目前,我使用以下代碼來查找最近的給定地理點 -
def get_closest_stops(lat, lng, data=db.STOPS):
def distance(lat1, lon1, lat2, lon2):
p = 0.017453292519943295
a = 0.5 - cos((lat2-lat1)*p)/2 cos(lat1*p)*cos(lat2*p) * (1-cos((lon2-lon1)*p)) / 2
return 12742 * asin(sqrt(a))
v = {'lat': lat, 'lng': lng}
return sorted(data.values(), key=lambda p: distance(v['lat'],v['lng'],p['lat'],p['lng']), reverse=False)
這是db.STOPS:
STOPS = {
'1282': {'lat': 59.773368, 'lng': 30.125112, 'image_osm': '1652229/464dae0763a8b1d5495e', 'name': 'name 1', 'descr': ''},
'1285': {'lat': 59.941117, 'lng': 30.271756, 'image_osm': '965417/63af068831d93dac9830', 'name': 'name 2', 'descr': ''},
...
}
dict 包含大約 7000 條記錄,搜索速度很慢。有什么辦法可以加快搜索速度嗎?我只需要 5 個結果。我可以重新排序字典。如果需要,我什至可以創建字典的副本。
uj5u.com熱心網友回復:
TLDR:numpy 提供了 10 倍的加速,分割距離又提高了 3 倍,總共約 30..50 倍。使用曼哈頓距離作為消除不可行候選的更便宜的近似值具有大致相同的效果,但不那么直觀。
這是一個帶有完整代碼的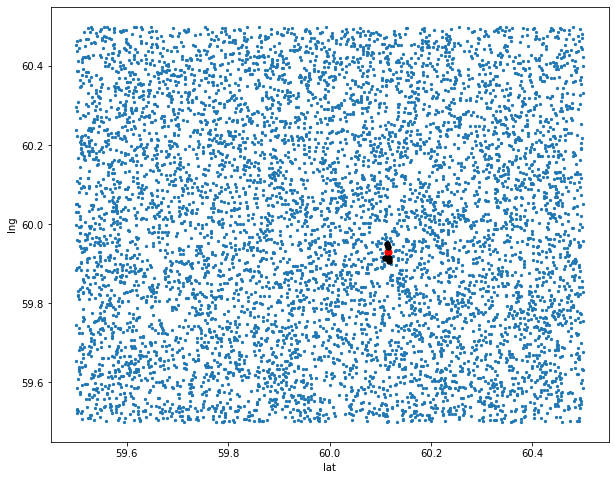
uj5u.com熱心網友回復:
使用多執行緒,并將記錄分解為可用執行緒數
希望這有助于多執行緒的教程點頁面
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/312287.html
標籤:Python python-2.7 排序 字典 地理