冒泡排序及其優化
?????冒泡排序基本思想
1.從頭依次訪問陣列每個元素,進行相鄰元素之間的交換
2.元素之間兩兩交換,把小的換到前面,大的放到后面,
3.所有元素交換完成后,一趟交換完成,此時最大的元素會到陣列尾部,
4.反復執行以上步驟,直到所有元素都排序完,
結束條件:在任何一趟進行程序中,未出現交換,
注意點:冒泡演算法通過雙回圈來控制跑的趟數和每趟需要比較的元素,即外層回圈控制跑的趟數,內層回圈控制需要比較的元素個數,
一趟最壞的情況是排好一個元素,所以n個元素需要n趟,因為剩最后一個元素時,已經排好序,所以最后需要n - 1趟,
編程思想:當解決某類問題沒有思路時,可以借助實體進行分析,
eg:冒泡排序中,當不知道j的判斷條件時,可以對實體進行分析,第一輪有10個元素,
進行10 - 1次交換,第二輪有10個元素,進行10 - 1 - j(此時的j為1) =8交換,
通過結果逆推出代碼,
// 冒泡排序
public static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {// 輪數
for (int j = 0; j < arr.length - i - 1; j++) {// 次數
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
優化一:
假設我們現在排序arr[] = { 1, 2, 3, 4, 5, 6, 7, 9, 8 }這組資料,按照上面的排序方法,第一趟排序后將8 和9 已經交換有序,接下來的排序就是多余的,什么也沒做,所以我們
可以在交換的地方加一個標記,如果那一趟排序沒有交換元素,說明這組資料已經有序,不用再繼續下去,
// 冒泡排序優化一:連片有序而整體無序,eg:{1,2,3,4,5,7,6}
public static void bubbleSort1(int[] arr) {
boolean flag = true;// 定義一個標志,監測某一輪是否發生交換
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
flag = false;
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
if (flag) {
break;
}
}
}優化二:
優化一僅僅適用于連片有序而整體無序的資料(例如:1,2,3,4,5,7,6),但是對于前面大部分是無序而后面小半部分有序的資料(1,2,5,7,4,3,6,8,9,10)排序效率也不樂觀,對于這種資料型別,我們可以繼續優化,即我們可以記下最后一次交換的位置,后邊沒有交換,必然是有序的,然后下一次排序從第一個比較 到 上一次記錄的位置 直至結束即可,
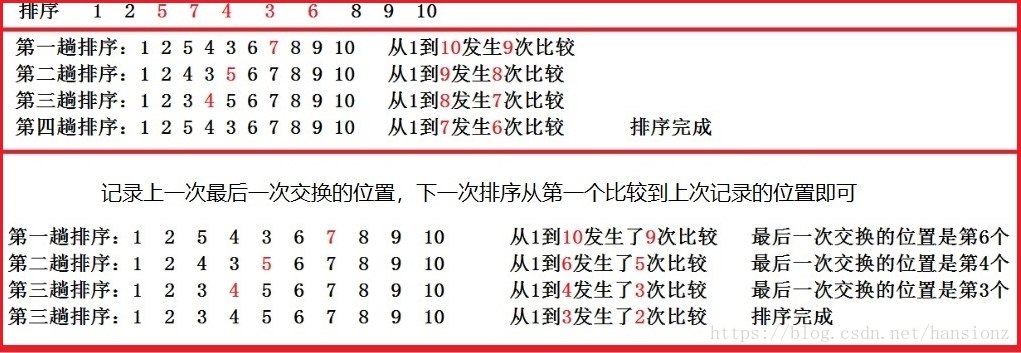
注:第二種優化不需要使用flag,比較多余,如果最后交換位置為0,就已經說明沒有交換了
// 冒泡排序優化二:前面大部分無序而后面小半部分有序,eg:{1,2,5,7,4,3,6,8,9,10}
public static void bubbleSort2(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {// 輪數
int end = arr.length - 1;
int pos = 0;// 記錄一輪中最后一次發生交換的位置
for (int j = 0; j < end; j++) {// 次數
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
pos = j;
}
}
end = pos;// 下一次比較到記錄位置即可
}
}
優化三:
雙向冒泡排序,又叫雞尾酒排序:它的程序是:先從左往右比較一次,再從右往左比較一次,然后又從左往右比較一次,以此類推,
優點:能夠再特定條件下,減少排序的回合數;缺點:代碼量增大一倍,使用場景:大部分元素已經有序的情況下,
他是為了優化前面的大部分元素都已經排好序的陣列,例如對于陣列[2,3,4,5,6,7,8,1]如果使用普通的冒泡排序,需要比較7次;而換成雙向冒泡排序,只需比較三次,
簡單起見,先看下單純的雙向冒泡排序(沒有結合前面兩種優化):
// 冒泡排序優化三(雙向冒泡排序):大部分元素已經有序的情況下,{2,3,4,5,6,7,8,1}
public static void bubbleSort3(int[] arr) {
int temp = 0;
for (int i = 0; i < arr.length / 2; i++) {
// 奇數輪,從左向右比較和交換
for (int j = i; j < arr.length - 1; j++) {
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
// 偶數輪,從右向左比較和交換
for (int j = arr.length - i - 1; j > i; j--) {
if (arr[j] < arr[j - 1]) {
temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
}
}
}最終優化:優化一 + 優化二 + 優化三
// 最終優化:方式一 + 方式二 + 方式三
public static void bubbleSort4(int[] arr) {
int temp = 0;
boolean flag = true;// 標志
int leftEnd = 0;// 無序數列的左邊界,每次比較只需要比到這里為止
int rightEnd = arr.length - 1;// 無序數列的右邊界,每次比較只需要比到這里為止
int posLeft = 0;// 記錄左側最后一次交換的位置
int posRight = 0;// 記錄右側最后一次交換的位置
for (int i = 0; i < arr.length / 2; i++) {
// 奇數輪,從左向右開始交換
for (int j = leftEnd; j < rightEnd; j++) {
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = false;
posRight = j;
}
}
rightEnd = posRight;
if (flag) {
break;
}
flag = true;// 標志重置!!!!!!!!!!!!!!!!!!!!!!!!!
