聊聊分布式事務,再說說解決方案
分布式事務CAP理解論證-解決方案
分布式系統的2PC、3PC詳細分析
github tcc示例
分布式事務、重復消費、順序消費
一、理論
CAP相關:
CAP與BASE相關:我的博客
而對于分布式中的問題的解決方案,CAP原則出現,描述如下:
一致性(Consistency):
像A節點寫入一條資訊之后,同一時刻,在其他節點都可以讀到這條資訊
可用性(Availability):
多布一些節點A,B,C…,任何時刻,用戶訪問,都應該以可預期的結果回傳,而不是瀏覽器報錯,404,500,頁面丟失…等用戶體驗不好的情況發生
磁區容忍性(PartitionTolerance):
當各系統模塊間通信出現問題時,設計一個策略,使系統仍可對外提供滿足一致性或可用性
剛接觸cap時,有些不理解磁區容忍性,我們自己倒推一下:
- 為了保證一致性,我們需要各個節點同步訊息
- 為了保證可用性我們可以多部署節點,部分節點掛了仍可對外提供服務
- 為了保證磁區容忍性:此刻卡殼了,怎么做?沒了一種具體的方式,然而他還是客觀存在的,后來發現:進入了思維盲點:只要在分布式場景中,磁區必然存在,那么如果不處理磁區發生時的情況,節點無法通訊時會發生什么?–此刻如果仍對外提供服務,那么導致無法同步訊息,即保證不了強一致性;如果要保證強一致性,那么就需要節點阻塞,一直等待通訊恢復,即保證不了可用性.
所以磁區容忍性就是:當發生磁區問題時,我們使用策略,在一致性和可用性二者間選擇
注意: 無法通信包括網路問題,或者節點機器宕機
誤區: CAP理論中說三者不可兼得,但實際情況是,在分布式場景中磁區一定存在,即必須有磁區容忍性對應的策略,之后才能在一致性和可用性間二者之間選擇.所以對主流架構來說不是三選二,而是二選一,
對P的理解
很多人可能對磁區容忍性不太理解,知乎有一個回答對這個解釋的比較清楚CAP理論中的P到底是個什么意思?,這里參考一下:
- 一個分布式系統里面,節點組成的網路本來應該是連通的,然而可能因為一些故障,使得有些節點之間不連通了,整個網路就分成了幾塊區域,資料就散布在了這些不連通的區域中,這就叫磁區,
- 當你一個資料項只在一個節點中保存,那么磁區出現后,和這個節點不連通的部分就訪問不到這個資料了,這時磁區就是無法容忍的,
- 提高磁區容忍性的辦法就是一個資料項復制到多個節點上,那么出現磁區之后,這一資料項就可能分布到各個區里,容忍性就提高了,
- 然而,要把資料復制到多個節點,就會帶來一致性的問題,就是多個節點上面的資料可能是不一致的,
- 要保證一致,每次寫操作就都要等待全部節點寫成功,而這等待又會帶來可用性的問題,
- 總的來說就是,資料存在的節點越多,磁區容忍性越高,但要復制更新的資料就越多,一致性就越難保證,為了保證一致性,更新所有節點資料所需要的時間就越長,可用性就會降低,
XA規范:
http://www.jasongj.com/big_data/two_phase_commit/
https://www.cnblogs.com/zhoujinyi/p/5257558.html
XA規范中,事務管理器主要通過以下的介面對資源管理器進行管理
- xa_open,xa_close:建立和關閉與資源管理器的連接,
- xa_start,xa_end:開始和結束一個本地事務,
- xa_prepare,xa_commit,xa_rollback:預提交、提交和回滾一個本地事務,
- xa_recover:回滾一個已進行預提交的事務,
XA規范:https://www.cnblogs.com/wt645631686/p/10882998.html
解決方案
一些具體實作
- 維護本地訊息表
- 使用rocketmq事務訊息:https://blog.csdn.net/weixin_40533111/article/details/84451219
- 兩階段提交協議(2PC)
- TCC事務補償機制
使用限制:
a. XA事務和本地事務以及鎖表操作是互斥的
開啟了xa事務就無法使用本地事務和鎖表操作:
mysql> xa start 't1xa';
Query OK, 0 rows affected (0.04 sec)
mysql> begin;
ERROR 1399 (XAE07): XAER_RMFAIL: The command cannot be executed when global transaction is in the ACTIVE state
mysql> lock table t1 read;
ERROR 1399 (XAE07): XAER_RMFAIL: The command cannot be executed when global transaction is in the ACTIVE state
開啟了本地事務就無法使用xa事務:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> xa start 'rrrr';
ERROR 1400 (XAE09): XAER_OUTSIDE: Some work is done outside global transaction
