎖,在讀多寫少的情況下,使用讀寫鎖可以大大提高系統的并發能力,
鎖分離
將讀寫鎖的思想進一步延伸就是鎖分離.讀寫鎖是根據讀寫操作功能上的不同進行了鎖分離.**根據應用程式功能的特點,也可以對獨占鎖進行分離.**如java.util.concurrent.LinkedBlockingQueue類中take()與put()方法分別從隊頭取資料,把資料添加到隊尾. 雖然這兩個方法都是對佇列進行修改操作,由于操作的主體是鏈表,take()操作的是鏈表的頭部,put()操作的是鏈表的尾部,兩者并不沖突. 如果采用獨占鎖的話,這兩個操作不能同時并發,在該類中就采用鎖分離,take()取資料時有取鎖, put()添加資料時有自己的添加鎖,這樣take()與put()相互獨立實作了并發,
粗鎖化
為了保證多執行緒間的有效并發,會要求每個執行緒持有鎖的時間盡量短.但是凡事都有一個度,如果對同一個鎖不斷的進行請求,同步和釋放,也會消耗系統資源.如:
public void method1(){
synchronized( lock ){
同步代碼塊1
}
synchronized( lock ){
同步代碼塊2
}
}
JVM在遇到一連串不斷對同一個鎖進行請求和釋放操作時,會把所有的鎖整合成對鎖的一次請求,從而減少對鎖的請求次數,這個操作叫鎖的粗化,如上一段代碼會整合為:
public void method1(){
synchronized( lock ){
同步代碼塊1
同步代碼塊2
}
}
在開發程序中,也應該有意識的在合理的場合進行鎖的粗化,尤其在回圈體內請求鎖時,如:
for(int i = 0 ; i< 100; i++){
synchronized(lock){}
}
這種情況下,意味著每次回圈都需要申請鎖和釋放鎖,所以一種更合理的做法就是在回圈外請求一次鎖,如:
synchronized( lock ){
for(int i = 0 ; i< 100; i++){}
}
JVM鎖優化
鎖偏向
鎖偏向是一種針對加鎖操作的優化,如果一個執行緒獲得了鎖,那么鎖就進入偏向模式, 當這個執行緒再次請求鎖時,無須再做任何同步操作,這樣可以節省有關鎖申請的時間,提高了程式的性能,
鎖偏向在沒有鎖競爭的場合可以有較好的優化效果,對于鎖競爭 比較激烈的場景,效果不佳, 鎖競爭激烈的情況下可能是每次都是不同的執行緒來請求鎖,這時偏向模式失效,
量級鎖
如果鎖偏向失敗,JVM不會立即掛起執行緒,還會使用一種稱為輕量級鎖的優化手段. 會將物件的頭部作為指標,指向持有鎖的執行緒堆疊內部, 來判斷一個執行緒是否持有物件鎖. 如果執行緒獲得輕量級鎖成功,就進入臨界區. 如果獲得輕量級鎖失敗,表示其他執行緒搶到了鎖,那么當前執行緒的鎖的請求就膨脹為重量級鎖.當前執行緒就轉到阻塞佇列中變為阻塞狀態,
偏向鎖,輕量級鎖都是樂觀鎖, 重量級鎖是悲觀鎖,
一個物件剛開始實體化時,沒有任何執行緒訪問它,它是可偏向的,即它認為只可能有一個執行緒來訪問它,所以當第一個執行緒來訪問它的時候,它會偏向這個執行緒. 偏向第一個執行緒,這個執行緒在修改物件頭成為偏向鎖時使用CAS操作,將物件頭中ThreadId改成自己的ID,之后再訪問這個物件時,只需要對比ID即可. 一旦有第二個執行緒訪問該物件,因為偏向鎖不會主動釋放,所以第二個執行緒可以查看物件的偏向狀態,當第二個執行緒訪問物件時,表示在這個物件上已經存在競爭了,檢查原來持有物件鎖的執行緒是否存活,如果掛了則將物件變為無鎖狀態,然后重新偏向新的執行緒; 如果原來的執行緒依然存活,則馬上執行原來執行緒的堆疊,檢查該物件的使用情況,如果仍然需要偏向鎖,則偏向鎖升級為輕量級鎖,
輕量級鎖認為競爭存在,但是競爭的程度很輕,一般兩個執行緒對同一個鎖的操作會錯開,或者稍微等待一下(自旋)另外一個執行緒就會釋放鎖. 當自旋超過一定次數,或者一個執行緒持有鎖,一個執行緒在自旋,又來第三個執行緒訪問時, 輕量級鎖會膨脹為重量級鎖, 重量級鎖除了持有鎖的執行緒外,其他的執行緒都阻塞,
自旋鎖
鎖膨脹后,JVM為了避免執行緒在真實的層面被掛起,JVM還會做最后的努力,這就是自旋鎖. 當前執行緒無法立即獲得鎖,但是在什么時候可以獲得鎖也不一定, 也許在幾個CPU周期后就可以得到鎖, 如果是這樣的話,簡單的將執行緒掛起可能是一種得不償失的操作. 因此JVM會進行一次賭注: JVM期望在不久的將來可以得到鎖. 因為JVM會讓當前的執行緒做幾個慷訓圈,在經過若干次回圈后,如果可以得到鎖就進入臨界區,如果還不能得到鎖則將執行緒真實的掛起,
鎖消除
鎖消除是一種更徹底的鎖優化, JVM在JIT編譯時,會通過掃描背景關系,去除不可能存在共享資源競爭的鎖, 通過鎖消除,可以節省毫無意義的請求鎖時間,
多執行緒開發良好的實踐
- 給執行緒起個有意義的名字,這樣可以方便找 Bug,
- 縮小同步范圍,從而減少鎖爭用,例如對于 synchronized,應該盡量使用同步塊而不是同步方法,
- 多用同步工具少用 wait() 和 notify(),首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 這些同步類簡化了編碼操作,而用 wait() 和 notify() 很難實作復雜控制流;其次,這些同步類是由最好的企業撰寫和維護,在后續的 JDK 中還會不斷優化和完善,
- 使用 BlockingQueue 實作生產者消費者問題,
- 多用并發集合少用同步集合,例如應該使用 ConcurrentHashMap 而不是 Hashtable,
- 使用本地變數和不可變類來保證執行緒安全,
- 使用執行緒池而不是直接創建執行緒,這是因為創建執行緒代價很高,執行緒池可以有效地利用有限的執行緒來啟動任務,
readLocal實體都有當前執行緒與特有實體之間的一個關聯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/306285.html
標籤:其他