// 偶數輪,從右向左開始交換
for (int j = rightEnd; j > leftEnd; j--) {
if (arr[j] < arr[j - 1]) {
temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
flag = false;
posLeft = j;
}
}
leftEnd = posLeft;
if (flag) {
break;
}
}
}快速排序及其優化

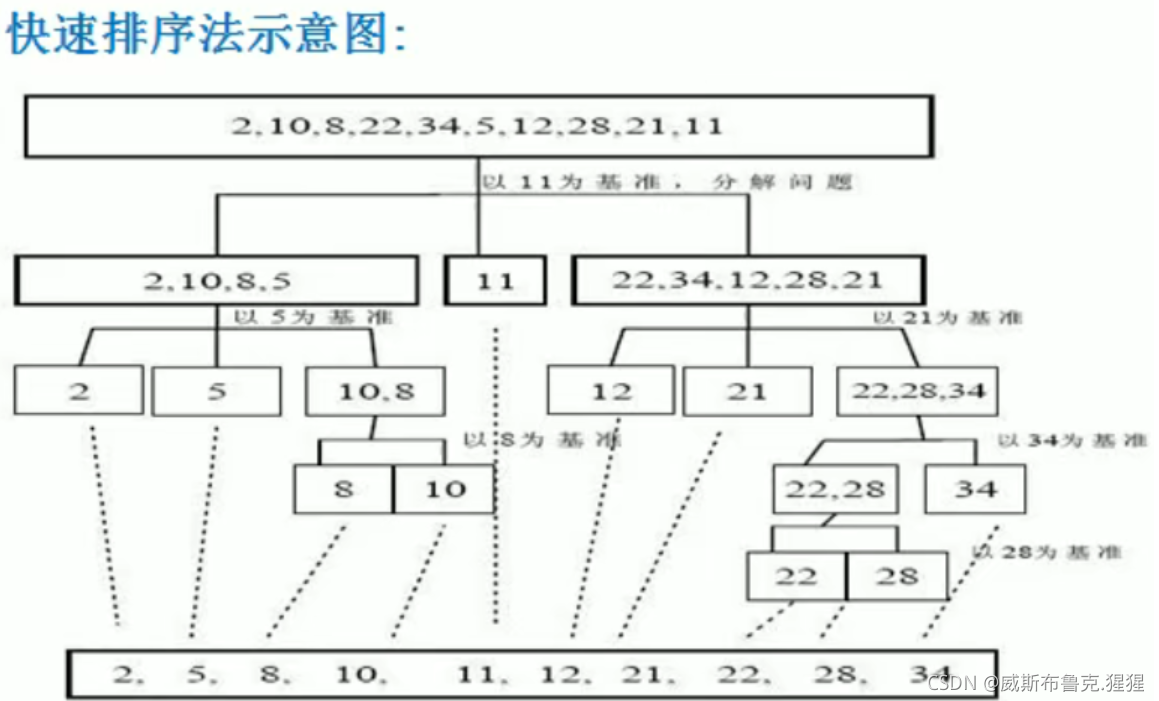 快速排序的三個步驟:
快速排序的三個步驟:
1)選擇基準:在待排序列中,按照某種方式挑出一個元素,作為 "基準"(pivot)
2)分割操作:以該基準在序列中的實際位置,把序列分成兩個子序列,此時,在基準左邊的元素都比該基準小,在基準右邊的元素都比基準大
3)遞回地對兩個序列進行快速排序,直到序列為慷訓者只有一個元素,
優化一:優化選取基準點
對于分治演算法,當每次劃分時,演算法若都能分成兩個等長的子序列時,那么分治演算法效率會達到最大,也就是說,基準的選擇是很重要的,選擇基準的方式決定了兩個分割后兩個子序列的長度,進而對整個演算法的效率產生決定性影響,最理想的方法是,選擇的基準恰好能把待排序序列分成兩個等長的子序列
兩種選擇基準的方法
方法(1):固定位置
思想:取序列的第一個或最后一個元素作為基準
注意:基本的快速排序選取第一個或最后一個元素作為基準,但是,這是一直很不好的處理方法,
思想:取序列的中間元素作為基準,

測驗資料分析:如果輸入序列是隨機的,處理時間可以接受的,如果陣列已經有序時,此時的分割就是一個非常不好的分割,因為每次劃分只能使待排序序列減1,此時為最壞情況,快速排序淪為起泡排序,時間復雜度為O(n^2),而且,輸入的資料是有序或部分有序的情況是相當常見的,因此,使用某一個元素作為樞紐元是非常糟糕的,為了避免這個情況,就引入了下面兩個獲取基準的方法,
方法(2):隨機選取基準
引入的原因:在待排序列是部分有序時,固定選取樞軸使快排效率底下,要緩解這種情況,就引入了隨機選取樞軸
思想:取待排序列中任意一個元素作為基準