b. xa start 之后必須xa end, 否則不能執行xa commit 和xa rollback
所以如果在執行xa事務程序中有陳述句出錯了,你也需要先xa end一下,然后才能xarollback,
注意事項:
a. mysql只是提供了xa事務的介面,分布式事務中的mysql實體之間是互相獨立的不感知的, 所以用戶必須
自己實作分布式事務的調度器
b. xa事務有一些使用上的bug, 參考http://www.mysqlops.com/2012/02/24/mysql-xa-optimize.html
主要是:
“MySQL資料庫的主備資料庫的同步,通過Binlog的復制完成,而Binlog是MySQL資料庫內部XA事務的協調者,并且MySQL資料庫為binlog做了優化——binlog不寫prepare日志,只寫commit日志,
所有的參與節點prepare完成,在進行xa commit前crash,crash recover如果選擇commit此事務,由于binlog在prepare階段未寫,因此主庫中看來,此分布式事務最終提交了,但是此事務的操作并未 寫到binlog中,因此也就未能成功復制到備庫,從而導致主備庫資料不一致的情況出現,
而crash recover如果選rollback, 那么就會出現全域不一致(該分布式事務對應的節點,部分已經提交,無法回滾,而部分節點回滾,最終導致同一分布式事務,在各參與節點,最終狀態不一致)”
參考的那篇blog中給出的辦法是修改mysql代碼,這個無法在DBScale中使用, 所以可選的替代方案是不使用
主從復制進行備份,而是直接使用xa事務實作同步寫來作為備份,
二、兩階段提交2PC
1. 介紹
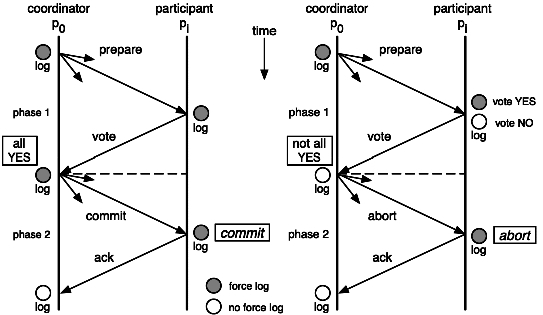
兩個角色:
- 協調者
- 參與者
兩個階段:
- 階段一:提交事務請求
- 階段二:執行事務提交
犧牲了一部分可用性來換取的一致性,解決方案有:springboot+Atomikos or Bitronix
優點: 原理簡單,實作方便
缺點:
- 同步阻塞:在提交的程序中,所有參與者都處于阻塞狀態,大大降低并發度
- 單點問題:一旦協調者出現問題,則所有參與者處于鎖定狀態,無法對外服務
- 資料不一致:在階段二,協調者發送了commit之后,發生了區域網路例外或者協調者尚未發送完commit請求就宕機了,導致部分參與者收到commit,導致系統出現不一致
- 太過保守:協調者在階段一中,參與者出現故障而導致協調者無法獲取到所有參與者的回應,協調者只能依靠超時時間來判斷是否中斷事務,換句話說,沒有完善的容錯機制,
2. 實作
JTA(Java Transaction API)定義了對XA事務的支持,像很多其他的Java規范一樣,JTA僅僅定義了介面,具體的實作則是由供應商(如J2EE廠商)負責提供,目前JTA的實作主要有以下幾種:
- J2EE容器所提供的JTA實作(如JBoss),
- 獨立的JTA實作:如JOTM(Java Open Transaction Manager),Atomikos,這些實作可以應用在那些不使用J2EE應用服務器的環境里用以提供分布事事務保證,
MySQL中的XA實作分為:外部XA和內部XA,前者是指我們通常意義上的分布式事務實作;后者是指單臺MySQL服務器中,Server層作為TM(事務協調者),而服務器中的多個資料庫實體作為RM,而進行的一種分布式事務,也就是MySQL跨庫事務;也就是一個事務涉及到同一條MySQL服務器中的兩個innodb資料庫(因為其它引擎不支持XA),
三、三階段提交3PC
是二階段的改進版,將二階段的提交事務請求程序一分為二,形成了:
- CanCommit:協調者發送事務詢問、參與者反饋
- PreCommit:協調者發送預提交請求、參與者事務預提交(執行事務操作,寫undo、redo日志)、參與者回應
- doCommit:協調者發送提交請求、參與者事務提交(事務提交,釋放資源)、參與者回應
在階段二中,參與者可能會回應no,或者協調者等待超時時間后還無法收到所有參與者的反饋,則中斷事務:協調者向所有參與者發送abort請求,參與者無論是收到協調者的abort請求,或者等待協調者請求程序中超時,都會中斷事務,
在階段三中,如果有任一參與者發送了no,或者等待超時后協調者還沒收到所有參與者的反饋,則中斷事務,需要注意的事,進入階段三,可能會有下面兩種故障:
- 協調者出現問題
- 協調者、參與者之間的網路出現問題
無論哪種情況,都會導致參與者無法及時收到來自協調者的doCommit或者abort請求,這種情況,參與者在等待超時后繼續進行事務提交,
優點:
- 降低了參與者的阻塞范圍(二階段中如果參與者與協調者斷開,參與者abort;三階段,提交),并且能夠在單點故障后繼續達成一致,
缺點:
- 參與者在收到preCommit后出現網路磁區,參與者依然會提交事務,會造成不一致,
四、實作
todo
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/32427.html
標籤:架構設計
上一篇:樂觀鎖和悲觀鎖的一個例子