int pivot = (int) (Math.random() * (r - l + 1)) + 1;測驗資料分析::這是一種相對安全的策略,由于樞軸的位置是隨機的,那么產生的分割也不會總是會出現劣質的分割,在整個陣列數字全相等時,仍然是最壞情況,時間復雜度是O(n^2),實際上,隨機化快速排序得到理論最壞情況的可能性僅為1/(2^n),所以隨機化快速排序可以對于絕大多數輸入資料達到O(nlogn)的期望時間復雜度,一位前輩做出了一個精辟的總結:“隨機化快速排序可以滿足一個人一輩子的人品需求,”
方法(3):三數取中(median-of-three)
分析:最佳的劃分是將待排序的序列分成等長的子序列,最佳的狀態我們可以使用序列的中間的值,也就是第N/2個數,可是,這很難算出來,并且會明顯減慢快速排序的速度,這樣的中值的估計可以通過隨機選取三個元素并用它們的中值作為樞紐元而得到,事實上,隨機性并沒有多大的幫助,因此一般的做法是使用左端、右端和中心位置上的三個元素的中值作為樞紐元,顯然使用三數中值分割法消除了預排序輸入的不好情形,并且減少快排大約14%的比較次數
舉例:待排序序列為:8 1 4 9 6 3 5 2 7 0
左邊為:8,右邊為0,中間為6.
我們這里取三個數排序后,中間那個數作為樞軸,則樞軸為6
注意:在選取中軸值時,可以從由左中右三個中選取擴大到五個元素中或者更多元素中選取,一般的,會有(2t+1)平均磁區法(median-of-(2t+1),三平均磁區法英文為median-of-three),
具體思想:對待排序序列中low、mid、high三個位置上資料進行排序,取他們中間的那個資料作為樞軸,并用0下標元素存盤樞軸,
即:采用三數取中,并用0下標元素存盤樞軸,
/**
* @return 取待排序序列中left、mid、right三個位置上資料,選取他們中間的那個資料作為樞軸
*/
public static int SelectPivotMedianOfThree(int arr[], int left, int right) {
int temp = 0;
int mid = left + ((right - left) >> 1);// 計算陣列中間元素的元素的下標
// 使用三數取中法選擇樞軸
if (arr[mid] > arr[right]) {// 目標:arr[mid] <= arr[right]
temp = arr[mid];
arr[mid] = arr[right];
arr[right] = temp;
}
if (arr[left] > arr[right]) {// 目標:arr[left] <= arr[right]
temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
if (arr[mid] > arr[left]) {// 目標:arr[left] <= arr[mid]
temp = arr[mid];
arr[mid] = arr[left];
arr[left] = temp;
}
// 此時,arr[mid] <= arr[left] <= arr[right]
// left的位置上保留這三個位置上大小為中間的值
return arr[left];
}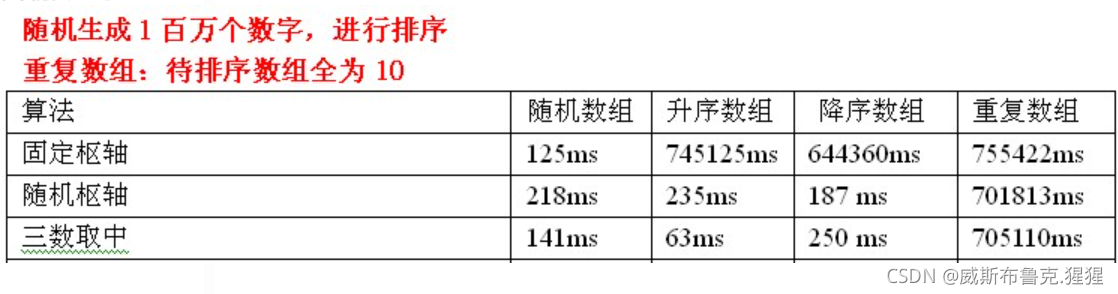
測驗資料分析:使用三數取中選擇樞軸優勢還是很明顯的,但是還是處理不了重復陣列
優化二:當待排序序列的長度分割到一定大小后,使用插入排序
原因:對于很小和部分有序的陣列,快排不如插排好,當待排序序列的長度分割到一定大小后,繼
續分割的效率比插入排序要差,此時可以使用插排而不是快排
截止范圍:待排序序列長度N = 10,雖然在5~20之間任一截止范圍都有可能產生類似的結果,這
種做法也避免了一些有害的退化情形,摘自《資料結構與演算法分析》Mark Allen Weiness 著
if (right - left + 1 < 10) {
insertSort(arr);
return;
}
//else正常的快速排序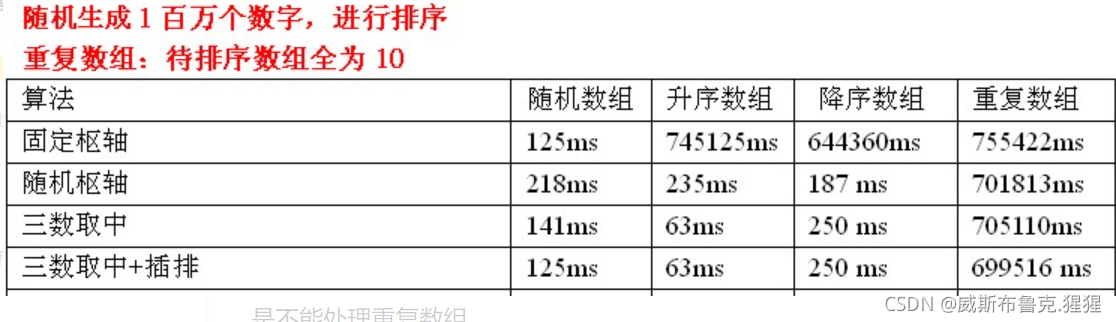
測驗資料分析:針對隨機陣列,使用三數取中選擇樞軸+插排,效率還是可以提高一點,真是針對已排序的陣列,是沒有任何用處的,因為待排序序列是已經有序的,那么每次劃分只能使待排序序列減一,此時,插排是發揮不了作用的,所以這里看不到時間的減少,另外,三數取中選擇樞軸+插排還是不能處理重復陣列
優化三:三路快速排序(雙主元快排)
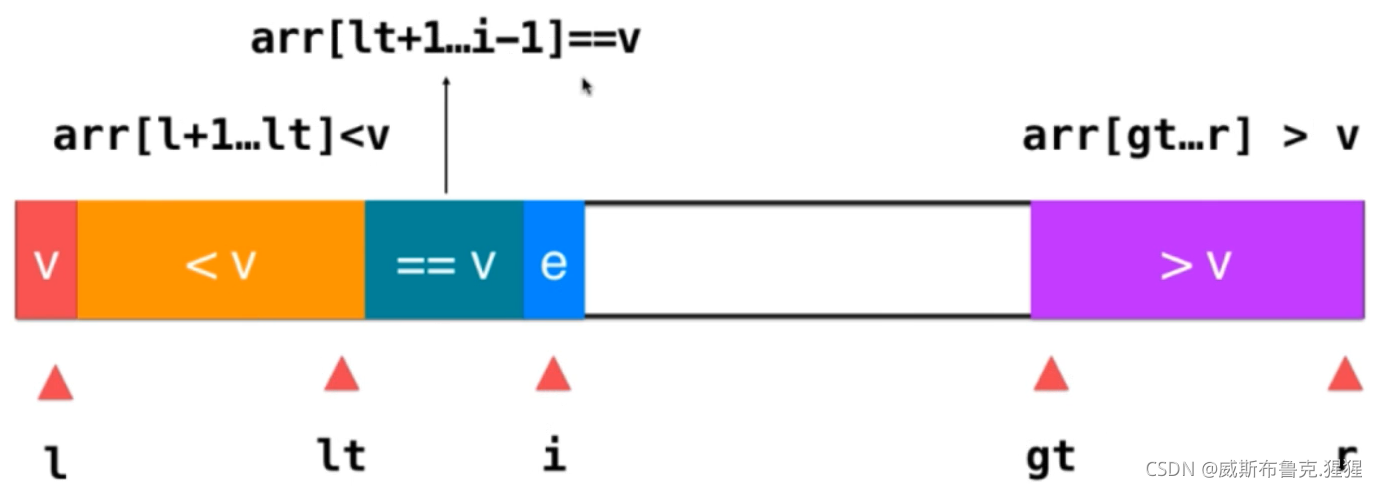
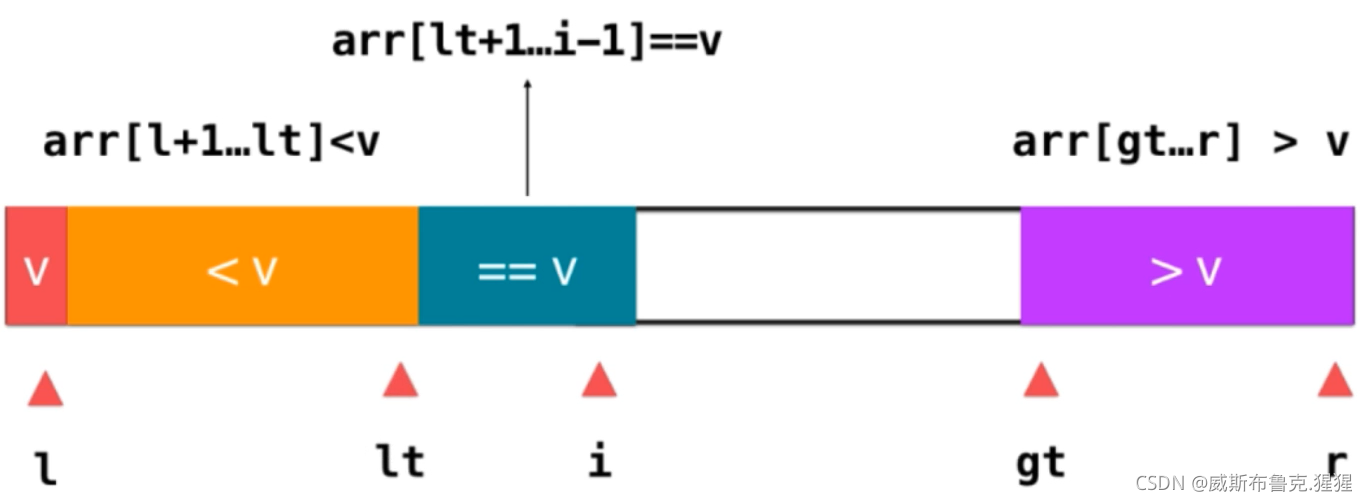
將陣列劃分為大于v、小于v、等于v三部分;l表示小于v部分的第一個元素,r表示大于v部分的最后一個元素;因此:arr[l + 1] ~~arr[lt]這部分表示的是所有小于v的元素;arr[lt + 1]~~arr[i - 1]表示等于v的元素;arr[gt] ~~arr[r] 表示的是大于v這部分元素;i表示當前遍歷到的元素;這樣,就把要遍歷的資料劃分好了;現在的主要問題是,劃分成這樣的區間后,面對一個新的元素,我們應該做咋樣的操作?
1)如果e == v ;就將e融入到等于v的這部分元素中,融入的方式就是i++;
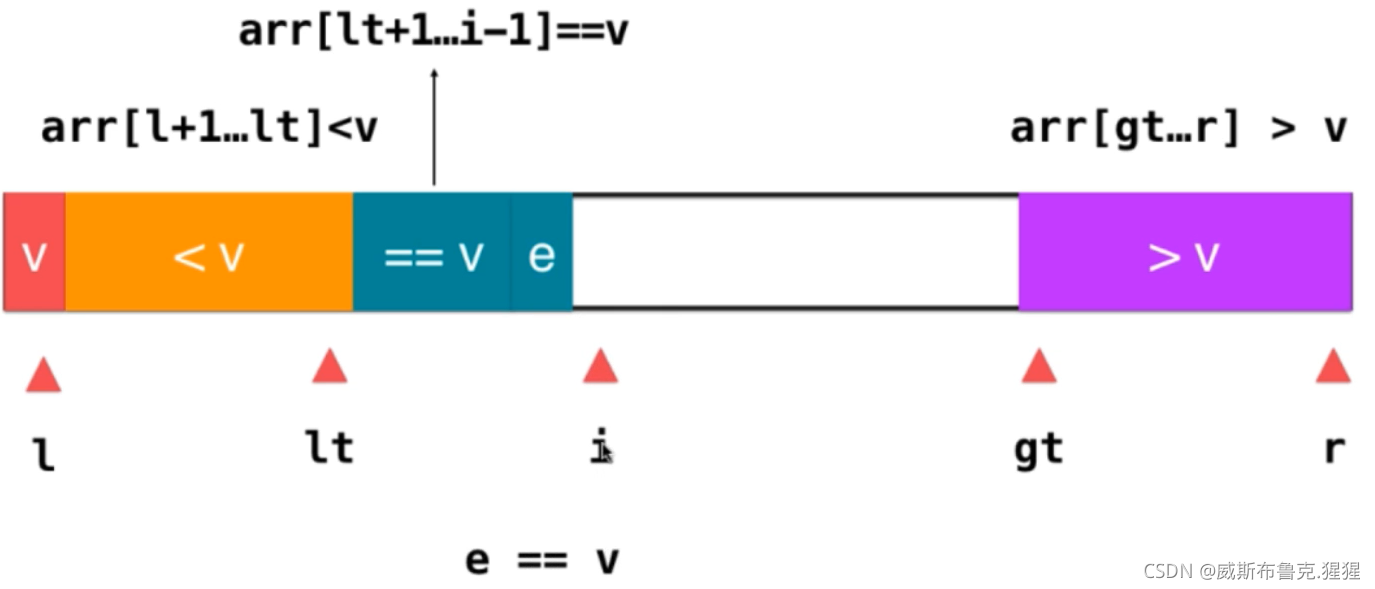
2)如果是e < v ;只需要將e和等于v部分的第一個元素交換位置即可;交換完位置后,e就位于小于v部分的后面了;這樣做的意義就是為了讓e融入小于v部分的元素,融入的方式就是lt++;之后i++,來看下一個元素
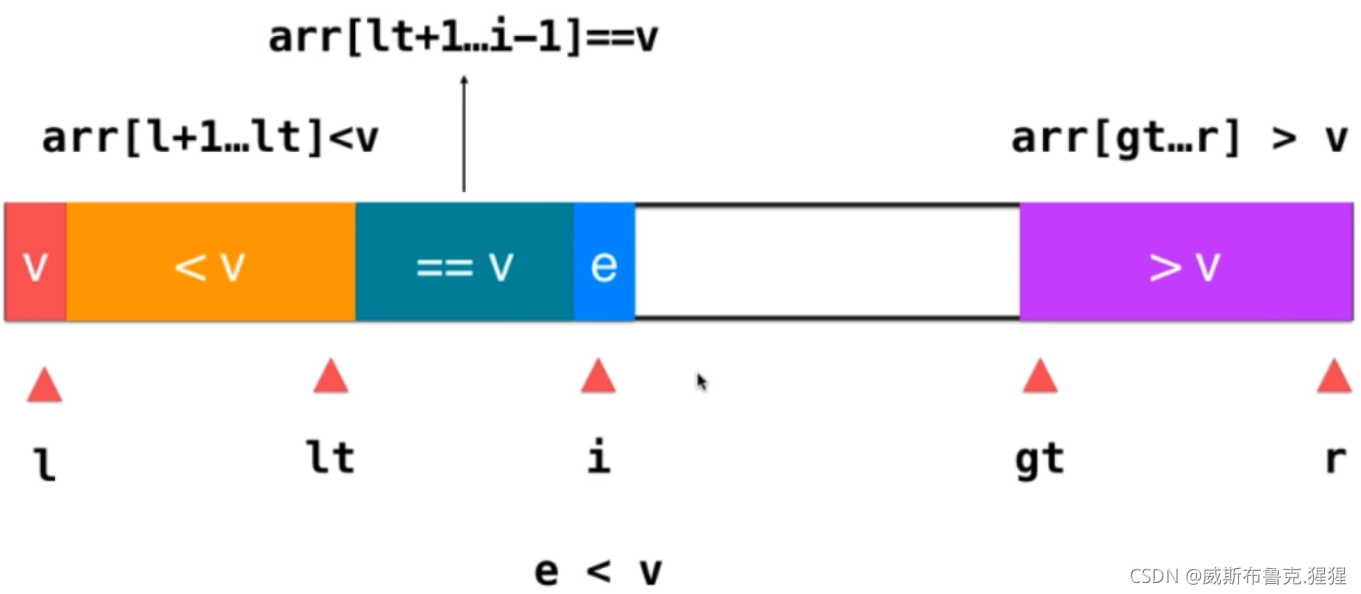
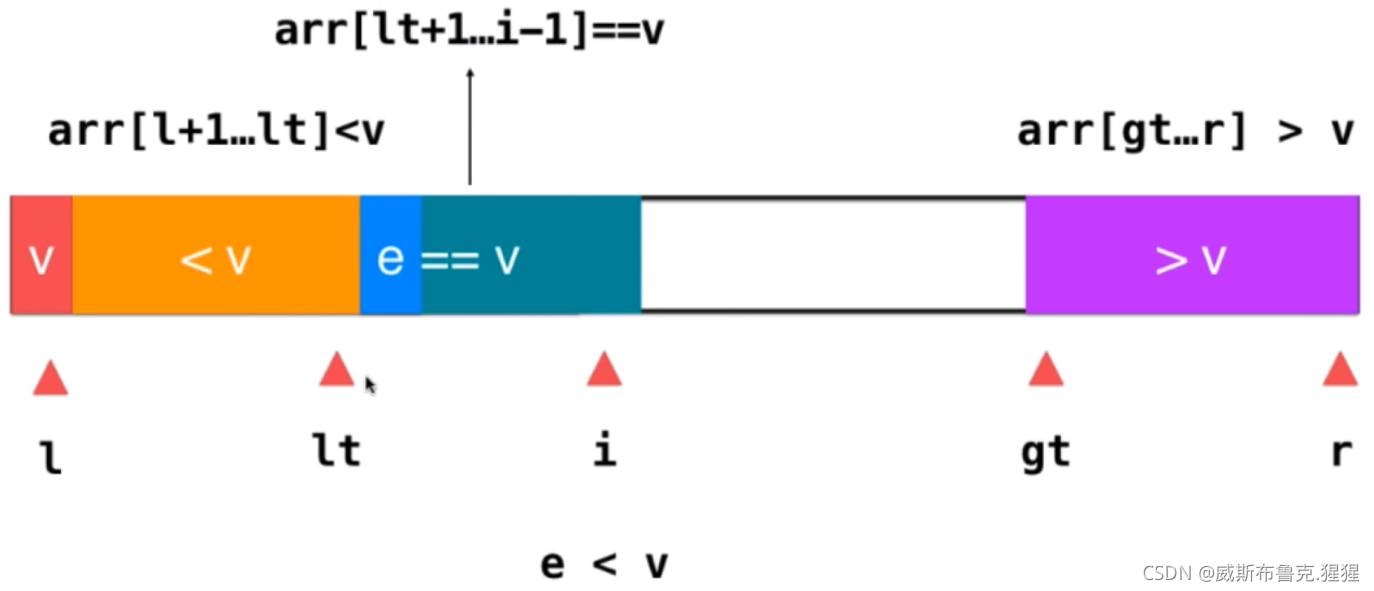
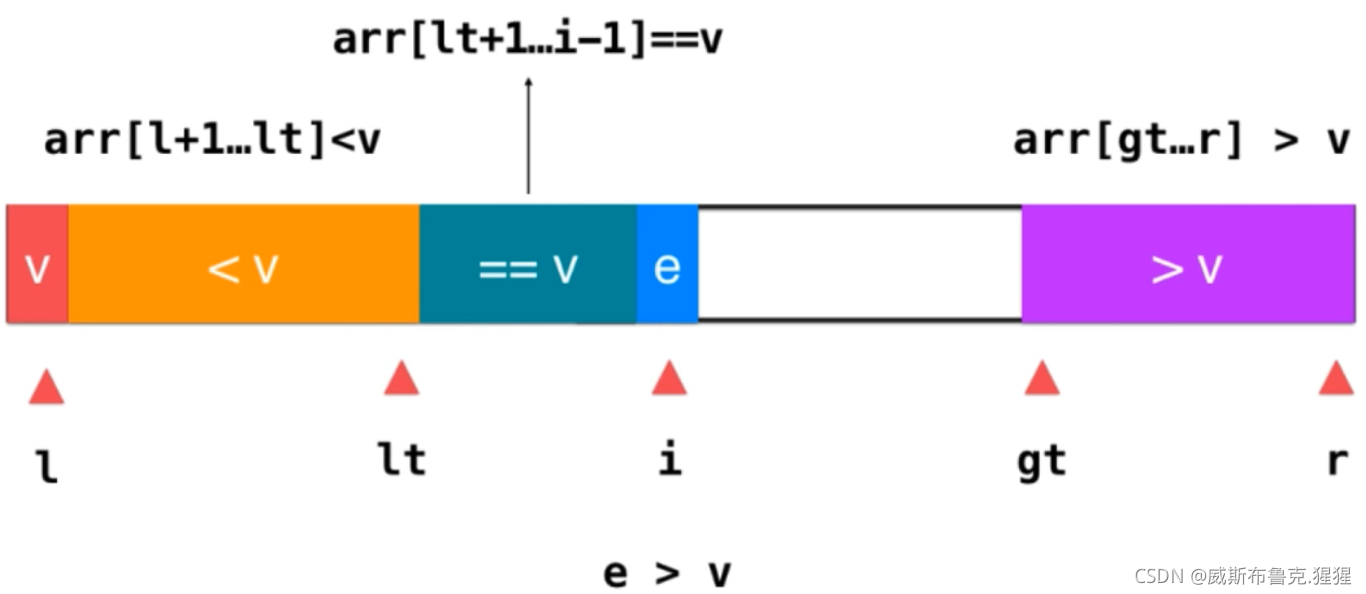
3)如果 e > v ;只需要將此元素與大于v部分的前一個元素交換位置即可,此時,原來的大于v部分的前一個元素是還沒被遍歷的元素,交換后,把它放在了i所指的位置,而e就已經緊挨著大于v這部分元素了,這時將e融入到這部分元素即可,操作為gt--;然后將i++;因為之前交換后,給i所指向的位置挪過來一個未遍歷的元素,此時,只需要繼續判斷這個元素就好了
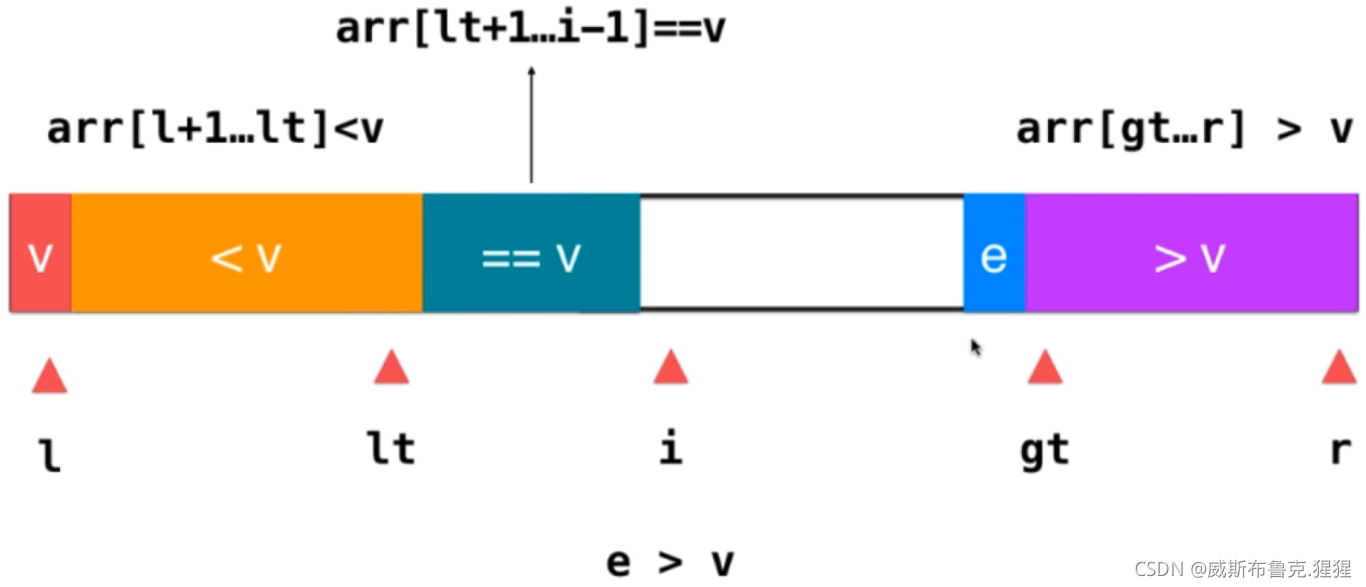
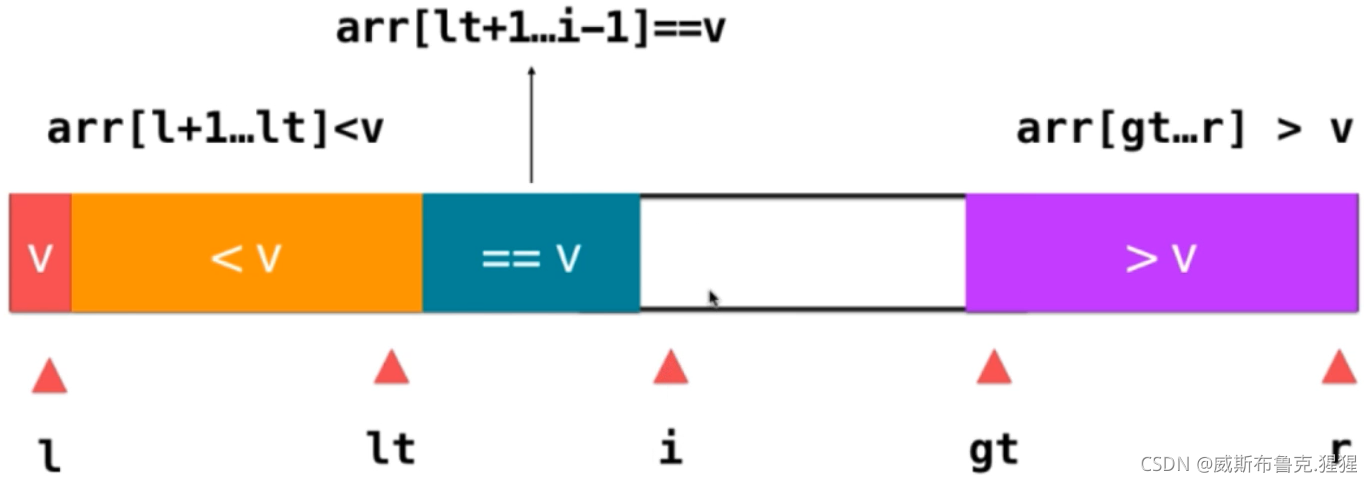
最終,使用以上的方式一直進行下去,原始的資料就被分成了三部分,終止條件是i == gt,表示當前已經遍歷完了所有的元素;然后,還要將v這個元素和lt指向的元素交換一下位置,這樣;lt左邊的元素都是小于v的元素,右邊都是大于等于v的元素;v和等于v這部分元素融為一體,就不需要考慮等于v這部分元素了;下一步,只需要遞回的對大于v和小于v這部分元素進行快速排序即可;三路排序的優點:不用考慮重復元素,極端情況下,如果要排序的資料元素全部相等,只需要一輪三路快排,就可以將所有元素全部排列有序,此時,時間復雜度進化為O(n),三路快排能夠非常好的處理有大量重復元素的資料,同時對于近乎有序的資料和完全無序的資料效果也很好,是很多語言標準庫中排序演算法的底層實作,Java就是這樣



public static void quickSort5(int[] arr, int left, int right) {
int l = left;// 左下標
int r = right;// 右下標
// 定義中軸值
// int pivot = arr[(left + right) / 2];
int pivot = (int) (Math.random() * (r - l + 1)) + l;
int temp = 0;
int v = arr[l];
temp = arr[l];
arr[l] = pivot;
pivot = temp;
int lt = l;
int gt = r + 1;
int i = l + 1;
while (i < gt) {
if (arr[i] < v) {
temp = arr[i];
arr[i] = arr[lt + 1];
arr[lt + 1] = temp;
lt++;
i++;
} else if (arr[i] > v) {
temp = arr[i];
arr[i] = arr[gt - 1];
arr[gt - 1] = temp;
gt--;
} else {
i++;
}
}
// 交換
temp = arr[l];
arr[l] = arr[lt];
arr[lt] = temp;
quickSort5(arr, l, lt - 1);
quickSort5(arr, gt, r);
}
優化四:尾遞回排序
快排函式在函式尾部有兩次遞回操作,我們可以對其使用尾遞回優化
優點:如果待排序的序列劃分極端不平衡,遞回的深度將趨近于n,而堆疊的大小是很有限的,每次遞回呼叫都會耗費一定的堆疊空間,函式的引數越多,每次遞回耗費的空間也越多,優化后,可以縮減堆疊深度,由原來的O(n)縮減為O(logn),將會提高性能,

總結:尾遞回的特點是在回歸程序中不用做任何操作,這個特性很重要,因為大多數現在的編譯器會利用這種特點自動生成優化的代碼;所以我感覺尾遞回的這種方式對于程式員本身而言,知道這種方式就好,因為在實際中,你的代碼有沒有尾遞回的操作,編譯器都會對你的代碼進行優化,所以,就不進行具體的代碼了,重點放在上面的三路快排!!
快速排序的實際應用
Java 7的對于排序演算法的底層使用了三路快排,Go的排序演算法的底層綜合了插入排序、三位取中選取基準、三路快排的綜合版,在小資料的時候會使用插入排序以及希爾排序,為了避免大資料的堆疊溢位所以也使用了堆排序,一般的情況下,Go會優先使用三路快排,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/306470.html
標籤:其他